LeNet-5上手敲代码
LeNet-5
LeNet-5由Yann LeCun在1998年提出,旨在解决手写数字识别问题,被认为是卷积神经网络的开创性工作之一。该网络是第一个被广泛应用于数字图像识别的神经网络之一,也是深度学习领域的里程碑之一。
LeNet-5的整体架构:
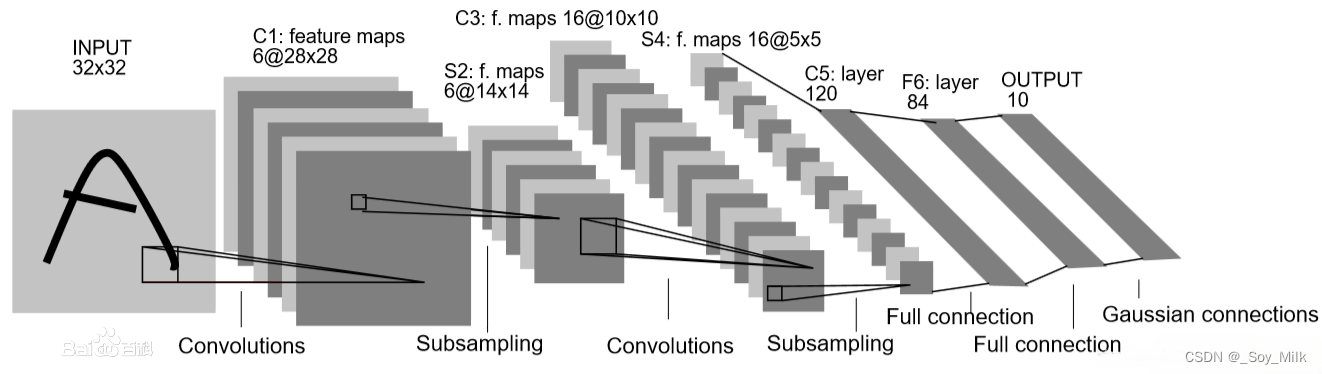
总体来看
LeNet-5由两个部分组成:
- 卷积编码器:由两个卷积层和两个下采样层组成;
- 全连接层密集块:由三个全连接层组成
特点:
1.相比MLP,LeNet使用了相对更少的参数,获得了更好的结果。
2.设计了MaxPool来提取特征
代码实现
1. 模型文件的实现
通过观察模型的整体架构,可以知到LeNet-5只用了三个基本的层——卷积层、下采样层、全连接层,因此我们很容易写出模型的基本框架。
其中
Gaussian connections也是一个全连接层。Gaussian Connections利用的是RBF函数(径向欧式距离函数),计算输入向量和参数向量之间的欧式距离。目前该方式基本已淘汰,取而代之的是Softmax。
为了提高模型的性能,我们会在卷积层与下采样层之间添加一个Relu激活函数,因此模型的整体流程架构为:
Convolutions->Relu->Subsampling->Convolutions->Relu->Subsampling->Full connection->Full connection->Full connection
在pytorch中,卷积层对应的是nn.Conv2d()方法, 下采样层可以使用pytorch中的最大池化下采样nn.MaxPool2d()方法来实现,全连接层可以使用nn.Linear()方法来实现。
确定参数:
卷积层:对于LeNet-5论文中输入的图片是 32 × 32 32 \times 32 32×32大小的图片(图片通道个数为3)。因此第一个卷积层的输入的通道个数为3,输出的通道个数为16,也就是说一共有16个卷积核。卷积核的个数等于通过卷积后图片的通道个数。
我们可以根据如下公式来计算出卷积核的大小。
计算卷积后图像宽和高的公式
I n p u t : ( N , C i n , H i n , W i n ) Input:(N, C_{in},H_{in},W_{in}) Input:(N,Cin,Hin,Win)
O u t p u t : ( N , C o u t , H o u t , W o u t ) Output:(N,C_{out},H_{out},W_{out}) Output:(N,Cout,Hout,Wout)
H o u t = [ H i n + 2 × p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] × ( k e r n e l _ s i z e [ 0 ] − 1 ) − 1 s t r i d e [ 0 ] + 1 ] H_{out} = [\frac{H_{in} + 2 \times padding[0] - dilation[0] \times (kernel\_size[0] - 1) - 1}{stride[0]} + 1] Hout=[stride[0]Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1+1]
W o u t = [ W i n + 2 × p a d d i n g [ 1 ] − d i l a t i o n [ 1 ] × ( k e r n e l _ s i z e [ 1 ] − 1 ) − 1 s t r i d e [ 1 ] + 1 ] W_{out} = [\frac{W_{in} + 2 \times padding[1] - dilation[1] \times (kernel\_size[1] - 1) - 1}{stride[1]} + 1] Wout=[stride[1]Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1+1]
公式中dilation我们没有使用,默认情况为1,输入的图片为 32 × 32 × 3 32 \times 32 \times 3 32×32×3输出为 28 × 28 × 6 28 \times 28 \times 6 28×28×6,通过公式,我们很容易算出 k e r n e l s i z e = ( 5 , 5 ) kernel_{size} = (5, 5) kernelsize=(5,5),【通常情况下如果通过卷积层后的图片的大小没有很明显的缩小(成倍数缩小),那么stride一般为默认值1】,通过以上公式,我们可以求得每一个卷积核的大小 。
最大池化下采样:由于特征图通过最大池化下采样层之后,图片的大小变为原来的一半,因此我们知道在长度方向上每两个像素之间取一个最大值,这样才能将长度变为原来的一半,宽度方向上每两个像素之间取一个最大值,这样才能将宽度变为原来的一半。结合起来得到池化层的每一个滑动窗口的大小为 2 × 2 2 \times 2 2×2,也就是说,每四个像素取一个最大值。
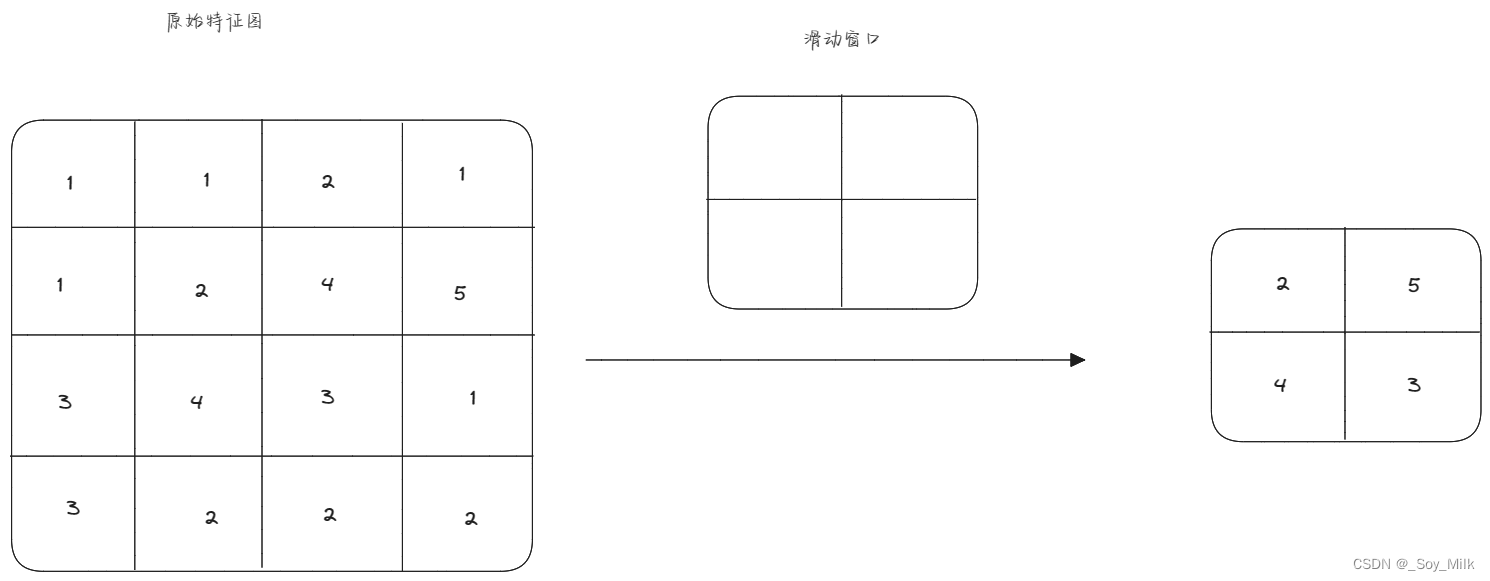
全连接层:输入为上一个层的输出数据大小,输出为自定义大小,对于第一个全连接层,输入为下采样层的输出,即: 5 × 5 × 16 5 \times 5 \times 16 5×5×16 个矩阵值。输出为下一个全连接层单元的个数(第二个全连接层的单元个数为84个),可以推出所有全连接层的单元个数。
model.py
import torch
import torch.nn as nn
import torch.nn.functional as Fclass LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.conv1 = nn.Conv2d(3, 6, (5, 5))self.pool1 = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, (5, 5))self.pool2 = nn.MaxPool2d(2, 2)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = F.relu(self.conv1(x))x = self.pool1(x)x = F.relu(self.conv2(x))x = self.pool2(x)x = x.view(-1, 16 * 5 * 5) # 改变张量形状为一个二维张量,第一个维度是自动推断的,第二个维度设定为16 * 5 * 5x = self.fc1(x)x = self.fc2(x)x = self.fc3(x)return xif __name__ == '__main__':model = LeNet()x = torch.randn((3, 32, 32))output = model(x)print(x)
2. 训练程序
写训练程序的基本步骤为:
- 加载训练数据
- 初始化模型
- 设定损失函数
- 设定优化器
- 设定迭代次数
- 根据情况保存模型权重文件
训练数据我们使用的是CIFAR10中的训练数据,验证集的数据也使用的是CIFAR10中的数据,同时将训练集和验证集的数据进行转换(转换为tensor类型,进行归一化)。设置dataloader,训练集的batch_size为64,并且进行随机打乱,设置num_workers为2,验证集的batch_size为5000,进行随机打乱,设置num_workers为2。
num_workers:用于设置是否使用多线程读取数据,开启后会加快数据读取速度,但是会占用更多内存,内存较小的电脑可以设置为2或者0
训练数据时,我们在每次的500步之后进行一次验证,验证的方式为,加载验证集,然后输入到网络中进行预测,得到输出的最大值的索引,然后再与真实标签进行比较,统计为True的个数,然后除以所有的标签的个数,得到最后的模型的正确率。
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, test_label).sum().item() / test_label.size(0) # .item() 方法将结果转换为标量,即 Python 中的普通数字类型。
在迭代完所有的步数之后进行保存模型的权重文件。
train.py
import torch
import torchvision
from torch import nn, optim
from torch.utils.data import DataLoaderfrom model import LeNetdef main():device = torch.device("cuda" if torch.cuda.is_available() else "cpu")transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 训练集train_set = torchvision.datasets.CIFAR10(root="./data", train=True, download=False, transform=transform)train_loader = DataLoader(dataset=train_set, batch_size=64, shuffle=True, num_workers=2)# 验证集test_set = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transform)test_loader = DataLoader(dataset=test_set, batch_size=5000, shuffle=True, num_workers=0)# 实例化网络,损失函数,优化器net = LeNet().to(device)net.load_state_dict(torch.load('LeNet_200.pth')) # 加载权重loss_function = nn.CrossEntropyLoss().to(device)optimizer = optim.Adam(net.parameters(), lr=0.001)epochs = 200epoch = 0# 开始训练print("training...")while epoch <= epochs:epoch += 1running_loss = 0.0for step, data in enumerate(train_loader):print(f"epoc: {epoch}, step: {step}")inputs, lables = datainputs, lables = inputs.to(device), lables.to(device) # 将数据移动到GPU上optimizer.zero_grad()output = net(inputs)loss = loss_function(output, lables)loss.backward()optimizer.step()running_loss += loss.item()if step % 500 == 499: # 每500个batch_size之后进行验证一次with torch.no_grad():test_image, test_label = next(iter(test_loader)) # iter(test_loader)作用是设定一个迭代器,这行代码的作用是取出验证集中的一个batch_size的图片和对应的标签。test_image, test_label = test_image.to(device), test_label.to(device) # 将数据移动到 GPU 上outputs = net(test_image)predict_y = torch.max(outputs, dim=1)[1]accuracy = torch.eq(predict_y, test_label).sum().item() / test_label.size(0) # .item() 方法将结果转换为标量,即 Python 中的普通数字类型。print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %(epoch + 1, step + 1, running_loss / 500, accuracy))running_loss = 0.0print(f"The epoc is {epoch}")print("Finish Training")save_path = "./LeNet.pth"torch.save(net.state_dict(), save_path)if __name__ == '__main__':main()3. 验证程序
验证程序,首先需要加载图片,然后进行转换(包括裁剪为模型的输入形状大小【这里为 32 × 32 32 \times 32 32×32】,然后转换为tensor类型,最后进行归一化),将预处理后的图片送入到模型中,模型输出的是一个batch_size个一维向量,每一个一维向量有10个数,表示输出的类别一共有10个,取10个中值最大的数的索引作为预测的类别,可以使用以下代码:predict = torch.max(outputs, dim=1)[1].numpy(),这表示在模型输出的结果中,取第一个维度上的10个数取最大值的索引,并将其转换为numpy类型的数据。然后将这个数对照标签的映射关系,可以得到最终预测的类别。
varify.py
import torch
import torchvision.transforms as transforms
from PIL import Imagefrom model import LeNetdef main():transform = transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')net = LeNet()net.load_state_dict(torch.load('LeNet_250.pth'))im = Image.open('2.jpg') # 加载图片im = transform(im) # [C, H, W]im = torch.unsqueeze(im, dim=0) # [N, C, H, W]with torch.no_grad(): # 用于设置在该上下文中不进行梯度计算,因为推断时不需要计算梯度,可以提高计算效率。outputs = net(im)predict = torch.max(outputs, dim=1)[1].numpy()print(classes[int(predict)])if __name__ == '__main__':main()相关文章:
LeNet-5上手敲代码
LeNet-5 LeNet-5由Yann LeCun在1998年提出,旨在解决手写数字识别问题,被认为是卷积神经网络的开创性工作之一。该网络是第一个被广泛应用于数字图像识别的神经网络之一,也是深度学习领域的里程碑之一。 LeNet-5的整体架构: 总体…...
javaWeb入门(自用)
1. vue学习 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title><script src"https://unpkg.com/vue2"></script> </head> <body><div id"…...

web3风格的网页怎么设计?分享几个,找找感觉。
web3风格的网站是指基于区块链技术和去中心化理念的网站设计风格。这种设计风格强调开放性、透明性和用户自治,体现了Web3的核心价值观。 以下是一些常见的Web3风格网站设计元素: 去中心化标志:在网站的设计中使用去中心化的标志࿰…...

ASP.NET MVC(-)表单的提交、获取表单数据
FromCollection 方式...

[AIGC] 《MyBatis-Plus 结合 Spring Boot 的动态数据源介绍及 Demo 演示》
在现代的 Web 应用开发中,Spring Boot 已经成为了一种流行的框架选择。而 MyBatis-Plus 则为 MyBatis 框架提供了更强大的功能和便利。当它们结合使用时,动态数据源的运用变得更加简单和高效。 动态数据源的概念允许我们在运行时根据不同的条件或需求选…...
)
【华为OD机试C卷D卷】部门人力分配(C++/Java/Python)
【华为OD机试】-(A卷+B卷+C卷+D卷)-2024真题合集目录 【华为OD机试】-(C卷+D卷)-2024最新真题目录 题目描述 部门在进行需求开发时需要进行人力安排。 当前部门需要完成 N 个需求,需求用 requirements 表述,requirements[i] 表示第 i 个需求的工作量大小,单位:人月。 这部…...
毕业设计:《基于 Prometheus 和 ELK 的基础平台监控系统设计与实现》
前言 《基于 Prometheus 和 ELK 的基础平台监控系统设计与实现》,这是我在本科阶段的毕业设计,通过引入 Prometheus 和 ELK 架构实现企业对指标与日志的全方位监控。并且基于云原生,使用容器化持续集成部署的开发方式,通过 Sprin…...
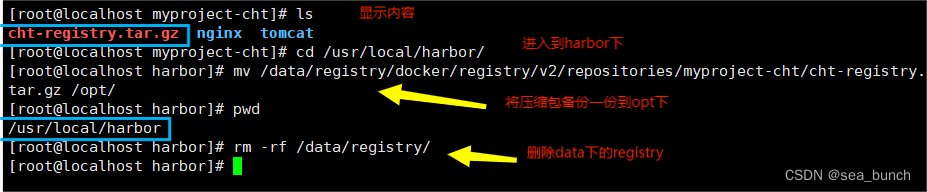
docker私有仓库部署与管理
一、搭建本地公有仓库 1.1 首先下载registry镜像 docker pull registry 1.2 在daemon.json文件中添加私有镜像仓库地址并重新启动docker服务 vim /etc/docker/daemon.json 1.3 运行registry容器 docker run -itd -v /data/registry:/var/lib/registry -p 5000:5000 --restartal…...

2024第六届济南国际大健康产业博会将于5月27日如期开幕
由山东省城市经济学会、山东省科学养生协会主办的第六届中国(济南)国际大健康产业博览会,将于5月27-29日,在济南黄河国际会展中心盛大举办。 近年来,健康越来越受到大众的重视,在我国经济重要的转型阶段成…...
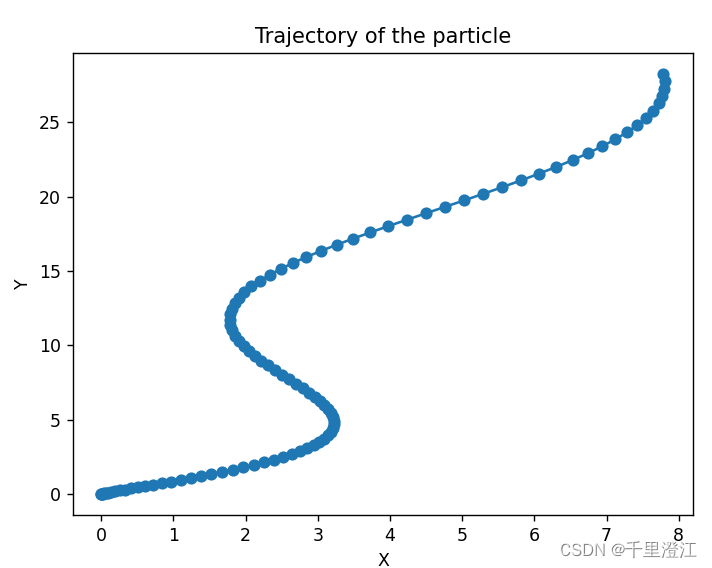
计算方法实验9:Romberg积分求解速度、位移
任务 输出质点的轨迹 ( x ( t ) , y ( t ) ) , t ∈ { 0.1 , 0.2 , 0.3 , . . . , 10 } (x(t), y(t)), t\in \{0.1, 0.2, 0.3, ..., 10\} (x(t),y(t)),t∈{0.1,0.2,0.3,...,10},并在二维平面中画出该轨迹.请比较M分别取4, 8, 12, 16, 20 时,Romberg积分达…...

设计模式有哪些基本原则
目录 开闭原则(Open Closed Principle) 里氏替换原则(Liskov Substitution principle) 单一职责原则(Single Responsibility Principle,SRP)...
别再出错了!华为交换机到底如何配置access、trunk、hybird端口?
号主:老杨丨11年资深网络工程师,更多网工提升干货,请关注公众号:网络工程师俱乐部 下午好,我的网工朋友。 我们都知道,网络工程师的工作离不开对交换机的熟练操作。华为交换机的配置,绝对是考验…...

OceanBase 分布式数据库【信创/国产化】- OceanBase 平台产品 - 迁移评估工具 OMA
本心、输入输出、结果 文章目录 OceanBase 分布式数据库【信创/国产化】- OceanBase 平台产品 - 迁移评估工具 OMA前言OceanBase 数据更新架构OceanBase 平台产品 - 迁移评估工具 OMA兼容性评估性能评估导出 OceanBase 数据库对象和 SQL 语句OceanBase 分布式数据库【信创/国产…...
UE5入门学习笔记(六)——编译低版本插件
对于有些低版本的插件,可以通过此方法自己编译到高版本而无需等待插件作者更新 使用工具:如图所示 步骤1:打开cmd,并使用cd命令切换到此目录 步骤2:输入如下指令 RunUAT.bat BuildPlugin -Plugin“路径1” -Package“…...

MySQL全局锁、表级锁、行锁、死锁、索引选择
文章目录 全局锁表级锁表锁元数据锁 MDL 如何安全的给小表添加字段1. 理解和监控长事务2. 使用NOWAIT和WAIT语法示例 3. 选择合适的时间窗口4. 分阶段执行5. 使用在线DDL工具 行锁死锁普通索引和唯一索引的选择索引基础业务场景分析性能考量实践建议索引及其选择机制索引选择错…...

深入解析算法效率核心:时间与空间复杂度概览及优化策略
算法复杂度,即时间复杂度与空间复杂度,衡量算法运行时资源消耗。时间复杂度反映执行时间随数据规模增长的关系,空间复杂度表明额外内存需求。优化策略,如选择合适数据结构、算法改进、循环展开等,对于提升程序效率、减…...
虚拟机装CentOS镜像
起先,是先安装一个VM虚拟机,再去官方网站之类的下载一些镜像,常见镜像有CentOS镜像,ubantu镜像,好像还有一个树莓还是什么的,软件这块,日新月异,更新太快,好久没碰&#…...
SpringCloud 集成consul,消费者报I/O error on GET request for...
创建消费者微服务,去调用生产者微服务的请求过程中,出现以下错误: 报错原因 因为在使用SpringCloudAlibaba中的Nacos框架时,自动整合了SpringCloud中的Ribbon框架中的负载均衡,因为微服务提供者有两个,在消…...

pytest的测试标记marks
引用打标的marks文档 Python的pytest框架(5)--测试标记(Markers)_pytest执行指定的marker-CSDN博客 https://www.cnblogs.com/pipile/p/12696226.html 给用例自定义打标签的代码示例 #coding:utf-8 import pytest pytest.mark.smoke def test_1():print("smoke的测试用…...
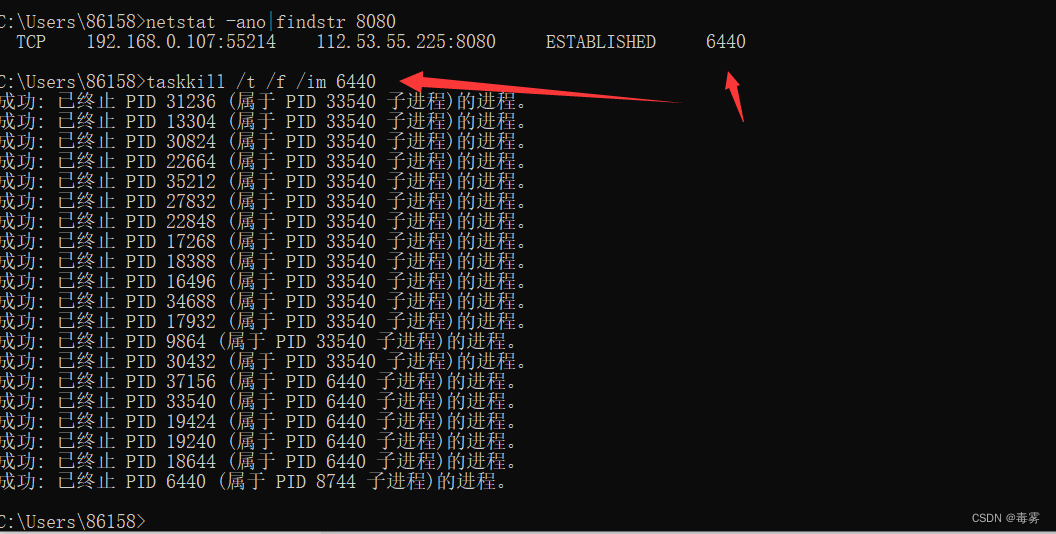
端口占用解决方法
1、查询端口 打开cmd命令提示符窗口,输入以下指令查询所有端口 netstat -ano //查询所有端口 netstat -ano|findstr 8080 //查询指定端口 2、杀死进程 taskkill /t /f /im 进程号(PID)...

Python 开发者如何通过 OpenAI 兼容协议快速接入 Taotoken
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python 开发者如何通过 OpenAI 兼容协议快速接入 Taotoken 对于使用 Python 的开发者而言,接入多个大模型服务通常意味…...

Cursor Pro无限使用指南:如何绕过API限制实现永久免费使用
Cursor Pro无限使用指南:如何绕过API限制实现永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

3步掌握WinUtil:Windows系统调校的终极自动化工具
3步掌握WinUtil:Windows系统调校的终极自动化工具 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil WinUtil是一款开源的Windows系统…...

告别手动输入!用这个SAP增强技巧,为不同采购类型定制专属批次号
SAP批次号智能生成:基于采购类型的动态规则设计与实战 当仓库管理员第17次因为批次号混淆而紧急叫停生产线时,企业终于意识到传统批次管理已无法支撑多元化采购场景。某医疗器械集团在引入高值耗材专项采购(Z04类型)后,…...

登封市总医院暨公卫应急救治中心全光网络建设百盛分析报告
一、项目背景登封市总医院暨公卫应急救治中心是河南省重点民生工程,位于登封市少林大道与花楼路交叉口东南角,总投资 18.6 亿元,建设用地面积约 169.14 亩,总建筑面积达 22.52 万平方米,核定床位 1500 张登封市公共资源…...

PaDiM实战:从理论到代码的异常检测全流程拆解
1. PaDiM异常检测模型入门指南 第一次接触PaDiM时,我也被那些数学公式吓到了。但真正用起来才发现,这个基于预训练CNN的异常检测框架其实很友好。简单来说,它就像个"找不同"的高手 - 先记住正常样本长什么样(训练阶段&a…...

基于Rust的高效远程桌面方案:从协议优化到部署实践
1. 项目概述:远程桌面连接的另一条路如果你和我一样,经常需要在Windows电脑上操作远在另一张桌子上的Mac,或者反过来,那么“远程桌面”这个需求就再熟悉不过了。市面上有VNC、微软的RDP,还有各种第三方工具,…...

AI研究代理:聚合真实用户行为,打破信息孤岛,实现智能信息整合
1. 项目概述:一个由真实用户行为驱动的AI研究代理如果你和我一样,每天需要快速了解一个陌生的人、公司、技术或者热点事件,你肯定也厌倦了在十几个浏览器标签页之间反复横跳。Google搜索的结果,往往是被SEO优化过的、几个月前的博…...
)
Win11系统下Anaconda3-2022.10保姆级安装与避坑指南(附不勾选PATH的详细原因)
Win11系统下Anaconda3-2022.10深度安装指南与关键配置解析 在数据科学和机器学习领域,Anaconda已经成为Python环境管理的标准工具之一。对于Windows 11用户来说,正确安装和配置Anaconda是开启数据分析之旅的第一步。本文将深入探讨Anaconda3-2022.10版本…...

别再被格式拖垮论文!Paperxie 一键搞定 4000 + 高校毕业论文排版,省下三天改稿时间
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能格式排版/文献综述/AI PPThttps://www.paperxie.cn/format/typesettinghttps://www.paperxie.cn/format/typesetting 当你终于写完毕业论文的最后一个字,以为能松口气,却发现格式排版才是真正的 “…...