大模型的不足与解决方案
文章目录
- ⭐ 不具备记忆能力 上下文窗口受限
- ⭐ 实时信息更新慢 新旧知识难区分
- ⭐ 内部操作很灵活 外部系统难操作
- ⭐ 无法为专业问题 提供靠谱的答案
- ⭐ 解决方案的结果 各有不同的侧重
在前面三个章节呢,为大家从技术的角度介绍了大模型的历程与发展,也为大家介绍了目前主流的大模型的一些特点。在平时的使用中呢,我们也能够感受得到 大模型 非常的强大,但不可否认的是 大模型也存在着一些不足的部分,具体表现在以下几方面。
⭐ 不具备记忆能力 上下文窗口受限

首先我们需要知道的一件事情,大模型虽然非常的强大,但是它是不具备记忆能力的,也就是说实际上大模型是一个 0状态 的东西。在使用大模型的时候,尤其是在使用大模型的API进行多轮对话的场景下,在经过一些轮次之后,原本与大模型对话所赋予的记忆就会消失,因为大模型也记不住这么多东西。
在一个就是上下文窗口的限制,什么意思呢?就是说大模型对于 input 和 output 、输入与输出有一定数量限制的,之所以这样是为了保护自身的计算能力,相当于是一个带宽的概念。比如说 OpenAI 之前的上下文限制是32K,最新的上下文窗口已经扩张到了 128K ,大概相当于是一本书的容量了,从这个角度来说 上下文限制 的问题已经被解决了,但是其他类型的大模型就没这么幸运了,它们的上下文依然会受到限制。
在上下文窗口比较下的情况下,就会存在很多的限制,比如说不可以发那种一长段 Prompt(提示词) 过去,也不可以一直不停的不受限制的与大模型进行对话,因为这需要对对话窗口的 Token 进行计算消耗,避免没有办法进行 input 和 output ,也就是输入和输出,这是大模型的第一个缺陷。
⭐ 实时信息更新慢 新旧知识难区分

在前面的大模型发展历程中我们都知道,大模型其实是基于 预训练 所实现的,所谓的 预训练 就是利用大量的数据在神经网络上进行训练,最终形成 现在这样真实可用的大模型。大模型的知识库就是依赖于这些被用来训练的数据,OpenAI 之前的知识库是截止到2021年,最新的 GPT-4 的知识库是更新到2023年,即使如此依然会存在实时的信息无法感知的情况。
比如说 GPT-4 的知识库更新到了 2023年的10月份,那么类似 2023年11月份、12月份之后时间点的信息,它就是不知道的。所以很多人在去 “调戏” GPT 的时候就会发现这些知识库之外的信息,它是不知道的。还有一个问题就是,在大模型的底模数据比较小的时候,就会出现一些大模型胡说八道的现象。
⭐ 内部操作很灵活 外部系统难操作

现在很多大模型只是支持去进行对话、做聊天,但是没有办法去针对外部系统进行操作的。虽然说现在 ChatGPT 提供了插件机制,并且提供了插件的开发工具,但是在实际使用之后就会知道这个东西其实就是提供了一个相当于是 标准化 的工具而已,无法满足一些定制化的开发,想要更深度的融合个性化业务的场景还是比较难的。ChatGPT尚且如此,就更别提其他的大模型了。
所以说,在操作外部系统这一层面做的其实算是比较差的,或者说是 缺少有效的工具 去支持大模型操作外部的系统。比如说想要让大模型去操作智能家居系统,去操作现在的植入智能操控的汽车,这些场景都是缺少有效的外部连接器或者是框架去帮助大模型实现的。
⭐ 无法为专业问题 提供靠谱的答案
关于专业问题上的答案,相信很多小伙伴的感受是最深的。就是我们向 ChatGPT 提问一些比较宽泛的问题时,它都能够回答的很好,但是一旦问一些专业的问题,它可能就回答不上来了。因为这块儿专业性的问题可能预训练的时候并不涉及,虽然它的答案看起来像是一个人在回答,但是能够看出来那个答案是不对的。针对这样的问题,业界内的专家们提出了两种解决方案,但是这两种方案都不能够 完全的解决这种问题 ,只能说是对部分问题进行了覆盖。

第一种就是基于 “微调” 实现的解决方案,主要解决的事专业知识库的问题,同时还包括了专业知识库的更新问题。 “微调” 的底层其实还是大模型,专业数据通过 “微调” 的方式 “喂” 给大模型再做一次训练,这种训练是一次性的,也无法解决实时感知的问题,智能更新底层的数据库。而且这种方式的成本也非常的高,以 GPT 为例,相当于是将数据 “喂” 给 OpenAI 重新做了一次全量的训练。所以这种方式呢,比较适合自有大量数据的行业模型,也就是专业领域的公司积累了大量的数据,利用自有的这些数据希望以AI的方式指导后续的业务工作,这个时候就可以通过 “微调” 的方式 “喂” 给大模型在做一次调教。
目前业界比较火的一个概念就是 Maas ,也就是 Model as a Service (模型即服务)。它就是通过 微调 的技术在大模型基础之上灌入行业数据,从而实现行业模型。非常适合于拥有大量行业数据的企业去这样做,但是这样做的话也只能是解决 领域数据专业性 的问题、或者说是 知识库更新 的问题,而不是 外部操作系统、记忆能力、窗口扩张 等问题。

第二种解决方案是通过 类似于 “提示词工程” 这样的方式来解决,也就是 “Prompt Engineering” ,通过上下文提示词的设计,引导大模型输出精确的答案。这种方案的原理就是在大模型的基础之上,将专业的数据通过 Embedding (词嵌入) 和 Prompt(提示词) 的方式来实现精准的、专业的回答。同时,这种解决方案可以实现 实时信息的感知,操作外部系统,包括记忆增强、上下文窗口的扩张,最大的好处就是无需训练,也就是说不需要在大模型上进行再次训练的,成本是非常低的。
这种解决方案呢,比较适合数据样本比较少的场景。比如说我们想要从某一本书上得到一些有用的信息,但是呢又不想整本书通读一遍,这个时候就可以通过AI的机器人的方式直接从书里找到答案。这里就可以将这本书的数据作为 专业数据 ,通过 词嵌入 的方式嵌入到大模型,再通过 Prompt 的方式去引导,从而得到一个精确的答案。在这个过程中间,甚至可以将这些答案与打印机连接起来,这些都是可以通过 “Prompt Engineering” (提示词工程) 来实现的。
⭐ 解决方案的结果 各有不同的侧重

所以我们可以看到,上述的两种方式都可以解决大模型出现的一些问题,但是适应的场景不同,各自擅长的点也不一样。很多时候呢,都是将两者结合起来使用,可能效果会比较好一些。
针对第一种的 微调 的解决方案,ChatGPT 其实也提供了一系列的可以直接微调的方式, 目前已经将门槛降的很低了,可以直接将想要微调的数据直接上传上去就可以了。但是 ChatGPT 又是闭源的,所以如果是企业用户的话,有可能就会担心数据安全、数据所有权问题等等。
另一个问题就是 “Prompt Engineering (提示词工程)” 这种方案适合于 开源的大模型 ,比如说我们在本地使用 ChatGLM ,在做 “词嵌入” 这种提示词引导的时候,就可以在本地实现。但是因为底层的底模没有 ChatGPT 这么强大,可能会在语言的组织和智能度稍微低一些,这一方案的代表大模型就是 LangChain 。
总结概括的话,大模型的这些问题,有两套的解决方案,每个方案呢都有自己的优劣点和适应场景。具体使用那种方案,还是得看我们整个项目的情况。需要提一下的是,在后续的内容中,我们所使用的解决方案是以 “Prompt Engineering (提示词工程)” 为主的,也就是 LangChain 框架。
相关文章:
大模型的不足与解决方案
文章目录 ⭐ 不具备记忆能力 上下文窗口受限⭐ 实时信息更新慢 新旧知识难区分⭐ 内部操作很灵活 外部系统难操作⭐ 无法为专业问题 提供靠谱的答案⭐ 解决方案的结果 各有不同的侧重 在前面三个章节呢,为大家从技术的角度介绍了大模型的历程与发展,也为…...

Java中使用FlatBuffers实现序列化
Java 中的 FlatBuffers有助于高速数据序列化/反序列化,消除解析开销。它由 Google 开发,为跨平台数据交换提供无模式、内存高效的解决方案。 Java 开发人员可以利用其直接内存访问来实现最佳性能和最小内存占用,从而提高应用程序速度、可扩展…...
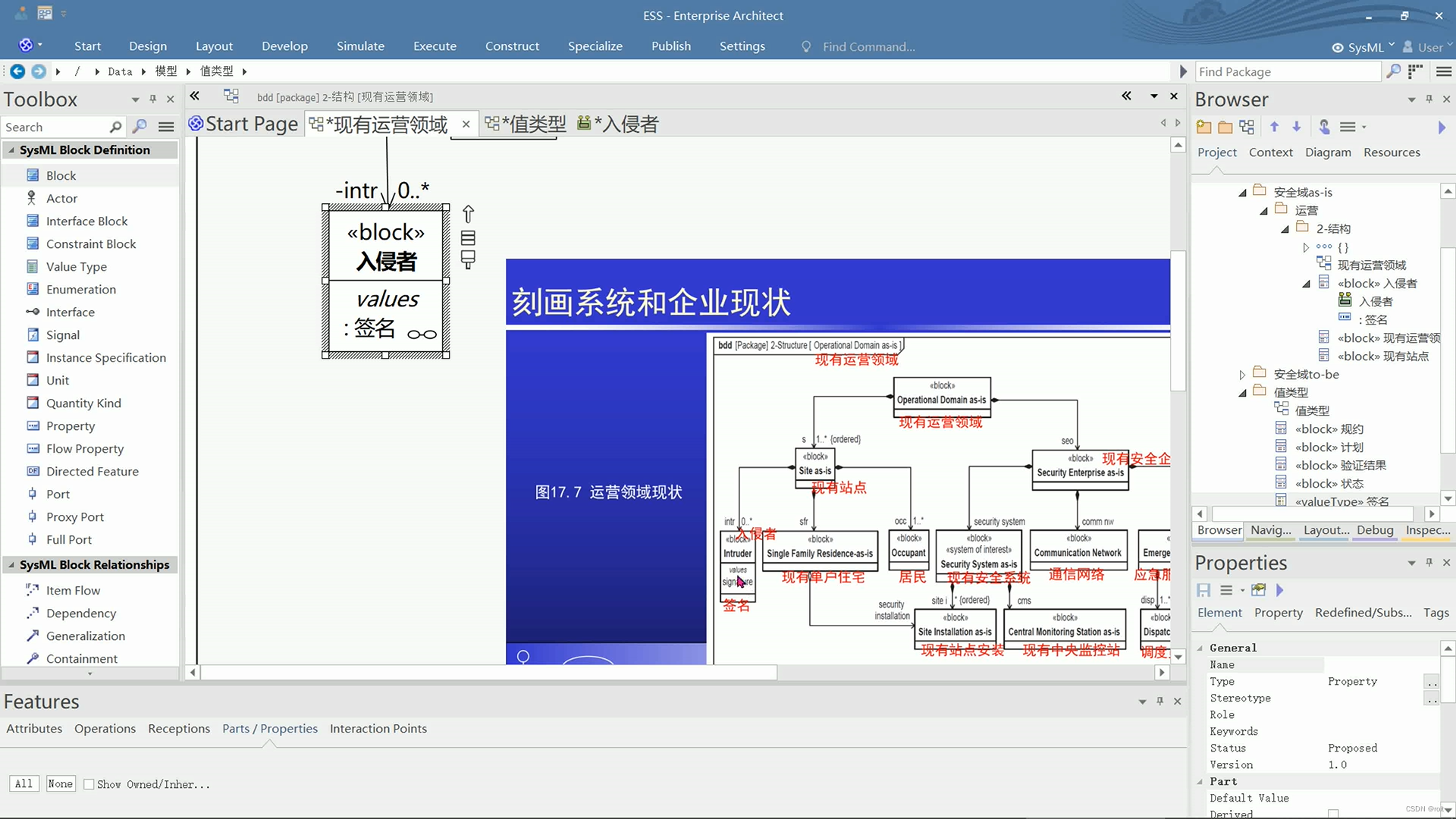
[图解]SysML和EA建模住宅安全系统-02
1 00:00:00,900 --> 00:00:02,690 这个就是一个块定义图了 2 00:00:03,790 --> 00:00:04,780 简称BDD 3 00:00:05,610 --> 00:00:08,070 实际上就是UML里面的类图 4 00:00:08,080 --> 00:00:09,950 和组件图的一个结合体 5 00:00:13,150 --> 00:00:14,690 我…...

2024年北京服贸会媒体邀约资源有哪些?
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 2024年北京服贸会(中国国际服务贸易交易会,简称CIFTIS)作为中国重要的国际性服务贸易盛会,会吸引众多媒体的关注和参与。媒体邀约资源通常…...

大语言模型LLM入门篇
大模型席卷全球,彷佛得模型者得天下。对于IT行业来说,以后可能没有各种软件了,只有各种各样的智体(Agent)调用各种各样的API。在这种大势下,笔者也阅读了很多大模型相关的资料,和很多新手一样&a…...

Alibaba Cloud Linux 安装mysql及注意事项
1.安装mysql #1.运行以下命令,更新YUM源。 sudo rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-7.noarch.rpm#2.(可选)当操作系统为Alibaba Cloud Linux 3时,执行如下命令,安装MySQL所需的库文件…...
)
设计模式——工厂模式(Factory)
工厂模式(Factory Pattern)是一种常用的设计模式,它提供了一种封装创建对象过程的方法。通过工厂方法或工厂类,你可以将对象的创建与使用分离,使得代码更加灵活和可维护。工厂模式主要分为三种类型:简单工厂…...

NVIDIA Omniverse Cloud API支持数字孪生开发,可解决复杂AI问题 | 最新快讯
在全球范围内,价值超过 50 万亿美元的重工业市场,正在竞相实现数字化。 基于此,为帮助数字孪生技术更好地赋能千行百业,AI 企业 NVIDIA 在架构底层算力的同时,也搭建了 NVIDIA AI Enterprise 和 Omniverse 两大平台。 …...
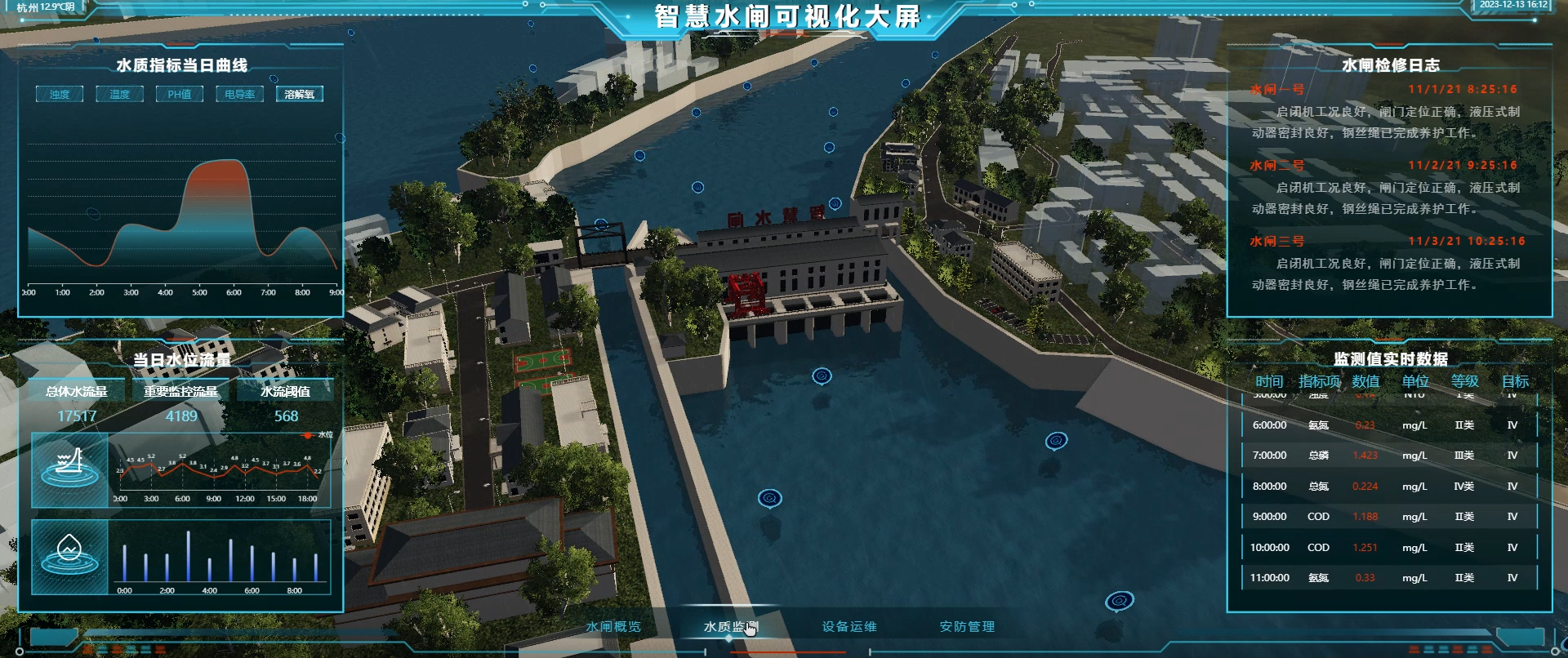
智慧电力,山海鲸引领
随着科技的不断进步和电力行业的快速发展,智能化管理已成为电力行业的重要趋势。在这一背景下,山海鲸智慧电力管理系统凭借其卓越的性能和创新的功能,为电力行业带来了革命性的改变。 山海鲸智慧电力管理系统是一套集数据采集、分析、展示于…...

【文章转载】ChatGPT 提示词十级技巧: 从新手到专家
学习了微博网友宝玉xp老师《ChatGPT 提示词十级技巧: 从新手到专家》 个人学习要点: 1、关于提示中避免使用否定句,播主说:“没有人能准确解释为什么,但大语言模型在你告诉它去做某事时,表现似乎比你让它不做某事时更…...
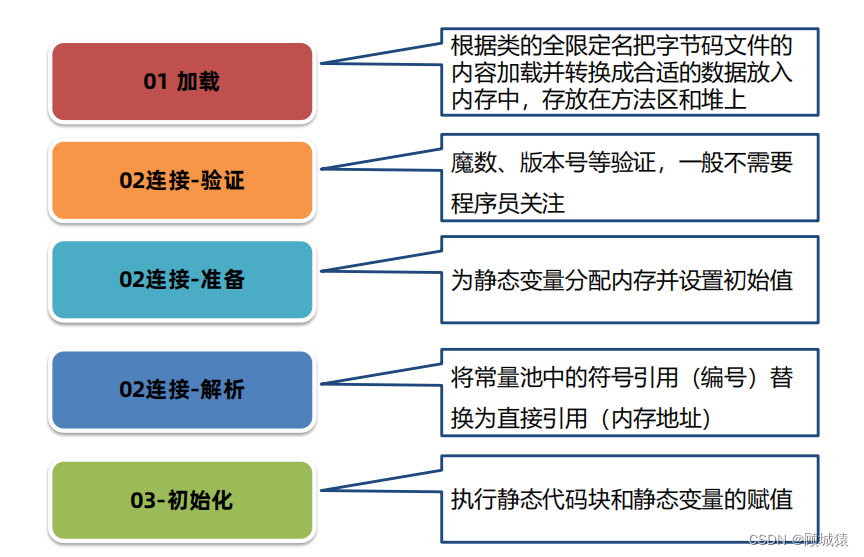
类的生命周期
目录 一、概述 二、加载阶段 三、连接阶段 连接阶段之验证 连接阶段之准备 连接阶段之解析 四、初始化阶段 五、总结 一、概述 类的生命周期描述了一个类加载、使用、卸载的整个过程。 也是其他知识的基础: 类的生命周期: 二、加载阶段 加载(Loading…...

AI赋能分层模式,解构未来,智领风潮
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》 💪🏻 制定明确可量化的目标,坚持默默的做事。 🚀 转载自热榜文章🔥:探索设计模式的魅力:AI赋能分…...
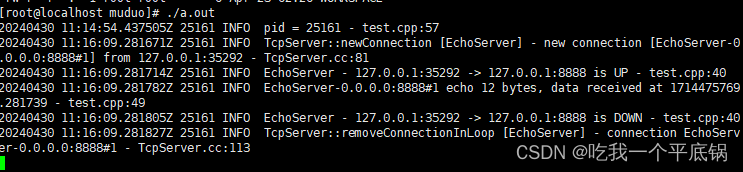
Linux平台下muduo网络库源码编译安装与测试,包含boost库的安装与测试!!!!
最近在学习muduo网络库,先来记录一下如何在Linux平台下编译安装以及测试muduo网络库源码。 获取源码 muduo库源码github仓库地址: https://github.com/chenshuo/muduo 在linux系统下,输入 git clone https://github.com/chenshuo/muduo.git…...

MATLAB 函数
MATLAB 函数 函数是一起执行任务的一组语句。在MATLAB中,函数是在单独的文件中定义的。文件名和函数名应该相同。 函数在其自己的工作空间(也称为本地工作空间)中对变量进行操作,与在MATLAB命令提示符下访问的工作空间࿰…...
spring高级篇(七)
1、异常处理 在DispatcherServlet中,doDispatch(HttpServletRequest request, HttpServletResponse response) 方法用于进行任务处理: 在捕获到异常后没有立刻进行处理,而是先用一个局部变量dispatchException进行记录,然后统一由…...

根据token获取了username后,能否在其他地方使用这个获取的username,或者在其他地方如何获取username?
当然可以在其他地方使用获取到的用户名。一旦你从token中获取到用户名,你可以将其存储在能够在整个应用程序中访问的地方。 在你的代码中,你从token中获取用户名的地方是这里: String username getUsernameFromToken(token);在这行之后&am…...

值模板参数Value Template Parameters
模板通常使用类型作为参数,但它们也可以使用值。使用类型和可选名称声明一个值模板参数,方式与声明函数参数类似。值模板参数仅限于可以指定编译时常量的类型是bool、char、int等,但不允许使用浮点类型、字符串字面值和类。 #include <io…...

Splashtop 荣获 TrustRadius 颁发的“2024年度最受欢迎奖”
2024年5月8日 加利福尼亚州库比蒂诺 Splashtop 在全球远程访问和支持解决方案领域处于领先地位,该公司正式宣布将连续第三年荣获远程桌面和远程支持类别的“TrustRadius 最受欢迎奖”。Splashtop 的 trScore 评分高达8.6分(满分10分)&#x…...
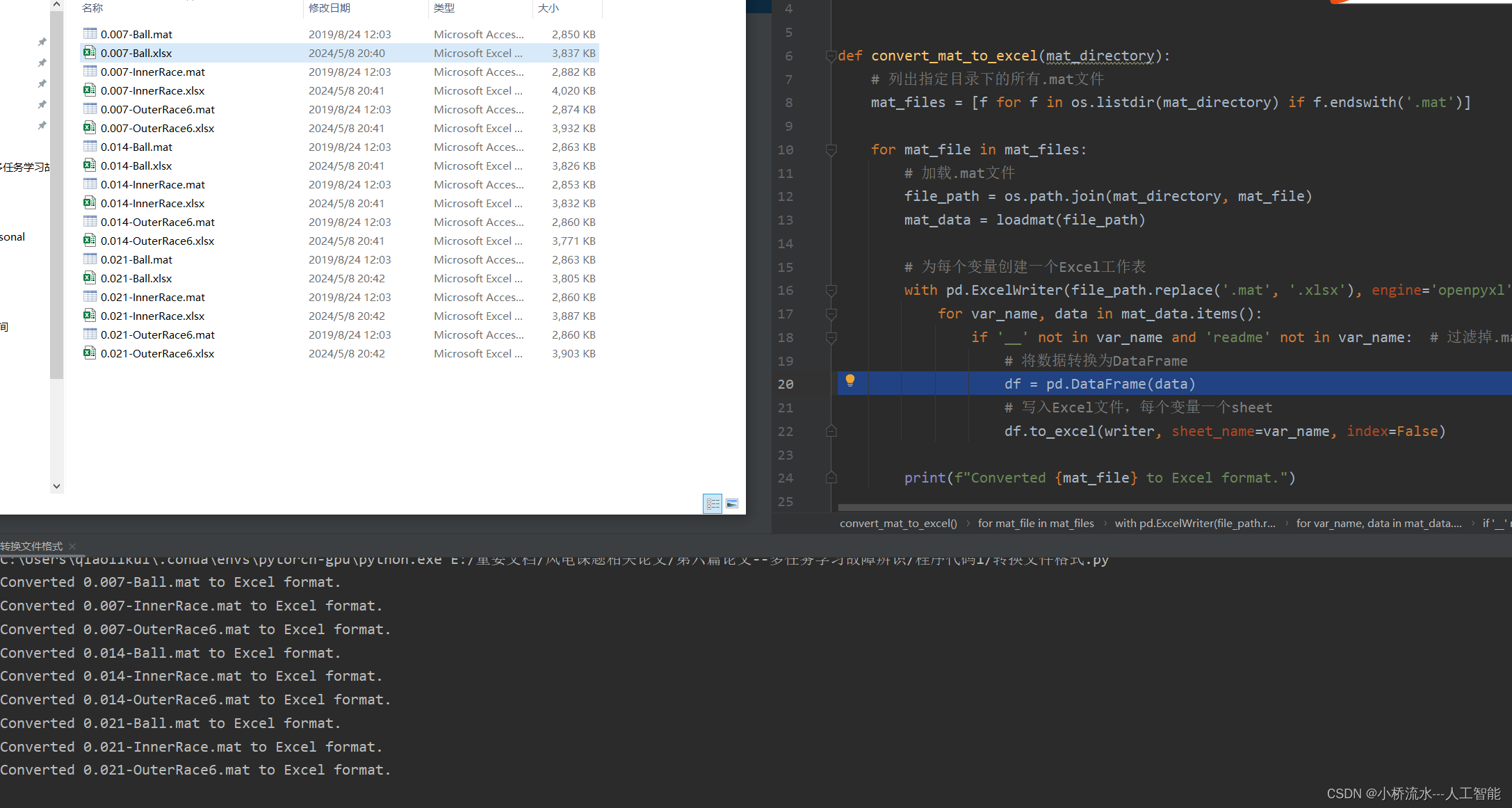
使用python将`.mat`文件转换成`.xlsx`格式的Excel文件!!
要将.mat文件转换成.xlsx格式的Excel文件 第一步:导入必要的库第二步:定义函数来转换.mat文件第三步:调用函数注意事项 要将.mat文件转换成.xlsx格式的Excel文件,并保持文件名一致,你可以使用scipy.io.loadmat来读取.m…...

python基础 面向练习学习python1
python基础 面向练习学习python1 1. 电话查询问题描述1. 问题分析1. 输入输出分析2. 需求分析:将题目的数据存储并查询2. 所需知识: python 数据存储的类型3. 确定数据存储类型4. 如何书写代码拓展 从键盘中添加或删除联系人5. 回到数据查询 代码拓展 功…...

【锂离子电池组的被动式电池均衡】电池组由两个并联的串联电池组成,每个并联串联都包含四个串联电池,目标是通过在电阻器上放电高SOC电池,直到所有电池的SOC相等附Simulink仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &…...
)
【新手专属】OpenClaw 一键安装包:Windows 完整部署流程(含安装包)
OpenClaw 一键安装包|一键部署,告别复杂环境配置 适配系统:Windows 10/11 64 位当前版本:v2.7.5(虾壳云版)核心优势:全程可视化操作,无需命令行、无需手动配置 Python/Node.js&…...

[实测可用 v2.7.5] 桌面端 Open Claw 搭建流程全程图文教程
前言 2026 年开源圈热门的「数字员工」OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 零代码操作 自动干活的核心优势广受关注!很多人误以为它是普通聊天 AI,实则是能真正操控电脑的自动化神…...

TP-LINK AX300 网卡驱动
TP-LINK AX300无线网卡的驱动一直不更新,只好自己动手 适配:TL-XDN6000H 免驱版 操作系统:Ubuntu 24.04.4 LTS 内核版本:6.17.0-29-generic #29~24.04.1-Ubuntu https://download.csdn.net/download/zzzhy/92882718...

Lenovo Legion Toolkit 维护版继续升级
Lenovo Legion Toolkit 维护版在继续更新。 项目地址:https://github.com/SSC-STUDIO/LenovoLegionToolkit 下载地址:https://github.com/SSC-STUDIO/LenovoLegionToolkit/releases/latest 这个版本面向 Windows 上的 Legion / IdeaPad Gaming / LOQ …...

保姆级教程:用Mermaid手绘CPU流水线时空图,理解数据冒险与阻塞
可视化解析CPU流水线:用代码绘制时空图理解数据冒险 在计算机体系结构的学习中,CPU流水线技术是提升处理器性能的核心机制之一。但对于初学者而言,理解流水线中的数据冒险(Data Hazard)及其导致的阻塞现象往往充满挑战…...

GJB 128B-2021标准变更深度解析:VDMOS产品试验方法的影响与应对
1. GJB 128B-2021标准变更的核心要点 对于从事VDMOS产品研发和质量控制的工程师来说,2022年3月正式实施的GJB 128B-2021标准带来了不少值得关注的调整。相比旧版标准,这次修订在试验条件、热平衡判定、静电防护等多个关键环节都做出了具体规定。我仔细研…...

OBS遮罩插件深度指南:15种特效解决直播画面优化的5大痛点
OBS遮罩插件深度指南:15种特效解决直播画面优化的5大痛点 【免费下载链接】obs-advanced-masks Advanced Masking Plugin for OBS 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-masks OBS高级遮罩插件(OBS Advanced Masksÿ…...

Synopsys ICC 2016环境变量配置详解:从.bashrc编辑到license启动的保姆级步骤
Synopsys ICC 2016环境变量配置全流程实战指南 当你第一次打开Synopsys ICC 2016却遭遇"Command not found"时,90%的问题都源于环境变量配置不当。作为芯片设计领域的工业级工具链,正确的环境配置不仅是运行的先决条件,更是后续所有…...

【亲测免费】 ST官方开源电机库FOC5.0:电机控制的利器
ST官方开源电机库FOC5.0:电机控制的利器 【下载地址】ST官方开源电机库FOC5.0下载仓库 ST官方开源电机库FOC5.0 下载仓库本仓库提供ST官方开源的电机库FOC5.0的资源文件下载 项目地址: https://gitcode.com/open-source-toolkit/a21b5 项目介绍 在电机控制领…...