Kafka概述
目录
1、为什么需要消息队列(MQ)
2、使用消息队列的好处
3、消息队列的两种模式
4、Kafka 定义
5、Kafka 简介
6、Kafka 的特性
7、Kafka 系统架构
8、Partation 数据路由规则
9、分区的原因
1、为什么需要消息队列(MQ)
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。
我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka 等。
2、使用消息队列的好处
(1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
(2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
(3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
(4)灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
(5)异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
3、消息队列的两种模式
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到消息队列中,然后消息消费者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息消费者不可能消费到已经被消费的消息。消息队列支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
(2)发布/订阅模式(一对多,又叫观察者模式,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
发布/订阅模式是定义对象间一种一对多的依赖关系,使得每当一个对象(目标对象)的状态发生改变,则所有依赖于它的对象(观察者对象)都会得到通知并自动更新。
4、Kafka 定义
Kafka 是一个分布式的基于发布/订阅模式的消息队列(MQ,Message Queue),主要应用于大数据实时处理领域。
5、Kafka 简介
Kafka 是最初由 Linkedin 公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于 Zookeeper 协调的分布式消息中间件系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于 hadoop 的批处理系统、低延迟的实时系统、Spark/Flink 流式处理引擎,nginx 访问日志,消息服务等等,用 scala 语言编写,
Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
6、Kafka 的特性
●高吞吐量、低延迟
Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。每个 topic 可以分多个 Partition,Consumer Group 对 Partition 进行消费操作,提高负载均衡能力和消费能力。
●可扩展性
kafka 集群支持热扩展
●持久性、可靠性
消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
●容错性
允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败)
●高并发
支持数千个客户端同时读写
7、Kafka 系统架构
(1)Broker
一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
(2)Topic
可以理解为一个队列,生产者和消费者面向的都是一个 topic。
类似于数据库的表名或者 ES 的 index
物理上不同 topic 的消息分开存储
(3)Partition
为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分割为一个或多个 partition,每个 partition 是一个有序的队列。Kafka 只保证 partition 内的记录是有序的,而不保证 topic 中不同 partition 的顺序。
每个 topic 至少有一个 partition,当生产者产生数据的时候,会根据分配策略选择分区,然后将消息追加到指定的分区的队列末尾。
8、Partation 数据路由规则
- 指定了 patition,则直接使用;
- 未指定 patition 但指定 key(相当于消息中某个属性),通过对 key 的 value 进行 hash 取模,选出一个 patition;
- patition 和 key 都未指定,使用轮询选出一个 patition。
每条消息都会有一个自增的编号,用于标识消息的偏移量,标识顺序从 0 开始。
每个 partition 中的数据使用多个 segment 文件存储。
如果 topic 有多个 partition,消费数据时就不能保证数据的顺序。严格保证消息的消费顺序的场景下(例如商品秒杀、 抢红包),需要将 partition 数目设为 1。
●broker 存储 topic 的数据。如果某 topic 有 N 个 partition,集群有 N 个 broker,那么每个 broker 存储该 topic 的一个 partition。
●如果某 topic 有 N 个 partition,集群有 (N+M) 个 broker,那么其中有 N 个 broker 存储 topic 的一个 partition, 剩下的 M 个 broker 不存储该 topic 的 partition 数据。
●如果某 topic 有 N 个 partition,集群中 broker 数目少于 N 个,那么一个 broker 存储该 topic 的一个或多个 partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致 Kafka 集群数据不均衡。
9、分区的原因
●方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
●可以提高并发,因为可以以Partition为单位读写了。
(4)Replica
副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
(5)Leader
每个 partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责数据的读写的 partition。
(6)Follower
Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader 保持数据同步。Follower 只负责备份,不负责数据的读写。
如果 Leader 故障,则从 Follower 中选举出一个新的 Leader。
当 Follower 挂掉、卡住或者同步太慢,Leader 会把这个 Follower 从 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合) 列表中删除,重新创建一个 Follower。
(7)Producer
生产者即数据的发布者,该角色将消息发布到 Kafka 的 topic 中。
broker 接收到生产者发送的消息后,broker 将该消息追加到当前用于追加数据的 segment 文件中。
生产者发送的消息,存储到一个 partition 中,生产者也可以指定数据存储的 partition。
(8)Consumer
消费者可以从 broker 中读取数据。消费者可以消费多个 topic 中的数据。
(9)Consumer Group(CG)
消费者组,由多个 consumer 组成。
所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。可为每个消费者指定组名,若不指定组名则属于默认的组。
将多个消费者集中到一起去处理某一个 Topic 的数据,可以更快的提高数据的消费能力。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,防止数据被重复读取。
消费者组之间互不影响。
(10)offset 偏移量
可以唯一的标识一条消息。
偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息(即消费位置)。
消息被消费之后,并不被马上删除,这样多个业务就可以重复使用 Kafka 的消息。
某一个业务也可以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制。
消息最终还是会被删除的,默认生命周期为 1 周(7*24小时)。
(11)Zookeeper
Kafka 通过 Zookeeper 来存储集群的 meta 信息。
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中;从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为 __consumer_offsets。
相关文章:

Kafka概述
目录 1、为什么需要消息队列(MQ) 2、使用消息队列的好处 3、消息队列的两种模式 4、Kafka 定义 5、Kafka 简介 6、Kafka 的特性 7、Kafka 系统架构 8、Partation 数据路由规则 9、分区的原因 1、为什么需要消息队列(MQ) …...

OpenHarmony编译构建系统
这篇来聊聊OpenHarmony的编译构建,经过前面的实践,再来看编译构建。 编译构建概述 在官网中提到了,OpenHarmony编译子系统是以GN和Ninja构建为基座,对构建和配置粒度进行部件化抽象、对内建模块进行功能增强、对业务模块进行功能…...

Qt5 编译oracle数据库驱动
库文件 1、Qt源码目录:D:\Qt5\5.15.2\Src\qtbase\src\plugins\sqldrivers\oci 2、oracle客户端SDK: https://www.oracle.com/database/technologies/instant-client/winx64-64-downloads.html 下载各版本中的如下压缩包,一定要版本相同的 将两个压缩包…...
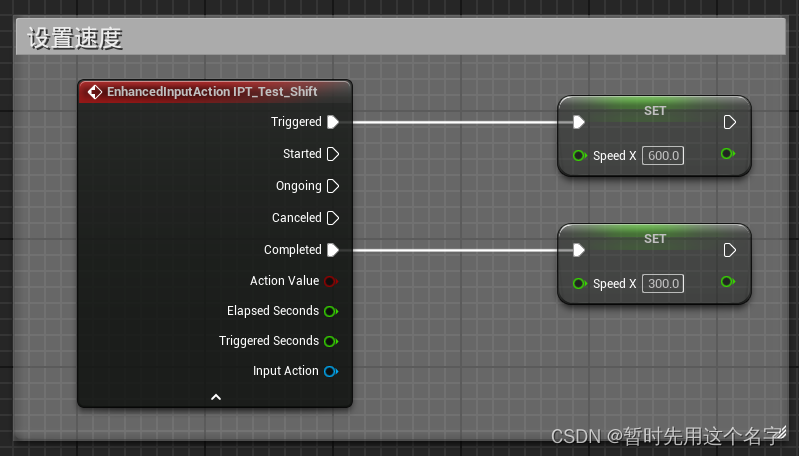
UE5学习日记——实现自定义输入及监听输入,组合出不同的按键输入~
UE5的自定义按键和UE4有所不同,在这里记录一下。 本文主要是记录如何设置UE5的自定义按键,重点是学会原理,实际开发时结合实际情况操作。 输入映射 1. 创建输入操作 输入操作并不是具体的按键映射,而是按键的激活方式࿰…...

为什么把script标签放在div下面?
放在底部可以优先加载页面的内容结构,提升页面渲染速度。只有等到HTML解析完成后,才会开始执行main.js,避免JS阻塞页面解析, 同时main.js里可能会操作DOM,如果放头部,可能会找不到节点而报错 <body><div id"root"><App></App>&l…...

Git 自定义命令
前言 在使用 hexo 搭建个人博客时,共两种部署的方法。分别为: 本地利用 hexo 的插件 hexo-deployer-git 来实现部署,缺点是需要多敲几个命令行且不方便对源码进行云端备份使用 Github Action 的 workflow 自动化部署,优势就是可…...

SpringBoot多数据源配置及使用
1.application.properties数据配置 首先现在配置文件中定义三个数据库相关信息 # 数据库1 targetLibraryMain.datasource.url jdbc:kingbase8://127.0.0.1:54321/DATA_ONE?useUnicodetrue&characterEncodingutf8&serverTimezoneGMT%2B8&allowMultiQueriestrue …...
12-项目部署_持续集成
项目部署_持续集成 1 今日内容介绍 1.1 什么是持续集成 持续集成( Continuous integration , 简称 CI )指的是,频繁地(一天多次)将代码集成到主干 持续集成的组成要素 一个自动构建过程, 从…...

文献阅读:LESS: Selecting Influential Data for Targeted Instruction Tuning
文献阅读:LESS: Selecting Influential Data for Targeted Instruction Tuning 1. 文章简介2. 方法介绍 1. Overview2. 原理说明 1. SGD上的定义2. Adam上的定义 3. 具体实现 1. Overview1. LoRA使用2. 数据选择3. LESS-T 3. 实验考察 & 结论 1. 实验设计2. 主…...

应对中年危机-高效学习
兴致勃勃的打开一本书,从第一行,第一个字开始,十分钟later……两眼皮一塌,哎,想睡觉了,真助眠。但其实我并不懒啊。 过去我是上诉这样,现在有了改善。如果你也是这样,希望看完了本文…...

Java二叉树(2)
一、二叉树的链式存储 二叉树的存储分为顺序存储和链式存储 (本文主要讲解链式存储) 二叉树的链式存储是通过一个一个节点引用起来的,常见的表示方式有二叉三叉 // 孩子表示法 class Node { int val; // 数据域 Node left; // 左孩子的引用…...

关于AG32 MCU的一些奇思妙想
1、AG32VF103的网口是100M还是10M? RE: 都是100M的。 2、用FPGA能不能再仿出一个网口?有些产品用到两个网口。 理论上可以,但是要考虑,一个是cpld实现难度,一个是需要的逻辑单元。因为mac逻辑多,内置的2KL…...

除了sql外还有那些查询语言
除了SQL(结构化查询语言)外,还有许多其他的查询语言,包括但不限于XQuery(对XML的查询语言)、MDX(多维查询语言,用于分析数据仓库)、DQL(数据查询语言…...
构建第一个ArkTS用的资源分类与访问
应用开发过程中,经常需要用到颜色、字体、间距、图片等资源,在不同的设备或配置中,这些资源的值可能不同。 应用资源:借助资源文件能力,开发者在应用中自定义资源,自行管理这些资源在不同的设备或配置中的表…...

JVM中都有哪些引用类型
● 强引用:JVM中默认引用关系就是强引用,即是对象被局部变量、静态变量等GC Root关联的对象引用,只要这层关系存在,普通对象就不会被回收 ● 软引用:软引用相对于强引用是一种比较弱的引用关系,如果一个对象…...

分布式锁-Redission快速入门
实战篇Redis 5、分布式锁-redission 5.2 分布式锁-Redission快速入门 引入依赖: <dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.13.6</version> </dependency>配置…...

IDEA 本地库引入了依赖但编译时找不到
在使用 IDEA 开发 Maven 项目的过程中,有时会遇到本地库引入了依赖,但编译时报找不到这个依赖,可以使用命令处理。 打开 Terminal。 执行清理命令。 mvn clean install -Dmaven.test.skiptrue执行更新命令。 mvn -U idea:idea...

hadoop最新详细版安装教程 2024 最新版
文章目录 hadoop安装教程 2024最新版提前准备工作用户配置安装 SSH Server免密登录设置编辑 SSH server 配置文件配置Java环境查看java 版本验证 环境变量设置安装Hadoop下载hadoop解压hadoop查看hadoop 版本hadoop 配置编辑编辑配置文件core-site.xml编辑配置文件hdfs-site.xm…...

Unity 中画线
前言: 在Unity项目中,调试和可视化是开发过程中不可或缺的部分。其中,绘制线条是一种常见的手段,可以用于在Scene场景和Game视图中进行调试和展示。本篇博客将为你介绍多种不同的绘制线条方法,帮助你轻松应对各种调试…...
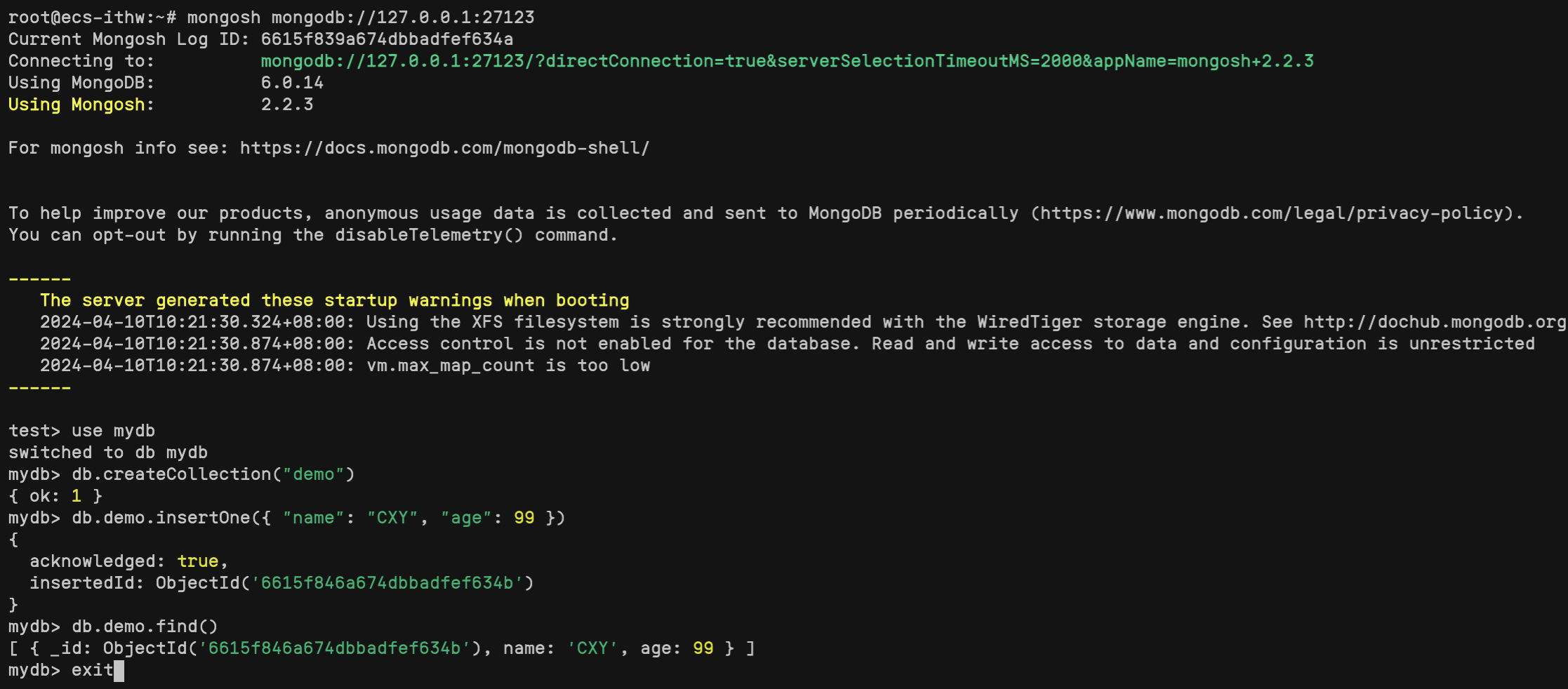
【快捷部署】017_MongoDB(6.0.14)
📣【快捷部署系列】017期信息 编号选型版本操作系统部署形式部署模式复检时间017MongoDB6.0.14Ubuntu 20.04apt单机2024-04-11 一、快捷部署 #!/bin/bash ################################################################################# # 作者:…...

1.8.2 掌握Scala类与对象 - 单例对象与伴生对象
本次实战通过三个案例深入解析了 Scala 中 object 的核心机制,展示了其如何替代 Java 的 static 关键字。首先,通过 MathUtils 定义了存放常量与工具方法的独立单例对象;其次,利用 Person 类与其同名对象演示了“伴生对象”特性&a…...

在Windows 10上搞定OpenPCDet:从KITTI数据集训练到自定义数据集的完整避坑指南
在Windows 10上搞定OpenPCDet:从KITTI数据集训练到自定义数据集的完整避坑指南 3D目标检测技术正在重塑自动驾驶、机器人感知等领域的发展格局。作为该领域的重要开源框架,OpenPCDet以其模块化设计和出色的性能表现吸引了大量研究者和开发者。然而&#…...

MediaCreationTool.bat:5大实用功能带你告别Windows安装烦恼
MediaCreationTool.bat:5大实用功能带你告别Windows安装烦恼 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...

告别机械生硬感:我熬夜实测了4款英文降AI工具,教你搞定结构级优化
最近不少学弟学妹跟我倒苦水,说查重率好不容易降下来了,结果偏偏卡在了英文降ai率上,眼看交稿DDL越来越近,心里特别着急。 我太懂这种感受了,我当时也因为英文降aigc率踩过不少坑,自己连夜纯手动改&#x…...
)
保姆级教程:用COMSOL 5.6搞定房间声学模态分析(附网格划分避坑指南)
保姆级教程:用COMSOL 5.6实现高精度房间声学模态分析 当你第一次尝试用COMSOL分析房间的声学特性时,是否曾被复杂的参数设置和网格划分搞得晕头转向?本文将带你一步步攻克声学模态分析中最关键的环节——特征频率求解与网格优化。不同于泛泛而…...
)
别再让FTP匿名登录成后门!手把手教你加固vsftpd服务(附CentOS 7实战配置)
企业级vsftpd安全加固实战指南:从匿名登录风险到全方位防护 FTP服务作为企业文件传输的经典解决方案,至今仍在许多组织的IT架构中扮演重要角色。然而,默认配置下的vsftpd服务往往隐藏着致命的安全隐患——匿名登录功能如同一扇未上锁的后门&a…...

开源协作平台Octopal:整合Git、文档与任务的项目管理利器
1. 项目概述:一个为开发者量身定制的开源协作平台如果你是一名开发者,或者是一个小型技术团队的负责人,那么你一定对这样的场景不陌生:手头有几个并行的项目,团队成员分散,沟通主要靠即时通讯工具ÿ…...

1k Star的p-retry,让异步操作失败自动重试
文章目录1k Star的p-retry,让异步操作失败自动重试核心功能适用场景注意事项1k Star的p-retry,让异步操作失败自动重试 sindresorhus开源的p-retry项目,目前在GitHub上获得1009个Star。这个库的核心功能是为异步操作添加重试机制,…...

5步实现Cursor Pro永久免费:终极破解工具完整指南
5步实现Cursor Pro永久免费:终极破解工具完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial r…...

Windows热键侦探:快速定位热键冲突的终极解决方案指南
Windows热键侦探:快速定位热键冲突的终极解决方案指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 在Window…...