prompt 工程整理(未完、持续更新)
工作期间会将阅读的论文、一些个人的理解整理到个人的文档中,久而久之就积累了不少“个人”能够看懂的脉络和提纲,于是近几日准备将这部分略显杂乱的内容重新进行梳理。论文部分以我个人的理解对其做了一些分类,并附上一些简短的理解,若读者对其感兴趣,可通过论文名称进行搜索。后续有时间,会持续更新和补充。
提示工程(Prompt Engineering)关注提示词开发和优化,帮助用户将大语言模型(Large Language Model,LLM)用于各场景和研究领域。
prompt 为人类与通用模型(如 LLM)的交互和使用提供了一个自然和直观的界面。由于其灵活性,prompt 已被广泛用作 NLP 任务的通用方法。然而,LLMs 需要细致的 prompt 工程,无论是手动还是自动,因为模型似乎不能像人类那样理解 prompt。尽管许多成功的 prompt 调整方法使用基于梯度的方法在连续空间上进行优化,但随着规模的扩大,这变得不太实际,因为计算梯度变得越来越昂贵,对模型的访问转向可能不提供梯度访问的 API。
论证研究
研究:prompt 顺序、格式的影响
- Calibrate Before Use:Improving Few-Shot Performance of Language Models:few-shot 学习可能是不稳定的,prompt 格式的选择、训练示例、甚至训练示例的顺序都会导致准确性从随机猜测到接近最先进的水平。不稳定性来自于语言模型对预测某些答案的偏向,多数标签偏差、回顾性偏差和常见 token 偏差。并提出上下文校准,一种调整模型输出概率的简单程序。
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity:论证了 prompt 的顺序对推断的结果有影响。
- Rethinking the Role of Demonstrations:What Makes In-Context Learning Work?:研究 demonstration 对于 ICL 成功所起到的作用。demonstration 中的 ground truth 输入-标签映射所起到的作用比想象的要小得多——用随机标签替换 gold 标签,只稍微降低了性能。收益主要来自于输入空间和标签空间的独立规范(independent specification);使用正确的格式,模型可以通过只使用输入或只使用标签集来保持高达 95% 的性能收益;带有语境学习目标的元训练会放大这些趋势。
研究:context 位置研究
- Lost in the Middle: How Language Models Use Long Contexts:模型更善于使用出现在上下文开头(首要偏差)和结尾(回顾偏差)的相关信息,而当被迫使用输入上下文中间的信息时,性能就会下降。并且用实验证明,在使用输入上下文方面,扩展上下文模型并不一定比非扩展上下文模型更好。
具体实现
prompt 优化
prompt 优化分为调整 context,或者在 context 中添加更多的信息,例如错误的信息、或者从错误信息中抽取到的思考、原则等辅助信息,也可以是通过检索得到的世界性知识或者专属知识。
方式:调整 context
添加更多的信息
往 context(prompt)中添加 few-shot 示例、错误的信息(或者从错误信息中抽取得到的思考、原则等辅助信息)。这部分更多与 RAG 结合使用。
- 2021-01:What Makes Good In-Context Examples for GPT-3?:提出 KATE 方法,根据测试样本与训练集相似度挑选最佳邻居作为上下文示例。
- 2021-10:Generated Knowledge Prompting for Commonsense Reasoning:提出生成知识提示,包括从语言模型中生成知识,然后在回答问题时将知识作为额外输入。
- 理解改进:将生成知识单独拆分出来,作为填充知识库内容会更好,因为我们无法保证语言模型中生成的知识是否有幻觉,需要通过一系列的方式进行过滤和处理。在回答问题时,通过 RAG 的方式检索高质量的知识作为额外输入可有效减少幻觉和冗余信息的影响。
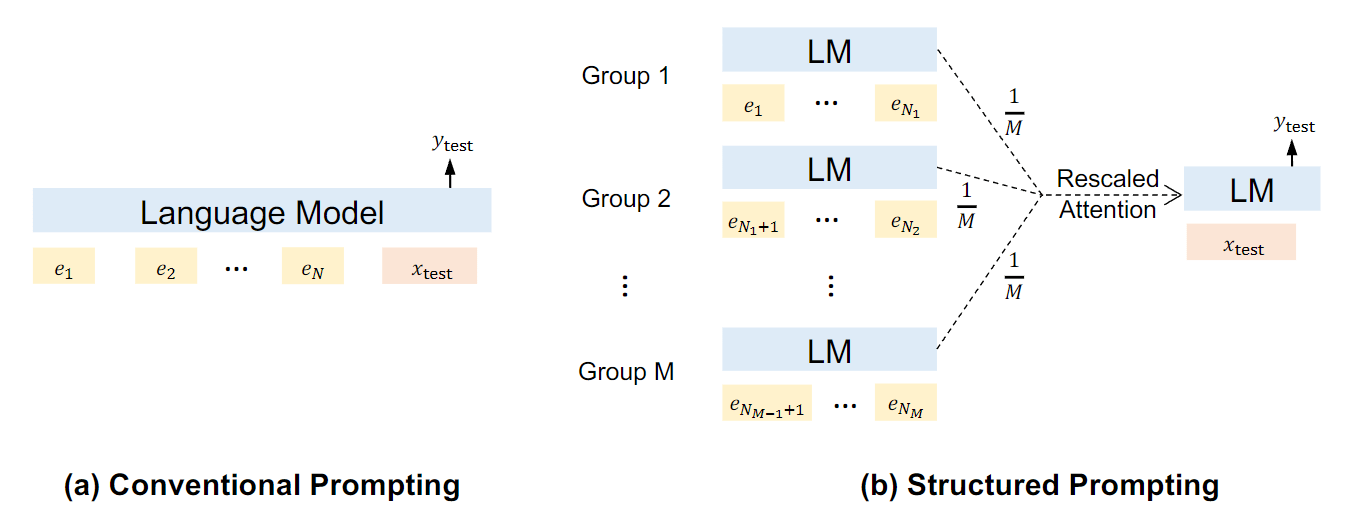
- 2022-12:Structured Prompting:Scaling In-Context Learning to 1,000 Examples:探索了如何利用更多的示例来进行语境学习,并提出了结构化 prompt,以在有限的计算复杂度下扩大示例的数量。对每组演示进行独立编码,并通过 rescaled attention 对语言模型的表征进行 prompt。
- 2023-11:Chain-of-Note:Enhancing Robustness in Retrieval-Augmented Language Models:介绍了一种新颖的方法 CHAIN-OF-NOTING(CoN)框架,核心理念是为每个检索到的文档生成连续的阅读笔记,以深入评估文档与所提问题的相关性,并整合这些信息来形成最终答案。
- 2024-02:In-Context Principle Learning from Mistakes:引入了学习原则(LEAP)。首先,有意诱导模型在这几个示例上犯错误;然后,模型本身会对这些错误进行反思,并从中学习明确的特定任务“原则”,这些原则有助于解决类似问题并避免常见错误;最后,提示模型使用原始的 few-shot 示例和这些学到的一般原则来回答未见过的测试问题。
过滤冗余或错误信息
- 2023-05:Deliberate then Generate: Enhanced Prompting Framework for Text Generation:提出 DTG 提示方法,通过让模型在可能包含错误的合成文本上检测错误类型,鼓励 LLM 在生成最终结果之前进行深思熟虑。
- 2023-11:System 2 Attention (Is Something You Might Need Too):通过诱导 LLM 重新生成输入上下文,使其只包含相关部分;然后再关注重新生成的上下文,以诱导出最终良好的响应。
方式:prompt 压缩
prompt 压缩可以缩短原始 prompt,同时尽可能保留最重要的信息。这可以减少模型推理阶段的 prefill 时间,并过滤掉 context 中冗余、错误的信息,帮助生成更为准确的回复。本质上也是调整 context,但还是将其另成一派。
可行性结论:
- 语言中常常包含不必要的重复,且无意义的内容,例如在传统 NLP 中,我们时常会去停用词,因为这些停用词没有太多的语义或者对模型输出结果几乎没有影响。
- 《Prediction and entropy of printed English》表明,英语在段落或章节长度的文本中有很多冗余,大约占 75%。这意味着大部分单词可以从它们前面的单词中预测出来。
疑问:
- prompt 被压缩后,后面位置的 token 其位置编码会相应变化,例如第 500 位置的 token 压缩后到了 200 位置,虽然它在 500 位置处的信息量或者 logits 对结果没有影响,但到了 200 位置是否就变得重要了呢?
- RLHF 对齐越好的模型,是否对 prompt 压缩越敏感?压缩后的 prompt 几乎人类不可读,与人类喜好对齐强的模型是否也不容易理解?在一篇讲述 Pinecone 搜索方案的博客中将压缩后的 prompt 送入 gpt-4-1106-preview,它会返回文章的格式和用词写法错误,但在 gpt-3.5-turbo 中就不会出现。
相关方法
- 2023-04:Unlocking Context Constrainits of LLMs:Enhancing Context Efficiency of LLMs with Self-Information-Based Content Filtering:引入了“选择性上下文”(Selective Context 技术),通过过滤掉信息量较少的内容,为 LLM 提供了一种更紧凑、更高效的上下文表示法,同时又不影响它们在各种任务中的性能。
- 2023-10:LLMLingua:Compressing Prompts for Accelerated Inference of Large Language Models:提出了一种从粗到细的提示压缩方法 LLMLingua,包括一种在高压缩率下保持语义完整性的预算控制器、一种能更好地模拟压缩内容间相互依存关系的 token 级迭代压缩算法,以及一种基于指令调整的语言模型间分布对齐方法。
方式:优化指令
以人的行为习惯、思维方式写下的 prompt 往往能达到及格分,经验丰富老道的提示工程师或许可以在第一步就写出达到 80 分的 prompt。但无论如何,人写下的 prompt 很难跳出人类的思维方式,我们会尽可能将话语和文字组织得通顺连贯、行文结构合理,偶尔捎带些许有趣性,但这并不一定是最符合模型的思考习惯。例如模型的对齐能力是否会有影响?对齐能力强的模型更能理解人的语言,即使低质量的 prompt 也能执行得好,例如 GPT4),我们可以不强求非得以人的视角写出符合人类习惯的 prompt,让模型自己去生成自己能更好理解的 prompt,似乎是一个更好的方向。
- 2022-03:An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels:介绍了一种选择 prompt 的方法,在一组候选 prompt 中,选择使输入和模型输出之间的互信息最大化的 prompt。
- 2022-11:Large Language Models Are Human-Level Prompt Engineers:提出了 APE(自动 prompt 工程师)框架,根据问题和回答让 LLM 自动生成指令,然后再用 LLM 去评估生成指令的质量,从中挑选效果最好的指令。此外,可以根据蒙特卡洛法去检索更好的指令集并减少迭代的计算成本。
- 2023-02:Active Prompting with Chain-of-Thought for Large Language Models:将主动学习的过程应用到 prompt 工程上,主要是流程和工程上面的改进,制定不确定性标准,例如分歧、熵、方差和置信度来评估 prompt 在特定任务上的效果。选择这些效果不佳的 prompt,交给人工去标注,最后进行推断。不断重复上述过程,与主动学习的过程相同。
方式:定向刺激
- 2023-02:Guidling Large Language Models via Directional Stimulus Prompting:提出了一个名为“定向刺激 prompt”(Directional Stimulus Prompting)的新型 prompt 框架,先训练一个经过微调、强化学习后的小型模型,然后使用该小型模型根据用户的查询来生成对应的刺激(文本),将其添加到 prompt 中来引导黑盒大语言模型朝着所需的输出方向前进。
- 2023-07:EmotionPrompt:Leveraging Psychology for Language Models Enhancement via Emotional Stimulus:作者从心理学中汲取灵感,提出 EmotionPrompt(情感提示)来探索情商,以提高 LLM 的性能。具体来说,作者为 LLMs 设计了 11 句情感刺激句子,只需将其添加到原始 prompt 中即可。缺陷在于情绪刺激可能并不适用于其他任务,并且对不同 LLM 的效果无法保证。
连续推理
将中间的推理步骤一步步思考完整,或者将一整个问题逐步分解成子问题来解决。核心在于需要执行多次或多跳来完成任务。
方式:CoT 与类 CoT 大家族
CoT 一系列研究,给我的感觉像是将数据结构中的链表、树和图依次应用到 CoT 中。
-
2022-02:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models:提出了思维链(CoT)的方法。
-
2022-03:Self-Consistency Improves Chain of Thought Reasoning in Language Models:提出了自我一致性方法,先使用思维链 prompt,然后通过采样等手段获取多条输入,汇总答案(根据投票以及加权等方式),并选择最一致的答案。该方法受限于固定的答案集,并且计算成本较高(多条输出、推理路径)。但在算术和常识推理任务上能够提高准确性。
理解改进:核心在于如何选择最一致的答案,在开放式闲聊场景中,使用奖励模型来评分是一个不错的方式,例如生成多条回复,让奖励模型打分,挑选分数最高的回复。
-
2023-05:Tree of Thoughts:Deliberate Problem Solving with Large Language Models:还未细看。
-
2023-08:Better Zero-Shot Reasoning with Role-Play Prompting:提出了一种由两阶段框架组成的新型 zero-shot role-play 提示方法,旨在增强 LLM 的推理能力。实验结果凸显了 role-play 提示作为一种隐性和有效的 CoT 触发器的潜力,从而提高了推理结果。
方式:问题拆分
- 2022-10:Measuring and Narrowing the Compositionality Gap in Language Models:提出了 self-ask 的方式,不断将复杂、多跳问题拆分为子问题,然后依次解决子问题,最后回答完整问题。在解决子问题的过程中,可借助搜索引擎来获取事实性知识。
- 2022-10:ReAct: Synergizing Reasoning and Acting in Language Models:提出了 ReAct 框架。
- 2023-06:Let’s Verify Step by Step:在数学推理领域,过程监督可以用来训练比结果监督更可靠的奖励模型。主动学习可以用来降低人类数据收集的成本。
风险和误用
真实性(幻觉)
LLM 模型有时会生成看起来连贯且令人信服的回答,但这回答是 LLM 模型虚构的答案,也就是说 LLM 模型在一本正经的胡说八道。改进 prompt 可以帮助提高模型生成更准确/真实的回答,并降低生成不一致和虚构回答的可能性。
偏见
LLMs 可能会产生问题的生成结果,这些结果可能会对模型在下游任务上的性能产生负面影响,并显示可能会恶化模型性能的偏见。其中一些可以通过有效的 prompt 策略来缓解,但可能需要更高级的解决方案,如调节和过滤。
在 Calibrate Before Use:Improving Few-Shot Performance of Language Models 论文中提到“方差在更多的数据和更大的模型中持续存在”,而造成高方差的原因是 LLMs 中存在的各种偏差(偏见),例如:
- 在 prompt 中经常出现的答案(多数标签偏差)。
- 在 prompt 的最后(回顾性偏差)。
- 在预训练数据中常见的答案(常见 token 偏差)。
多数标签偏差
当一个类别更常见时,GPT-3 会严重偏向预测该类别,本质是多数标签严重影响模型预测分布,从而对准确性造成很大影响。
理解:1-shot 时,模型预测很大程度上受到这一个训练示例标签的影响,从而输出该训练示例的标签,而非期望得到的标签。
回顾性偏差
模型的多数标签偏差因其回顾性偏差而加剧:重复出现在 prompt 结束时的答案的倾向。例如,当两个负例出现在最后,模型将严重倾向于负面的类别。
回顾性偏差也会影响到生成任务。对于 4-shot 的 LAMA,更接近 prompt 结束的训练答案更有可能被模型重复。总的来说,回顾性偏差与多数标签偏差一样,都会影响模型预测的分布。
例如,joyland 模型重复问题,很大程度上由于 context 中存在大量重复的回复,尤其是最近几轮相近或相同的回复,加上对话的 prompt 组织格式形似 ICL,这进一步加重回顾性偏差,从而导致当前轮模型回复继续重复。详细研究请参考 Rethinking Historical Messages。
常见 token 偏差
模型倾向于输出预训练分布中常见的 token,而这可能对下游任务的答案分布来说是次优的。在 LAMA 事实检索数据集上,模型常常预测常见的实体,而 ground truth 的答案却是罕见的实体。在文本分类中也出现了更细微的常见token偏差问题,因为某些标签名称在预训练数据中出现的频率较高,所以模型会对预测某些类别有固有偏见。总的来说,常见 token 偏差解释了标签名称的选择对于模型预测的重要性,以及为什么模型在处理罕见答案时会遇到困难。
相关工具
| 名称 | 链接 |
|---|---|
| awesome-chatgpt-prompts-zh | https://github.com/PlexPt/awesome-chatgpt-prompts-zh |
| snackprompt | https://snackprompt.com/ |
| flowgpt | https://flowgpt.com/ |
| prompthero | https://prompthero.com/ |
| publicprompts.art | https://publicprompts.art/ |
| guidance | https://github.com/guidance-ai/guidance |
| Synapse_CoR | https://github.com/ProfSynapse/Synapse_CoR |
| PromptInject | https://github.com/agencyenterprise/PromptInject |
参考资料
- 工程指南:https://www.promptingguide.ai/zh
- prompt 学习:https://learningprompt.wiki/
相关文章:
prompt 工程整理(未完、持续更新)
工作期间会将阅读的论文、一些个人的理解整理到个人的文档中,久而久之就积累了不少“个人”能够看懂的脉络和提纲,于是近几日准备将这部分略显杂乱的内容重新进行梳理。论文部分以我个人的理解对其做了一些分类,并附上一些简短的理解…...

兼容性测试用例
备注:本文为博主原创文章,未经博主允许禁止转载。如有问题,欢迎指正。 个人笔记(整理不易,有帮助,收藏+点赞+评论,爱你们!!!你的支持是我写作的动力) 笔记目录:学习笔记目录_pytest和unittest、airtest_weixin_42717928的博客-CSDN博客 个人随笔:工作总结随笔_8、…...
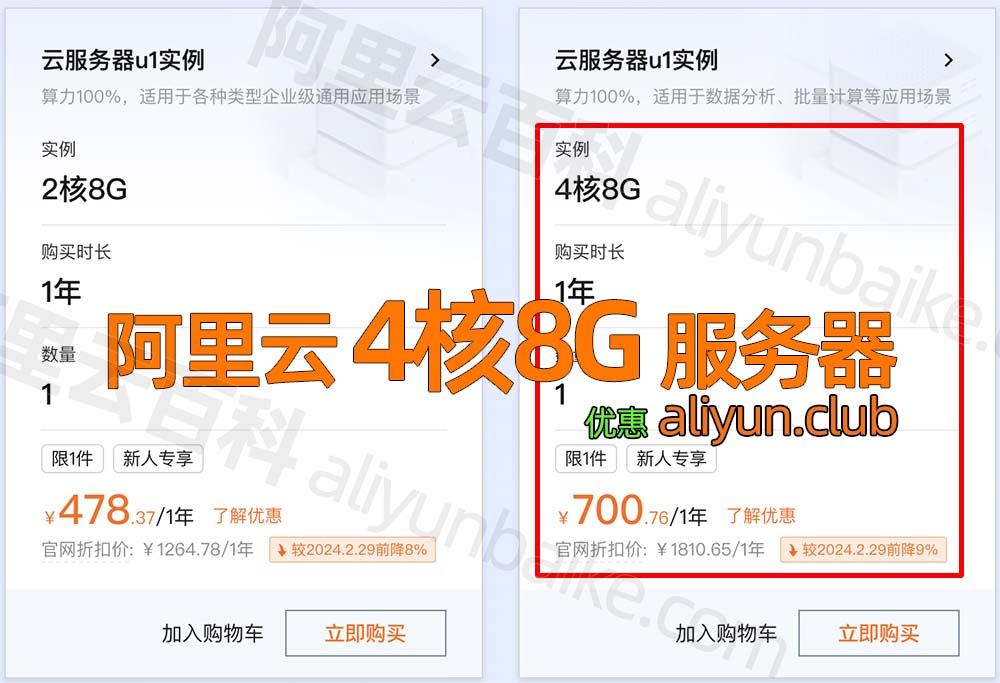
阿里云4核8G云服务器价格多少钱?700元1年
阿里云4核8G云服务器价格多少钱?700元1年。阿里云4核8G服务器租用优惠价格700元1年,配置为ECS通用算力型u1实例(ecs.u1-c1m2.xlarge)4核8G配置、1M到3M带宽可选、ESSD Entry系统盘20G到40G可选,CPU采用Intel(R) Xeon(R…...

ts 中的keyof 和typeof
作用: keyof:用于获取对象类型的所有键的联合类型。typeof:用于获取变量或表达式的类型。 返回类型: keyof:返回的是一个对象类型的所有键组成的联合类型。typeof:返回的是一个值的类型。 使用场景…...

每日一题:买卖股票的最佳时机II
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。 在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。 返回 你能获得的 最大 利润 。 示例 1&a…...
nginx安装在linux上
nginx主要用于反向代理和负载均衡,现在简单的说说如何在linux操作系统上安装nginx 第一步:安装依赖 yum install -y gcc-c pcre pcre-devel zlib zlib-devel openssl openssl-devel 第二步: 下载nginx,访问官网,ngin…...
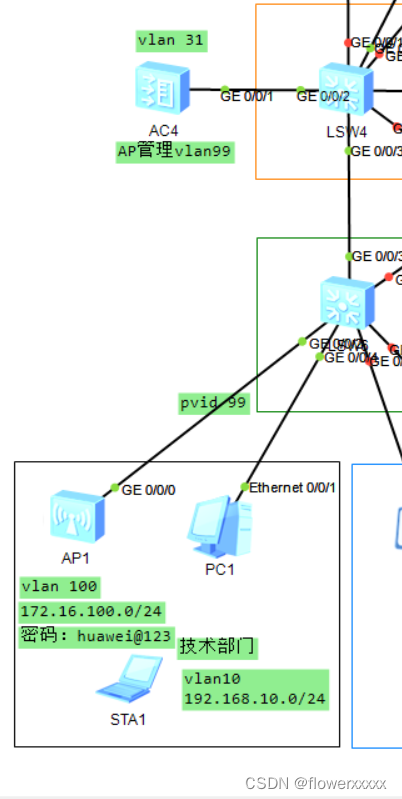
ENSP-旁挂式AC
提醒:如果AC不能成功上线AP,一般问题不会出在AC上,优先关注AC-AP线路上的二层或三层组网的三层交换机 拓扑图 管理VLAN:99 | 业务VLAN:100 注意点: 1.连接AP的接口需要打上pvid为管理vlan的标签 2.AC和…...

如何获取手机root权限?
获取手机的 root 权限通常是指在 Android 设备上获取超级用户权限,这样用户就可以访问和修改系统文件、安装定制的 ROM、管理应用权限等。然而,需要注意的是,获取 root 权限可能会导致手机失去保修、安全性降低以及使系统变得不稳定。在获取 …...
海南赛区复赛真题)
2023年全国青少年信息素养大赛(Python)海南赛区复赛真题
2023年全国青少年信息素养大赛(Python)海南赛区复赛真题第1题,整数加8 题目描述: 输入一个整数,输出这个整数加8 的结果。 输入描述: 输入一行一个正整数。 输出描述: 输出求和的结果。 样例1: 输入: 5 输出: 13 x= int(input()) print(x+8) 第2题,哼哈二将 题目描…...

node.js服务器动态资源处理
一、node.js服务器动态资源处理与静态资源处理的区别? 静态与动态服务器主要区别于是否读取数据库,若然在数据库中的资料处理中将数据转换成可取用格式的结构,也就是说把对象转化为可传输的字节序列过程称为序列化,反之则为反序列…...

DNS是TCP还是UDP
既使用TCP也使用UDP 1. 域名解析时用UDP 在大多数情况下,DNS请求使用UDP协议,因为UDP协议可以提供较高的效率和安全性,尤其是在查询的响应大小较小(通常不超过512字节)时。非可靠连接,因为传输的数据量小…...
)
Redis魔法:解锁高性能缓存的神奇之门(二)
本系列文章简介: 在现代的软件开发中,高性能和高可用性是每个开发者都追求的目标。然而,随着数据量和访问频率的不断增长,传统的数据库存储方案往往难以应对这种挑战。这就引出了一个问题:如何在保证数据的高效访问和持…...
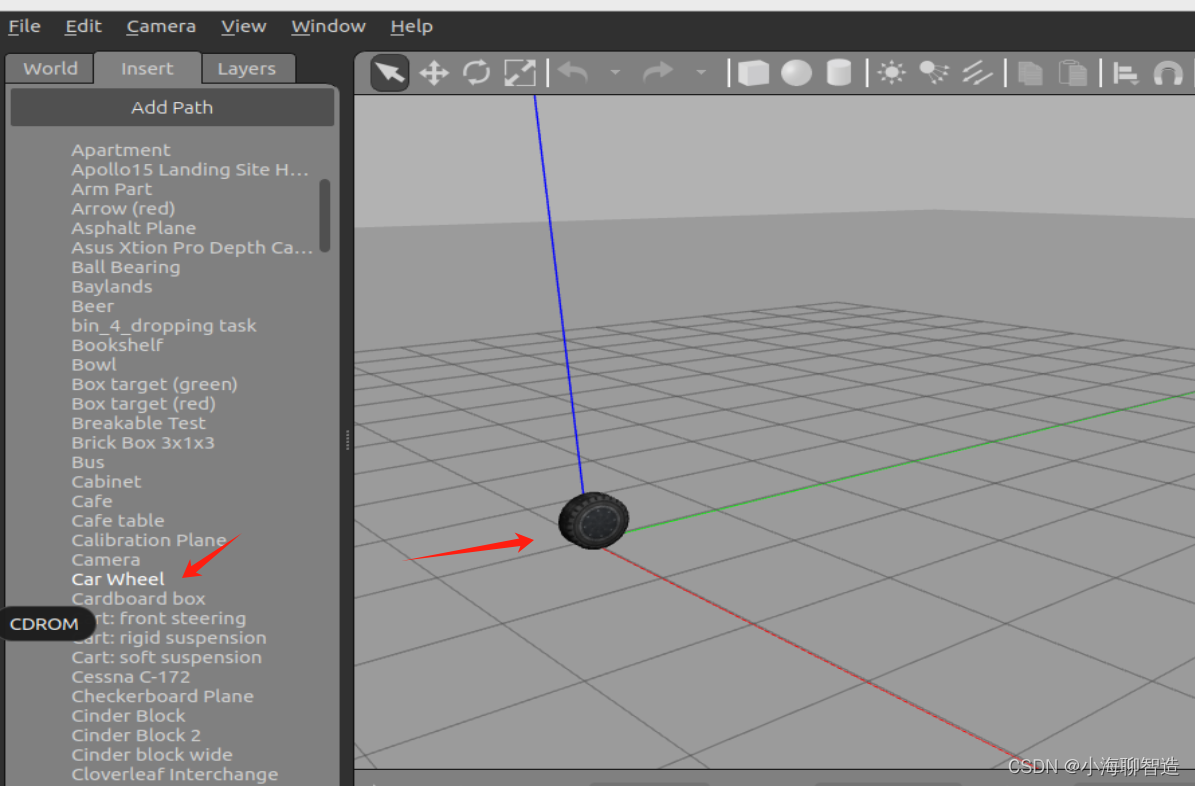
ROS2 仿真学习02 Gazebo导入官方示例模型
1.下载模型 git clone https://gitee.com/bingda-robot/gazebo_models.git将gazebo_models拖到到.gazebo当中(如果没看到.gazebo文件请按住CTRLh) 2.添加模型到gazebo的Insert 这就将官方示例的模型都导入到Gazebo 了 随便试试一个模型...

echarts图表按需导入
引入核心包引入图表类型引入使用组件引入渲染器注册所有引入 在项目中引入 Apache ECharts // 引入 echarts 核心模块,核心模块提供了 echarts 使用必须要的接口。 import * as echarts from echarts/core; // 引入柱状图图表,图表后缀都为 Chart impo…...

蓝桥杯(基础题)
试题 C: 好数 时间限制 : 1.0s 内存限制: 256.0MB 本题总分:10 分 【问题描述】 一个整数如果按从低位到高位的顺序,奇数位(个位、百位、万位 )上 的数字是奇数,偶数位(十位、千位、十万位 &…...
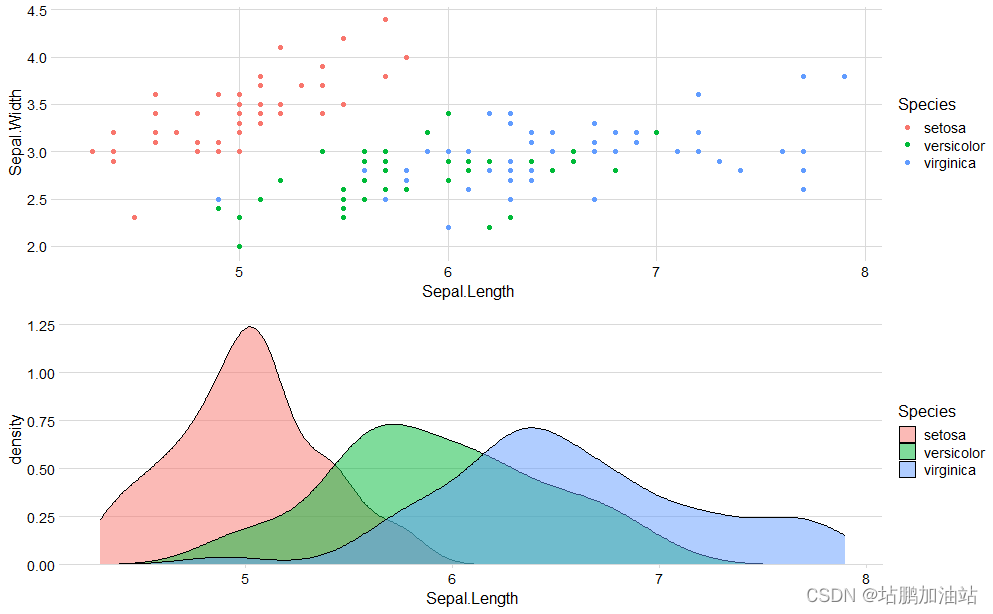
【R语言】概率密度图
概率密度图是用来表示连续型数据的分布情况的一种图形化方法。它通过在数据的取值范围内绘制一条曲线来描述数据的分布情况,曲线下的面积代表了在该范围内观察到某一数值的概率。具体来说,对于给定的连续型数据,概率密度图会使用核密度估计&a…...

【学习】软件测试需求分析要从哪些方面入手
软件测试需求分析是软件测试过程中非常重要的一个环节,它是为了明确软件测试的目标、范围、资源和时间等要素,以确保软件测试的有效性和全面性。本文将从以下几个方面对软件测试需求分析进行详细的阐述: 一、软件测试目标 软件测试目标是指…...

starrocks的fe节点启动不起来的解决办法
fe节点启动报错:Do not specify the helper node to FE itself. Please specify it to the existing running Leader or Follower FE at com.starrocks.StarRocksFE.main(StarRocksFE.java:68) [starrocks-fe.jar:?] Caused by: com.sleepycat.je.EnvironmentFailureExcepti…...
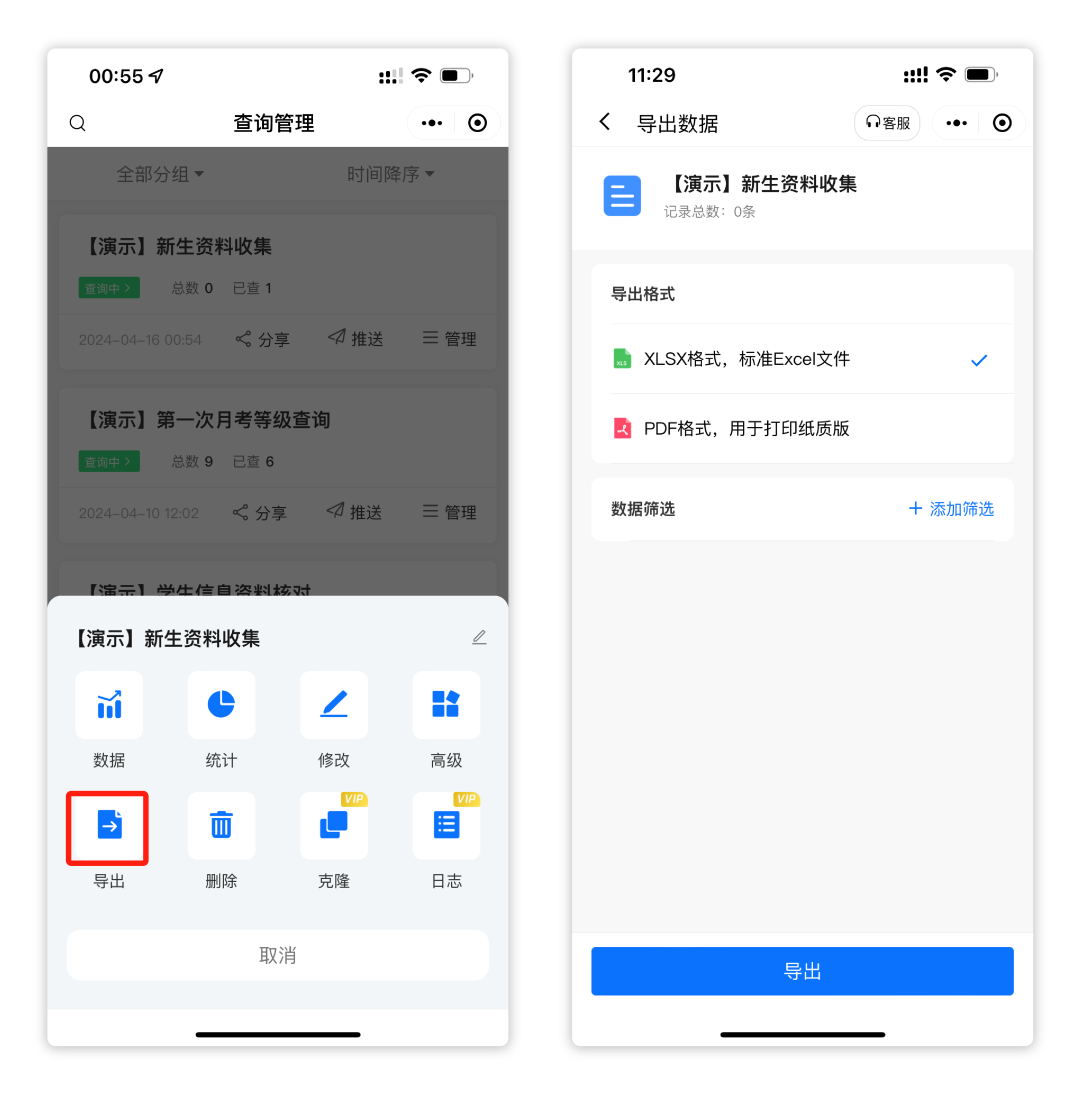
如何用易查分小程序快速制作填表?
工作中,我们经常需要收集信息,填写表格,可以使用易查分的新建填表功能,本文将介绍怎样快速制作一个信息收集表。 案例:新生资料收集系统 01进入新建填表 进入易查分小程序首页,点击新建填表,有…...
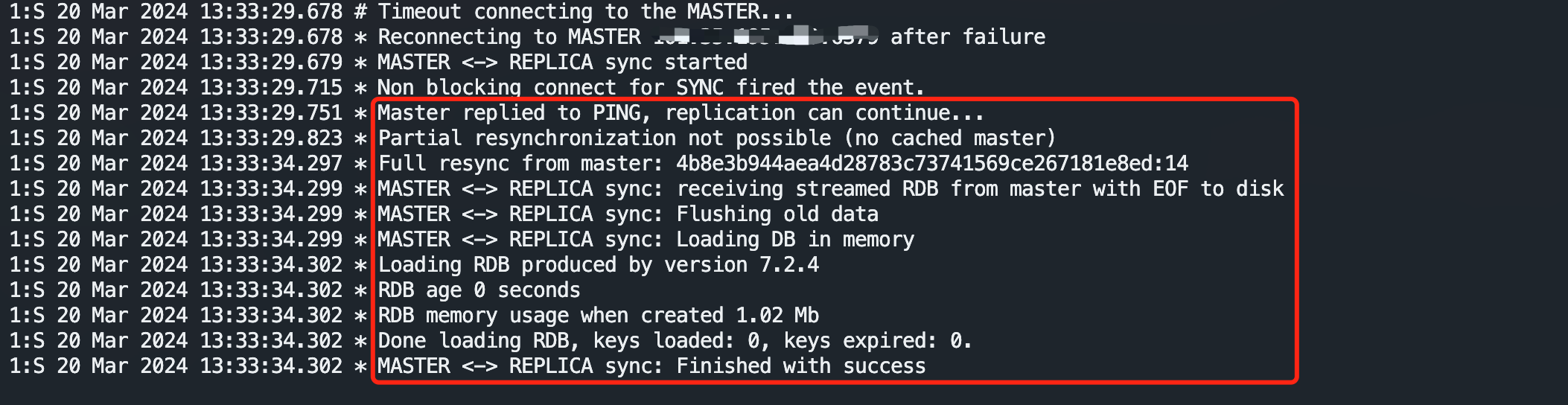
Redis部署之主从
使用两台云服务器,在 Docker 下部署。 Redis版本为:7.2.4 下载并配置redis 配置文件 下载 wget -c http://download.redis.io/redis-stable/redis.conf配置 master节点配置 bind 0.0.0.0 # 使得Redis服务器可以跨网络访问,生产环境请考虑…...

AI Agent沙箱环境部署指南:从Docker容器化到生产级运维
1. 项目概述:构建一个生产级的AI Agent沙箱环境最近在折腾一个挺有意思的项目,叫NemoClaw OpenClaw Sandbox。简单来说,它是一套完整的、开箱即用的部署方案,能帮你在自己的云服务器(VPS)上,快速…...

手机写作app2026推荐,助力高效创作体验
手机写作app2026推荐,助力高效创作体验在当今数字化时代,手机写作app成为了众多创作者的得力助手。据《2026 中国数字写作行业报告》显示,2026 年手机写作app的用户规模同比增长了 35%,但能真正满足创作者多样化需求的app仅占 20%…...

node.js、node、nvm、npm、npx的关系
1、node.js Node.js:一个基于Chrome V8引擎的JavaScript运行环境。Node.js是一个开源的、跨平台的JavaScript运行环境,用于在服务器端运行JavaScript代码。它使得开发人员可以使用JavaScript来编写服务器端应用程序,从而简化了开发过程&#…...

Postman实战:自动化管理API访问令牌的两种高效策略
1. 为什么需要自动化管理API访问令牌 在如今的API开发中,身份验证和授权已经成为必不可少的安全机制。大多数现代API都采用基于令牌(Token)的认证方式,其中Bearer Token是最常见的标准之一。想象一下,每次调用API都需要手动复制粘贴一长串Tok…...

【限时开放】DeepSeek内部调试工具集首次对外披露:含Request ID全链路追踪、模型响应热力图与异常模式识别器
更多请点击: https://intelliparadigm.com 第一章:DeepSeek API接入开发教程 DeepSeek 提供了稳定、高性能的大模型 API 接口,支持文本生成、对话补全与函数调用等多种能力。接入前需在官方控制台申请 API Key,并确保账户已开通对…...

SoC设计中虚拟原型技术与TLM建模实践
1. 虚拟原型技术概述在SoC设计领域,虚拟原型技术(Virtual Prototyping)已经成为现代芯片开发流程中不可或缺的关键环节。这项技术的核心价值在于,它能够在RTL级硬件设计完成之前,就为软件团队提供一个可执行的硬件抽象模型。作为一名经历过多…...

从零到一:Windows环境下Oracle19c的完整部署与实战配置
1. 环境准备:搭建Oracle19c的Windows温床 第一次在Windows上装Oracle数据库就像给新房子铺水电——基础没打好,后面全是坑。我见过太多人因为忽略环境检查,导致安装到一半报错重来的惨剧。这里分享几个实测有效的准备工作: 硬件配…...

如何在5分钟内快速上手LeRobot机器人AI控制框架:从零到一的完整指南
如何在5分钟内快速上手LeRobot机器人AI控制框架:从零到一的完整指南 【免费下载链接】lerobot 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning 项目地址: https://gitcode.com/GitHub_Trending/le/lerobot 还在为…...

基于Azure AI Search与OpenAI构建企业级智能问答系统实战指南
1. 项目概述:当企业级搜索遇上生成式AI 如果你正在为如何让公司内部的知识库、产品文档或客服系统变得更“聪明”而头疼,那么你很可能已经听说过或将接触到这个项目: Azure-Samples/azure-search-openai-demo 。这不仅仅是一个简单的代码示…...

ReRAM与PCM存内计算:突破冯·诺依曼瓶颈,赋能边缘AI与类脑计算
1. 从冯诺依曼瓶颈到存内计算:一场芯片架构的范式转移最近几年,但凡关注芯片和人工智能领域的朋友,肯定对“存内计算”这个词不陌生。它听起来像是一个技术术语,但背后直指一个困扰了我们半个多世纪的计算机根本性难题:…...