八股kafka(一)
目录
1、面试官:Kafka是如何保证消息不丢失
2、面试官:Kafka中消息的重复消费问题如何解决的
3、面试官:Kafka是如何保证消费的顺序性
4、面试官:Kafka的高可用机制有了解过嘛
5、面试官:解释一下复制机制中的ISR
6、面试官:Kafka数据清理机制了解过嘛
7、面试官:Kafka中实现高性能的设计有了解过嘛
1、面试官:Kafka是如何保证消息不丢失
候选人:
嗯,这个保证机制很多,在发送消息到消费者接收消息,在每个阶段都有可能会丢失消息,所以我们解决的话也是从多个方面考虑
第一个是生产者发送消息的时候,可以使用异步回调发送,如果消息发送失败,我们可以通过回调获取失败后的消息信息,可以考虑重试或记录日志,后边再做补偿都是可以的。同时在生产者这边还可以设置消息重试,有的时候是由于网络抖动的原因导致发送不成功,就可以使用重试机制来解决
第二个在broker中消息有可能会丢失,我们可以通过kafka的复制机制来确保消息不丢失,在生产者发送消息的时候,可以设置一个acks,就是确认机制。我们可以设置参数为all,这样的话,当生产者发送消息到了分区之后,不仅仅只在leader分区保存确认,在follwer分区也会保存确认,只有当所有的副本都保存确认以后才算是成功发送了消息,所以,这样设置就很大程度了保证了消息不会在broker丢失
第三个有可能是在消费者端丢失消息,kafka消费消息都是按照offset进行标记消费的,消费者默认是自动按期提交已经消费的偏移量,默认是每隔5s提交一次,如果出现重平衡的情况,可能会重复消费或丢失数据。我们一般都会禁用掉自动提价偏移量,改为手动提交,当消费成功以后再报告给broker消费的位置,这样就可以避免消息丢失和重复消费了
2、面试官:Kafka中消息的重复消费问题如何解决的
候选人:
kafka消费消息都是按照offset进行标记消费的,消费者默认是自动按期提交已经消费的偏移量,默认是每隔5s提交一次,如果出现重平衡的情况,可能会重复消费或丢失数据。我们一般都会禁用掉自动提价偏移量,改为手动提交,当消费成功以后再报告给broker消费的位置,这样就可以避免消息丢失和重复消费了
为了消息的幂等,我们也可以设置唯一主键来进行区分,或者是加锁,数据库的锁,或者是redis分布式锁,都能解决幂等的问题
3、面试官:Kafka是如何保证消费的顺序性
候选人:
kafka默认存储和消费消息,是不能保证顺序性的,因为一个topic数据可能存储在不同的分区中,每个分区都有一个按照顺序的存储的偏移量,如果消费者关联了多个分区不能保证顺序性
如果有这样的需求的话,我们是可以解决的,把消息都存储同一个分区下就行了,有两种方式都可以进行设置,第一个是发送消息时指定分区号,第二个是发送消息时按照相同的业务设置相同的key,因为默认情况下分区也是通过key的hashcode值来选择分区的,hash值如果一样的话,分区肯定也是一样的
4、面试官:Kafka的高可用机制有了解过嘛
候选人:
嗯,主要是有两个层面,第一个是集群,第二个是提供了复制机制
kafka集群指的是由多个broker实例组成,即使某一台宕机,也不耽误其他broker继续对外提供服务
复制机制是可以保证kafka的高可用的,一个topic有多个分区,每个分区有多个副本,有一个leader,其余的是follower,副本存储在不同的broker中;所有的分区副本的内容是都是相同的,如果leader发生故障时,会自动将其中一个follower提升为leader,保证了系统的容错性、高可用性
5、面试官:解释一下复制机制中的ISR
候选人:
ISR的意思是in-sync replica,就是需要同步复制保存的follower
其中分区副本有很多的follower,分为了两类,一个是ISR,与leader副本同步保存数据,另外一个普通的副本,是异步同步数据,当leader挂掉之后,会优先从ISR副本列表中选取一个作为leader,因为ISR是同步保存数据,数据更加的完整一些,所以优先选择ISR副本列表
6、面试官:Kafka数据清理机制了解过嘛
候选人:
嗯,了解过~~
Kafka中topic的数据存储在分区上,分区如果文件过大会分段存储segment
每个分段都在磁盘上以索引(xxxx.index)和日志文件(xxxx.log)的形式存储,这样分段的好处是,第一能够减少单个文件内容的大小,查找数据方便,第二方便kafka进行日志清理。
在kafka中提供了两个日志的清理策略:
第一,根据消息的保留时间,当消息保存的时间超过了指定的时间,就会触发清理,默认是168小时( 7天)
第二是根据topic存储的数据大小,当topic所占的日志文件大小大于一定的阈值,则开始删除最久的消息。这个默认是关闭的
这两个策略都可以通过kafka的broker中的配置文件进行设置
7、面试官:Kafka中实现高性能的设计有了解过嘛
候选人:
Kafka 高性能,是多方面协同的结果,包括宏观架构、分布式存储、ISR 数据同步、以及高效的利用磁盘、操作系统特性等。主要体现有这么几点:
消息分区:不受单台服务器的限制,可以不受限的处理更多的数据
顺序读写:磁盘顺序读写,提升读写效率
页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
零拷贝:减少上下文切换及数据拷贝
消息压缩:减少磁盘IO和网络IO
分批发送:将消息打包批量发送,减少网络开销
相关文章:
)
八股kafka(一)
目录 1、面试官:Kafka是如何保证消息不丢失 2、面试官:Kafka中消息的重复消费问题如何解决的 3、面试官:Kafka是如何保证消费的顺序性 4、面试官:Kafka的高可用机制有了解过嘛 5、面试官:解释一下复制机制中的ISR 6、面…...
SemCity: 一个应用于真实户外环境场景生成的3D Diffusion模型
论文标题: SemCity: Semantic Scene Generation with Triplane Diffusion 论文作者: Jumin Lee1, Sebin Lee1, Changho Jo, Woobin Im, Juhyeong Seon, Sung-Eui Yoon 项目地址:https://sglab.kaist.ac.kr/SemCity/ 前言: 该论…...

鸿蒙内核源码分析(互斥锁篇) | 互斥锁比自旋锁丰满多了
内核中哪些地方会用到互斥锁?看图: 图中是内核有关模块对互斥锁初始化,有文件,有内存,用消息队列等等,使用面非常的广.其实在给内核源码加注的过程中,会看到大量的自旋锁和互斥锁,它们的存在有序的保证了内核和应用程序的正常运行.是非常基础和重要的功能. 概述 自旋锁 和…...

MySQL之查询 拿下 * 。*
DQL数据查询语言 对上述的的查询操作进行代码演示(续上一篇学生表代码进行处理) 下面是上一篇的代码分享 下面进行简单的查询操作 字符串如果强行进行算数运算默认只为0 查询时常用的单行函数列举 未完待续...
领域,常见词汇)
目标检测(二阶段)领域,常见词汇
1、Backbone(主干网络) 定义: Backbone是目标检测模型的基础部分,通常是一个预训练的卷积神经网络(如ResNet、VGG、MobileNet等),负责从输入图像中提取多层特征图。这些特征图包含了不同尺度和抽象级别的信…...

区块链与人工智能哪个更有前景?
一、引言 随着科技的飞速发展,区块链技术和人工智能(AI)无疑是两大热门领域,各自以其独特的魅力吸引着全球的关注。两者虽源自不同的技术基础,却都预示着未来技术发展的无限可能。本文旨在探讨区块链与人工智能各自的前…...
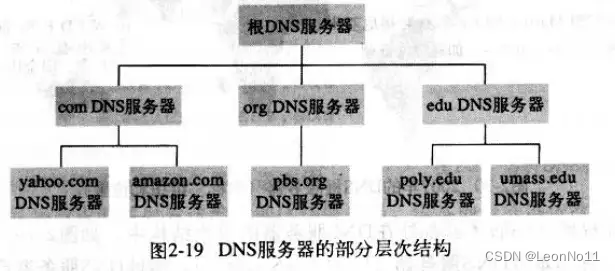
计算机网络【应用层】邮件和DNS
文章目录 电子邮件DNSDNS提供的服务:域名分级域名解析流程DNS资源记录DNS服务器类型 电子邮件 使用SMTP协议发送邮件之前,需要将二进制多媒体数据编码为ASCII码SMTP一般不使用中间邮件服务器发送邮件,如果收件服务器没开机,那么会…...
js遍历数组将数组中属性名相同的属性值组成新的数组再转化成字符串并换行(js换行和html换行不同)
{label: 告警结果,display:true, html:true,formatter:(row)>{let list ""if(row.funRes&&row.funRes.length){let propName value; list row.funRes.map(obj > {return <span style"vertical-align: text-top;padding-right: 2px;">…...

Ai绘画|如何安装使用秋叶comfyui整合包,手把手详细教程
B 站的秋叶大佬在 1 月份就已经发布了 comfy ui 的整合包。用户将压缩包下载后,能够一键启动 comfy ui。其便利性与之前的 webui 整合包如出一辙。然而在整合包下载完成后,新手或许会遭遇插件以及模型缺失的情况,同时也不清楚该如何运行工作流…...
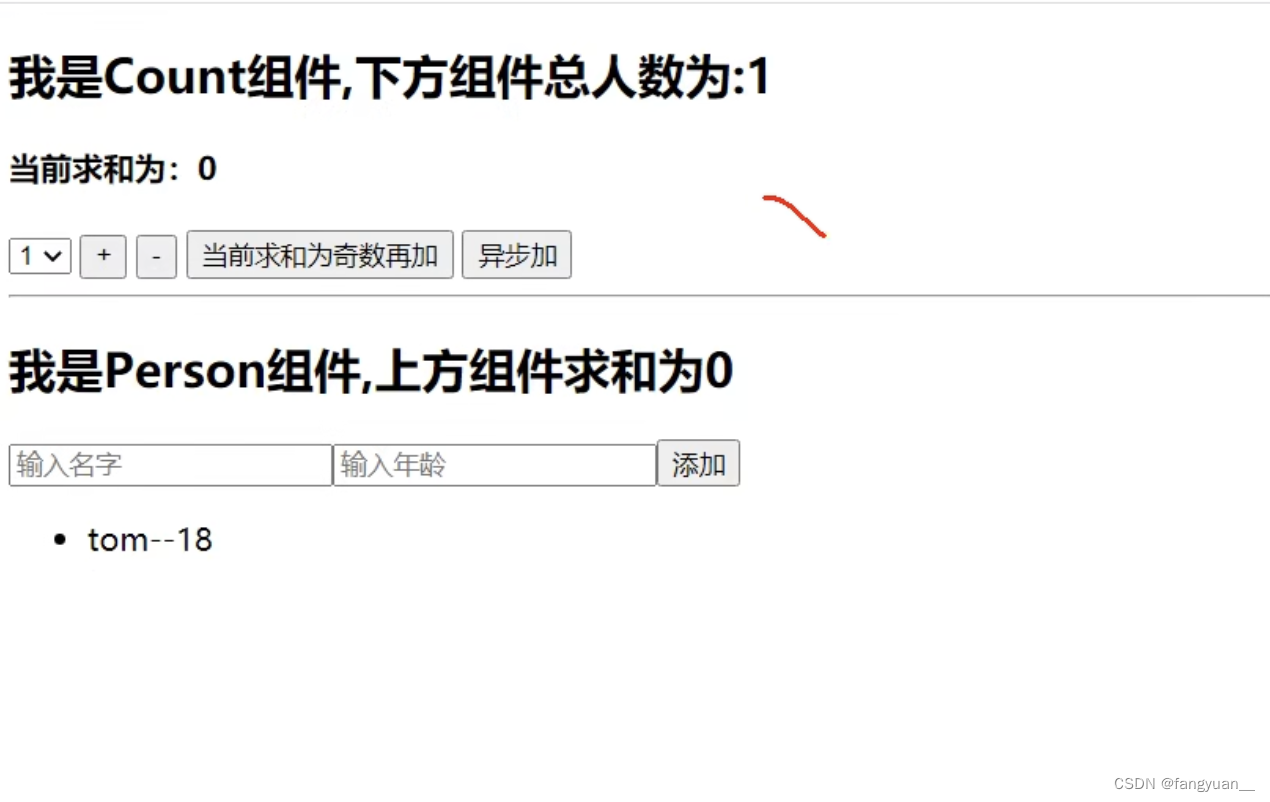
【React】React-redux多组件间的状态传递
效果(部分完整代码在最底部): 编写 Person 组件 上面的 Count 组件,已经在前面几篇写过了,也可以直接翻到最底部看 首先我们需要在 containers 文件夹下编写 Person 组件的容器组件 首先我们需要编写 index.jsx 文件…...
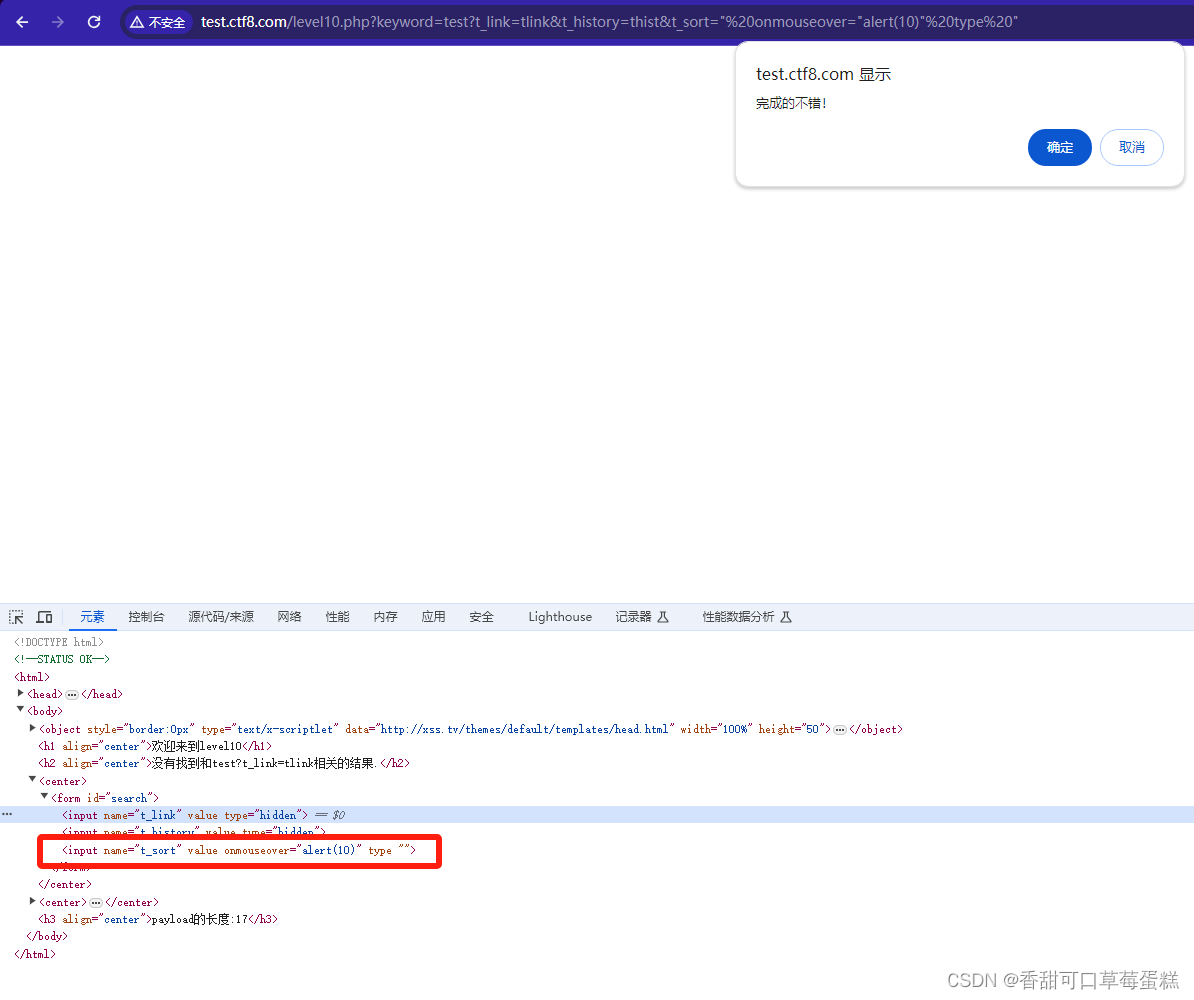
XSS-Labs 靶场通过解析(上)
前言 XSS-Labs靶场是一个专门用于学习和练习跨站脚本攻击(XSS)技术的在线平台。它提供了一系列的实验场景和演示,帮助安全研究人员、开发人员和安全爱好者深入了解XSS攻击的原理和防御方法。 XSS-Labs靶场的主要特点和功能包括:…...
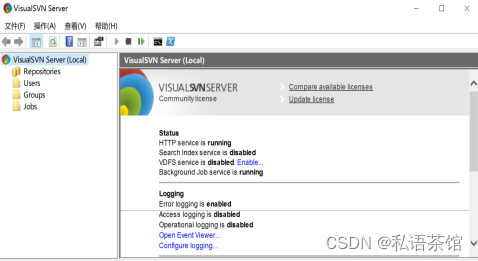
开源版本管理系统的搭建一:SVN服务端安装
作者:私语茶馆 1.Windows搭建SVN版本管理系统 点评:SVN本身非常简洁易用,VisualSVN文档支撑非常好,客户端TortoiseSVN非常专业。5星好评。 1.1.SVN概要和组成 背景介绍 Svn是一个开源版本管理系统,由CollabNet公司…...

Fastfetch一个类似neofetch的系统信息工具软件
1. 使用默认配置运行:fastfetch 2. 使用所有支持的模块运行,并找到您感兴趣的内容:fastfetch -c all.jsonc 3. 查找 fastfetch 检测到的所有数据:fastfetch -s <模块> --format json 4. 显示帮助信息:fastfetch …...

DV试验和PV试验介绍
1 基本介绍 DV试验 DV试验,全称Design Verification Test,又称设计验证试验,是指在产品设计阶段,对产品的设计进行验证的一种试验方法。DV试验的主要目的是为了验证产品的设计是否满足功能和性能要求,并找出设计中的…...
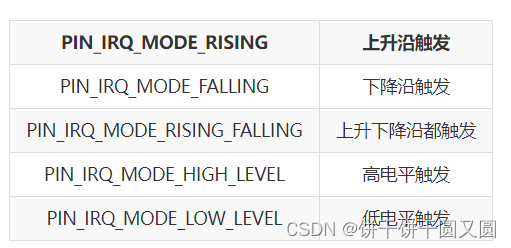
RTT PIN设备学习
获取GPIO编号 GET_PIN(port, pin)#define LED_BLUE_PIN GET_PIN(A, 0)设置引脚模式 void rt_pin_mode(rt_base_t pin, rt_base_t mode);设置引脚电平 void rt_pin_write(rt_base_t pin, rt_base_t value);rt_base_t pin 同上, 为引脚编号,尽量通过宏定…...
)
Spring Boot面试知识点总结(经典15问)
Spring Boot面试知识点总结(问答合集) 文章目录 Spring Boot面试知识点总结(问答合集)一、Spring Boot简介二、核心特性三、面试问题及答案问题1:Spring Boot的核心配置文件是什么?问题2:Spring…...
安卓手机原生运行 ARM Ubuntu 24.04 桌面版(一)
本篇文章,聊一聊尝试让安卓手机原生运行 Ubuntu,尤其是运行官方未发布过的 ARM 架构的 Ubuntu 24.04 桌面版本。 写在前面 最近的几篇文章,都包含了比较多的实操内容、需要反复的复现验证,以及大量的调试过程,为了不…...
AHB---数据总线
1. 数据总线 为了实现AHB系统,需要独立的读写数据总线。虽然推荐的最小数据总线宽度被指定为32位,但这可以根据数据总线宽度进行更改。 数据总线包含以下部分: HWDATAHRDATAEndianness(字节序) 1.1 HWDATA 在写传输…...

「51媒体」企业单位新闻稿件考核,怎么发布
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 电力税务企事业单位部门等单位提供了新闻稿件,如何在一些重点媒体进行宣发呢: 精准锁定发布媒体 了解考核要求:仔细阅读宣传任务名单,了解…...

「 网络安全常用术语解读 」SBOM主流格式CycloneDX详解
CycloneDX是软件供应链的现代标准。CycloneDX物料清单(BOM)可以表示软件、硬件、服务和其他类型资产的全栈库存。该规范由OWASP基金会发起并领导,由Ecma International标准化,并得到全球信息安全界的支持,如今CycloneD…...

Vulkan学习笔记
顺序很重要:#define 必须在 #include <GLFW/glfw3.h> 之前出现,否则不起作用。作用:当 GLFW 的头文件看到这个宏被定义后,它就会知道你需要 Vulkan 支持,并自动执行 #include <vulkan/vulkan.h>࿰…...

保姆级教程:在Ubuntu 22.04上从源码编译DPDK TestPMD并跑通第一个包转发测试
从零构建DPDK TestPMD:Ubuntu 22.04实战指南与性能调优 当你第一次听说DPDK能实现百万级数据包转发时,是否好奇这背后的技术魔法?本文将带你用一台普通Ubuntu服务器,亲手搭建这套高性能网络处理框架。不同于官方文档的抽象描述&am…...

Python全栈实战:前后端分离开发核心要点
后端API搭建FastAPI与Flask是Python全栈开发的主流后端框架选择。两者均支持RESTful API开发,但适用场景不同:FastAPI代码示例(高性能方案):from fastapi import FastAPI app FastAPI()app.get("/items/{item_id…...

机器学习之随机森林详解
摘要随机森林(Random Forest)是一种基于Bagging集成学习思想的 ensemble method,通过构建多棵决策树并综合其预测结果来实现分类和回归任务。本文详细介绍了随机森林的核心原理、关键超参数、OOB误差估计机制,以及其在特征重要性分…...

手把手教你排查和修复Gradle Daemon启动失败的NoClassDefFoundError
深度解析Gradle Daemon启动失败的NoClassDefFoundError排查方法论 当你正专注于开发进度,突然在终端看到一行刺眼的红色错误提示:"Could not initialize class org.codehaus.groovy.vmplugin.v7.Java7",Gradle构建进程戛然而止。这…...

从PTA到项目实战:用C++实现矩阵乘法的几种姿势与性能小谈
从PTA到项目实战:用C实现矩阵乘法的几种姿势与性能小谈 矩阵乘法作为线性代数中的基础运算,在计算机科学领域有着广泛的应用场景。从学生时代的编程练习题到工业级的高性能计算,矩阵乘法的实现方式直接影响着程序效率。本文将带您从基础的PTA…...

终极跨平台语音识别解决方案:sherpa-onnx全平台部署实战指南
终极跨平台语音识别解决方案:sherpa-onnx全平台部署实战指南 【免费下载链接】sherpa-onnx Speech-to-text, text-to-speech, speaker diarization, speech enhancement, source separation, and VAD using next-gen Kaldi with onnxruntime without Internet conne…...

最新OpenClaw 2.7.1 Windows 环境快速部署教程
Windows 一键部署 OpenClaw v2.7.1 教程|5 分钟搭建本地 AI 智能体 在开源 AI 工具持续更新的当下,OpenClaw(小龙虾)凭借本地运行、零代码操控、自动化执行等特点,成为广受用户欢迎的本地 AI 智能体,GitHu…...

用Python和Matlab可视化高斯分布融合:从理论到代码,理解卡尔曼滤波的‘信任权重’
高斯分布融合的可视化实践:用Python与Matlab揭秘卡尔曼滤波的信任机制 在传感器融合、机器人定位和金融预测等领域,我们常常需要将多个不确定信息源的数据进行整合。高斯分布(正态分布)作为描述不确定性的黄金标准,其融…...

League Akari技术架构解析:基于LCU API的英雄联盟客户端自动化工具实现
League Akari技术架构解析:基于LCU API的英雄联盟客户端自动化工具实现 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Aka…...