Ubuntu22.04下安装kafka_2.11-0.10.1.0并运行简单实例
目录
一、版本信息
二、安装Kafka
1.将Kafka安装包移到下载目录中
2.下载Spark并确保hadoop用户对Spark目录有操作权限
三、启动Kafka并测试Kafka是否正常工作
1.启动Kafka
2.测试Kafka是否正常工作
一、版本信息
虚拟机产品:VMware® Workstation 17 Pro 虚拟机版本:17.0.0 build-20800274
ISO映像文件:ubuntukylin-22.04-pro-amd64.iso
Hadoop版本:Hadoop 3.1.3
JDK版本:Java JDK 1.8
Spark版本:Spark 3.2.0
Kafka版本:kafka_2.11-0.10.1.0
前面的2.11就是该Kafka所支持的Scala版本号,后面的0.10.1.0是Kafka自身的版本号
这里有我放的百度网盘下载链接,读者可以自行下载:
链接:https://pan.baidu.com/s/121zVsgc4muSt9rgCWnJZmw
提取码:wkk6
也可去Kafka官网进行下载:Apache Kafka
注意:其中的ISO映像文件为ubuntukylin-16.04.7版本的而不是22.04版本,22.04版本内存过大无法上传,见谅!!!
附上Ubuntu Kylin(优麒麟)官网下载:优麒麟 (ubuntukylin.com) 读者可以前去官网下载ISO映像文件
现附上相关资料,读者可通过这些资料来查看自己的Spark与其他组件(例如JDK,Hadoop,Yarn,Hive,Kafka等)的兼容版本、Spark Streaming + Kafka 集成指南、Kafka清华源镜像下载地址等:
1. 查看Spark与Hadoop等其他组件的兼容版本
查看Spark与Hadoop等其他组件的兼容版本 - 技术研究与问题解决 - 博客园 (cnblogs.com)![]() https://www.cnblogs.com/liuys635/p/12371793.html
https://www.cnblogs.com/liuys635/p/12371793.html
2. Github中Spark开源项目地址
apache/spark: Apache Spark - A unified analytics engine for large-scale data processing (github.com)![]() https://github.com/apache/spark3. Spark Streaming + Kafka 集成指南
https://github.com/apache/spark3. Spark Streaming + Kafka 集成指南
Spark Streaming + Kafka Integration Guide (Kafka broker version 0.10.0 or higher) - Spark 3.2.0 Documentation (apache.org)![]() https://spark.apache.org/docs/3.2.0/streaming-kafka-0-10-integration.html4. Kafka清华源镜像下载地址
https://spark.apache.org/docs/3.2.0/streaming-kafka-0-10-integration.html4. Kafka清华源镜像下载地址
Index of /apache/kafka (tsinghua.edu.cn)![]() https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/
https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/
二、安装Kafka
1.将Kafka安装包移到下载目录中
将物理机上下载的Kafka安装包拖拽到读者虚拟机Ubuntu系统家目录中的下载目录中(安装包内已经附带zookeeper,不需要额外安装zookeeper):

2.下载Spark并确保hadoop用户对Spark目录有操作权限
sudo tar -zxf ~/下载/kafka_2.11-0.10.1.0.tgz -C /usr/local
cd /usr/local
sudo mv kafka_2.11-0.10.1.0/ ./kafka
sudo chown -R hadoop ./kafka # 此处的 hadoop 为你的用户名sudo tar -zxf ~/下载/kafka_2.11-0.10.1.0.tgz -C /usr/local:
- 使用
sudo权限解压缩并解包 Kafka 压缩包文件kafka_2.11-0.10.1.0.tgz -zxf参数表示使用 gzip 解压缩,并且是解包操作~/下载/kafka_2.11-0.10.1.0.tgz是 Kafka 压缩包的路径-C /usr/local指定了解压缩后的文件应该放置的目标路径为/usr/local
cd /usr/local:
- 切换当前工作目录到
/usr/local
sudo mv kafka_2.11-0.10.1.0/ ./kafka:
- 使用
sudo权限将 Kafka 解压后的文件夹kafka_2.11-0.10.1.0重命名为kafka ./kafka意味着将文件夹移动到当前目录下,也就是/usr/local目录
sudo chown -R hadoop ./kafka:
- 使用
sudo权限递归地更改kafka文件夹及其所有子文件和子文件夹的所有者为hadoop用户 -R参数表示递归地更改权限

至此,Kafka安装完成,下面在Ubuntu系统环境下测试简单的实例
三、启动Kafka并测试Kafka是否正常工作
1.启动Kafka
打开第一个终端,输入下面命令启动Zookeeper服务:
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties千万不要关闭这个终端窗口,一旦关闭,Zookeeper服务就停止了(Kafka工作运行完毕后不再使用时再关闭)

打开第二个终端,然后输入下面命令启动Kafka服务:
cd /usr/local/kafka
bin/kafka-server-start.sh config/server.properties千万不要关闭这个终端窗口,一旦关闭,Kafka服务就停止了(Kafka工作运行完毕后不再使用时再关闭)

2.测试Kafka是否正常工作
再打开第三个终端,然后输入下面命令创建一个自定义名称为“wordsendertest”的Topic:
cd /usr/local/kafka
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wordsendertest
#可以用list列出所有创建的Topic,验证是否创建成功
./bin/kafka-topics.sh --list --zookeeper localhost:2181- kafka-topics.sh:Kafka 提供的命令行工具,用于管理 Kafka 主题(topics)
- --create:指示命令要创建一个新的主题
- --zookeeper localhost:2181:指定ZooKeeper 的连接地址,Kafka 使用 ZooKeeper 来管理集群的状态信息。在此,localhost:2181 表示 ZooKeeper 运行在本地主机上,端口号为2181
- --replication-factor 1:指定主题的副本因子(replication factor),即该主题的每个分区的数据将被复制到几个副本中。这里设置为1,表示每个分区只有一个副本
- --partitions 1:指定主题的分区数。分区用于将主题的数据分散存储和处理,可以提高性能和扩展性。这里设置为1,表示只有一个分区
- --topic dblab:指定要创建的主题的名称,这里命名为 "dblab"。 在本地主机上创建一个名为 "dblab" 的 Kafka 主题,该主题具有1个副本因子和1个分区

下面用生产者(Producer)来产生一些数据,请在当前终端(记作“数据源终端”)内继续输入下面命令:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic wordsendertest- - kafka-console-producer.sh: Kafka 提供的命令行工具,用于在控制台上向 Kafka 主题发送消息
- --broker-list localhost:9092:指定Kafka 集群的 broker 地址列表,用于指定消息要发送到哪个 Kafka 集群。在此,localhost:9092 表示 Kafka 集群的一个 broker 运行在本地主机上,端口号为9092
- --topic dblab:指定要发送消息的目标主题,这里是 "dblab"。 在本地主机上向名为 "dblab" 的 Kafka 主题发送消息
上面命令执行后,就可以在当前终端内用键盘输入一些英文单词(也可以等消费者启用后再输入)
现在可以启动一个消费者(Consumer),来查看刚才生产者产生的数据。请另外打开第四个终端,输入下面命令:
cd /usr/local/kafka
./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wordsendertest --from-beginning- - kafka-console-consumer.sh:Kafka 提供的命令行工具,用于在控制台上消费 Kafka 主题的消息
- --zookeeper localhost:2181:指定了 ZooKeeper 的连接地址,Kafka 使用 ZooKeeper 来管理集群的状态信息。在此,localhost:2181 表示 ZooKeeper 运行在本地主机上,端口号为2181。尽管在较新的 Kafka 版本中,已经不再需要指定 ZooKeeper 地址,而是直接连接到 Kafka broker,但是一些旧版本的命令仍然需要指定
- --topic dblab:指定要消费消息的目标主题,这里是 "dblab"
- --from-beginning:指示消费者从该主题的起始位置开始消费消息,而不是从当前最新的消息开始消费。 从名为 "dblab" 的 Kafka 主题消费消息,并从起始位置开始消费
可以看到,屏幕上会显示出如下结果,也就是刚才在另外一个终端里面输入的内容(启动消费者后亦可在生产者中输入内容,消费者终端也可查看到)

-> 实例运行结束后可以Ctrl+Z停止进程 ~~~
相关文章:
Ubuntu22.04下安装kafka_2.11-0.10.1.0并运行简单实例
目录 一、版本信息 二、安装Kafka 1.将Kafka安装包移到下载目录中 2.下载Spark并确保hadoop用户对Spark目录有操作权限 三、启动Kafka并测试Kafka是否正常工作 1.启动Kafka 2.测试Kafka是否正常工作 一、版本信息 虚拟机产品:VMware Workstation 17 Pro 虚…...

【S32K3 MCAL配置】-7.2-GPT Driver:仿OS,周期/定时调用APP SWC和BSW模块的主函数
"><--返回「Autosar_MCAL高阶配置」专栏主页--> 案例背景:当没有移至FreeRTOS时,如何仿OS,快速搭建“若干个周期执行的Task”,在其中周期/定时调用APP SWC和BSW模块的主函数。 并在这个简易的仿OS中,如何设置“主函数调用的先后顺序”,以及如何设置“主函…...

golang内置包里面的sort.Slice 切片排序函数使用示例
go语言里面用的最多的数据类型应该是切片Slice了, 今天就给大家介绍这个go内置包里面的切片排序函数的使用方法 函数原型 func Slice(x any, less func(i, j int) bool) 参数说明 这个函数有2个参数, 第一个是你要进行排序的slice切片,地个…...

Golang | Leetcode Golang题解之第70题爬楼梯
题目: 题解: func climbStairs(n int) int {sqrt5 : math.Sqrt(5)pow1 : math.Pow((1sqrt5)/2, float64(n1))pow2 : math.Pow((1-sqrt5)/2, float64(n1))return int(math.Round((pow1 - pow2) / sqrt5)) }...

区块链 | NFT 相关论文:Preventing Content Cloning in NFT Collections(三)
🐶原文: Preventing Content Cloning in NFT Collections 🐶写在前面: 这是一篇 2023 年的 CCF-C 类,本博客只记录其中提出的方法。 F C o l l N F T \mathbf{F_{CollNFT}} FCollNFT and Blockchains with Native S…...
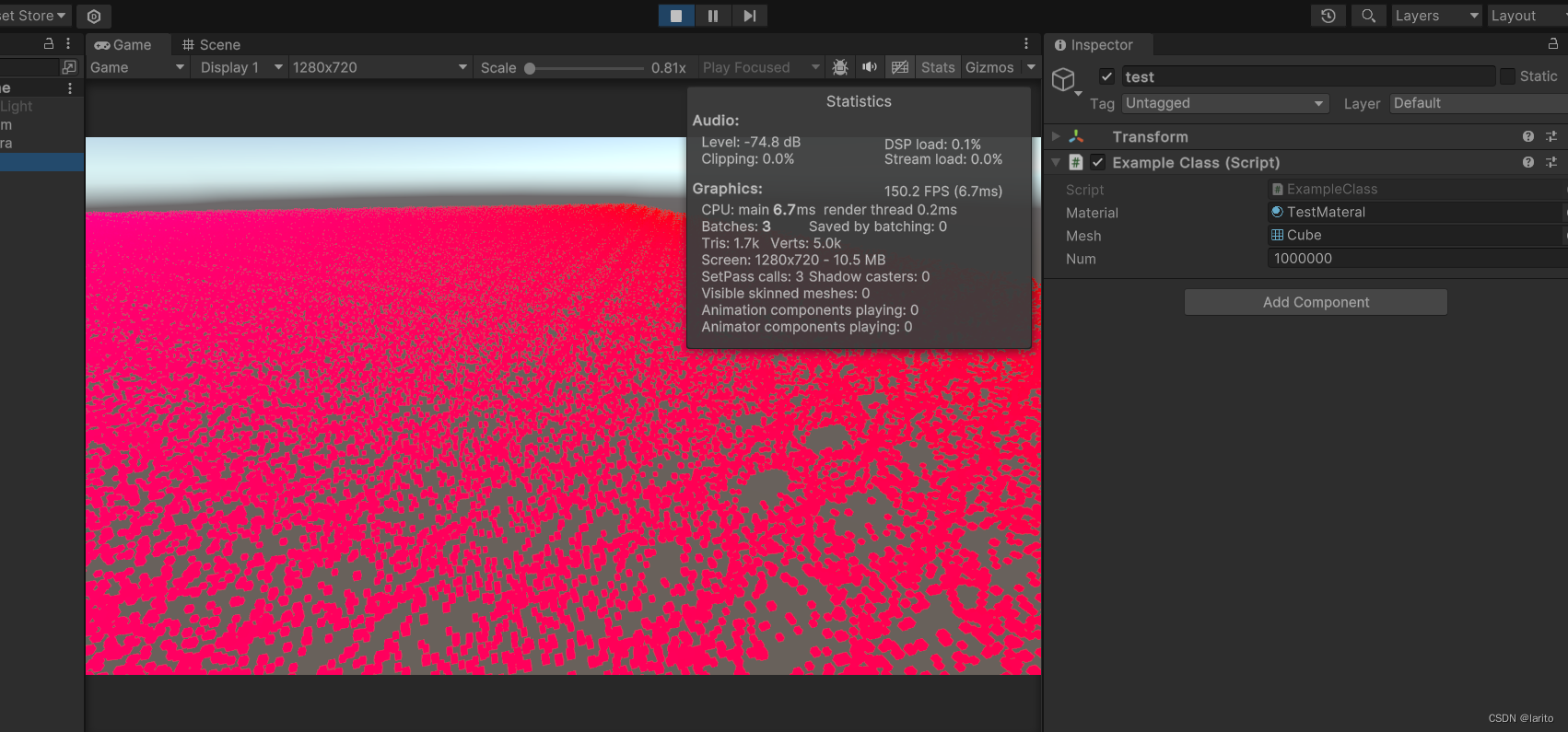
Unity技术学习:渲染大量物体的解决方案,外加RenderMesh、RenderMeshInstanced、RenderMeshIndirect的简单使用
叠甲:本人比较菜,如果哪里不对或者有认知不到的地方,欢迎锐评(不玻璃心)! 导师留了个任务,渲染大量的、移动的物体。 寻找解决方案: 当时找了几个解决方案: 静态批处…...

[数据概念|方案实操][最新]数据资产入表4月速递
“ 在各地数据资产变现“热辣滚烫”” 国家数据局全国数据工作会议前后,数据资源“入表”的尝试在各地持续热火朝天地展开,多地实现数据资产入表和利用数据资产进行融资实现“零的突破”。 我们今天就把4月前后的案例做一个小结,之前的案例大…...

C++中使用Multimap和Vector管理和展示数据
一: 在本文中,我们将探讨如何在C中使用vector和multimap容器来管理一个简单的员工数据系统。我们将创建一个员工类,随机生成员工数据,将员工分组,并展示各组员工的详细信息。此示例展示了C标准模板库(STL&…...

Java---类和方法的再学习
上一篇主要介绍了面向对象的思想以及内存实现,关于类与对象感觉写的不够好,因此才会有这一篇作为补充; 一:类与对象 (1)类 一些相同属性和行为的事物的统称,比较广泛、抽象,比如…...
)
C语言每日一练(12、水仙花数)
在编程的领域中,我们常常会遇到一些有趣而富有挑战性的问题。今天,让我们一起来探讨一个经典的编程题目——打印出所有的“水仙花数”。 所谓“水仙花数”,是指一个三位数,其各位数字的立方和等于该数本身。例如,153 …...

HTML5实现酷炫个人产品推广、工具推广、信息推广、个人主页、个人介绍、酷炫官网、门户网站模板源码
文章目录 1.设计来源1.1 主界面1.2 我的产品界面1.3 关于我们界面1.4 照片墙界面1.5 发展历程界面1.6 优秀人才界面1.7 热门产品界面1.8 联系我们界面 2.灵活调整模块3.效果和源码3.1 动态效果3.2 源代码 源码下载 作者:xcLeigh 文章地址:https://blog.c…...

系统如何做好安全加固?
一、Windows系统 Windows系统出厂时,微软为了兼容性,默认并未对系统安全做严格的限制,因此还需要做一些基本的安全加固,方可防止黑客入侵。 1、系统补丁更新 为什么要更新系统补丁?很多人感觉漏洞更新没必要&#x…...

对NI系统和PLC系统的应用比较
以下是对这两种系统的基本比较: 1. 设计和功能性 NI系统: 通常基于LabVIEW等软件平台,提供强大的数据采集、信号处理和图形界面开发能力。高度模块化和可扩展,支持各种传感器和信号类型。适合进行复杂的数据分析和高级控制算法的…...
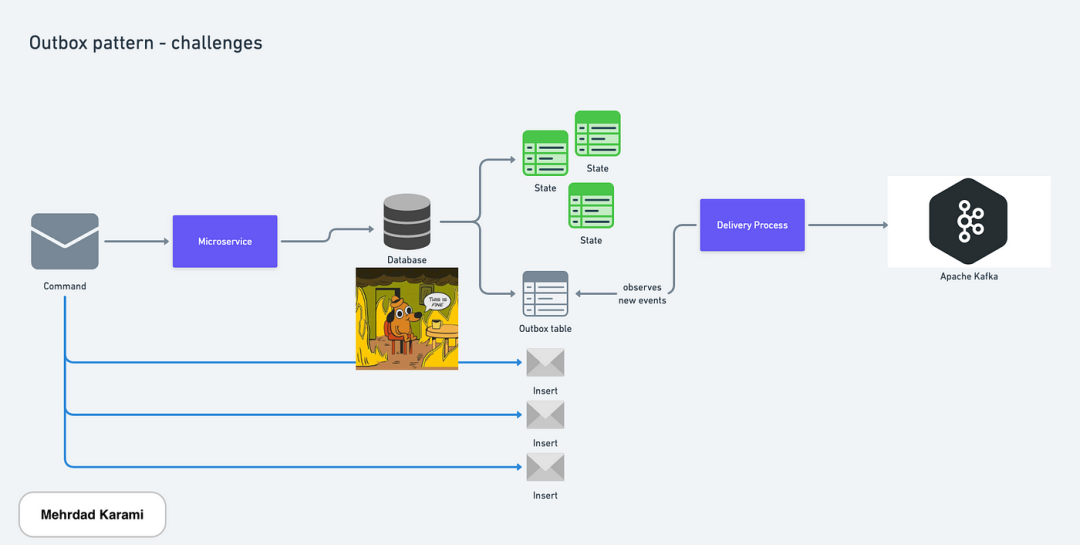
微服务架构中的挑战及应对方式:Outbox 模式
使用 Outbox 模式保持微服务数据一致性 在一个由许多小型服务组成的系统中保持数据一致性是困难的,因为它们分散在各处。以下是一些常见问题以及如何处理它们的方法:当服务发送消息时,同时更新数据库和发送消息是棘手的问题。 在微服务中发出…...

使用Docker安装MySQL5.7.36
拉取镜像并查看 docker pull mysql:5.7.36拉取成功后查看(非必须) docker images创建并设置宿主机 mysql 配置文件目录和数据文件目录 创建相关文件夹将容器中的mysql数据保存到本地,这样即使容器被删除,数据也不会丢失。 mkd…...
)
【PyTorch】6-可视化(网络结构可视化、CNN可视化、TensorBoard、wandb)
PyTorch:6-可视化 注:所有资料来源且归属于thorough-pytorch(https://datawhalechina.github.io/thorough-pytorch/),下文仅为学习记录 6.1:可视化网络结构 Keras中可以调用model.summary()的API进行模型参数可视化 torchinfo…...

C++容器——map和pair对组
pair(对组) 是一种模板类,允许将两个不同类型的值组合在一起。它由两个数据成员first和second组成,分别用来保存这两个值。 头文件 加头文件 #include<utility> 对于 C11 及以上标准,pair 类型可以在不包含头…...
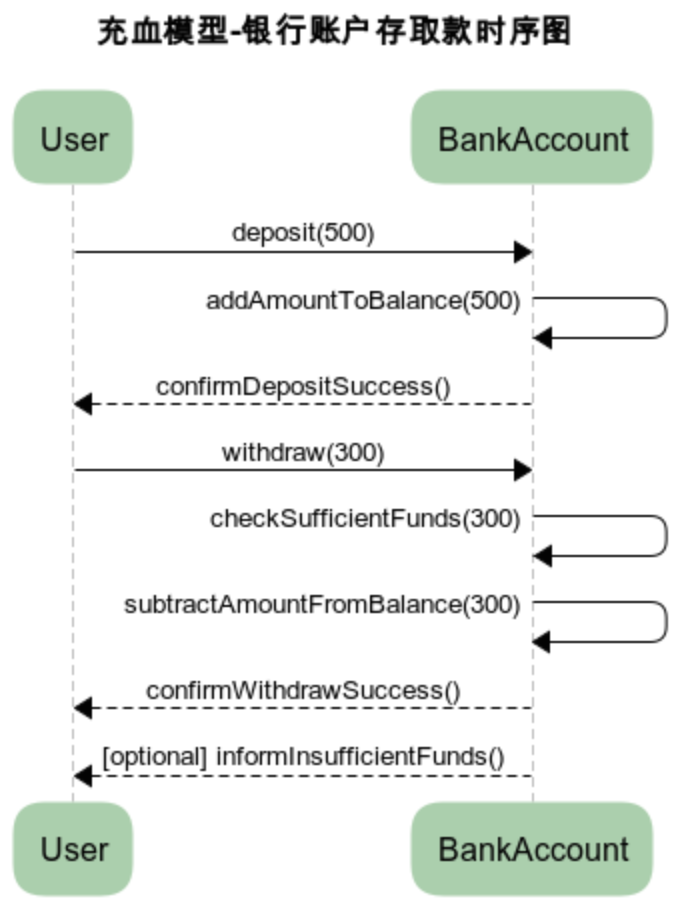
MVC和DDD的贫血和充血模型对比
文章目录 架构区别MVC三层架构DDD四层架构 贫血模型代码示例 充血模型代码示例 架构区别 MVC三层架构 MVC三层架构是软件工程中的一种设计模式,它将软件系统分为 模型(Model)、视图(View)和控制器(Contro…...

如何利用AI提高内容生产效率?
如何利用AI提高内容生产效率? 简介:探讨如何通过AI技术提升内容生产的效率和质量。 方向一:自动化内容生成 自动化内容生成是一种利用人工智能技术来自动创建文本、图像、音频等内容的方法。 以下是一些常见的自动化内容生成方式: 基于…...

C++ stack、queue以及deque
1、stack和queue常用接口 严格来说栈和队列的实现是容器适配器 1、常用接口: 栈:top、push、pop、size、emptystack - C Reference (cplusplus.com) 队列:top、push、pop、swap、size、emptyqueue - C Reference (cplusplus.com) 2、deque&a…...

【LeetCode刷题日记】112.递归中的「减法思维」:一题带你打通二叉树路径求和的任督二脉
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

告别卡顿!手把手教你配置UE5+Cesium子关卡,打造流畅的大型开放世界
告别卡顿!UE5Cesium子关卡实战:打造流畅的大型开放世界 当你在UE5中构建一个横跨多个城市的开放世界时,是否遇到过这样的场景:镜头拉到高空俯瞰时帧率骤降,或者角色在城市间快速移动时出现明显的加载卡顿?这…...

如何通过DriverStore Explorer解决Windows驱动管理的三大核心难题
如何通过DriverStore Explorer解决Windows驱动管理的三大核心难题 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 作为一名系统管理员或技术爱好者,你是否曾面临这样的困境&…...

【NotebookLM图书馆学研究实战指南】:20年图情专家亲授AI时代知识管理新范式
更多请点击: https://codechina.net 第一章:NotebookLM图书馆学研究的范式革命 传统图书馆学研究长期依赖人工文献综述、卡片目录索引与线性知识组织方式,而NotebookLM的引入正从根本上重构知识发现、关联与推理的底层逻辑。作为Google推出的…...

终极GitHub加速方案:3步让你的下载速度飙升10倍
终极GitHub加速方案:3步让你的下载速度飙升10倍 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 还在为GitHub的龟速下载…...

3个关键指标揭示:你的游戏手柄响应速度是否拖了后腿?
3个关键指标揭示:你的游戏手柄响应速度是否拖了后腿? 【免费下载链接】XInputTest Xbox 360 Controller (XInput) Polling Rate Checker 项目地址: https://gitcode.com/gh_mirrors/xin/XInputTest 在竞技游戏的激烈对决中,每一毫秒的…...

Zotero Format Metadata:让文献元数据格式化变得简单高效
Zotero Format Metadata:让文献元数据格式化变得简单高效 【免费下载链接】zotero-format-metadata Linter for Zotero. A plugin for Zotero to format item metadata. Shortcut to set title rich text; set journal abbreviations, university places, and item …...

SoC设计全流程解析:从架构到流片的核心步骤与挑战
1. 项目概述:从“黑盒子”到“城市蓝图”每次拿起手机,我们都在与一个极其复杂的微型“城市”互动。这个城市,就是SoC。对于很多刚入行的朋友,甚至是一些有经验的软件工程师来说,SoC常常像一个“黑盒子”——我们知道它…...

企业内如何通过Taotoken实现大模型API的统一管理与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何通过Taotoken实现大模型API的统一管理与审计 对于需要将大模型能力集成到内部系统的企业而言,直接让各个团队…...

蓝桥杯单片机备赛:AT24C02 EEPROM存储整型数据的完整流程与常见错误分析
蓝桥杯单片机备赛:AT24C02 EEPROM存储整型数据的完整流程与常见错误分析 在蓝桥杯单片机竞赛中,AT24C02 EEPROM模块是必考内容之一。许多选手已经掌握了基本字符型数据的读写操作,但当面对整型数据时,往往会遇到各种问题。本文将深…...