LLM⊗KG范式下的知识图谱问答实现框架思想阅读
分享一张有趣的图,意思是在分类场景下,使用大模型和fasttext的效果,评论也很逗。
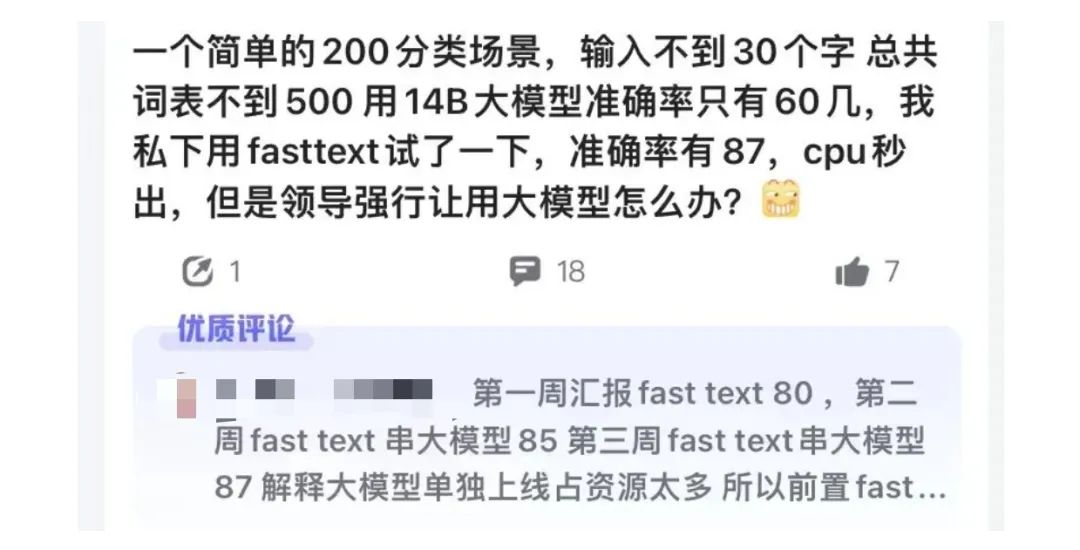
这其实背后的逻辑是,在类别众多的分类场景下,尤其是在标注数据量不缺的情况下,大模型的收益是否能够比有监督模型的收益更多。这个例子虽然没有说标注数据量,但估计量不会少。
我们继续回到知识图谱与大模型的话题:
读到一个大模型和知识图谱融合的有趣工作《 Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph》(https://arxiv.org/pdf/2307.07697.pdf、https://github.com/IDEA-FinAI/ToG.),该工作提出了一种新的LLM-KG集成范式"LLM⊗KG",将LLM视为一个代理,通过交互式地探索KG上的相关实体和关系,并根据检索到的知识执行推理,取得了一定的效果。
这个工作有很多有趣的细节,供大家一起参考。
一、从三种LLM推理范式说起
大模型在各种自然语言处理任务中表现出了卓越的性能,但在面对复杂的知识推理任务时仍有很大的局限性。
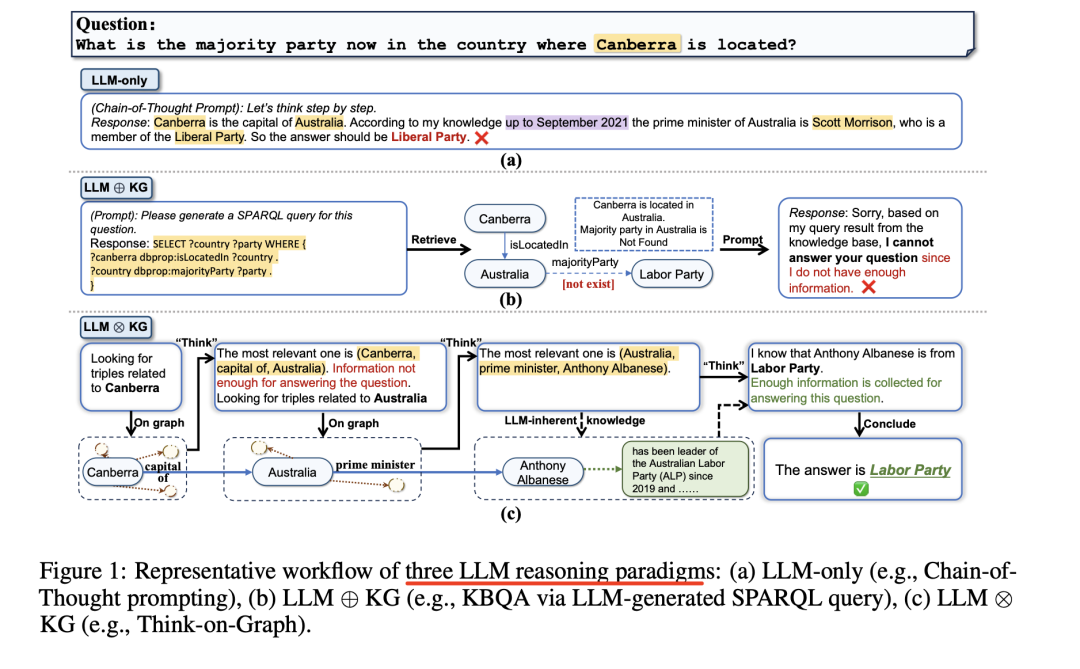
上图1中介绍了三种LLM推理范式的代表性工作流程,其中:
1、纯LLM推理范式
纯LLM,例如采用思维链提示,对于需要专业化知识的问题,LLMs通常无法提供超出预训练阶段(图1a中的过时知识)的准确答案,或者对于需要长逻辑链和多跳知识推理的问题,LLMs也无法提供准确答案。

2、LLM⊕KG范式
LLM⊕KG范式,通常通过LLM生成的SPARQL查询进行KBQA,考虑到纯LLM推理范式的不足,一个自然而有前途的解决方案就是纳入外部知识,如知识图谱(KGs),以帮助提高LLM的推理能力。

早期的研究在预训练或微调过程中将KG中的结构化知识嵌入LLM的底层神经网络。然而,嵌入LLM的KG牺牲了其自身在知识推理中的可解释性和知识更新的效率。
另外一条路,知识图谱提供了结构化、明确和可编辑的知识表征,为缓解LLM的局限性提供了一种补充策略。研究人员已经探索了如何使用KG作为外部知识源来减轻LLM的幻觉。
例如,将LLM与KG结合起来,将KG中的相关结构化知识转化为LLM的文本提示,例如:
Li等人(https://doi.org/10.18653/v1/2023.acl-long.385)使用LLM生成SPARQL查询的主干,并使用KGs填充完整的信息。
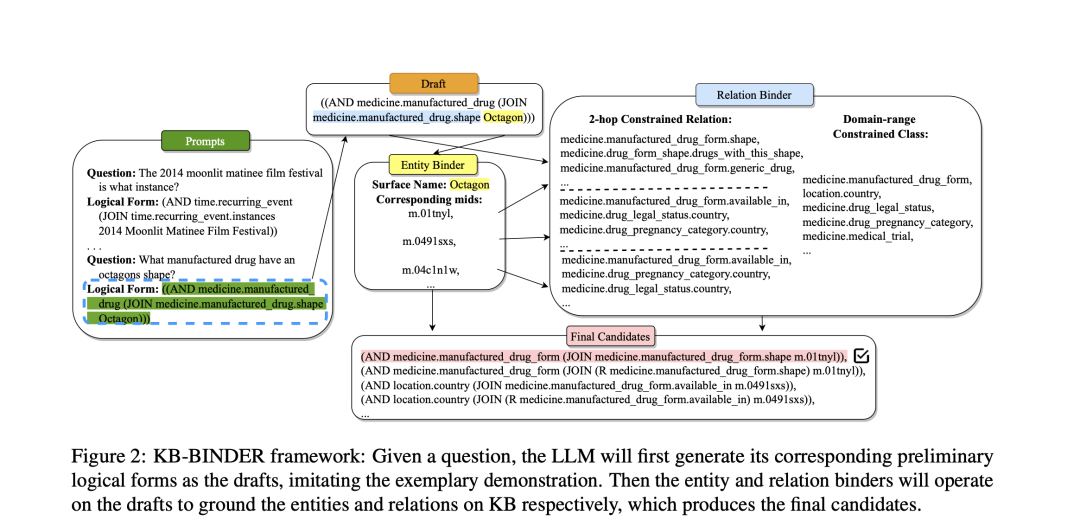
Baek等人(https://arxiv.org/abs/2306.04136)采样了包含出现问题的实体的三元组,用于LLM推理。

Li等人(https://arxiv.org/abs/2305.13269)使用LLM将问题分解为若干子问题,然后使用微调Llama生成相应的可执行SPARQL查询,以便从KGs中检索知识。
Wang等人(https://arxiv.org/abs/2308.13259)提出了一种检索器-阅读器-验证器QA系统,用于访问外部知识并与LLM交互。
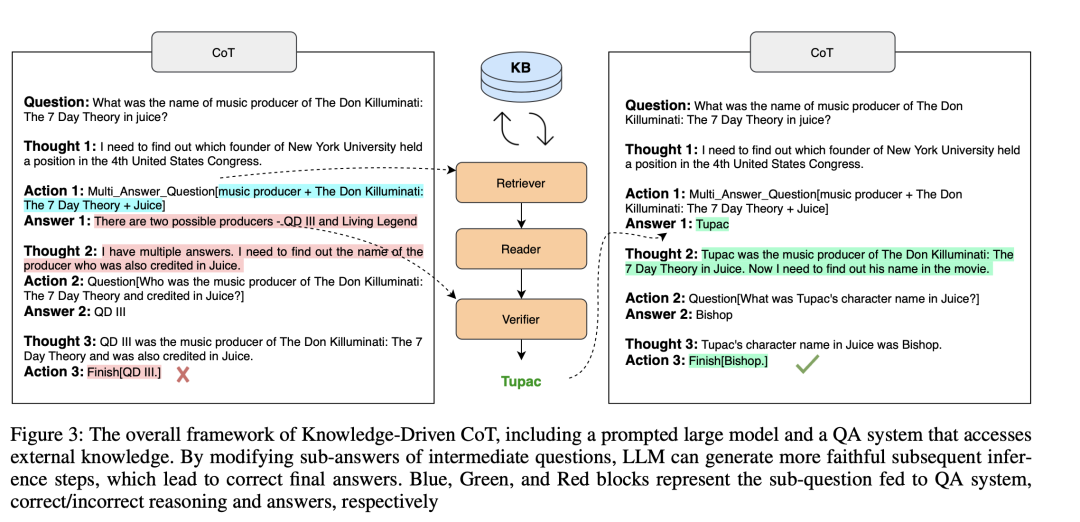
这些方法都遵循一个模式:从大模型获取信息,相应地增强提示,然后将增强后的提示输入LLM。
不过,在LLM⊕KG范式中,LLM扮演的角色是翻译,将输入的问题转换成机器可理解的命令,供KG搜索和推理,但它并不直接参与图推理过程,并且,LLM⊕KG模式成功在很大程度上取决于KG的完整性和高质量。
例如,在图1b中,尽管LLM成功地识别出了回答问题所需的关系类型,但由于缺少关系"多数党",导致无法检索到正确答案。
3、LLM⊗KG
"LLM⊗KG"范式指的是KG和LLM协同工作,在图推理的每个步骤中互为补充,如图1c所示:
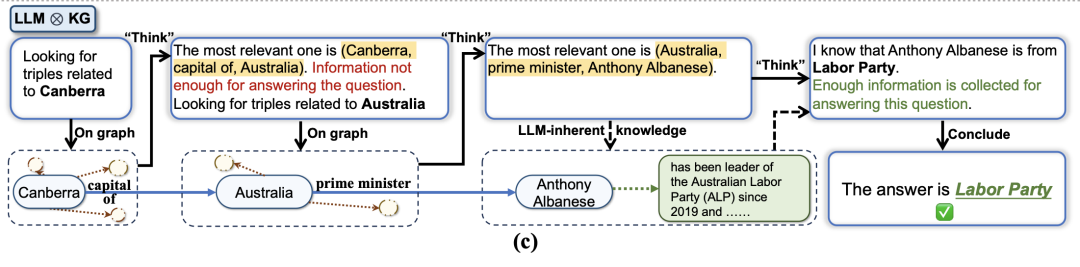
图1c举例说明了LLM⊗KG的优势。在这个例子中,图1b中导致失败的"多数党"关系缺失,可以通过具有动态推理能力的LLM代理(发现的参考三元组(澳大利亚、总理、安东尼-阿尔巴内斯)以及来自LLM固有知识的安东尼-阿尔巴内斯的政党成员身份得到补充。
二、Think-on-Graph(ToG)的实现流程
Think-on-Graph(ToG),意思是LLM沿着图"思考",也就是LLM沿着推理路径"在"知识图谱"上逐步"思考"。
ToG使用KG/LLM推理中的beamsearch搜索算法,允许LLM动态探索KG中的若干推理路径并做出相应决策,简单来说,就是借鉴了Transformer的beam-search算法思路。
该算法为一个可循环的迭代过程,每次循环需先后完成搜索剪枝、推理决策两个任务,搜索剪枝用于找出最有希望成为正确答案的推理路径,推理决策任务则通过LLM来判断已有的候选推理路径是否足以回答问题,如果判断结果为否,则继续迭代到下个循环。
在ToG之外,ToG-R根据实体搜索得到的以EDcand结尾的所有候选推理路径执行推理步骤。与ToG相比,ToG-R省去了使用LLM修剪实体的过程,从而降低了总体成本和推理时间,并且强调关系的字面信息,当中间实体的字面信息缺失或不为LLM所熟悉时,可以降低误导推理的风险。

1、具体实现
图2显示了一个标准的ToG工作流程例子,ToG通过要求LLM在知识图谱上执行束搜索来实现"LLM⊗KG"范式。
ToG会不断更新和维护前N个推理路径P={p1,p2,...其中N表示波束搜索的宽度。ToG的整个推理过程包括以下3个阶段:初始化、探索和推理。
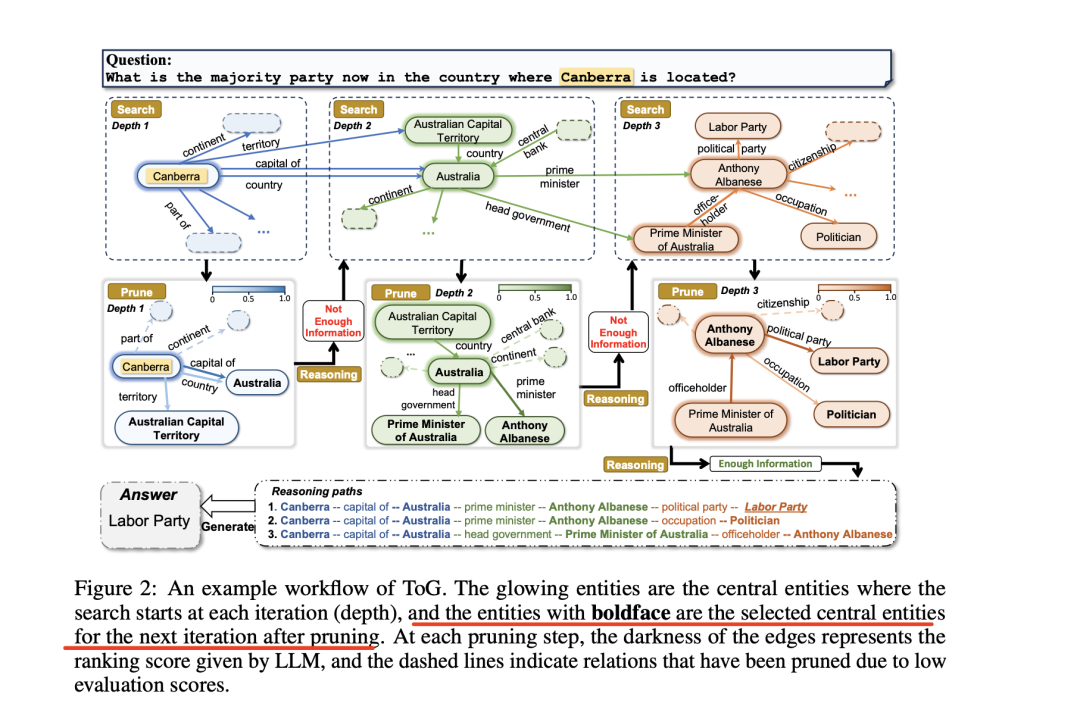
高亮的实体是每次迭代(深度)开始搜索的中心实体,黑体字实体是剪枝后为下一次迭代选择的中心实体。
在每个剪枝步骤中,边的深浅代表LLM给出的排序分数,虚线表示因评估分数低而被剪枝的关系。
因此,这个时候的核心,就在于怎么选择中心实体,以及怎么进行边的排序从而实现剪枝。
1、初始化实体提取
给定问题后,ToG利用底层LLM定位知识图谱上推理路径的初始实体。这一阶段可视为前N个推理路径P的初始化。
ToG首先会提示LLM自动提取问题中的主题实体,并得到问题的前N个主题实体E0={e01,e02,...,e0N},主题实体的数量可能少于N。,这一步可以通过prompt完成。
在测试数据集上,事先给定了主题实体。
例如,在SimpleQA中,topic_entity为预先设置好的主题实体,作为初始化:
{"topic_entity": {"m.02qkg8m": "Madam Satan"},"answer": "United States of America","question": "where is the madam satan located","relation": "country"},{"topic_entity": {"m.04knq3": "California Department of Parks and Recreation"},"answer": "A\u00f1o Nuevo State Park","question": "which parks are a part of the california department of parks and recreation","relation": "member_parks"}
}2、子图查询与路径召回
子图查询中,包括关系查询和实体查询,先根据实体,查找其存在的关系,然后再根据关系,查询对应的实体。

2、关系的剪枝
对于给定的实体,通过查询,可以得到多个路径,需要对路径进行排序,在这里,利用大模型进行评估,通过prompt完成,如:请检索对问题有贡献的N个关系(用分号隔开),并按0到1的等级对其贡献进行评分(N个关系的分数总和为 1)。 如对应的prompt实现代码如下:
如对应的prompt实现代码如下:
extract_relation_prompt = """Please retrieve %s relations (separated by semicolon) that contribute to the question and rate their contribution on a scale from 0 to 1 (the sum of the scores of %s relations is 1).
Q: Name the president of the country whose main spoken language was Brahui in 1980?
Topic Entity: Brahui Language
Relations: language.human_language.main_country; language.human_language.language_family; language.human_language.iso_639_3_code; base.rosetta.languoid.parent; language.human_language.writing_system; base.rosetta.languoid.languoid_class; language.human_language.countries_spoken_in; kg.object_profile.prominent_type; base.rosetta.languoid.document; base.ontologies.ontology_instance.equivalent_instances; base.rosetta.languoid.local_name; language.human_language.region
A: 1. {language.human_language.main_country (Score: 0.4))}: This relation is highly relevant as it directly relates to the country whose president is being asked for, and the main country where Brahui language is spoken in 1980.
2. {language.human_language.countries_spoken_in (Score: 0.3)}: This relation is also relevant as it provides information on the countries where Brahui language is spoken, which could help narrow down the search for the president.
3. {base.rosetta.languoid.parent (Score: 0.2)}: This relation is less relevant but still provides some context on the language family to which Brahui belongs, which could be useful in understanding the linguistic and cultural background of the country in question.
Q: """3、实体的剪枝
让大模型用0至1分给各实体对问题的贡献打分(所有实体得分之和为1),用来做评分对比,也是通过prompt实现:

如对应的prompt实现代码如下:
score_entity_candidates_prompt = """Please score the entities' contribution to the question on a scale from 0 to 1 (the sum of the scores of all entities is 1).
Q: The movie featured Miley Cyrus and was produced by Tobin Armbrust?
Relation: film.producer.film
Entites: The Resident; So Undercover; Let Me In; Begin Again; The Quiet Ones; A Walk Among the Tombstones
Score: 0.0, 1.0, 0.0, 0.0, 0.0, 0.0
The movie that matches the given criteria is "So Undercover" with Miley Cyrus and produced by Tobin Armbrust. Therefore, the score for "So Undercover" would be 1, and the scores for all other entities would be 0.
Q: {}
Relation: {}
Entites: """4、判断是否满足条件
通过探索过程获得当前推理路径P后,会提示LLM评估当前推理路径是否足以生成答案。如果评估结果是肯定的,就提示LLM以查询为输入,使用推理路径生成答案。
反之,如果评估结果为负,则重复探索和推理步骤,直到评估结果为正或达到最大搜索深度Dmax。
如果算法尚未结束,则表明即使达到最大搜索深度Dmax,ToG仍无法探索出解决问题的推理路径。在这种情况下,ToG将完全根据LLM中的固有知识生成答案。
这一目标,同样也是依赖prompt完成处理,思想在于:给定一个问题和相关的检索知识图谱三元组(实体、关系、实体),要求大模型回答用这些三元组和大模型知识是否足以回答这个问题(是或否)。


5、生成结果
生成结果阶段,直接将检索到的文本加入到prompt中,送入大模型,完成答案生成。

三、具体的效果与有趣的结论
1、一个具体的例子
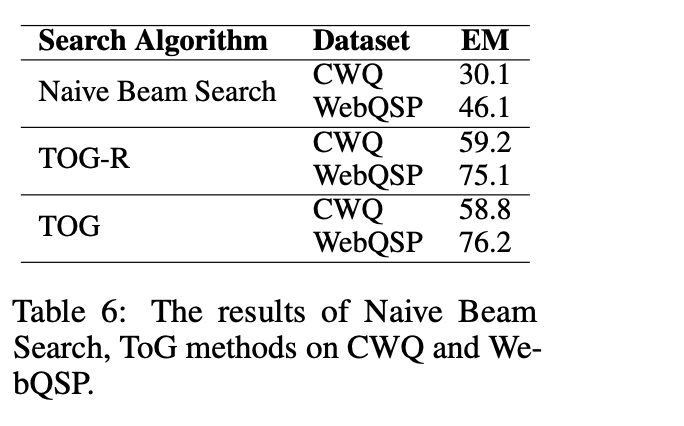
如下表所示,可以看看一个具体的例子,给定问题,得到推理路径,生成答案。

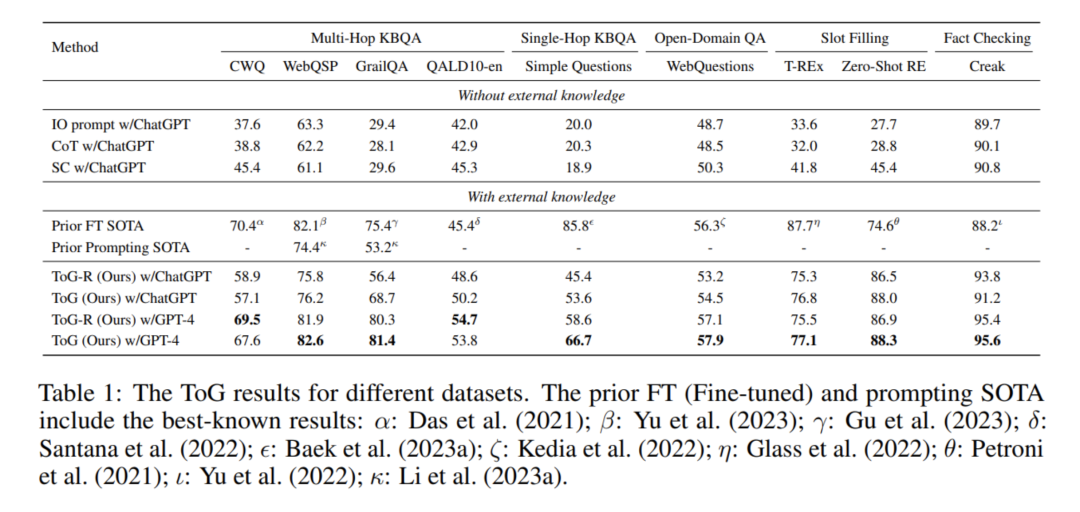
2、对应效果
具体地指标可以从下表中看到,有一定的收益。
3、一些有趣的发展
其一,为了探索搜索深度Dmax和波束宽度N对ToG性能的影响,该工作在深度为1到4和宽度为1到4的设置下进行了实验。
如图3所示,ToG的性能随着搜索深度和宽度的增加而提高。这也意味着ToG的性能有可能随着探索深度和广度的增加而提高。【这个跟问题是否多跳有很大关系】
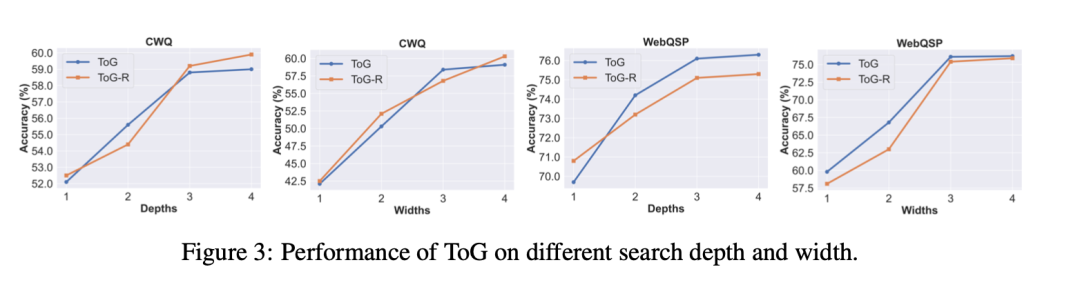
另一方面,当深度超过3时,性能增长就会减弱。这主要是因为只有一小部分问题的推理深度(基于SPARQL中的关系数,大于3。
其二,为了探究不同的提示设计对ToG的影响,需要确定哪种类型的提示表示法更为实用。实验结果见表4。
其中:
"Triplet"表示使用三重格式作为提示来表示多个路径,如"(堪培拉,澳大利亚首都),(澳大利亚,总理,安东尼-阿尔巴内斯)"。
"sequence"是指使用序列格式,如图2所示。
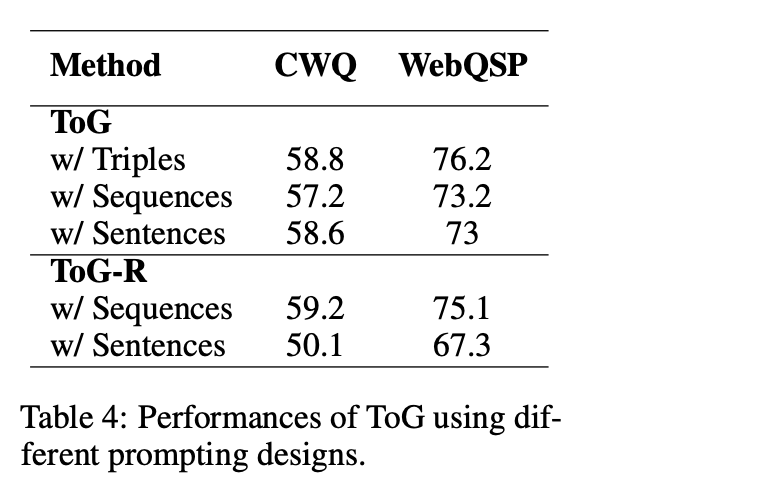
"sentence"涉及将三元组转换为自然语言句子。例如,"(堪培拉,澳大利亚首都)"可转换为"堪培拉的首都是澳大利亚"。
结果表明,在推理路径中使用基于三元组的表示法能产生最高的效率和最好的性能。
相反,在考虑ToG-R时,每条推理路径都是以主题实体为起点的关系链,因此与基于triple的提示表示法不兼容。因此,将ToG-R转换为自然语言形式会导致提示过于冗长,从而导致性能明显下降。
其三,不同剪枝工具的影响。除了LLM之外,像BM25和SentenceBERT这样能确保文本相似性的轻量级模型也可以在探索阶段用作剪枝工具。
例如,可以根据实体和关系与问题的字面相似性来选择前N个实体和关系。对ToG性能的影响,如表5所示。使用BM25或SentenceBERT替代LLM会导致性能显著下降。
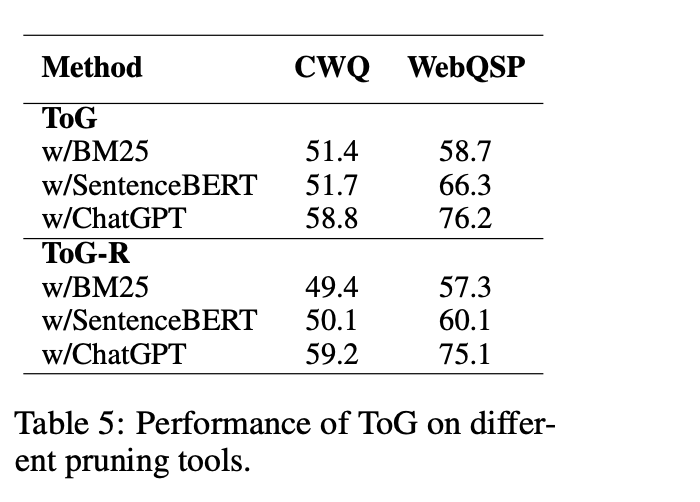
不过,在使用BM25或SentenceBERT后,可以有效减少调用LLM的次数。
其四,种子示例数量的敏感性。为了更好地了解ToG对种子示例数量的敏感性,该工作进行敏感性分析。
具体地,在fewshot试验的基础上,并从训练集中选择了1-6个示例作为fewshot试验设置。在Fewshot测试中,随机选择{1,2,3,4,6}个示例中的M个作为示例,并重复实验三次。随着示例数量的增加,整体性能也普遍提高。
总结
本文主要介绍了一个大模型和知识图谱融合的有趣工作《 Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph》(https://arxiv.org/pdf/2307.07697.pdf、https://github.com/IDEA-FinAI/ToG.),该工作提出了一种新的LLM-KG集成范式"LLM⊗KG",将LLM视为一个代理,通过交互式地探索KG上的相关实体和关系,并根据检索到的知识执行推理,取得了一定的效果。
其中关于剪枝的算法、prompt构造细节都值得我们学习,具体细节,可以看源代码,会有更多收获。
参考文献
1、https://arxiv.org/pdf/2307.07697.pdf
2、https://github.com/IDEA-FinAI/ToG.
相关文章:
LLM⊗KG范式下的知识图谱问答实现框架思想阅读
分享一张有趣的图,意思是在分类场景下,使用大模型和fasttext的效果,评论也很逗。 这其实背后的逻辑是,在类别众多的分类场景下,尤其是在标注数据量不缺的情况下,大模型的收益是否能够比有监督模型的收益更多…...

ue引擎游戏开发笔记(35)——为射击添加轨道,并显示落点
1.需求分析: 我们只添加了开枪特效,事实上并没有实际的效果产生例如弹痕,落点等等。所以逐步实现射击的完整化,先从实现落点开始。 2.操作实现: 1.思路:可以这样理解,每次射击的过程是一次由摄…...

路由策略与路由控制
1.路由控制工具 匹配工具1:访问控制列表 (1)通配符 当进行IP地址匹配的时候,后面会跟着32位掩码位,这32位称为通配符。 通配符,也是点分十进制格式,换算成二进制后,“0”表示“匹配…...

JAVA版本的ATM编程问题记录
前段时间用C语言写了个银行ATM系统,还写了一篇文章记录了一些,C语言的ATM文章。后来又用IDEA写了一个JAVA版本的银行ATM。有人就会问为啥浪费这个时间写ATM呢?🧐其实是我本科代码没学好,所以现在想利用比较熟悉的ATM系…...
C#winfrom三层架构实现简单课程管理系统管理系统,三层架构实现增删改查
1. 项目展示 1.1登录展示 1.2添加课程信息展示 1.3课程信息管理-查询-修改-删除 1.4修改登录密码 2.项目功能介绍(图) 3.数据库设计 3.1 教师表设计 3.2 课程分类表 3.3 课程信息表 4. 创建样式界面 winfrom 超详细UI创建过程 实现双色球选号器UI界面…...
AI技术赋能下的视频监控方案是如何解决新能源汽车充电难问题的?
一、方案背景 刚刚结束的第十八届北京车展异常火爆,其中一组与汽车有关的数字让人格外关注。根据乘联会2024年4月19日公布的最新数据,全国乘用车市场零售达到51.6万辆,其中新能源车的销量约为26万辆,市场渗透率达到50.39%。 这意味…...

长难句打卡5.6
For H&M to offer a $5.95 knit miniskirt in all its 2,300-plus stores around the world, it must rely on low-wage overseas labor, order in volumes that strain natural resources, and use massive amounts of harmful chemicals. 翻译:H&M若要在其全球总共2…...
总结)
PDF编辑器软件常见问题(技巧)总结
目录 问题pdf高级编辑器中编辑文字时" 格式 " 如何出现? 待续、更新中 问题 pdf高级编辑器中编辑文字时" 格式 " 如何出现? shiftF4 待续、更新中 1 顿号“、” : 先使用ctrl. 再使用一遍切回 2 下标: 在数字两边加上 ~ 即可 , 21 3 上标: 2 0 2^{0} …...
)
Dive into Deep Learning-优化算法(1)
优化和深度学习的关系 优化是最小化损失函数,而深度学习的目标是在给定有限数据量的情况下寻找合适的模型,分别对应着训练误差和泛化误差;需要注意过拟合; 优化面临的挑战(求解数值解) 局部最小值&#…...
Partisia Blockchain 生态首个zk跨链DEX现已上线
在5月1日,由Partisia Blockchain与zkCross创建合作推出的Partisia zkCrossDEX在Partisia Blockchain生态正式上线。Partisia zkCrossDEX是Partisia Blockchain上重要的互操作枢纽,其融合了zkCross的zk技术跨链互操作方案,并利用Partisia Bloc…...
.NET操作 Access (MSAccess)
注意:新项目推荐 Sqlite ,Access需要注意的东西太多了,比如OFFICE版本,是X86还是X64 连接字符串 ProviderMicrosoft.ACE.OleDB.15.0;Data Source"GetCurrentProjectPath"\\test.accdb//不同的office版本 连接字符串有…...

shell脚本,删除30天以前的日志,并将日志推送到nas,但运行出现/bin/bash^M。
删除30天以前的日志 将日志推送到nas中,然后删除pod中的日志 pod挂载到本地 运行出现/bin/bash^M 1、删除30天以前的日志: #! /bin/bash# 定义源日志目录 LOG_DIR/home/log/ # 删除日志 find $LOG_DIR -type f -name "*.log" -mtime 30 -exec…...

现身说法暑期三下乡社会实践团一个好的投稿方法胜似千军万马
作为一名在校大学生,去年夏天我有幸参与了学院组织的暑期大学生三下乡社会实践活动,这段经历不仅让我深入基层,体验了不一样的生活,更是在新闻投稿的实践中,经历了一次从传统到智能的跨越。回忆起那段时光,从最初的邮箱投稿困境,到后来智慧软文发布系统的高效运用,每一步都刻印…...
小程序账号设置以及request请求的封装
一般开发在小程序时,都会有测试版和正式版,这样在开发时会比较方便。 在开发时。产品经理都会给到测试账号和正式账号,后端给的接口也都会有测试环境用到的接口和正式环境用到的接口。 这里讲一讲我这边如何去做的。 1.在更目录随便命名一…...

怎么解决端口被占用
目录 一、引言 二、解决方法 一、引言 最近用vscode写网页,老是遇见端口被占用,报错如下: listen tcp :8080: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted. 二、解决方法 1.换…...

JavaScript 循环方法详解
在编程中,循环是一种重复执行代码块的机制,直到满足某个条件为止。JavaScript 提供了多种循环结构来帮助我们实现这一功能。以下是 JavaScript 中常用的几种循环方法的详细解释。 1. for 循环 for 循环是 JavaScript 中最常用的循环结构之一。它使用一…...
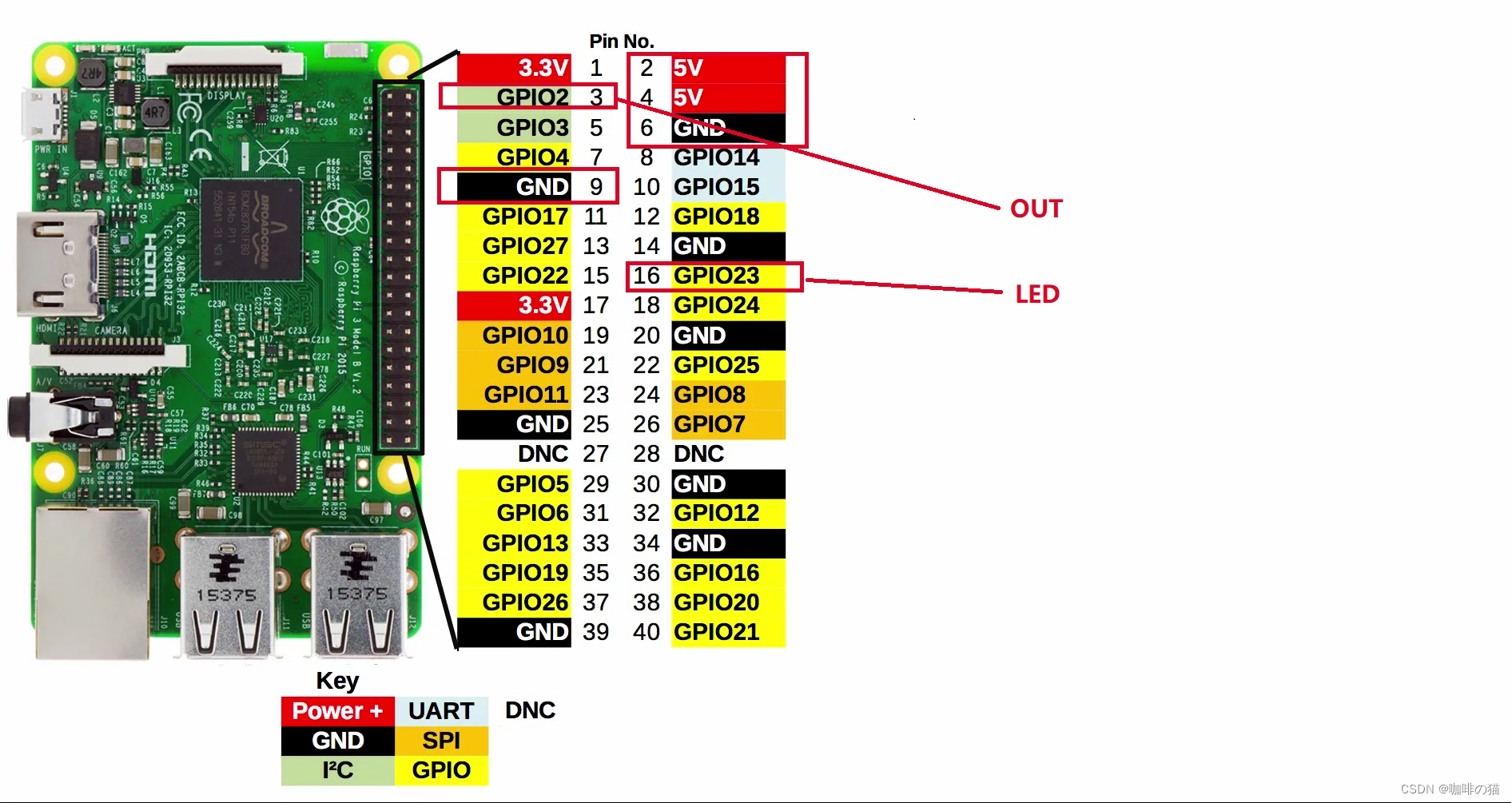
树莓派4b测量PM2.5
1.GP2Y1010AU0F粉尘传感器连接图 2. GP2Y1010AU0F工作原理 工作原理 传感器中心有个洞可以让空气自由流过,定向发射LED光,通过检测经过空气中灰尘折射过后的光线来判断灰尘的含量。 3.源代码 main.py # coding=UTF-8 import RPi.GPIO as GPIO from ADC import ADS1015…...

恒生电子,快手25届实习内推
恒生电子,快手25届实习内推 ①快手 【岗位】算法、工程、游戏,产品运营、市场、职能等 【一键内推】https://campus.kuaishou.cn/recruit/campus/e/h5/#/campus/jobs?codecampuswQrLOMvHE 【内推码】campuswQrLOMvHE ②恒生电子 【招聘岗位】JAVA、测试…...

蓝桥杯练习系统(算法训练)ALGO-949 勇士和地雷阵
资源限制 内存限制:256.0MB C/C时间限制:1.0s Java时间限制:3.0s Python时间限制:5.0s 问题描述 勇士们不小心进入了敌人的地雷阵(用n行n列的矩阵表示,*表示某个位置埋有地雷,-表示某个…...
一面)
腾讯安全客户端(电脑管家部门)一面
上来介绍部门,之后自我介绍 说了是个喜欢每天都学点新东西的人,然后平常也会在课余时间之外去做点项目方面的学习,比如Web项目做出来就是因为兴趣。喜欢结构性的东西,有一门课叫电路电子学一次考试是专业第二。其他也都还可以&am…...

IDE扩展管理套件:实现配置即代码与团队环境同步
1. 项目概述:一个为开发者定制的IDE扩展管理套件如果你和我一样,每天的工作都离不开各种集成开发环境(IDE),比如 Visual Studio Code、IntelliJ IDEA 或者 PyCharm,那你一定对“扩展”或“插件”又爱又恨。…...

从数据迷雾到精准洞察:Granblue Fantasy: Relink战斗分析工具深度解析
从数据迷雾到精准洞察:Granblue Fantasy: Relink战斗分析工具深度解析 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors/gb/gbfr…...

避开安全门调试大坑:详解西门子SFDOOR指令的3个关键参数与常见故障复位
西门子SFDOOR指令实战排错手册:3个关键参数解析与故障复位技巧 1. 安全门控制的核心逻辑与典型故障模式 在工业自动化现场,安全门作为保护人员安全的关键设备,其可靠性直接关系到生产系统的稳定运行。西门子SFDOOR功能块通过双通道信号检测和…...

别再被Nginx的rewrite循环搞懵了!一个真实Vue项目部署的500错误排查实录
从Nginx重定向死循环到优雅解决:Vue项目部署的深度排错指南 凌晨三点,服务器监控突然告警——刚上线的Vue企业门户网站出现大面积500错误。查看日志时,那个令人窒息的rewrite or internal redirection cycle错误信息让整个运维团队陷入沉思。…...

写论文缺参考文献?教你一招最快的反向查文献
写文献综述、毕业论文、科研报告时,你是不是也常遇到这些难题:观点明明写得很清楚,却找不到权威文献支撑;文献综述凑不够篇幅,论据来源不充分;逐篇翻数据库筛选文献太耗时,引文格式排版还总出错…...

从电机控制到服务器电源:详解功率MOSFET栅极外加电容CGS与CGD的选型计算与布局要点
功率MOSFET栅极电容设计实战:从电机驱动到服务器电源的差异化策略 在电力电子系统的核心地带,功率MOSFET如同精密交响乐团的指挥,其开关性能直接决定整个系统的效率与可靠性。当我们面对电机驱动系统要求快速切换以降低损耗,或是服…...

告别商业收费与审核枷锁:深度拆解 Open-Generative-AI,构建 MIT 开源、零过滤的私有化视频生成工作站
发布日期: 2026-05-18标签: #Open-Generative-AI #Sora #Flux #Veo #AI视频生成 #私有化部署一、 引言在 2026 年,大模型生成图像与视频(Text-to-Video)的技术已经炉火纯青,但创作者们依然面临着三大难以言…...

使用Taotoken后我们如何观测与优化大模型API调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后我们如何观测与优化大模型API调用成本 1. 从黑盒到透明:成本观测的第一步 在接入大模型API的初期&…...

抠图怎么抠出来?2026年最好用的免费AI抠图工具测评指南
你是否经常为了一张证件照、商品图或者头像而烦恼?想要快速去掉背景但又不想学复杂的PS操作?我今天要分享的,就是如何用现代AI抠图工具轻松搞定这一切。为什么抠图这么难?抠图之所以成为很多人的"老大难",主…...

Arduino Audio Tools终极指南:从音频新手到专业开发者的完整解决方案
Arduino Audio Tools终极指南:从音频新手到专业开发者的完整解决方案 【免费下载链接】arduino-audio-tools Arduino Audio Tools (a powerful Audio library not only for Arduino) 项目地址: https://gitcode.com/gh_mirrors/ar/arduino-audio-tools 在嵌入…...