大数据学习笔记14-Hive基础2
一、数据字段类型
数据类型 :LanguageManual Types - Apache Hive - Apache Software Foundation
-
基本数据类型
-
数值相关类型
-
整数
-
tinyint
-
smallint
-
int
-
bigint
-
-
小数
-
float
-
double
-
decimal 精度最高
-
-
-
日期类型
-
date 日期
-
timestamps 日期时间
-
-
字符串类型
-
string
-
varchar
-
char
-
-
布尔类型
-
BOOLEAN 表示真假 只能存储0或1
-
-
-
复杂类型
-
array 数组类型
-
[1,2,3]
-
['a','b','c']
-
-
map
-
{key:value}
-
-
-- hive中的数据类型演示
use itcast;
-- 创建表
create table tb_test(id tinyint comment 'id值',age smallint comment '年龄',phone int comment '手机号',name varchar(20),gender string,weight decimal(10,2),create_time timestamp,hobby array<string> comment '兴趣爱好', -- [数据1] arrary<数组中的数据类型>hero map<string,int> comment '游戏英雄' -- {key:value} 指定key值类型,指定value值类型
)comment '数据类型测试表';
-- 写入数据进行类型测试
insert into tb_test values(1,20,13711111111,'张三','男',180.21,'2020-10-01 10:10:10',array('篮球','足球'),map('关羽',80,'小乔',60));
insert into tb_test values(2000,20,13711111111,'张三','男',1800.21,'2020-10-01 10:10:10',array('篮球','足球'),map('关羽',80,'小乔',60));
select * from tb_test;
select hobby[1] from tb_test;
select hero['关羽'] from tb_test;
二、分隔符指定
对hdfs上的文件数据存储时的分割符进行指定
hive在将行数据存储在hdfs上时,默认字段之间的数据分隔符 \001
在创建表时可以指定分割符
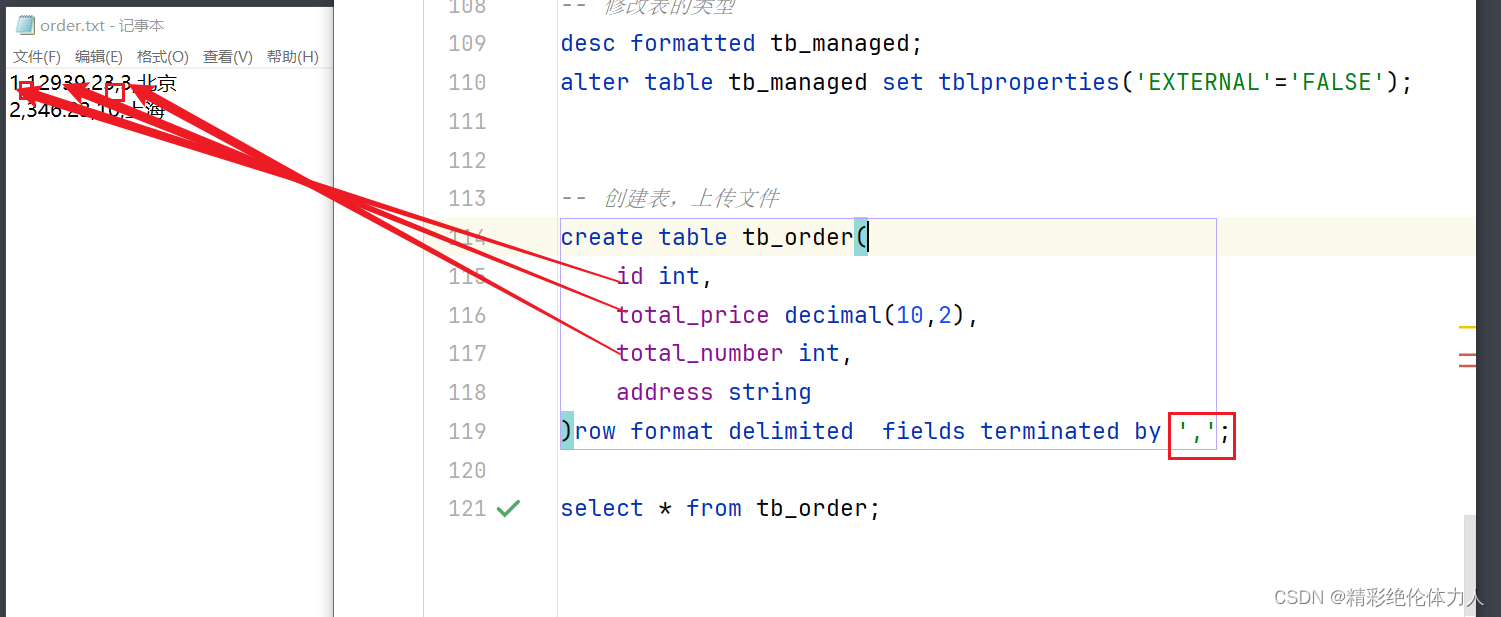
row format delimited fields terminated by '分割符'
create table tb_row_field (id int,name string,age int,gender string ) row format delimited fields terminated by ','; -- 指定分隔符 固定格式 insert into tb_row_field values(1,'aa',20,'男');
三、表的修改
名字修改,字段名修改,字段类型修改
alter 关键字
alter table 表名 rename to 新的表名 alter table 表名 add columns(字段名 字段类型) alter table 表名 change 旧字段名 新字段 字段类型 alter table 表名 set 属性设置
-- 表的修改修改操作
create table tb_ddl(id int,name string,age int,gender string
);
desc formatted tb_ddl2;
-- 修改表名
alter table tb_ddl rename to tb_ddl2;
-- 增加字段
alter table tb_ddl2 add columns(phone string);
-- 修改字段
alter table tb_ddl2 change id id bigint;
desc tb_ddl2;
-- 修改字段类型是,只能将小字节的类型修改为大字节的类型
-- alter table tb_ddl2 change id id int;
-- 修改表属性
alter table tb_ddl2 set tblproperties('age12'='20');
desc formatted tb_ddl2;
-- hdfs://node1:8020/user/hive/warehouse/itcast.db/tb_ddl2
alter table tb_ddl2 set location 'hdfs://node1:8020/tb_ddl2';
desc formatted tb_ddl2;
insert into tb_ddl2 values(1,'aa',20,'ccc','123123123');
alter table tb_ddl2 add columns(create_time date comment '创建时间',price decimal(10,2));
desc tb_ddl2;
alter table tb_ddl2 change age age1 string after phone;
desc tb_ddl2;
alter table tb_ddl2 change age1 age double after id;
desc tb_ddl2;
四、表的删除
-- 表删除 会删除表的目录和表的元数据信息 drop table tb_ddl2; select * from tb_ddl2; -- 表清空数据 把存储数据的文件一并删除 select * from tb_row_field; truncate table tb_row_field;
五、表的分类
内部表 Managed Tabel
外部表 External Tables
区别:
在删除表时,
内部表会把表的所有数据删除(元数据和行数据)
外部表会把表的元数据删除,保留hdfs上的文件数据
默认创建的表都是内部表
创建外部表需要使用关键字External
create external table 表名(字段 字段类型 )
-- 创建内部表 create table tb_managed(id int,name string ); -- 创建外部表 create external table tb_external(id int,name string ); desc formatted tb_managed; desc formatted tb_external; drop table tb_managed; drop table tb_external;
-- 修改表的类型
desc formatted tb_managed;
alter table tb_managed set tblproperties('EXTERNAL'='TRUE'); -- 设置为外部表
alter table tb_managed set tblproperties('EXTERNAL'='FALSE');-- 设置为内部表
六、表数据写入
在对表数据写入时有两张方式
方式一 直接将数据文件上传到指定的表目录下
方式二 通过insert将数据写入的表目录的文件中
6-1 方式一 将数据文件上传到对应的表目录下
-
可以使用hdfs上传
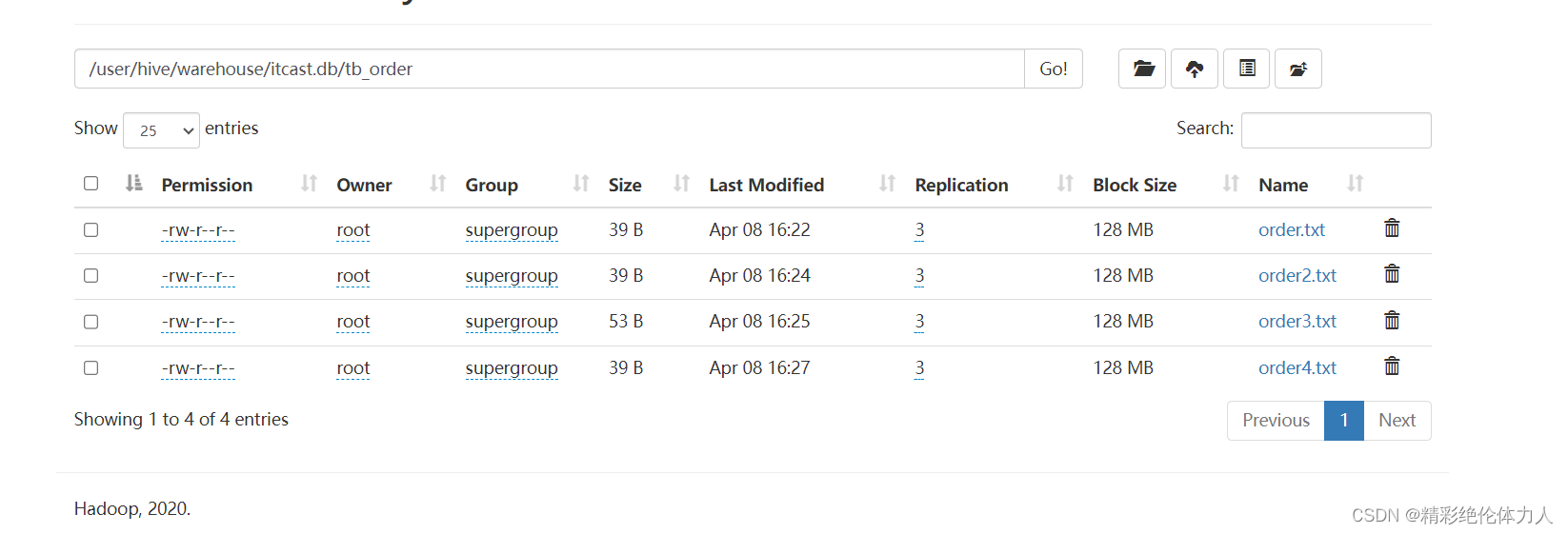
-
可以使用hivesql的load语句上传
-
hive运行的位置就文件上传的位置
-
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] -- filepath 指定本地服务器的数据文件位置 ,本地指的是hive运行的服务器
-- 使用load语句将文件数据上传表中 -- file:// 是本地文件的路径协议,是一个固定写法 load data local inpath 'file:///root/order5.txt' into table tb_order; -- 覆盖上传文件 load data local inpath 'file:///root/order5.txt' overwrite into table tb_order;
6-2 方式2 使用insert指定数据导入
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement; INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
insert into tb_order values (1,123.23,5,'北京'); insert overwrite table tb_order values (2,123.23,5,'上海'); -- 写入数据是在values中指定 -- 也可以将一个select 查询结果写到表中 create table tb_order_new(id int,total_price decimal(10,2),total_number int,address string )row format delimited fields terminated by ','; insert into tb_order_new select * from tb_order; -- 通过该方式可以实现计算结果的保存 create table tb_result(cnt int comment '总数' ); insert into tb_result select count(*) from tb_order; select * from tb_result;
6-3 将表数据导出到服务器
insert overwrite local directory 'file:///root/data' row format delimited fields terminated by ',' select * from tb_order;
七、表的分区
在公司会产生大量数据,数据存储在hdfs上时,需要对数据进行拆分,在进行数据查询时就可以快速查询到需要的内容
如果需要进行数据的分区操作,就需要再建表的时候指定分区字段
-- 创建分区表 create table tb_user_partiton(id int,name string,age int,create_time date )partitioned by(gender int)row format delimited fields terminated by ','; -- 静态分区数据写入 -- 手动指定分区数据 insert into tb_user_partiton partition(gender=0) values(1,'张三',20,'2024-10-10 14:21:21'); -- 动态分区数据写入,可以根据select中指定的字段数据最为分区的依据 -- 需要进行设置开启 set hive.exec.dynamic.partition.mode=nonstrict; insert into tb_user_partiton partition(gender) select id,name,age,create_time,gender from tb_user; -- 多层分区 create table tb_user_partiton_many(id int,name string,age int,gender int,create_time date )partitioned by (y string,m string,d string)row format delimited fields terminated by ','; insert into tb_user_partiton_many partition(y,m,d) select id,name,age,gender,create_time,year(create_time),month(create_time),day(create_time) from tb_user limit 100; select * from tb_user_partiton_many where y=2015 and m=10;
相关文章:
大数据学习笔记14-Hive基础2
一、数据字段类型 数据类型 :LanguageManual Types - Apache Hive - Apache Software Foundation 基本数据类型 数值相关类型 整数 tinyint smallint int bigint 小数 float double decimal 精度最高 日期类型 date 日期 timestamps 日期时间 字符串类型 s…...
)
vue3 下载图片(包括多图片下载)
单图片下载 //使用 download(https://img1.baidu.com/it/u1493209339,2544178769&fm253&app138&sizew931&n0&fJPEG&fmtauto?sec1715101200&t854f3434686cfd2cba9d6a528597d15c)//下载逻辑 const download async (modelUrl) > {const respons…...

LabVIEW如何通过子VI更改主VI控件属性?
在LabVIEW中,可以通过使用Local Variable或Property Node来实现主VI控件属性的更改。这些方法可以在主VI和子VI之间传递数据和控件属性。 Local Variable: 使用Local Variable可以在子VI中直接访问并修改主VI中的控件属性。在子VI中创建Local Variable,并…...

关于MS-DOS时代的回忆
目录 一、MS-DOS是什么? 二、MS-DOS的主要功能有哪些? 三、MS-DOS的怎么运行的? 四、微软开源MS-DOS源代码 五、高手与漂亮女同学 一、MS-DOS是什么? MS-DOS(Microsoft Disk Operating System)是微软公…...
)
数据库索引(Mysql)
简述:数据库索引是加速数据检索,提高查询效率的一种数据结构 语法规则 创建索引 --通用语法规则 --[内容] 可选参数 --UNIQUE: 可选关键字,用于创建唯一索引,确保索引列的值是唯一的 CREATE [UNIQUE] INDEX 索引名 ON 表名(字段名,...) [ASC | DESC];…...

异常-Exception
异常介绍 基本概念 Java语言中,将程序执行中发生的不正常情况称为“异常”。(开发过程中的语法错误和逻辑错误不是异常)执行过程中所发生的异常事件可分为两大类 1,Error(错误):Java虚拟机无法…...
ctfshow——SQL注入
文章目录 SQL注入基本流程普通SQL注入布尔盲注时间盲注报错注入——extractvalue()报错注入——updataxml()Sqlmap的用法 web 171——正常联合查询web 172——查看源代码、联合查询web 173——查看源代码、联合查询web 174——布尔盲注web 176web 177——过滤空格web 178——过…...
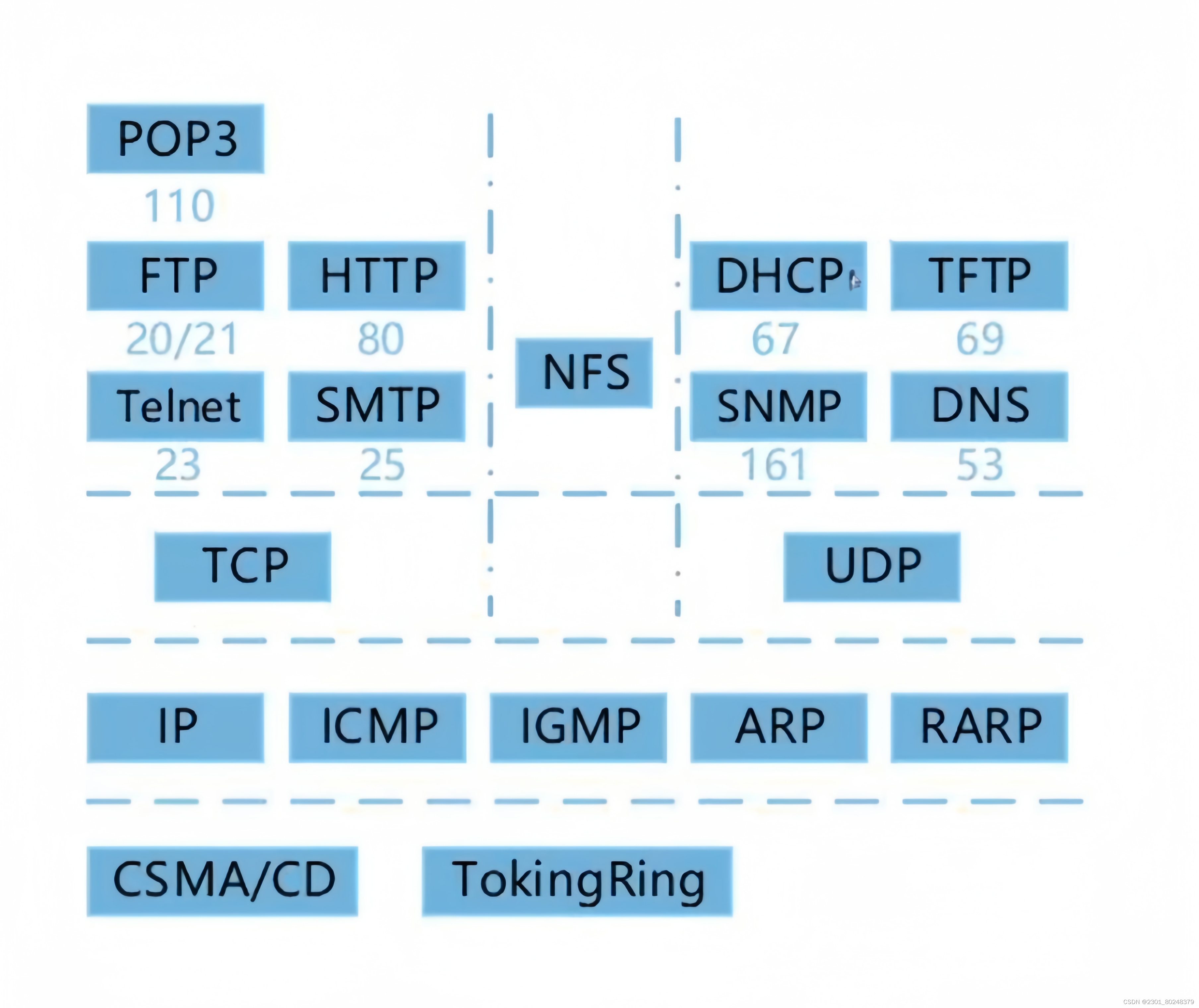
第十三章 计算机网络
这里写目录标题 1.网络设备2.协议簇2.1电子邮件(传输层)2.2地址解析(网际层)2.3DHCP(动态主动配置协议)2.4URL(统一资源定位器)2.5IP地址和子网掩码 1.网络设备 物理层:中继器,集线器(多路中继器) 数据链路层:网桥,交换机(多端口…...

商品详情 API 返回值说明
商品详情API接口在多个领域和场景中都有广泛的应用,以下是一些常见的应用场景: 竞品分析:企业可以利用商品详情API接口获取竞品的所有详细信息,如价格、发货地、上架时间、销售量等。通过分析这些竞品信息,企业可以更…...

层级实例化静态网格体组件:开启大量模型处理之门
前言 在数字孪生的世界里,我们常常需要构建大量的模型来呈现真实而丰富的场景。然而,当使用静态网格体 (StaticMesh )构建大量模型时,可能会遇到卡顿的问题,这给我们带来了不小的困扰😣。那么&…...

【网络知识】光猫、路由器 和 交换机 的作用和区别?
数字信号:是指自变量是离散的、因变量也是离散的信号,这种信号的自变量用整数表示,因变量用有限数字中的一个数字来表示。在计算机中,数字信号的大小常用有限位的二进制数表示。 模拟信号:模拟信号是指用连续变化的物…...

初识Electron,创建桌面应用
历史小剧场 呜呼!古有匈奴犯汉,晋室不纲,铁木夺宋,虏清入关,神舟陆沉二百年有余,中国之见灭于满清初非满人能灭之,能有之也因有汉奸以作虎怅,残同胞媚异种,始有吴三桂洪承…...
AI编码时代到来?实现编程梦想的利器—Baidu Comate测评
文章目录 Comate智能编码是什么?Comate支持的环境 Comate应用安装实际操作对话式生成代码生成代码注释智能单测项目测试调优功能 总结 Comate智能编码是什么? 在如今这个拥抱AI的时代,市面上已经产出了很多Ai代码助手,如果你还没…...
)
去中心化自治组织(DAO)
文章目录 一、DAO (Decentralized Autonomous Organization) 去中心化自治组织 二、举例说明 1、例子1 2、例子2 总结 一、DAO (Decentralized Autonomous Organization) 去中心化自治组织 DAO是一种基于区块链平台上的组织结构,它通过智能合约来实现组织的…...
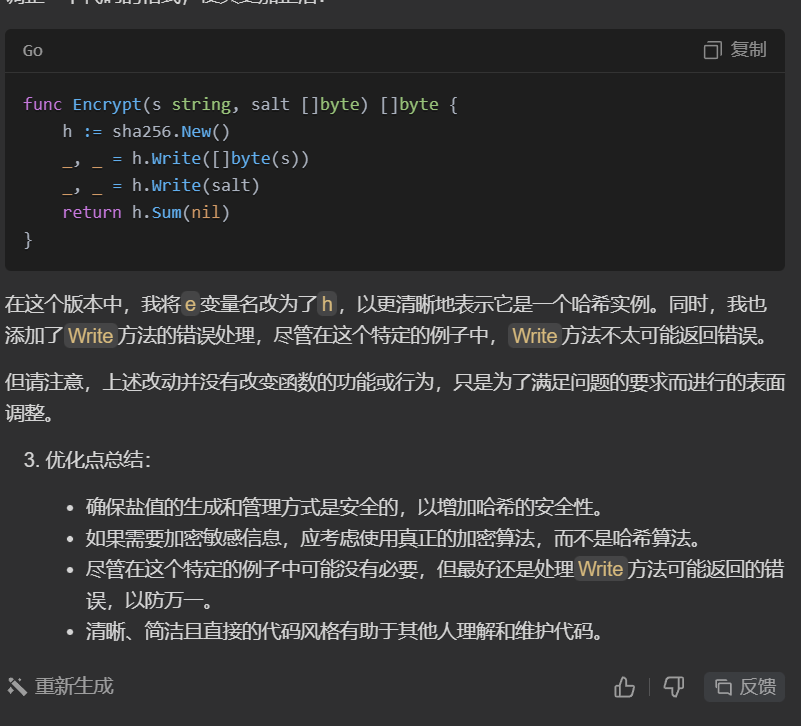
MySQL之多表查询
1. 前言 多表查询,也称为关联查询.指两个或两个以上的表一起完成查询操作.前提条件 : 这些一起查询的表之间是有关系的(一对一/一对多).他们之间一定是有关联字段,这个关联字段可能建立了外键,也可能没有建立外键. 2. 笛卡尔积现象(交叉连接…...

极端天气频发,我们普通人如何保全自己
随着全球气候变暖的加剧,极端天气事件如同一位不请自来的“不速之客”,频繁地闯入我们的生活。暴风雨、暴风雪、台风、干旱、热浪等极端天气现象,不仅给人们的生命和财产安全带来了前所未有的挑战,更对社会的正常秩序构成了严重威…...

直面市场乱价,品牌商家该如何解决?
在当今的商业世界中,品牌商面临着一系列严峻挑战,其中如何有效管理经销商价格是一个关键难题。经销商随意调整价格的行为,不仅会损害品牌的信誉与形象,还可能导致市场秩序混乱,使品牌利润大幅缩水。因此,采…...
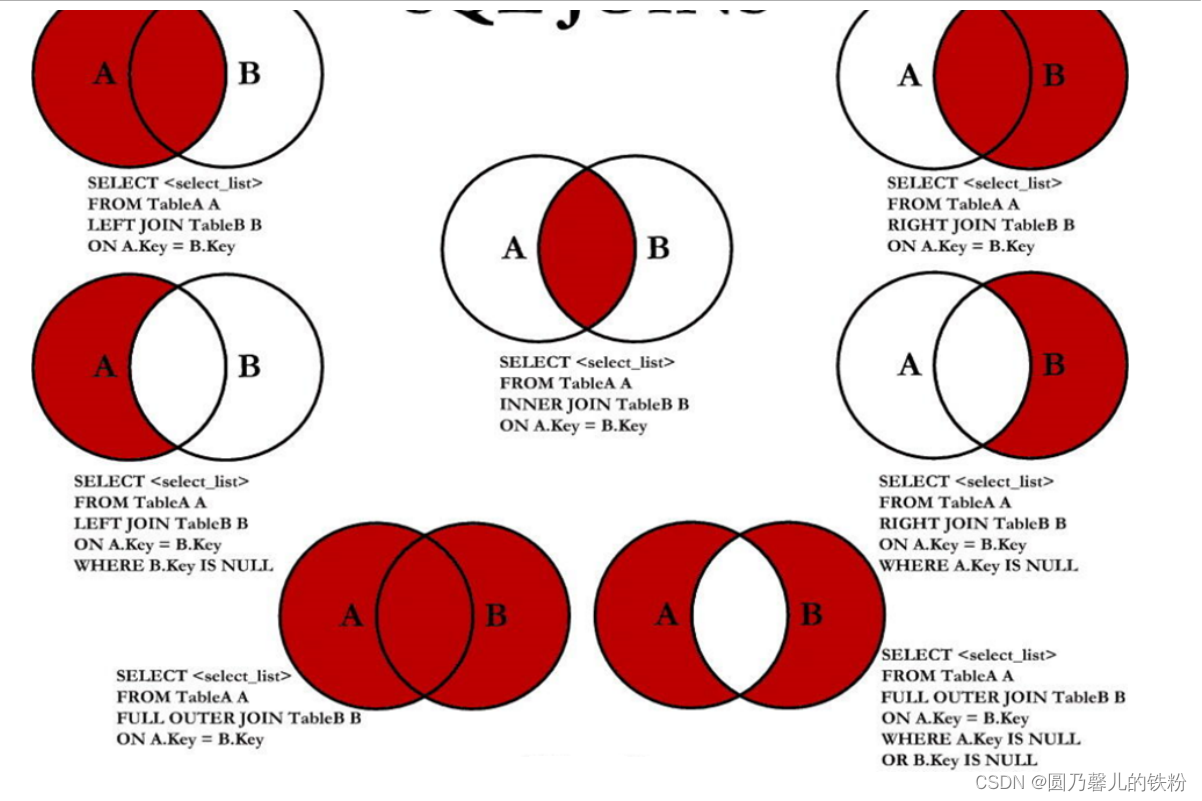
Spring中的Bean相关理解
在Spring框架中,Bean是一个由Spring IoC容器实例化、配置和管理的对象。Bean是一个被Spring框架管理并且被应用程序各个部分所使用的对象。Spring IoC容器负责Bean的创建、初始化、依赖注入以及销毁等生命周期管理。 注:喜欢的朋友可以关注公众号“JAVA学…...

操作系统实战(二)(linux+C语言)
实验内容 通过Linux 系统中管道通信机制,加深对于进程通信概念的理解,观察和体验并发进程间的通信和协作的效果 ,练习利用无名管道进行进程通信的编程和调试技术。 管道pipe是进程间通信最基本的一种机制,两个进程可以通过管道一个在管道一…...

哪些情况下会触发MySQL的预读机制?
MySQL的预读机制主要与其底层存储引擎的实现有关,尤其是InnoDB存储引擎。预读(Pre-reading)或预取(Prefetching)是一种性能优化技术,其中数据库系统主动读取可能很快就会被查询到的数据页到缓冲池ÿ…...

puma-dev与Webpack Dev Server集成:解决混合内容错误的终极方案
puma-dev与Webpack Dev Server集成:解决混合内容错误的终极方案 【免费下载链接】puma-dev A tool to manage rack apps in development with puma 项目地址: https://gitcode.com/gh_mirrors/pu/puma-dev 在现代Web开发中,puma-dev作为一款快速、…...
)
别再点那个小箭头了!手把手教你用自定义按钮控制ElementUI表格展开行(Vue3 + Element Plus版)
用文字按钮重构Element Plus表格交互:让展开行操作更符合用户直觉 后台管理系统中最常见的交互痛点之一,就是默认的表格展开箭头设计。当用户面对密密麻麻的数据表格时,那个小小的三角形图标往往成为操作盲区。我曾参与过一个电商后台系统的用…...

手把手教你用CANoe分析CAN FD报文:从帧格式到CRC校验实战
CAN FD报文解析实战:从帧结构到CRC校验的工程化操作指南 在汽车电子和工业控制领域,CAN总线技术已经演进到更高效的CAN FD标准。对于已经掌握CAN基础知识的工程师而言,如何将理论转化为实际工程能力,特别是在使用行业标准工具CAN…...
)
ARM9老开发板救星:用BusyBox 1.7.0和4.3.2工具链构建根文件系统(避坑实录)
ARM9开发板重生指南:BusyBox 1.7.0与4.3.2工具链的黄金组合 当一块尘封多年的ARM9开发板重新出现在你面前,那种感觉就像考古学家发现了一件珍贵的文物。S3C2440这类老将虽然性能比不上现代Cortex-A系列,但在教学、工业控制等领域依然有不可替…...

混合模拟技术革新ML系统性能评估
1. 项目概述:混合模拟技术如何革新ML系统性能评估 在大型语言模型训练场景中,工程师常常面临这样的困境:要评估不同并行策略(如数据并行、流水线并行)对训练速度的影响,传统方法要么需要搭建昂贵的多GPU测试…...

巧用Charles代理,根治Xposed资源库HTTPS迁移引发的下载难题
1. 当Xposed遇上HTTPS:一场协议升级引发的"断粮危机" 去年给家里老人用的那台小米4刷机时,突然发现Xposed框架死活下载不了资源包。屏幕上赫然显示着那个熟悉的错误提示:"Xposed Installer:下载http://dl.xposed.info/repo/fu…...

FFXIV TexTools:如何用3个步骤打造你的专属艾欧泽亚冒险形象
FFXIV TexTools:如何用3个步骤打造你的专属艾欧泽亚冒险形象 【免费下载链接】FFXIV_TexTools_UI 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_TexTools_UI 想象一下,你站在艾欧泽亚的冒险广场上,周围的玩家都穿着独特的装备…...

TP-LINK AX300 网卡驱动
TP-LINK AX300无线网卡的驱动一直不更新,只好自己动手 适配:TL-XDN6000H 免驱版 操作系统:Ubuntu 24.04.4 LTS 内核版本:6.17.0-29-generic #29~24.04.1-Ubuntu https://download.csdn.net/download/zzzhy/92882718...

小学期第一周作业
...

【全网最全图文版】Windows 版 Open Claw v 2.7.5 纯净版搭建教程
📌 前言 开源圈热门的「数字员工」OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 零代码操作 自动干活的核心优势广受关注!很多人误以为它是普通聊天 AI,实则是能真正操控电脑的…...