(BERT蒸馏)TinyBERT: Distilling BERT for Natural Language Understanding
文章链接:https://arxiv.org/abs/1909.10351
背景
在自然语言处理(NLP)领域,预训练语言模型(如BERT)通过大规模的数据训练,已在多种NLP任务中取得了卓越的性能。尽管BERT模型在语言理解和生成任务中表现出色,其庞大的模型尺寸和高昂的计算成本限制了其在资源受限环境下的应用。
挑战
BERT等大型模型的计算成本高,不适合在移动设备或低资源环境中部署。因此,急需一种能将大型模型的能力转移到更小、更高效模型上的技术,这种技术被称为“知识蒸馏”。知识蒸馏的挑战在于如何在减小模型尺寸的同时,尽可能保留原模型的性能。
方法
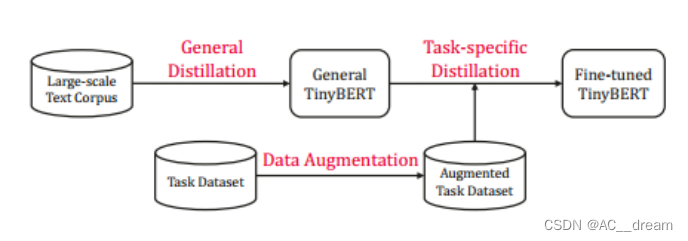
TinyBERT学习框架
TinyBERT通过以下步骤实现BERT的知识蒸馏:
1. Transformer蒸馏方法:针对Transformer基础的模型设计了一种新的知识蒸馏方法,旨在将大型BERT模型中编码的丰富知识有效转移到小型TinyBERT模型。
2. 两阶段学习框架:TinyBERT采用了一种新颖的两阶段学习框架,包括预训练阶段和具体任务学习阶段的蒸馏,确保TinyBERT模型不仅能捕获通用领域知识,还能捕获特定任务知识。
3. 数据增强和多样性:为了进一步提高TinyBERT在特定任务上的性能,引入数据增强技术,通过扩展训练样本来增加模型的泛化能力。
损失计算
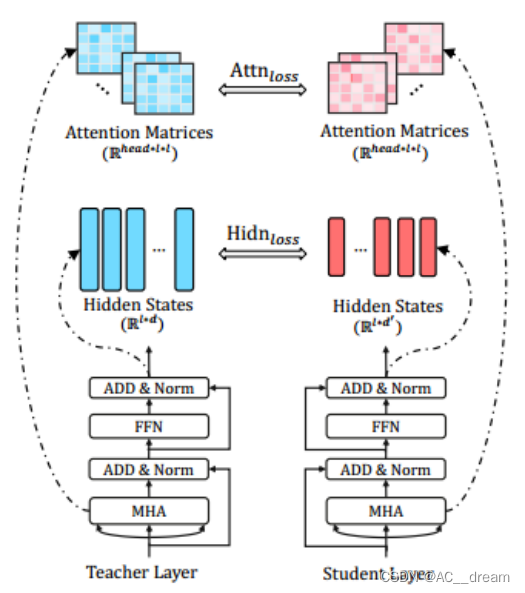
Transformer层中注意力矩阵和隐藏状态蒸馏示意图

其中Zs和Zt分别是学生和教师模型的逻辑输出,CE 代表交叉熵损失函数,t是一个软化温度参数,用于调整软标签的分布,使得学生模型可以从教师模型的预测中学习更多信息。
通过上述损失函数的组合,TinyBERT不仅学习了教师模型的最终输出,还学习了教师模型处理信息的内在方式,包括注意力机制和隐藏层的表示。这些损失函数的综合使用,确保了学生模型TinyBERT在显著减少模型大小和计算成本的同时,能够尽可能地保留教师模型BERT的性能。
和
矩阵说明:
目的:
尺寸转换:由于TinyBERT模型的隐藏层尺寸通常小于BERT模型的隐藏层尺寸,因此需要和
矩阵将学生模型的输出转换为与教师模型相同维度的空间,以便进行有效的比较。
信息转换:这个矩阵不仅仅是简单地改变尺寸,它还能帮助学生模型学习如何将其较小的、压缩的表示形式映射到一个更丰富的表示空间,这是教师模型所使用的。
获取方式(以为例):
通过训练过程中的反向传播得到的,具体步骤如下:
初始化:矩阵在训练前随机初始化
损失函数:通过定义一个损失函数来量化学生模型转换后的输出与教师模型输出之间的差异。常用的损失函数包括均方误差(MSE)。
反向传播更新:在训练过程中,使用梯度下降方法(或其他优化算法)根据损失函数的结果来调整矩阵的值,以最小化学生和教师模型输出之间的差异。
训练过程:在Transformer层蒸馏的上下文中,每当输入一个训练样本,学生模型(TinyBERT)和教师模型(BERT)都会计算各自的隐藏状态。然后,使用矩阵将TinyBERT的隐藏状态转换到与BERT相同的维度,接着计算和反向传播这两者之间的差异,不断更新
矩阵以及其他相关的模型参数。通过这样的过程,
矩阵最终能够有效地帮助TinyBERT模仿BERT的行为和输出,尽管TinyBERT的模型尺寸更小,参数更少。这种方法是蒸馏技术中减小模型尺寸同时保持性能的关键步骤之一。
数据增强

输入x:一个单词序列(句子或文本片段)
参数:
:阈值概率,决定是否对单词进行替换的门槛。
:每个样本生成的增强样本数量。
K:候选集大小,即为每个单词生成的可能替换词的数量。
输出D’:增强后的数据集
算法过程:
1.初始化计数器n为0,并创建空的增强数据集列表D’。
2.当n小于需要生成的样本数量时,执行循环
3.将输入序列x赋值给,以开始对其进行增强。
4.遍历序列x中的每个单词x[i]:
如果x[i]是一个单片词(即不可分割的词),就执行两步操作,第一步是将[i]替换为特殊标记[MASK],第二步是使用BERT模型找出当
[i]是[MASK]时,K个最有可能的单词,然后把这个集合赋值给集合C
反之如果x[i]不是一个单片词,使用GloVe模型找出与x[i]最相似的K个单词,并赋值给集合C
5.从[0,1]中均匀采样一个概率值p,如果p≤,就在集合C中随机选择一个单词替换
[i]
6.替换操作完成后,继续遍历中的下一个单词
7.当所有单词都遍历完,将增强后的序列添加到D中
8.增加计数器n 的值
9.如果n<,则重复上述操作
10.当所有增强样本都生成后就返回增强后的数据集D
总的来说,这个算法通过在原始文本序列中替换一些单词,来生成新的文本样本。这些替换基于BERT或GloVe模型的输出,取决于待替换的词是否是单片词。通过这种方式,它创造出与原始样本在语义上保持一致,但在表述上有所变化的新样本。这有助于学生模型在训练过程中获得更广泛的语言表达能力,以及更好的泛化性能。
结果
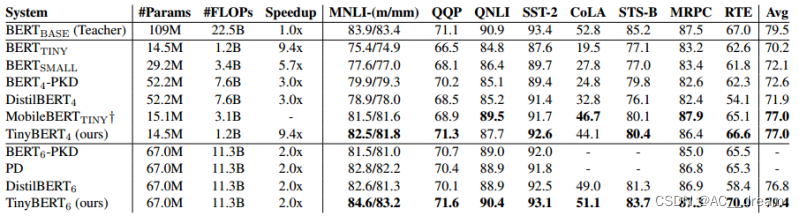
TinyBERT在GLUE基准测试中表现出色,与教师模型BERT相比,TinyBERT在模型大小和推理速度上均有显著改进,同时保持了相近的性能。例如,TinyBERT在模型大小上缩小了7.5倍,在推理速度上提高了9.4倍,而在性能上能达到教师模型的96.8%。
总结
TinyBERT的成功证明了通过精心设计的知识蒸馏方法和两阶段学习框架,可以有效地将大型模型的能力转移到更小、更高效的模型上,从而在保持性能的同时显著减少计算资源的需求。这为在资源受限的环境下部署高性能NLP模型提供了可能。
相关文章:
(BERT蒸馏)TinyBERT: Distilling BERT for Natural Language Understanding
文章链接:https://arxiv.org/abs/1909.10351 背景 在自然语言处理(NLP)领域,预训练语言模型(如BERT)通过大规模的数据训练,已在多种NLP任务中取得了卓越的性能。尽管BERT模型在语言理解和生成…...

【数据结构|C语言版】双向链表
前言1. 初步认识双向链表1.1 定义1.2 结构1.3 储存 2. 双向链表的方法(接口函数)2.1 动态申请空间2.2 创建哨兵位2.3 查找指定数据2.4 指定位置插入2.5 指定位置删除2.6 头部插入2.7 头部删除2.8 尾部插入2.9 尾部删除2.10 计算链表大小2.11 销毁链表 3.…...
适用于 Windows 的 10 个顶级 PDF 编辑器 [免费和付费]
曾经打开PDF文件,感觉自己被困在数字迷宫中吗?无法编辑的文本、无法调整大小的图像以及签署感觉像是一件苦差事的文档?好吧,不用再担心了!本指南解开了在 Windows 上掌握 PDF 的秘密,其中包含 10 款适用于 …...

久菜盒子|留学|推荐信|活动类|改性伽马-三氧化二铝催化剂上甲醇制备二甲醚的研究项目
尊敬的录取委员会: 我是华东理工大学化工学院的刘殿华。非常荣幸在此推荐我校优秀学生 XXX 进入贵校学习。 我认识 XXX是在一年前,当时,我正计划做一个有关改性伽马-三氧化二铝催化剂上甲醇制备二甲醚的研究项目。XXX 找到了我,表示希望能够加…...
Java项目如何使用EasyExcel插件对Excel数据进行导入导出
文章目录 一、EasyExcel的示例导入依赖创建实体类数据导入和导出 二、EasyExcel的作用三、EasyExcel的注解 EasyExcel是一个阿里巴巴开源的excel处理框架,它以使用简单、节省内存著称。在解析Excel时,EasyExcel没有将文件数据一次性全部加载到内存中&…...

python标准库常用方法集合
前段时间准备第十五届蓝桥杯python a组,因为赛中不允许导包,因此对py中的标准库进行了笔记和总结,即不导包即可使用的常用方法。包含了内置函数、math、random、datetime、os、sys、re、queue、collections、itertools库的常用方法࿰…...
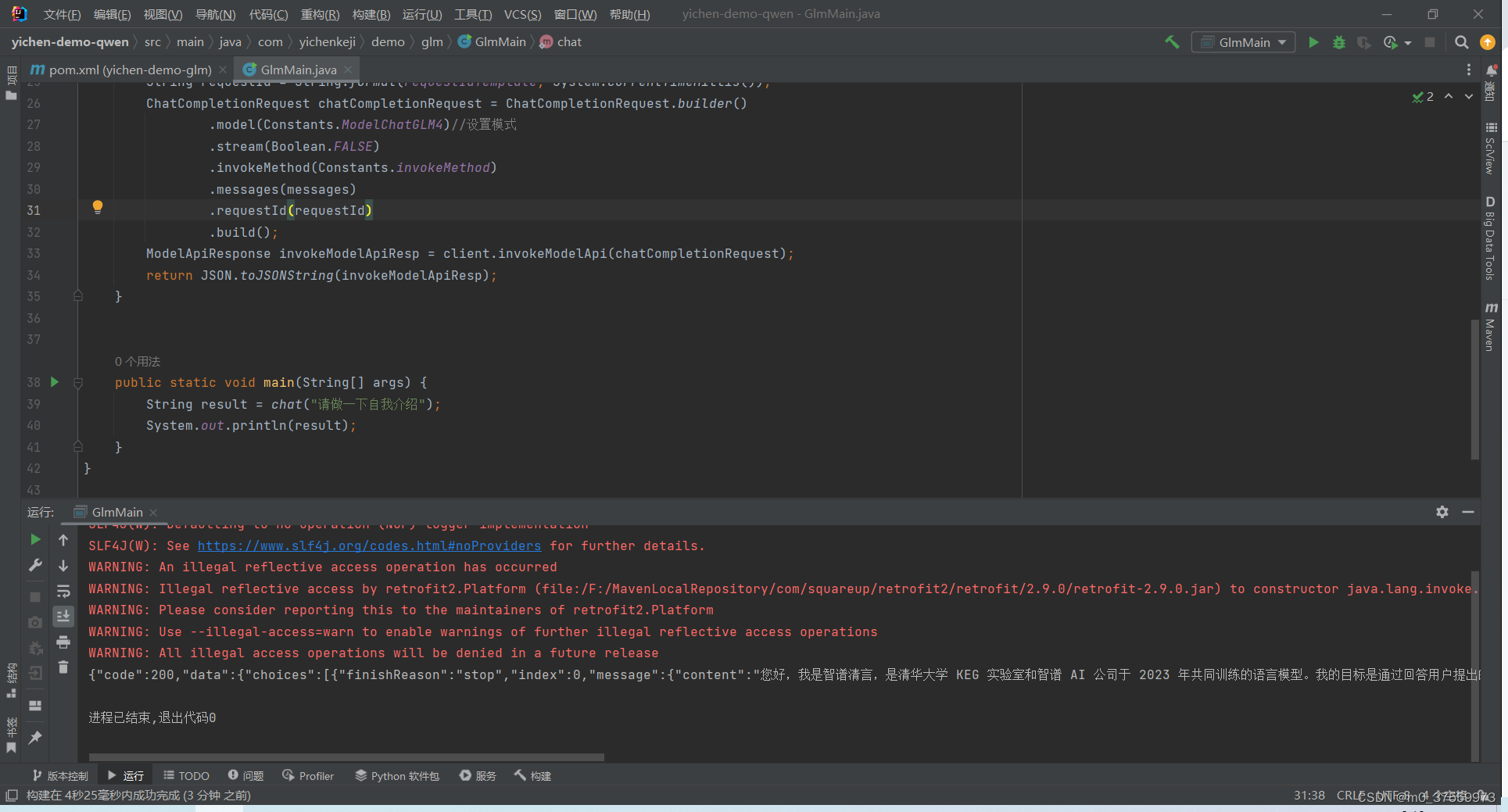
智谱AI通用大模型:官方开放API开发基础
目录 一、模型介绍 1.1主要模型 1.2 计费单价 二、前置条件 2.1 申请API Key 三、基于SDK开发 3.1 Maven引入SDK 3.2 代码实现 3.3 运行代码 一、模型介绍 GLM-4是智谱AI发布的新一代基座大模型,整体性能相比GLM3提升60%,支持128K上下文&#x…...

单片机家电产品--OC门电路
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 单片机家电产品–OC门电路 前言 记录学习单片机家电产品内容 已转载记录为主 一、知识点 1OC门电路和OD门电路的区别 OC门电路和OD门电路的区别 OC门:三极管…...

gcc常用命令指南(更新中...)
笔记为gcc常用命令指南(自用),用到啥方法就具体研究一下,更新进去... 编译过程的分布执行 64位系统生成32位汇编代码 gcc -m32 test.c -o test -m32用于生成32位汇编语言...
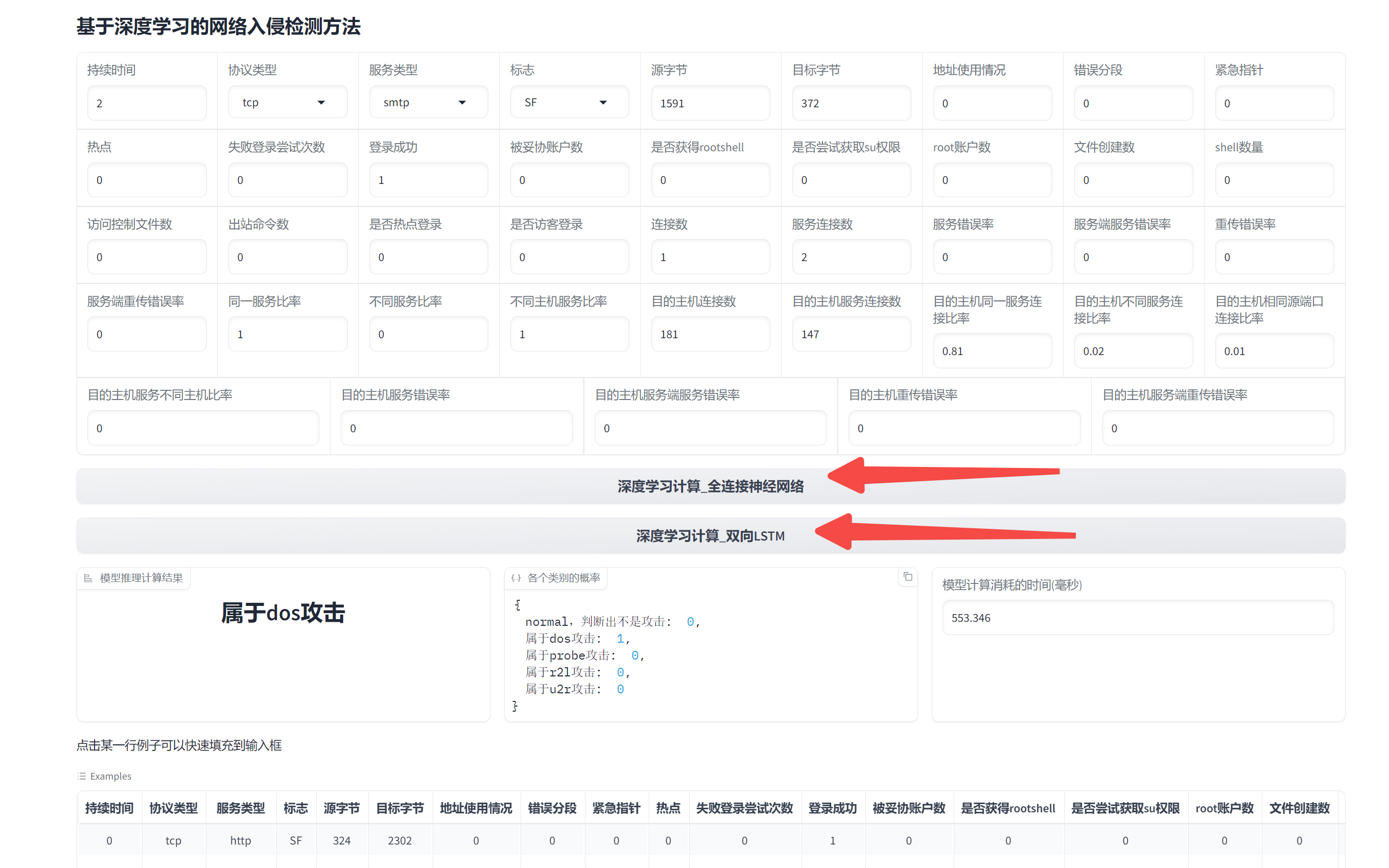
【深度学习】【机器学习】用神经网络进行入侵检测,NSL-KDD数据集,基于机器学习(深度学习)判断网络入侵,网络攻击,流量异常【3】
之前用NSL-KDD数据集做入侵检测的项目是: 【1】https://qq742971636.blog.csdn.net/article/details/137082925 【2】https://qq742971636.blog.csdn.net/article/details/137170933 有人问我是不是可以改代码,我说可以。 训练 我将NSL_KDD_Final_1.i…...
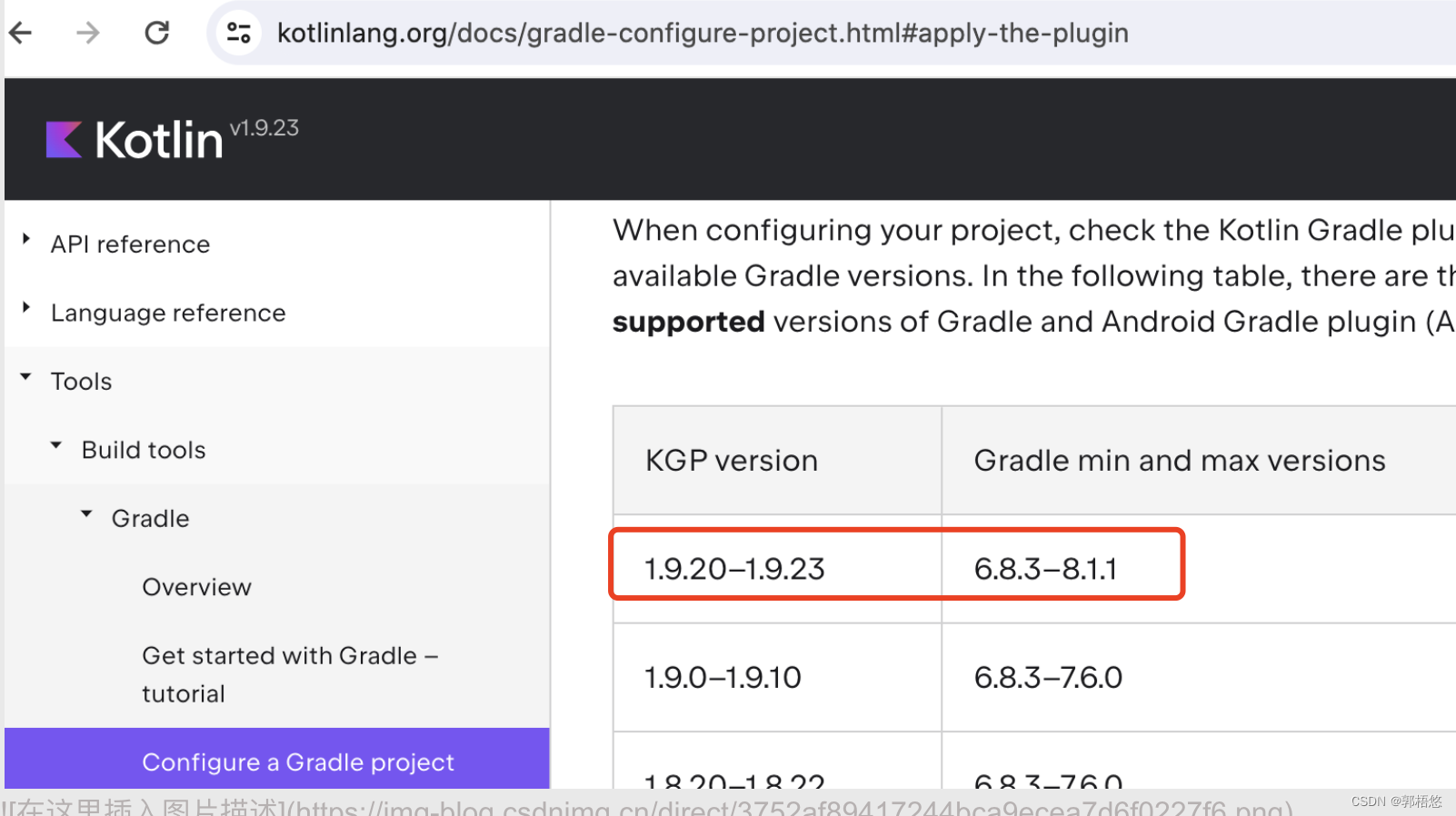
两步解决 Flutter Your project requires a newer version of the Kotlin Gradle plugin
在开发Flutter项目的时候,遇到这个问题Flutter Your project requires a newer version of the Kotlin Gradle plugin 解决方案分两步: 1、在android/build.gradle里配置最新版本的kotlin 根据提示的kotlin官方网站搜到了Kotlin的最新版本是1.9.23,如下图所示: 同时在Ko…...
ArcGIS加载的各类地图怎么去除服务署名水印
昨天介绍的: 一套图源搞定!清新规划底图、影像图、境界、海洋、地形阴影图、导航图-CSDN博客文章浏览阅读373次,点赞7次,收藏11次。一体化集成在一起的各类型图源,比如包括影像、清新的出图底图、地形、地图阴影、道路…...

AttributeError: module ‘cv2.face’ has no attribute ‘LBPHFaceRecognizer_create’
问题描述: 报错如下: recognizer cv2.face.LBPHFaceRecognizer_create() AttributeError: module ‘cv2.face’ has no attribute ‘LBPHFaceRecognizer_create’ 解决方案: 把opencv-python卸载了,然后安装ope…...
配置路由器实现互通
1.实验环境 实验用具包括两台路由器(或交换机),一根双绞线缆,一台PC,一条Console 线缆。 2.需求描述 如图6.14 所示,将两台路由器的F0/0 接口相连,通过一台PC 连接设备的 Console 端口并配置P地址(192.1…...

Google Guava第五讲:本地缓存实战及踩坑
本地缓存实战及踩坑 本文是Google Guava第五讲,先介绍为什么使用本地缓存;然后结合实际业务,讲解如何使用本地缓存、清理本地缓存,以及使用过程中踩过的坑。 文章目录 本地缓存实战及踩坑1、缓存系统概述2、缓存架构演变2.1、无缓存架构2.2、引入分布式缓存问题1:为什么选…...
一个文生视频MoneyPrinterTurbo项目解析
最近抖音剪映发布了图文生成视频功能,同时百家号也有这个功能,这个可以看做是一个开源的实现,一起看看它的原理吧~ 一句话提示词 大模型生成文案 百家号生成视频效果 MoneyPrinterTurbo生成视频效果 天空为什么是蓝色的? 天空之所以呈现蓝色,是因为大气中的分子和小粒子会…...
智能商品计划系统如何提升鞋服零售品牌的竞争力
国内鞋服零售企业经过多年的发展,已经形成了众多知名品牌,然而近年来一些企业频频受到库存问题的困扰,这一问题不仅影响了品牌商自身,也给长期合作的经销商带来了困扰。订货会制度在初期曾经有效地解决了盲目生产的问题࿰…...

OpenHarmony开发案例:【分布式遥控器】
1.概述 目前家庭电视机主要通过其自带的遥控器进行操控,实现的功能较为单一。例如,当我们要在TV端搜索节目时,电视机在遥控器的操控下往往只能完成一些字母或数字的输入,而无法输入其他复杂的内容。分布式遥控器将手机的输入能力…...

如何将Oracle 中的部分不兼容对象迁移到 OceanBase
本文总结分析了 Oracle 迁移至 OceanBase 时,在出现三种不兼容对象的情况时的处理策略以及迁移前的预检方式,通过提前发现并处理这些问题,可以有效规避迁移过程中的报错风险。 作者:余振兴,爱可生 DBA 团队成员&#x…...
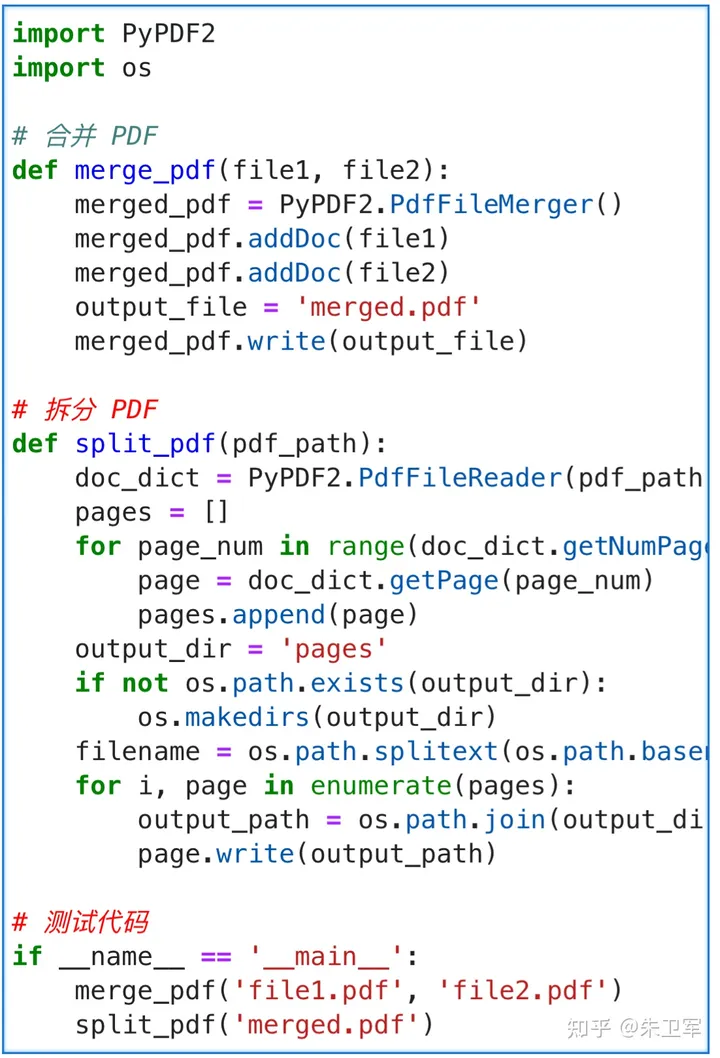
Python也可以合并和拆分PDF,批量高效!
PDF是最方便的文档格式,可以在任何设备原样且无损的打开,但因为PDF不可编辑,所以很难去拆分合并。 知乎上也有人问,如何对PDF进行合并和拆分? 看很多回答推荐了各种PDF编辑器或者网站,确实方法比较多。 …...

AI辅助生殖:多模态数据融合与深度学习在胚胎评估中的应用
1. 项目概述:当AI遇见生命的起点在辅助生殖技术(ART)这个关乎无数家庭希望的前沿领域,每一次胚胎移植都像是一场精密的“押注”。医生和胚胎学家们需要在显微镜下,从数个甚至数十个胚胎中,挑选出那个最有潜…...

FPGA加速中性原子量子计算机的原子检测技术
1. 中性原子量子计算机的原子检测挑战量子计算领域近年来最激动人心的进展之一,就是中性原子量子计算机的快速发展。这种量子计算机利用激光镊子(光学镊子)阵列来捕获和排列中性原子(如铷、铯等碱金属原子),…...

CANN/asc-devkit Trunc截断函数API
Trunc 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann…...

【信息科学与工程学】【通信工程】第二篇 网络的主要算法10 容器网络
容器与虚拟机对比特征表 特征维度 容器特征函数 虚拟机特征函数 技术实现差异 性能影响 适用场景 1. 资源隔离 container_isolation(namespace, cgroup) 函数说明:基于Linux命名空间和cgroup的资源隔离 输入:namespace_type, cgroup_config 输出:isolation_level(0…...

如何用python函数制作一个计算工具
大家好,这里是junlang的python文章 今天教大家如何用python函数做一个计算器,希望大家好好学习哦 如何制作 首先我们先定义4个函数,其中除法计算代码请看下面: def add (a,b,c):return (a b - c) def sub (x,y):return(x - y) def mulpl…...

Taotoken用量看板如何帮助开发者清晰掌握消费明细
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助开发者清晰掌握消费明细 对于使用大模型API的开发者而言,成本控制与预算管理是项目持续运营的…...

从零到一:我的循迹小车避坑指南与实战心得
1. 从零开始:循迹小车项目初体验 第一次接触循迹小车是在大学电子设计课上,看着学长们的小车能自动沿着黑线跑,觉得特别神奇。当时就暗下决心要自己做一辆,没想到这个决定让我开启了长达一个月的"痛苦并快乐着"的旅程。…...

为OpenClaw智能体工作流配置Taotoken作为统一的模型服务后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken作为统一的模型服务后端 对于使用OpenClaw框架构建AI智能体的开发者而言,一个稳定…...

为团队统一开发环境利用Taotoken CLI一键配置多模型密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为团队统一开发环境利用Taotoken CLI一键配置多模型密钥 在团队协作开发中,一个常见的挑战是如何统一管理AI模型调用的…...

Horos:如何在macOS上免费构建专业级医疗影像工作站
Horos:如何在macOS上免费构建专业级医疗影像工作站 【免费下载链接】horos Horos™ is a free, open source medical image viewer. The goal of the Horos Project is to develop a fully functional, 64-bit medical image viewer for OS X. Horos is based upon …...