【hive】单节点搭建hadoop和hive
一、背景
需要使用hive远程debug,尝试使用无hadoop部署hive方式一直失败,无果,还是使用有hadoop方式。最终查看linux内存占用6GB,还在后台运行docker的mysql(bitnami/mysql:8.0),基本满意。
版本选择:
(1)hive2 hadoop2 和hive3和hadoop3需要搭配使用,不能像chd的hive2和hadoop3搭配使用,容易出现问题。
本文选择版本,都是官网推荐的版本:
hadoop-3.3.6.tar.gz
apache-hive-3.1.3-bin.tar.gz
二、创建用户和组
# hadoop缩写hdp
useradd hdp
groupadd hadoop
后边启动hadoop不能用root用户。
三、配置集群(单节点)互信
su hdp && cd .ssh
ssh-keygen
# 一路回车
cat id_rsa.pub >> authorized_keys
vi /etc/hosts
# localhost 行后追加 hdp # 配置后测试下
ssh hdp
ssh localhost
四、hadoop搭建
hadoop官网
下载安装包
本文hadoop安装路径:/opt/hadoop-3.3.6
# 解压
tar -xvf hadoop-3.3.6.tar.gz
# 改名字
mv ... hadoop-3.3.6# 加个软连接
cd hadoop-3.3.6
ln -s etc/hadoop conf
修改hadoop-env.sh
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
export HADOOP_CLIENT_OPTS="-Xmx2048m $HADOOP_CLIENT_OPTS"
修改core-site.xml,添加:
<configuration><property><name>fs.defaultFS</name><value>hdfs://hdp:9000</value><description>hdfs内部通讯访问地址</description></property><property><name>hadoop.tmp.dir</name><!--临时文件目录需要自己建立--><value>/var/hadoop/tmp</value></property><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value>
</property>
</configuration>
修改hdfs-site.xml,添加:
<configuration><property><name>dfs.namenode.name.dir</name><value>/var/hadoop/data/namenode</value><description> namenode 存放name table(fsimage)本地目录需要修改,如果没有需要自己创建文件目录)</description></property><property><name>dfs.datanode.data.dir</name><value>/var/hadoop/data/datanode</value><description>datanode存放block本地目录(需要修改,如果没有需要自己创建文件目录)</description></property><property><!--由于只有一台机器,hdfs的副本数就指定为1--><name>dfs.replication</name><value>1</value></property>
</configuration>
修改yarn-site.xml
<configuration>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value>
</property>
<property><name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value>
</property>
<property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value>
</property>
<property><name>mapred.child.java.opts</name><value>-Xmx1024m</value>
</property>
<property><name>yarn.application.classpath</name><value>/opt/hadoop-3.3.6/conf:/opt/hadoop-3.3.6/share/hadoop/common/lib/*:/opt/hadoop-3.3.6/share/hadoop/common/*:/opt/hadoop-3.3.6/share/hadoop/hdfs:/opt/hadoop-3.3.6/share/hadoop/hdfs/lib/*:/opt/hadoop-3.3.6/share/hadoop/hdfs/*:/opt/hadoop-3.3.6/share/hadoop/mapreduce/*:/opt/hadoop-3.3.6/share/hadoop/yarn:/opt/hadoop-3.3.6/share/hadoop/yarn/lib/*:/opt/hadoop-3.3.6/share/hadoop/yarn/*</value>
</property>
</configuration>
yarn.application.classpath是使用hadoop classpath生成的,一定要有此配置。
修改mapred-site.xml,添加:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
touch init-env.sh
添加如下内容,本文使用的hadoop安装路径的是:/opt/hadoop-3.3.6:
#!/bin/bash
# 移除老的环境变量
# 如果本机已经安装过hadoop一定要注意,将旧hadoop环境变量移除,可以使用printenv 或者env 查看已经有的环境变量
unset HADOOP_HDFS_HOME
unset HADOOP_YARN_HOME
unset HADOOP_CLASSPATH
unset HADOOP_MAPRED_HOME
unset HADOOP_HOME
unset HADOOP_CONF_DIR
# 添加新的环境变量
export HADOOP_HOME=/opt/hadoop-3.3.6
export HADOOP_CONF_DIR=$HADOOP_HOME/conf
export HADOOP_LOG_DIR=/var/hadoop/log
export PATH=$HADOOP_HOME/bin:$PATH
加载环境变量
source init-env.sh
# 测试下:
env
echo $HADOOP_HOME
echo $HADOOP_CONF_DIR
初始化namenode
# 删除hdfs-site.xml中配置的namenode和datanode本地路径
rm -rf /var/hadoop/data/namenode/* /var/hadoop/data/datanode/*
hdfs namenode -format
启动和停止hadoop
chown -R hdp:hadoop $HADOOP_HOME
# 必须使用非root账户登录
su hdp
$HADOOP_HOME/sbin/start-all.sh
# 使用jps查看下java进程情况:
NameNode
ResourceManager
NodeManager
SecondaryNameNode
DataNode# 停止
$HADOOP_HOME/sbin/stop-all.sh# 可以在console查看日志的脚本,即单独启动yarn或者hdfs:
start-dfs.sh
start-yarn.sh
hdfs web
yarn web
使用命令行确认下hdfs和yarn是否可用:
hdfs dfs -mkdir /tmp
hdfs dfs -ls /
yarn application -list
六、hive搭建
本文hive安装位置:/opt/hive-3.1.3/
hive官网
tar -xvf apache-hive-3.1.3-bin.tar.gz
mv apache-hive-3.1.3-bin hive-3.1.3
cd hive-3.1.3 && mkdir logs
cp hive-env.sh.template hive-env.sh
touch hive-site.xml
# 不手动添加的话,hive不打印日志!!!
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
修改hive-env.sh
HADOOP_HOME=/opt/hadoop-3.3.6
修改hive-site.xml,添加:
本文hive使用mysql作为metastore,提前在mysql中创建好数据库hive3_local
<configuration>
<!-- 数据库连接JDBC的URL地址,& 是urlencode后的表达-->
<property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://mysql-ip:3306/hive3_local?createDatabaseIfNotExist=true&useSSL=false</value>
</property><!-- 数据库连接driver,即MySQL驱动-->
<property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value>
</property><!-- MySQL数据库用户名-->
<property><name>javax.jdo.option.ConnectionUserName</name><value>root</value>
</property><!-- MySQL数据库密码-->
<property><name>javax.jdo.option.ConnectionPassword</name><value>密码</value>
</property>
<property><!--hive表在hdfs的位置--><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value>
</property>
<property><name>hive.security.authorization.enabled</name><value>false</value>
</property>
<property><name>hive.security.authorization.createtable.owner.grants</name><value>ALL</value>
</property>
<property><name>hive.server2.enable.doAs</name><value>false</value>
</property>
</configuration>
touch init-env.sh
添加如下内容
#!/bin/bash
export HIVE_HOME=/opt/hive-3.1.3
export HIVE_CONF_DIR=$HIVE_HOME/conf
export PATH=$HIVE_HOME/bin:$PATH
加载hive环境变量。
source init-env.sh
初始化metastore
把数据库jdbc驱动复制到lib目录下,本文是mysql-connector-j-8.0.31.jar
# 进入hive的bin目录
./schematool -dbType mysql -initSchema
配置hive启动脚本
touch start-all.sh
添加如下内容:
#!/bin/bash
nohup $HIVE_HOME/bin/hive --service metastore &
nohup $HIVE_HOME/bin/hive --service hiveserver2 &
启动hive,注:一定要确保hadoop已经成功启动,才能启动hive,否则连接hive beeline会卡死但是不报错!!!
chown -R hdp:hadoop $HIVE_HOME
su hdp
source /opt/hadoop-3.3.6/conf/init-env.sh
source /opt/hive-3.1.3/conf/init-env.sh
sh start-all.sh# 查看进程,可以看到两个RunJar。
jps
153216 RunJar
152044 RunJar
配置hive停止脚本
touch stop-all.sh
添加如下内容:
jps | grep RunJar | awk '{print $1}' | xargs kill -9
判断linux端口使用已经监听:
# hive的metastore端口号9083
netstat -ntulp |grep 9083
# 出现端口信息,说明metastore已经启动成功了。
(Not all processes could be identified, non-owned process infowill not be shown, you would have to be root to see it all.)
tcp6 0 0 :::9083 :::* LISTEN 152044/java
# 使用如上获取的ip获取具体进程启动命令:
ps -ef | grep 152044
hdp 152044 36213 0 4月09 pts/1 00:01:01 /usr/hdp/3.0.1.0-187/jdk1.8/bin/java -Dproc_jar -Xmx2048m -Dproc_metastore -Dlog4j2.formatMsgNoLookups=true -Dlog4j.configurationFile=hive-log4j2.properties -Djava.util.logging.config.file=/opt/hive-3.1.3/conf/parquet-logging.properties -Dyarn.log.dir=/opt/hadoop-3.3.6/logs -Dyarn.log.file=hadoop.log -Dyarn.home.dir=/opt/hadoop-3.3.6 -Dyarn.root.logger=INFO,console -Djava.library.path=/opt/hadoop-3.3.6/lib/native -Dhadoop.log.dir=/opt/hadoop-3.3.6/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/opt/hadoop-3.3.6 -Dhadoop.id.str=hdp -Dhadoop.root.logger=INFO,console -Dhadoop.policy.file=hadoop-policy.xml -Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.util.RunJar /opt/hive-3.1.3/lib/hive-metastore-3.1.3.jar org.apache.hadoop.hive.metastore.HiveMetaStore# hive的hiveserver2端口号10000
netstat -ntulp | grep 10000
# 出现端口信息,说明hiveserver已经启动成功了。
(Not all processes could be identified, non-owned process infowill not be shown, you would have to be root to see it all.)
tcp6 0 0 :::10000 :::* LISTEN 152045/java
# 使用如上获取的ip获取具体进程启动命令:
ps -ef | grep 152045
hdp 152045 36213 0 4月09 pts/1 00:04:30 /usr/hdp/3.0.1.0-187/jdk1.8/bin/java -Dproc_jar -Xmx2048m -Dproc_hiveserver2 -Dlog4j2.formatMsgNoLookups=true -Dlog4j.configurationFile=hive-log4j2.properties -Djava.util.logging.config.file=/opt/hive-3.1.3/conf/parquet-logging.properties -Djline.terminal=jline.UnsupportedTerminal -Dyarn.log.dir=/opt/hadoop-3.3.6/logs -Dyarn.log.file=hadoop.log -Dyarn.home.dir=/opt/hadoop-3.3.6 -Dyarn.root.logger=INFO,console -Djava.library.path=/opt/hadoop-3.3.6/lib/native -Dhadoop.log.dir=/opt/hadoop-3.3.6/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/opt/hadoop-3.3.6 -Dhadoop.id.str=hdp -Dhadoop.root.logger=INFO,console -Dhadoop.policy.file=hadoop-policy.xml -Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.util.RunJar /opt/hive-3.1.3/lib/hive-service-3.1.3.jar org.apache.hive.service.server.HiveServer2
beeline链接hive
beeline
# 输入`!verbose`,设置打印日志verbose
!verbose
# 使用hive用户登录,不输入密码(空密码),直接回车。
!connect jdbc:hive2://localhost:10000 hive
七、参考文档
hadoop和hive单机部署
Hive2 新版连接工具 beeline 详解
找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
DBeaver连接Hive错误总结
User: hadoop is not allowed to impersonate anonymous
return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
hive设置权限
hive 入门 修改hive日志路径
Hadoop常见端口号及配置文件
相关文章:

【hive】单节点搭建hadoop和hive
一、背景 需要使用hive远程debug,尝试使用无hadoop部署hive方式一直失败,无果,还是使用有hadoop方式。最终查看linux内存占用6GB,还在后台运行docker的mysql(bitnami/mysql:8.0),基本满意。 版本选择: &a…...
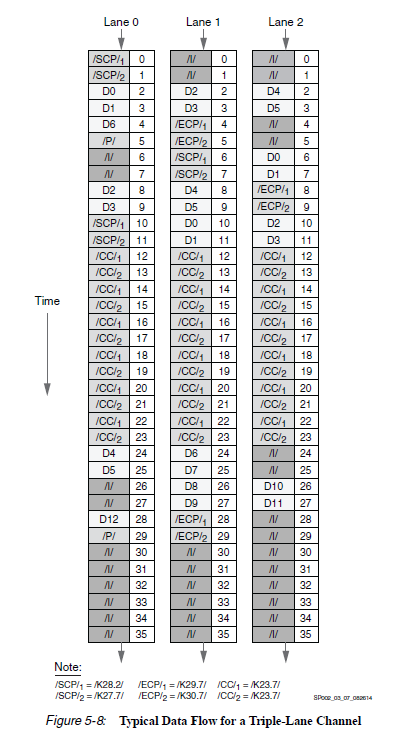
Aurora 协议学习理解与应用——Aurora 8B10B协议学习
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 Aurora 8B10B协议学习之一,理解协议 概述8B10B数据发送和接收Symbol-Pairs传输调度用户PDU传输过程用户PDU接收过程 流控自然流量控制操作自然流量控制延迟自然流…...

Vue基础使用之V-Model绑定单选、复选、动态渲染选项的值
这里要说明一下,在v-model 绑定的值是id还是value是和<option>中的v-bind保持一致的,如第四个,如果是 <option :value"op[1]" 那v-model绑定的就是数组第二项的值2,4,6 如果是 <option :va…...
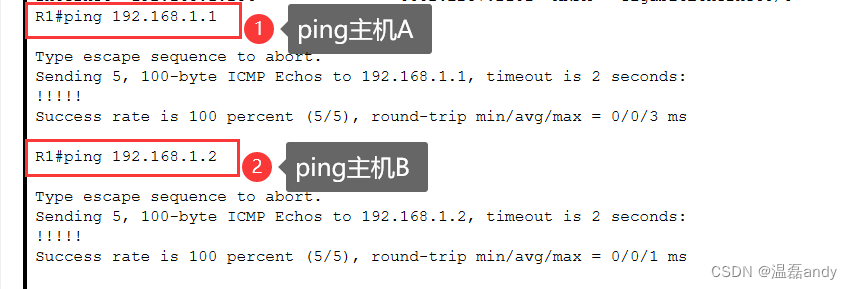
分析ARP解析过程
1、实验环境 主机A和主机B连接到交换机,并与一台路由器互连,如图7.17所示,路由器充当网关。 图7.17 实验案例一示意图 2、需求描述 查看 ARP 相关信息,熟悉在PC 和 Cisco 设备上的常用命令,设置主机A和主机B为同一个网段网关设置为路由接…...

为硬刚小米SU7,华为智界S7整出了「梅开二度」操作
如今国产中大型新能源轿车市场,在小米 SU7 加入后,可算彻底活了过来。 过去几年,咱们自主新能源品牌在 20-30 万元级轿车上发力明显不足,老牌车厂比亚迪汉几乎以一己之力扛起销量担当。 随着新能源汽车消费升级、竞争加剧&#x…...

408数据结构,怎么练习算法大题?
其实考研的数据结构算法题是有得分技巧的 得分要点 会写结构定义(没有就自己写上)写清楚解题的算法思想描述清楚算法实现最后写出时间和空间复杂度 以上这四步是完成一道算法题的基本步骤,也是其中得分的主要地方就是后面两步。但是前面两…...

imgcat 工具
如果经常在远程服务器或嵌入式设备中操作图片,要查看图片效果,就要先把图片dump到本地,比较麻烦。可以使用这个工具,直接在终端上显示。类似于这种效果。 imgcat 是一个终端工具,使用 iTerm2 内置的特性,允…...

Anaconda换清华源
1. 查看conda配置文件 sudo vim ~/.condarc2. 删除~/.condarc文件内容 使用vim中的dd命令 3. 打开并复制清华源的地址粘贴到~/.condarc文件中 https://mirrors4.tuna.tsinghua.edu.cn/help/anaconda/ channels:- defaults show_channel_urls: true default_channels:- https…...

react使用npm i @reduxjs/toolkit react-redux
npm i reduxjs/toolkit react-redux 创建一个 store文件夹,里面创建index.js文件和子模块文件夹 index,js文件写入以下代码 import {configureStore} from reduxjs/toolkit // 导入子模块 import counterReducer from ./modules/one import two from ./modules/tw…...

Nessus【部署 03】Docker部署漏洞扫描工具Nessus详细过程分享(下载+安装+注册+激活)文末福利
Docker部署漏洞扫描工具Nessus 1.安装2.配置2.1 添加用户2.2 获取Challenge code2.3 获取插件和许可证2.4 注册 3.使用4.进阶 整体流程: 1.安装 # 1.查询镜像 docker search nessus# 2.拉取镜像 docker pull tenableofficial/nessus# 3.启动镜像【挂载目录用于放置…...

2023年看雪安全技术峰会(公开)PPT合集(11份)
2023年看雪安全技术峰会(公开)PPT合集,共11份,供大家学习参阅。 1、MaginotDNS攻击:绕过DNS 缓存防御的马奇诺防线 2、从形式逻辑计算到神经计算:针对LLM角色扮演攻击的威胁分析以及防御实践 3、TheDog、0…...
Docker仅需3步搭建免费私有化的AI搜索引擎-FreeAskInternet
简介 FreeAskInternet 是一个完全免费、私有且本地运行的搜索引擎,并使用 LLM 生成答案,无需 GPU。用户可以提出问题,系统会进行多引擎搜索,并将搜索结果合并到ChatGPT3.5 LLM中,并根据搜索结果生成答案。 什么是 Fr…...

线程安全的单例模式
使用 synchronized 修饰 getInstance 方法 确保了只有一个线程可以同时访问 getInstance 方法。这意味着在任何时候只有一个线程可以执行 getInstance() 方法,从而避免了多个线程同时创建多个实例的情况,因此是线程安全的。 public class ClientUtil {…...
OpenHarmony实战开发-Grid和List内拖拽交换子组件位置。
介绍 本示例分别通过onItemDrop()和onDrop()回调,实现子组件在Grid和List中的子组件位置交换。 效果图预览 使用说明: 拖拽Grid中子组件,到目标Grid子组件位置,进行两者位置互换。拖拽List中子组件,到目标List子组件…...

设计模式:时序图
设计模式:时序图 设计模式:时序图时序图元素(Sequence Diagram Elements)角色(Actor)对象(Object)生命线(Lifeline)控制焦点(Focus of Control&am…...

前端性能监控(面试常见)
1. 用户体验优化 2. Web Vitals提取了几个核心网络指标 哇一头死 FCL 三大指标 FID被 INP干点 Largest Contentful Paint (LCP):最大内容绘制 衡量加载性能。 为了提供良好的用户体验,LCP 必须在网页首次开始加载后的 2.5 秒内发生。Interaction to Ne…...

react17 + antd4 如何实现Card组件与左侧内容对齐并撑满高度
在使用antd进行页面布局时,经常会遇到需要将内容区域进行左右分栏,并在右侧区域内放置一个或多个Card组件的情况。然而,有时我们会发现右侧的Card组件并不能与左侧的栏目对齐,尤其是当左侧栏目高度动态变化时。本文将介绍如何使用…...

Rust入门-Hello World
1、安装 在 Linux 或 macOS 上安装 rustup 打开终端并输入下面命令: $ curl --proto https --tlsv1.2 https://sh.rustup.rs -sSf | sh如果安装成功,将出现下面这行: Rust is installed now. Great!2、更新 $ rustup self uninstall3、卸…...

堆放砖块-第12届蓝桥杯选拔赛Python真题精选
[导读]:超平老师的Scratch蓝桥杯真题解读系列在推出之后,受到了广大老师和家长的好评,非常感谢各位的认可和厚爱。作为回馈,超平老师计划推出《Python蓝桥杯真题解析100讲》,这是解读系列的第47讲。 堆放砖块…...
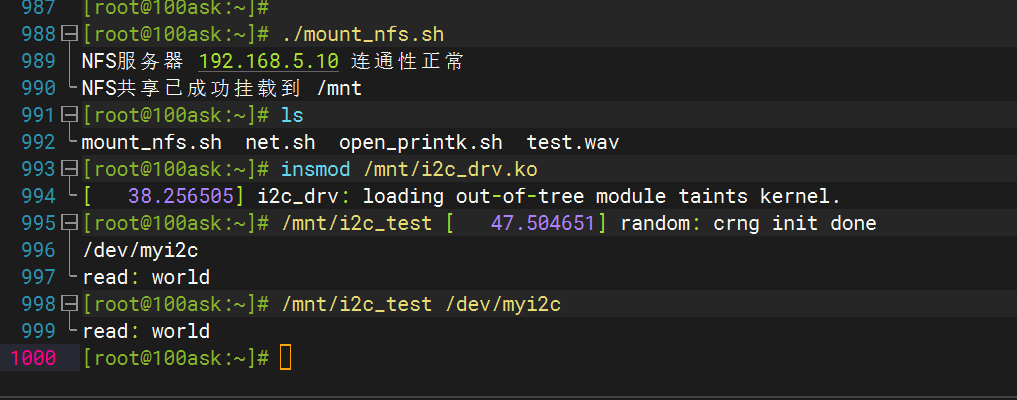
019——IIC模块驱动开发(基于EEPROM【AT24C02】和I.MX6uLL)
目录 一、 IIC基础知识 二、Linux中的IIC(韦东山老师的学习笔记) 1. I2C驱动程序的层次 2. I2C总线-设备-驱动模型 2.1 i2c_driver 2.2 i2c_client 三、 AT24C02 介绍 四、 AT24C02驱动开发 实验 驱动程序 应用程序 一、 IIC基础知识 总线类…...

Standard计划突然限速?揭秘MJ v6.1后台配额算法变更,3步绕过队列延迟,今日生效
更多请点击: https://intelliparadigm.com 第一章:Standard计划限速事件的全貌还原 2024年Q2,Standard计划在多个云原生生产环境中突发性触发API速率限制(Rate Limiting),导致下游服务批量超时与重试风暴。…...

联邦学习与RAG融合:构建隐私保护的分布式智能问答系统
1. 项目概述:当联邦学习遇上检索增强生成最近在折腾一个挺有意思的开源项目,叫fed-rag,来自 Vector Institute。光看名字,老司机们大概就能猜出个七七八八了:这玩意儿是把联邦学习和检索增强生成给揉到一块儿去了。我花…...

Cayley图数据库终极调优指南:针对不同工作负载的存储引擎配置
Cayley图数据库终极调优指南:针对不同工作负载的存储引擎配置 【免费下载链接】cayley An open-source graph database 项目地址: https://gitcode.com/gh_mirrors/ca/cayley Cayley是一款开源图数据库,支持多种存储引擎,针对不同工作…...

开源机器人夹爪OpenClaw Max:从硬件组装到ROS集成的完整开发指南
1. 项目概述与核心价值 最近在机器人抓取领域,一个名为 minakovai/openclaw-max-guide 的项目在社区里引起了不小的讨论。乍一看这个标题,它像是一个关于“OpenClaw Max”的开源指南或教程。但如果你深入挖掘,会发现它远不止于此。这实际上…...

为什么92%的AI团队误用DeepSeek Serverless?——基于37家客户架构审计报告的5大认知断层与重构路径
更多请点击: https://intelliparadigm.com 第一章:为什么92%的AI团队误用DeepSeek Serverless? DeepSeek Serverless 本为轻量推理与函数即服务(FaaS)场景设计,但大量团队将其当作通用模型托管平台使用&am…...

基于多平台行为数据构建AI Agent深度用户画像:Know Your Owner项目解析
1. 项目概述:从“你是谁”到“我懂你”的智能跨越在AI助手日益普及的今天,我们面临着一个核心矛盾:用户期望获得高度个性化的服务,而AI助手在初次接触时却对用户一无所知。传统的解决方案,比如让用户填写冗长的问卷&am…...

企业内网应用如何安全合规地集成外部大模型API服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内网应用如何安全合规地集成外部大模型API服务 在构建内部AI工具时,企业开发团队面临一个核心挑战:如何…...

Articuler.Ai 技术深度解析:海量人脉匹配、数字足迹解析与高转化冷触达引擎
摘要Articuler.Ai 是一款面向商业人脉精准匹配与高效触达的 AI 引擎,核心定位为 “商业关系搜索引擎 智能触达工作台”,彻底重构传统关键词搜索失效背景下的 B2B 人脉连接逻辑。本文从9.8 亿级公开档案数据底座、语义匹配引擎架构、Playbook 深度解析技…...

MAX31856在工业温控项目中的实战应用:从选型、电路设计到故障诊断避坑指南
MAX31856工业温控系统设计全流程:从芯片选型到抗干扰实战 工业温度监测系统的可靠性直接关系到生产安全与产品质量。在钢铁冶炼、化工反应等场景中,一个温度传感器的失效可能导致数百万损失。MAX31856作为工业级热电偶数字转换器,其45V过压保…...

量子噪声对机器学习模型的影响与缓解策略
1. 量子噪声与机器学习模型的复杂关系量子计算领域近年来最令人兴奋的进展之一,就是量子机器学习(QML)的兴起。作为一名长期跟踪量子计算发展的从业者,我亲眼见证了量子算法在机器学习任务中展现出的惊人潜力。然而,在…...