Anaconda安装和深度学习环境的安装(TensorFlow、Pytorch)
换了新电脑,重新装一下anaconda这些编程环境。好久没装过了,自己也需要查查资料,然后记录一下,分享给别人。
目标,三个环境:1.anaconda基础环境(包含xgboost和lightgbm),2.TensorFlow环境,3.Pytorch环境(能用GPU加速的那种。)
Anaconda安装
这个装了太多次了,很简单,选一个自己喜欢的版本下载就行。一般没什么特殊要求就直接开官网下载就行:Distribution | Anaconda
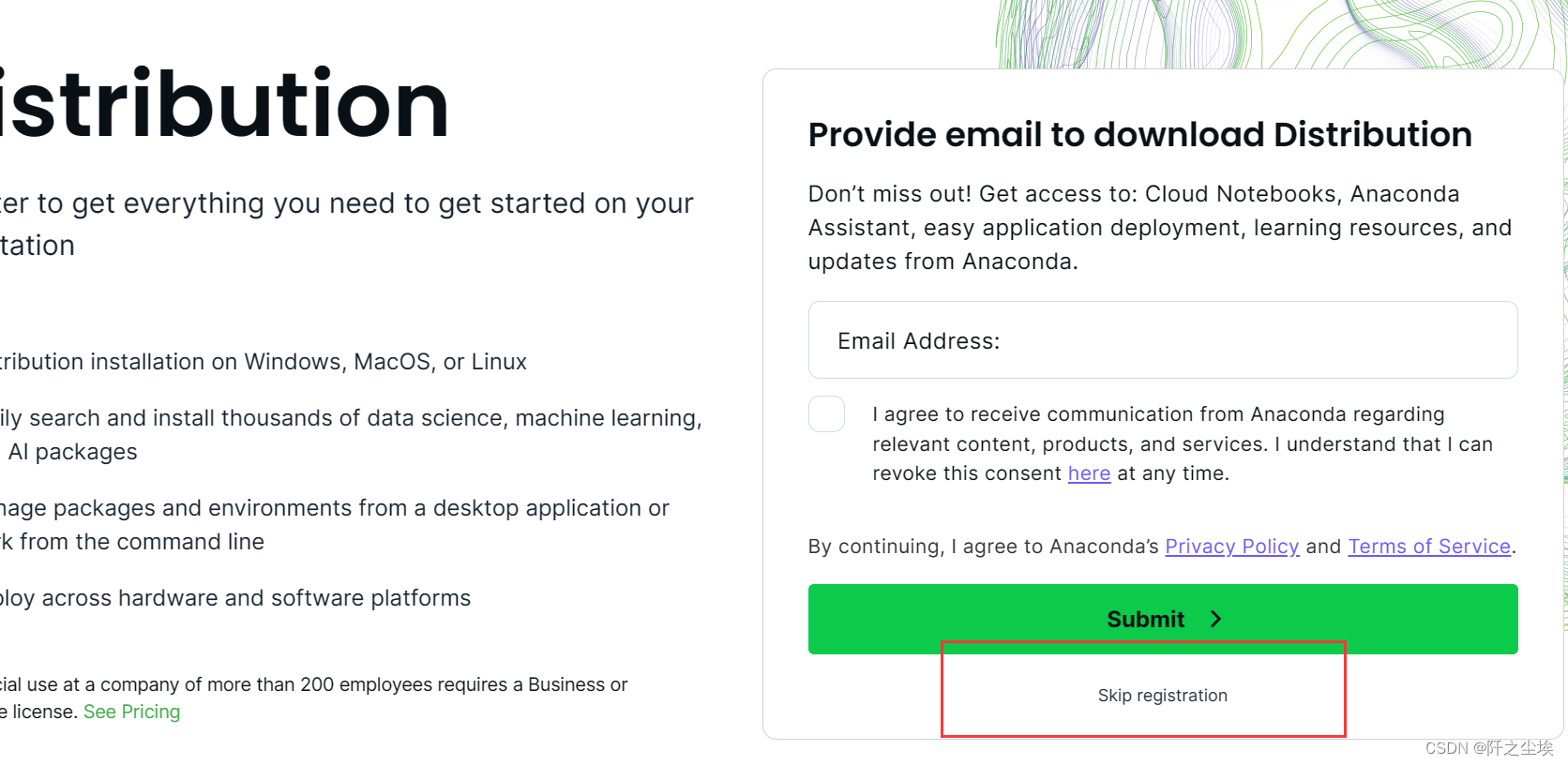
之前是打开直接点下载,现在还需要你填邮件,当然也可以点击跳过。然后找自己对应的电脑系统安装就行。

我看了一下,这个Windows版本是py3.11,我觉得太高了,就去以往的列表找一下之前的版本的安装包。Index of / (anaconda.com)

我看这个2023年的7月感觉不错,我就下载这个版本安装了。
下载好的exe文件直接双击运行:

点击下一步,我同意,然后这里可以选自己用,也可以选所有人用:

选择安装路径

这个选前2个就行:

第三个是清除安装包,我觉得没必要。
然后等待安装完成:

一直点击继续,到最后这两个去掉勾选就行了。

点击完成!基础的环境就安装好了。
环境变量
查看一下anaconda路径有没有在环境变量里面,其实不在环境变量里面也不影响运行,但是在的话更好,这与会避免后面可能的报错。
在查找里面搜索如下的 编辑系统环境变量,

点击环境变量

在用户变量里面找到Path这一列,双击

我里面没得环境变量,按道理来说安装的时候会让你勾选的。我这个安装包没看见,所以我自己手动把anaconda,还有里面的带bin 和scripts的这些路径都添加到环境变量了。同学可以模仿这个路径复制进去就行。

设置好之后点确定确定。
然后win+r,输入cmd,打开

输入下面红色框框的东西,出现了信息就说明安装好了,环境变量也成功了。

安装xgboost和lightgbm
这两个包时做表格数据的机器学习效果最好的模型。若是不需要的同学,只做深度学习的话就可以跳过。
在菜单键的所有应用中,打开anaconda的命令提示符,
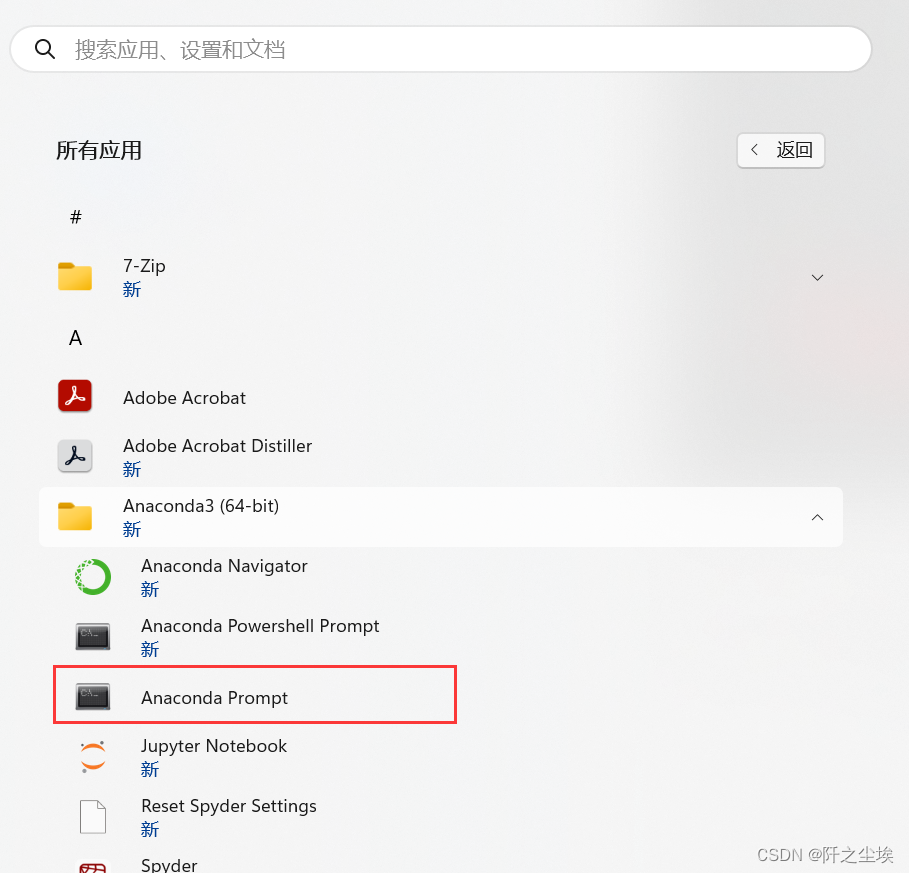
输入:
pip install xgboost
等待安装好就行。
若出现一屏幕的红色字体报错的话:
不要慌,你看见time out就表示是超时了,我们只需要再输入一遍回车等待就行。还超时的话就不停地输入这个安装命令和回车。。装好为止。
lightgbm也是一样的
pip install lightgbm
等待安装好就行。
测试
装好了,当然要看看能不能正常运行了。我们首先打开jupyter notebook(现在实习的公司用的是jupyter lab,都可以,我比较喜欢notebook)
还是打开conda的命令提示符:

切换到D盘(因为我代码放在D盘的),然后输入jupyter notebook

等待一下,就能看到下面的网址了

按道理来说,一个会自动跳转到默认的浏览器打开他们的,但是我新电脑没有跳转。。算了,无伤大雅,我手动复制到浏览器打开,然后沿着代码文件的路径进去打开要运行的代码文件:

直接重启运行全部代码

OK完美运行,速度很快(毕竟是新电脑)

测试完成!基础环境就已经装好了,下面来装TensorFlow。
TensorFlow安装
选择版本
深度学习首先得问题就是用CPU跑,还是GPU跑。。我当然想用GPU跑,不然买新电脑是做啥、、GPU跑得多块,一下就训练完了。然后库的版本,我其实也想装个比较新的版本,但是TensorFlow的环境这几年真的不太行了,毕竟谷歌自己都不怎么用了,现在都去弄pytorch了。
然后我自己去官网看了看:
Build from source on Windows | TensorFlow (google.cn)
发现他们从2.10版本之后的版本,win系统都不支持cuda了,见鬼,看来我想装2.11版本以上的TensorFlow 这英伟达显卡起不来作用了,那就老老实实装CPU版本吧。

看看CPU版本的对照型号:

我还是感觉太新的版本不好,咋们就来个python3.11,TensorFlow2.15的吧。
虚拟环境安装
为什么要创建虚拟环境呢?就是防止版本冲突,深度学习依赖的库太多,要是你在基础环境里面哪天不小心升级了一个包,然后整个深度学习框架不能用了就会很尴尬。。
所以我们先要创建一个虚拟环境,然后在里面安装TensorFlow。

还是打开命令提示符,输入下面的代码
conda create --name tensorflow_env python=3.11 anaconda这一行的功能是创建一个名称为:“tensorflow_env”的虚拟环境,安装py3.11的内核,我后面带了一个anaconda是因为我喜欢在这个TensorFlow环境里面把所有的anaconda组件都带上,免得如果只装py的话,后面还需要安装一堆常用的包(pandas,numpy,seaborn)等。。。
然后会跳出来一堆包的名称,输入y,同意安装

安装好了上面会提示你怎么激活环境,怎么退出环境:

输入“conda activate tensorflow_env”激活虚拟环境后,还可以在里面“conda --version”,查看版本信息,‘conda info’,还可以看看里面有哪些库:“pip list”

然后就是安装TensorFlow了。很简单其实,就是pip就行了。我还作死看了一下他默认给我装的3.11是3.11几,一看好家伙,是3.11.9,这无线接近3.12的版本的py能上TensorFlow2.15吗,我只能先试试了。
输入:
pip install tensorflow==2.15.0

然后等待安装

仔细一看他装的包,keras就在里面,不用额外装了。
感觉可以用了,我去跑个代码试试:

可以没问题是能运行的,但是好像keras库里面发出来警告,keras里面的TensorFlow的api没有更新,虽然能用。。但是好像也不长久了。。没事,反正后面keras也可以用pytorch的框架了,想这样过渡凑合着用吧。
(ps,不想这样被警告的同学,可以换TensorFlow2.14版本试一下,说不定就还好。)
TensorFlow安装完成!虽然用不了GPU加速,但是也还不错了,也是没办法的事情官网都不支持cuda了。
下面去安装pytorch 的环境。pytorch就可以用gpu了。
Pytorch安装
版本选择
pytorch的安装就有点讲究了,除了前面说的虚拟环境外,torch包的版本,py 的版本,还有cuda 的版本要都对应上。
(不过现在的pytorch安装是不需要装什么cuda驱动的,只要版本是对的,就一行命令就安装好了)
首先在英伟达的控制面板里面去找自己显卡的的CUDA Toolkit的版本

没这个就在搜索里面搜

可以看到我的CUDA Toolkit是12.2.146的版本,也就是说CUDA 12.2以下的版本应该都是支持的。
怎么查看cuda和pytorch版本的关系呢?,可以查看官网的安装命令:
Previous PyTorch Versions | PyTorch
上面会有每个torch版本的对应的cuda的版本命令:

例如这里的2.2.2就支持cuda11.8和12.2的版本。
那我们12.2的cuda就都可以选了,无所谓,那就来最新版本的pytorch2.3吧!

我就准备用这个命令安装了。
cuda和pytorch版本对应了后,去找python 的版本。
然后去官网查看py和pytorch的版本对应关系:
GitHub - pytorch/vision: Datasets, Transforms and Models specific to Computer Vision
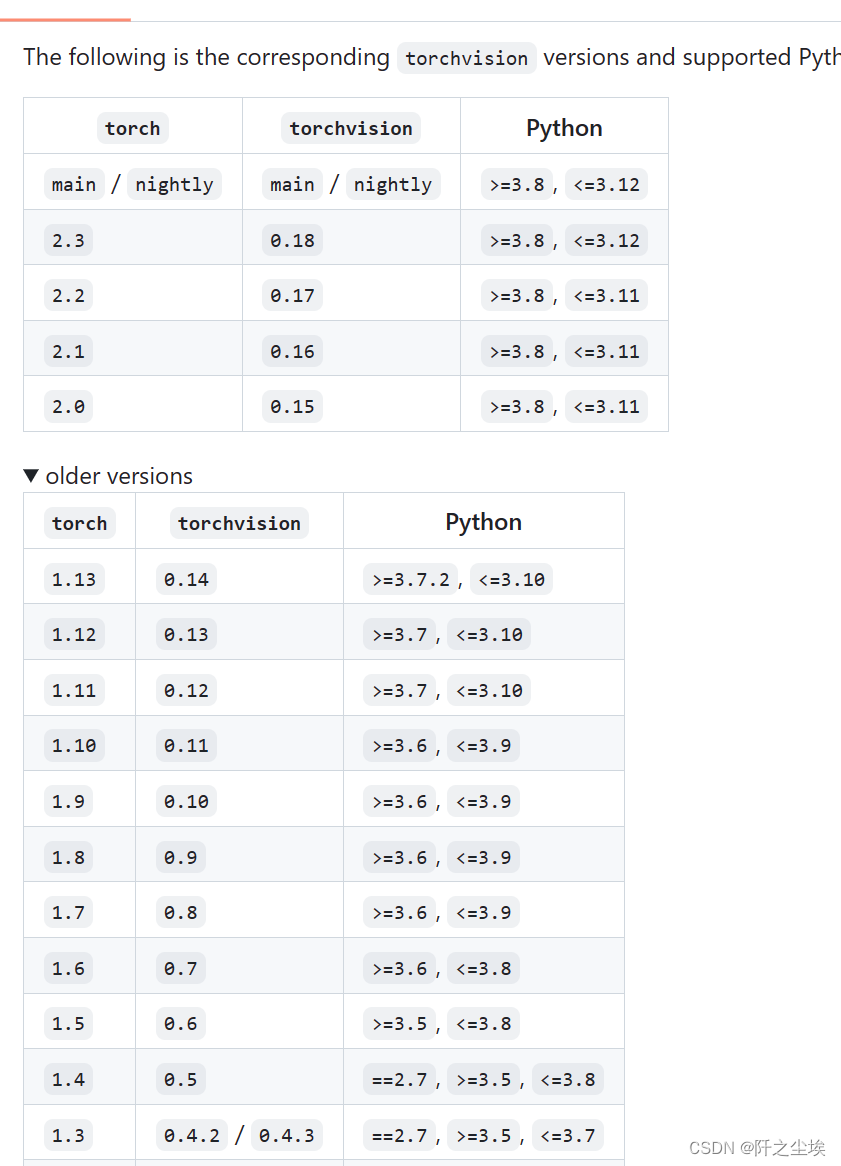
其实基本上3.8-3.11这个版本的python都是支持2.0以上版本的 torch 的。
那我们还是弄一个3.11版本的py吧。
开始安装!
虚拟环境安装
所以我们先要创建一个虚拟环境,然后在里面安装pytorch。
还是打开命令提示符,输入下面的代码
conda create --name pytorch_env python=3.11这一行的功能是创建一个名称为:“pytorch_env”的虚拟环境,安装py3.11的内核,这次后面没有带anaconda,所以这个环境后面还需要安装一堆常用的数据科学的包(pandas,numpy,seaborn)等。。。
然后还是会跳出来一堆包的名称,但是明显少一些,都是很基础的包。输入y,同意安装

安装好了上面会提示你怎么激活环境,怎么退出环境:

同样我们激活这个虚拟环境
conda activate pytorch_env然后我从官网上掏出了最新的安装命令:Start Locally | PyTorch

pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121我是cuda是最新的12.2才敢这样做的,其他同学的版本不一样的可不要学我,要去查找对应cuda 的torch版本的安装命令。

等待安装,包还挺大。

(等待安装的时候我就在想,这个torch环境在anaconda里面,所以我外面要装stable diffusion的时候还要装一下torch环境,不过这样也好,隔开的,一个科研跑数据,一个画画,挺好的。)
安装过程可能会提示你什么什么包没有,装一下就好了。然后还可以反复运行上面pytorch 的安装代码,没事,就反复运行尝试就行。
还可以参考李沐老师的这本书的教程,b站也有网课。
安装 — 动手学深度学习 2.0.0 documentation (d2l.ai)
pytorch 的生态和环境还是很丰富,啥问题都可以上网找得到的。
安装完了, 我在这个虚拟环境下输入python,进入py 的环境,然后输入下面的py代码测试是不是能用到cuda显卡:
import torch
torch.cuda.is_available()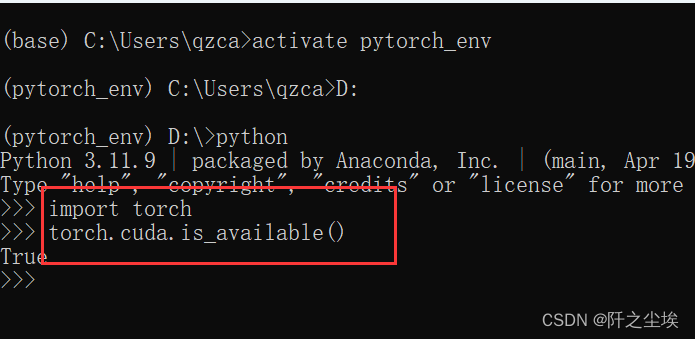
好耶,是可以的。看来现在的pytorch安装是不需要装什么cuda驱动的。
安装完了,我去跑个代码试试,找了个vgg,还有点大的神经网络。
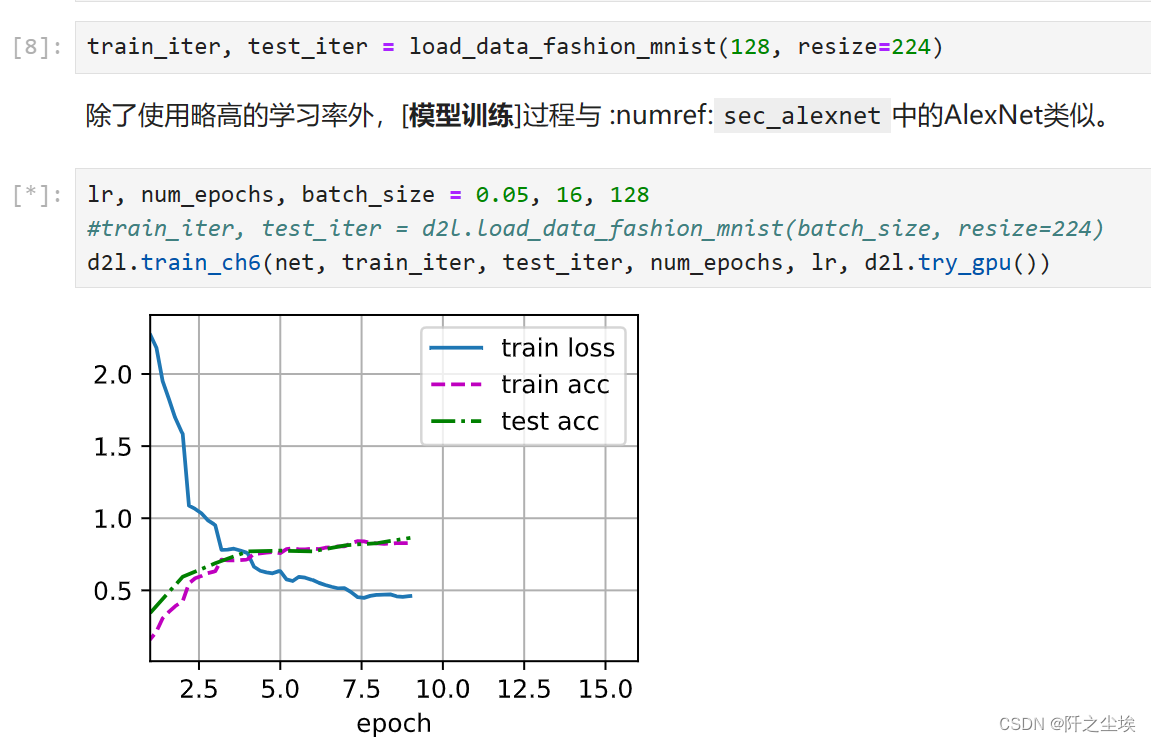
完全能运行,一点问题都没有。我显卡被狂用。。温度上升。。
大功告成!机器学习和深度学习的环境都装备好了! 后面就轻松愉快的写代码了
(创作不易,各位看官觉得还不错能帮到你们就点个赞和收藏吧)
相关文章:
Anaconda安装和深度学习环境的安装(TensorFlow、Pytorch)
换了新电脑,重新装一下anaconda这些编程环境。好久没装过了,自己也需要查查资料,然后记录一下,分享给别人。 目标,三个环境:1.anaconda基础环境(包含xgboost和lightgbm),…...

元素设置 flex:1,但是会被内部长单词宽度超出拉伸
初始布局如上图,left中是代码编辑器,实际上是个文本域,当输入长文本过长时,left宽度会被拉伸。 右侧容器被挤压。 解决方案:width:0; .left{flex:1; width:0} 当输入长文本过长时,…...
win11 安装oracle11g详细流程及问题总结
1.安装包下载地址 本案例操作系统, Oracle 11g下载-Oracle 11g 64位/32位下载官方版(附详细的安装图解教程) - 多多软件站多多为大家免费提供Oracle 11g下载,包含64位/32位官方版本,并附详细的Oracle 11g安装图解教程,同时希望能…...

自我模拟面试
在面试中,你如何面对面试官呢? 我认为,对于面试官提出的问题,如果你不会,那就是不会。你的思考过程,实际上就是将你平时所学的,所了解的,在脑海中进行一次复习,就像当别…...

头歌java面向对象基础
第一关类的定义 package step1;// ---------------------Begin------------------------ public class Student{String name"李四";int age18;public void speak(){System.out.println("我爱学习");} }// ---------------------End----------------------…...
PMP课程知识点很多,无法入手,该如何学习?
回顾整个学习过程,我花费了不少时间,但也学到了系统的项目管理知识,考试结果也让我感到满意。在学习过程中,我认为以下几点非常重要: 1、需要对课本进行整体阅读,以便对内容有一个整体印象; 2…...
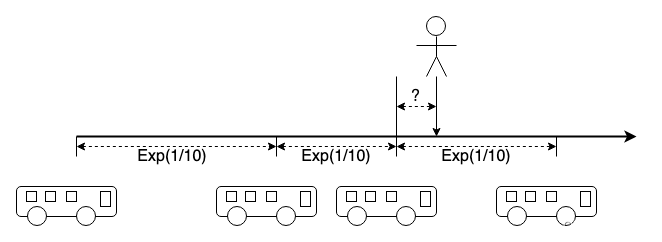
隔离流量优化网络传输
不要将长流和短突发流(或者大象流和老鼠流)混部在一起,我建议用切片或虚通道将它们在全链路范围彻底隔离,而不仅仅在交换机上配合着大肆宣讲的高端包分类算法配置一些排队调度。 也不必扯泊松到达,帕累托分布,这些概念在论文建模…...

【前端热门框架【vue框架】】——事件处理与表单输入绑定以及学习技巧,让学习如此简单
👨💻个人主页:程序员-曼亿点 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 曼亿点 原创 👨💻 收录于专栏:…...

芒果YOLOv8改进164:检测头篇:ImplicitHead 隐性知识检测头| 即插即用,独家新颖更新,精度高效涨点
💡本篇内容:芒果YOLOv8改进164:检测头篇:ImplicitHead 独家原创检测头 | 即插即用,独家新颖更新,精度高效涨点 芒果专栏提出:原创隐性知识学习检测头 ImplicitHead 结构,改进源码教程 | 详情如下🥇 即插即用 ImplicitHead检测头,包括改进所需的 核心结构代码 文件作…...

学习周报:文献阅读+Fluent案例+有限体积法理论学习
目录 摘要 Abstract 文献阅读:使用带有域分解的PINN求解NS方程 文献摘要 文献讨论|结论 实验设置 NS方程介绍 PINN框架 损失函数 域分解 减轻梯度病理的方法 动态权重方法 新型网络架构 案例证明:2D圆柱尾流 Fluent案例:径向流…...
用户中心(下)
文章目录 计划登录逻辑接口简单说明cookie和session写代码流程后端逻辑层控制层测试用户管理接口 前端简化代码对接后端代理 计划 开发完成后端登录功能 (单机登录 > 后续改造为分布式 / 第三方登录)✔开发后端用户的管理接口 (用户的查询…...

商务分析方法与工具(六):Python的趣味快捷-字符串巧妙破解密码本、身份证号码、词云图问题
Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊! 喜欢我的博客的话,记得…...

ftp方式和http方式搭建云仓库
1.搭建阿里云仓库 国外云仓库比较慢,可以使用阿里云仓库代替 1.服务端和客户端切换到 yum.repo.d 目录 将自带的仓库移走 [rootlocalhost ~] cd /etc/yum.repos.d/ [rootlocalhost yum.repos.d] mkdir bak [rootlocalhost yum.repos.d] mv *.repo bak/ [rootloca…...

vue2 + antvx6 实现流程图功能
导入关键包 npm install antv/x6 --save npm install antv/x6-vue-shape 保存插件 (可选) npm install --save antv/x6-plugin-clipboard antv/x6-plugin-history antv/x6-plugin-keyboard antv/x6-plugin-selection antv/x6-plugin-snapline antv/x6-plugin-stencil antv/…...
IDEA 中的奇技淫巧
IDEA 中的奇技淫巧 书签 在使用ctrlalt方向键跳转时,或者追踪代码时,经常遇到的情况是层级太多,找不到代码的初始位置,入口。可以通过书签的形式去打上一个标记,后续可以直接跳转到书签位置。 标记书签:c…...
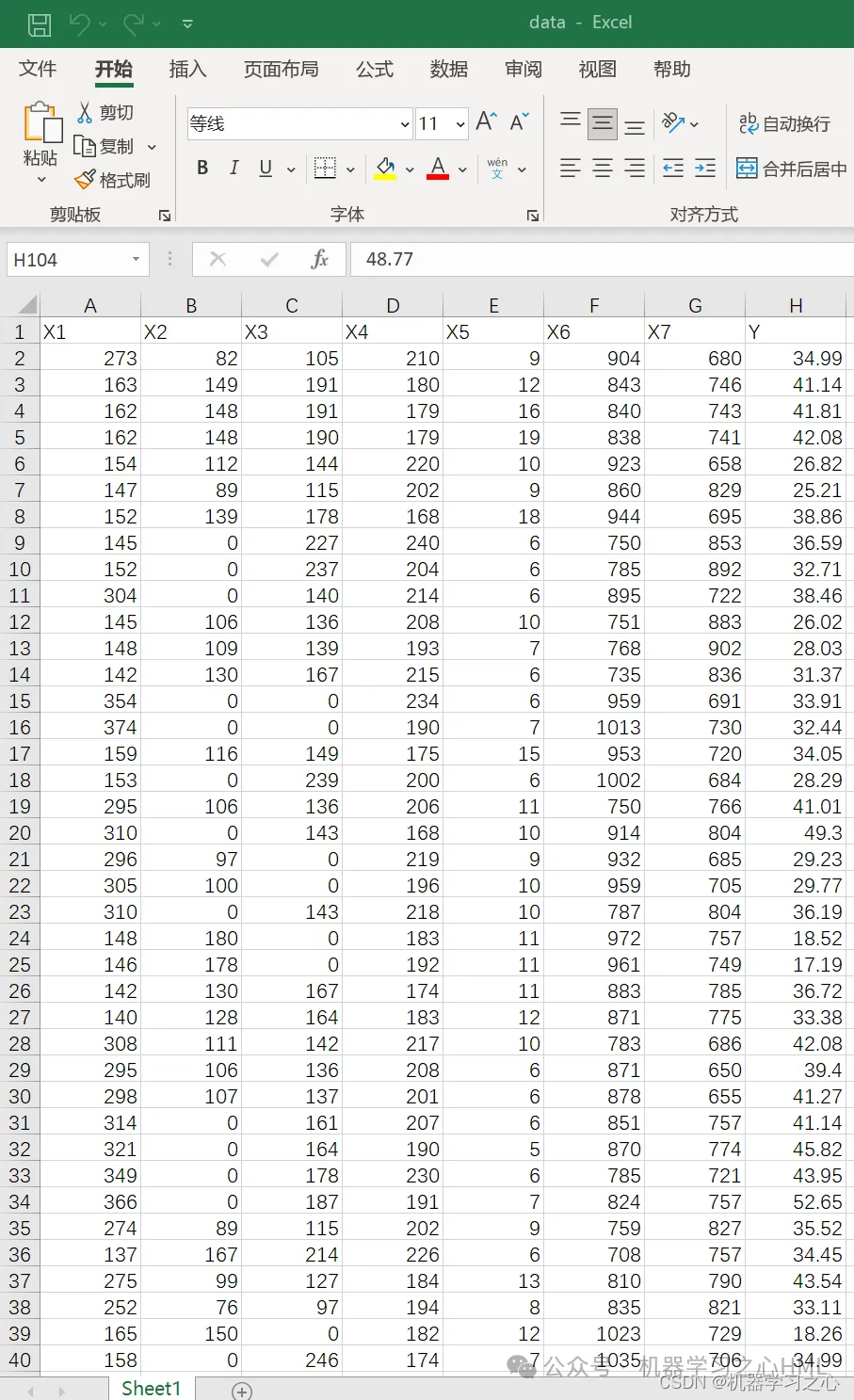
LSTM-KDE的长短期记忆神经网络结合核密度估计多变量回归区间预测(Matlab)
LSTM-KDE的长短期记忆神经网络结合核密度估计多变量回归区间预测(Matlab) 目录 LSTM-KDE的长短期记忆神经网络结合核密度估计多变量回归区间预测(Matlab)效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.LSTM-KDE的长短期…...

CMakeLists.txt语法规则:部分常用命令说明三
一. 简介 前面几篇文章学习了CMakeLists.txt语法中 add_executable命令,add_library命令,aux_source_directory命令,include_directories命令,add_subdirectory 命令的简单使用。文章如下: CMakeLists.txt语法规则&…...
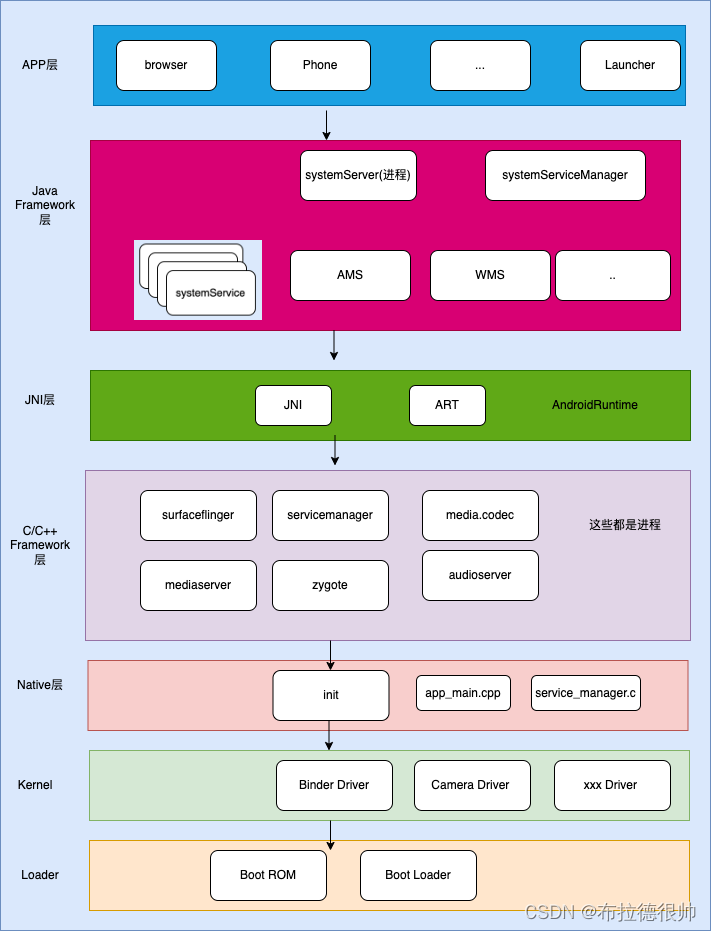
android init进程启动流程
一,Android系统完整的启动流程 二,android 系统架构图 三,init进程的启动流程 四,init进程启动服务的顺序 五,android系统启动架构图 六,Android系统运行时架构图 bool Service::Start() {// Starting a service removes it from the disabled or reset state and// imme…...

利用爬虫解决数据采集难题
文章目录 安装为什么选择 BeautifulSoup 和 requests?安装 BeautifulSoup 和 requests解决安装问题 示例总结 在现代信息时代,数据是企业决策和发展的关键。然而,许多有用的数据分散在网络上,且以各种格式和结构存在,因…...
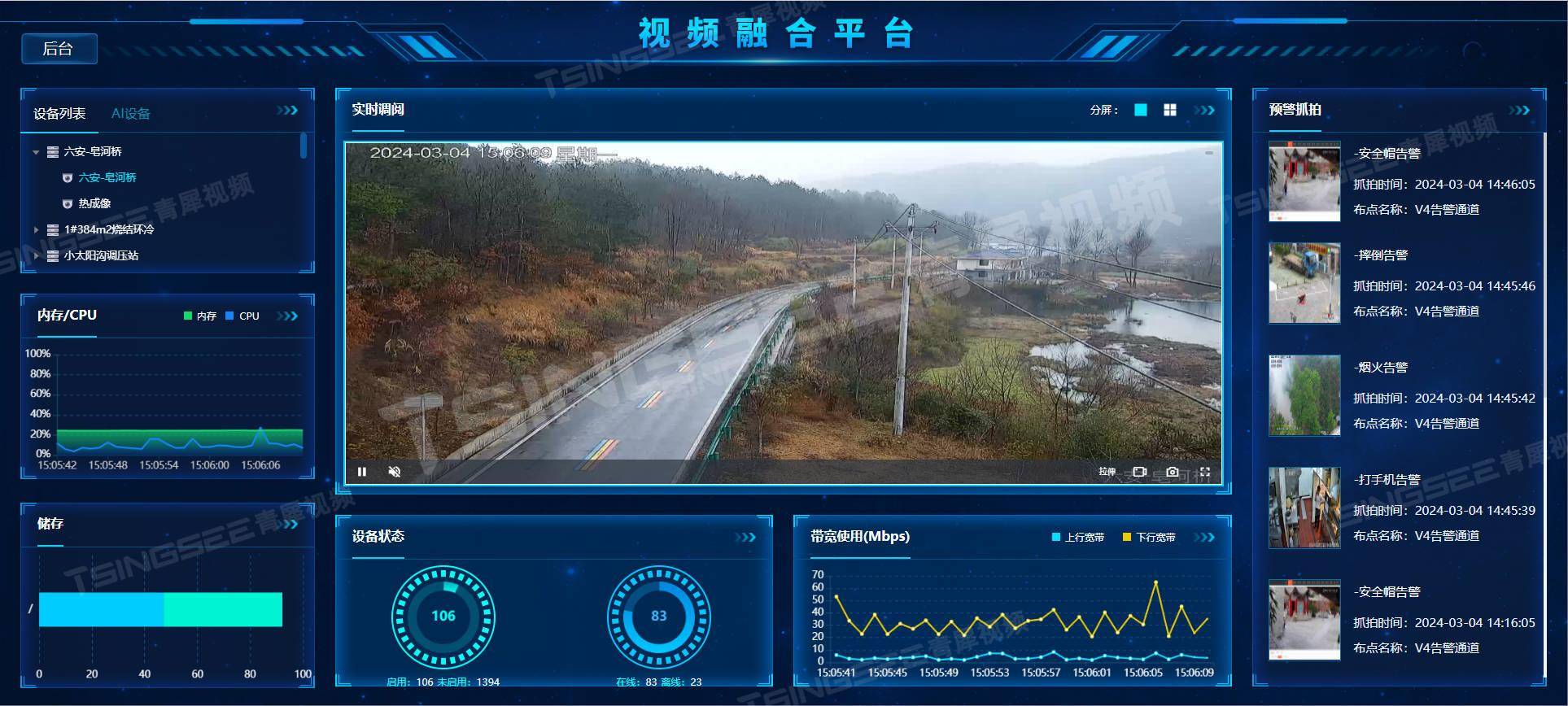
智慧粮库/粮仓视频监管系统:AI视频智能监测保障储粮安全
智慧粮库视频监管系统是一种基于物联网、AI技术和视频监控技术的先进管理系统,主要用于对粮食储存环境进行实时监测、数据分析和预警。TSINGSEE青犀智慧粮库/粮仓视频智能管理系统方案通过部署多区域温、湿度、空气成分等多类传感器以及视频监控等设施,对…...

AI Toolkit for Visual Studio Code完全指南:从环境配置到应用部署的AI开发工具链实践
AI Toolkit for Visual Studio Code完全指南:从环境配置到应用部署的AI开发工具链实践 【免费下载链接】vscode-ai-toolkit 项目地址: https://gitcode.com/GitHub_Trending/vs/vscode-ai-toolkit 工具认知篇:重新定义AI开发流程 AI开发工具链正…...

深入解析SD卡CMD指令集:从寄存器操作到数据传输实战
1. SD卡基础寄存器全解析 当你把一张SD卡插入读卡器时,系统瞬间就能识别出容量和型号,这个过程背后其实是SD卡内部寄存器的功劳。这些寄存器就像SD卡的"身份证"和"体检报告",存储着所有关键信息。我刚开始接触嵌入式开发…...

WIFI UDP广播数据实时发送的可靠性困境与底层协议探析
1. WIFI UDP广播为何总在关键时刻掉链子? 上周调试智能家居设备时,我遇到了一个典型场景:AP需要向20多个终端同时发送控制指令。最初直接使用UDP广播,结果总有设备"装聋作哑"。换成单播后问题消失,但CPU占用…...

Phi-3 Forest Laboratory 数学公式处理:集成MathType逻辑的LaTeX代码生成
Phi-3 Forest Laboratory 数学公式处理:集成MathType逻辑的LaTeX代码生成 你是不是也遇到过这样的场景?写论文或者做笔记时,需要插入一个复杂的数学公式,比如那个让人头疼的“二元二次方程的求根公式”。你打开LaTeX编辑器&#…...

开箱即用!rwkv7-1.5B-g1a镜像部署与基础问答功能实测
开箱即用!rwkv7-1.5B-g1a镜像部署与基础问答功能实测 1. 镜像概述与核心优势 rwkv7-1.5B-g1a是基于RWKV-7架构的多语言文本生成模型镜像,专为轻量级AI应用场景设计。这个1.5B参数的模型在保持高效推理能力的同时,特别适合中文环境下的基础问…...

全平台数据采集工具:BarrageGrab直播弹幕实时抓取解决方案
全平台数据采集工具:BarrageGrab直播弹幕实时抓取解决方案 【免费下载链接】BarrageGrab 抖音快手bilibili直播弹幕wss直连,非系统代理方式,无需多开浏览器窗口 项目地址: https://gitcode.com/gh_mirrors/ba/BarrageGrab 在数字直播时…...

Lenovo Legion Toolkit深度解析:5大场景硬件优化与性能调校实战指南
Lenovo Legion Toolkit深度解析:5大场景硬件优化与性能调校实战指南 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit …...

3步搞定浏览器脚本:Greasy Fork小白也能懂的终极指南
3步搞定浏览器脚本:Greasy Fork小白也能懂的终极指南 【免费下载链接】greasyfork An online repository of user scripts. 项目地址: https://gitcode.com/gh_mirrors/gr/greasyfork 你是否厌倦了网页上烦人的广告?想要自动填充表单、一键下载视…...

如何用AnythingLLM打造你的智能文档聊天机器人:5大核心功能全解析
如何用AnythingLLM打造你的智能文档聊天机器人:5大核心功能全解析 【免费下载链接】anything-llm 这是一个全栈应用程序,可以将任何文档、资源(如网址链接、音频、视频)或内容片段转换为上下文,以便任何大语言模型&…...

OpenClaw+QwQ-32B客服模拟:电商问答自动化测试
OpenClawQwQ-32B客服模拟:电商问答自动化测试 1. 为什么需要自动化客服测试 去年双十一前,我们团队遇到了一个棘手问题:每次大促前,客服团队都要手动测试上百个产品页面的问答话术。人工测试不仅耗时耗力,还经常遗漏…...