工业数学模型——高炉煤气发生量预测(三)
1、工业场景
冶金过程中生产的各种煤气,例如高炉煤气、焦炉煤气、转炉煤气等。作为重要的副产品和二次能源,保证它们的梯级利用和减少放散是煤气能源平衡调控的一项紧迫任务,准确的预测煤气的发生量是实现煤气系统在线最优调控的前提。
2、数学模型
本次研究主要采用了长短记忆模型(LSTM)预测了正常工况下的高炉煤气发生量。后续研究方向希望将正常工况扩展到变化工况条件下,例如休风、减产、停产、检修等条件下煤气发生量,并引入更多特征维度,例如:焦比、煤比、风量、富氧、风温、风压、炉内压差等。下面重点介绍一下LSTM网络结构。
长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。
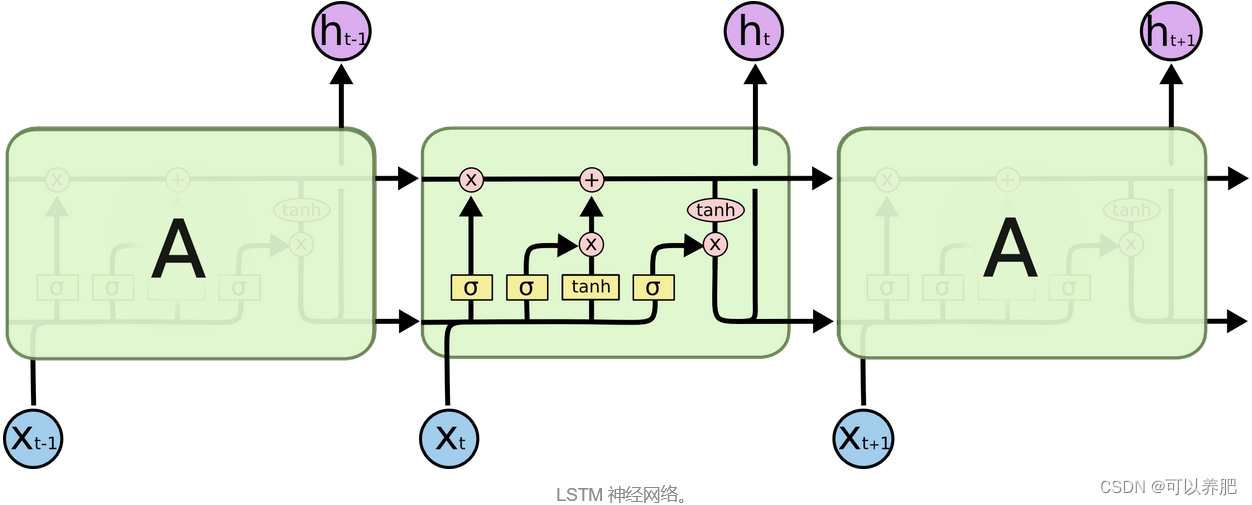 这张图片是经典的LSTM网络结构的图片,但是不好理解,图片把多维的空间结构压缩成了二维图片,所以需要大家脑补一下,回放到立体空间中去理解。相对比RNN 通过时间步骤地更新隐藏状态和输出结果。而LSTM 通过输入门、遗忘门和输出门来控制隐藏状态的更新和输出。在这里不过多的去讲解模型结构,大家可以从网上了解一下,LSTM网络模型作为世纪霸主被广泛应用于自然语言处理、语音识别、图像处理等领域。总之很厉害!
这张图片是经典的LSTM网络结构的图片,但是不好理解,图片把多维的空间结构压缩成了二维图片,所以需要大家脑补一下,回放到立体空间中去理解。相对比RNN 通过时间步骤地更新隐藏状态和输出结果。而LSTM 通过输入门、遗忘门和输出门来控制隐藏状态的更新和输出。在这里不过多的去讲解模型结构,大家可以从网上了解一下,LSTM网络模型作为世纪霸主被广泛应用于自然语言处理、语音识别、图像处理等领域。总之很厉害!
3、数据准备
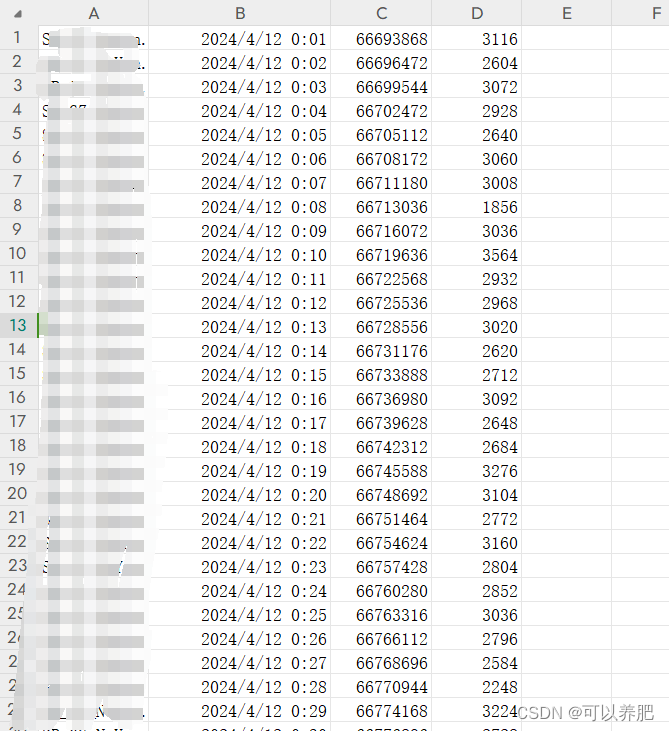
本次数据收集了1#高炉从4月12日0点到4月16日0点72小时的煤气累计发生量数据,时间间隔为60000ms也就是1分钟一次点位数据,通过计算获取5760个分钟级的煤气发生量数据。
如图:第一个字段是数采时序库中的点位标识,第二个字段是时间,第三个字段是当前煤气发生量累计值,第四个字段是计算获得的当前分钟内煤气发生量。
4、模型构建
class LSTM(nn.Module):"""LSMT网络搭建"""def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):super().__init__()self.input_size = input_sizeself.hidden_size = hidden_sizeself.num_layers = num_layersself.output_size = output_sizeself.num_directions = 1 # 单向LSTMself.batch_size = batch_sizeself.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True)self.linear = nn.Linear(self.hidden_size, self.output_size)def forward(self, input_seq):batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size)c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size)output, _ = self.lstm(input_seq, (h_0, c_0))pred = self.linear(output)pred = pred[:, -1, :]return pred5、模型训练
①数据预处理:加载数据文件,原始数据文件为csv(通过1#高炉84小时内煤气发生量累计值,时间间隔为60000ms,计算出84小时内每分钟的发生量)将数据分为训练集:验证集:测试集=3:1:1。
def load_data(file_name):"""加载数据文件,原始数据文件为csv(通过1#高炉24小时内煤气发生量累计值,时间间隔为60000ms,计算出24小时内每分钟的发生量):param file_name csv文件的绝对路径:return 训练集、验证集、测试集、训练集中最大值、训练集中最小值训练集:验证集:测试集=3:1:1"""dataset = pd.read_csv('D:\\LIHAOWORK\\' + file_name, encoding='gbk')train = dataset[:int(len(dataset) * 0.6)]val = dataset[int(len(dataset) * 0.6):int(len(dataset) * 0.8)]test = dataset[int(len(dataset) * 0.8):len(dataset)]max, nin = np.max(train[train.columns[3]]), np.min(train[train.columns[3]]) # 分钟内发生量是csv中第四个字段return train, val, test, max, nin②数据组装:把数据组装成训练、验证、测试需要的格式。实质是90个顺序数据为一组作为输入值x,第91个作为真实发生值y,如此循环。
def process_data(data, batch_size, shuffle, m, n, k):"""数据处理:param data 待处理数据:param batch_size 批量大小:param shuffle 是否打乱:param m 最大值:param n 最小值:param k 序列长度:return 处理好的数据"""data_3 = data.iloc[0:, [3]].to_numpy().reshape(-1) #data_3 = data_3.tolist()data = data.values.tolist()data_3 = (data_3 - n) / (m - n)feature = []label = []for i in range(len(data) - k):train_seq = []train_label = []for j in range(i, i + k):x = [data_3[j]]train_seq.append(x)train_label.append(data_3[i + k])feature.append(train_seq)label.append(train_label)feature_tensor = torch.FloatTensor(feature)label_tensor = torch.FloatTensor(label)data = TensorDataset(feature_tensor, label_tensor)data_loader = DataLoader(dataset=data, batch_size=batch_size, shuffle=shuffle, num_workers=0, drop_last=True)return data_loader③模型训练:输入大小为1;隐藏层大小为128,隐藏层数为1,输出大小为1,批量大小为5,学习率为0.01,训练次数3。
def train(Dtr, Val, path):"""训练:param Dtr 训练集:param Val 验证集:param path 模型保持路劲"""input_size = 1hidden_size = 128num_layers = 1output_size = 1epochs = 5model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=5)loss_function = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=1e-4)# optimizer = torch.optim.SGD(model.parameters(), lr=0.05, momentum=0.9, weight_decay=1e-4)scheduler = StepLR(optimizer, step_size=30, gamma=0.1)# start trainingfor epoch in tqdm(range(epochs)):train_loss = []for (seq, label) in Dtr:y_pred = model(seq)loss = loss_function(y_pred, label)train_loss.append(loss.item())optimizer.zero_grad()loss.backward()optimizer.step()scheduler.step()# validationmodel.eval()val_loss = []for seq, label in Val:y_pred = model(seq)loss = loss_function(y_pred, label)val_loss.append(loss.item())print('epoch {:03d} train_loss {:.8f} val_loss {:.8f}'.format(epoch, np.mean(train_loss), np.mean(val_loss)))model.train()state = {'models': model.state_dict()}torch.save(state, path)训练过程如下:

④模型测试:
def test(Dte, path, m, n):"""测试:param Dte 测试集:param path 模型:param m 最大值:param n 最小值"""pred = []y = []input_size = 1hidden_size = 128num_layers = 1output_size = 1model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=5)model.load_state_dict(torch.load(path)['models'])model.eval()for (seq, target) in tqdm(Dte):y.extend(target)with torch.no_grad():y_pred = model(seq)pred.extend(y_pred)y, pred = np.array(y), np.array(pred)y = (m - n) * y + npred = (m - n) * pred + n# 出图x = [i for i in range(len(y))]x_smooth = np.linspace(np.min(x), np.max(x), 1000)y_smooth = make_interp_spline(x, y)(x_smooth)plt.plot(x_smooth, y_smooth, c='green', marker='*', ms=1, alpha=1, label='true')y_smooth = make_interp_spline(x, pred)(x_smooth)plt.plot(x_smooth, y_smooth, c='red', marker='o', ms=1, alpha=1, label='pred')plt.grid(axis='y')plt.legend()plt.show()
直接对比图:红色线为模型在测试数据集上的预测值,绿色线为真实的发生值。
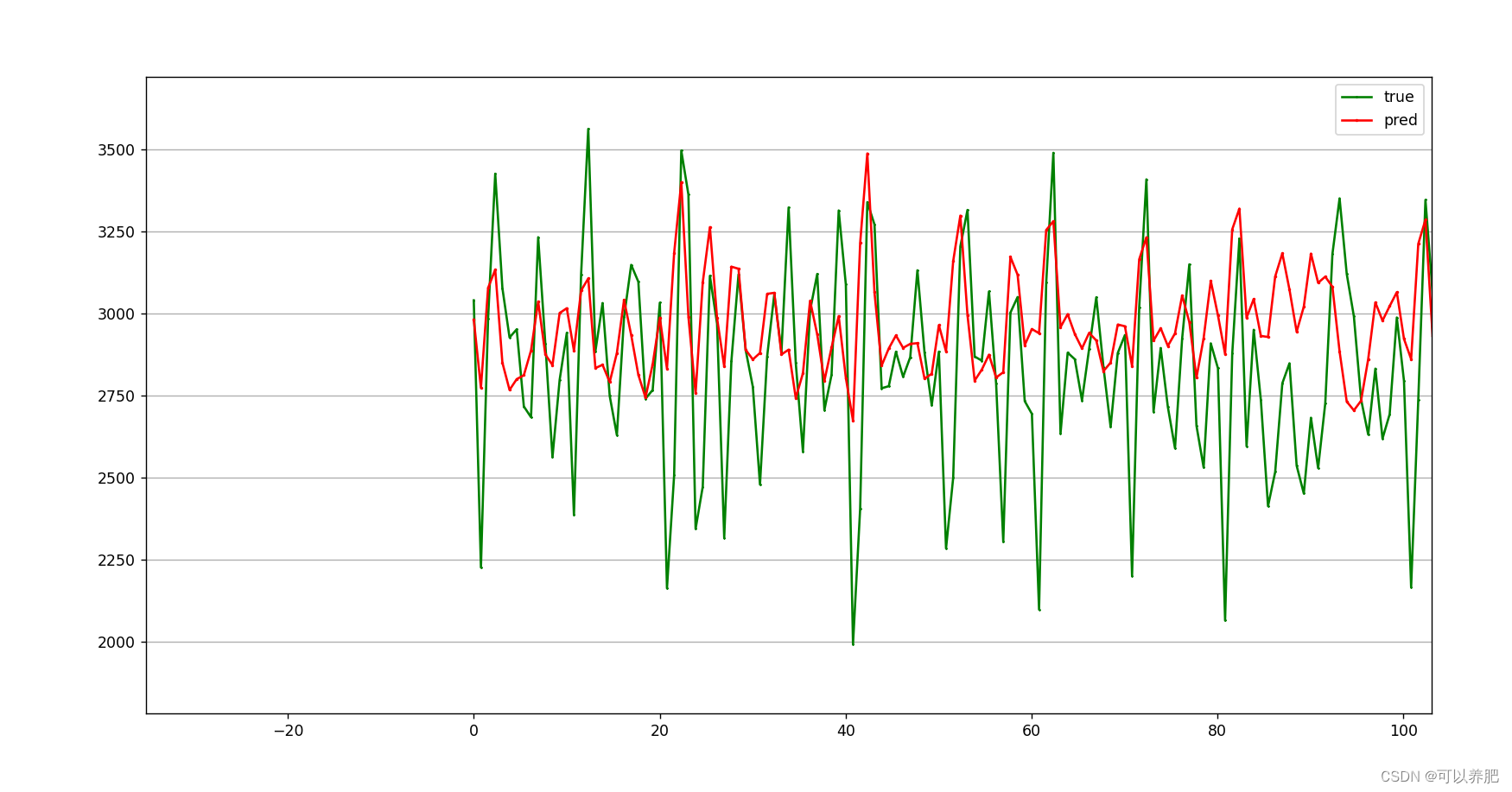
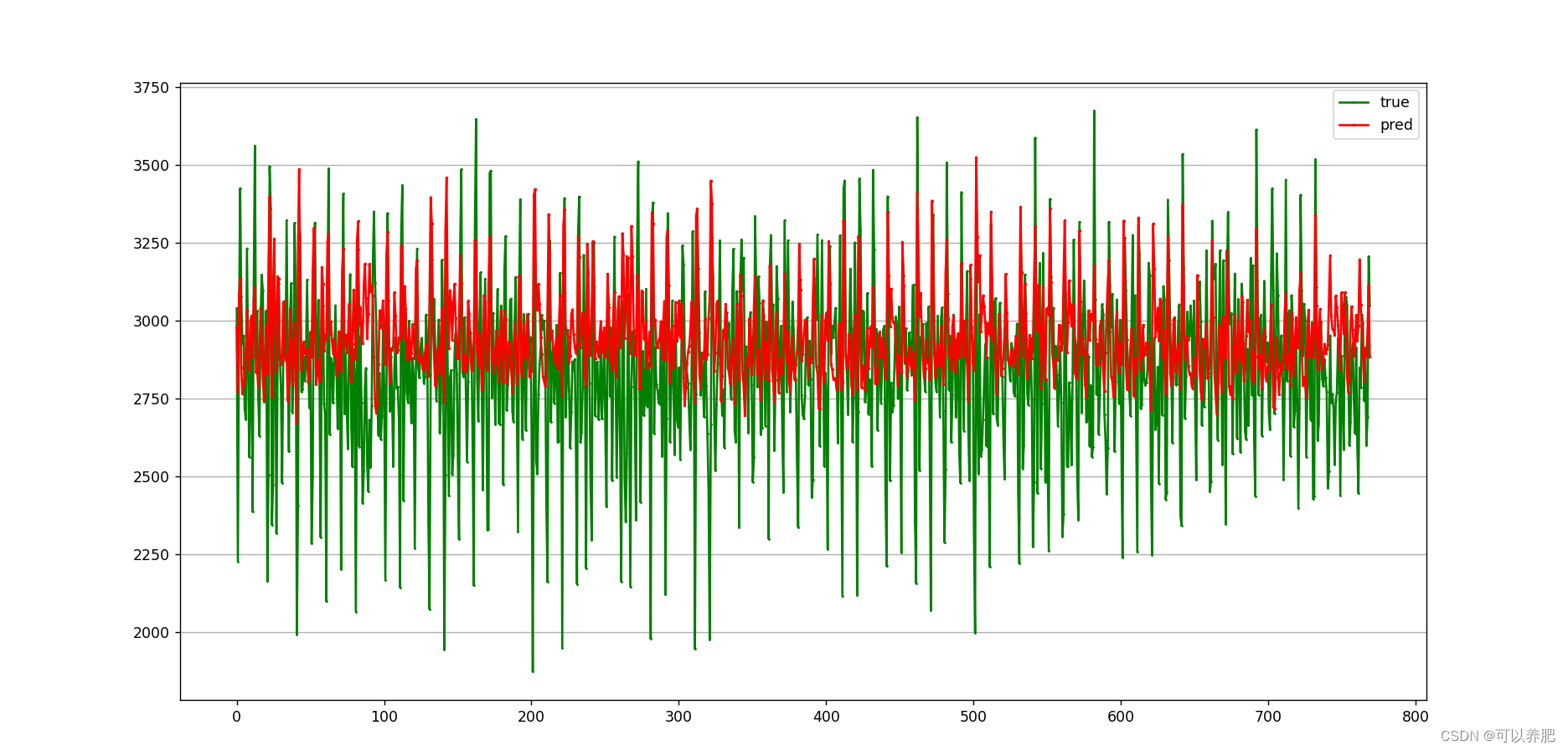 有点密密麻麻,我们可以看一下局部
有点密密麻麻,我们可以看一下局部
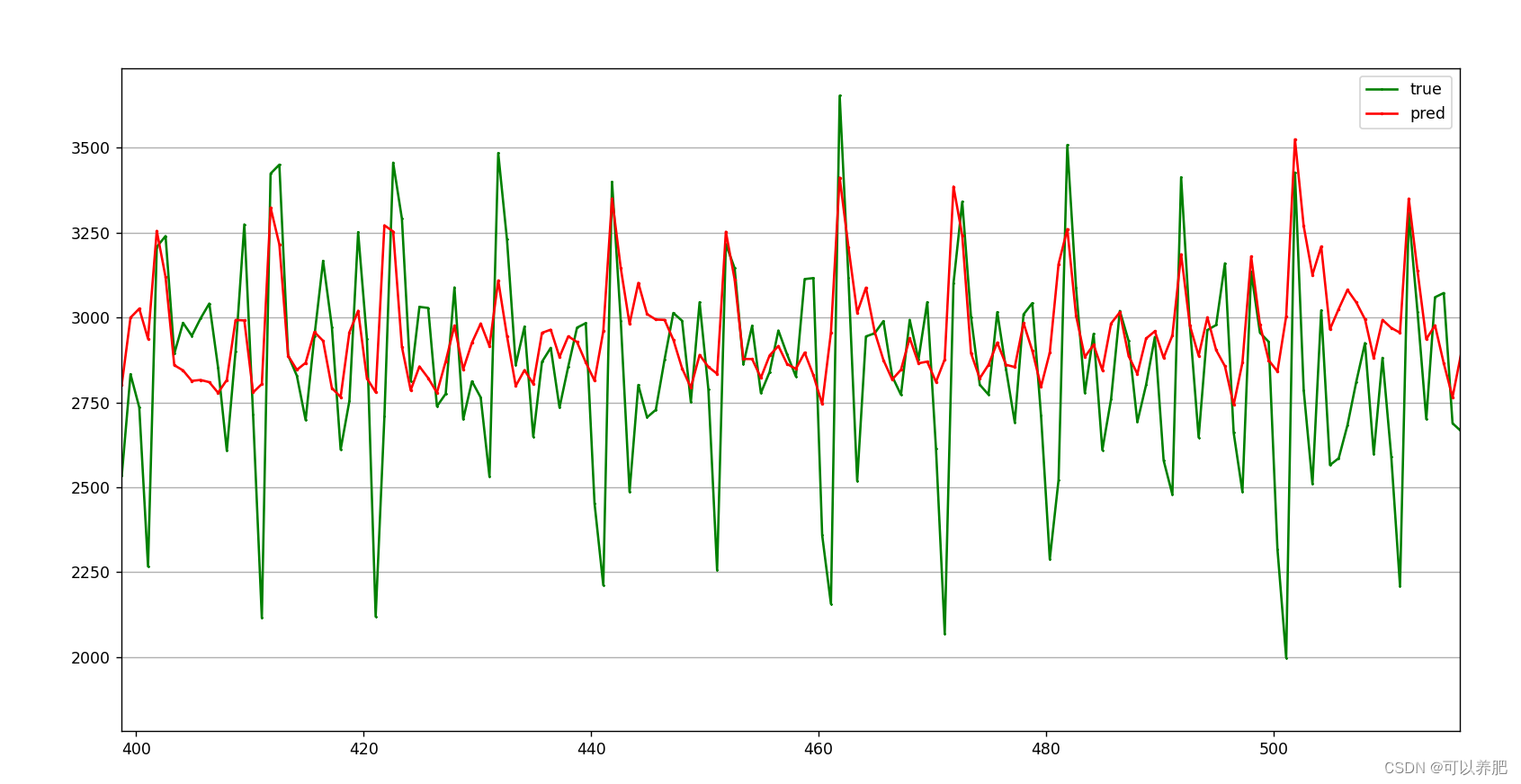 ⑤滚动测试30分钟内发生值,利用前90分钟的真实发生值预测第91分钟的发生值,再将第91分钟的发生值加入到输入中,预测第92分钟的发生值,以此类推,预测30分钟内的高炉煤气发生量。
⑤滚动测试30分钟内发生值,利用前90分钟的真实发生值预测第91分钟的发生值,再将第91分钟的发生值加入到输入中,预测第92分钟的发生值,以此类推,预测30分钟内的高炉煤气发生量。
def test_rolling(Dte, path, m, n):"""滚动测试,预测30条:param Dte 测试集:param path 模型:param m 最大值:param n 最小值"""pred = []y = []input_size = 1hidden_size = 128num_layers = 1output_size = 1model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=1)model.load_state_dict(torch.load(path)['models'])model.eval()i = 0 # 控制滚动预测的长度,这里计划通过前90分钟内的发生量预测后30分钟内的发生量for (seq, target) in tqdm(Dte):y.extend(target)with torch.no_grad():seq = seq.numpy().tolist()[0]seq.extend(pred) # 预测值追加到后面seq = seq[-90:] # 截取后90条数据,滚动预测seq = torch.tensor(seq).resize(1, 90, 1)y_pred = model(seq)pred.extend(y_pred)i = i + 1if i >= 30: # 控制滚动预测的长度,这里计划通过前90分钟内的发生量预测后30分钟内的发生量breaky, pred = np.array(y), np.array(pred)y = (m - n) * y + npred = (m - n) * pred + n# 出图x = [i for i in range(len(y))]x_smooth = np.linspace(np.min(x), np.max(x), 1000)y_smooth = make_interp_spline(x, y)(x_smooth)plt.plot(x_smooth, y_smooth, c='green', marker='*', ms=1, alpha=1, label='true')y_smooth = make_interp_spline(x, pred)(x_smooth)plt.plot(x_smooth, y_smooth, c='red', marker='o', ms=1, alpha=1, label='pred')plt.grid(axis='y')plt.legend()plt.show()出图
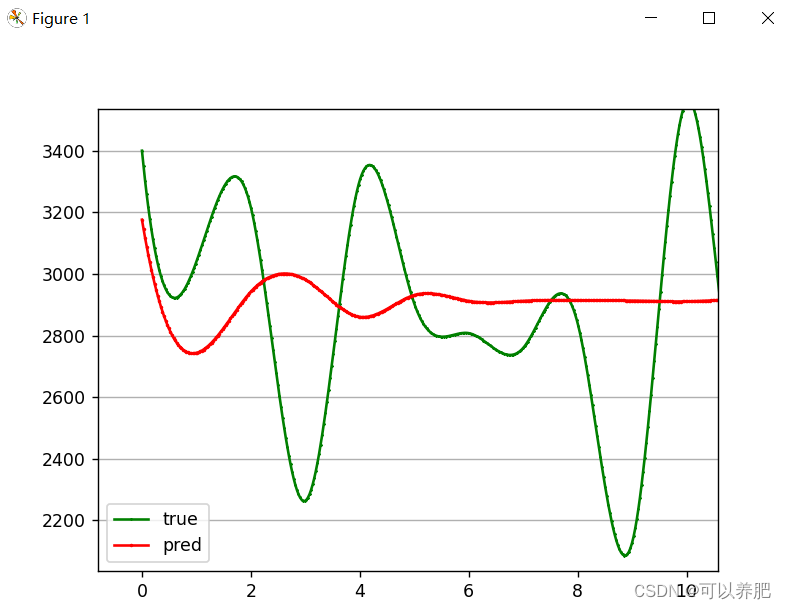 有点过分拟合
有点过分拟合
调整参数num_layers = 2 增加dropout=0.3 后
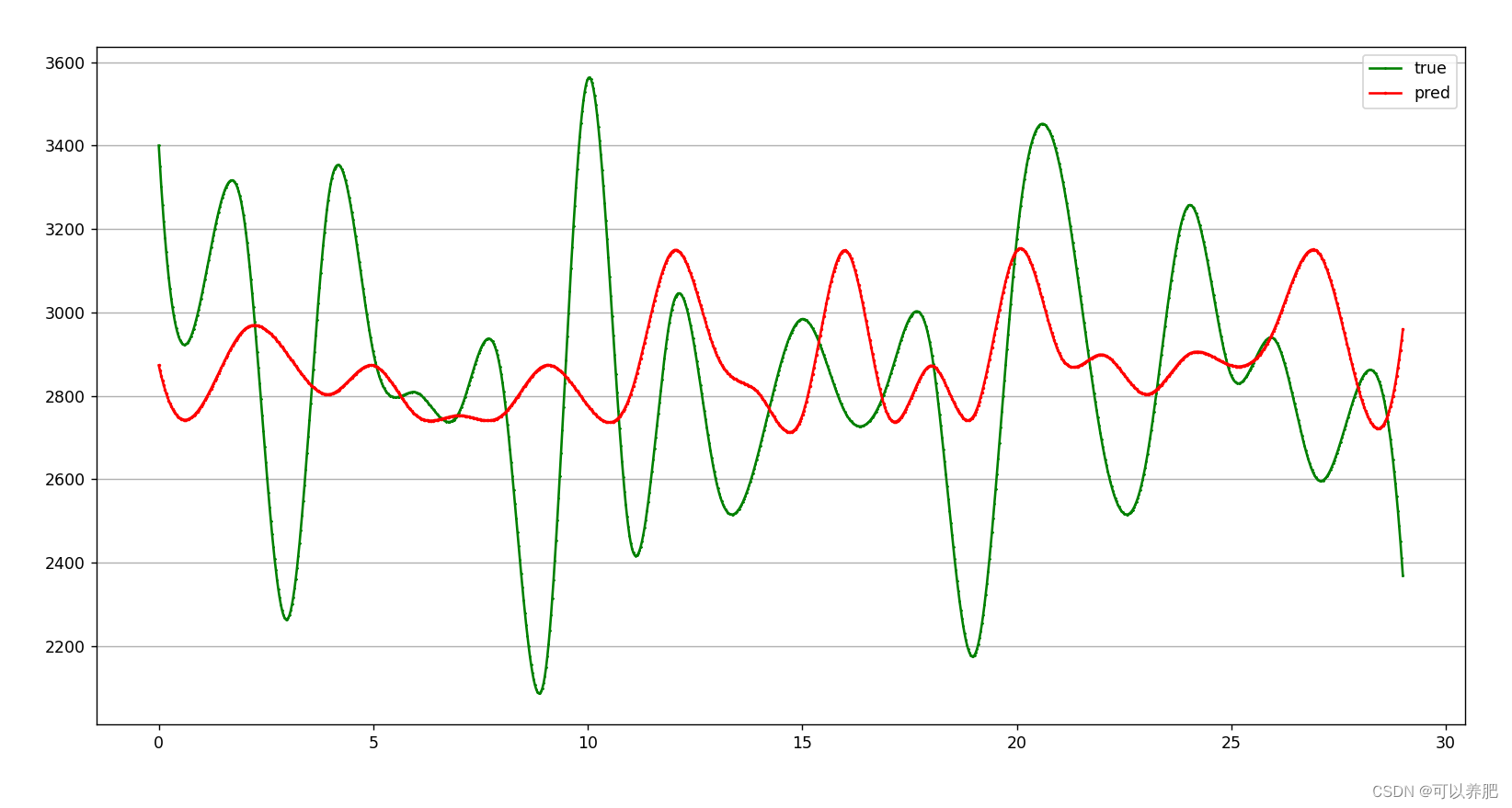 整体效果不是很理想,可能再调一下参会好一些。
整体效果不是很理想,可能再调一下参会好一些。
目前的完整代码如下:
import pandas as pd
import numpy as np
import torch
from matplotlib import pyplot as plt
from scipy.interpolate import make_interp_spline
from torch import nn
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader, TensorDataset
from tqdm import tqdmdef load_data(file_name):"""加载数据文件,原始数据文件为csv(通过1#高炉24小时内煤气发生量累计值,时间间隔为60000ms,计算出24小时内每分钟的发生量):param file_name csv文件的绝对路径:return 训练集、验证集、测试集、训练集中最大值、训练集中最小值训练集:验证集:测试集=3:1:1"""dataset = pd.read_csv('D:\\LIHAOWORK\\' + file_name, encoding='gbk')train = dataset[:int(len(dataset) * 0.6)]val = dataset[int(len(dataset) * 0.6):int(len(dataset) * 0.8)]test = dataset[int(len(dataset) * 0.8):len(dataset)]max, nin = np.max(train[train.columns[3]]), np.min(train[train.columns[3]]) # 分钟内发生量是csv中第四个字段return train, val, test, max, nindef process_data(data, batch_size, shuffle, m, n, k):"""数据处理:param data 待处理数据:param batch_size 批量大小:param shuffle 是否打乱:param m 最大值:param n 最小值:param k 序列长度:return 处理好的数据"""data_3 = data.iloc[0:, [3]].to_numpy().reshape(-1) #data_3 = data_3.tolist()data = data.values.tolist()data_3 = (data_3 - n) / (m - n)feature = []label = []for i in range(len(data) - k):train_seq = []train_label = []for j in range(i, i + k):x = [data_3[j]]train_seq.append(x)train_label.append(data_3[i + k])feature.append(train_seq)label.append(train_label)feature_tensor = torch.FloatTensor(feature)label_tensor = torch.FloatTensor(label)data = TensorDataset(feature_tensor, label_tensor)data_loader = DataLoader(dataset=data, batch_size=batch_size, shuffle=shuffle, num_workers=0, drop_last=True)return data_loaderclass LSTM(nn.Module):"""LSMT网络搭建"""def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):super().__init__()self.input_size = input_sizeself.hidden_size = hidden_sizeself.num_layers = num_layersself.output_size = output_sizeself.num_directions = 1 # 单向LSTMself.batch_size = batch_sizeself.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, dropout=0.3, batch_first=True)self.linear = nn.Linear(self.hidden_size, self.output_size)def forward(self, input_seq):batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size)c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size)output, _ = self.lstm(input_seq, (h_0, c_0))pred = self.linear(output)pred = pred[:, -1, :]return preddef train(Dtr, Val, path):"""训练:param Dtr 训练集:param Val 验证集:param path 模型保持路劲"""input_size = 1hidden_size = 128num_layers = 2output_size = 1epochs = 3model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=5)loss_function = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=1e-4)# optimizer = torch.optim.SGD(model.parameters(), lr=0.05, momentum=0.9, weight_decay=1e-4)scheduler = StepLR(optimizer, step_size=30, gamma=0.1)# start trainingfor epoch in tqdm(range(epochs)):train_loss = []for (seq, label) in Dtr:y_pred = model(seq)loss = loss_function(y_pred, label)train_loss.append(loss.item())optimizer.zero_grad()loss.backward()optimizer.step()scheduler.step()# validationmodel.eval()val_loss = []for seq, label in Val:y_pred = model(seq)loss = loss_function(y_pred, label)val_loss.append(loss.item())print('epoch {:03d} train_loss {:.8f} val_loss {:.8f}'.format(epoch, np.mean(train_loss), np.mean(val_loss)))model.train()state = {'models': model.state_dict()}torch.save(state, path)def test(Dte, path, m, n):"""测试:param Dte 测试集:param path 模型:param m 最大值:param n 最小值"""pred = []y = []input_size = 1hidden_size = 128num_layers = 2output_size = 1model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=5)model.load_state_dict(torch.load(path)['models'])model.eval()for (seq, target) in tqdm(Dte):y.extend(target)with torch.no_grad():y_pred = model(seq)pred.extend(y_pred)y, pred = np.array(y), np.array(pred)y = (m - n) * y + npred = (m - n) * pred + n# 出图x = [i for i in range(len(y))]x_smooth = np.linspace(np.min(x), np.max(x), 1000)y_smooth = make_interp_spline(x, y)(x_smooth)plt.plot(x_smooth, y_smooth, c='green', marker='*', ms=1, alpha=1, label='true')y_smooth = make_interp_spline(x, pred)(x_smooth)plt.plot(x_smooth, y_smooth, c='red', marker='o', ms=1, alpha=1, label='pred')plt.grid(axis='y')plt.legend()plt.show()def test_rolling(Dte, path, m, n):"""滚动测试,预测30条:param Dte 测试集:param path 模型:param m 最大值:param n 最小值"""pred = []y = []input_size = 1hidden_size = 128num_layers = 2output_size = 1model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=1)model.load_state_dict(torch.load(path)['models'])model.eval()i = 0 # 控制滚动预测的长度,这里计划通过前90分钟内的发生量预测后30分钟内的发生量for (seq, target) in tqdm(Dte):y.extend(target)with torch.no_grad():seq = seq.numpy().tolist()[0]seq.extend(pred) # 预测值追加到后面seq = seq[-90:] # 截取后90条数据,滚动预测seq = torch.tensor(seq).resize(1, 90, 1)y_pred = model(seq)pred.extend(y_pred)i = i + 1if i >= 30: # 控制滚动预测的长度,这里计划通过前90分钟内的发生量预测后30分钟内的发生量breaky, pred = np.array(y), np.array(pred)y = (m - n) * y + npred = (m - n) * pred + n# 出图x = [i for i in range(len(y))]x_smooth = np.linspace(np.min(x), np.max(x), 1000)y_smooth = make_interp_spline(x, y)(x_smooth)plt.plot(x_smooth, y_smooth, c='green', marker='*', ms=1, alpha=1, label='true')y_smooth = make_interp_spline(x, pred)(x_smooth)plt.plot(x_smooth, y_smooth, c='red', marker='o', ms=1, alpha=1, label='pred')plt.grid(axis='y')plt.legend()plt.show()if __name__ == '__main__':Dtr, Val, Dte, m, n = load_data("4.csv")Dtr = process_data(Dtr, 5, False, m, n, 90)Val = process_data(Val, 5, False, m, n, 90)#Dte = process_data(Dte, 5, False, m, n, 90)Dte = process_data(Dte, 1, False, m, n, 90)train(Dtr, Val, "D:\\LIHAOWORK\\model.pth")#test(Dte, "D:\\LIHAOWORK\\model.pth", m, n)test_rolling(Dte, "D:\\LIHAOWORK\\model.pth", m, n)相关文章:
工业数学模型——高炉煤气发生量预测(三)
1、工业场景 冶金过程中生产的各种煤气,例如高炉煤气、焦炉煤气、转炉煤气等。作为重要的副产品和二次能源,保证它们的梯级利用和减少放散是煤气能源平衡调控的一项紧迫任务,准确的预测煤气的发生量是实现煤气系统在线最优调控的前提。 2、…...
pnpm - Failed to resolve loader: cache-loader. You may need to install it.
起因 工作原因需要研究 vue-grid-layout 的源码,于是下载到本地。因为我习惯使用 pnpm,所以直接用 pnpm i 安装依赖,npm run serve 启动失败。折腾了一番没成功。 看到源码里有 yarn.lock,于是重新用 yarn install 安装依赖&…...
CSS transition和animation的用法和区别
Transition和Animation在CSS中都是用于实现元素状态变化的效果,但它们在用法和特性上存在明显的区别。 Transition transition是过度属性,主要强调的是元素状态的过渡效果。 它通常用于在元素的状态发生变化时,平滑地过渡到一个新的状态。…...
)
书籍推荐(附上每本书的看点)
1、《FPGA深度解析》,这本书的FIFO部分我觉得讲得很好; 2、《verilog数字系统设计教程》,夏宇闻老师的蓝皮书,这本书里包含很多考试知识点; 3、《SOC设计方法和实现》郭炜老师写的,我觉得他的低功耗设计讲得很好; 《高级FPGA设计结…...

LLM理解v1
答疑 什么是知识库? LLM(Large Language Models,大型语言模型)如GPT系列,通常是基于海量的文本数据进行训练的。它们通过分析和理解这些数据来生成回答、撰写文章、解决问题等。当我们提到LLM的“本地知识库”时&…...

ubuntu 22.04 -- cmake安装
安装方式一:源码安装 1、下载安装包 官网下载:下载链接:Download CMake 也可以使用命令行下载 wget https://github.com/Kitware/CMake/releases/download/v3.26.5/cmake-3.26.5.tar.gz2、解压并安装 # 1、解压 tar -zxvf cmake-3.26.5.…...
)
字符串算法题(第二十四天)
344. 反转字符串 题目 编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。 不要给另外的数组分配额外的空间,你必须**原地修改输入数组**、使用 O(1) 的额外空间解决这一问题。 示例 1: 输入࿱…...

【Linux】应用层协议序列化和反序列化
欢迎来到Cefler的博客😁 🕌博客主页:折纸花满衣 🏠个人专栏:题目解析 🌎推荐文章:C【智能指针】 前言 在正式代码开始前,会有一些前提知识引入 目录 👉🏻序列…...

使用Canal同步MySQL 8到ES中小白配置教程
🚀 使用Canal同步MySQL 8到ES中小白配置教程 🚀 文章目录 🚀 使用Canal同步MySQL 8到ES中小白配置教程 🚀**摘要****引言****正文**📘 第1章:初识Canal1.1 Canal概述1.2 工作原理解析 📘 第2章&…...
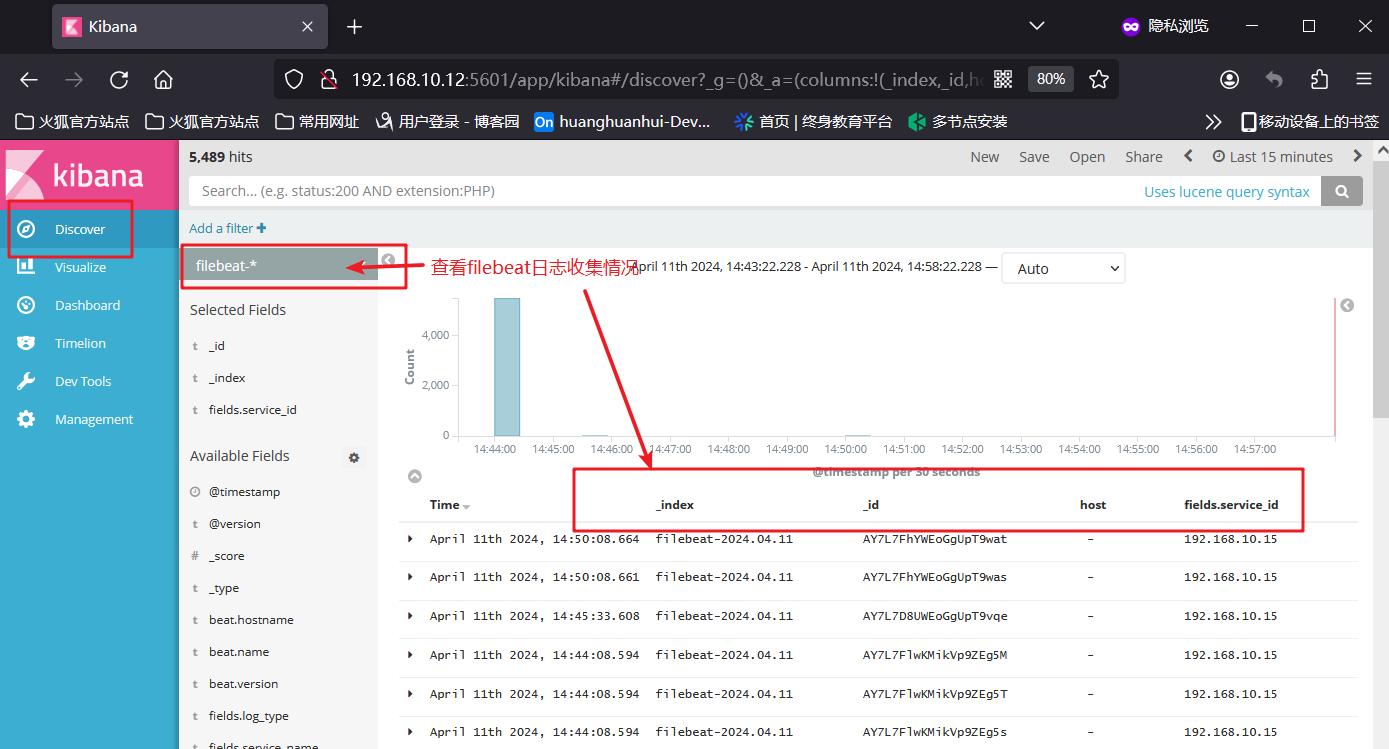
关于部署ELK和EFLK的相关知识
文章目录 一、ELK日志分析系统1、ELK简介1.2 ElasticSearch1.3 Logstash1.4 Kibana(展示数据可视化界面)1.5 Filebeat 2、使用ELK的原因3、完整日志系统的基本特征4、ELK的工作原理 二、部署ELK日志分析系统1、服务器配置2、关闭防火墙3、ELK ElasticSea…...
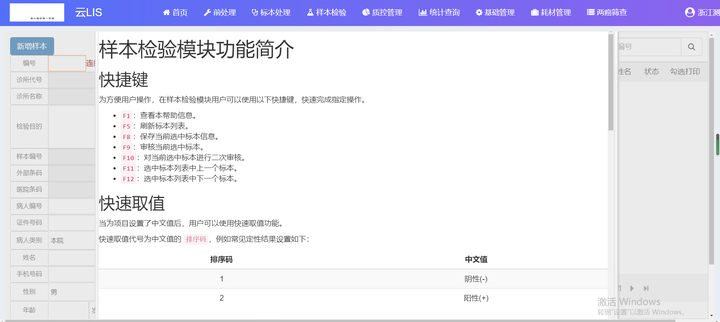
实验室信息系统源码 saas模式java+.Net Core版开发的云LIS系统全套源码可二次开发有演示
实验室信息系统源码 saas模式java.Net Core版开发的云LIS系统全套源码可二次开发有演示 一、技术框架 技术架构:Asp.NET CORE 3.1 MVC SQLserver Redis等 开发语言:C# 6.0、JavaScript 前端框架:JQuery、EasyUI、Bootstrap 后端框架&am…...
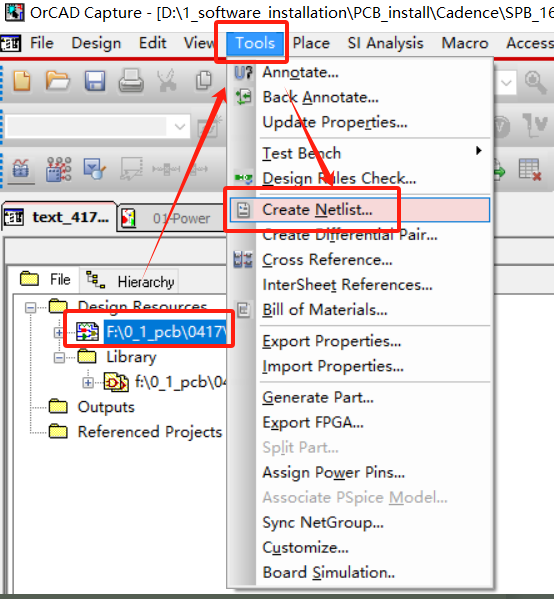
PCB---Design Entry cis 绘图 导出
修改纸张大小: 画图前准备:导入 画图: 习惯: 电源朝上 地朝下 配置pbc_footprint编号: 都配置好编号就可以导出了 导出:...

vue 一键更换主题颜色
这里提供简单的实现步骤,具体看自己怎么加到项目中 我展示的是vue2 vue3同理 在 App.vue 添加 入口处直接修改 #app { // 定义的全局修改颜色变量--themeColor:#008cff; } // 组件某些背景颜色需要跟着一起改变,其他也是同理 /deep/ .ant-btn-primar…...
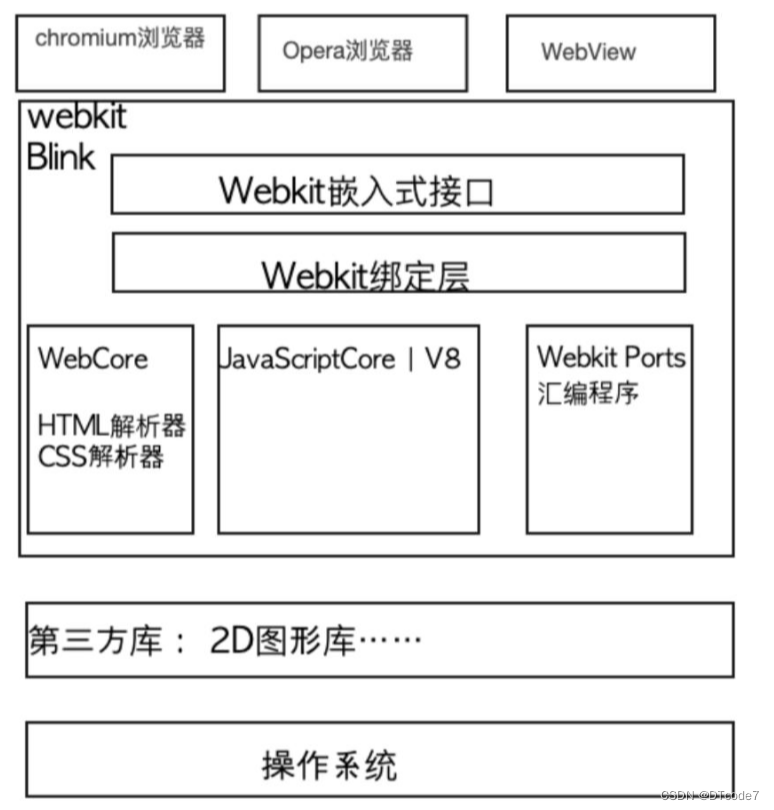
WebKit内核游览器
WebKit内核游览器 基础概念游览器引擎Chromium 浏览器架构Webkit 资源加载这里就不得不提到http超文本传输协议这个概念了: 游览器多线程HTML 解析总结 基础概念 百度百科介绍 WebKit 是一个开源的浏览器引擎,与之相对应的引擎有Gecko(Mozil…...
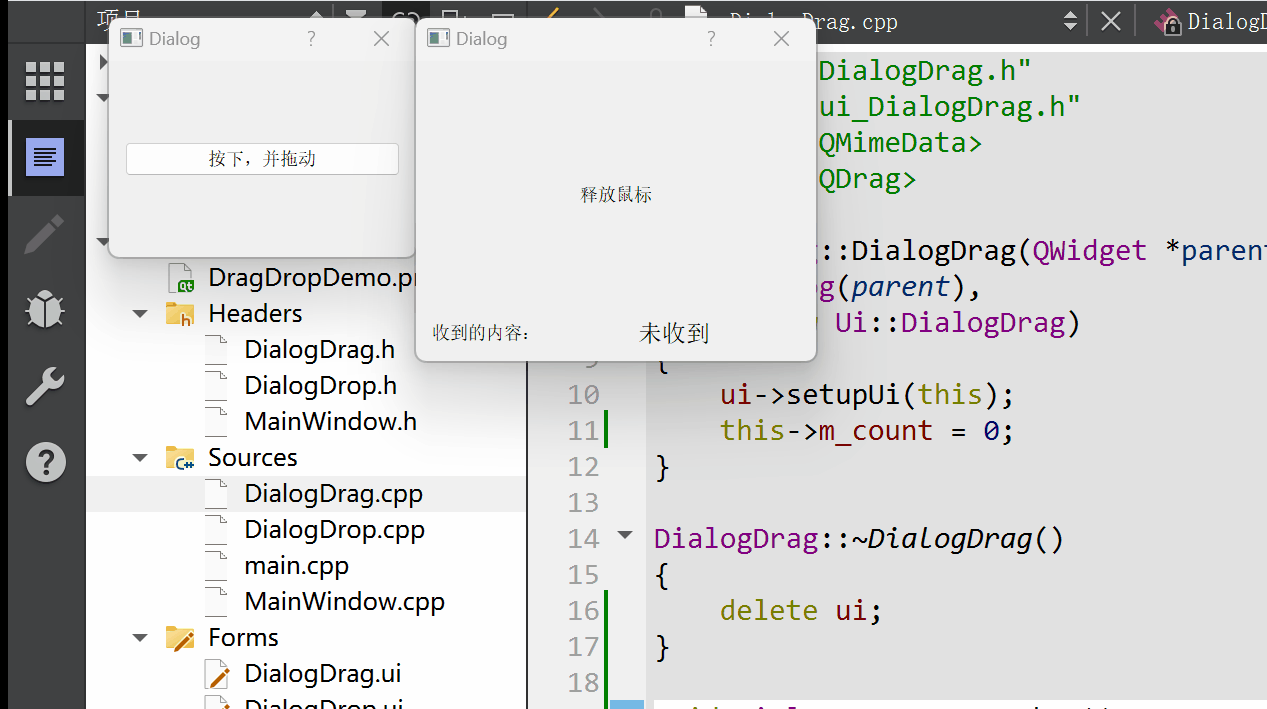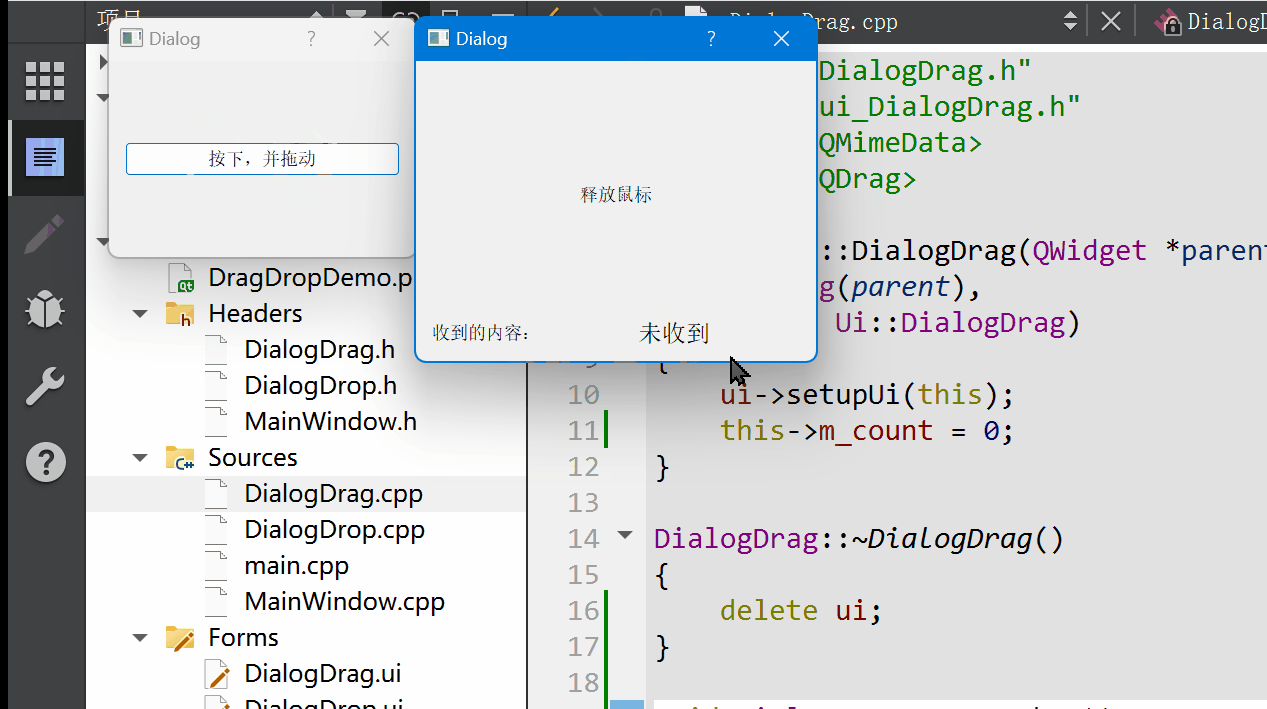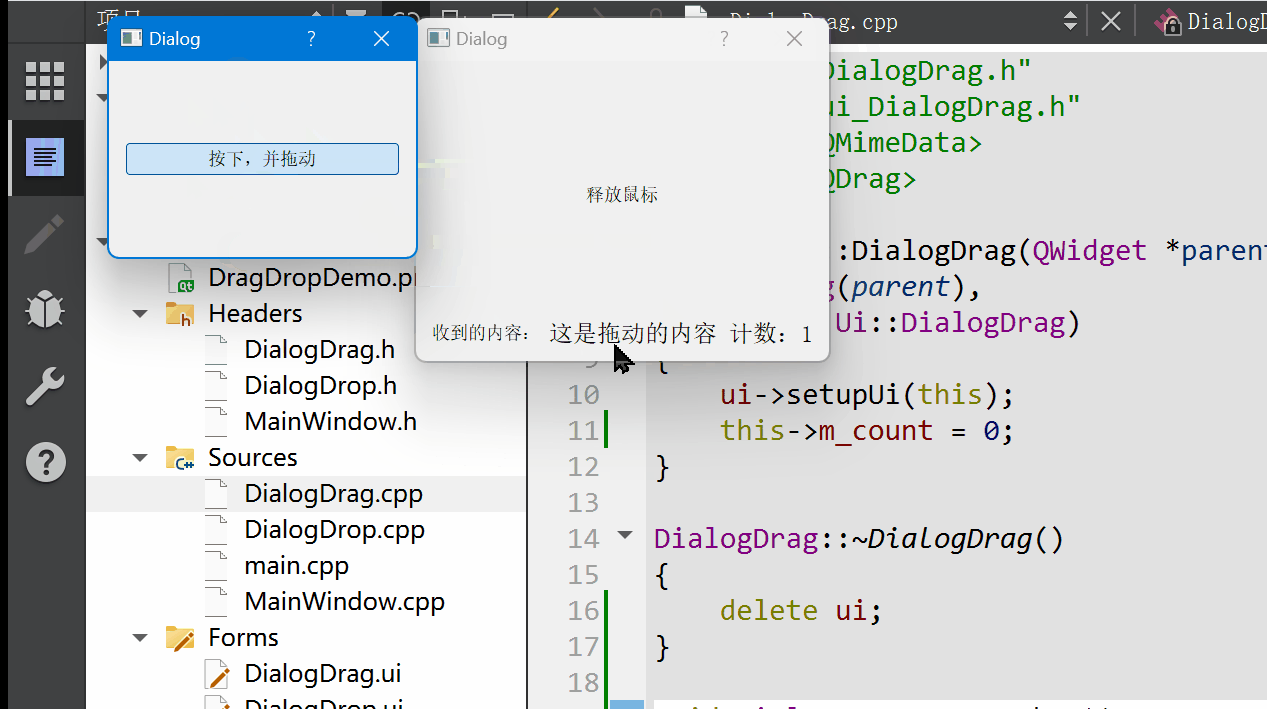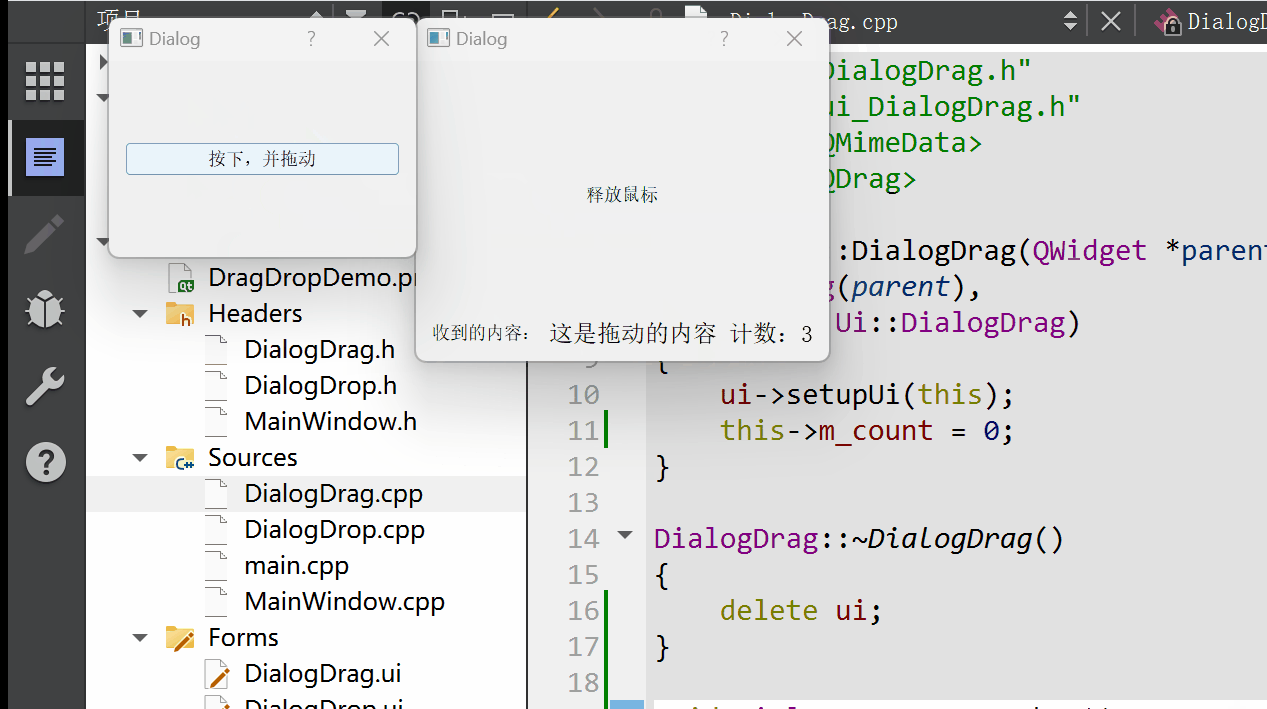
Qt 拖放功能详解:理论与实践并举的深度指南
拖放(Drag and Drop)作为一种直观且高效的用户交互方式,在现代图形用户界面中扮演着重要角色。Qt 框架提供了完善的拖放支持,允许开发者在应用程序中轻松实现这一功能。本篇博文将详细阐述Qt拖放机制的工作原理,结合详…...
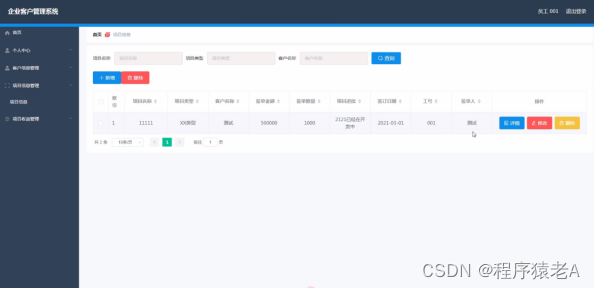
Springboot+Vue项目-基于Java+MySQL的企业客户管理系统(附源码+演示视频+LW)
大家好!我是程序猿老A,感谢您阅读本文,欢迎一键三连哦。 💞当前专栏:Java毕业设计 精彩专栏推荐👇🏻👇🏻👇🏻 🎀 Python毕业设计 &…...
【Linux学习】Linux指令(四)
文章标题 🚀zip/unzip指令:🚀tar指令(重要):🚀uname –r指令:🚀关机指令🚀几个常用操作 🚀zip/unzip指令: zip 与 unzip的安装 yum i…...
阿里云服务器 使用Certbot申请免费 HTTPS 证书及自动续期
前言 Certbot是一款免费且开源的自动化安全证书管理工具,由电子前沿基金会(EFF)开发和维护,是在Linux、Apache和Nginx服务器上配置和管理SSL/TLS证书的一种机制。Certbot可以自动完成域名的认证并安装证书。 一、 安装软件 1.1…...

统一SQL-number/decimal/dec/numeric转换
统一SQL介绍 https://www.light-pg.com/docs/LTSQL/current/index.html 源和目标 源数据库:Oracle 目标数据库:Postgresql,TDSQL-MySQL,达梦8,LightDB-Oracle 操作目标 通过统一SQL,将Oracle中的numb…...
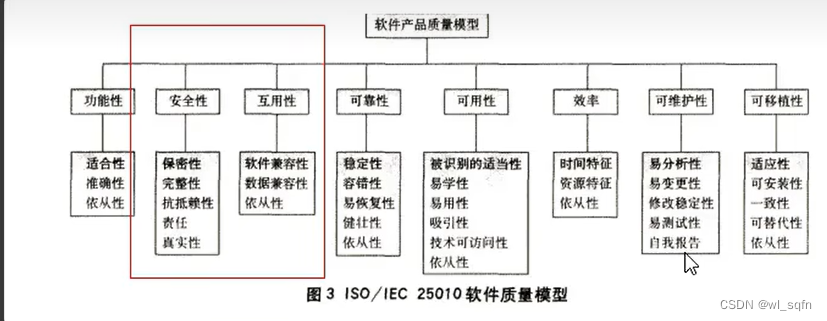
软件测试入门学习笔记
系统测试流程规范 一.研发模型 1.瀑布模型 从可行性研究(或系统分析)开始,需求 2.增量迭代模型 3.敏捷开发模型 二.质量模型...

淘宝商品详情 API 实现标题 / SKU / 主图批量采集
item_get_pro-获得淘宝商品详情高级版请求示例-- 请求示例 url 默认请求参数已经URL编码处理 curl -i "https://api-服务器.cn/taobao/item_get_pro/?key<您自己的apiKey>&secret<您自己的apiSecret>&num_iid678121631641"响应示例"num_ii…...

抖音下载器终极指南:3分钟实现无水印批量下载的高效解决方案
抖音下载器终极指南:3分钟实现无水印批量下载的高效解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback…...
自动对齐结构孔)
从CAD到PCB的‘神同步’:利用Altium Designer图层映射,让你的丝印层(Top Overlay)自动对齐结构孔
从CAD到PCB的‘神同步’:Altium Designer图层映射实战指南 在消费电子和嵌入式设备开发中,PCB与外壳结构的精确对齐常常成为产品落地的最后一道障碍。想象一下:当结构工程师更新了智能手表外壳的3D模型,新增了螺丝孔位和屏幕开口&…...

Windows 11任务栏拖放功能终极修复指南:3步恢复高效操作体验
Windows 11任务栏拖放功能终极修复指南:3步恢复高效操作体验 【免费下载链接】Windows11DragAndDropToTaskbarFix "Windows 11 Drag & Drop to the Taskbar (Fix)" fixes the missing "Drag & Drop to the Taskbar" support in Windows…...

Windows运行Android应用终极指南:APK Installer让你的电脑秒变安卓手机
Windows运行Android应用终极指南:APK Installer让你的电脑秒变安卓手机 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在移动应用生态日益丰富的今天&…...

Vitis HLS里给LED闪烁函数‘打标签’:深入解读ap_hs与ap_none协议的选择与实战影响
Vitis HLS中LED闪烁函数接口协议深度解析:ap_hs与ap_none的硬件实现差异与工程选择 在FPGA开发中,Vitis HLS作为高级综合工具,能够将C代码转换为可综合的硬件描述语言。然而,许多开发者在使用过程中常常忽略一个关键细节——函数…...

在Nodejs后端服务中集成Taotoken实现稳定可靠的大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成Taotoken实现稳定可靠的大模型调用 将大模型能力集成到后端服务是现代应用开发的常见需求。对于Node.js开发…...

终极百度网盘加速解决方案:BaiduPCS-Web完整使用指南
终极百度网盘加速解决方案:BaiduPCS-Web完整使用指南 【免费下载链接】baidupcs-web 项目地址: https://gitcode.com/gh_mirrors/ba/baidupcs-web 还在为百度网盘那令人抓狂的下载速度而烦恼吗?当下载进度条像蜗牛一样缓慢移动时,你是…...
)
CES效用函数保姆级解析:从公式推导到Python代码实现(附替代弹性计算)
CES效用函数实战指南:从数学本质到Python可视化 在经济学建模和金融工程领域,CES(Constant Elasticity of Substitution)效用函数就像一把瑞士军刀——它不仅能描述消费者偏好,还能通过调整参数δ来模拟完全替代、Cobb…...

从平面到立体:ImageToSTL如何让任何图片在3分钟内变成立体可打印模型
从平面到立体:ImageToSTL如何让任何图片在3分钟内变成立体可打印模型 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from t…...