【Kafka】ZK和Kafka集群的安装和配置
一、集群环境说明
1. 虚拟机:192.168.223.101/103/105
2. 系统版本:CentOS 7.9
3. JDK版本:11.0.18.0.1
4. Zookeeper版本:3.7.1
5. Kafka版本:2.13-2.8.2
备注:无论是ZK,还是Kafka,都需要用到JDK,我上面给出的ZK和Kafka版本,都已经支持JDK11。这三者之间的兼容关系,感兴趣的可以去对应的官网上查询相关官方Docs,这里就不做赘述了。
二、集群组件部署
2.1 安装JDK
使用root用户安装JDK11,JDK目录为:/usr/jdk-11.0.18.0.1
tar -xzf jdk-11.0.18.0.1_linux-x64_bin.tar.gz
rm -f jdk-11.0.18.0.1_linux-x64_bin.tar.gz
# 目录授权,供其他用户和组调用
chmod -R 755 jdk-11.0.18.0.12.2 创建用户和组
由于Zookeeper和Kafka的安装和运行无需root用户,因此从安全角度考虑,我们为其安装和运行创建普通用户和组(app:apps)。
groupadd apps
useradd -d /app -g apps app
chmod -R 755 /app
chown -R app:apps /app2.3配置Java环境变量
首先,我们切换到app用户下,然后vi .bash_profile这个文件(如果不存在可以直接vi创建即可)。然后将下面的内容黏贴到文件中,并保存退出。最后使用source .bash_profile使配置生效即可。
# .bash_profile# Get the aliases and functions
if [ -f ~/.bashrc ]; then. ~/.bashrc
fi# User specific environment and startup programs
JAVA_HOME=/usr/jdk-11.0.18.0.1
export JAVA_HOMECLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar
export CLASSPATHPATH=$JAVA_HOME/bin:$PATH:/usr/local/bin:$HOME/bin
export PATH2.4 安装Zookeeper集群
首先,我们将zk的安装包使用rz命令上传到app用户目录下,然后解压,按照下面的配置编辑配置文件即可。
tar -xzf apache-zookeeper-3.7.1-bin.tar.gz
rm -f ./apache-zookeeper-3.7.1-bin.tar.gz
mv apache-zookeeper-3.7.1-bin/ zookeeper
cd /app/zookeeper/conf
vi zoo.cfg192.168.223.101/103/105三台服务器上的zoo.cfg配置一致,这里需要注意dataDir,需要自定义目录,目录需要提前创建好。
# The number of milliseconds of each tick
tickTime=2000# The number of ticks that the initial synchronization phase can take
initLimit=10# The number of ticks that can pass between sending a request and getting an acknowledgement
syncLimit=5# the directory where the snapshot is stored.do not use /tmp for storage, /tmp here is just example sakes.
dataDir=/app/zookeeper/data# the port at which the clients will connect
clientPort=2181# the maximum number of client connections.increase this if you need to handle more clients
maxClientCnxns=60# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3# Purge task interval in hours Set to "0" to disable auto purge feature
autopurge.purgeInterval=1## Metrics Providers
# https://prometheus.io Metrics Exporter
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpPort=17000
metricsProvider.exportJvmInfo=trueserver.1=192.168.223.101:2888:3888
server.2=192.168.223.103:2888:3888
server.3=192.168.223.105:2888:3888这里不同的配置为myid,配置如下:
# 192.168.223.101
cd /app/zookeeper/data
echo 1 > myid# 192.168.223.103
cd /app/zookeeper/data
echo 2 > myid# 192.168.223.105
cd /app/zookeeper/data
echo 3 > myid最后依次启动三台服务器上的zookeeper即可,并检查当前节点的状态,三个节点中,2个为follower,1个为leader。
cd /app/zookeeper/bin
./zkServer.sh start
./zkServer.sh status到这里,zookeeper集群的安装配置就完成了。下面我们安装安装配置Kafka集群。
2.5 安装Kafka集群
首先,还是先将Kafka的二进制包上传的app用户目录下,然后执行解压、配置和服务启动。
tar -xzf kafka_2.13-2.8.2.tgz
rm -f kafka_2.13-2.8.2.tgz
mv kafka_2.13-2.8.2 kafka
cd kafka/config
mv server.properties server.properties.bak
vi server.properties三台服务器的配置分别如下:
# Server - 192.168.223.101
############################# Server Basics #############################
# 每个节点的broker-id不能一样,需要修改
broker.id=1############################# Socket Server Settings #############################
# 每个节点的listeners,需要修改IP
listeners=PLAINTEXT://192.168.223.101:9092num.network.threads=3
num.io.threads=8socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600############################# Log Basics #############################
# 自定义log目录路径
log.dirs=/app/kafka/logsnum.partitions=3
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy #############################
log.flush.interval.messages=10000
log.flush.interval.ms=1000############################# Log Retention Policy #############################
log.retention.hours=168
log.retention.bytes=1073741824
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000############################# Zookeeper #############################
zookeeper.connect=192.168.223.101:2181,192.168.223.103:2181,192.168.223.105:2181
zookeeper.connection.timeout.ms=18000############################# Group Coordinator Settings #############################
group.initial.rebalance.delay.ms=0# Server - 192.168.223.103
############################# Server Basics #############################
# 每个节点的broker-id不能一样,需要修改
broker.id=2############################# Socket Server Settings #############################
# 每个节点的listeners,需要修改IP
listeners=PLAINTEXT://192.168.223.103:9092num.network.threads=3
num.io.threads=8socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600############################# Log Basics #############################
# 自定义log目录路径
log.dirs=/app/kafka/logsnum.partitions=3
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy #############################
log.flush.interval.messages=10000
log.flush.interval.ms=1000############################# Log Retention Policy #############################
log.retention.hours=168
log.retention.bytes=1073741824
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000############################# Zookeeper #############################
zookeeper.connect=192.168.223.101:2181,192.168.223.103:2181,192.168.223.105:2181
zookeeper.connection.timeout.ms=18000############################# Group Coordinator Settings #############################
group.initial.rebalance.delay.ms=0# Server - 192.168.223.105
############################# Server Basics #############################
# 每个节点的broker-id不能一样,需要修改
broker.id=3############################# Socket Server Settings #############################
# 每个节点的listeners,需要修改IP
listeners=PLAINTEXT://192.168.223.105:9092num.network.threads=3
num.io.threads=8socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600############################# Log Basics #############################
# 自定义log目录路径
log.dirs=/app/kafka/logsnum.partitions=3
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy #############################
log.flush.interval.messages=10000
log.flush.interval.ms=1000############################# Log Retention Policy #############################
log.retention.hours=168
log.retention.bytes=1073741824
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000############################# Zookeeper #############################
zookeeper.connect=192.168.223.101:2181,192.168.223.103:2181,192.168.223.105:2181
zookeeper.connection.timeout.ms=18000############################# Group Coordinator Settings #############################
group.initial.rebalance.delay.ms=0然后,我们依次启动三台服务器上的Kafka即可
cd /app/kafka
./bin/kafka-server-start.sh -daemon ./config/server.properties备注:-daemon为后台启动,这样就无需在启动命令中写nohup …… &这样的字符了。
三、Kafka使用测试
到此为止,三节点的Kafka集群就已经部署完毕,可能部分参数还有待调优,这里就不做详细说明了,生产环境上的配置,以本地的配置为准。
$ cd /app/kafka# 创建topic
$ sh ./bin/kafka-topics.sh --create --zookeeper 192.168.223.103:2181 --replication-factor 1 --partitions 1 --topic my-topic
Created topic my-topic.# 浏览所有topic
$ ./bin/kafka-topics.sh --list --zookeeper 192.168.223.103:2181
my-topic$ ./bin/kafka-topics.sh --list --zookeeper 192.168.223.101:2181
my-topic$ ./bin/kafka-topics.sh --list --zookeeper 192.168.223.105:2181
my-topic# 浏览指定topic
$ ./bin/kafka-topics.sh --describe --zookeeper 192.168.223.103:2181 --topic my-topic
Topic: my-topic TopicId: wfI9VvK1QAyCP9ReZrDlIQ PartitionCount: 1 ReplicationFactor: 1 Configs: Topic: my-topic Partition: 0 Leader: 2 Replicas: 2 Isr: 2# 生产console信息
$ ./bin/kafka-console-producer.sh --broker-list 192.168.223.103:9092 --topic my-topic# 消费Console消息:
$ ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.223.103:9092 --topic my-topic --from-beginning$ cd /app/zookeeper/bin
$ ./zkCli.sh -server 192.168.223.103:2181
[zk: 192.168.223.103:2181(CONNECTED) 6] ls /brokers/topics
[__consumer_offsets, my-topic]相关文章:

【Kafka】ZK和Kafka集群的安装和配置
一、集群环境说明1. 虚拟机:192.168.223.101/103/1052. 系统版本:CentOS 7.93. JDK版本:11.0.18.0.14. Zookeeper版本:3.7.15. Kafka版本:2.13-2.8.2备注:无论是ZK,还是Kafka,都需要…...

并发编程出现的问题以及解决方式
解决并发编程出现的问题基于java内存模式的设计出现的问题基于java内存模式的设计,多线程操作一些共享的数据时,出现以下三个问题:1.不可见性问题:多个线程同时在各自的工作内存对共享数据进行操作,彼此之间不可见。操…...

[ linux ] linux 命令英文全称及解释
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】🎉点赞➕评论➕收藏 养成习…...

C++11新特性
文章目录说在前面花括号{}初始化new的列表初始化STL相关容器的列表初始化相关语法格式容器列表初始化的底层原理forward_list和array与类型相关的新特性decltype左值引用和右值引用什么是左值,什么是右值左值和右值的本质区别右值引用如何理解右值引用std::move移动…...

【宝塔部署SpringBoot前后端不分离项目】含域名访问部署、数据库、反向代理、Nginx等配置
一定要弄懂项目部署的方方面面。当服务器上部署的项目过多时,端口号什么时候该放行、什么时候才会发生冲突?多个项目使用redis怎么防止覆盖?Nginx的配置会不会产生站点冲突?二级域名如何合理配置?空闲的时候要自己用服…...

从0到1一步一步玩转openEuler--11 openEuler基础配置-设置磁盘调度算法
11 openEuler基础配置-设置磁盘调度算法 文章目录11 openEuler基础配置-设置磁盘调度算法11.1 设置磁盘调度算法11.1.1 临时修改调度策略11.1.2 永久设置调度策略11.1 设置磁盘调度算法 本节介绍如何设置磁盘调度算法。 11.1.1 临时修改调度策略 例如将所有IO调度算法修改为…...
河道治理漂浮物识别监测系统 yolov7
河道治理漂浮物识别监测系统通过yolov7网络模型深度视觉分析技术,河道治理漂浮物识别监测算法模型实时检测着河道水面是否存在漂浮物、水浮莲以及生活垃圾等,识别到河道水面存在水藻垃圾等漂浮物,立即抓拍存档预警。You Only Look Once说的是…...
微信小程序 java ssm Springboot学生作业提交管理系统
系统具有良好的集成性,提供标准接口,以实现与其他相关系统的功能和数据集成。开放性好,便于系统的升级维护、以及与各种信息系统进行集成。功能定位充分考虑平台服务对象的需求。 一个微信小程序由.js、.json、.wxml、.wxss四种文件构成&…...

实战项目-课程潜在会员用户预测(朴素贝叶斯&神经网络)
目录1、背景介绍2、朴素贝叶斯2.1 模型介绍2.2 模型实现3、人工神经网络1、背景介绍 目标:将根据用户产生的数据对课程潜在的会员用户(可能产生购买会员的行为)进行预测。 平台的一位注册用户是否购买会员的行为应该是建立在一定背景条件下…...

ESP32设备驱动-定时器与定时器中断
定时器与定时器中断 文章目录 定时器与定时器中断1、ESP32定时器介绍2、定时器相关API介绍3、软件准备4、硬件准备3、代码实现有时需要按时发生某些事情,这就是计时器和计时器中断发挥作用的地方。 定时器是一种中断。 它就像一个简单的时钟,用于测量和控制时间事件,提供精确…...

【JavaScript 逆向】安居客滑块逆向分析
声明本文章中所有内容仅供学习交流,相关链接做了脱敏处理,若有侵权,请联系我立即删除!案例目标验证码:aHR0cHM6Ly93d3cuYW5qdWtlLmNvbS9jYXB0Y2hhLXZlcmlmeS8/Y2FsbGJhY2s9c2hpZWxkJmZyb209YW50aXNwYW0以上均做了脱敏处…...

【STM32】【HAL库】遥控关灯1主机
相关连接 【STM32】【HAL库】遥控关灯0 概述 【STM32】【HAL库】遥控关灯1主机 【STM32】【HAL库】遥控关灯2 分机 【STM32】【HAL库】遥控关灯3 遥控器 需求 主机需要以下功能: 接收来自物联网平台的命令发送RF433信号给从机接收RF433信号和红外信号驱动舵机动作 方案设计…...

Java 初始化块
文章目录1、初识初始化块2、实例初始化块和构造器3、类初始化块1、初识初始化块 Java 使用构造器来对单个对象进行初始化操作,使用构造器先完成对整个 Java 对象的状态初始化,然后将 Java 对象返回给程序,从而让该 Java 对象的信息更加完整。…...
超详细讲解长度受限制的字符串函数(保姆级教程!!!)
超详细讲解长度受限制的字符串函数(保姆级教程!!!)长度受限制的字符串函数strncpy函数strncpy函数的使用strncpy函数的模拟实现strncat函数strncat函数的使用strncat函数的模拟实现strncmp函数strncmp函数的使用strncm…...
——cmd命令提示符,c#调用cmd)
【c#】c#常用小技巧方法整理(4)——cmd命令提示符,c#调用cmd
CMD命令是一种命令提示符,CMD是command的缩写,位于系统System32的目录下,是大多数Windows操作系统中可用的命令行解释器应用程序。用于执行输入的命令。其中大多数命令通过脚本和批处理文件自动执行任务,执行高级管理功能…...
在项目中遇到的关于form表单的问题
前言 以下内容都是基于element Plus 和 vue3 一个form-item校验两个下拉框 有时候不可避免会遇到需要一个form-item校验两个下拉框的情况,比如: 这种情况下传统的校验已经无法实现,需要通过form表单提供的自定义校验来实现。以上面的必填…...

德国奔驰、博世和保时捷的员工年薪有多少?
点击 欧盟IT那些事 关注我们公告:因企鹅审核规定,本公众号从《德国IT那些事》更名为《欧盟IT那些事》。从职场新人到总裁,一个个盘。位于德国斯图加特的梅赛德斯-奔驰集团及其子公司梅赛德斯-奔驰是世界最知名的汽车制造商之一。奔驰车代表着…...
Mybatis与微服务注册
目录 一,Springboot整合MybatisPlus 创建商品微服务子模块 二,SpringBoot整合Freeamarker 三、SpringBoot整合微服务 &gateway&nginx 整合微服务之商品服务zmall-product 创建并配置网关gateway服务 安装配置SwitchHosts 安装配置Windo…...

JAVA练习47-合并两个有序数组
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、题目-合并两个有序数组 1.题目描述 2.思路与代码 2.1 思路 2.2 代码 总结 前言 提示:这里可以添加本文要记录的大概内容: 2月11日练习…...
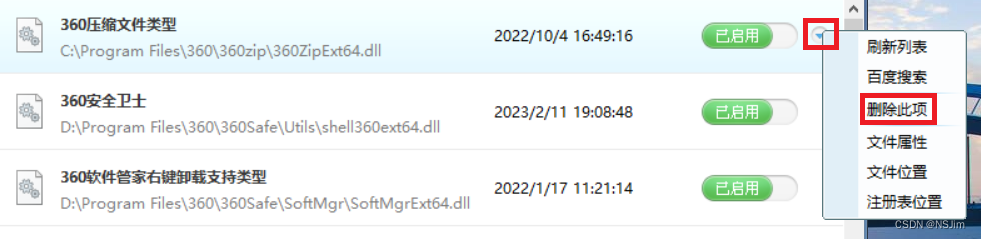
右键菜单管理 - Win系统
右键菜单管理 - Win系统前言软件工具管理右键菜单360右键管理右键管家前言 Windows系统可以借助软件工具对右键菜单进行管理,可对指定的右键菜单进行删除和恢复。下面以Win10系统为例介绍管理方法。 注意:使用本文提及的工具将某软件的右键菜单删除后&…...

BrowserClaw:容器化浏览器自动化平台部署与爬虫实战指南
1. 项目概述:一个浏览器自动化与数据抓取的瑞士军刀最近在折腾一些数据采集和自动化测试的活儿,发现一个挺有意思的开源项目,叫BrowserClaw。这名字起得挺形象,“浏览器之爪”,一听就知道是跟浏览器自动化、网页抓取相…...

哔哩下载姬完全指南:三步掌握B站视频批量下载技巧
哔哩下载姬完全指南:三步掌握B站视频批量下载技巧 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等࿰…...

从锂电池热失控到锡须短路:高可靠性系统安全工程实践
1. 从“工程恐怖故事”到系统安全文化的反思最近在整理资料时,翻到一篇十多年前的旧文,标题叫《工程恐怖:机毁人亡》。文章汇集了几位航空与国防领域工程师亲历的、令人脊背发凉的真实事故案例。这些故事没有出现在主流新闻的头条,…...

终极指南:在Windows上无需模拟器安装安卓应用的完整教程
终极指南:在Windows上无需模拟器安装安卓应用的完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为安卓模拟器的臃肿和卡顿烦恼吗?今…...

SIGTRAN协议:电信网络IP化的关键技术解析
1. SIGTRAN:下一代电信网络的信令传输基石2003年全球电信业寒冬中,一个技术决策正在悄然改变行业格局。当运营商们紧缩资本开支时,AT&T、Verizon等巨头却不约而同地加大了对IP网络的投入。这背后隐藏着一个关键技术转折——传统TDM网络向…...

如何用JPlag守护代码原创性:5分钟快速上手指南
如何用JPlag守护代码原创性:5分钟快速上手指南 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag 你是否曾担心…...

跨境直播里,为什么很多团队设备很强,画面却依旧不稳定?
做跨境直播的人,基本都会经历一个阶段:疯狂升级设备。更贵的相机更强的显卡更高规格的采集卡更多灯光但实际开播后:直播依旧掉帧OBS 占用异常推流延迟增加画面偶发模糊音视频不同步很多时候,问题并不是设备性能不够。而是…...

别再死记硬背了!用PyTorch和TensorFlow动手实现四种池化层,直观理解它的作用
用代码可视化理解深度学习中的池化层:PyTorch与TensorFlow实战指南 当你第一次听说"池化层"这个概念时,是否也感到困惑?为什么神经网络需要这样一个"缩小"图像的层?本文将通过PyTorch和TensorFlow两种框架的实…...

为什么92%的团队用错Gemini做Slides?——基于17家SaaS公司实测数据的生成效率断层分析
更多请点击: https://intelliparadigm.com 第一章:Gemini生成Slides的底层机制与能力边界 Gemini 生成幻灯片(Slides)并非简单地将文本转为 PPT 页面,而是依托多模态大模型对语义结构、视觉层级与演示逻辑的联合建模。…...

ML:Q 学习的基本原理与实现
在强化学习中,模型面对的不是一批固定样本,而是一个可以不断交互的环境。智能体(Agent)在某个状态下采取动作,环境给出奖励,并进入新的状态。智能体的目标不是只看当前一步是否得分,而是学习一种…...