Python数据清洗与可视化实践:国际旅游收入数据分析
文章目录
- 概要
- 整体流程
- 名词解释
- NumPy
- Pandas
- Matplotlib
- re
- 技术细节
- 数据清洗
- 可视化
- 小结
概要
在本篇博客中,我们将通过一个实际的案例,演示如何使用Python进行数据清洗和可视化,以分析国际旅游收入数据。我们将使用Python中的Pandas库来进行数据处理和清洗,然后使用Matplotlib库来绘制饼图,展示各地区2017年至2019年国际旅游收入总和的占比情况。

整体流程
- 将表头统一为一行。
- 将地区字符串中的符号“?”,“ ”去除。
- 删除空白行。
- 删除重复行。
- 表格中第二列数据(B列)等于第三四五列之和,将第二、三、四、五列中的空值填充。
- 使用mean()填充第六列空值。
- 使用中位数法填充第7列空值。
- 使用四分位法对第8列数据进行异常值处理,并将异常值设置为该列均值。
- 使用除均值和中位数法以外的方法将第9和10列的空值填充。
- 结果保留一位小数
- 对数据绘制可视化饼图
名词解释
数据分析是指利用统计学和计算机科学的方法,对收集到的数据进行分析、解释和探索,从而发现数据中的模式、趋势和关联性,提取有用的信息和知识,并为决策和问题解决提供支持。数据分析可以应用于各个领域,包括商业、科学、工程、医疗等,帮助人们更好地理解数据、发现问题和机会,并制定合适的策略和方案。
数据分析的主要目标包括:
- 描述性分析:对数据进行汇总和描述,包括统计量的计算、图表的绘制等,以便对数据有一个整体的了解。
- 探索性分析:通过可视化和探索性数据分析(EDA),探索数据中的模式、趋势和关系,发现数据中的隐藏信息和规律。
- 预测性分析:利用统计和机器学习方法,建立模型来预测未来的趋势和行为,帮助做出更准确的预测和决策。
- 解释性分析:对模型和结果进行解释,理解模型背后的原理和机制,从而深入理解数据背后的规律和关联性。
数据分析通常涉及多种技术和工具,包括数据清洗、数据可视化、统计分析、机器学习等。通过对数据进行系统和深入的分析,可以发现数据中的价值和见解,为组织和个人提供更好的决策支持和业务洞察。
NumPy
- NumPy 是 Python 中用于科学计算的核心库之一,提供了高性能的多维数组对象和各种数学函数。它是许多其他数据分析工具的基础,如 Pandas 和 SciPy。
- NumPy 的核心是 ndarray(N-dimensional array)对象,可以用来存储和处理多维数组数据。它提供了各种函数和方法,可以进行数组的创建、索引、切片、数学运算、线性代数运算等操作。
Pandas
- Pandas 是 Python 中用于数据分析的核心库之一,提供了快速、灵活且高效的数据结构和数据操作工具。它的主要数据结构是 Series(一维数组)和 DataFrame(二维表格),可以轻松处理结构化数据。
- Pandas 提供了丰富的函数和方法,可以进行数据的加载、清洗、转换、分组、聚合等操作。它还支持对缺失值和异常值的处理,以及数据的合并和拆分等高级操作。
Matplotlib
- Matplotlib 是 Python 中用于创建可视化图表的主要库之一,提供了广泛的功能和灵活性。它可以创建各种类型的静态图表,如折线图、散点图、直方图等。
- Matplotlib 的设计灵感来自于 MATLAB,因此其语法和用法与 MATLAB 相似。它支持绘制高质量的图表,并且可以通过设置不同的样式和参数来定制图表的外观和风格。
re
- re 是 Python 中用于正则表达式操作的标准库,提供了强大的文本模式匹配和处理功能。正则表达式是一种强大的文本搜索和处理工具,可以用来查找、替换、分割等。
- re 库提供了各种函数和方法,可以用来编译和执行正则表达式,以及进行各种文本操作。它通常用于处理复杂的文本数据,如日志文件、网络数据等。
这些库在数据分析领域发挥着重要的作用,通过它们的组合,可以完成从数据加载到数据可视化的整个数据分析过程。
技术细节
首先安装Python🚪和Jupyter Lab,如果已经安装了这两个的话可以直接打开jupyter lab进行下一步
// 安装:
pip3 install jupyterlab
安装完成之后,可以查看版本号看安装是否成功
然后打开cmd命令行,进到你要打开的文件夹目录下,输入jupyter lab打开,通过以上步骤,你就可以成功安装和启动 Jupyter Lab,并开始使用它进行数据分析、机器学习、编程等工作了。
数据清洗
首先导入需要用来数据分析的依赖numpy,Pandas,Matplotlib.pyplot,re。再从excel文件中读取Excel 文件数据,并将读取的数据存储在名为 data 的 DataFrame 中。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import repath = 'chuji.xlsx'
data = pd.read_excel(path, engine='openpyxl') # 数据读取
将表头统一为一行:将data的列名(表头)设置为指定的列表,列表中的每个元素对应一个列名,再删除第一行数据,索引为 0 的行
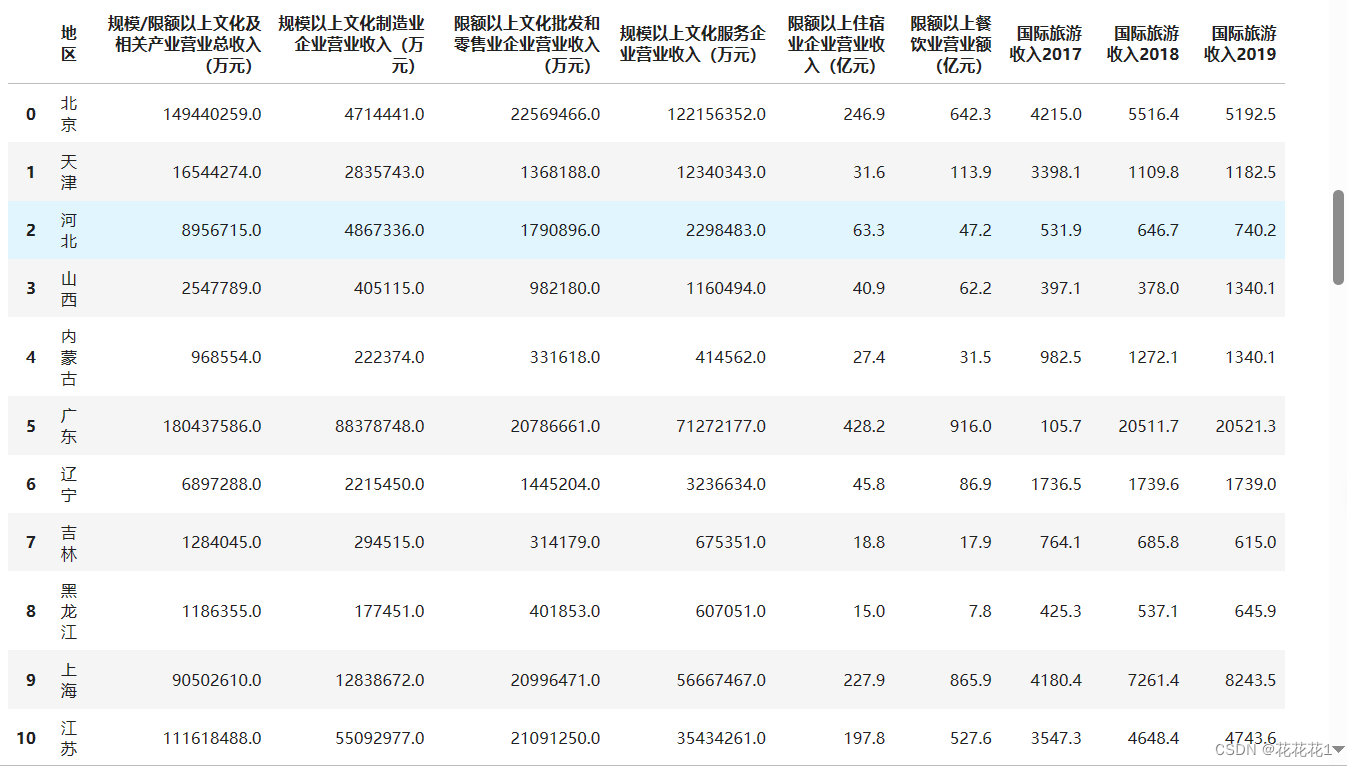
data.columns = ['地区','规模/限额以上文化及相关产业营业总收入(万元)','规模以上文化制造业企业营业收入(万元)','限额以上文化批发和零售业企业营业收入(万元)','规模以上文化服务企业营业收入(万元)','限额以上住宿业企业营业收入(亿元)','限额以上餐饮业营业额(亿元)','国际旅游收入2017','国际旅游收入2018','国际旅游收入2019']
data = data.drop(0)
将地区字符串中的符号“?”,“ ”去除:使用了正则表达式模块 re 中的 sub() 函数来替换字符串中的匹配项。lambda x: re.sub(r'\s+', '', str(x)) if not pd.isna(x) else x 是一个匿名函数,这个函数首先检查元素是否为 NaN(缺失值),如果不是,则使用正则表达式 re.sub() 将字符串中的所有空格(\s+)替换为空字符串,从而去除空格。如果元素是NaN,则返回原始值。最后,使用 .apply() 函数将这个匿名函数应用于地区列中的每个元素,从而实现去除符号“?”和空格的操作。
data.iloc[:, 0] = data.iloc[:, 0].apply(lambda x: re.sub(r'\s+', '', str(x)) if not pd.isna(x) else x)
删除空白行和重复行:dropna() 方法来删除包含空值(NaN)的行,axis=0 参数指定了操作的轴向,这里设为 0 表示按行进行操作。how=‘all’ 参数指定了删除行的条件,这里设为 ‘all’ 表示当行中所有元素都是空值(NaN)时才删除该行。drop_duplicates() 方法来删除重复行,inplace=True 参数表示在原始 DataFrame 上进行操作,不创建新的 DataFrame。
data.dropna(axis=0, how='all', inplace=True)
data.drop_duplicates(inplace=True)
由于之前删除了空白行和重复行,所以要重设索引,使用 DataFrame 的 reset_index() 方法重新设置索引。参数 drop=True 表示丢弃原始索引,而不保留在 DataFrame 中作为新的列。重新设置索引后,DataFrame 的索引会按照从 0 开始的顺序重新排列。
data.reset_index(drop=True, inplace=True) # 重置索引
填充二三四五列数据:对第二列进行处理:data.iloc[:, 1].isnull().any():检查第二列是否存在空值。如果存在空值,则使用 fillna() 方法填充空值。填充值为第三、四、五列之和,使用 data.iloc[:, 2] +data.iloc[:, 3] + data.iloc[:, 4] 计算。同时使用 astype(data.iloc[:, 1].dtype) 将填后的数据类型转换为第二列原始的数据类型,以保持数据一致性。其它三列也是相同的处理方法
# 如果第二列为空值,求和第三四五列
if data.iloc[:, 1].isnull().any(): data.iloc[:, 1] = data.iloc[:, 1].fillna(data.iloc[:, 2] + data.iloc[:, 3] + data.iloc[:, 4]).astype(data.iloc[:, 1].dtype)
# 对第三列进行空值判断
if data.iloc[:, 2].isnull().any():data.iloc[:, 2] = data.iloc[:, 2].fillna(data.iloc[:, 1] - data.iloc[:, 3] - data.iloc[:, 4]).astype(data.iloc[:, 2].dtype)
# 对第四列进行空值判断
if data.iloc[:, 3].isnull().any():data.iloc[:, 3] = data.iloc[:, 3].fillna(data.iloc[:, 1] - data.iloc[:, 2] - data.iloc[:, 4]).astype(data.iloc[:, 3].dtype)
# 对第五列进行空值判断
if data.iloc[:, 4].isnull().any():data.iloc[:, 4] = data.iloc[:, 4].fillna(data.iloc[:, 1] - data.iloc[:, 2] - data.iloc[:, 3]).astype(data.iloc[:, 4].dtype)
第六列数据:使用 mean() 方法获取列的均值,使用 fillna() 方法填充第六列的空值。填充值为前面计算得到的均值 mean_value
mean_value = data.iloc[:, 5].mean()
data.iloc[:, 5].fillna(mean_value, inplace=True)
第七列数据:使用 median() 方法获取列的中位数,使用 fillna() 方法填充第七列的空值。填充值为前面计算得到的中位数 median_value
median_value = data.iloc[:, 6].median()
data.iloc[:, 6].fillna(median_value, inplace=True)
第八列数据:首先,计算第八列数据的四分位数和 IQR = Q3 - Q1(四分位间距):计算第八列数据的第一四分位数(25th percentile)。计算第八列数据的第三四分位数(75th percentile)。接着,计算异常值的上下界,使用 np.where() 函数将超出异常值范围的值替换为该列的均值
Q1 = data.iloc[:, 7].quantile(0.25)
Q3 = data.iloc[:, 7].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
data.iloc[:, 7] = np.where((data.iloc[:, 7] < lower_bound) | (data.iloc[:, 7] > upper_bound), mean_value, data.iloc[:, 7])
第九、十列数据:参数 method='ffill' 表示使用前向填充法,即用前一个非空值填充当前空值。参数 method='bfill' 表示使用后向填充法,即用后一个非空值填充当前空值。
data.iloc[:, 8].fillna(method='ffill', inplace=True) # 前向填充第9列
data.iloc[:, 9].fillna(method='bfill', inplace=True) # 后向填充第10列
所有结果保留一位小数:使用 for 循环遍历索引范围从 0 到 10,即遍历所有列。round() 方法是 Python 中用于四舍五入的函数,参数 1 表示保留一位小数。
for i in range(0,10):data.iloc[:, i] = data.iloc[:, i].round(1)
可视化
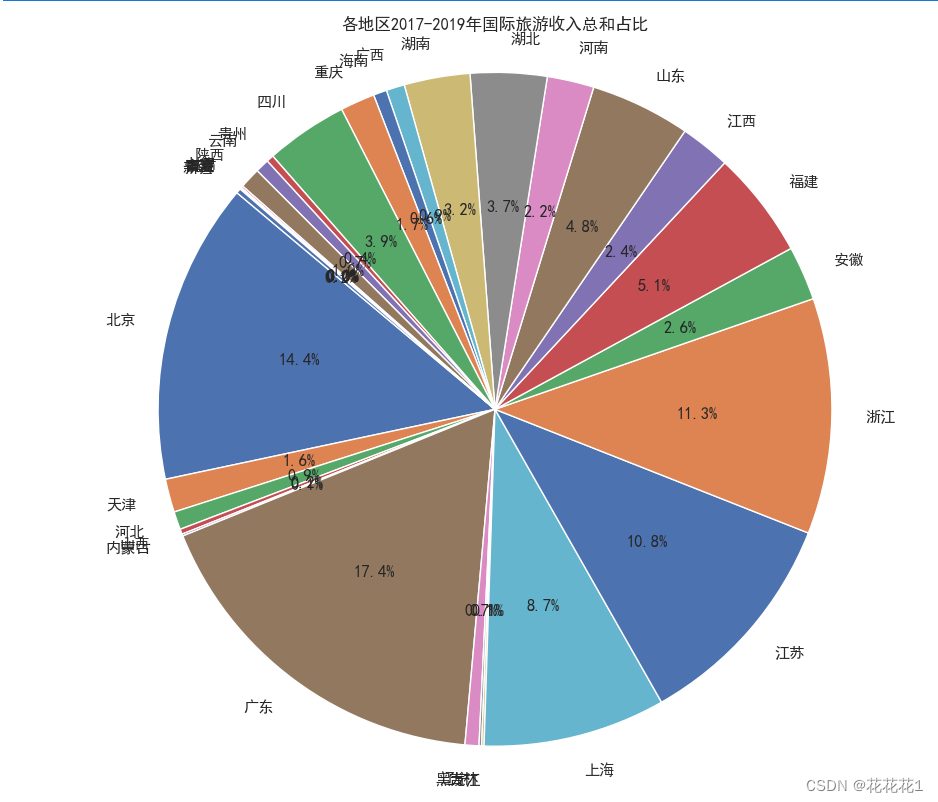
在清洗和预处理完数据之后,我们可以使用Matplotlib库来绘制饼图,展示各地区2017年至2019年国际旅游收入总和的占比情况。
设置中文显示:用于设置字体为中文,以及解决坐标轴负号显示问题
plt.rcParams['font.sans-serif'] = ['simHei']
plt.rcParams['axes.unicode_minus'] = False
将每个地区2017年至2019年国际旅游收入的总和计算出来,并存储在名为"总收入"的新列中
data['总收入'] = data.iloc[:, 1:].sum(axis=1)
创建了一个大小为10x8英寸的画布,用于绘制饼图
plt.figure(figsize=(10, 8))
绘制了饼图,其中data[‘总收入’]是各地区收入总和的数据,labels是各地区的标签,autopct='%1.1f%%'是指定了数据标签的显示格式,startangle=140是设置了起始角度为140度
plt.pie(data['总收入'], labels=data['地区'], autopct='%1.1f%%', startangle=140)
添加了饼图的标题
plt.title('各地区2017-2019年国际旅游收入总和占比')
调整了布局,使得图形更加美观
plt.tight_layout()
保持饼图的长宽比相等,然后plt.show()将绘制好的图形显示出来
plt.axis('equal')
plt.show()
小结
通过本篇博客,我们学习了如何使用Python进行数据清洗和可视化分析。首先,我们使用Pandas库对数据进行了清洗和预处理,然后利用Matplotlib库绘制了饼图,展示了各地区2017年至2019年国际旅游收入总和的占比情况。这个案例展示了Python在数据分析领域的强大应用和灵活性
希望本文能够帮助读者更好地了解的Python在数据分析方面的使用,如果有任何疑问或者建议,欢迎留言讨论🌹
相关文章:
Python数据清洗与可视化实践:国际旅游收入数据分析
文章目录 概要整体流程名词解释NumPyPandasMatplotlibre 技术细节数据清洗可视化 小结 概要 在本篇博客中,我们将通过一个实际的案例,演示如何使用Python进行数据清洗和可视化,以分析国际旅游收入数据。我们将使用Python中的Pandas库来进行数…...

前置知识储备
基本认知 什么是模式 在一定环境中解决一些问题的方案(通俗来说:特定环境中用固定的套路解决问题) 什么是设计模式 设计模式是一套反复被人使用,多数人知晓的,经过分类编目的代码设计经验的总结 设计模式最终的目…...
六月品牌互动营销方案的作用是什么
品牌需要借势营销,六月的六个节日热点,是企业商家不能错过的,如何运用合适的工具/方法借势也同样重要。 互动h5游戏/传单页面发挥不同效果,这份《六月品牌互动营销方案》看看有哪些内容吧~ 1、儿童节 宜:回忆欢乐营销…...

dummy_worker C++ 预占用部分比例cpu资源,人为创造cpu资源紧张
背景 有时候为了C测试程序在cpu资源紧张情况下是否正常,需要人为创造cpu资源紧张 编译方法 g -o dummp_worker dummp_worker.cpp -stdc11 -pthread 使用方法 ./dummp_worker 4 0.2 占用4个cpu核的20%比例的cpu资源 源码 // dummp_worker.cpp #include <c…...

电脑缺失opencl.dll怎么办,轻松解决opencl.dll的多种方法分享
当我们在操作电脑过程中遇到系统提示“由于找不到opencl.dll,无法继续执行代码”,这个错误会导致软件应用无法正常运行。OpenCL.dll作为一个与Open Computing Language(开放计算语言)相关的动态链接库文件,它在执行需要…...
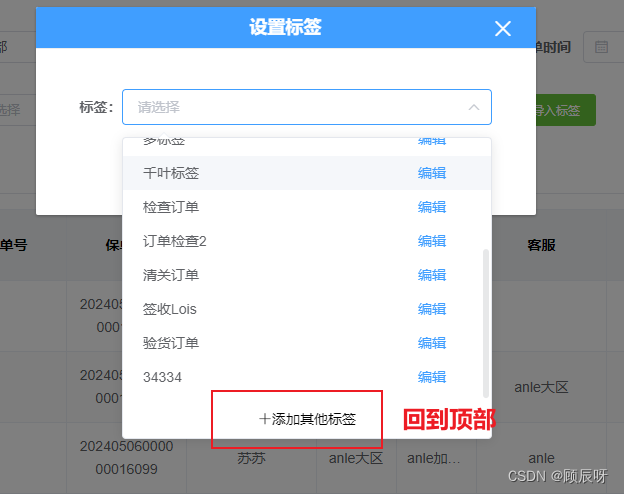
el-select 点击按钮滚动到选择框顶部
主要代码是在visibleChange 在这个 popper 里面找到 .el-select-dropdown__list let popper ref.$refs.popper const ref this.$refs.select let dom popper.querySelector(.el-select-dropdown__list) setTimeout(() > { dom.scrollIntoView() }, 800) <templat…...

vue 钩子函数updated什么时候触发
触发时机 updated是Vue生命周期钩子函数之一,在组件的数据变化导致虚拟DOM重新渲染并应用到实际DOM之后触发。具体来说,updated会在以下几种情况下被触发: 初始渲染完成后:当组件首次渲染完成并将虚拟DOM渲染到实际DOM之后&#…...

消息队列使用常见问题
一、消息丢失的时机? 生产端消息丢失 问题:因为网络异常导致消息发送失败,此时可能会产生消息丢失的情况,重试后可能产生消息重复生产的情况。 解决:超时重试,并在消费端保证幂等性。 消息队列中消息丢失 …...
常用SQL命令
应用经常需要处理用户的数据,并将用户的数据保存到指定位置,数据库是常用的数据存储工具,数据库是结构化信息或数据的有序集合,几乎所有的关系数据库都使用 SQL 编程语言来查询、操作和定义数据,进行数据访问控制&…...

【neteq】tgcall的调用、neteq的创建及接收侧ReceiveStatisticsImpl统计
G:\CDN\P2P-DEV\Libraries\tg_owt\src\call\call.cc基本是按照原生webrtc的来的:G:\CDN\P2P-DEV\tdesktop-offical\Telegram\ThirdParty\tgcalls\tgcalls\group\GroupInstanceCustomImpl.cpptg对neteq的使用 worker 线程创建call Call的config需要neteqfactory Call::CreateAu…...

使用Python读取las点云,写入las点云,无损坐标精度
目录 1 为什么要写这个博文2 提出一些关键问题3 给出全部代码安装依赖源码(laspy v2.x) 1 为什么要写这个博文 搜索使用python读写las点云数据,可以找到很多结果。但是! 有些只是简单的demo,且没有发现/说明可能遇到的…...

python开发二
python开发二 requests请求模块 requests 是一个常用的 Python 第三方库,用于发送 HTTP 请求。它提供了简洁且易于使用的接口,使得与 Web 服务进行交互变得非常方便。 发送 GET 请求并获取响应 import requestsresponse requests.get("https:/…...
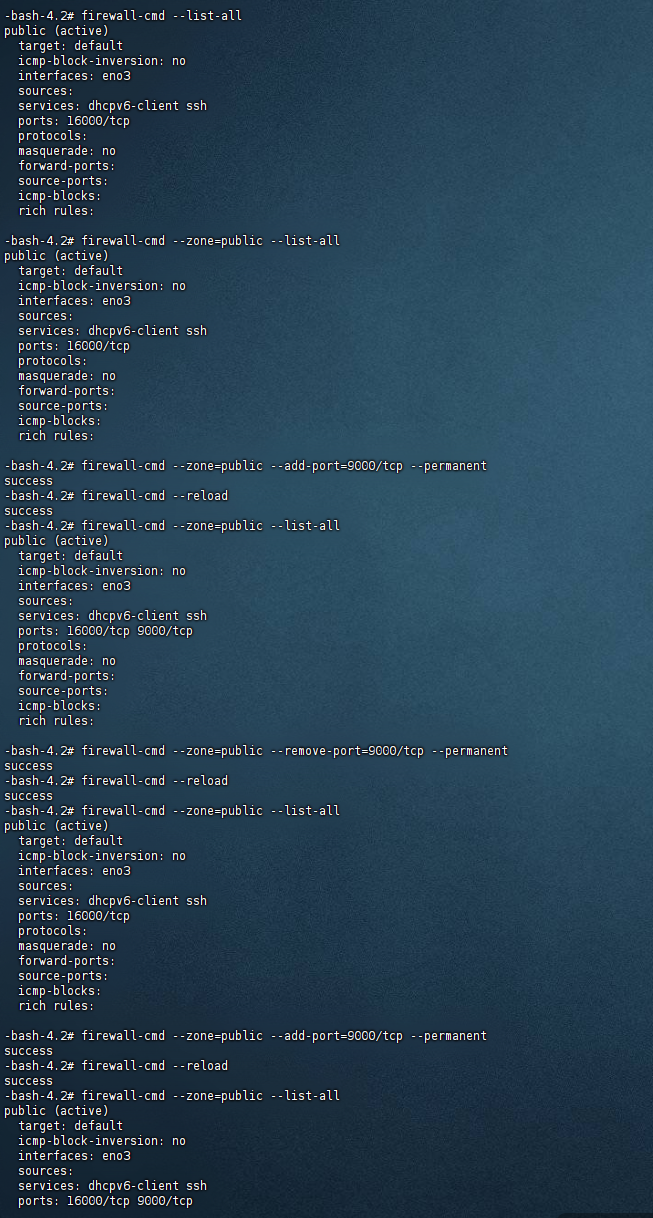
部署JVS服务出现上传文件不可用,问题原因排查。
事情的起因是这样的,部门经理让我部署一下JVS资源共享框架,项目的地址是在这里 项目资源地址 各位小伙伴们做好了,我要开始发车了,全新的“裂开之旅” 简单展示一下如何部署JVS文档 直达链接 撕裂要开始了 本来服务启动的好好…...

机器视觉检测为什么是工业生产的刚需?
机器视觉检测在工业生产中被视为刚需,主要是因为它具备以下几个关键优势: 提高精度与效率:机器视觉系统可以进行高速、高精度的检测。这对于保证产品质量、减少废品非常关键。例如,在生产线上,机器视觉可以迅速识别产品…...
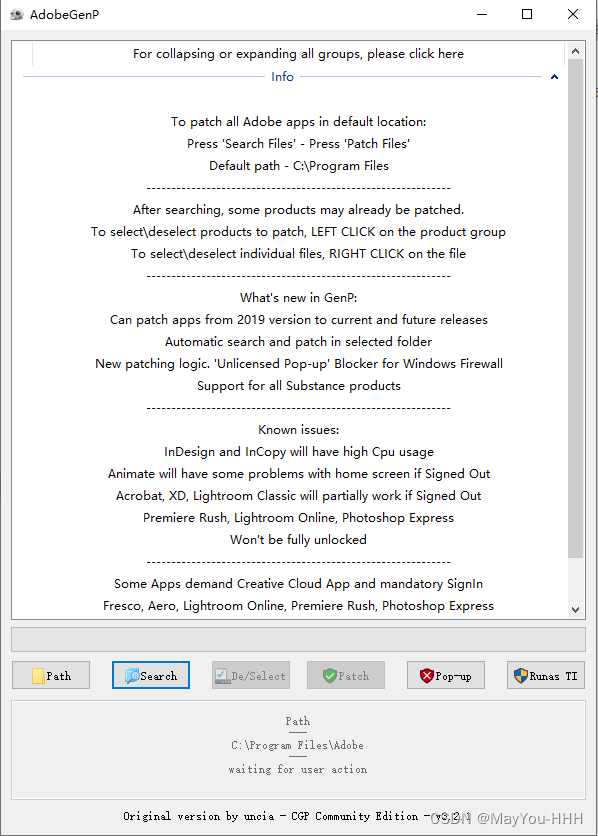
Adobe系列软件安装
双击解压 先运行Creative_Cloud_Set_Up.exe。 完毕后,运行AdobeGenP.exe 先Path,选路径,如 C:\Program Files\Adobe 后Search 最后Patch。 关闭软件,修图!...
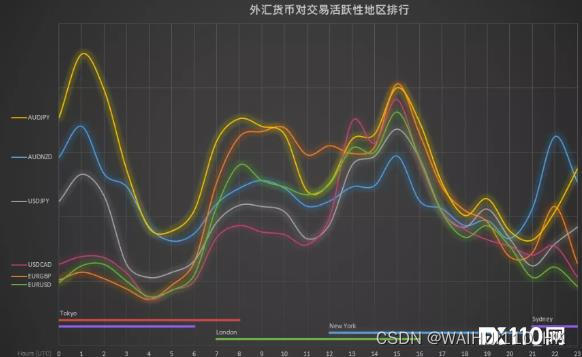
【FX110】2024外汇市场中交易量最大的货币对是哪个?
作为最大、最流动的金融市场之一,外汇市场每天的交易量高达几万亿美元,涉及到数百种货币。不同货币对的交易活跃程度并不一样,交易者需要根据货币对各自的特点去进行交易。 全年外汇市场中涉及美元的外汇交易超过50%! 实际上&…...
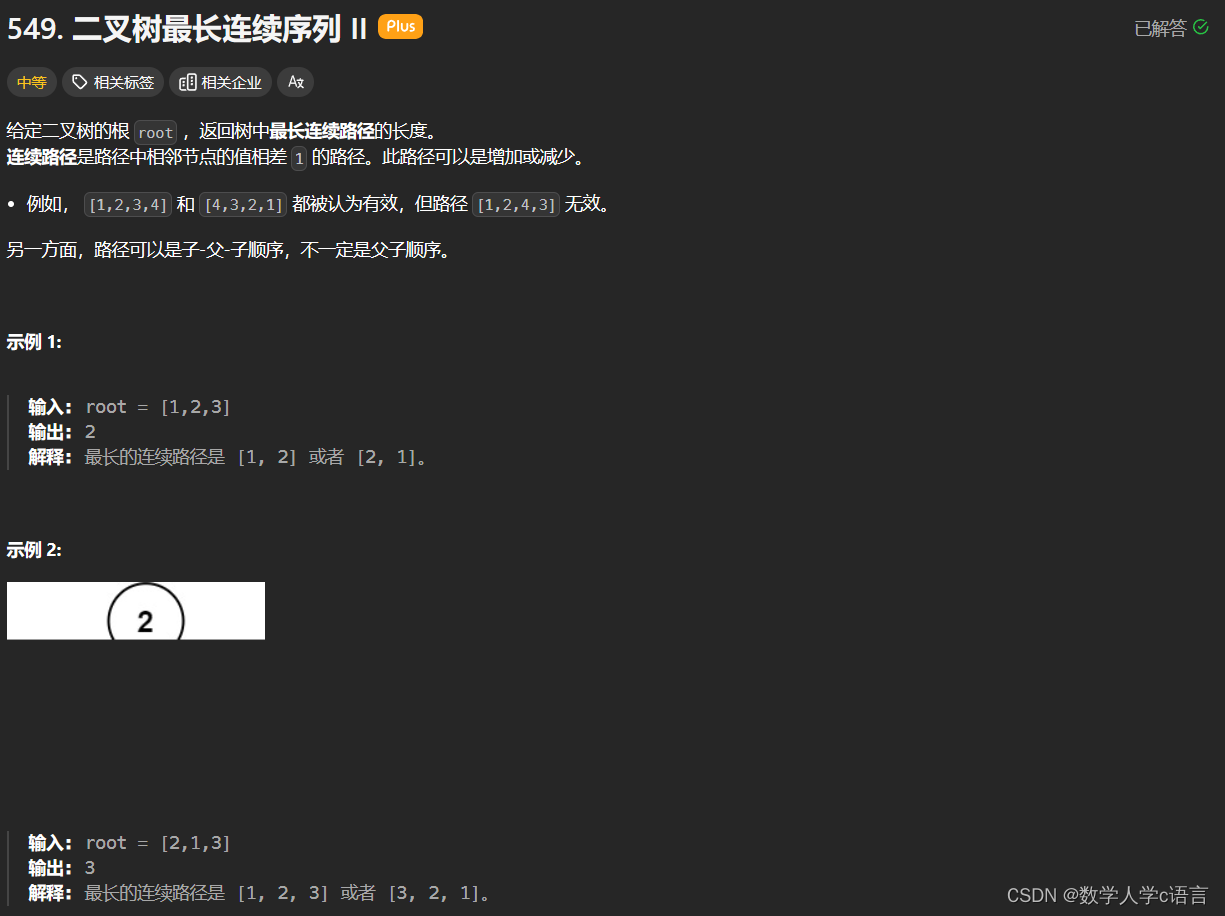
leetcode尊享面试100题(549二叉树最长连续序列||,python)
题目不长,就是分析时间太久了。 思路使用dfs深度遍历,先想好这个函数返回什么,题目给出路径可以是子-父-子的路径,那么1-2-3可以,3-2-1也可以,那么考虑dfs返回两个值,对于当前节点node来说&…...

C#面试题: 寻找中间值
给定一个数组,在区间内从左到右查找中间值,每次查找最小值与最大值区间内的中间值,且这个区间元素数量不小于3。 例如 1.给定数组float[] data { 1, 2.3f, 4, 5.75f, 8.125f, 10.5f, 13, 15, 20 } 输出:10.5、5.75、4、2.3、8…...
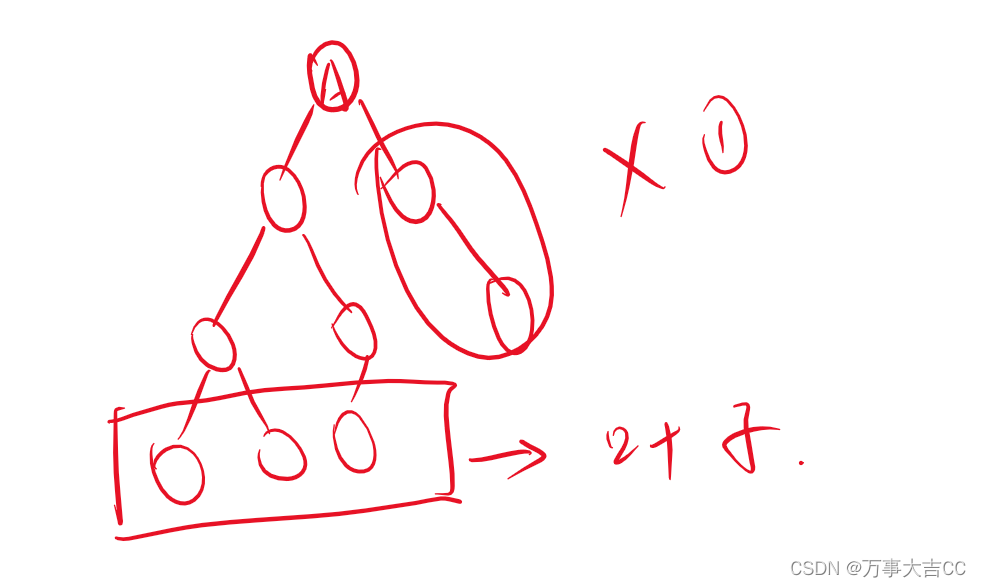
987: 输出用先序遍历创建的二叉树是否为完全二叉树的判定结果
解法: 一棵二叉树是完全二叉树的条件是: 对于任意一个结点,如果它有右子树而没有左子树,则这棵树不是完全二叉树。 如果一个结点有左子树但是没有右子树,则这个结点之后的所有结点都必须是叶子结点。 如果满足以上条…...

13:HAL---SPI
目录 一:SPL通信 1:简历 2:硬件电路 3:移动数据图 4:SPI时序基本单元 A : 开/ 终条件 B:SPI时序基本单元 A:模式0 B:模式1 C:模式2 D:模式3 C:SPl时序 A:发送指令 B: 指定地址写 C:指定地址读 5:NSS(CS) 6:时钟 二: W25Q64 1:简历 2…...

【技术实战】从ATE测试平台构建到电源芯片动态性能精准评估
1. ATE测试平台基础搭建指南 第一次接触ATE(Automatic Test Equipment)时,我和很多工程师一样被它的复杂配置吓到。但实际拆解后发现,搭建测试平台就像组装乐高积木,关键是要理解每个模块的作用。以我们测试Buck电源芯…...

信号净化实战:从基础平滑到智能去噪
1. 信号净化入门:为什么我们需要处理噪声? 第一次接触传感器数据时,我被现实狠狠上了一课——实验室里漂亮的平滑曲线在真实场景中根本不存在。记得去年处理工厂振动传感器数据时,原始信号看起来就像心电图叠加了摇滚乐节奏。这种…...

用STC89C52单片机+ADC0832做个智能台灯:手把手教你实现PWM调光和光敏自动控制
从零打造智能台灯:STC89C52与ADC0832的完美结合 记得第一次在宿舍熬夜赶项目时,刺眼的台灯总让我眼睛酸涩不已。那时我就在想,如果能有一个能自动调节亮度的台灯该多好。今天,我们就用STC89C52单片机和ADC0832模数转换器ÿ…...
CircuitPython实战:用传感器数据驱动NeoPixel灯光效果
1. 项目概述如果你刚拿到一块像Adafruit Circuit Playground Express这样的开发板,看着上面一圈彩色的NeoPixel LED和一堆传感器,可能会有点无从下手。别担心,这几乎是每个嵌入式开发者的必经之路。这块板子集成了光传感器、温度传感器、加速…...

开源法律知识库:结构化数据驱动法律科技应用
1. 项目概述:一个法律领域的开源知识库最近在整理一些法律相关的资料时,发现了一个挺有意思的开源项目,叫mileson/moticlaw。乍一看这个名字,可能会有点摸不着头脑,但如果你对法律科技或者开源社区有所关注,…...

fastmod vs codemod:为什么你应该选择这个更快的代码替换工具
fastmod vs codemod:为什么你应该选择这个更快的代码替换工具 【免费下载链接】fastmod A fast partial replacement for the codemod tool. Assists with large-scale codebase refactors via regex-based find and replace with human oversight and occasional i…...

国产信创电脑是什么意思?为什么政府和企业都在用?
国产信创电脑——这个名词虽然听起来有些陌生,但它正在深刻影响着我们的工作和生活。从政府采购到企业信息化方案,再到科技媒体的报道,“国产信创电脑”已经成为了关键词之一。那么,它究竟是什么?为什么如此重要&#…...

2026 最新 6 款漏洞扫描工具!一篇全覆盖
渗透测试收集信息完成后,就要根据所收集的信息,扫描目标站点可能存在的漏洞了,包括我们之前提到过的如:SQL注入漏洞、跨站脚本漏洞、文件上传漏洞、文件包含漏洞及命令执行漏洞等,通过这些已知的漏洞,来寻找…...
)
千问 LeetCode 2402.会议室 III public int mostBooked(int n, int[][] meetings)
这道题是经典的会议室 III,核心是双堆模拟,一个堆管空闲会议室(按编号排序),一个堆管正在使用的会议室(按结束时间排序)。解题思路1. 排序:按会议开始时间升序排列。 2. 双堆初始化&…...

7种智能提取方案深度解析:网盘直链下载助手的跨平台文件管理革命
7种智能提取方案深度解析:网盘直链下载助手的跨平台文件管理革命 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云…...