FineReport高频面试题及参考答案
FineReport是一款利用什么语言开发的报表工具?
FineReport是一款基于Java语言开发的报表工具。Java是一种广泛使用的编程语言,特别适合于跨平台的软件开发。FineReport利用Java语言的诸多优势,如稳定性、安全性、可移植性和强大的网络功能,构建了一个功能丰富且高效的报表设计和展示平台。通过Java,FineReport能够为用户提供服务器端的数据处理和客户端的交互式报表展示,支持多种数据源的连接,以及实现复杂的业务逻辑和数据处理需求。
在FineReport中,以下哪些数据库类型是支持的?
FineReport支持多种数据库类型,包括但不限于关系型数据库如MySQL、Oracle、SQL Server、DB2,以及非关系型数据库如MongoDB。此外,FineReport还能够连接到一些特定的数据源,如SAP系统、Excel文件、文本文件等。这种广泛的数据库支持能力使得FineReport能够满足不同行业和不同规模企业的需求,帮助企业实现数据集成、报表生成和数据分析。
FineReport报表工具必须购买激活码后才能使用,这个说法正确吗?
这个说法不完全正确。FineReport提供了不同的使用模式,包括试用版和正式版。试用版通常允许用户在一定时间范围内免费体验软件的所有或部分功能,而正式版则需要购买激活码来解锁全部功能并继续使用。然而,即使在试用版过期后,用户仍然可以使用FineReport的一些基本功能,只是会有一些限制,例如功能模块的限制或并发用户数的限制。购买激活码后,用户可以享受到完整的功能支持和官方的技术服务。
在FineReport中,以下哪些方式属于预览模式?
FineReport提供多种预览模式以适应不同的查看和交互需求。这些预览模式包括:
- 分页预览:模拟纸张分页的效果,适用于打印预览。
- 填报预览:用于填报功能的模板,允许用户填写和提交数据。
- 数据分析:提供数据的筛选、排序、汇总等功能,适用于数据的深入分析。
- 移动端预览:优化报表布局以适应移动设备的显示。
- 新填报预览:改进的填报预览模式,提供更好的用户体验和功能。 这些预览模式使得FineReport能够灵活地应用于不同的业务场景和用户需求。
以下哪些是访问帮助文档的方式?
访问FineReport帮助文档的方式有多种,包括:
- 设计器中社区菜单下的帮助文档:通过FineReport设计器的内置菜单,可以直接访问到帮助文档。
- 直接访问官方帮助文档网站:通过浏览器访问http://help.finereport.com,获取详细的帮助信息。
- 论坛首页的FR区帮助文档:在FineReport的官方论坛中,也有帮助文档的链接。
- 官方首页的学习园地帮助文档:在FineReport的官方网站上,通常会有一个专门的学习园地区域,提供帮助文档和其他学习资源。 这些方式为用户提供了便捷的获取帮助和学习资源的途径,有助于用户更好地理解和使用FineReport。
数据集类型包括以下哪几种?
FineReport支持多种数据集类型,主要包括以下几种:
- 数据库查询数据集:这是最常见的数据集类型,用于连接数据库并执行SQL查询。
- 内置数据集:用于处理一些不需要外部数据源的计算和逻辑,如系统内置的参数或变量。
- 文件数据集:允许用户从文本文件、Excel文件、XML文件等导入数据。
- SAP数据集:专门用于从SAP系统中提取数据。
- 存储过程:执行存储在数据库中的存储过程以获取数据。
- 多维数据库:用于连接OLAP服务器进行数据分析。
- 关联数据集:可以与其他数据集关联,用于更复杂的数据关联和查询。
- 树数据集:用于处理具有层级关系的数据,如组织架构图。 这些数据集类型使得FineReport能够适应各种数据源和业务场景,提供灵活的数据集成和报表生成能力。
文件数据集只能连接本地文件,这个说法正确吗?
这个说法是错误的。FineReport的文件数据集不仅可以连接本地文件,还可以连接网络位置或Web服务上的文件。这意味着用户可以通过文件数据集访问局域网内共享的文件、互联网上通过URL访问的文件,或者通过Web服务接口动态生成的数据文件。这种灵活性使得FineReport可以更好地集成不同来源的数据,支持更广泛的应用场景。
当一个组织人员层级数较多时,我们可以使用哪种数据集进行简化操作?
当组织人员层级数较多时,可以使用树数据集进行简化操作。树数据集专为处理层级结构化的数据而设计,能够很好地表示和管理组织架构、产品分类等具有层级关系的数据。使用树数据集,用户可以方便地实现人员或数据的分级展示、汇总和分析,同时简化了数据的查询和报表的设计过程。它通常与树状的报表块结合使用,以直观地展示层级数据,并提供如展开/收起子节点等交互功能。
FineReport目前支持的文件数据集类型有哪些?
FineReport支持多种类型的文件数据集,包括:
- 文本数据集:可以连接和导入纯文本格式的文件,如TXT或CSV文件。
- Excel数据集:支持连接和导入Microsoft Excel格式的文件,允许用户直接在报表中使用Excel文件中的数据。
- 远程Excel数据集:与Excel数据集类似,但专门用于访问网络位置或Web服务上的Excel文件。
- XML数据集:用于连接和解析XML格式的文件,提取其中的数据。 这些文件数据集类型使得FineReport能够兼容多种文件格式,方便用户根据不同的数据源选择合适的文件数据集类型进行数据集成和报表开发。
定义数据连接的URL中,可以使用参数,这个说法正确吗?
是的,这个说法是正确的。在FineReport中定义数据连接时,URL中可以使用参数,这为数据连接提供了灵活性和动态性。参数化的URL允许用户在连接过程中动态替换某些值,例如,可以根据不同的需求动态改变数据库服务器的地址、端口号、数据库名称等。这样的设计使得数据连接更加通用,可以轻松适应不同的环境和需求变化。同时,参数也可以在报表生成时由用户输入,或者通过FineReport的参数传递机制动态生成,从而实现个性化的数据查询和报表展示。
制作一张模板的主要流程顺序是什么?
制作一张FineReport模板的主要流程通常包括以下几个步骤:
- 需求分析:与业务部门沟通,了解报表的目的、数据需求和业务逻辑。
- 设计数据模型:根据需求分析的结果,设计合适的数据模型,包括确定需要的数据表、字段和数据关系。
- 创建数据集:在FineReport中创建数据集,配置数据源连接,编写SQL语句或存储过程来获取所需的数据。
- 新建模板:在FineReport设计器中创建新的模板文件,设置模板的基本属性,如页面大小、方向和边距等。
- 模板布局设计:利用设计器提供的界面元素,如表格、图表、图片等,设计报表的布局和样式。
- 绑定数据:将数据集中的字段与模板中的元素绑定,实现数据的展示和交互。
- 参数设置:如果报表需要根据不同的输入条件动态显示数据,可以设置参数,并在模板中使用这些参数。
- 模板测试:在设计器中预览模板,检查数据展示是否正确,交互功能是否正常。
- 权限设置:根据业务需求,设置报表的访问权限,控制不同用户可以查看或操作的数据范围。
- 发布部署:将设计好的模板部署到报表服务器,以便用户可以通过Web浏览器或其他客户端访问。
- 用户培训和文档编写:为用户提供培训,确保他们能够正确使用报表系统,并编写操作手册或用户指南。
- 维护和优化:根据用户反馈进行报表的维护和性能优化,以满足业务发展的需求。
为了让一个参数在所有模板中都可以使用,通常使用什么参数?
为了让一个参数在所有模板中都可以使用,通常会使用全局参数。全局参数是在整个FineReport工程中都有效的参数,它们不同于模板参数和数据集参数,后者的作用域限定在单个模板或数据集内。全局参数可以在多个模板之间共享,非常适合于那些在多个报表中都需要用到的公共参数,如组织机构选择、日期范围选择等。通过使用全局参数,可以简化模板的设计,避免在多个模板中重复定义相同的参数,并且方便进行权限管理和数据的统一处理。
新特性图表是FineReport内置的图表格式,不需要安装插件,这个说法正确吗?
这个说法是正确的。FineReport提供了丰富的内置图表格式,用户可以直接在设计器中选择合适的图表类型来展示数据,无需额外安装插件。这些图表类型包括但不限于条形图、折线图、饼图、散点图、气泡图、雷达图等,它们覆盖了大多数的数据可视化需求。内置图表的优势在于它们与FineReport的集成度高,用户可以在设计器中方便地进行配置和样式调整,同时也保证了报表的性能和兼容性。此外,FineReport还支持图表的交互功能,如工具提示、数据过滤和数据高亮等,增强了用户的数据探索和分析体验。
在通过URL直接访问报表及决策系统时,&op=write代表的是什么操作?
在通过URL直接访问FineReport报表及决策系统时,&op=write参数代表的是一个特定的操作,即填报预览。这意味着用户可以通过Web浏览器访问报表,并在其中输入或修改数据。这种操作模式通常用于需要用户交互填写数据的报表场景,如数据采集、信息反馈或在线表单等。在FineReport中,op参数是一个功能开关,通过指定不同的值,可以控制报表的预览模式或执行特定的操作。除了write,op参数还可以有其他值,如view(数据分析预览)、write_plus(新填报预览)、mobile(移动端预览)等,以适应不同的业务需求和用户操作。
FineReport设计好的模板可以导出的格式种类有哪些?
FineReport设计好的模板可以导出多种格式,以满足不同的使用和分发需求。可导出的格式主要包括:
- PDF:将模板导出为PDF格式,便于打印和分发,同时保持了模板的版面设计。
- Excel:导出为Excel格式,支持数据的进一步处理和分析,包括分页导出、原样导出、分页分Sheet导出等。
- Word:将报表内容导出为Word文档,适用于需要将报表内容嵌入到Word文档中的场景。
- 图片:将模板导出为图片格式,如JPG、PNG、GIF和BMP,适合于需要将报表作为图像嵌入到网页或演示文档中的情况。
- HTML:导出为HTML文件,可以在Web页面中直接展示报表内容,便于在线查看和分享。
- CSV/TXT:导出为纯文本格式,适用于简单的数据交换和长期存储。 通过这些导出格式,FineReport能够满足用户在不同场合和不同设备上查看、分析和使用报表数据的需求。导出功能是FineReport强大报表能力的一个重要组成部分,它为用户提供了高度的灵活性和便利性。
FineReport支持多种报表打印方式,其中支持进行静默打印的有哪几种?
FineReport提供了多种报表打印方式,以满足不同的打印需求。在这些打印方式中,支持进行静默打印的主要有:
- PDF打印:FineReport可以将报表导出为PDF格式,然后通过PDF打印机进行打印。在配置好打印参数后,用户可以选择静默打印,即无需打开PDF预览直接进行打印。
- Applet打印:FineReport的Applet打印方式允许用户在Web浏览器中直接打印报表。通过设置,可以实现在后台静默打印,避免了打印预览的步骤。
- 服务器端打印:在服务器端打印方式中,报表的打印操作完全在服务器上执行,而不需要客户端参与,这种方式适合于集中管理和批量打印报表的场景。 静默打印是FineReport的一个实用功能,它允许在没有用户交互的情况下自动完成打印任务,非常适合需要批量打印或者自动化打印报表的业务场景。
移动端支持的预览方式有哪些?
FineReport为了适应移动设备上的报表查看需求,提供了多种移动端预览方式,主要包括:
- 移动端预览:专门为移动设备优化的报表展示方式,可以自适应各种屏幕尺寸和分辨率。
- 数据分析预览:在移动端提供数据分析能力,允许用户在移动设备上进行数据的筛选、排序和汇总等操作。
- 填报预览:允许用户在移动设备上填写和提交数据,适用于需要现场数据采集和移动办公的场景。
- 新填报预览:改进的填报预览模式,提供更友好的用户界面和更丰富的数据录入功能。
- 表单预览:针对决策报表,提供了表单模式的预览,适合于需要复杂交互的移动应用。 这些预览方式使得FineReport能够为移动用户提供良好的阅读体验和交互方式,满足移动办公和数据分析的需求。
移动端在数据分析预览中可实现动态折叠树效果,这个说法正确吗?
是的,这个说法是正确的。FineReport在移动端的数据分析预览中确实可以实现动态折叠树效果。这种效果允许用户在移动设备上通过交互操作来展开或折叠报表中的树状数据结构。例如,在查看具有层级关系的数据时,用户可以点击树节点来展开查看子节点的详细信息,或者折叠节点以简化视图。动态折叠树效果增强了移动端用户的交互体验,使得复杂数据的展示和浏览变得更加直观和便捷。
普通报表在移动端的默认自适应逻辑是什么?
FineReport在移动端对普通报表的默认自适应逻辑是尽可能保持报表的原有布局和设计,同时对报表元素的大小和布局进行适当调整,以适应不同尺寸的移动设备屏幕。这种自适应逻辑通常包括:
- 元素缩放:对报表中的文本、图片和其他元素进行缩放,以适应屏幕宽度。
- 布局调整:对报表的布局进行微调,如调整表格的列宽和行高,确保内容在小屏幕设备上的可读性。
- 分页优化:在必要时,对报表内容进行分页,以避免内容在屏幕上横向滚动。 默认自适应逻辑旨在确保用户在移动设备上也能获得尽可能接近原设计的报表展示效果。
普通报表在移动端的支持的自适应逻辑有哪些?
FineReport为普通报表在移动端提供了多种自适应逻辑,以满足不同用户和不同场景的需求。这些自适应逻辑包括:
- 横向自适应:报表内容会根据移动设备的屏幕宽度进行调整,以适应横向浏览。
- 纵向自适应:类似于横向自适应,但是针对纵向浏览进行优化。
- 弹性布局:报表元素的大小和位置可以根据屏幕大小动态变化,以最大化利用可用空间。
- 分栏显示:在屏幕较宽的设备上,可以将报表内容分栏显示,提高阅读效率。
- 交互式操作:提供缩放、平移等交互功能,让用户可以自由地探索报表内容。
- 内容隐藏与显示:允许用户根据需要在移动设备上隐藏或显示报表的某些部分。
- 响应式设计:通过CSS媒体查询等技术,实现对不同屏幕尺寸的响应式设计。 这些自适应逻辑的实现,确保了FineReport的报表在移动端具有良好的可用性和用户体验。用户可以根据自己的需求和偏好选择合适的自适应逻辑,或者自定义自适应规则以达到最佳展示效果。
针对影响性能的因素,FineReport有哪些优化方案?
FineReport作为一款强大的报表工具,对性能优化有着一系列的解决方案,主要针对以下几个方面:
- SQL优化:FineReport建议优化SQL查询语句,比如通过索引、减少子查询、使用JOIN操作等手段提高查询效率。
- 数据集缓存:通过缓存机制,对数据集进行缓存,减少数据库的访问次数,从而提高报表的响应速度。
- 使用存储过程:将复杂的数据处理逻辑移至数据库层面,利用存储过程来提高数据处理效率。
- 减少数据量:通过过滤和只获取必要的数据量,减少网络传输的数据量,提高加载速度。
- 报表模板设计:避免在模板中使用过于复杂的计算和大量的数据处理,合理使用报表元素。
- 服务器配置:合理配置报表服务器,包括内存分配、JVM参数调优等,确保服务器性能满足需求。
- 资源复用:对于多个报表中重复使用的元素或数据,可以进行复用,避免重复创建相同的对象或执行相同的查询。
- 异步加载:对于报表中的图片或大尺寸数据,可以采用异步加载的方式,提高用户体验。
- 报表输出优化:在报表输出时,选择合适的格式和参数,比如PDF导出时选择压缩选项,减少文件大小。
- 版本升级:使用最新版本的FineReport,利用新版本中的性能改进和优化。 通过上述优化方案,可以显著提高FineReport报表的运行效率和用户体验。
决策报表组件包括哪些?
决策报表是FineReport中的一种高级报表类型,它通常包含以下组件:
- 参数面板:允许用户输入或选择参数,以动态地改变报表展示的数据和视图。
- 报表块:报表块是决策报表中的核心组件,用于展示数据,并可以包含多个数据集。
- 图表块:以图形化的方式展示数据,支持多种图表类型,如柱状图、折线图、饼图等。
- 控件:包括文本框、下拉框、单选按钮、复选框等,用于实现用户与报表的交互。
- Tab块:允许将多个报表块或图表块组织在不同的标签页下,方便用户切换查看。
- 树导航:以树状结构展示数据,支持动态展开和折叠,适合于层级数据的展示。
- 仪表盘:提供KPI指标卡、速度表、进度条等,用于展示关键业务指标。
- 过滤栏:允许用户通过输入条件来过滤报表中的数据,快速找到所需信息。
- 数据展示:除了图表,还可以使用表格、列表等形式展示数据。
- 导出功能:支持将报表导出为PDF、Excel、Word等格式,方便数据的分享和分发。 这些组件的组合使用,使得决策报表能够灵活地满足各种复杂的数据分析和展示需求。
单元格内设置了控件,什么预览方式能预览显示?
在FineReport中,当单元格内设置了控件,可以通过以下几种预览方式来预览显示这些控件:
- 分页预览:这是最常见的预览方式,可以显示单元格内控件的当前状态和布局。
- 填报预览:如果控件用于填报功能,填报预览可以展示控件的交互界面,允许用户填写或选择数据。
- 新填报预览:这是填报预览的改进版,提供了更好的用户界面和交互体验。
- 数据分析预览:在这种预览模式下,用户可以对报表数据进行分析,控件可以参与到数据的筛选、排序等操作中。
- 移动端预览:对于需要在移动设备上查看的报表,移动端预览可以展示控件在移动设备上的表现。
- 表单预览:特别是在决策报表中,表单预览可以展示控件的表单视图,适合于数据输入和收集。 在实际使用中,根据报表的设计目的和用户的交互需求,选择合适的预览方式来展示单元格内的控件是非常重要的。
FineReport对于填报数据的提交类型提供了几种方式?
FineReport支持多种填报数据的提交方式,主要包括:
- 即时提交:每次用户在填报控件中输入数据后,可以配置为立即提交到服务器,适用于需要实时数据处理的场景。
- 定时提交:可以设置定时任务,让填报的数据在特定时间自动提交到服务器。
- 批量提交:允许用户在填报完毕后,一次性提交所有更改,适用于大量数据的填报和提交。
- 按键提交:用户可以通过点击一个提交按钮来触发数据的提交过程。
- 表单提交:在决策报表中,可以配置整个表单的提交行为,如验证数据的合法性后整体提交。
- Ajax异步提交:通过Ajax技术实现数据的异步提交,提高用户体验,避免页面刷新。
- 通过URL参数提交:允许通过URL传递参数来实现数据的提交,适合于集成和自动化处理。
- 通过Java API提交:提供编程接口,允许开发者在Java程序中通过代码控制数据的提交。 这些提交方式使得FineReport能够灵活地适应不同的业务需求和用户场景,提高数据填报和管理的效率。
FineReport目前使用的脚本语言是什么?
FineReport目前使用的脚本语言是JavaScript。JavaScript是一种非常流行的高级编程语言,广泛用于增强Web页面的交互性,它也是客户端脚本语言的主流选择。在FineReport中,JavaScript可以用于:
- 单元格计算:在单元格中进行数据的计算和逻辑处理。
- 参数验证:对用户输入的参数值进行验证和转换。
- 动态交互:实现报表与用户之间的动态交互,如根据用户操作动态修改报表内容。
- 事件处理:处理用户的点击、输入等事件,执行相应的脚本代码。
- 自定义函数:编写自定义的JavaScript函数,以扩展报表的功能。
- 客户端验证:在客户端进行数据的验证和处理,提高响应速度和用户体验。
- 报表行为控制:控制报表的显示、隐藏、打印等行为。 通过JavaScript,FineReport能够实现更加丰富和智能的报表功能,满足复杂的业务逻辑和用户交互需求。
在FineReport内置的参数时,代表当前服务器地址的是什么?
FineReport在内置参数中提供了多种系统参数,用于代表当前服务器的地址。最常用的参数是$SERVER_IP,它代表当前服务器的IP地址。此外,还可以使用$SERVER_NAME参数来获取服务器的主机名。这些参数在报表设计中非常有用,尤其是在需要根据服务器地址进行动态数据处理或报表路由时。例如,可以利用这些参数来动态生成报表的访问链接,或者根据不同服务器的地址执行不同的报表逻辑。在实际应用中,服务器地址参数可以与报表中的其他元素结合使用,如结合URL参数、数据集查询条件等,以实现更加灵活和智能化的报表设计。
在分页预览时,可以通过哪个参数取得当前页码?
在FineReport的分页预览模式下,可以使用系统内置的参数$PAGE_NO来获取当前页码。这个参数在报表的任何位置都可以使用,它会自动更新为当前显示页的页码。利用$PAGE_NO参数,可以实现多种页码相关的功能,如显示当前页码、计算总页数、生成分页链接等。此外,还可以结合其他系统参数,如$PAGE_COUNT(总页数)和$PAGE_SIZE(每页显示的记录数),来进行更复杂的分页计算和控制。$PAGE_NO参数的使用,增强了报表的交互性和用户体验,特别是在需要进行分页显示和分页导航的场合。
设计模板时控件值可以有以下哪些方式定义?
FineReport在设计模板时提供了多种定义控件值的方式,主要包括:
- 直接输入:在控件的属性设置中直接输入一个固定值。
- 绑定数据:将控件与数据集中的字段绑定,控件的值会显示数据集中对应的字段值。
- 表达式设置:通过设置JavaScript表达式或SQL表达式,动态计算控件的值。
- 参数传递:通过报表参数传递值,用户在报表预览时输入参数值,控件显示参数值。
- 函数调用:调用FineReport提供的内置函数或自定义函数来设置控件的值。
- 脚本控制:使用JavaScript脚本动态设置控件的值,可以根据用户交互或其他事件来改变。
- 数据字典:对于需要从固定选项中选择的控件,可以关联数据字典,控件的值从数据字典中获取。
- 继承值:控件的值可以继承自模板继承的上级控件的值。
- 用户输入:对于填报类控件,其值可以由用户在填报时输入。 这些定义方式为控件值的设置提供了极大的灵活性,使得控件可以适应各种不同的数据展示和交互需求。
下列哪些控件可以进行数据字典设置?
在FineReport中,可以进行数据字典设置的控件主要包括:
- 下拉框:允许用户从下拉列表中选择一个值,列表的选项来自数据字典。
- 复选框:用于表示多个选项的选中状态,每个选项的显示文本和值可以来自数据字典。
- 单选按钮组:一组单选按钮,用于选择一个固定选项,选项来自数据字典。
- 列表框:显示一系列选项供选择,选项可以是数据字典中的项。
- 树形选择器:以树状结构展示数据字典中的层级数据,用户可以选择树中的节点。
- 日历控件:日期控件的显示格式可以通过数据字典来设置,以符合不同的日期展示需求。 数据字典为控件提供了一种标准化和集中管理数据的方式,它允许报表设计者定义一系列的选项和对应的值,然后在整个报表中复用这些定义,这样可以减少重复工作,提高报表的一致性和可维护性。
按钮控件没有控件值属性,这个说法正确吗?
这个说法是正确的。在FineReport中,按钮控件(Button)通常用于触发事件或执行某些操作,它本身并不具有像文本框(Textbox)那样的“控件值”属性。按钮控件的核心功能是作为用户交互的触发器,而不是用来显示或输入数据的。按钮控件可以绑定各种事件处理器,如点击事件(onClick),当用户点击按钮时,可以执行页面跳转、报表参数的传递、数据的提交、执行JavaScript代码等操作。虽然按钮控件没有控件值属性,但它可以通过事件处理器与报表中的其他元素或数据集交互,实现复杂的业务逻辑。在设计报表时,按钮控件的使用非常灵活,可以根据需要配置多种交互行为,增强报表的功能性和用户体验。
FineReport部署有哪几种方式?
FineReport支持多种部署方式,以满足不同规模和需求的企业应用。主要的部署方式包括:
- 独立部署:将FineReport作为一个独立的应用程序部署在服务器上。这种方式适合于小型企业或单一应用场景,部署过程简单,易于维护。
- 服务器部署包:适用于中等复杂度的应用场景,可以通过部署包的形式,将FineReport部署到支持的Java应用服务器上,如Tomcat、JBoss等。
- 嵌入式部署:将FineReport嵌入到现有的Java EE应用中,与其他应用共享同一个应用服务器。这种方式适合于需要将报表功能集成到现有企业系统中的情况。
- 集群部署:在多台服务器上部署FineReport,通过负载均衡等技术实现高可用性和高性能。适合于大型企业或需要高并发访问的业务场景。
- 云端部署:利用云服务提供商的资源,将FineReport部署在云端,以利用云服务的弹性和便捷性。
- 移动端部署:FineReport还支持移动端应用的部署,通过移动应用为用户展示报表和数据分析。 每种部署方式都有其特点和适用场景,企业可以根据自身需求和资源情况选择合适的部署策略。
FineReport目前不支持在哪种服务器下直接部署使用?
FineReport作为一款Java开发的报表工具,支持多种常见的Java应用服务器,如Tomcat、JBoss、WebLogic、WebSphere、Jetty、Glassfish、Resin等。然而,根据搜索到的资料,FineReport目前不支持在IIS(Internet Information Services)服务器下直接部署使用。IIS是微软的Internet服务管理器,主要用于托管和管理ASP.NET、PHP等Web应用程序,而FineReport需要Java运行环境,因此不适用于IIS服务器。
在Tomcat服务器下采用独立部署时,是将报表哪个目录放在tomcat下的哪个目录下?
在Tomcat服务器下采用独立部署FineReport时,通常会将FineReport的Web应用目录放置在Tomcat的webapps目录下。具体步骤如下:
- 将FineReport的安装包解压,找到其中的Web应用压缩包(通常是
.war文件)。 - 将该
.war文件复制到Tomcat安装目录下的webapps文件夹中。 - Tomcat在启动时会自动解压
.war文件,并在webapps目录下生成一个以.war文件名命名的文件夹,这个文件夹包含了FineReport的所有Web资源。 - 此外,可能还需要配置FineReport的数据源和日志等,这通常涉及到修改Tomcat的
conf目录下的context.xml和server.xml文件。 通过这种方式,FineReport就可以作为一个Web应用在Tomcat服务器上运行,用户可以通过浏览器访问配置的URL来使用FineReport。
部署到服务器的常见错误500可能是由于哪些情况造成的?
HTTP 500错误通常指的是服务器内部错误,当FineReport部署到服务器上出现这个错误时,可能的原因包括:
- 配置错误:如数据源配置不正确、Web应用的context-path配置错误等。
- 资源缺失:缺少必要的JAR包或驱动程序,或者资源文件未能正确放置。
- 代码问题:FineReport的自定义代码或插件存在问题,如自定义函数错误、表达式错误等。
- 权限问题:服务器上缺少运行FineReport所需的权限,如数据库访问权限、文件读写权限等。
- 服务器环境:Java版本与FineReport不兼容,或应用服务器(如Tomcat)的版本不支持。
- 数据库连接:数据库连接失败或超时,或者数据库服务器出现问题。
- 异常处理:未捕获的异常导致服务器端程序崩溃。
- Web服务器问题:如Tomcat服务器内部错误,可能由于内存泄漏、线程死锁等。
- 网络问题:网络配置不当,如防火墙设置、端口冲突等。 解决500错误通常需要查看服务器的日志文件,定位具体的错误信息,然后根据错误信息进行调试和修复。
Java语言不支持多重继承,一个类只能继承一个父类,但一个父类可以有多个子类,这个说法正确吗?
是的,这个说法是正确的。Java语言在类继承方面采用的是单继承机制,即一个类只能有一个直接父类。这是为了避免多重继承带来的复杂性和潜在的继承冲突。虽然Java不允许一个类继承多个类,但它提供了其他的机制来实现代码复用和多态性,如接口(interface)的使用。接口允许一个类实现多个,从而获得多个类型的能力。此外,Java通过抽象类(abstract class)和继承(extends)以及组合(composition)等手段,提供了灵活的代码复用方式。这种单继承多实现的模式,使得Java的类层次结构更加清晰,有助于降低系统的复杂度和提高可维护性。
Java中可以脱离父类直接构造子类,这个说法正确吗? 这个说法是错误的。在Java语言中,子类的构造过程必须调用其父类的构造方法。Java确保了在创建子类对象时,首先会执行父类的构造方法来初始化从父类继承的成员变量。这是因为子类继承了父类的状态,而构造方法的职责就是初始化对象的状态。在Java中,如果子类没有显式地调用父类的构造方法,编译器会自动插入一个对父类无参构造方法的调用,并且这个调用会在调用子类构造方法之前执行。如果父类没有无参的构造方法,那么子类必须通过super关键字显式地调用父类有参的构造方法。如果既不提供无参构造方法,也不显式调用,编译将会失败。因此,子类的构造不能脱离父类,它是依赖于父类构造方法的。
防火墙中地址翻译的主要作用是什么?
防火墙中的地址翻译(Address Translation)主要作用是实现网络地址的转换,这项技术通常被称为网络地址转换(Network Address Translation,简称NAT)。NAT允许多台设备共享一个或一组IP地址,以便能够访问互联网,这对于节省IP地址空间尤其有用。地址翻译的主要作用包括:
- IP地址隐藏:隐藏内部网络结构,提高网络安全性。
- 地址复用:允许多个设备使用少量的公网IP地址。
- 负载均衡:在多个网络接口上分配网络流量,提高网络性能和可靠性。
- 故障转移:在防火墙或网络设备发生故障时,通过地址翻译实现流量的自动转移。
- 策略控制:基于源或目的IP地址实施流量过滤和访问控制策略。 地址翻译是防火墙提供的一项基本而重要的功能,它在确保网络安全和优化网络资源方面发挥着关键作用。
不属于防火墙的测试性能参数的是什么?
防火墙的测试性能参数通常包括吞吐量、延迟、并发连接数、新连接速率、数据包丢失率等。这些参数用于衡量防火墙在不同网络负载下的性能表现。不属于防火墙测试性能参数的可能是一些与防火墙性能无关的指标,例如:
- 软件兼容性:不同操作系统或应用程序与防火墙的兼容性。
- 用户界面易用性:防火墙管理界面的友好程度。
- 功耗:防火墙设备的能耗水平。
- 物理尺寸:防火墙设备的体积大小。
- 噪音水平:物理防火墙设备的噪音等级。
- 颜色和外观:防火墙设备的外观设计和颜色。 这些参数虽然可能与防火墙的使用和部署有关,但并不直接反映防火墙在网络中的性能表现。
FineReport设计器自带的服务器默认启动的端口号是多少?
FineReport设计器自带的服务器,即FineReport内置的Web服务器,用于在设计时预览报表效果。根据搜索到的资料,FineReport设计器自带的服务器默认启动的端口号通常为8075。这个端口号是设计器在启动时用于Web预览的默认端口,用户可以通过这个端口号访问设计器中的报表预览。如果默认端口与服务器上其他应用的端口冲突,用户可以根据需要修改端口号。修改端口号的操作通常在设计器的设置或配置文件中进行。
未注册版本的并发数为2,即同时只能有2个客户端访问服务器,这个说法正确吗?
这个说法是正确的。根据FineReport的官方信息,未注册的FineReport软件通常会有一定的功能限制,其中之一就是并发用户数的限制。未注册版本的FineReport允许最多2个客户端同时访问服务器。这意味着在同一时间点,只有两个用户能够通过Web浏览器或客户端软件连接到FineReport服务器并使用其功能。超过限制的额外用户可能无法访问报表或会被提示等待。这种限制是FineReport作为一种商业软件的版权和授权策略的一部分。用户可以通过购买正式的注册版本来获得更高的并发数和其他高级功能。
在决策系统中,默认的日志统计级别是什么?
FineReport决策系统中的日志统计级别默认为“INFO”级别。日志级别是用于指定日志系统记录信息的详细程度的,它通常包括多个层次,如“DEBUG”、“INFO”、“WARN”、“ERROR”等。在FineReport中,“INFO”级别的日志统计会记录大部分的运行信息,但不会像“DEBUG”那样记录过于详细的调试信息,也不会像“WARN”或“ERROR”那样只记录警告和错误信息。使用“INFO”作为默认级别,可以在不牺牲太多性能的情况下,获取足够的日志信息,以便于系统维护和故障排查。管理员可以根据需要调整日志级别,以便更细致地控制日志输出的内容和数量。
决策系统中默认采取的服务器端字符编码是什么?
FineReport决策系统中默认采取的服务器端字符编码是UTF-8。UTF-8是一种变长的字符编码方式,它能够兼容ASCII编码,并且可以表示Unicode标准中的任何字符。UTF-8编码具有很好的跨平台性和国际化特性,是目前互联网上使用最广泛的字符编码。在FineReport中使用UTF-8编码,可以确保报表在不同语言环境下的兼容性,避免字符显示乱码的问题。同时,UTF-8编码也有助于提高数据交换的效率和准确性,特别是在处理国际化报表和数据时。
报表开发要以人为本,这个观点你怎么看?
“报表开发要以人为本”是一个非常关键的观点,它强调了在报表开发过程中,需要以用户的需求和体验为中心。这意味着报表开发者在设计报表时,不仅仅是技术上的实现,更重要的是要理解报表用户的业务需求、使用习惯和决策偏好。报表的目的是为了帮助用户更好地理解数据,支持决策,因此报表应该清晰、准确、及时地传达信息。在实践中,这可能意味着需要与业务部门紧密合作,进行需求调研,了解报表的使用场景,以及用户对数据的关心点。此外,还需要考虑到报表的可读性、易用性和交互性,使用户能够轻松地获取所需信息,并对数据进行必要的分析和操作。
如何挖掘业务需求以优化报表开发?
挖掘业务需求是优化报表开发的重要步骤,可以通过以下方法进行:
- 沟通与协作:与业务部门建立良好的沟通机制,通过会议、访谈、问卷等方式,收集业务人员的意见和建议。
- 需求分析:对收集到的信息进行分析,理解业务流程、关键业务指标和报表使用场景。
- 原型展示:设计初步的报表原型,邀请用户进行测试和反馈,以便更好地理解用户的实际需求。
- 持续迭代:根据用户反馈,不断调整和优化报表设计,形成快速迭代的开发流程。
- 数据理解:深入理解业务背后的数据结构和数据关系,确保报表能够准确反映业务状况。
- 用户参与:让用户参与到报表的设计和测试过程中,特别是关键决策者,确保报表满足其决策需求。
- 专业引导:利用自身的专业知识,引导用户提出更加合理和可行的需求。
- 需求管理:建立需求管理机制,对需求进行优先级排序,合理安排开发计划。
化繁为简,做好报表管理的方法有哪些?
化繁为简,优化报表管理可以采取以下方法:
- 报表分类:根据报表的功能、业务模块或使用频率对报表进行分类,便于管理和检索。
- 模板复用:设计通用的报表模板,减少重复开发,提高开发效率。
- 权限控制:合理设置报表的访问权限,确保数据安全,同时简化权限管理。
- 报表简化:避免不必要的复杂性,只展示关键信息,减少不必要的报表字段和计算。
- 交互设计:优化报表的用户交互设计,如使用图表、颜色编码和布局优化,提高报表的可读性。
- 自动化报表:利用自动化工具和脚本来生成报表,减少人工干预。
- 性能优化:定期检查和优化报表性能,如优化SQL查询、使用缓存等。
- 反馈机制:建立用户反馈机制,及时了解报表使用情况,不断改进报表。
- 文档和培训:提供详细的报表使用文档和培训,帮助用户理解报表内容和操作方法。
- 报表门户:建立报表门户,集中展示和管理所有报表,方便用户访问和使用。
利用高效的开发工具对报表开发的影响是什么?
利用高效的开发工具对报表开发的影响是多方面的,可以从以下几个角度来分析:
- 提高开发效率:高效的开发工具通常提供直观的设计界面和丰富的功能组件,可以大大减少手动编码的工作量,提高开发速度。
- 改善用户体验:良好的工具往往有更人性化的交互设计,使得报表设计更加直观和便捷,提升报表开发者的工作效率和体验。
- 增强报表功能:高效的开发工具往往集成了先进的数据分析和可视化技术,能够实现更复杂的报表功能,如多维数据分析、动态交互等。
- 促进团队协作:一些开发工具支持多人协作,可以使得报表开发团队成员之间的沟通和协作更加顺畅。
- 降低技术门槛:对于非技术人员,高效的开发工具可以降低报表开发的技术门槛,使得更多业务人员能够参与到报表的设计和制作中。
- 优化报表维护:高效的开发工具往往提供更好的版本控制和维护管理功能,有助于报表的长期维护和迭代更新。
- 提升数据安全性:通过工具提供的权限管理和数据加密等安全机制,可以更好地保护报表中的数据安全。
- 支持移动设备:随着移动设备的普及,高效的开发工具还能支持报表在移动设备上的展示和交互,满足移动办公的需求。 以FineReport为例,它作为一种高效的报表开发工具,通过提供类Excel的设计器、丰富的数据源连接、灵活的报表模板设计等功能,极大地提升了报表开发的效率和质量。
为什么说懂数据,懂业务对报表开发者来说很重要?
报表开发者如果懂数据、懂业务,将对整个报表开发过程产生积极影响:
- 更准确的业务理解:了解业务知识可以帮助开发者准确把握报表需求,避免开发出与实际业务脱节的报表。
- 更有效的沟通:与业务部门的沟通更加顺畅,能够快速理解业务人员的需求,并提供合适的解决方案。
- 更深入的数据洞察:对数据的理解可以帮助开发者发现数据之间的关系和潜在的业务价值,从而设计出更有洞察力的报表。
- 更强的问题解决能力:在报表开发过程中遇到问题时,懂业务的开发者能够更快地定位问题,并提出切实可行的解决方案。
- 更好的决策支持:懂业务的报表开发者能够设计出真正支持决策的报表,帮助管理层做出更明智的业务决策。
- 更高的用户满意度:开发的报表能够更好地满足用户的实际需求,提高用户满意度和报表的使用率。
- 更强的竞争力:在职场中,懂数据懂业务的报表开发者更具竞争力,能够为企业提供更大的价值。
注意突出重点在报表开发中的必要性是什么?
在报表开发中注意突出重点非常必要,原因如下:
- 信息传递更清晰:通过突出重点,可以让用户快速抓住报表的核心信息,提高信息传递的效率。
- 提高决策效率:对于管理层来说,能够迅速识别关键数据,有助于快速做出决策。
- 优化用户体验:合理布局和突出显示重要信息,可以提升用户阅读报表的体验。
- 减少信息干扰:过多的信息可能会使用户分心,通过突出重点可以减少不必要的信息干扰。
- 提高报表的可读性:对于复杂的报表,突出重点可以帮助用户更好地理解数据和报表结构。
- 应对紧急情况:在紧急情况下,用户可能需要迅速获取关键信息,突出重点可以满足这一需求。
- 节约用户时间:用户可能没有足够的时间阅读完整的报表,突出重点可以让用户在短时间内获取最关键的信息。
报表开发中常见的问题有哪些?
报表开发中可能会遇到的一些常见问题包括:
- 需求不明确:业务部门的需求描述不够清晰,导致报表开发方向错误或反复修改。
- 数据质量问题:数据不准确、不完整或存在错误,影响报表的可信度。
- 性能瓶颈:报表在处理大量数据时性能不佳,导致加载缓慢或响应时间长。
- 用户体验差:报表界面设计不合理,操作复杂,用户难以理解和使用。
- 缺乏交互性:报表过于静态,不能提供用户交互,如数据筛选、排序等。
- 移动适应性:报表在移动设备上的展示效果不佳,未考虑移动用户的使用习惯。
- 安全性问题:报表中的数据未经适当保护,存在泄露风险。
- 维护困难:报表逻辑复杂,难以维护和更新,每次需求变更都需要大量工作。
- 忽视用户培训:报表交付后缺乏相应的用户培训,导致用户无法充分利用报表功能。
如何在报表中有效展示核心数据?
在报表中有效展示核心数据的方法包括:
- 数据筛选:只展示与主题相关的核心数据,去除无关信息。
- 重点突出:通过加粗、高亮、颜色等手段突出显示关键数据。
- 数据汇总:对数据进行汇总和聚合,展示总体趋势和关键指标。
- 使用图表:利用图表(如柱状图、折线图、饼图)直观展示数据变化和分布。
- 分层展示:对于复杂的数据,采用分层或分页的方式逐步展示,避免一次性展示过多信息。
- 交互设计:提供数据筛选、排序、详细信息查看等交互功能,让用户可以根据自己的需求探索数据。
- 简洁的布局:保持报表布局的简洁性,避免过多的装饰性元素干扰数据展示。
- 适当的注释:对于复杂的数据或图表,提供必要的文字说明和注释,帮助用户理解。
- 一致性设计:确保报表中的数据展示风格一致,如统一的字体、颜色和图表样式。
- 用户视角:从用户的角度出发,展示对用户决策最有价值的数据。
- 性能优化:优化报表性能,确保即使在数据量大的情况下也能快速加载和展示数据。
相关文章:

FineReport高频面试题及参考答案
FineReport是一款利用什么语言开发的报表工具? FineReport是一款基于Java语言开发的报表工具。Java是一种广泛使用的编程语言,特别适合于跨平台的软件开发。FineReport利用Java语言的诸多优势,如稳定性、安全性、可移植性和强大的网络功能&a…...

git merge 命令合并指定分支到当前分支
git merge 是一个用于合并两个分支的 Git 命令。当你在不同的分支上工作时,可能会有一些不同的更改。使用 git merge 可以将这些更改合并到一起。以下是一些常见的 git merge 用法示例: 1. 合并当前分支与另一个分支的更改 git merge <branch-name&…...
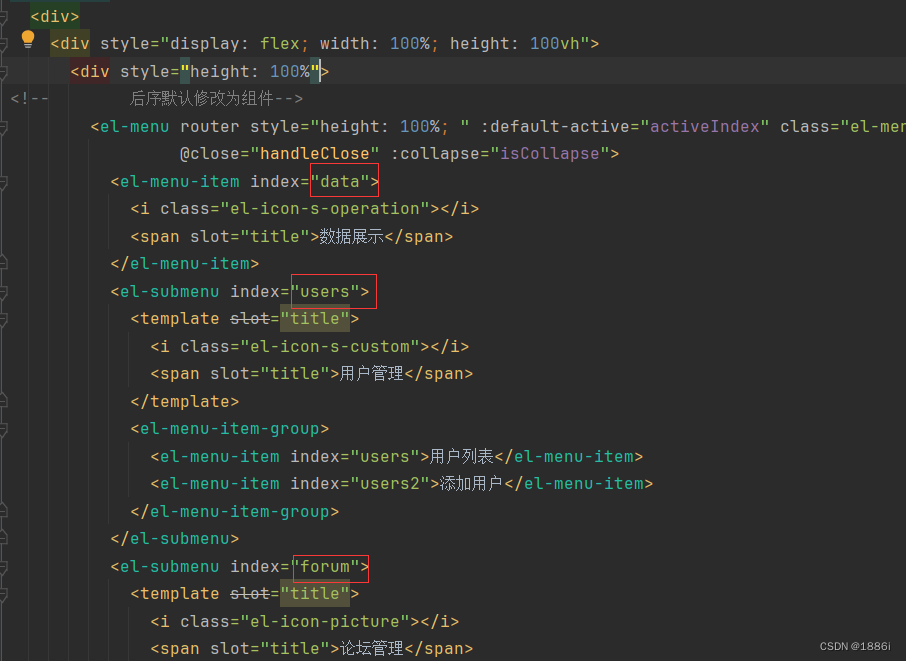
【在线OJ】Vue创建OJ管理系统
一、创建项目 vue ui命令创建项目 项目创建完成后来到项目 二、导航栏 首先创建一个根页面,让他展示在页面上 创建之后来到路由配置界面 然后安装ElementUI,来到官网找到导航栏 复制代码后粘贴到刚才创建的vue文件里,启动项目ÿ…...

常用算法汇总
作者:指针不指南吗 专栏:算法篇 🐾算法思维逻辑🐾 文章目录 1.判断闰年2.计算从某天到某天的天数3.二分4. 前缀和5.差分6.图论6.1dfs6.2走迷宫 7.最短路7.1dijkstra7.2foly 8.并查集9.数论9.1gcd lcm9.2判断素数(质数)9.3分解质因…...
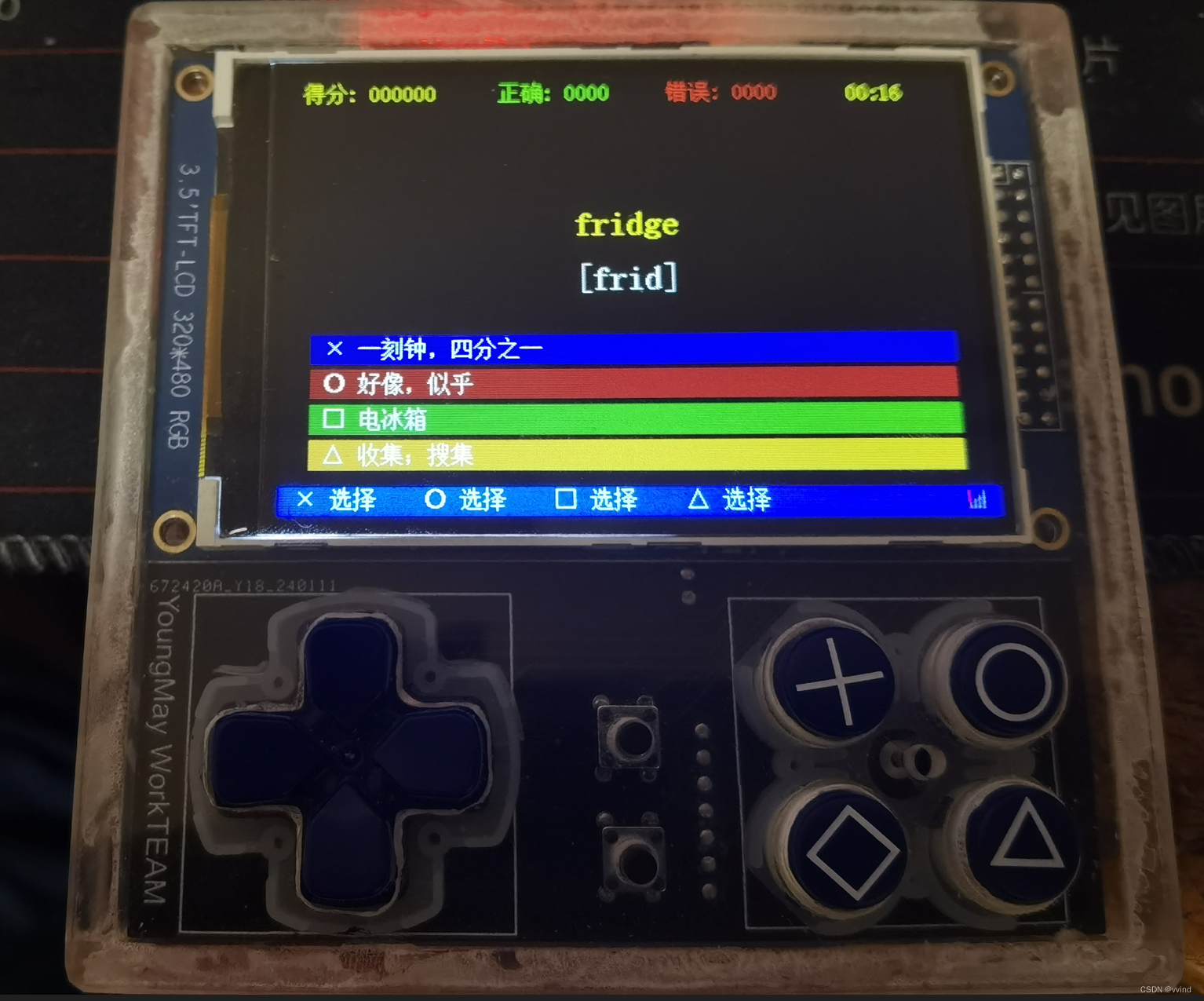
W801学习笔记二十二:英语背单词学习应用——下
续上篇: W801学习笔记二十一:英语背单词学习应用——上 五、处理用户交互 由于英语也是采用了和唐诗一样的《三分钟限时挑战》《五十题竞速挑战》《零错误闯关挑战》,所以用户交互的逻辑和唐诗是一样的。所以,我们抽一个基类&a…...

Vue路由的模式和原理
一、hash模式(默认) 使用URL的hash来模拟一个完整的URL,当URL发生改变时不会向服务器发起请求。# 和其后面的字符称为hash,可通过 window.location.hash 获取。当hash改变会触发(包括浏览器的前进、后退)会…...

在K8S中,静态、动态、自主式Pod有何区别
在Kubernetes(简称K8s)中,静态Pod、自主式Pod和动态Pod是不同管理方式下的Pod类型,它们的区别主要体现在创建和管理方式上: 静态Pod: 静态Pod是由kubelet直接管理的,其配置文件存储在节点本地而…...

【Three.js基础学习】15.scroll-based-animation
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 前言 课程要点 结合html等场景 做滚动动画 1.遇到的问题, 在向下滚动时,下方会显白(部分浏览器) 解决:alpha:true …...
ubantu安装mysql
安装 准备:下载:版本5.1.17的MySQL并上传至Ubuntu系统 #解压 tar -xvf mysql-server_5.7.17-1ubuntu16.10_amd64.deb-bundle.tar #提前安装插件 sudo apt-get install libaio1 libmecab2 #若安装失败使用以下命令 apt --fix-broken install sudo apt-g…...

注意!华为HCIP-Datacom认证考试题有变化!
01 注意 HCIP Datacom H12-831考试变题了,最近要考试的多观望一下,821目前稳定。 华为HCIP考试以后要加难度,增加实验题,还没考完的小伙伴抓紧时间了。 02 华为HCIP认证大更新 未来将增加实验考试,拒绝背题库的Pass&a…...

你是我的荣耀 | 林先生:从酷爱数学到毕业走向数据分析岗位
人物背景: 研究生国家奖学金、本科生国家奖学金、学业奖学金一等奖、上海市优秀毕业生; 应用统计专业 CPDA优秀学员 ## 为什么选择数据分析相关专业 我是应用统计专业的一个应届毕业生,目前在一家上海市属的国企,从事数据分析相关…...

操作系统真象还原-bochs安装
今天读了《操作系统真象还原》这本书,写上比较幽默通俗。书中例子需要安装一个bochs系统,记录一下安装过程。参考了书中1.4,1.5两节,书中尽让有两处问题,也记录了下来。 1.3 操作系统的宿主环境 下载地址:…...
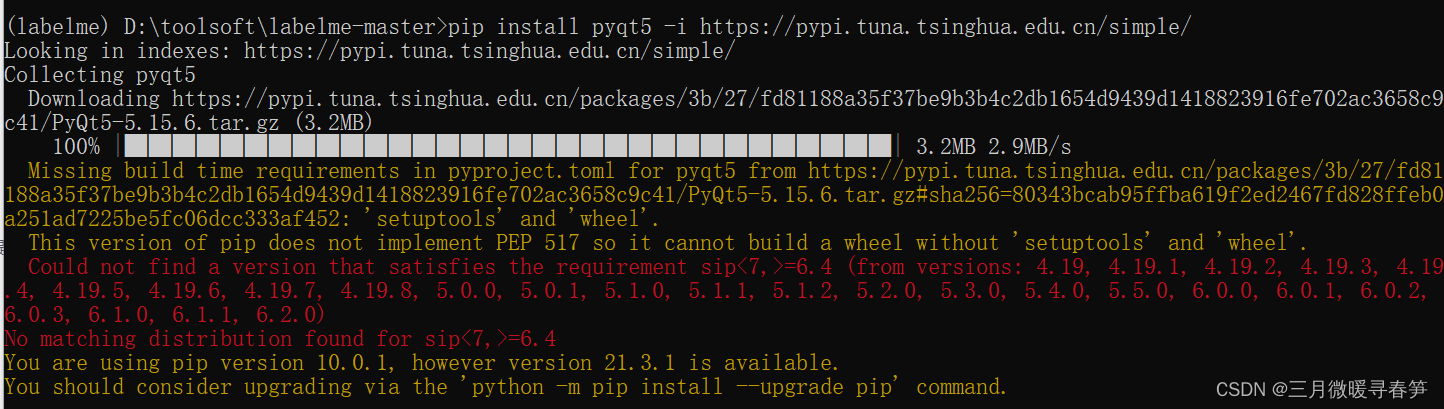
windows平台安装labelme
之前写过一篇文章也是关于在windows平台安装labelme的:《windows平台python版labelme安装与使用_labelme下载-CSDN博客》,随着软件与工具的更新换代,按照同样的方法最近在使用的时候出现了错误,出现创建虚拟环境失败,具…...
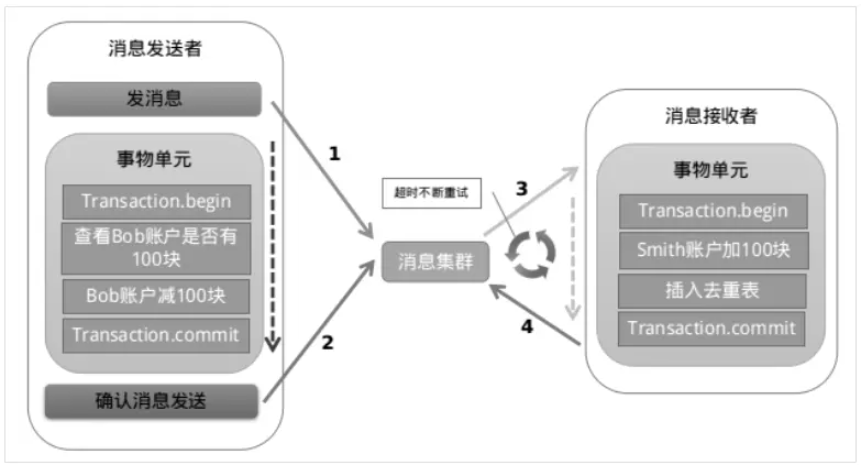
微服务之SpringCloud AlibabaSeata处理分布式事务
一、概述 1.1背景 一次业务操作需要跨多个数据源或需要跨多个系统进行远程调用,就会产生分布式事务问题 but 关系型数据库提供的能力是基于单机事务的,一旦遇到分布式事务场景,就需要通过更多其他技术手段来解决问题。 全局事务:…...
2005-2021年全国各地级市生态环境注意力/环保注意力数据(根据政府报告文本词频统计)
2005-2021年全国各地级市生态环境注意力/环保注意力数据(根据政府报告文本词频统计) 2005-2021年全国各地级市生态环境注意力/环保注意力数据(根据政府报告文本词频统计) 1、时间:2005-2021年 2、范围:2…...

熟悉这些道理可以让人更好地应对各种挑战和困难。
1. 为别人尽最大的力量,最后就是为自己尽最大的力量。——罗斯金 2. 世上有一条永恒不变的法则:当你不在乎,你就得到。当你变好,你才会遇到更好的。只有当你变强大,你才不害怕孤单。当你不害怕孤单,你才能够宁缺毋滥。…...

AI去衣技术在动画制作中的应用
随着科技的发展,人工智能(AI)已经在各个领域中发挥了重要作用,其中包括动画制作。在动画制作中,AI去衣技术是一个重要的工具,它可以帮助动画师们更加高效地完成工作。 AI去衣技术是一种基于人工智能的图像…...

卷积神经网络要点和难点实际案例和代码解析
卷积神经网络(Convolutional Neural Networks,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。卷积神经网络仿造生物的视知觉机制构建,可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够…...

initramfs及rpm/dracut操作
一、背景 更新bundle包后发现系统异常。 定位发现驱动升级不成功,内核启动后加载的还是更新前的旧驱动。但等内核启动完成后,卸载旧驱动手动insmod新驱动,是可以加载成功的。 驱动的安装目录在/lib/modules/$KERNELVERSION/extra目录下。 …...

Kafka 2.13-3.7.0 在 Windows 上的安装与配置指南
在本文中,我将引导您完成在Windows操作系统上安装Apache Kafka 2.13-3.7.0的全过程,包括下载Scala运行环境、Kafka软件包、配置相关设置,并最终启动Kafka服务。此外,还会简要介绍如何使用客户端工具进行查看和管理。 Kafka的命名…...

VAP特效动画创作指南:3步打造跨平台炫酷视觉特效
VAP特效动画创作指南:3步打造跨平台炫酷视觉特效 【免费下载链接】vap VAP是企鹅电竞开发,用于播放特效动画的实现方案。具有高压缩率、硬件解码等优点。同时支持 iOS,Android,Web 平台。 项目地址: https://gitcode.com/gh_mirrors/va/vap 还在为…...

5分钟快速上手:FlicFlac音频格式转换工具完全指南 [特殊字符]
5分钟快速上手:FlicFlac音频格式转换工具完全指南 🎵 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 还在为不同设备间的音频格式…...

TestDisk PhotoRec:免费开源数据恢复终极指南,快速找回丢失的分区和文件
TestDisk & PhotoRec:免费开源数据恢复终极指南,快速找回丢失的分区和文件 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 你是否曾经不小心删除了重要文件?或者硬盘分…...

计算机科学论文降AI工具免费推荐:2026年计算机毕业论文知网维普降AI4.8元亲测完整方案
计算机科学论文降AI工具免费推荐:2026年计算机毕业论文知网维普降AI4.8元亲测完整方案 答辩前夕,AI率36%,学校要求15%以下。 用嘎嘎降AI(www.aigcleaner.com),4.8元,两小时搞定,一…...
)
蓝桥杯单片机备赛:AT24C02读写避坑指南(附STC15完整工程)
蓝桥杯单片机备赛:AT24C02读写避坑指南(附STC15完整工程) 在蓝桥杯单片机竞赛中,AT24C02这颗小小的EEPROM芯片常常成为决定胜负的关键。作为参赛选手,你可能已经掌握了I2C协议的基本原理,但在紧张的比赛环境…...

如何快速创建一个轻量美观的导航站?Typecho + MijiNav组合轻松完成
在现在信息过载的数字化时代,信息碎片化问题也越来越严重,拥有一个经过严格筛查的高质量网址导航页,已经成为许多人的需求。一个轻量、美观的导航页可以大大提升工作效率和用户体验。实现一个导航网站的方式有很多,今天࿰…...

Perplexity社会新闻搜索响应延迟突增47%?独家披露其底层新闻图谱更新机制与3类高危缓存失效场景
更多请点击: https://kaifayun.com 第一章:Perplexity社会新闻搜索响应延迟突增47%?独家披露其底层新闻图谱更新机制与3类高危缓存失效场景 Perplexity 社会新闻搜索服务近期观测到 P95 响应延迟从 320ms 飙升至 468ms,增幅达 4…...

全面配置指南:Excel MCP Server高效部署与专业运维实战
全面配置指南:Excel MCP Server高效部署与专业运维实战 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server Excel MCP Server是一个强大的模型…...

ViGEmBus虚拟游戏控制器驱动:从零开始掌握Windows手柄模拟技术
ViGEmBus虚拟游戏控制器驱动:从零开始掌握Windows手柄模拟技术 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想在Windows电脑上使用任意手柄玩…...
)
告别手动测量!用ArcGIS+CAD搞定河道平均宽度的两种实用方法(附详细步骤)
河道平均宽度计算实战:ArcGIS与CAD高效协同方案解析 河道宽度测量是水文分析、防洪规划与生态评估中的基础工作,但传统手工测量方式在面对复杂河道形态时往往效率低下。本文将深入解析两种基于ArcGIS与CAD协同的自动化计算方法,通过技术组合实…...