车牌号识别系统:PyQT5+QT Designe+crnn/PaddleOCR+YOLO+OpenCV矫正算法。
PyQT5&QT Designe+crnn/PaddleOCR+YOLO+传统OpenCV矫正算法。可视化的车牌识别系统项目。
车牌号识别系统
- 项目绪论
- 1.项目展示
- 2.视频展示
- 3.整体思路
- 一、PyQT5 和 QT Designer
- 1.简介
- 2.安装
- 3.使用
- 二、YOLO检测算法
- 三、OpenCV矫正算法
- 四、crnn/PaddleOCR字符识别算法
- 五、QT界面中对得到的检测结果进行展示
- 六、源码获取
- 附录
- 1.安装包国内镜像
项目绪论
1.项目展示
要实现的效果如下图所示

2.视频展示
视频展示链接(展示的另一个瓶盖生产日期检测项目):https://www.bilibili.com/video/BV1K1421673E/
3.整体思路
还是先给出整体思路
1.第一步需要用QT把界面呈现出来
2.第二步用YOLO把车牌位置检测出来
3.第三步,由于第二步检测出来的车牌不一定是正的,所以采用简单的传统OpenCV算法把歪的车牌矫正一下
4.第四步,使用字符识别算法如PaddleOCR或crnn等对矫正后的车牌图像进行字符识别
5.第五步,在QT界面上把识别出的内容展示出来
一、PyQT5 和 QT Designer
1.简介
PyQt5是Python编程语言的一个GUI(图形用户界面)工具包,它允许开发人员使用Python语言创建桌面应用程序。PyQt提供了许多用于创建丰富多样的用户界面的类和功能,以及用于处理用户输入和交互的工具。
而Qt Designer是PyQt程序UI界面的实现工具,使用Qt Designer可以拖拽、点击完成GUI界面设计,并且设计完成的.ui程序可以转换成.py文件供python程序调用。
因此结合PyQT5和QT Designer,可以采用直接拖拽和写代码二者结合的方式,快速实现界面的设计。
2.安装
在PyCharm里面安装PyQt5和QT工具包(如果报错可以切别的镜像源,更多镜像源在附录第一节),其中PyQT5-tools中就包括QT Designer
pip install PyQt5 -i https://pypi.douban.com/simple
pip install PyQt5-tools -i https://pypi.douban.com/simple
3.使用
下载完成之后,在虚拟环境的文件夹下,找到
\Lib\site-packages\qt5_applications\Qt\bin,点击designer.exe,即可直接进入QT Designer设计界面。
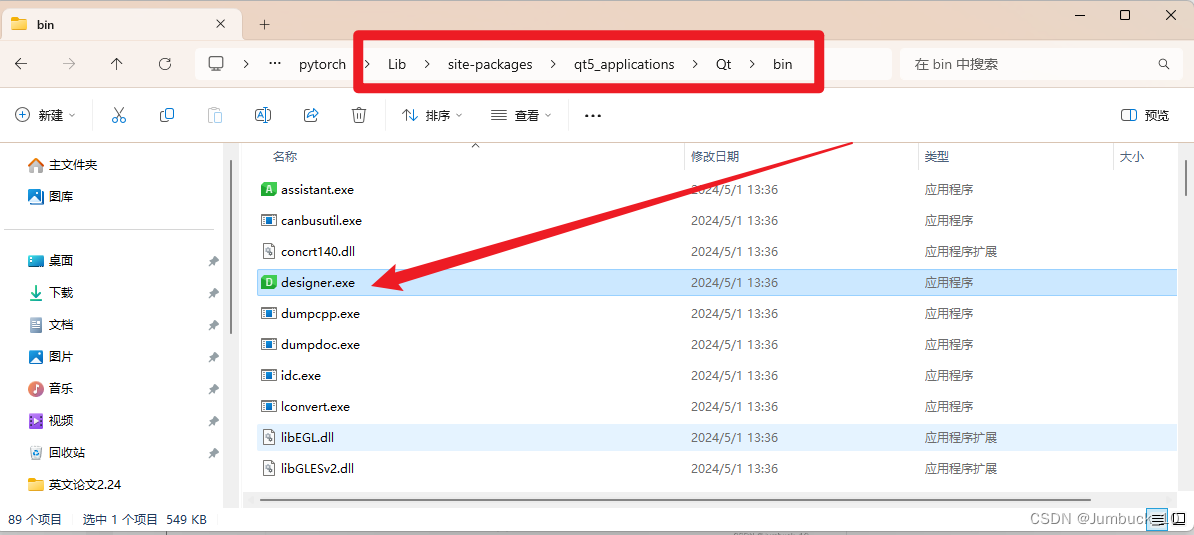
在此界面中,选择默认的Widget,然后直接创建即可
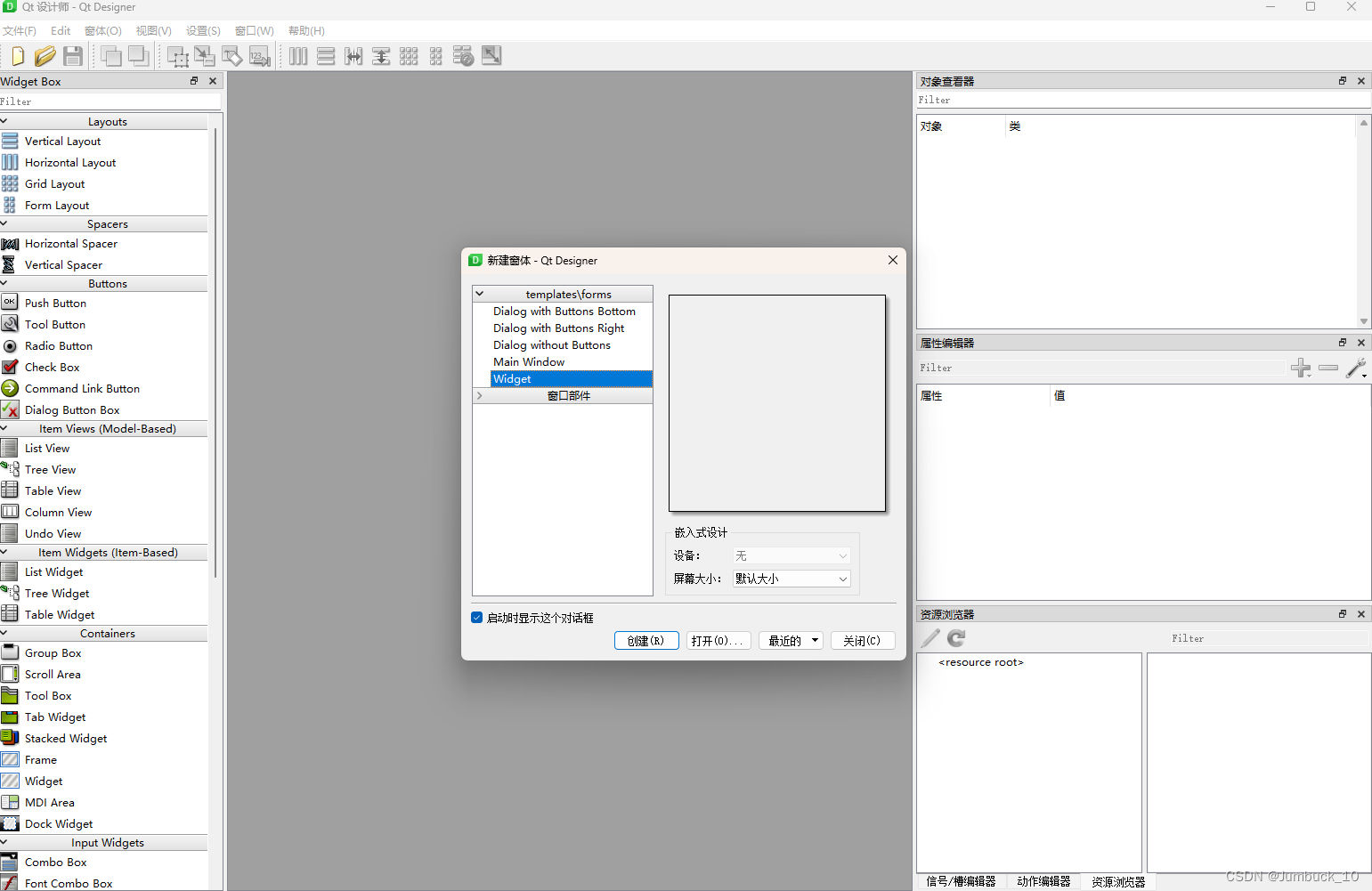
左侧栏可以选择一些插件,其中最常用的插件如下:
QLabel可以显示图像、文本等等(可以放文字)
QPushButton是按钮,用于响应事件
通过上述插件,我们已经通过可视化界面设计出一个简易的可视化界面了。
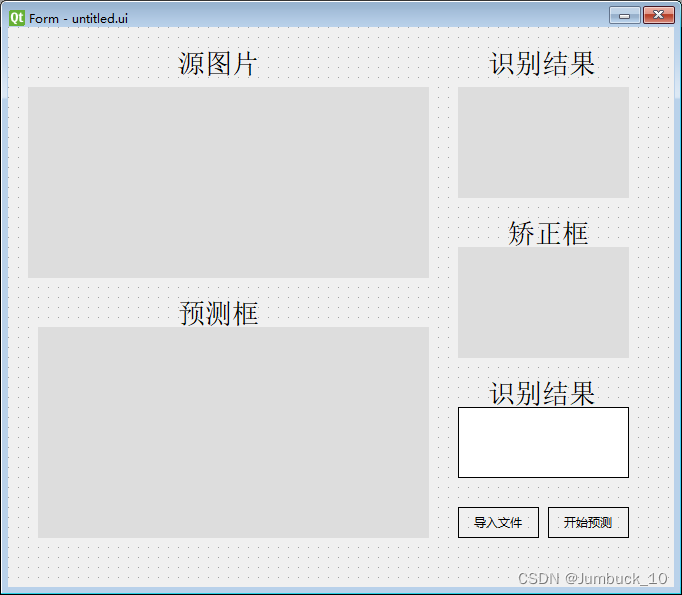
ctrl+s保存直接生成一份.ui为后缀的文件(文件默认名称为untitled.ui),
然后再使用如下指令:
pyuic5 -o untitled.py untitled.ui
将untitled.ui变为可以通过编译器执行的untitled.py。
生成的文件中,基础结构如下:
class Ui_Form(object):def setupUi(self, Form):Form.setObjectName("Form")Form.resize(666, 560)......# 定义的几个按钮self.pushButton = QtWidgets.QPushButton(Form)self.pushButton.setGeometry(QtCore.QRect(450, 480, 81, 31))self.pushButton.setStyleSheet("border:1px solid black")self.pushButton.setObjectName("pushButton")......# 对应的按钮响应方法# 导入文件self.pushButton.clicked.connect(self.browse_image)# 开始预测self.pushButton_2.clicked.connect(self.predict_image)
随后我们在setupUi即定义各种组件的相应方法,如上代码的最后两行。
其中pushButton_2为代码中定义的按钮,predict_image为下方我们自己定义的相应方法。即:现在已经把predict_image和pushButton_2进行链接了,点击pushButton_2对应的按钮,响应predict_image方法
二、YOLO检测算法

使用标注过的数据集对车牌区域进行识别,识别效果如下图所示

YOLO算法本身也属于老生常谈的技术了,因此不在这里过多赘述,有疑问的同学可以翻一下博主之前的博客。
三、OpenCV矫正算法
识别出来的车牌可能非正,如下图所示,这样会给后续的字符识别工作带来困难

因此我们使用OpenCV的矫正算法,对其进行校正

我们这里使用透视矫正:在图像中存在透视变换时,矫正算法可以将图像中的对象转换为在一个平面上的投影,以消除透视效应,从而更容易进行后续的分析和处理。透视矫正通常用于计算机视觉、机器人导航、虚拟现实等领域。
矫正的具体代码如下所示
import cv2
import numpy as np# 读取图像
imgPath = "D:\PythonCode\pyQT\warpMethods\data\\2.png"
image = cv2.imread(imgPath)
cv2.imshow('dilated Box', image)
cv2.waitKey(0)
# 将图像转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow('dilated Box', gray)
cv2.waitKey(0)
# 二值化处理
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)# 膨胀操作,用于连接相邻的文字
kernel = np.ones((5,5), np.uint8)
dilated = cv2.dilate(binary, kernel, iterations=3)
cv2.imshow('dilated Box', dilated)
cv2.waitKey(0)
# 腐蚀操作,用于消除细小的噪声
eroded = cv2.erode(dilated, kernel, iterations=3)
cv2.imshow('eroded Box', eroded)
cv2.waitKey(0)
# 查找轮廓
contours, hierarchy = cv2.findContours(eroded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)# 获取所有文本区域的最小外接矩形
boxes = []
for contour in contours:rect = cv2.minAreaRect(contour)box = cv2.boxPoints(rect)box = np.int0(box)boxes.append(box)# 将所有文本区域的矩形框合并为一个大矩形框
merged_box = cv2.minAreaRect(np.concatenate(boxes))# 提取矩形框的角点
rect_points = cv2.boxPoints(merged_box)# 将角点转换为整数类型
rect_points = np.int0(rect_points)
print(rect_points)
# 在图像上绘制合并后的矩形框
cv2.drawContours(image, [rect_points], 0, (0, 255, 0), 2)# 显示结果
cv2.imshow('Merged Box', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 提取矩形框的角点并转换为浮点数类型的 NumPy 数组
src_pts = cv2.boxPoints(merged_box)
src_pts = np.float32(src_pts)# 定义目标点
dst_pts = np.float32([[0, merged_box[1][1]-1],[0, 0],[merged_box[1][0]-1, 0],[merged_box[1][0]-1, merged_box[1][1]-1]])# 获取透视变换矩阵
M = cv2.getPerspectiveTransform(src_pts, dst_pts)# 执行透视变换,校正文本区域
corrected_image = cv2.warpPerspective(image, M, (int(merged_box[1][0]), int(merged_box[1][1])))# 检查纵向长度是否比横向长度长,如果是则翻转图像
if corrected_image.shape[0] > corrected_image.shape[1]:corrected_image = cv2.rotate(corrected_image, cv2.ROTATE_90_CLOCKWISE)# 显示结果
cv2.imshow('Corrected Image', corrected_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
四、crnn/PaddleOCR字符识别算法
文本识别是图像领域的一个常见任务,场景文字识别OCR任务中,需要先检测出图像中文字位置,再对检测出的文字进行识别,文节介绍的CRNN模型可用于后者, 对检测出的文字进行识别。

crnn存在不足的地方是它只能预测一行数据,因此多行数据不能进行预测,我们这里的车牌仅一行,但是如果有同学是识别多行的任务,则需要写个脚本对图像的进行分离,具体代码如下所示:
# 将图像分成上下两段height = img.shape[0]half_height = height // 2upper_img = img[:half_height, :]lower_img = img[half_height:, :]# 对上半部分进行预测upper_img = Image.fromarray(upper_img)upper_image = upper_img.convert('L')upper_image = transformer(upper_image)if torch.cuda.is_available():upper_image = upper_image.cuda()upper_image = upper_image.view(1, *upper_image.size())upper_image = Variable(upper_image)model.eval()upper_preds = model(upper_image)_, upper_preds = upper_preds.max(2)upper_preds = upper_preds.transpose(1, 0).contiguous().view(-1)upper_preds_size = Variable(torch.IntTensor([upper_preds.size(0)]))upper_raw_pred = converter.decode(upper_preds.data, upper_preds_size.data, raw=True)upper_sim_pred = converter.decode(upper_preds.data, upper_preds_size.data, raw=False)print('Upper prediction: %-20s => %-20s' % (upper_raw_pred, upper_sim_pred))# 对下半部分进行预测lower_img = Image.fromarray(lower_img)lower_image = lower_img.convert('L')lower_image = transformer(lower_image)if torch.cuda.is_available():lower_image = lower_image.cuda()lower_image = lower_image.view(1, *lower_image.size())lower_image = Variable(lower_image)lower_preds = model(lower_image)_, lower_preds = lower_preds.max(2)lower_preds = lower_preds.transpose(1, 0).contiguous().view(-1)lower_preds_size = Variable(torch.IntTensor([lower_preds.size(0)]))lower_raw_pred = converter.decode(lower_preds.data, lower_preds_size.data, raw=True)lower_sim_pred = converter.decode(lower_preds.data, lower_preds_size.data, raw=False)print('Lower prediction: %-20s => %-20s' % (lower_raw_pred, lower_sim_pred))words = upper_sim_pred + "\n" + lower_sim_pred如果只是为了方便我们也可以使用paddleocr提供的远端服务方式进行访问。这样精度更高且不用配置环境,博主试了一下精度特别高,基本能满足简易条件下的数据。
访问方法如下所示:
import base64
import json
import urllib
import requestsdef main():url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic?access_token# image 可以通过 get_file_content_as_base64("C:\fakepath\1.bmp",True) 方法获取payload = '&detect_language=false¶graph=false&probability=false'headers = {'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)result_str = response.text# 解析 JSON 字符串data = json.loads(result_str)# 提取出 words 后的两个字符串if "words_result" in data:words_result = data["words_result"]if len(words_result) >= 2:word1 = words_result[0]["words"]word2 = words_result[1]["words"]print("提取结果:", word1, word2)else:print("Error: 'words_result' 中的元素数量不足 2")else:print("Error: 没有找到 'words_result' 键")result_str = word1+'\n' + word2print(result_str)def get_file_content_as_base64(path, urlencoded=False):"""获取文件base64编码:param path: 文件路径:param urlencoded: 是否对结果进行urlencoded:return: base64编码信息"""with open(path, "rb") as f:content = base64.b64encode(f.read()).decode("utf8")if urlencoded:content = urllib.parse.quote_plus(content)return contentif __name__ == '__main__':main()
其中token需要替换成自己的(需要的同学多的话可以专门出一期PaddleOCR部署的博文)
五、QT界面中对得到的检测结果进行展示
具体逻辑为:
- 点击图片预测后,把图像路径传给predict_image( self.file_path定义为公共,因此可以直接访问)
- 使用YOLOv5Detect 中的predict方法,使用该文件路径,对其进行一系列的预测(具体方法如上文所示),即,先用yolo检测、再用opencv进行校正、最后使用paddleocr进行字符识别
- 拿到返回的数据,使用setPixmap显示到QT界面上。
from YOLOv5Detect import predictdef predict_image(self):try:if self.file_path:# 这里执行图像预测的逻辑,例如调用预测模型print("预测图片路径:", self.file_path)# 在这里使用 self.file_path 进行图像预测predImg,cropped_image,warpImg,words = predict(self.file_path) # 假设 predict 函数返回处理后的图像数组if predImg is not None and isinstance(predImg, np.ndarray):pixmap = self.convert_array_to_pixmap(predImg)self.output_img.setPixmap(pixmap.scaled(self.output_img.size(), Qt.KeepAspectRatio))if cropped_image is not None and isinstance(cropped_image, np.ndarray):pixmap = self.convert_array_to_pixmap(cropped_image)self.yucekuang_img.setPixmap(pixmap.scaled(self.yucekuang_img.size(), Qt.KeepAspectRatio))if warpImg is not None and isinstance(warpImg, np.ndarray):pixmap = self.convert_array_to_pixmap(warpImg)self.jiaozhenghou_img.setPixmap(pixmap.scaled(self.yucekuang_img.size(), Qt.KeepAspectRatio))if words:self.shibiejieguo_kuang.setText(words)else:print("预测函数返回无效的图像数组")else:print("请先选择图片")except Exception as e:print("预测图像时发生异常:", str(e))六、源码获取
为了方便大家文档及论文撰写,博主更新了一篇五千字的技术细节文档,有需要可以联系.
<1831255794---q>制备数据集和写算法耗费了大量时间精力,因此收取点小费希望理解!!!
可接项目,大作业,毕设等
价格略贵,技术够硬,认真负责,保证质量

附录
1.安装包国内镜像
清华大学镜像源:
https://pypi.tuna.tsinghua.edu.cn/simple/阿里云镜像源:
http://mirrors.aliyun.com/pypi/simple/中国科技大学镜像源:
https://pypi.mirrors.ustc.edu.cn/simple/华中科技大学镜像源:
http://pypi.hustunique.com/simple/上海交通大学镜像源:
https://mirror.sjtu.edu.cn/pypi/web/simple/豆瓣镜像源:
http://pypi.douban.com/simple/山东理工大学镜像源:
http://pypi.sdutlinux.org/百度镜像源:
https://mirror.baidu.com/pypi/simple使用方法:
pip install <安装包> -i <镜像源>
相关文章:
车牌号识别系统:PyQT5+QT Designe+crnn/PaddleOCR+YOLO+OpenCV矫正算法。
PyQT5&QT Designecrnn/PaddleOCRYOLO传统OpenCV矫正算法。可视化的车牌识别系统项目。 车牌号识别系统 项目绪论1.项目展示2.视频展示3.整体思路 一、PyQT5 和 QT Designer1.简介2.安装3.使用 二、YOLO检测算法三、OpenCV矫正算法四、crnn/PaddleOCR字符识别算法五、QT界面…...
【基于MAX98357的Minimax(百度)长文本语音合成TTS 接入教程】
【基于MAX98357的Minimax(百度)长文本语音合成TTS 接入教程】 1. 前言2. 先决条件2.1 硬件准备2.2 软件准备2.3 接线 3. 核心代码3.1 驱动实现3.2 代码解析 4. 播放文本5. 结论 视频地址: SeeedXIAO ESP32S3 Sense【基于MAX98357的Minimax&am…...
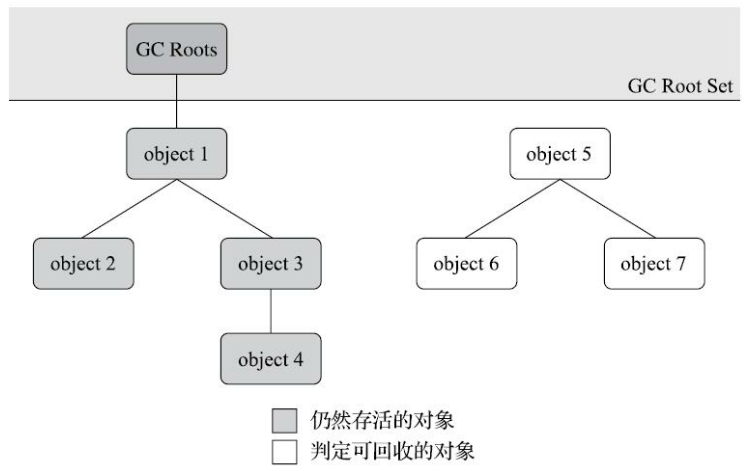
秋招后端开发面试题 - JVM底层原理
目录 JVM底层原理前言面试题Java 对象的创建过程?什么是指针碰撞?什么是空闲列表?/ 内存分配的两种方式?JVM 里 new 对象时,堆会发生抢占吗?JVM 是怎么设计来保证线程安全的?/ 内存分配并发问题…...
)
VUE2从入门到精通(一)
**************************************************************************************************************************************************************************** 1、课程概述 【1】前置储备:HTMLCSSJS、WebAPI、Ajax、Node.js 【2】1天&…...

cmake进阶:文件操作之写文件
一. 简介 cmake 提供了 file() 命令可对文件进行一系列操作,譬如读写文件、删除文件、文件重命名、拷贝文件、创建目录等等。 接下来 学习这个功能强大的 file() 命令。 本文学习 CMakeLists.txt语法中写文件操作。 二. cmake进阶:文件操作之写文件…...
ubuntu 安装单节点HBase
下载HBase mkdir -p /home/ellis/HBase/ cd /home/ellis/HBase/ wget https://downloads.apache.org/hbase/2.5.8/hbase-2.5.8-bin.tar.gz tar -xvf hbase-2.5.8-bin.tar.gz安装java jdk sudo apt install openjdk-11-jdksudo vim /etc/profileexport JAVA_HOME/usr/lib/jvm/…...
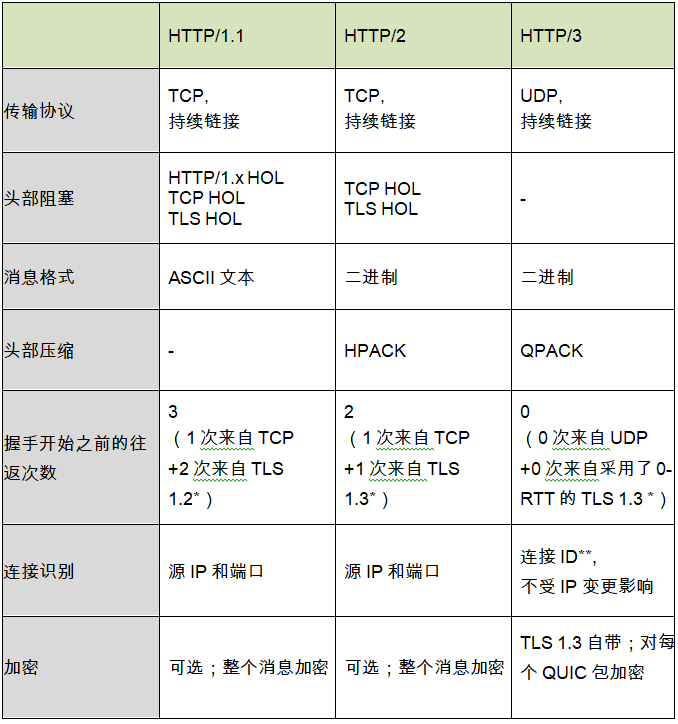
HTTP 多个版本
了解一下各个版本的HTTP。 上个世纪90年代初期,蒂姆伯纳斯-李(Tim Berners-Lee)及其 CERN的团队共同努力,制定了互联网的基础,定义了互联网的四个构建模块: 超文本文档格式(HTML) …...

【DevOps】探索Linux命令行世界:深入了解Shell的力量
目录 一、Linux Shell 详细介绍 1. Shell基础概念 2. Shell的功能特性 3. 常用Shell命令与技巧 4. 高级Shell特性与实践 二、常见的Shell及其比较 1. Bash (Bourne Again SHell) 2. Zsh (Z Shell) 3. Fish (Friendly Interactive SHell) 4. Ksh (Korn SHell) 5. Csh …...

互斥量的使用
文章目录 前言一、互斥量与二进制信号量二、优先级反转与优先级继承三、递归锁 前言 通过学习上一章互斥量理论基础,这一章我们来做一些实验进行验证。 一、互斥量与二进制信号量 互斥量使用和二进制信号量类似 互斥量有优先级继承功能,二进制信号量没有…...

关于面试真题的压迫
1.请描述一下您在使用JavaScript进行DOM操作时,如何提高页面性能和用户体验? 使用事件委托:在父元素上监听事件,而不是为每个子元素都添加事件监听器。这样可以减少事件处理程序的数量,提高性能。 缓存DOM查询&#x…...
1700java进销存管理系统Myeclipse开发sqlserver数据库web结构java编程计算机网页项目
一、源码特点 java web进销存管理系统是一套完善的java web信息管理系统,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为 TOMCAT7.0,Myeclipse8.5开发,数据库为sqlser…...

mysql数据库(排序与分页)
目录 一. 排序数据 1.1 排序规则 1.2 单列排序 1.我们也可以使用列的别名,给别名进行排序 2.列的别名只能在 ODER BY 中使用, 不能在WHERE中使用。 3.强调格式:WHERE 需要在 FROM 后, ORDER BY 之前 1.3 二级排序&…...
)
Android 实时监听Activity堆栈变化(系统应用)
private val mIActivityManager: IActivityManager ActivityManagerNative.asInterface(ServiceManager.getService(Context.ACTIVITY_SERVICE)) 方式一(registerProcessObserver) : mIActivityManager.registerProcessObserver(mIProcess…...

双目深度估计原理立体视觉
双目深度估计原理&立体视觉 0. 写在前面1. 双目估计的大致步骤2. 理想双目系统的深度估计公式推导3. 双目标定公式推导4. 极线校正理论推导 0. 写在前面 双目深度估计是通过两个相机的对同一个点的视差来得到给该点的深度。 标准系统的双目深度估计的公式推导需要满足:1)两…...

Redis探索之旅(基础)
目录 今日良言:满怀憧憬,阔步向前 一、基础命令 1.1 通用命令 1.2 五大基本类型的命令 1.2.1 String 1.2.2 Hash 1.2.3 List 1.2.4 Set 1.2.5 Zset 二、过期策略以及单线程模型 2.1 过期策略 2.2 单线程模型 2.3 Redis 效率为什么这么高 三…...

C语言/数据结构——每日一题(链表的中间节点)
一.前言 今天我在LeetCode刷到了一道单链表题,想着和大家分享一下这道题:https://leetcode.cn/problems/middle-of-the-linked-list。废话不多说让我们开始今天的知识分享吧。 二.正文 1.1题目描述 1.2题目分析 这道题有一个非常简便的方法——快慢指…...
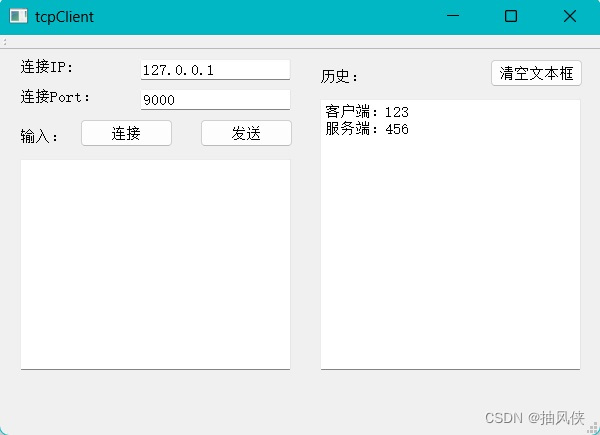
这是用VS写的一个tcp客户端和服务端的demo
服务端: 客户端: 其实这里面的核心代码就两行。 客户端的核心代码: //套接字连接服务端 m_tcpSocket->connectToHost(_ip,_port);//通过套接字发送数据m_tcpSocket->write(ui.textEditSend->toPlainText().toUtf8());//如果收到信…...

代码随想录算法训练营day18 | 102.二叉树的层序遍历、226.翻转二叉树、101. 对称二叉树
102.二叉树的层序遍历 迭代法 层序遍历使用队列,同时记录每层的个数 class Solution:def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:res []if not root:return resqueue collections.deque()queue.append(root)while queue:size len…...
--设备通信协议详解及选型)
工厂自动化升级改造参考(01)--设备通信协议详解及选型
以下是整合了通信协议的特点、应用场景、优缺点以及常用接口方式的描述: 以太网/IP: 来历: 以太网是一种局域网技术,由罗伯特梅特卡夫和大卫博格在1973年开发。IP是网络层协议,负责在网络中的设备间传输数据。特点:基于标准的以太网技术,使用TCP/IP协议栈,支持高速数据传…...
数据结构与算法之经典排序算法
一、简单排序 在我们的程序中,排序是非常常见的一种需求,提供一些数据元素,把这些数据元素按照一定的规则进行排序。比如查询一些订单按照订单的日期进行排序,再比如查询一些商品,按照商品的价格进行排序等等。所以&a…...

Open-CLI技能扩展框架:构建模块化命令行工具生态
1. 项目概述:一个为Open-CLI设计的技能扩展框架最近在折腾命令行工具,特别是那些支持插件或技能扩展的CLI框架时,发现了一个挺有意思的项目:GloriaGuo/opencli-skill。简单来说,这是一个为“Open-CLI”设计的技能&…...

机器视觉项目中的GRR和CPK
在机器视觉项目中,GRR 和 Cpk 是两个核心的统计学指标,分别用于评估测量系统本身是否可靠以及生产过程是否稳定受控。下面分别详细解释。---一、GRR(量具重复性与再现性)1.1 是什么?GRR(Gauge Repeatabilit…...

基于Remix与React构建隐私优先的订阅费用追踪器Subs
1. 项目概述:一个纯粹、高效的订阅费用追踪器在数字订阅服务泛滥的今天,你是否也常常感到困惑:每个月到底有多少笔自动扣款?Netflix、Spotify、各种云服务、会员费……这些零散的费用加起来,一年可能是一笔不小的开销。…...

构建具备上下文感知的智能对话机器人:从记忆管理到主动服务
1. 项目概述:一个能“悬浮”的智能对话机器人最近在GitHub上看到一个挺有意思的项目,叫goncharenko/hoverbot-chatbot。光看名字,hoverbot就挺抓人眼球的,直译过来是“悬浮机器人”,这不禁让人好奇,一个聊天…...

AI驱动的学术研究技能:自动化文献综述与深度分析工作流
1. 项目概述:一个为AI智能体设计的深度学术研究技能如果你是一名研究生、科研人员,或者任何需要快速、系统地梳理某个领域文献的人,那么你肯定体会过那种面对海量论文时的无力感。传统的流程是:打开Google Scholar,输入…...

DeepSeek本地部署:从零开始,把大模型跑在自己电脑上
DeepSeek本地部署:从零开始,把大模型跑在自己电脑上我们公司因为数据安全要求,所有文档不能传到外部API。但团队又想用AI辅助写代码、做文档分析。解决方案:本地部署DeepSeek。这篇文章记录了完整的部署过程、踩过的坑、以及部署之…...
)
别再求公司账号了!个人开发者也能搞定uniapp打包iOS(保姆级证书+profile配置)
个人开发者独立完成uniapp iOS打包全流程指南 在移动应用开发领域,iOS平台始终是开发者无法绕开的重要阵地。然而,许多独立开发者和小团队常常被苹果开发者账号的门槛所困扰,误以为必须依赖企业级账号才能完成应用打包和上架。实际上&#x…...

Daptin状态机管理:企业级工作流自动化的核心
Daptin状态机管理:企业级工作流自动化的核心 【免费下载链接】daptin Daptin - Backend As A Service - GraphQL/JSON-API Headless CMS 项目地址: https://gitcode.com/gh_mirrors/da/daptin Daptin作为后端即服务(Backend As A Service…...

3步搞定Windows部署自动化:MediaCreationTool.bat终极指南
3步搞定Windows部署自动化:MediaCreationTool.bat终极指南 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...

3个步骤掌握APK Installer:在Windows上直接安装Android应用的终极指南
3个步骤掌握APK Installer:在Windows上直接安装Android应用的终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了在Windows电脑上使用笨重…...