基于torch的图像识别训练策略与常用模块
数据预处理部分:
- 数据增强:torchvision中transforms模块自带功能,比较实用
- 数据预处理:torchvision中transforms也帮我们实现好了,直接调用即可
- DataLoader模块直接读取batch数据
网络模块设置:
- 加载预训练模型,torchvision中有很多经典网络架构,调用起来十分方便,并且可以用人家训练好的权重参数来继续训练,也就是所谓的迁移学习
- 需要注意的是别人训练好的任务跟咱们的可不是完全一样,需要把最后的head层改一改,一般也就是最后的全连接层,改成咱们自己的任务
- 训练时可以全部重头训练,也可以只训练最后咱们任务的层,因为前几层都是做特征提取的,本质任务目标是一致的
网络模型保存与测试
- 模型保存的时候可以带有选择性,例如在验证集中如果当前效果好则保存
- 读取模型进行实际测试
data_transforms = {'train': transforms.Compose([transforms.Resize([96, 96]),transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选transforms.CenterCrop(64),#从中心开始裁剪transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=Btransforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差]),'valid': transforms.Compose([transforms.Resize([64, 64]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}
选择性的权重更新
def set_parameter_requires_grad(model, feature_extracting):if feature_extracting:for param in model.parameters():param.requires_grad = False
自定义修改模型输出层,以resnet18为例
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):model_ft = models.resnet18(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.fc.in_featuresmodel_ft.fc = nn.Linear(num_ftrs, 102)#类别数自己根据自己任务来input_size = 64#输入大小根据自己配置来return model_ft, input_size
训练权重 选择
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True)#GPU还是CPU计算
model_ft = model_ft.to(device)# 模型保存,名字自己起
filename='checkpoint.pth'# 是否训练所有层
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:params_to_update = []for name,param in model_ft.named_parameters():if param.requires_grad == True:params_to_update.append(param)print("\t",name)
else:for name,param in model_ft.named_parameters():if param.requires_grad == True:print("\t",name)
基本训练代码
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25,filename='best.pt'):#咱们要算时间的since = time.time()#也要记录最好的那一次best_acc = 0#模型也得放到你的CPU或者GPUmodel.to(device)#训练过程中打印一堆损失和指标val_acc_history = []train_acc_history = []train_losses = []valid_losses = []#学习率LRs = [optimizer.param_groups[0]['lr']]#最好的那次模型,后续会变的,先初始化best_model_wts = copy.deepcopy(model.state_dict())#一个个epoch来遍历for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 训练和验证for phase in ['train', 'valid']:if phase == 'train':model.train() # 训练else:model.eval() # 验证running_loss = 0.0running_corrects = 0# 把数据都取个遍for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)#放到你的CPU或GPUlabels = labels.to(device)# 清零optimizer.zero_grad()# 只有训练的时候计算和更新梯度outputs = model(inputs)loss = criterion(outputs, labels)_, preds = torch.max(outputs, 1)# 训练阶段更新权重if phase == 'train':loss.backward()optimizer.step()# 计算损失running_loss += loss.item() * inputs.size(0)#0表示batch那个维度running_corrects += torch.sum(preds == labels.data)#预测结果最大的和真实值是否一致epoch_loss = running_loss / len(dataloaders[phase].dataset)#算平均epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)time_elapsed = time.time() - since#一个epoch我浪费了多少时间print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))# 得到最好那次的模型if phase == 'valid' and epoch_acc > best_acc:best_acc = epoch_accbest_model_wts = copy.deepcopy(model.state_dict())state = {'state_dict': model.state_dict(),#字典里key就是各层的名字,值就是训练好的权重'best_acc': best_acc,'optimizer' : optimizer.state_dict(),}torch.save(state, filename)if phase == 'valid':val_acc_history.append(epoch_acc)valid_losses.append(epoch_loss)#scheduler.step(epoch_loss)#学习率衰减if phase == 'train':train_acc_history.append(epoch_acc)train_losses.append(epoch_loss)print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))LRs.append(optimizer.param_groups[0]['lr'])print()scheduler.step()#学习率衰减time_elapsed = time.time() - sinceprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('Best val Acc: {:4f}'.format(best_acc))# 训练完后用最好的一次当做模型最终的结果,等着一会测试model.load_state_dict(best_model_wts)return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs
调用训练
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=20)
def im_convert(tensor):""" 展示数据"""image = tensor.to("cpu").clone().detach()image = image.numpy().squeeze()image = image.transpose(1,2,0)image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))image = image.clip(0, 1)return image
相关文章:

基于torch的图像识别训练策略与常用模块
数据预处理部分: 数据增强:torchvision中transforms模块自带功能,比较实用数据预处理:torchvision中transforms也帮我们实现好了,直接调用即可DataLoader模块直接读取batch数据 网络模块设置: 加载预训练…...
微信小程序制作圆形进度条
微信小程序制作圆形进度条 1. 建立文件夹 选择一个目录建立一个文件夹,比如 mycircle 吧,另外把对应 page 的相关文件都建立出来,包括 js,json,wxml 和 wxcc。 2. 开启元件属性 在 mycircle.json中开启 component 属…...

大模型(Large Models):探索人工智能领域的新边界
🌟文章目录 🌟大模型的定义与特点🌟模型架构🌟大模型的训练策略🌟大模型的优化方法🌟大模型的应用案例 随着人工智能技术的飞速发展,大模型(Large Models)成为了引领深度…...
缓存相关知识总结
一、缓存的作用和分类 缓存可以减少数据库的访问压力,提升整个网站的数据访问速度,改善数据库的写入性能。缓存可以分为两种: 缓存在应用服务器上的本地缓存:访问速度快,但受应用服务器内存限制 缓存在专门的分布式缓存…...

Mapmost Alpha:开启三维城市场景创作新纪元
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

【大模型完全入门手册】——引言
博主作为一名大模型开发算法工程师,很希望能够将所学到的以及实践中感悟到的内容梳理成为书籍。作为先导,以专栏的形式先整理内容,后续进行不断更新完善。希望能够构建起从理论到实践的全流程体系。 助力更多的人了解大模型,接触大模型,一起感受AI的魅力! 在当今人工智能…...

在 Vue 3 中使用 Axios 发送 POST 请求
在 Vue 3 中使用 Axios 发送 POST 请求需要首先安装 Axios,然后在 Vue 组件或 Vuex 中使用它。以下是一个简单的安装和使用案例: 安装 Axios 你可以使用 npm 或 yarn 来安装 Axios: npm install axios # 或者 yarn add axios 使用 Axios…...

【LeetCode刷题记录】189. 轮转数组
189 轮转数组 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4,5] 向右轮转 3 步: …...
1.open3d处理点云数据的常见方法
1. 点云的读取、可视化、保存 在这里是读取的点云的pcd文件,代码如下: import open3d as o3dif __name__ __main__:#1.点云读取point o3d.io.read_point_cloud("E:\daima\huawei\img\change2.pcd")print(">",point)#2.点云可视…...

https和http有什么区别,为什么要用https
HTTPS(Hypertext Transfer Protocol Secure)和HTTP(Hypertext Transfer Protocol)之间的主要区别在于安全性。 安全性: HTTP是一种明文传输协议,数据在客户端和服务器之间以明文形式传输,容易…...

微前端框架主流方案剖析
微前端架构是为了在解决单体应用在一个相对长的时间跨度下,由于参与的人员、团队的增多、变迁,从一个普通应用演变成一个巨石应用(Frontend Monolith)后,随之而来的应用不可维护的问题。这类问题在企业级 Web 应用中尤其常见。 微前端框架内的各个应用都支持独立开发部署、不…...

安卓逆向之-Xposed RPC
引言: 逆向为最终的协议,或者爬虫的作用。 有几种方式,比如直接能力强,搞成协议。 现在好多加密解密都写入到so ,所以可以使用unidbg 一个可以模拟器so 执行的环境的开源项目。RPC 调用,又分为Frida, 还有今天讲的Xposed RPC。 原理: Xposed 可以hook ,然后可以直接…...

【排序 贪心】3107. 使数组中位数等于 K 的最少操作数
算法可以发掘本质,如: 一,若干师傅和徒弟互有好感,有好感的师徒可以结对学习。师傅和徒弟都只能参加一个对子。如何让对子最多。 二,有无限多1X2和2X1的骨牌,某个棋盘若干格子坏了,如何在没有坏…...
预览pdf文件和Excel文件
开发的时候要一个可上传下载预览的静态页面以下是数据html <el-table v-loading"loading" :data"fileList" selection-change"handleSelectionChange"><el-table-column type"selection" width"55" align"ce…...
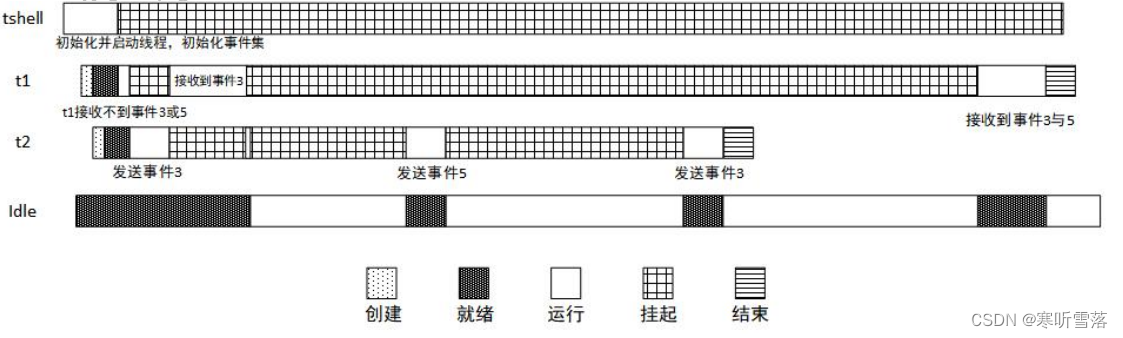
RT-thread线程间同步:事件集/消息队列/邮箱功能
一,事件集 1,事件集作用 事件集主要用于线程间的同步,与信号量不同,它的特点是可以实现一对多,多对多的同步。即一个线程与多个事件的关系可设置为:其中任意一个事件唤醒线程,或几个事件都到达后才唤醒线程进行后续的处理;同样事件也可以是多个线程同步多个事件。 2,…...

【机器学习】一文掌握机器学习十大分类算法(上)。
十大分类算法 1、引言2、分类算法总结2.1 逻辑回归2.1.1 核心原理2.1.2 算法公式2.1.3 代码实例 2.2 决策树2.2.1 核心原理2.2. 代码实例 2.3 随机森林2.3.1 核心原理2.3.2 代码实例 2.4 支持向量机2.4.1 核心原理2.4.2 算法公式2.4.3 代码实例 2.5 朴素贝叶斯2.5.1 核心原理2.…...

策略模式(知识点)——设计模式学习笔记
文章目录 0 概念1 使用场景2 优缺点2.1 优点2.2 缺点 3 实现方式4 和其他模式的区别5 具体例子实现5.1 实现代码 0 概念 定义:定义一个算法族,并分别封装起来。策略让算法的变化独立于它的客户(这样就可在不修改上下文代码或其他策略的情况下…...

Python学习从0开始——专栏汇总
Python学习从0开始——000参考 一、推荐二、基础三、项目一 一、推荐 Hello World in Python - 这个项目列出了用Python实现的各种"Hello World"程序。 Python Tricks - 这个项目包含了Python中的高级技巧和技术。 Think Python - 这是一本教授Python的在线书籍&…...

【iOS ARKit】Web 网页中嵌入 AR Quick Look
在支持 ARKit 的设备上,iOS 12 及以上版本系统中的 Safari浏览器支持 AR Quick Look, 因此可以通过浏览器直接使用3D/AR 的方式展示 Web 页面中的模型文件,目前 Web 版本的AR Quick Look 支持USDZ 格式文件。苹果公司有一个自建的3D模型示例库…...
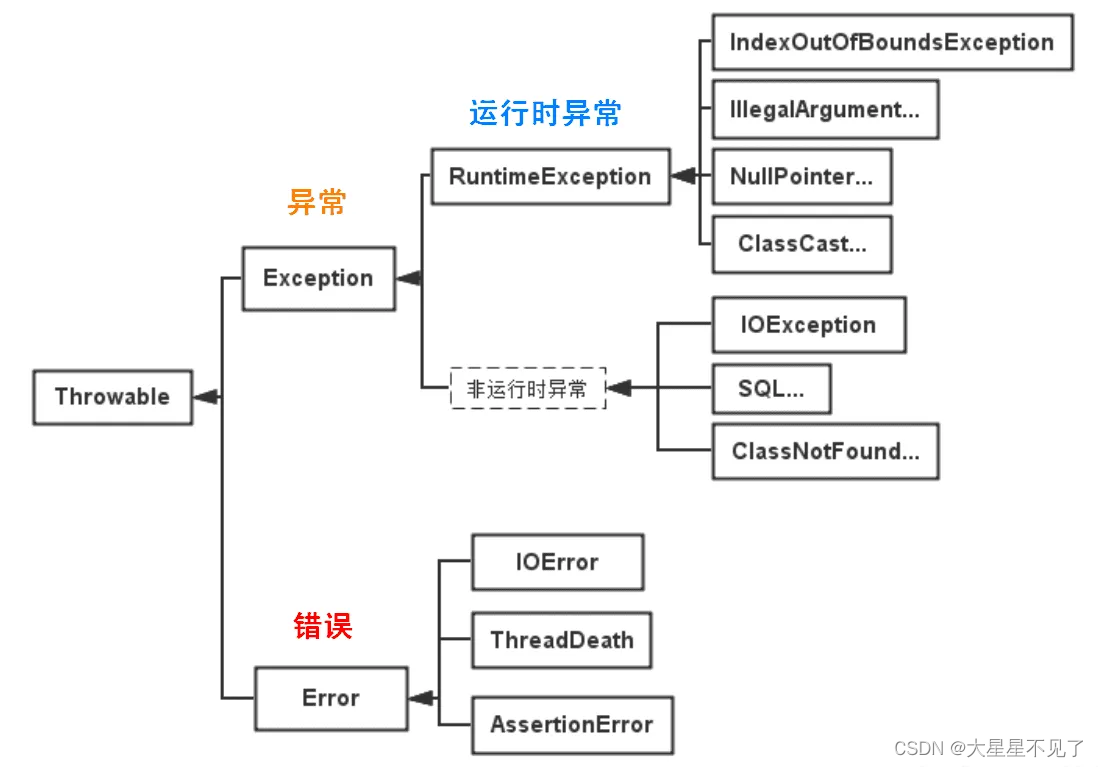
Java基础-知识点03(面试|学习)
Java基础-知识点03 String类String类的作用及特性String不可以改变的原因及好处String、StringBuilder、StringBuffer的区别String中的replace和replaceAll的区别字符串拼接使用还是使用StringbuilderString中的equal()与Object方法中equals()区别String a new String("a…...

Cursor Pro破解工具:5步实现永久免费使用的完整指南
Cursor Pro破解工具:5步实现永久免费使用的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial…...

SuperMap GIS集成天地图服务:从协议解析到多端应用实战
1. 天地图服务与SuperMap GIS集成基础 第一次接触天地图服务集成时,我被各种参数和协议搞得晕头转向。后来在智慧城市项目中反复实践才发现,理解这些基础概念就像学做菜要先认识调料一样重要。 天地图服务主要分为国家版和地方版两种。国家天地图采用449…...
)
NotebookLM播客化功能上线即爆火(2024Q2内部灰度测试TOP3功能首次公开)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM文档播客化功能详解 NotebookLM 的文档播客化(Doc-to-Podcast)功能将静态文本内容智能转化为自然流畅的语音叙述,支持多角色配音、语速调节与上下文感知停…...

Android开发终极指南:Sunflower项目中ViewModel数据共享的最佳实践
Android开发终极指南:Sunflower项目中ViewModel数据共享的最佳实践 【免费下载链接】sunflower A gardening app illustrating Android development best practices with migrating a View-based app to Jetpack Compose. 项目地址: https://gitcode.com/gh_mirro…...

ARM Fast Models MTI插件开发与性能优化实战
1. Fast Models中的Model Trace Interface架构解析在嵌入式系统仿真领域,ARM Fast Models提供的Model Trace Interface(MTI)是一套高效的仿真数据采集框架。作为一位长期从事嵌入式调试工具开发的工程师,我发现MTI的独特设计使其成…...

Gemini3.1Pro解决新媒体小编选题难痛点
做新媒体的小编,最怕的不是写,而是“今天写什么”。 选题总是来得很急,热点总是变化很快,账号又要求持续更新,结果就是:内容压力大、时间不够用、框架搭不出来。如果你每天都在追热点、找角度、写标题、搭结…...

Windows右键菜单为何变得臃肿?ContextMenuManager帮你重新掌控
Windows右键菜单为何变得臃肿?ContextMenuManager帮你重新掌控 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否曾为Windows右键菜单的混乱而烦…...

OpenClaw:重新定义 AI 智能体,从对话到执行的全能 “龙虾
在 AI 技术飞速迭代的今天,大语言模型已能流畅对话、生成内容,但多数仍停留在 “只说不做” 的层面。OpenClaw(外号 “龙虾”)的出现,打破了这一僵局 —— 它是一款由奥地利工程师 Peter Steinberger 主导开发…...

结构函数:电子封装热分析的关键技术解析
1. 结构函数:热分析领域的核心桥梁在电子封装设计与散热方案开发中,热特性分析一直是个令人头疼的问题。想象一下,你手里拿着一块正在发烫的芯片,却无法直接"看到"热量是如何在内部传递的——这就像医生无法用X光检查病…...

传统RAG把文档切碎,TreeSearch不接受,结果反而更快更准
无需 Embedding,无需向量库,无需切分——开源项目TreeSearch 用树结构保留文档灵魂,毫秒级检索万级文档。 你是不是也被 RAG 切碎过? 用过 RAG 的人都知道这个痛点: 文档被机械地切成固定大小的 chunk,喂…...