【目标检测 DETR】通俗理解 End-to-End Object Detection with Transformers,值得一品。
文章目录
- DETR
- 1. 亮点工作
- 1.1 E to E
- 1.2 self-attention
- 1.3 引入位置嵌入向量
- 1.4 消除了候选框生成阶段
- 2. Set Prediction
- 2.1 N个对象
- 2.2 Hungarian algorithm
- 3. 实例剖析
- 4. 代码
- 4.1 配置文件
- 4.1.1 数据集的类别数
- 4.1.2 训练集和验证集的路径
- 4.1.3 图片的大小
- 4.1.4 训练时的批量大小、学习率等参数
- 4.2 模型部分
- 4.2.1 backbone
- 4.2.2 neck
- 4.2.3 head
- 4.3 train/engine.py
- 4.3.1 train.py
- 4.3.2 engine.py
- train_one_epoch()
- evaluate()
DETR
链接:https://github.com/facebookresearch/detr
论文地址:https://arxiv.org/pdf/2005.12872.pdf,
CNN生成的特征图将被送入Transformer,然后经过一系列的自注意力层和前馈神经网络层,最终得到一组对象的表示。每个对象的表示由一个类别分数和四个坐标值组成。这些类别分数和坐标值是预测得出的,它们表示对象在图像中的位置和类别信息。
解码器将这些对象解码为一组检测结果。在解码过程中,匹配函数将预测类别和预测坐标与这些对象进行匹配,从而找到与预测类别和预测坐标最匹配的对象,并将其作为最终的检测结果输出。
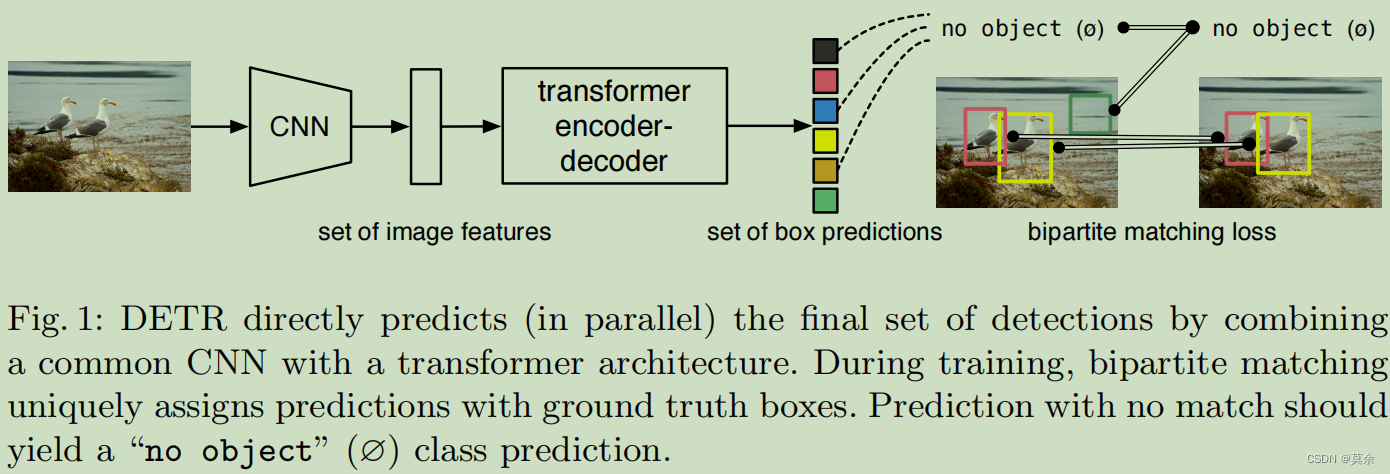
1. 亮点工作
1.1 E to E
DETR是第一个使用Transformer实现端到端目标检测的方法。这种方法不需要预定义的候选框或先验知识,并且可以同时执行分类和定位任务。
1.2 self-attention
DETR使用自注意力机制替代传统的卷积神经网络结构。自注意力机制能够有效地捕获全局上下文信息,从而在目标检测任务中获得更好的性能。
1.3 引入位置嵌入向量
DETR引入了一组位置嵌入向量来帮助解码器在生成目标检测结果时理解对象之间的相对位置关系
1.4 消除了候选框生成阶段
传统目标检测方法需要先生成一组候选框,然后对这些候选框进行分类和定位。DETR通过消除这个阶段,可以更好地利用计算资源和提高检测效率。
2. Set Prediction
实现了对 一组对象 的分类。
2.1 N个对象
在解码器中,每个位置都生成了一组对象,这些对象由类别分数和坐标表示。N就是指每个位置生成的对象的数量。一般情况下,N的值越大,DETR的检测性能就越好,但同时会带来更高的计算成本和内存占用。因此,需要在性能和效率之间进行权衡,并选择合适的N值。
在实际应用中,根据具体的任务和资源限制,N的值可能需要进行调整。
2.2 Hungarian algorithm
一种用于解决二分图匹配问题的经典算法,它的时间复杂度为O(n2),其中n为顶点数。
在DETR中,每个预测结果都需要与所有的实际目标进行匹配,因此可以将预测结果看作左边的顶点,实际目标看作右边的顶点,然后通过匈牙利算法计算出每个左边的顶点最匹配的右边的顶点是谁。这样可以快速地得到每个预测结果对应的实际目标,从而得到最终的检测结果。
解码器生成的一组对象 对比于 预测类别和预测坐标
在解码过程中,DETR模型会将编码器得到的一组对象表示解码为一组检测结果,其中每个对象的表示由一个类别分数和四个坐标值组成。这些类别分数和坐标值就是预测的类别和坐标。
3. 实例剖析
假设我们有一个图像,其中包含三个对象:一个狗、一个猫和一个椅子。
狗:坐标=(5, 15, 55, 65)
猫:坐标=(35, 45, 75, 85)
椅子:坐标=(95, 95, 145, 145)
设置N=3,DETR得到一组检测结果,如下所示:
对象1:类别分数=0.9,坐标=(10, 20, 50, 60)
对象2:类别分数=0.8,坐标=(30, 40, 70, 80)
对象3:类别分数=0.7,坐标=(100, 100, 150, 150)
首先,计算IoU,(145-100)×(145-100)=2025,它们之间的并集面积为(50×50)+(50×50)-2025 = 2975。
IoU得分:2025/2975 = 0.6
总得分:0.7*0.6 = 0.42 < 0.5
输出1:狗,类别分数=0.9,坐标=(10, 20, 50, 60)
输出2:猫,类别分数=0.8,坐标=(30, 40, 70, 80)
输出3:椅子,类别分数=0.0,坐标=(0, 0, 0, 0)
由于第三个输出与任何一个真实对象都没有匹配,因此其类别分数和坐标值都被设为0。
4. 代码
4.1 配置文件
d2/configs/detr_256_6_6_torchvision.yaml
d2/detr/config.py
4.1.1 数据集的类别数
需要根据自己的数据集修改模型的分类器的输出维度,使其等于数据集中的类别数。
cfg.MODEL.DETR.NUM_CLASSES = 80
4.1.2 训练集和验证集的路径
需要在训练和验证代码中设置自己数据集的路径。
DATASETS:TRAIN: ("coco_2017_train",)TEST: ("coco_2017_val",)
4.1.3 图片的大小
需要根据自己的数据集图片的大小修改模型的输入大小。
INPUT:MIN_SIZE_TRAIN: (480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800)CROP:ENABLED: TrueTYPE: "absolute_range"SIZE: (384, 600)FORMAT: "RGB"
4.1.4 训练时的批量大小、学习率等参数
需要根据自己的数据集和硬件环境进行调整。
SOLVER:IMS_PER_BATCH: 64BASE_LR: 0.0001
4.2 模型部分
4.2.1 backbone
DETR的backbone是Dilated ResNet,它是一种轻量级的卷积神经网络。
4.2.2 neck
DETR使用了Transformer的Encoder作为其neck部分的主要组成部分。
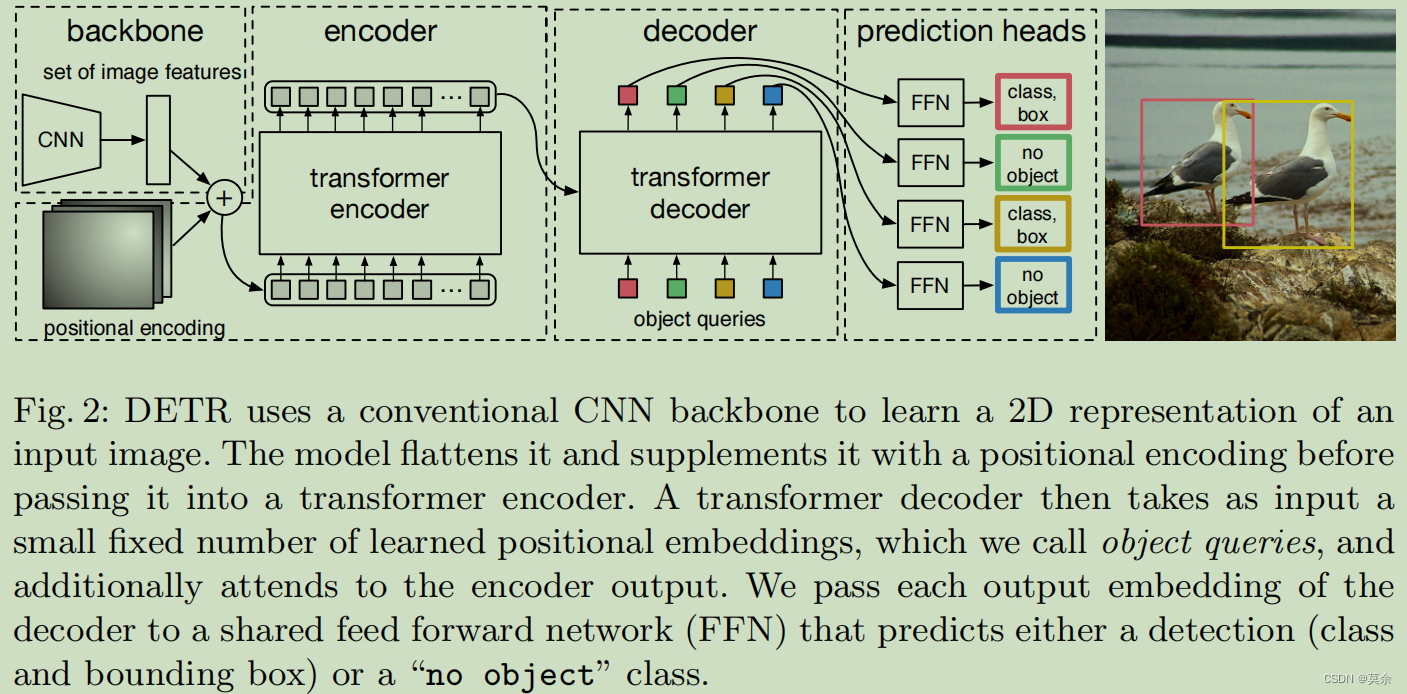
具体来说,DETR包含一个Encoder和一个Decoder,其中Encoder使用Transformer对输入的图像特征进行编码,将其转换为一组上下文向量,而Decoder使用Transformer对这些上下文向量和预测的对象查询向量进行解码,生成最终的目标预测结果。
4.2.3 head
主要包含Transformer Decoder、Query Embedding。
DETR中的全局嵌入(Query Embedding)是在Transformer Decoder的输出之上计算的。具体地,Transformer Decoder的输出通过多头自注意力(Multi-Head Self-Attention)进行加权求和,得到一个新的表示,即为每个对象提取了不同的上下文信息。
接着,这个表示会被传递到Feed-Forward Network(FFN)中进行进一步的处理,以产生更丰富的特征表示。
最后,Query Embedding是在FFN的输出上计算得到的,它是一个用于匹配对象嵌入向量。因此,可以说,在DETR中,FFN和Query Embedding是在Transformer Decoder之上进行的。
假设我们有一个包含4个对象的图像,并使用DETR模型对其进行目标检测。在DETR模型的输入端,我们有图像张量 XXX,其尺寸为 C×H×WC\times H\times WC×H×W,其中 CCC 是通道数,HHH 和 WWW 是高度和宽度。
首先,我们使用DETR的backbone网络(Diamante)将图像张量 XXX 转换为特征张量 FbackboneF_{\text{backbone}}Fbackbone。这个特征张量的大小是 Cbackbone×Hbackbone×WbackboneC_{\text{backbone}}\times H_{\text{backbone}}\times W_{\text{backbone}}Cbackbone×Hbackbone×Wbackbone。
接下来,我们将特征张量 FbackboneF_{\text{backbone}}Fbackbone 送入Transformer Decoder网络,得到Transformer Decoder的输出 FdecoderF_{\text{decoder}}Fdecoder。这个输出张量的大小也是 Cdecoder×Hdecoder×WdecoderC_{\text{decoder}}\times H_{\text{decoder}}\times W_{\text{decoder}}Cdecoder×Hdecoder×Wdecoder。
然后,我们对 FdecoderF_{\text{decoder}}Fdecoder 进行FFN,得到FFN的输出张量 FffnF_{\text{ffn}}Fffn。这个张量的大小和 FdecoderF_{\text{decoder}}Fdecoder 相同。
最后,我们使用Query Embedding将 FffnF_{\text{ffn}}Fffn 映射到特定的目标类别,得到每个对象的预测框坐标和类别。
4.3 train/engine.py
4.3.1 train.py
DETR的main.py文件是训练和测试DETR模型的主要脚本。在该脚本中,首先通过命令行参数解析器解析各种配置和超参数,然后通过build_model()函数构建DETR模型和优化器,通过build_lr_scheduler()函数构建学习率调度器,最后通过DefaultTrainer()类进行训练或测试。
4.3.2 engine.py
定义了一些训练和测试的辅助函数,包括计算loss、前向传播、后向传播、评估等。如构建匹配矩阵和计算损失。
train_one_epoch()
模型和损失切换到训练状态。
记录日志信息,主要是损失。
最后生成metric_logger的所有信息。
evaluate()
@torch.no_grad()装饰器,在评估过程中不进行梯度计算和参数更新。
设置模型和损失设置为评估状态。
使用for循环遍历数据集中的每个批次,并在MetricLogger对象上记录指标。
将输入数据和目标数据移到GPU上,然后使用模型进行前向传递。
如果数据集包含分割任务,则将分割结果与目标进行比较,以获得更准确的结果。
对所有结果进行聚合,以获得数据集上的总体评估指标。输出评估指标,包括平均指标和COCO指标。
相关文章:
【目标检测 DETR】通俗理解 End-to-End Object Detection with Transformers,值得一品。
文章目录DETR1. 亮点工作1.1 E to E1.2 self-attention1.3 引入位置嵌入向量1.4 消除了候选框生成阶段2. Set Prediction2.1 N个对象2.2 Hungarian algorithm3. 实例剖析4. 代码4.1 配置文件4.1.1 数据集的类别数4.1.2 训练集和验证集的路径4.1.3 图片的大小4.1.4 训练时的批量…...

项目ER图和资料
常用的数据类型 模型类 一对多 from app import db import datetimeclass BaseModel(db.Model):__abstract__ Truecreate_time db.Column(db.DateTime,defaultdatetime.datetime.now())update_time db.Column(db.DateTime,defaultdatetime.datetime.now())class Role(db.M…...
)
剑指 Offer 20. 表示数值的字符串(java+python)
请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。 数值(按顺序)可以分成以下几个部分: 若干空格 一个 小数 或者 整数 (可选)一个 ‘e’ 或 ‘E’ ,后面跟着一个 整数…...

程序员的逆向思维
前要: 为什么你读不懂面试官提问的真实意图,导致很难把问题回答到面试官心坎上? 为什么在面试结束时,你只知道问薪资待遇,不知道如何高质量反问? 作为一名程序员,思维和技能是我们职场生涯中最重要的两个方面。有时候…...
吐血整理学习方法,2年多功能测试成功进阶自动化测试,月薪23k+......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 测试进阶方向 测试进…...

mysql慢查询:pt-query-digest 分析
"某些SQL语句执行效率慢",这个问题总体上分为两类: 出现了慢查询语句某些查询语句没有使用索引 由于数据的写入量非常大,所以要想直接打开慢查询日志来查看到底哪些语句有问题几乎是不可能的,因为日志的刷新速度太快了…...

git的使用整合
git的下载和安装暂时不论述了,将git安装后会自动配置环境变量,所以环境变量也不需要配置。 一、初始化配置 打开git bash here(使用linux系统下运行的口令),弹出一个类似于cmd的窗口。 (1)配置属性 git config --glob…...

XCPC第九站———背包问题!
1.01背包问题 我们首先定义一个二维数组f,其中f[i][j]表示在前i个物品中取且总体积不超过j的取法中的最大价值。那么我们如何得到f[i][j]呢?我们运用递推的思想。由于第i个物品只有选和不选两种情况,当不选第i个物品时,f[i][j]f[i…...

【软考 系统架构设计师】论文范文④ 论基于构件的软件开发
>>回到总目录<< 文章目录 论基于构件的软件开发范文摘要正文论基于构件的软件开发 软件系统的复杂性不断增长、软件人员的频繁流动和软件行业的激烈竞争迫使软件企业提高软件质量、积累和固化知识财富,并尽可能地缩短软件产品的开发周期。 集软件复用、分布式对…...

spring-integration-redis中分布式锁RedisLockRegistry的使用
pom依赖:<!-- redis --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.springframework.integ…...
城市通电(prim算法)
acwing3728 蓝桥杯集训每日一题 平面上遍布着 n 座城市,编号 1∼n。 第 i 座城市的位置坐标为 (xi,yi) 不同城市的位置有可能重合。 现在要通过建立发电站和搭建电线的方式给每座城市都通电。 一个城市如果建有发电站,或者通过电线直接或间接的与建…...

【动态规划】
动态规划1引言题目509. 斐波那契数70. 爬楼梯746. 使用最小花费爬楼梯小结53. 最大子数组和结语引言 蓝桥杯快开始了啊,自从报名后还没认真学过算法有(>﹏<)′,临时抱一下佛脚,一起学学算法。 题目 509. 斐波那契数 斐波那契数 &am…...

秒懂算法 | DP概述和常见DP面试题
动态(DP)是一种算法技术,它将大问题分解为更简单的子问题,对整体问题的最优解决方案取决于子问题的最优解决方案。本篇内容介绍了DP的概念和基本操作;DP的设计、方程推导、记忆化编码、递推编码、滚动数组以及常见的DP面试题。 01、DP概述 1. DP问题的特征 下面以斐波那…...
)
【C++提高编程】C++全栈体系(二十五)
C提高编程 第四章 STL- 函数对象 一、函数对象 1. 函数对象概念 概念: 重载函数调用操作符的类,其对象常称为函数对象函数对象使用重载的()时,行为类似函数调用,也叫仿函数 本质: 函数对象(仿函数)是一个类&…...

【云原生】k8s核心技术—集群安全机制 Ingress Helm 持久化存储-20230222
文章目录一、k8s集群安全机制1. 概述2. RBAC——基于角色的访问控制二、Ingress三、Helm1. 引入2. 使用功能Helm可以解决哪些问题3. 介绍4. 3个重要概念5. helm 版本变化6. helm安装及配置仓库7. 使用helm快速部署应用8. 自己创建chart9. 实现yaml高效复用四、持久化存储1.nfs—…...
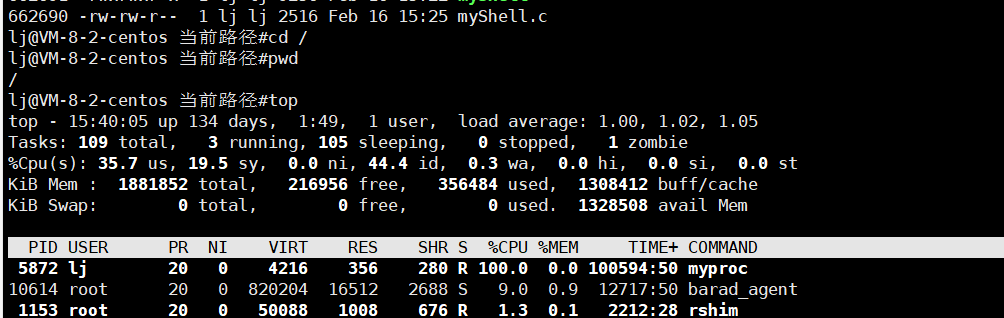
【Linux】实现简易的Shell命令行解释器
大家好我是沐曦希💕 文章目录一、前言二、准备工作1.输出提示符2.输入和获取命令3.shell运行原理4.内建命令5.替换三、整体代码一、前言 前面学到了进程创建,进程终止,进程等待,进程替换,那么通过这些来制作一个简易的…...

再获认可!腾讯安全NDR获Forrester权威推荐
近日,国际权威研究机构Forrester发布最新研究报告《The Network Analysis And Visibility Landscape, Q1 2023》(以下简称“NAV报告”),从网络分析和可视化(NAV)厂商规模、产品功能、市场占有率及重点案例等…...
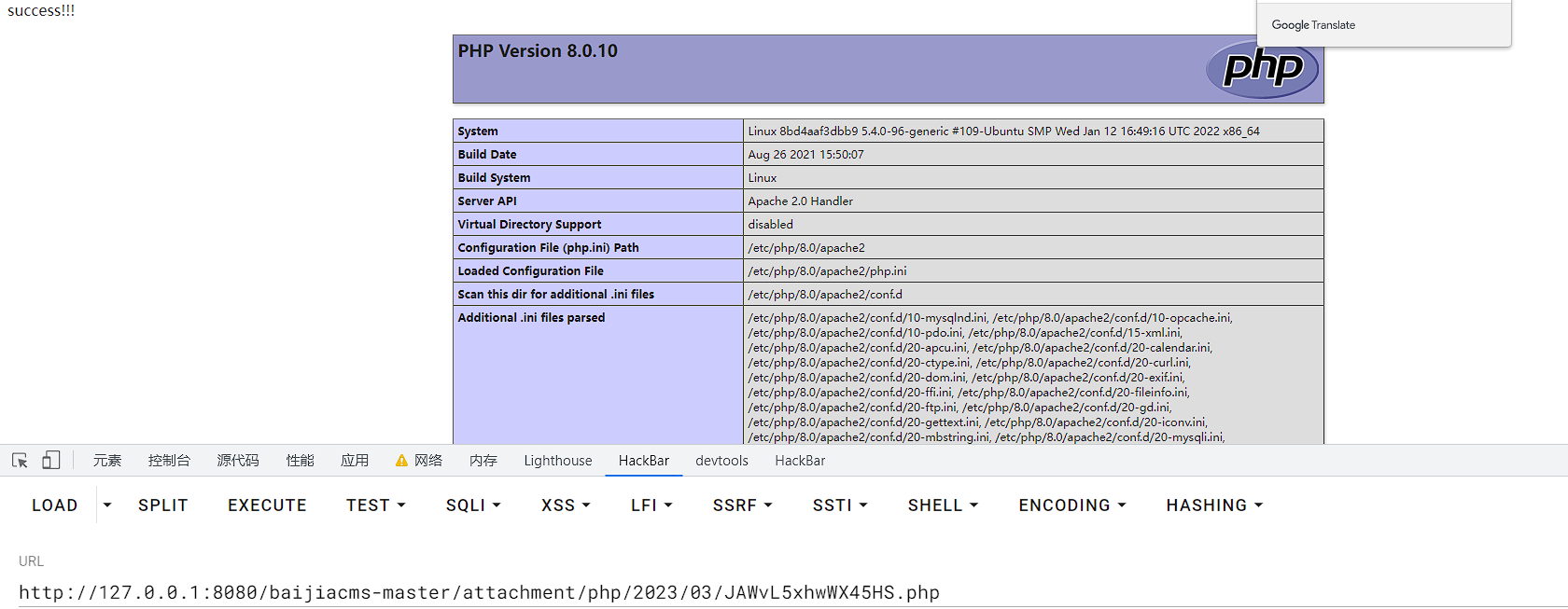
代码审计之旅之百家CMS
前言 之前审计的CMS大多是利用工具,即Seay昆仑镜联动扫描出漏洞点,而后进行审计。感觉自己的能力仍与零无异,因此本次审计CMS绝大多数使用手动探测,即通过搜索危险函数的方式进行漏洞寻找,以此来提升审计能力…...
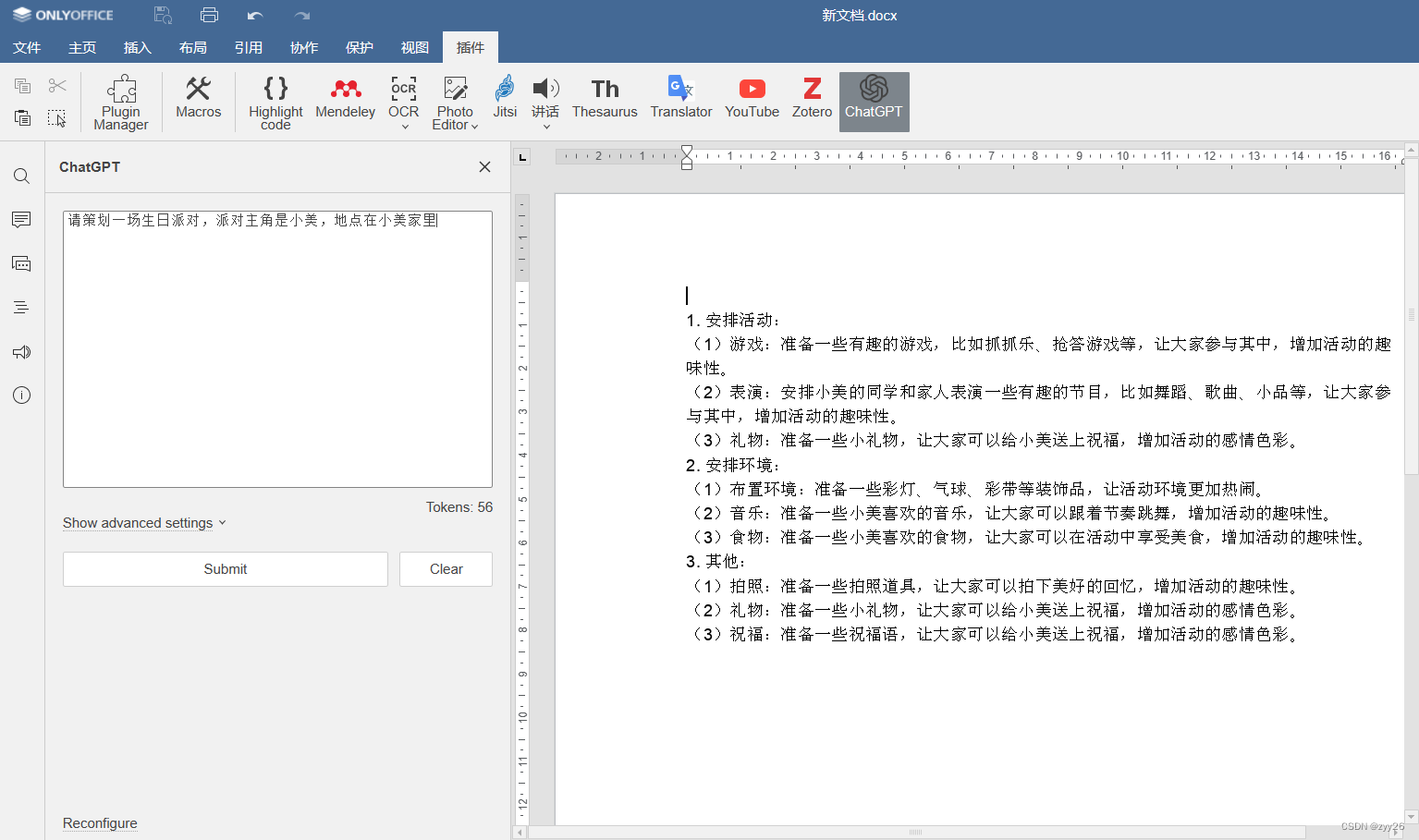
ONLYOFFICE中利用chatGPT帮助我们策划一场生日派对
近日,人工智能chatGPT聊天机器人爆火,在去年年底发布后,仅仅两个月就吸引了全球近一亿的用户,成为史上最快的应用消费程序,chatGPT拥有强大的学习和交互能力 可以被学生,教师,上班族各种职业运…...
)
Java面试题-线程(一)
在典型的 Java 面试中, 面试官会从线程的基本概念问起, 如:为什么你需要使用线程,如何创建线程,用什么方式创建线程比较好(比如:继承 thread 类还是调用 Runnable 接口),…...

18.地下室的服务器
六月第一个周末的深夜,暴雨如注。陈远坐在书桌前,屏幕上是花花绿绿的监控图表,代表着他那台二手服务器资源使用率的曲线,正像垂死病人的心电图一样剧烈地上下跳动。CPU占用率长时间维持在90%以上,内存也逼近红线。这已…...

ctf show web 入门43
打开靶场代码逻辑如下: if(!preg_match(“/\ |/|cat/i”, $c)) 它过滤了三个关键内容: \ (空格):你不能直接在命令中使用空格(例如 ls -l 或 cat flag 都会失败)。 / (正斜杠):你不能使用路径符号…...

NotebookLM与Google Drive整合性能瓶颈实测报告:单次索引超10万页PDF时,延迟突增217%的根源与绕行方案
更多请点击: https://intelliparadigm.com 第一章:NotebookLM与Google Drive整合性能瓶颈实测报告:单次索引超10万页PDF时,延迟突增217%的根源与绕行方案 延迟突增的核心成因 实测表明,当 NotebookLM 通过 Google Dr…...
首次公开)
为什么顶尖SRE团队已停用Ctrl+F搜索Stack Overflow?Perplexity智能查询协议(P-SOQ v2.1)首次公开
更多请点击: https://intelliparadigm.com 第一章:为什么顶尖SRE团队已停用CtrlF搜索Stack Overflow?Perplexity智能查询协议(P-SOQ v2.1)首次公开 搜索范式的根本性迁移 传统 SRE 工作流中,工程师依赖关…...
)
手把手教你用C语言实现三相锁相环(附完整源码与仿真波形分析)
手把手教你用C语言实现三相锁相环(附完整源码与仿真波形分析) 在电力电子和电机控制领域,锁相环(PLL)技术是实现电网同步、逆变器控制的核心组件。传统教材往往停留在理论推导,而实际工程中,如何…...

LocalChat:零门槛本地部署开源大语言模型,实现隐私安全的离线AI对话
1. 项目概述与核心价值如果你和我一样,对ChatGPT这类大语言模型的能力感到兴奋,但又对数据隐私、服务依赖和网络延迟心存顾虑,那么LocalChat这个项目可能就是为你量身打造的。简单来说,LocalChat是一个让你能在自己电脑上…...

应对2026检测算法:论文AI率居高不下怎么救?5款降AI工具深度实测
最近不少学弟学妹在后台跟我倒苦水,说查重率好不容易低了,结果AI率越改越高。眼看临近DDL,生怕又因为这个耽误答辩。 作为已经摸爬滚打出来的老学长,今天我就根据我总结出来的经验,从检测系统的底层逻辑开始讲起&…...

轻量级GraphRAG框架nano-graphrag:模块化设计与实践指南
1. 项目概述:一个为开发者而生的轻量级GraphRAG实现 如果你正在寻找一个能够快速上手、代码清晰、易于二次开发的GraphRAG(图增强检索生成)框架,那么 nano-graphrag 很可能就是你需要的那个工具。GraphRAG这个概念,简…...

[已解决]Vscode插件Keil Assistant连接Keil后出现的头文件路径无法寻找问题
问题详情 按照网络上的教程按照并且配置好vscode的Keil Assistant插件后,成功打开了Keil工程并且编译成功。但是头文件无法跳转,以及出现红色波浪线报错。 解决方法 在.vscode\c_cpp_properties.json中添加以下两行路径: "includePath&q…...

VCF 9.1 新特性:安装器与 Fleet Depot 支持 HTTP 无认证离线软件源
VMware Cloud Foundation(VCF)9.0 推出了统一软件仓库(Software Depot),支持连接博通在线源或企业内部离线源。但在 9.0 中,离线源默认必须使用 HTTPS 基础认证,即使关闭 HTTPS 也依然需要认证,对纯内网环境很不友好。在 VCF 9.1…...