扩展学习|一文读懂知识图谱
一、知识图谱的技术实现流程及相关应用
文献来源:曹倩,赵一鸣.知识图谱的技术实现流程及相关应用[J].情报理论与实践,2015, 38(12):127-132.
(一)知识图谱的特征及功能
知识图谱是为了适应新的网络信息环境而产生的一种语义知识组织和服务的方法,通过把用户查询的关键词映射到语义知识库的概念上,使计算机能够理解人类的语言交流模式,从而更加智能地反馈给用户需要的答案。知识库是知识图谱的核心,采用某种知识表示方式来存储管理互相关联的知识片集合,它必须包含丰富的数据,数据来源于原有的关系型数据库、LOD中的部分关联数据集、 领域本体、用户数据、从半结构化和非结构的数据内容中抽取出的理论知识、事实数据、启发式知识等。知识库是服从于本体控制的知识单元的载体,覆盖了各种概念、实例、属性、关系等要素,并保持高效率地更新,以便随时满足用户的知识需求。以谷歌知识图谱为例,它在2012年5月发布时已包含5亿多的对象实体和关于这些实体的超过35亿的事实关系,仅仅6个月后,实体数量增长到5. 7亿,事实关系增长到180亿,到目前为止,还在不断地更新扩展。
知识图谱的功能主要体现在知识组织、展示与搜索方面: 第一,给用户提供正确的理想答案,在一定程度上克服自然语言的歧义性; 第二,通过信息元侧边栏,把经过梳理、总结的知识提供给用户; 第三,通过信息推荐, 提供更深入更广阔的知识,知识图谱尝试通过对其他用户相关的搜索记录进行推理,帮助用户在提问之前就回答出下一个问题,激发用户对知识的搜索兴趣,从而进行一次全新的查询操作。
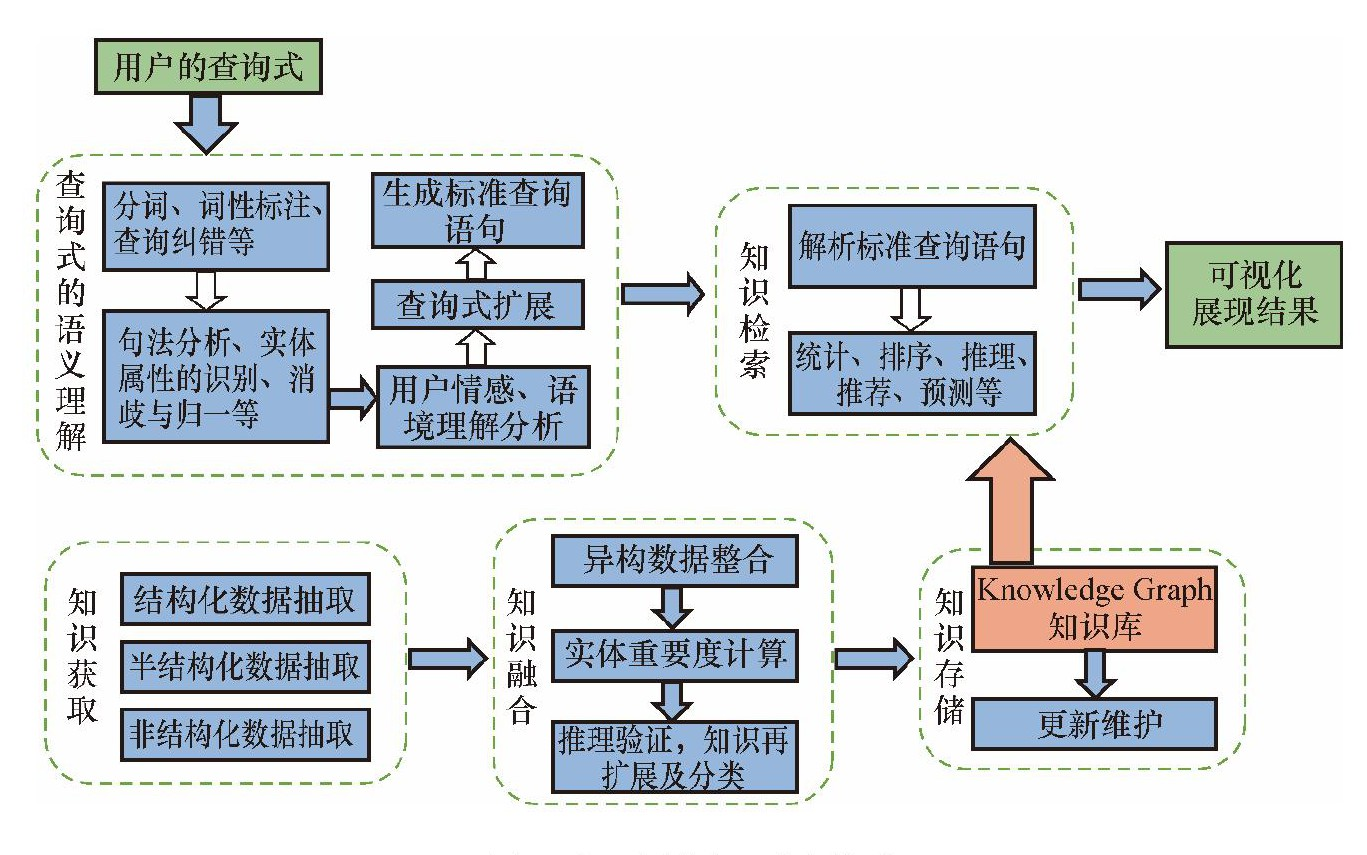
(二)知识图谱的实现流程及关键技术
知识图谱的实现流程可总结为6个模块,即知识获取、知识融合、知识存储、查询式的语义理解、知识检索和可视化展现,见图1。其中知识库的构建是知识图谱实现的核心,知识库中存储的内容需要经过广泛的知识获取及充分的知识融合,当用户进行查询检索时,用户的自然语言查询式经过语义分析处理后进入检索系统,和知识库中的内容进行匹配,整合后的反馈结果以可视化的形式展现给用户。
1.知识获取
为了提高知识服务的质量,提供用户满意的答案,知识图谱不仅要包含各个领域的常识性知识,还要及时发现并添加新知识,知识的数量和质量决定了其所能提供的知识服务的广度和深度以及解决问题的能力,因此知识图谱的构建需要以高效的知识获取作为支撑。
常识性知识的获取主要来自百科类站点和各种垂直站点的结构化数据,如从DBpedia中抽取某一主题的知识, 根据一定的抽取策略提取出领域相关的事实,包括主题下的细分知识以及扩展的相关类别知识等。同时还要从一些半结构化和非结构化数据中抽取实例和属性来丰富相关实体的描述。
随着用户交互大量涌现,用户生成内容( UGC)不断增加,大量用户投入到网络信息的创建、组织和传播中,这其中产生的一些知识也是知识图谱知识获取中重要的一方面。新知识可以从用户的查询日志中发现新的实体属性,不断地扩展知识的覆盖率。此外,由于知识图谱要根据用户的兴趣提供相关的知识推荐,所以用户相关的行为数据也要抽取,包括用户所在的国家,能确定用户身份的信息、查询语句使用的语言、 查询时间、以往的访问日志数据等。例如在用户查询过程中可以分析用户的兴趣: 根据用户筛选后点击的链接,以及 “长点击”与 “短点击”判断用户对答案的满意度及感兴趣程度,从而获得用户行为数据, 也可以根据这些数据抽取对应的实体。
知识获取实现的主要技术包括机器学习、知识挖掘、自然语言处理、基于内在机理的知识发现技术等。在大数据环境下,智能化的数据抽取、提炼与挖掘技术显得尤为重要,大量的知识资源为后续的知识推理融合奠定了坚实的基础。
2.知识融合
由于知识图谱中的知识来源广,存在知识质量良莠不齐、来自不同数据源的知识重复、知识间的关联不够明确等问题,所以必须要进行知识的融合。知识融合是高层次的知识组织,使来自不同知识源的知识在同一框架规范下进行异构数据整合、实体重要度计算和推理验证等步骤,达到数据、信息、方法、经验以及人的思想的融合。
异构数据整合要进行数据清洗、实体对齐、属性值决策以及关系的建立。数据清洗包括对拼写错误的数据、相似重复数据、孤立数据、数据时间粒度不一致等问题进行处理; 实体对齐解决来自不同数据源的相同实体中对同一特性的描述、格式等方面不一致的问题,对实体描述方式和格式进行规范统一,如 “籍贯”与 “出生地” 的表述差别,日期书写格式的不同等; 属性值决策主要是针对同一属性出现不同值的情况下,根据数据来源的数量和可靠度进行抉择,提炼出较为准确的属性值; 关系是知识图谱中非常重要的知识,任何实体概念都不是孤立的,都处在和周围概念一定的逻辑关系中,如等同关系、属分关系和相关关系等。从本质上看,知识图谱建立关系的过程可以简化为相关实体挖掘,即寻找用户类似查询中共现的实体或是在同一个查询中被提到的其他实体,通过对链接的提取统计以及对用户查询日志的分析,发掘查询式的主题分布,把同一主题中的相关实体进行类型验证并建立关联。
实体的重要度主要通过Page Rank等算法进行计算, 实体属性和实体间的关系、不同实体和语义关系的流行程度、抽取的置信度等都会影响实体重要度计算的结果。 用户查询式中的实体被识别后,关于该实体的结构化摘要就会展现给用户,当查询涉及多个实体时,就需要选择与查询更相关且更重要的实体展现出来。如查询 “李娜”, 同名实体有超过20个,就要根据重要度的计算对这些实体进行排序。
推理的规则一般涉及两类,针对属性和针对关系的。 通过推理验证可以检测逻辑矛盾,提高知识质量; 也可以获取属性值和实体间隐含的关系,从而建立更多实体间的关联。通过推理形成新的数据对知识进行再扩展,提高知识的完整性,并通过知识的聚合、分类等技术把知识具体化和分类整合。
3.知识存储
知识图谱中的知识存储在它的知识库中,是一个规模庞大的关联集合。杂乱的信息经过前期的融合与处理,形成了有序、关联可用的知识,按照知识的类别以规范化的形式分类存储在知识库中不同的知识模块里,生成索引, 以便在知识检索时更加智能有效地匹配以及进行知识的深度挖掘。
知识库中知识节点和节点间映射关系的数目是庞大的,并且在不断增长。另外,知识库中的知识与规则要保证及时的更新、纠错与维护,一些知识会长期存储保留, 而一些时效较短的知识就要及时删除或修改,知识的变化还会打乱其内部像网络一样的关联关系,这给知识存储带来了很大的挑战。因此,知识图谱中的知识依赖合适的存储介质和合理的存储方式进行有效存储,既保证知识的可读性和稳定性,又不影响系统运行效率和对数据的操纵管理能力。知识库中知识的更新修订遵守一定的原则, 使得新知识的加入与老知识的更新不会引起知识库结构发生变化,修改后的知识库不应该依赖原始知识库或新公式的语法形式,同时要保持知识表达的充足性和连贯一致性,新知识应该尽可能多地被接受,而许多老知识也应该尽量保持,这样更有利于知识库大量吸收并储备各方面的知识。
总之,知识图谱的知识存储依赖于海量数据存储技术来管理大规模分布式的数据,以实现海量存储系统大容量、可扩展、高可靠性和高性能的要求。
4.查询式的语义理解
用户的查询式一般可分为4种: 定义型,如 “什么是知识组织”; 事实型,如 “Knowledge Graph的出现时间”;肯定否定型,如 “Tim Berners-Lee是万维网之父吗”; 意见型,如 “如何看待大数据时代”。针对用户不同的查询式问题,经过自然语言处理,可以根据以上类型大致归类,系统分类理解查询式,方便答案的反馈。
知识图谱中对查询式的语义分析包括以下几个关键步骤: 1对查询式进行分词、词性标注和查询纠错。
2对句法进行分析,基于一些通用词典和本体库等实现实体识别,同时对实体进行过滤和消歧; 基于模式挖掘实现属性识别,对实体属性进行归一处理。因为用户的表达方式不一样,不同用户对实体、属性等都有不同的描述方式,因而对不同的描述进行归一,进而和知识库中的相关知识匹配。
3用户情感及语境的理解分析,在不同语境下用户查询式中的实体会有差别,知识图谱要识别用户的情感,以反馈用户此刻需要的答案。
4查询式扩展,明确了查询的确切所指以及用户的信息意图后,加入与其语义相关的其他概念来实施扩展。查询式语义分析后会生成标准查询语句,以SPARQL为代表,SPARQL查询语句是基于模板匹配的一种标准化的格式,可以与知识库中的知识更好地衔接; 另外,它还是基于需求重要度排序后的查询语句,反馈的知识结果会展现出优先顺序。
查询式的语义理解涉及的相关技术主要包括自然语言处理技术和人工智能等。
5.知识检索
知识检索是基于之前的知识组织体系,实现知识关联和概念语义检索的智能化检索方式。知识图谱中的知识检索包含两类核心任务: 一是利用相关性在知识库中找到相应的实体; 二是在此基础上根据实体的类别、关系及相关性等信息找到关联的实体。
用户输入的查询式经过语义分析理解后生成的标准查询语句进入检索系统后被解析,与知识库中的知识匹配, 并进行统计、排序、推理、推荐、预测等工作。系统会基于对查询词表达的概念和语义内涵的深度理解作为搜索依据,同时对该词的同义词、近义词、广义词、狭义词检索,进行概念的扩充,扩大检索,避免漏检; 另外,还会进行相关概念的联想检索,做好推荐预测的工作。通过对知识库进行深层次的知识挖掘与提炼后,检索系统为用户反馈出具有重要性排序的准确且完整的知识,并推荐用户可能感兴趣的相关知识。
知识检索阶段涉及信息检索、知识挖掘等关键技术, 比如相似性、重要性计算。
6.可视化展现
知识图谱可视化的结果展现提升了用户的使用体验,它将知识库中的信息转化为更方便用户理解的方式进行呈现,通常整合为简洁明了的内容放在一个信息栏中,用户可以一目了然地了解到他需要的知识,快速解答疑惑; 同时提供了更加丰富的富文本信息,除文字外还有图片、列表等可以直接消费的形式,增加了更多的用户交互元素,提升用户体验,如图片浏览、点击试听等,引导用户在短时间内获取到更多的知识。例如,在百度中搜索 “十大元帅”,信息栏中既有文字的介绍,还有每一位元帅的照片; 搜索 “周星驰和吴孟达的电影”,信息栏中整合了所有符合条件的电影结果,还可以按照类型、地区、 年代、最新、最热、用户好评等标签缩小搜索范围,帮助用户快速锁定目标; 在搜狗搜索中输入 “梁启超儿子的太太的好友”,信息栏中简洁地给出答案: 泰戈尔和金岳霖,并配有他们的照片,另外还显示了问题答案的推理说明。
知识图谱可视化的展现不仅注重答案的精准,注重内容显示粒度上的把握,还关注页面中显示的位置、知识模块位置的安排等细节,还考虑了在智能手机和平板电脑等多种设备上显示的效果等问题。需要涉及Web客户端技术、可视化技术、人机交互等技术来帮助用户实现高效答案获取和知识学习。
二、知识组织研究现状
文献来源:司莉,何依,郭晓彤.国外知识组织研究主题、特征及思考[J].情报资料工作,2024,45(01):12-22.
知识组织的探索从古希腊柏拉图、亚里士多德开始,一直伴随着人类文明史发展的整个过程。其发展不仅是内部变革使然,也是外部技术驱动的结果。本文从理论视角全方位、系统性探索了新科技浪潮对KO的影响,深入揭示国外KO研究主题、研究方法及领域应用的特征。研究结果发现,过去二十年间KO研究主题持续深入细化,关注点从概念理论等表层问题转向核心价值、伦理道德、质量评估、教学培训等深层问题的探讨,方法体系从面向纸质文献的书目描述、分类标引到面向多源异构多模态资源的语义关联,技术手段从依赖于专家人工操作到辅以众包及自动化技术,不断得到继承与发展。研究方法形成“实践-理论-实践”的发展路径,实证研究逐渐成为主流。应用范围从图书情报向生物医学、教育法学等领域扩展,且呈现向药物安全监测、课程建模管理、新闻浏览等特定场景发展的趋势。鉴于此,我国可在教学培训、理论和实践应用方面进一步拓展KO疆域,包括:建立合理的评估体系,重视KO质量;关注中文数据基础设施建设,推动语义化、关联化进程;从实证研究出发,关注领域知识组织研究,促进研究成果转化;“群体+技术+专家”三轮驱动,加快海量数据的组织;扩展特定领域应用实践,提升KO服务水平;更新教学内容,优化理论基础课与实践进阶课,培养伦理道德、跨文化意识。
相关文章:
扩展学习|一文读懂知识图谱
一、知识图谱的技术实现流程及相关应用 文献来源:曹倩,赵一鸣.知识图谱的技术实现流程及相关应用[J].情报理论与实践,2015, 38(12):127-132. (一)知识图谱的特征及功能 知识图谱是为了适应新的网络信息环境而产生的一种语义知识组织和服务的方…...
ubuntu中的docker记录(3)——如何安装nvidia-docker以更好地支持GPU加速计算应用程序的运行
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、nvidia-docker2的安装1. 安装docker2. 安装nvidia-docker2(1) 添加密钥(2) 更新软件列表(3) 安装nvidia-docker2(4) 测试nvidia-docker2 二、可能的报错及解…...

MLP实现fashion_mnist数据集分类(1)-模型构建、训练、保存与加载(tensorflow)
1、查看tensorflow版本 import tensorflow as tfprint(Tensorflow Version:{}.format(tf.__version__)) print(tf.config.list_physical_devices())2、fashion_mnist数据集下载与展示 (train_image,train_label),(test_image,test_label) tf.keras.datasets.fashion_mnist.l…...

ChatGPT-税收支持新质生产力
Prompt: 税收发展助力新质生产力 Response: 是的,税收发展可以促进新质生产力的发展。通过税收政策的调整和优化,政府可以提供更好的创新环境,激发企业投资研发,推动新技术、新产品的出现,从而推动经济结构升级和新…...

Linux下深度学习虚拟环境的搭建与模型训练
在深度学习实践中,环境配置是十分重要且免不了的一步。本文以 YOLOv4 模型,介绍在Linux下虚拟环境配置到模型训练的过程。 安装Miniconda: Miniconda是Anaconda的一个轻量级版本,非常适合用于科学计算和数据处理。 wget https:…...

Map-Reduce是个什么东东?
MapReduce是一种用于使用并行分布式算法在集群计算机上处理大型数据集的编程模型及其相关实现。这一概念首先由Google普及,并随后作为Apache Hadoop项目的一部分开源发布。 MapReduce的基本工作流程: 映射(Mapping):这是第一阶段,…...

上位机工作感想-从C#到Qt的转变-2
2.技术总结 语言方面 最大收获就是掌握了C Qt编程,自己也是粗看了一遍《深入理解计算机系统》,大致了解了计算机基本组成、虚拟内存、缓存命中率等基基础知识,那本书确实有的部分看起来很吃力,等这段时间忙完再研读一遍。对于封装…...
)
【C++】C++ 中 的 lambda 表达式(匿名函数)
C11 引入的匿名函数,通常被称为 Lambda 函数,是语言的一个重要增强,它允许程序员在运行时创建简洁的、一次性使用的函数对象。Lambda 函数的主要特点是它们没有名称,但可以捕获周围作用域中的变量,这使得它们非常适合在…...
OpenSSL实现AES-CBC加解密,可一次性加解密任意长度的明文字符串或字节流(QT C++环境)
本篇博文讲述如何在Qt C的环境中使用OpenSSL实现AES-CBC-Pkcs7加/解密,可以一次性加解密一个任意长度的明文字符串或者字节流,但不适合分段读取加解密的(例如,一个4GB的大型文件需要加解密,要分段读取,每次…...

cURL:命令行下的网络工具
序言 在当今互联网时代,我们经常需要与远程服务器通信,获取数据、发送请求或下载文件。在这些情况下,cURL 是一个强大而灵活的工具,它允许我们通过命令行进行各种类型的网络交互。本文将深入探讨 cURL 的基本用法以及一些高级功能…...
)
Baumer工业相机堡盟工业相机如何通过NEOAPISDK查询和轮询相机设备事件函数(C#)
Baumer工业相机堡盟工业相机如何通过NEOAPISDK查询和轮询相机设备事件函数(C#) Baumer工业相机Baumer工业相机NEOAPI SDK和相机设备事件的技术背景Baumer工业相机通过NEOAPISDK在相机中查询和轮询相机设备事件函数功能1.引用合适的类文件2.通过NEOAPISDK…...
、322. 零钱兑换、279.完全平方数、139.单词拆分)
Day45代码随想录动态规划part07:70. 爬楼梯(进阶版)、322. 零钱兑换、279.完全平方数、139.单词拆分
Day45 动态规划part07 完全背包 70. 爬楼梯(进阶版) 卡码网链接:57. 爬楼梯(第八期模拟笔试) (kamacoder.com) 题意:假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬至多m (1 < m < n)个…...

土壤重金属含量分布、Cd镉含量、Cr、Pb、Cu、Zn、As和Hg、土壤采样点、土壤类型分布
土壤是人类赖以生存和发展的重要资源之一,也是陆地生态系统重要的组成部分。近年来, 随着我国城市化进程加快,矿产资源开发、金属加工冶炼、化工生产、污水灌溉以及不合理的化肥农药施用等因素导致重金属在农田土壤中不断富集。重金属作为土壤环境中一种具有潜在危害…...
)
力扣:100284. 有效单词(Java)
目录 题目描述:输入:输出:代码实现: 题目描述: 有效单词 需要满足以下几个条件: 至少 包含 3 个字符。 由数字 0-9 和英文大小写字母组成。(不必包含所有这类字符。) 至少 包含一个 …...
如何快速掌握DDT数据驱动测试?
前言 网盗概念相同的测试脚本使用不同的测试数据来执行,测试数据和测试行为完全分离, 这样的测试脚本设计模式称为数据驱动。(网盗结束)当我们测试某个网站的登录功能时,我们往往会使用不同的用户名和密码来验证登录模块对系统的影响&#x…...
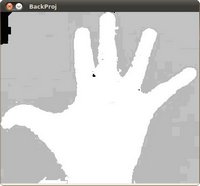
OpenCV如何实现背投(58)
返回:OpenCV系列文章目录(持续更新中......) 上一篇:OpenCV直方图比较(57) 下一篇:OpenCV如何模板匹配(59) 目标 在本教程中,您将学习: 什么是背投以及它为什么有用如何使用 OpenCV 函数 cv::calcBackP…...
5-在Linux上部署各类软件
1. MySQL 数据库安装部署 1.1 MySQL 5.7 版本在 CentOS 系统安装 注意:安装操作需要 root 权限 MySQL 的安装我们可以通过前面学习的 yum 命令进行。 1.1.1 安装 配置 yum 仓库 # 更新密钥 rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022# 安装Mysql…...
:Jenkins凭证管理(实现使用 SSH 、HTTP克隆Gitlab代码))
【Jenkins】持续集成与交付 (八):Jenkins凭证管理(实现使用 SSH 、HTTP克隆Gitlab代码)
🟣【Jenkins】持续集成与交付 (八):Jenkins凭证管理(实现使用 SSH 、HTTP克隆Gitlab代码) 1、安装Credentials Binding、git插件2、凭证类型及用途3、(用户名和密码类型)凭证的添加和使用3.1 用户密码类型3.2 测试凭证是否可用3.3 开始构建项目3.3 查看结果(进入Jenk…...

开源模型应用落地-CodeQwen模型小试-SQL专家测试(二)
一、前言 代码专家模型是基于人工智能的先进技术,它能够自动分析和理解大量的代码库,并从中学习常见的编码模式和最佳实践。这种模型可以提供准确而高效的代码建议,帮助开发人员在编写代码时避免常见的错误和陷阱。 通过学习代码专家模型&…...

Arch Linux安装macOS
安装需要的包 sudo pacman -S qemu-full libvirt virt-manager p7zip yay -S dmg2img安装步骤 cd ~ git clone --depth 1 --recursive https://github.com/kholia/OSX-KVM.git cd OSX-KVM # 选择iOS版本 ./fetch-macOS.py #将上一步下载的BaseSystem.dmg转换格式 dmg2img -…...

JDspyder:京东自动化抢购解决方案的技术实现与实战指南
JDspyder:京东自动化抢购解决方案的技术实现与实战指南 【免费下载链接】JDspyder 京东预约&抢购脚本,可以自定义商品链接 项目地址: https://gitcode.com/gh_mirrors/jd/JDspyder 在电商秒杀和限量商品抢购的激烈竞争中,技术手段…...

Python 爬虫进阶技巧:本地 Cookies 导入实现免登录爬取
前言 在 Python 爬虫实际开发场景中,大量资讯平台、社交站点、电商后台、个人中心类页面均设置了登录权限校验,未携带有效登录身份标识的请求会直接跳转登录页、返回权限不足提示或拒绝数据响应。常规账号密码模拟登录存在诸多弊端,接口加密、验证码拦截、账号风控封禁、参…...

如何用Sticky便签应用提升Linux桌面工作效率的5个秘诀
如何用Sticky便签应用提升Linux桌面工作效率的5个秘诀 【免费下载链接】sticky A sticky notes app for the linux desktop 项目地址: https://gitcode.com/gh_mirrors/stic/sticky 你是否厌倦了在多个窗口间切换查找笔记?是否经常忘记重要的待办事项&#x…...

Daptin状态机管理:企业级工作流自动化的核心
Daptin状态机管理:企业级工作流自动化的核心 【免费下载链接】daptin Daptin - Backend As A Service - GraphQL/JSON-API Headless CMS 项目地址: https://gitcode.com/gh_mirrors/da/daptin Daptin作为后端即服务(Backend As A Service…...

本地部署开源大模型聊天界面Serge:零成本私有化AI助手实战指南
1. 项目概述:一个能在本地运行的开源大语言模型聊天界面如果你和我一样,对大型语言模型(LLM)充满好奇,既想体验它们强大的对话和推理能力,又对数据隐私、网络依赖和API调用成本心存顾虑,那么ser…...

3步解锁百度网盘Mac版高速下载:逆向工程实践指南
3步解锁百度网盘Mac版高速下载:逆向工程实践指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘在macOS平台上的下载速度限…...

黑莓BB10失败启示录:操作系统生态竞争与品牌转型的经典案例
1. 项目概述:一场关于键盘的“信仰崩塌”作为一名在消费电子和移动通信领域摸爬滚打了十几年的从业者,我见过太多产品的起起落落。但2012年5月1日,在奥兰多黑莓世界大会上发生的那一幕,至今回想起来,依然能让我清晰地感…...

DDR内存信号测试难题:芯片中介层原理与实战部署指南
1. 项目概述:当PCB上的DDR内存引脚“无处下针”时作为一名在硬件测试和信号完整性领域摸爬滚打了十几年的工程师,我太熟悉那种场景了:测试工程师拿着示波器探头,对着电路板上密密麻麻的元器件,尤其是那些藏在其他芯片底…...

Windows系统清理终极指南:DriverStore Explorer深度使用教程
Windows系统清理终极指南:DriverStore Explorer深度使用教程 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你的C盘是不是总在不知不觉中变小?系统运行越来越慢…...

如何用ComfyUI MixLab插件重塑你的AI创作流程:5个颠覆性应用场景
如何用ComfyUI MixLab插件重塑你的AI创作流程:5个颠覆性应用场景 【免费下载链接】comfyui-mixlab-nodes Workflow-to-APP、ScreenShare&FloatingVideo、GPT & 3D、SpeechRecognition&TTS 项目地址: https://gitcode.com/gh_mirrors/co/comfyui-mixla…...