深度神经网络中的不确定性研究综述
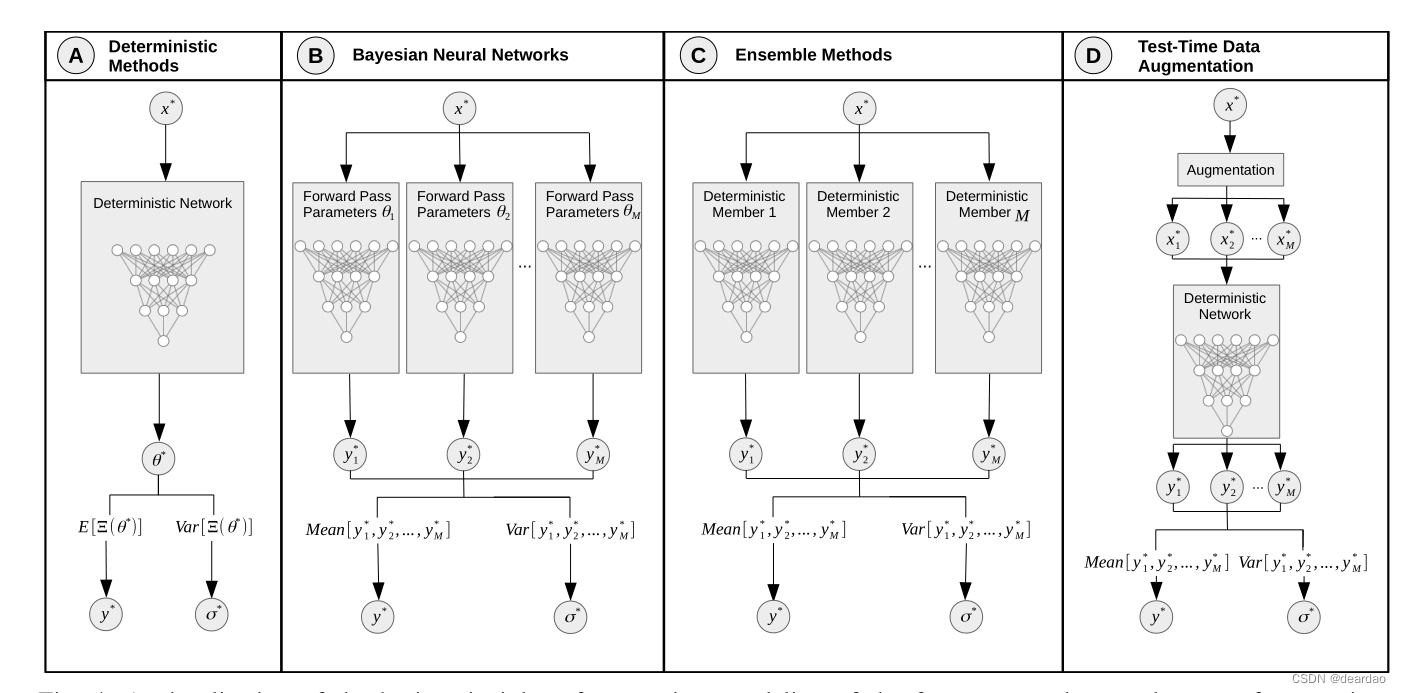
A.单一确定性方法
对于确定性神经网络,参数是确定的,每次向前传递的重复都会产生相同的结果。对于不确定性量化的单一确定性网络方法,我们总结了在确定性网络中基于单一正向传递计算预测y *的不确定性的所有方法。在文献中,可以找到几种这样的方法。它们大致可以分为两种方法,一种是对单个网络进行显式建模和训练,以量化不确定性[44]、[32]、[92]、[64]、[93];另一种是使用附加组件对网络的预测进行不确定性估计[46]、[36]、[71]、[72]。对于第一种类型,不确定性量化影响网络的训练过程和预测,而后一种类型通常应用于已经训练好的网络。由于经过训练的网络没有被这些方法修改,它们对网络的预测没有影响。下面,我们将这两种类型称为内部和外部不确定性量化方法。
1)内部不确定性量化方法:许多内部不确定性量化方法遵循预测分布参数的思想,而不是直接的逐点最大后验估计。通常,此类网络的损失函数会考虑真实分布与预测分布之间的期望散度,例如[32]、[94]。输出上的分布可以解释为模型不确定性的量化(参见第二节),试图模拟网络贝叶斯建模的行为。
对于分类任务,输出通常表示类概率。这些概率是应用softmax函数的结果。这些概率已经可以解释为对数据不确定性的预测。然而,人们普遍认为神经网络往往过于自信,而softmax输出往往校准不当,导致不确定度估计不准确[95]、[67]、[44]、[92]。此外,softmax的输出不能与模型的不确定性相关联。但是,如果没有明确地考虑到模型的不确定性,分布外样本可能导致证明错误置信度的输出。例如,对猫和狗进行训练的网络,当给它喂食鸟的图像时,很可能不会产生50%的狗和50%的猫。这是因为网络从图像中提取特征,即使这些特征不适合猫类,它们可能更不适合狗类。因此,网络将更多的概率放在cat上。此外,研究表明,整流线性单元(ReLu)网络和softmax输出的组合导致网络随着分布外样本之间的距离变得越来越自信。

图5显示了一个示例,其中从MNIST中旋转一个数字会导致具有高softmax值的错误预测。Hein等人对这一现象进行了描述和进一步研究[96],他们提出了一种避免这种行为的方法,该方法基于强制远离训练数据的均匀预测分布。其他几种分类方法[44],[32],[94],
[64]采用了类似的思想,考虑了logit幅度,但使用了Dirichlet分布。狄利克雷分布是分类分布的共轭先验,因此可以解释为分类分布上的分布。
不确定度度量和质量
下面,我们提出了量化不同预测类型的不确定性的不同措施。一般来说,这些不确定性的正确性和可信度并不是自动给出的。事实上,有几个原因可以解释为什么评估不确定性评估的质量是一项具有挑战性的任务。
- 首先,不确定性估计的质量取决于估计不确定性的基本方法。Yao等人的研究[256]证明了这一点,该研究表明贝叶斯推理的不同近似(例如高斯近似和拉普拉斯近似)会导致不同质量的不确定性估计。
- 其次,缺乏真值不确定性估计[31],并且定义真值不确定性估计具有挑战性。例如,如果我们将基础真理不确定性定义为人类受试者的不确定性,我们仍然需要回答“我们需要多少受试者?”或“如何选择科目?”
- 第三,缺乏统一的定量评价指标[257]。更具体地说,不确定性在不同的机器学习任务中有不同的定义,如分类、分割和回归。例如,预测间隔或标准差用于表示回归任务中的不确定性,而熵(和其他相关度量)用于捕获分类和分割任务中的不确定性。
A 评估分类任务中的不确定性
对于分类任务,网络的softmax输出已经就绪,代表了一种信心的度量。但由于原始的softmax输出既不太可靠[67],也不能代表所有的不确定性来源[19],因此开发了进一步的方法和相应的措施。
1 测量分类任务中的数据不确定性
考虑一个分类任务,有K个不同的类,对于一些输入样本x,有一个概率向量网络输出p(x),下面p用于简化,pk表示向量中的第K个条目。一般来说,给定的预测p代表一个分类分布,即它为每个类别分配一个正确预测的概率。由于预测不是作为显式类给出的,而是作为概率分布给出的,因此(不)确定性估计可以直接从预测中导出。一般来说,这种逐点预测可以看作是估计的数据不确定性[60]。然而,如第二节所述,模型对数据不确定性的估计受到模型不确定性的影响,必须单独考虑。为了评估预测数据不确定性的数量,例如可以应用最大类概率或熵度量:
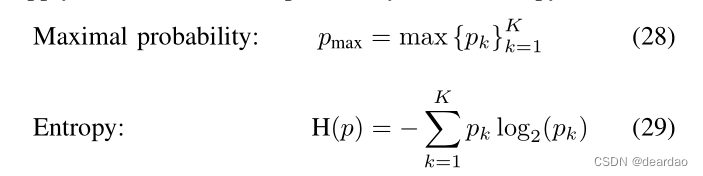
最大概率代表了确定性的直接表示,而熵描述了随机变量中信息的平均水平。即使softmax输出应该代表数据的不确定性,人们也不能从单个预测中判断出影响该特定预测的模型不确定性的量有多大。
2 分类任务中模型不确定性的测量
正如第三节已经讨论的那样,单一的softmax预测并不是一种非常可靠的不确定性量化方法,因为它通常校准得很差[19],并且没有关于模型本身对该特定输出的确定性的任何信息[19]。学习到的模型参数的(近似的)后验分布p(θ|D)有助于得到更好的不确定性估计。有了这样的后验分布,softmax输出本身就变成了一个随机变量,人们可以评估它的变化,即不确定性。为简单起见,我们将p(y|θ, x)也表示为p,从上下文中可以清楚地看出p是否依赖于θ。最常见的测量方法是互信息(MI)、预期Kullback-Leibler散度(EKL)和预测方差。基本上,所有这些度量都计算(随机)softmax输出和期望softmax输出之间的期望散度:
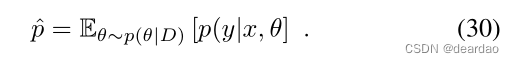
MI使用熵来度量两个变量之间的相互依赖性。在所描述的情况下,将期望softmax输出中给出的信息与softmax输出中期望信息之间的差进行比较,即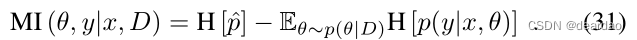
Smith和Gal[19]指出,当关于模型参数的知识不增加最终预测中的信息时,MI是最小的。因此,MI可以被解释为模型不确定性的度量。
Kullback-Leibler散度度量两个给定概率分布之间的散度。EKL可用于测量可能的softmax输出之间的(预期)散度,
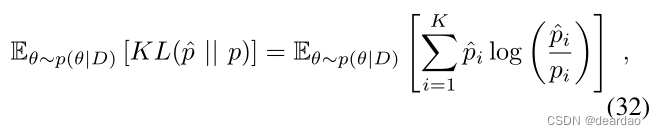
它也可以被解释为对模型输出的不确定性的度量,因此代表了模型的不确定性。
预测方差评估(随机)softmax输出上的方差,即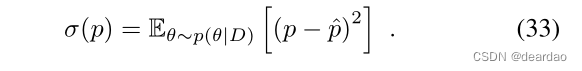
如第三节所述,分析描述的后置分布p(θ|D)仅适用于贝叶斯方法的一个子集。即使对于解析描述的分布,在几乎所有情况下,参数不确定性在预测中的传播也是难以处理的,必须进行近似,例如用蒙特卡罗近似。类似地,集成方法从M个神经网络收集预测,测试时间数据增强方法从应用于原始输入样本的M个不同的增强中接收M个预测。对于所有这些情况,我们收到一组M个样本,可用来近似难以处理甚至未定义的底层分布。有了这些近似值,(31)、(32)和(33)所规定的方法就可以直接应用,只需用平均值代替期望。例如,期望的softmax输出变成
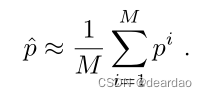
对于式(31)、式(32)和式(33)中给出的期望,期望近似相似。
3 分类中分布不确定性的测量任务
尽管这些不确定性度量被广泛用于捕获来自贝叶斯神经网络[60]、集成方法[31]或测试时间数据增强方法[14]的几种预测之间的可变性,但它们不能捕获输入数据或分布外示例中的分布变化,这可能导致有偏差的推断过程和错误的置信度陈述。如果所有的预测者都将高概率质量归因于相同的(错误的)类别标签,这将导致估计之间的低可变性。因此,网络似乎对其预测是确定的,而预测本身的不确定性(由softmax概率给出)也被评估为低。为了解决这个问题,第三节中描述的几种方法考虑了logit的大小,因为较大的logit表明相应类别的证据较多[44]。因此,这些方法要么将对数(指数)的总和解释为狄利克雷分布的精度值(参见第III-A节对狄利克雷先验的描述)[32]、[94]、[64],要么将其解释为与定义常数相比较的证据集合[44]、[92]。我们还可以分别为每个类推导出总类概率对每个logit应用sigmoid函数。基于类总概率,OOD样本可能更容易被检测到,因为所有类同时具有低概率。其他方法提供了一个显式的度量,新数据样本适合训练数据分布的程度。在此基础上,他们还给出了一个样本将被正确预测的度量[36]。
4 完全数据集上的性能度量
虽然上面描述的措施衡量单个预测的性能,但其他措施评估这些措施在一组样本上的使用情况。不确定度可以用来区分正确和错误分类的样本,或者区分域内和分布外的样本[67]。为此,将样本分成两组,例如域内和分布外,或正确分类和错误分类。最常用的两种方法是受试者工作特征(ROC)曲线和精确召回率(PR)曲线。这两种方法都基于底层度量的不同阈值生成曲线。对于每个考虑的阈值,ROC曲线绘制了真阳性率和假阳性率的对比图,PR曲线绘制了召回率和精度的对比图。虽然ROC和PR曲线提供了一个直观的概念,说明底层度量如何很好地适合于分离两个被考虑的测试用例,但它们并没有给出一个定性的度量。为了达到这个目的,可以评估曲线下面积(AUC)。粗略地说,AUC给出了一个随机选择的正样本比随机选择的负样本导致更高测量值的概率值。例如,最大softmax值衡量正确分类的示例比错误分类的示例的等级高。Hendrycks和Gimpel[67]表明,在几个应用领域中,正确的预测通常比错误的预测具有更高的softmax值的预测确定性。特别是对于域内和分布外示例的评估,常用的方法是Receiver Operating Curve (AUROC)和Precision Recall Curce (AUPRC)[64],[32],[94]。这些评估的明显缺点是,性能是评估的,最佳阈值是基于给定的测试数据集计算的。偏离测试集分布的分布可能会破坏整个性能,并使派生的阈值不切实际。
相关文章:
深度神经网络中的不确定性研究综述
A.单一确定性方法 对于确定性神经网络,参数是确定的,每次向前传递的重复都会产生相同的结果。对于不确定性量化的单一确定性网络方法,我们总结了在确定性网络中基于单一正向传递计算预测y *的不确定性的所有方法。在文献中,可以找…...

实用的Chrome浏览器命令
Google Chrome 是一款广泛使用的网络浏览器,它提供了许多实用的快捷键和命令,可以帮助用户更高效地浏览网页。以下是一些常用的 Chrome 浏览器命令: 1. 新标签页: Ctrl T (Windows/Linux) 或 Command T (Mac) 2. 关闭当前标签: Ctrl W 或…...

无人作业控制器--4G/5G通信
一、环境 开发环境:ubuntu 22 ros2 humble 发布运行环境:地平线旭日x3派、arm64 4G 模组: 移远EC20模块 5G 模组:移远RG200U-CN 网络通信模组根据需要选择其中一款, 前期我们使用4G模组,后续迭代因为…...

动态规划-两个数组的dp问题2
文章目录 1. 不同的子序列(115)2. 通配符匹配(44) 1. 不同的子序列(115) 题目描述: 状态表示: 根据题意这里的dp数组可以定义为二维,并且dp[i][j]表示字符串t的0到i的…...

如何设置并行度 ——《OceanBase 并行执行》系列 2
并行度(degree of parallelism,简称 DOP),是指在执行过程中所使用的工作线程数量。设计并行执行的初衷在于充分利用多核资源以提升效率。OceanBase 的并行执行框架支持多种设定并行度的方式,既允许用户手动设置&#x…...
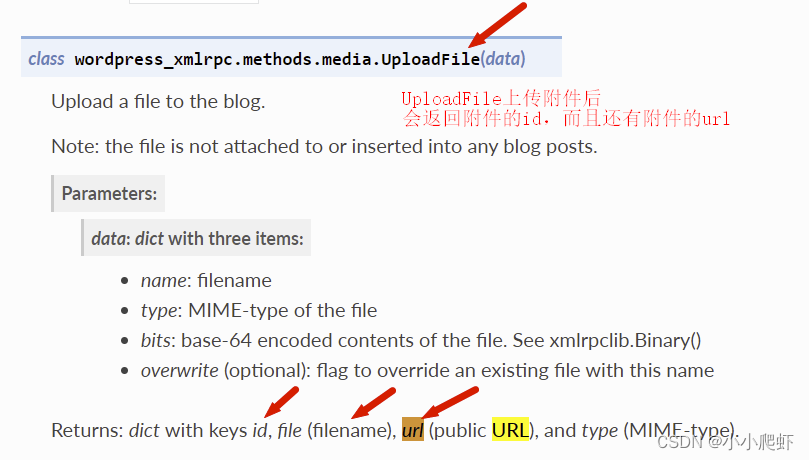
python直接发布到网站wordpress之三批量发布图片
在前面的文章中,实现了使用python操作wordpress发布文字内容和图片内容。 python直接发布到网站wordpress之一只发布文字-CSDN博客 python直接发布到网站wordpress之二发布图片-CSDN博客 不过,此时发布图片的数量只能是一张图片。但在实际应用中&…...

C#面:ADO.NET 相对于ADO等主要有什么改进
C# ADO.NET 是微软为.NET平台开发的一套数据访问技术,相对于传统的ADO(ActiveX Data Objects)等,它有以下几个主要改进: 面向对象:ADO.NET 是面向对象的数据访问技术,它使用.NET框架中的类和对…...
web前端学习笔记7-iconfont使用
7. iconfont的使用流程 字体图标使用较多的是阿里巴巴iconfont图标库,它是阿里巴巴体验团队推出的图标库和图标管理平台,提供了大量免费和可定制的矢量图标,以满足网页设计、平面设计、UI设计、应用程序开发和其他创意项目的需求。 官方网站:https://www.iconfont.cn/ 使用…...
国内小白用什么方法充值使用ChatGPT4.0?
首先说一下IOS礼品卡订阅,目前最经济实惠的订阅方式,具体操作步骤 使用IOS设备充值,用 App Stroe 兑换券 1、支付宝地址切换旧金山,在里面买app store 的兑换卷 2、美区Apple ID登陆app store ,充值兑换券 3、IOS设…...

富格林:正确杜绝欺诈实现出金
富格林悉知,现货黄金一直以来都是投资者们追逐的热门品种之一。其安全性和避险特性吸引着广大投资者。但在现货黄金市场中要想实现出金其实并不简单,是需要我们通过一定的技巧和方法去正确杜绝欺诈套路。下面为了帮助广大投资者正确杜绝欺诈实现出金&…...
基于java,SpringBoot和VUE的求职招聘简历管理系统设计
摘要 基于Java, Spring Boot和Vue的求职招聘管理系统是一个为了简化求职者与雇主间互动流程而设计的现代化在线平台。该系统后端采用Spring Boot框架,以便快速搭建具有自动配置、安全性和事务管理等特性的RESTful API服务,而前端则使用Vue.js框架构建动…...

sqlserver数据库日志文件log.ldf文件占用过大清除的办法
sqlserver数据库日志文件log.ldf文件占用过大清除的办法 技术交流 http://idea.coderyj.com/ 1.清除数据库日志的方法 --- 查看数据库日志文件名 USE cs GO SELECT file_id, name,size,* FROM sys.database_files;ps 可以看到其中name字段为数据库日志名称"数据库日志名称…...

【Python小技巧】matplotlib不显示图像竟是numpy惹的祸
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、问题:df.plot() 显示不出图像二、尝试各种解决办法1. 增加matplotlib.use,设定GUI2. 升级matplotlib版本 三、numpy是个重要的库1. …...

【AIGC】1、爆火的 AIGC 到底是什么 | 全面介绍
文章目录 一、AIGC 的简要介绍二、AIGC 的发展历程三、AIGC 的基石3.1 基本模型3.2 基于人类反馈的强化学习3.3 算力支持 四、生成式 AI(Generative AI)4.1 单模态4.1.1 生成式语言模型(Generative Language Models,GLM࿰…...

云计算技术概述_3.云计算的部署方式
根据NIST的定义,云计算从部署模式上看可以分为公有云、社区云、私有云和混合云四种类型。 注:NIST(美国国家标准与技术研究院)是美国商务部下属的一个物理科学实验室和非监管机构。 其任务是促进创新和行业竞争力。 NIST 将其活动…...
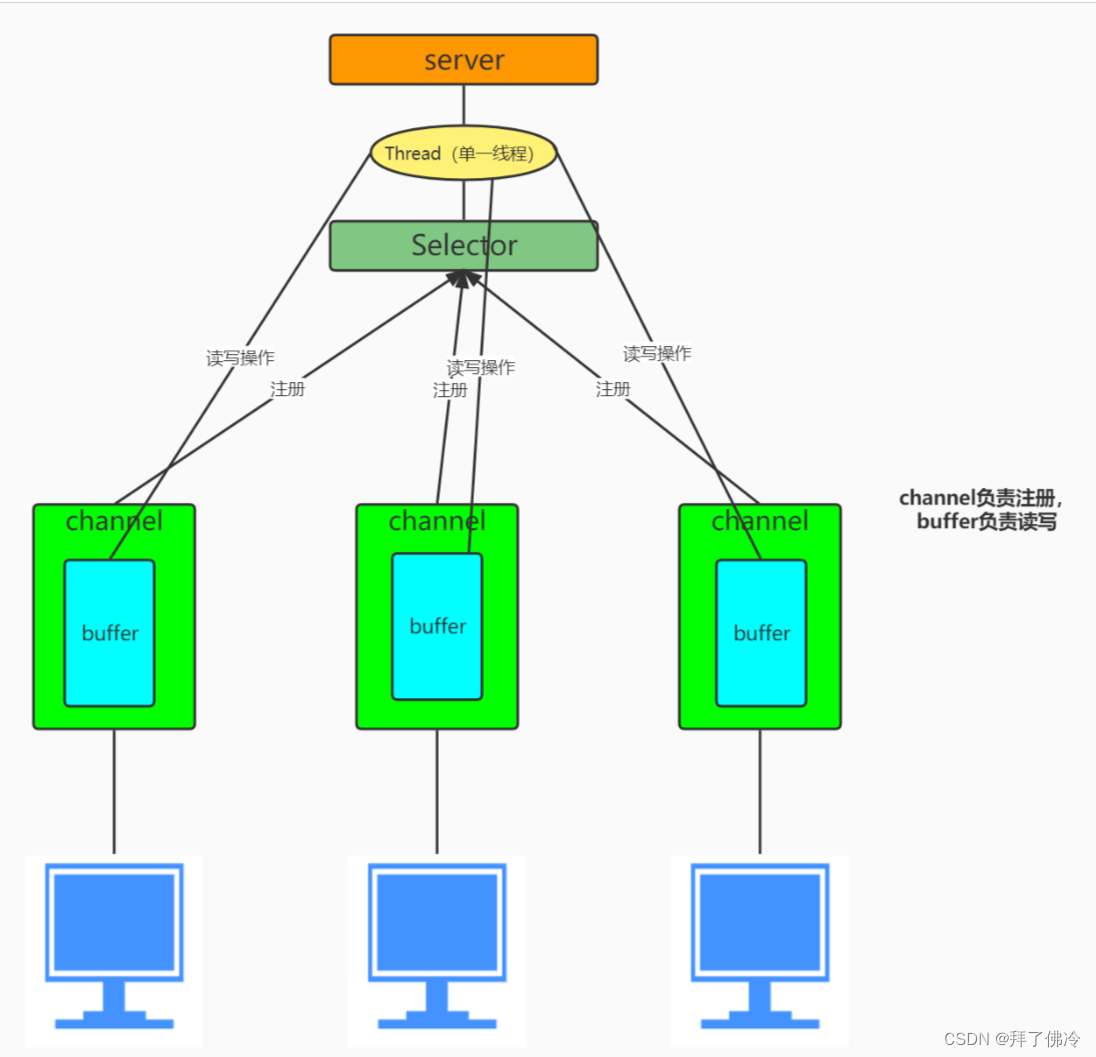
简述 BIO 、NIO 模型
BIO : 同步阻塞I/O(Block IO) 服务器实现模式为每一个连接一个线程,即客户端有连接请求时服务器就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,此处可以通过线程池机制进行优化。 impo…...

【Python小练】随机验证码
题目 提示输出含数字、字母的四位随机数,输入提示的验证码进行验证,验证码正确结束程序,验证码错误继续输入。 分析 我们可以通过random模块生成0到9的随机数,也可以通过生成65到90的随机数,将65到90的随机ASCLL码转换…...

《1w实盘and大盘基金预测 day30》
今日预测: 3123-3150-3177 探底回升,震荡上涨,收小红小绿 双创指数后期上涨的幅度也是会大于上证的,四月底的时候就提醒建仓。 关注板块:医疗、地产、电力、证券 这周预测 这周上证指数最高看到3200 继续看涨&#…...
软件工程案例学习-图书管理系统-面向对象方法
文档编号:LMS_1 版 本 号:V1.0 ** ** ** ** ** ** 文档名称:需求分析规格说明书 项目名称:图书管理系统 项目负责人:计敏 胡杰 ** ** …...
)
python:机器学习特征优选(过滤法)
作者:CSDN @ _养乐多_ 本文将介绍如何使用 python 语言使用过滤法进行机器学习特征优选。分别有F值、互信息(Mutual Information,MI)、方差阈值(Variance Threshold,VT)、相关性方法。 文章目录 一、特征数据1.1 将用于分析的数据从GEE下载到本地1.2 从其他方法获取二、…...

SubLens:AI订阅管理浏览器插件,一站式聚合账单与扣款提醒
1. 项目概述:一个帮你管好AI订阅账单的浏览器插件 如果你和我一样,订阅了不止一个AI服务——比如ChatGPT Plus用来日常对话和写作,Claude Pro用来处理长文档,GitHub Copilot写代码,Cursor辅助开发,再加上G…...

跨端三维GIS实战:uni-app集成Cesium.js的RenderJS方案解析
1. 为什么需要跨端三维GIS解决方案 最近几年三维GIS应用越来越普及,从传统的Web端到移动端APP,开发者都希望实现"一次开发,多端运行"的目标。uni-app作为跨端开发框架,天然具备这个优势。但当我们想在uni-app中集成Cesi…...

3分钟掌握百度网盘秒传技术:彻底解决文件分享失效难题
3分钟掌握百度网盘秒传技术:彻底解决文件分享失效难题 【免费下载链接】rapid-upload-userscript-doc 秒传链接提取脚本 - 文档&教程 项目地址: https://gitcode.com/gh_mirrors/ra/rapid-upload-userscript-doc 在数字化协作时代,百度网盘秒…...

NoFences:彻底解决Windows桌面杂乱问题,免费开源桌面整理革命
NoFences:彻底解决Windows桌面杂乱问题,免费开源桌面整理革命 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否厌倦了Windows桌面上满屏的图标&a…...

NVIDIA显卡终极调校指南:用Profile Inspector释放游戏潜能的简单方法
NVIDIA显卡终极调校指南:用Profile Inspector释放游戏潜能的简单方法 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 还在为游戏卡顿、画面撕裂而烦恼吗?NVIDIA Profile Inspect…...

终极歌词获取方案:163MusicLyrics让你轻松获取网易云和QQ音乐LRC歌词
终极歌词获取方案:163MusicLyrics让你轻松获取网易云和QQ音乐LRC歌词 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为寻找准确歌词而烦恼吗?…...

AI建站工具从0到1全流程保姆级攻略:零代码生成网站就这么简单
AI建站工具从0到1全流程保姆级攻略:零代码生成网站就这么简单被外包公司几万块的报价劝退?被老板催着下周上线活动页却连域名是什么都不清楚?别慌,用AI建站工具,不写一行代码、不学复杂技术,普通人也能在两…...

VLSI时代下74系列离散逻辑芯片的现代应用与设计实践
1. 从“胶水逻辑”到“系统粘合剂”:离散逻辑芯片的现代生存法则 在今天的数字电路设计领域,提起“7400系列”或者“74HC04”,很多年轻工程师的第一反应可能是博物馆里的古董,或者教科书上的历史章节。主流叙事已经被SoC、FPGA和高…...

从入门到精通:摄影测量学核心概念与应用全景解析
1. 摄影测量学入门指南:从零开始理解核心概念 第一次接触摄影测量学时,我被那些专业术语搞得晕头转向。直到有一次在公园用手机拍摄了一组树木照片,尝试用免费软件生成3D模型后,才真正理解了这门技术的魅力。摄影测量学本质上就是…...

Excel+ChatGPT函数实战:零代码实现语义理解与智能数据处理
1. 为什么说“在Excel里直接调用ChatGPT”不是噱头,而是真正在改写数据处理的工作流 你有没有过这样的时刻:盯着Excel表格里一列杂乱的客户反馈,想快速标出哪些是投诉、哪些是表扬,却卡在手动翻查、复制粘贴、反复试错公式上&…...