pandas数据分析(二)
文章目录
- DataFrame数据处理与分析
- 读取Excel文件中的数据
- 筛选符合特定条件的数据
- 查看数据特征和统计信息
- 按不同标准对数据排序
- 使用分组与聚合对员工业绩进行汇总
DataFrame数据处理与分析
部分数据如下
这个数据百度可以搜到,就是下面这个
读取Excel文件中的数据
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide',True)
pd.set_option('display.unicode.east_asian_width',True)
#usecols指定要读取的列的索引或名字
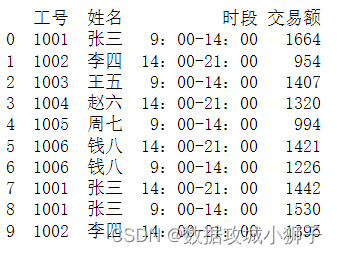
df=pd.read_excel(r'C:\Users\dell\Desktop\超市营业额2.xlsx',usecols=['工号','姓名','时段','交易额'])
print(df[:10],end='\n\n')#输出前10行数据
#读取第一个worksheet中所有列
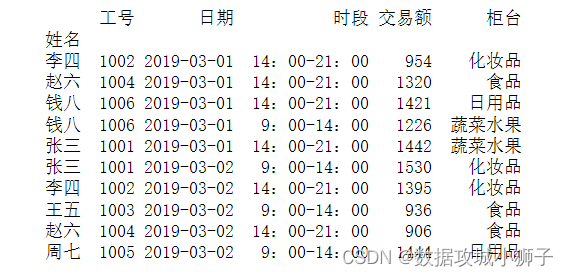
#跳过第1、3、5行,指定下标为1的列中数据为DataFrame的行索引标签
df=pd.read_excel(r'C:\Users\dell\Desktop\超市营业额2.xlsx',skiprows=[1,3,5],index_col=1)
print(df[:10])
筛选符合特定条件的数据
#读取全部数据,使用默认索引
df=pd.read_excel(r'C:\Users\dell\Desktop\超市营业额2.xlsx')
#下标在[5,10]区间的行,切片限定的是左闭右开区间
df[5:11]
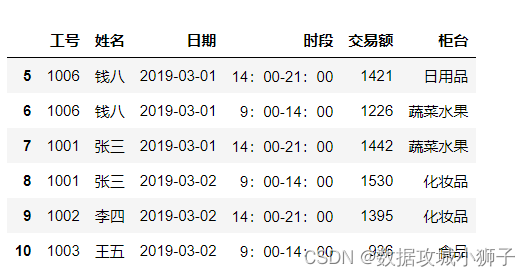
#iloc使用整数做索引
df.iloc[5]#索引为5的行

df.iloc[[3,5,10]]#下标为[3,5,10]的行
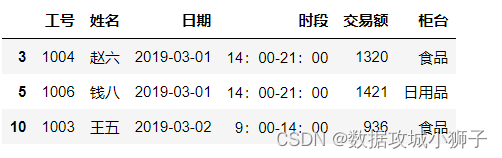
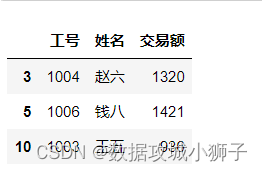
df.iloc[[3,5,10],[0,1,4]]#行下标[3,5,10],列下标[0,1,4]
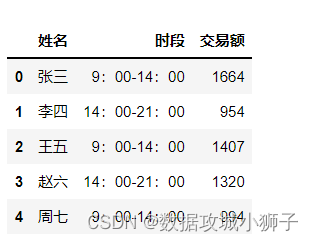
df[['姓名','时段','交易额']][:5]#指定的列前5行的数据
df[:10][['姓名','日期','柜台']]#只查看前10行指定的列

df.loc[[3,5,10],['姓名','交易额']]#下标为[3,5,10]行的指定列

df.at[3,'姓名']#行下标为3,姓名列的值'赵六'
#如果有报错,看看柜台列的字符是不是跑到交易额列去了
#因为交易额有几个是空值,直接复制来的数据可能位置不对
print(df[df['交易额']>1700])#交易额高于1700元的数据
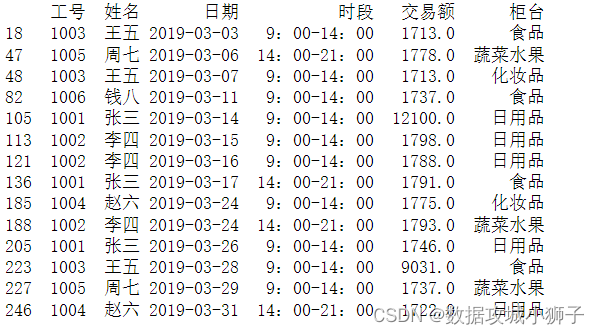
df['交易额'].sum()#交易总额327257.0
#注意这个数据里是中文冒号
df[df['时段']=='14:00-21:00']['交易额'].sum()#下午班的交易总额151228.0
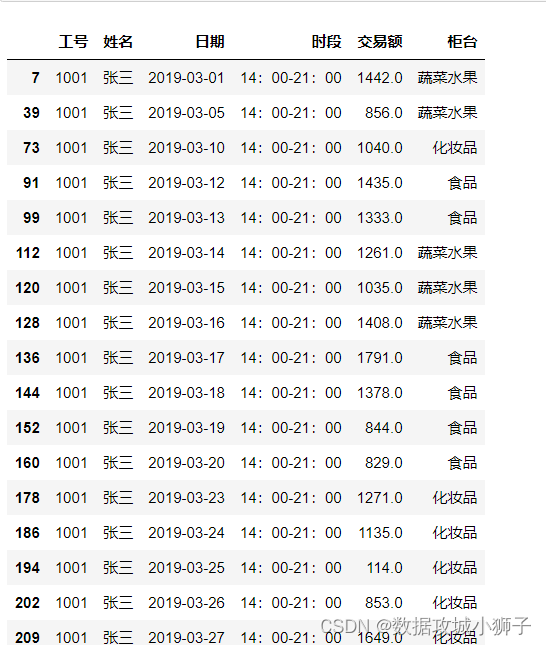
#张三下午班的交易情况
df[(df.姓名=='张三')&(df.时段=='14:00-21:00')]
#日用品柜台销售总额
df[df['柜台']=='日用品']['交易额'].sum()88162.0
#张三和李四2人销售总额
df[df['姓名'].isin(['张三','李四'])]['交易额'].sum()116860.0
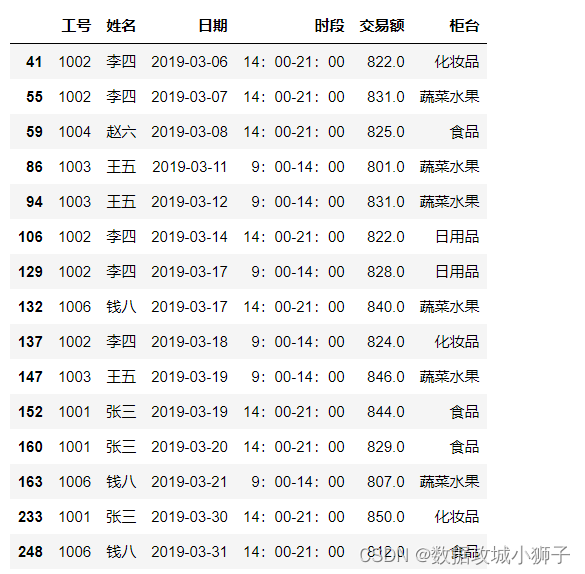
#交易额在指定范围内的记录
df[df['交易额'].between(800,850)]
查看数据特征和统计信息
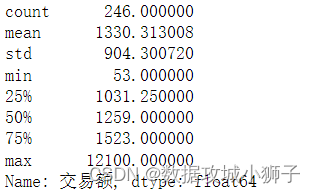
#查看交易额统计信息
df['交易额'].describe()
#交易额四分位数
df['交易额'].quantile([0,0.25,0.5,0.75,1.0])
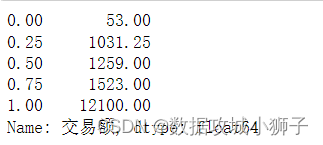
#交易额中值
df['交易额'].median()1259.0
#交易额最小的3条记录
df.nsmallest(3,'交易额')
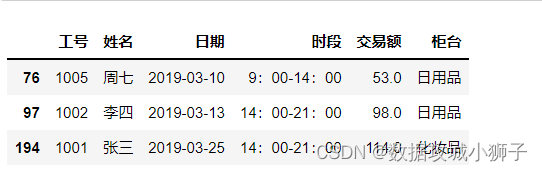
#交易额最大的3条记录
df.nlargest(3,'交易额')
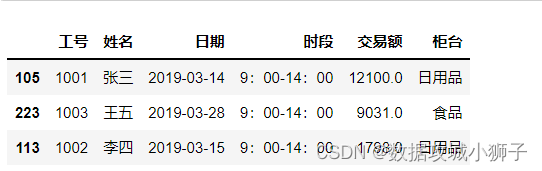
#最后一个日期
df['日期'].max()Timestamp('2019-03-31 00:00:00')
#最小的工号
df['工号'].min()1001
#第一个最小交易额的行下标
index=df['交易额'].idxmin()
print(index)
#第一个最小交易额
print(df.loc[index,'交易额'])76
53.0
#第一个最大交易额的行下标
index=df['交易额'].idxmax()
print(index)
#第一个最大交易额
print(df.loc[index,'交易额'])105
12100.0
按不同标准对数据排序
#按交易额和工号降序排序
df.sort_values(by=['交易额','工号'],ascending=False)
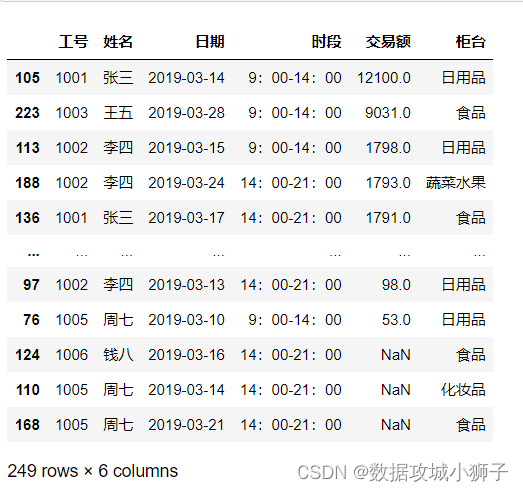
#按交易额降序、工号升序排序
df.sort_values(by=['交易额','工号'],ascending=[False,True])
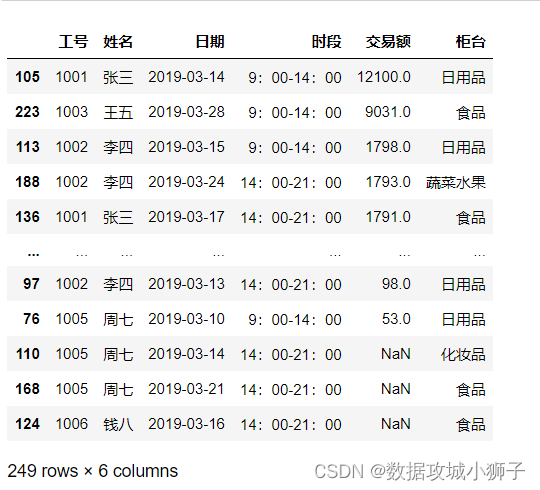
#按工号升序排序,na_position指定缺失值放在最前面/后面,first/last
df.sort_values(by='工号',na_position='last')

#按列名升序排序
#汉字的Unicode编码排序
df.sort_values(by='姓名',ascending=True)
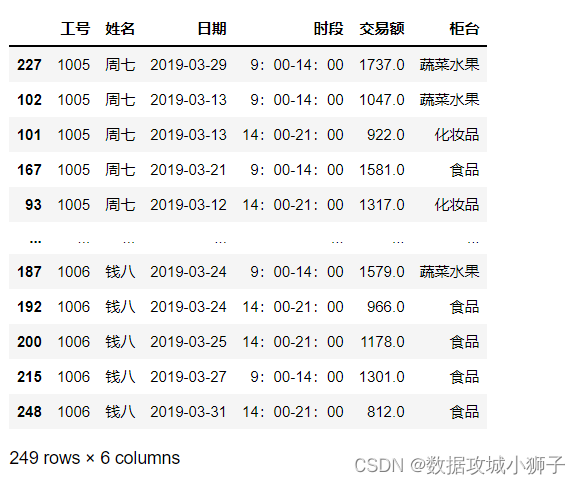
使用分组与聚合对员工业绩进行汇总
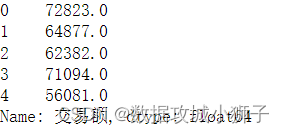
#index对5求余,然后求和
df.groupby(by=lambda num:num%5)['交易额'].sum()
#根据指定字典的键对index进行分组,值为index标签
df.groupby(by={7:'下标为7的行',35:'下标为35的行'})['交易额'].sum()

#不同时段的销售总额
df.groupby(by='时段')['交易额'].sum()
某行数据有问题,但无伤大雅,重要的是方法

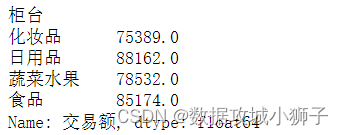
#各柜台销售总额
df.groupby(by='柜台')['交易额'].sum()
#查看每个员工上班总时长是否均匀
ddf=df.groupby(by='姓名')['日期'].count()
ddf.name='上班次数'
ddf

#每个员工交易额的平均值
df.groupby(by='姓名')['交易额'].mean().round(2).sort_values()

#汇总交易额转换为整数
df.groupby(by='姓名').sum()['交易额'].apply(int)

#每个员工交易额的中值
df.groupby(by='姓名')['交易额'].median()

# 每个员工交易额中值的排名
dff=df.groupby(by='姓名').median()
dff['排名']=dff['交易额'].rank(ascending=False)
dff[['交易额','排名']]
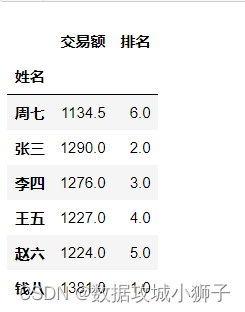
# 每个员工不同时段的交易额
df.groupby(by=['姓名','时段'])['交易额'].sum()
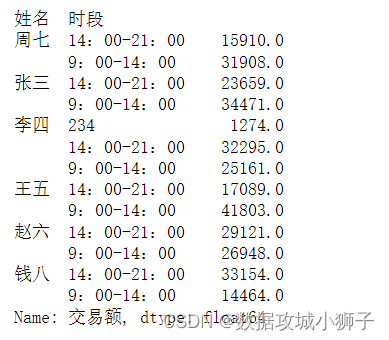
# 时段和交易额采用不同的聚合方式
df.groupby(by=['姓名'])['时段','交易额'].aggregate({'交易额':['sum'],'时段':lambda x:'各时段累计'})
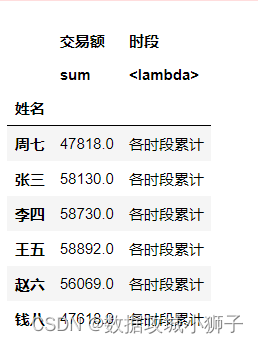
# 使用DataFrame结构的agg()方法对指定列进行聚合
df.agg({'交易额':['sum','mean','min','max','median'],'日期':['min','max']})
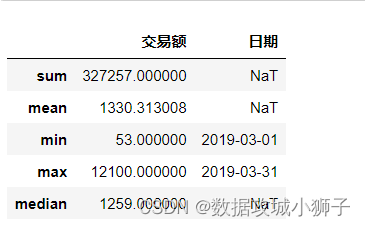
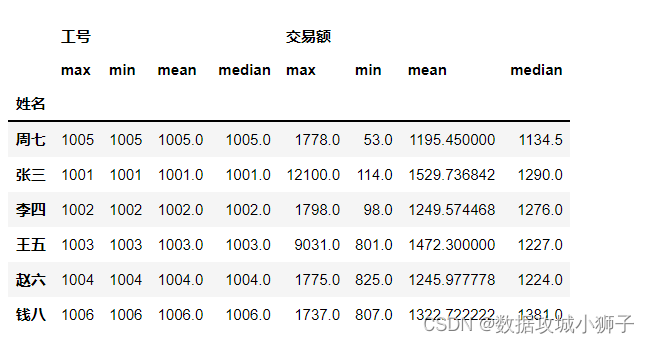
# 对分组结果进行聚合
df.groupby(by='姓名').agg(['max','min','mean','median'])[['工号','交易额']]
相关文章:
pandas数据分析(二)
文章目录DataFrame数据处理与分析读取Excel文件中的数据筛选符合特定条件的数据查看数据特征和统计信息按不同标准对数据排序使用分组与聚合对员工业绩进行汇总DataFrame数据处理与分析 部分数据如下 这个数据百度可以搜到,就是下面这个 读取Excel文件中的数据 …...

Spring实现[拦截器+统一异常处理+统一数据返回]
Spring拦截器 1.实现一个普通拦截器 关键步骤 实现 HandlerInterceptor 接口重写 preHeadler 方法,在方法中编写自己的业务代码 Component public class LoginInterceptor implements HandlerInterceptor {/*** 此方法返回一个 boolean,如果为 true …...
MySQL——插入加锁/唯一索引插入死锁/批量插入效率
本篇主要介绍MySQL跟加锁相关的一些概念、MySQL执行插入Insert时的加锁过程、唯一索引下批量插入可能导致的死锁情况,以及分别从业务角度和MySQL配置角度介绍提升批量插入的效率的方法;MySQL跟加锁相关的一些概念在介绍MySQL执行插入的加锁过程之前&…...

【专项训练】数组、链表
数组array: list = []链表linked list # Definition for singly-linked list. class ListNode:def __init__(self, x):self.val = xself.next =...
基于Jeecgboot前后端分离的ERP系统开发代码生成(六)
商品信息原先生成的不符合要求,重新生成,包括一个附表商品价格信息表 一、采用TAB主题一对多的模式 因为主键,在online表单配置是灰的,所以不能进行外键管理,只能通过下面数据库进行关联录入,否则online界面…...

什么?同步代码块失效了?-- 自定义类加载器引起的问题
一、背景 最近编码过程中遇到了一个非常奇怪的问题,基于单例对象的同步代码块似乎失效了,百思不得其姐。 下面给出模拟过程和最终的结论。 二、场景描述和模拟 2.1 现象描述 Database实现单例,在 init 方法中使用同步代码块来保证 data不…...

CHAPTER 4 文件共享 - Samba
文件共享 - Samba1 Samba1.1 Samba的软件架构1.2 搭建Samba服务器1.3 samba用户管理1. 添加用户2. 修改用户密码3. 删除用户和密码4. 查看samba用户列表5. 查看samba服务器状态1.4 samba共享设置(配置文件详解)1.5 访问共享目录1. windows访问2. linux客…...
深入分析@Configuration源码
文章目录一、源码时序图1. 注册ConfigurationClassPostProcessor流程源码时序图2. 注册ConfigurationAnnotationConfig流程源码时序图3. 实例化流程源码时序图二、源码解析1. 注册ConfigurationClassPostProcessor流程源码解析(1)运行案例程序启动类Conf…...

Unity 代码优化 内存管理优化
项目遇到了卡顿的情况 仔细检查了代码没检查出有误的地方 仔细的总结了一下可以优化的东西 解决了卡顿 记录一下 1 协程 项目之前写的关于倒计时之类的东西 都是开了个协程 虽然协程是消耗很小的线程 , 可是还是有额外消耗 而且 有很多用携程来检测销毁预制体的操作 也都放到U…...
设计模式~门面(外观)模式(Facade)-08
目录 (1)优点 (2)缺点 (3)使用场景 (4)注意事项: (5)应用实例: (6)源码中的经典应用 代码 外观模式&am…...

C++面向对象编程之一:封装
C面向对象编程三大特性为:封装,继承,多态。C认为万事万物皆为对象,对象有属性和行为。比如:游戏里的地图场景可以看作是长方形对象,属性场景id,有长,有宽,可能有NPC&…...

IDEA插件系列(3):Maven Helper插件
一、引言在写Java代码的时候,我们可能会出现Jar包的冲突的问题,这时候就需要我们去解决依赖冲突了,而解决依赖冲突就需要先找到是那些依赖发生了冲突,当项目比较小的时候,还比较依靠IEDA的【Diagrams】查看依赖关系&am…...
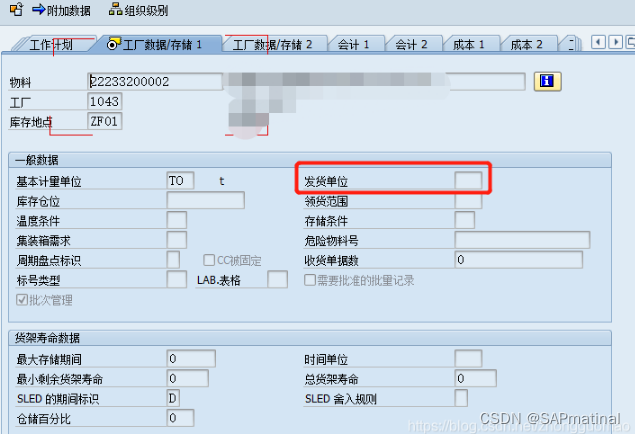
SAP 更改物料基本计量单位
前言部分 在SAP中物料创建后,一旦发生业务,其基本计量单位便很难修改。由于单位无法满足业务要求,往往会要求新建一个物料替代旧物料。这时候除了要将旧物料上所有的未清业务删除外,还需要替换工艺与BOM中的旧物料。特别是当出现旧…...

蓝桥web基础知识学习
HTMLCSS 知识点重要指数HTML 基础标签🌟🌟🌟🌟🌟HTML5 新特性🌟🌟🌟🌟🌟HTML5 本地存储🌟🌟🌟🌟CSS 基础语法…...

Python+ChatGPT制作一个AI实用百宝箱
目录一、注册OpenAI二、搭建网站及其框架三、AI聊天机器人四、AI绘画机器人ChatGPT 最近在互联网掀起了一阵热潮,其高度智能化的功能能够给我们现实生活带来诸多的便利,可以帮助你写文章、写报告、写周报、做表格、做策划甚至还会写代码。只要与文字相关…...

Python中格式化字符串输出的4种方式
Python格式化字符串的4中方式 一、%号 二、str.format(args) 三、f-Strings 四、标准库模板 五、总结四种方式的应用场景’ 一、%号占位符 这是一种引入最早的一种,也是比较容易理解的一种方式.使用方式为: 1、格式化字符串中变化的部分使用占位符 2、…...

C#基础教程15 枚举与类
文章目录 C# 枚举(Enum)声明 enum 变量C# 类(Class)类的定义成员函数和封装C# 中的构造函数关键字 staticC# 枚举(Enum) 枚举是一组命名整型常量。枚举类型是使用 enum 关键字声明的。 C# 枚举是值类型。换句话说,枚举包含自己的值,且不能继承或传递继承。 声明 enum 变…...

三步 让你的 vscode 自动编译ts文件
三步让你的 vscode 自动编译ts文件 TypeScript环境安装与如何在vscode实现自动编译ts文件? 文章目录三步让你的 vscode 自动编译ts文件前提条件环境安装自动编译运行监视任务时报错?前提条件 安装 node 环境 环境安装 tsc 作用:负责将ts 代码 转为 浏…...

STM32程序下载和启动方式
目录1 BOOT引脚配置和下载说明2 关于串口下载方式3 关于一按复位就跑代码4 关于下载调试速度5 关于三种启动方式5.1 FLASH启动5.2 系统存储器器启动5.3 SRAM启动6 关于程序的三种下载方式1 BOOT引脚配置和下载说明 BOOT0BOOT1程序运行ST-Link下载串口下载启动说明xx无0x√√用…...

基础01-ajax fetch axios 的区别
ajax fetch axios 的区别 题目 ajax fetch axios 的区别 分析 三者根本没有可比性,不要被题目搞混了。要说出他们的本质 传统 ajax AJAX (几个单词首字母,按规范应该大写) - Asynchronous JavaScript and XML(异…...

深度解密:如何通过SMUDebugTool完全掌控AMD锐龙处理器的隐藏性能
深度解密:如何通过SMUDebugTool完全掌控AMD锐龙处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: …...

B站缓存视频转换完整指南:3步将m4s文件转为通用MP4
B站缓存视频转换完整指南:3步将m4s文件转为通用MP4 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾在B站缓存了大量珍贵视频…...
)
ChatGPT记忆功能深度解析(2024官方API文档未公开的7个底层机制)
更多请点击: https://kaifayun.com 第一章:ChatGPT记忆功能怎么用 ChatGPT 的记忆功能(Memory)允许模型在对话中持续记住用户提供的关键信息,从而实现更连贯、个性化的交互体验。该功能并非默认开启,需用户…...

3分钟快速解密Navicat密码:开源工具终极指南
3分钟快速解密Navicat密码:开源工具终极指南 【免费下载链接】navicat_password_decrypt 忘记navicat密码时,此工具可以帮您查看密码 项目地址: https://gitcode.com/gh_mirrors/na/navicat_password_decrypt 当您忘记Navicat中保存的数据库连接密码时&#…...

魔兽争霸3闪退修复终极指南:5步让你的经典游戏重获新生
魔兽争霸3闪退修复终极指南:5步让你的经典游戏重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3闪退而烦恼吗&…...

2026年腾讯云OpenClaw/Hermes Agent配置Token Plan部署保姆级
2026年腾讯云OpenClaw/Hermes Agent配置Token Plan部署保姆级。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&am…...

5分钟掌握NCM解密:网易云音乐文件转换终极指南
5分钟掌握NCM解密:网易云音乐文件转换终极指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经遇到过这样的情况:在网易云音…...

GitHub中文插件:打破语言壁垒,让开源协作更顺畅
GitHub中文插件:打破语言壁垒,让开源协作更顺畅 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 你是否曾在Git…...

统信UOS 1070系统克隆实战:用自带工具给电脑做个‘替身’,换机迁移不求人
统信UOS 1070系统克隆实战:用自带工具给电脑做个‘替身’,换机迁移不求人当企业批量采购新设备或个人用户升级电脑时,如何快速将原有系统环境完整迁移到新硬件?传统方案往往依赖第三方工具,而统信UOS 1070内置的备份还…...

终极指南:如何用wxappUnpacker破解微信小程序加密包
终极指南:如何用wxappUnpacker破解微信小程序加密包 【免费下载链接】wxappUnpacker forked from https://github.com/qwerty472123/wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 微信小程序逆向工程一直是开发者面临的核心…...