2024数维杯数学建模选题建议及各题思路来啦!
大家好呀,2024数维杯数学建模挑战赛开始了,来说一下初步的选题建议吧:
首先定下主基调,
本次数维杯建议选B。难度上C>A>B。B题目是比较经典的数据分析类题目,主要做统计分析差异显著性以及相关性,此外还有优化和机器学习预测的两个小问,求解思路很确定,整体也可以做不少可视化,获奖概率会高很多,大家到时候直接运行我给的python代码即可,不需要你配环境,我会录制怎么运行的视频,无脑运行,很简单。
精力有限,以下只是简略的图文版初步思路,更详细的视频版完整讲解请移步:
2024数维杯数学建模挑战赛选题建议及ABC题详细思路!_哔哩哔哩_bilibili
OK,接下来讲一下ABC题的思路。
数维杯思路
A题 多源机会信号建模与导航分析
1. 结合题目信息与数据,建立机会信号的数学表达式。同时,针对每一类机会信号,讨论能够唯一确定飞行器位置的最少的机会信号个数。
2. 根据附件 1 的接收情况 1 数据,不考虑数据偏差的情况下(认为所有数据可信),请设计飞行器实时位置的估计方法,并给出飞行器 0 秒至 10 秒的导航定位结果(实时的位置估计值)。
3. 在附件 1 的接收情况 1 数据中,某些机会信号可能有较大的偏差,请建立机会信号的实时筛选方法,筛选出偏差较大的机会信号。根据建立的机会信号筛选方法,给出此时飞行器 0 秒至 10 秒的导航 定位情况。
4. 机会信号的偏差可以分为两种,一种是随机性偏差(零均值), 一种是常值飘移。请建立评价判断方法,并依据所提出方法,判断接 收情况 2 中的机会信号的随机性偏差程度以及常值飘移量。设计合理 的机会信号筛选方法,给出接收情况 2 下的飞行器 0 秒至 10 秒的定位结果
问题一:建立机会信号的数学表达式,并讨论确定飞行器位置的最少机会信号个数

问题二:设计飞行器实时位置的估计方法,并给出飞行器0秒至10秒的导航定位结果
建模思路:
1. 数据融合:使用如卡尔曼滤波器等算法综合不同机会信号,估计飞行器的位置。
2. 实时定位算法:开发一个算法,利用接收到的连续信号数据,实时计算飞行器的位置。
结合TOA, TDOA, 和AOA的测量结果使用多边测量方法。可以使用非线性最小二乘法来解决这些方程,以找到最佳的飞行器位置估计。
3. 导航结果:模拟0秒至10秒间飞行器的导航路径,使用预设的信号数据进行验证。
问题三:建立机会信号的实时筛选方法,筛选出偏差较大的机会信号
建模思路:
1. 偏差分析:对接收到的信号进行统计分析,如计算平均值和标准偏差。
2. 筛选算法:设定阈值,筛选出超出正常范围的信号数据,可能包括噪声或错误数据。
问题四:机会信号的偏差可以分为随机性偏差和常值飘移,请建立评价判断方法
建模思路:
1. 随机性偏差分析:使用统计方法如方差和标准偏差来评估信号的随机性偏差。
2. 常值飘移分析:分析信号随时间的变化趋势,确定是否存在常值飘移。常值飘移可以通过比较长时间内信号的平均偏移来评估。
3. 判断和筛选方法:根据上述分析结果,开发一套标准化的评价和筛选流程。
B题 生物质和煤共热解问题的研究
请通过数学建模完成下列问题:
(1)基于附件一,请分析正己烷不溶物(INS)对热解产率(主要考虑焦油产率、水产率、焦渣产率)是否产生显著影响?并利用图像加以解释。
(2)热解实验中,正己烷不溶物(INS)和混合比例是否存在交互效应,对热解产物产量产生重要影响?若存在交互效应,在哪些具体的热解产物上样品重量和混合比例的交互效应最为明显?
(3)根据附件一,基于共热解产物的特性和组成,请建立模型优化共解热混合比例,以提高产物利用率和能源转化效率。
(4)根据附件二,请分析每种共热解组合的产物收率实验值与理论计算值是否存在显著性差异?若存在差异,请通过对不同共热解组合的数据进行子组分析,确定实验值与理论计算值之间的差异在哪些混合比例上体现?
(5)基于实验数据,请建立相应的模型,对热解产物产率进行预测。
问题1:正己烷不溶物对热解产率的影响分析
建模思路
1. 数据分析:首先分析附件一中的正己烷不溶物(INS)的数据,与不同热解产率(焦油产率、水产率、焦渣产率)的相关性。
2. 统计检验:使用相关性分析(如皮尔逊相关系数)来确定INS和不同产率之间的相关性大小。
3. 可视化:绘制散点图和回归线,展示INS量与热解产率的关系,用以直观表达INS的变化如何影响产率。
4. 模型建立:如果存在显著相关性,考虑建立回归模型来描述这种关系,预测INS变化对热解产率的影响。
问题2:正己烷不溶物和混合比例的交互效应
建模思路
1. 交互效应分析:利用多元回归分析,将INS和混合比例以及它们的交互项作为自变量,热解产物产率作为因变量进行分析。
2. 模型验证:进行ANOVA(方差分析)来检验模型的显著性,特别是交互项的显著性。
3. 结果解释:解释模型中交互项的系数,确定在哪些热解产物上INS和混合比例的交互效应最为明显。
问题3:优化共解热混合比例
建模思路
1. 响应面方法:使用实验设计的响应面分析方法,建立生物质与煤的混合比例与热解产物产率之间的数学模型。
2. 优化算法:利用建立的模型,通过算法(如梯度下降法或遗传算法)来找到最优的混合比例,以最大化产物的产率和质量。
3. 模型验证与调整:通过交叉验证等方法评估模型的预测能力,并根据实际数据调整模型参数。
问题4:实验值与理论计算值的显著性差异
建模思路
1. 差异分析:先通过统计测试(如t-test或ANOVA)比较不同共热解组合的产物收率实验值和理论值的差异。
2. 子组分析:如果存在显著差异,再进行更详细的子组分析,以确定在哪些混合比例上实验值与理论值之间存在显著差异。
问题5:预测热解产物产率
建模思路
1. 数据建模:根据实验数据,使用适合的机器学习方法(如随机森林、支持向量机等)建立热解产物产率的预测模型。
2. 特征工程:分析和选择影响热解产率的关键因素作为模型输入。
3. 模型优化:通过调整模型参数和使用模型选择技术来优化模型性能。
4. 模型评估:通过交叉验证等方法评估模型的预测性能,并根据实际应用需求调整模型,以达到最佳的预测效果。
C题 天然气水合物资源量评价
为了研究某海域天然气水合物分布情况,地质资源勘探部门在该地区选择了 14 个位置进行钻孔勘探,在每个钻孔有深度信息和在对应深度的测量的孔隙度和天然气水合物饱和度信息。试根据所给勘探数据研究以下问题:
1)根据附件勘探井位信息确定天然气水合物资源分布范围;
2)确定研究区域内天然气水合物资源参数有效厚度、地层孔隙度和饱和度的概率分布及其在勘探区域内的变化规律;
3)请给出天然气水合物资的概率分布,以及估计天然气水合物资源量。
4) 为了对本区域储量有个更精细勘查结果,拟在本区域再增加 5 口井,问如何安排井位?
问题一:确定天然气水合物资源分布范围
建模思路
1. 数据集成:首先整合附件中的勘探井位信息,包括每个勘探点的地理位置和地质数据。
2. 空间插值:使用地理信息系统(GIS)技术,通过插值方法估计未勘探区域的天然气水合物的可能存在。
3. 资源分布模型:构建一个空间统计模型,如克里金或反距离权重(IDW),来确定整个研究区域内的天然气水合物分布范围。
问题二:确定资源参数的概率分布及其变化规律
建模思路
1. 参数统计分析:对有效厚度、地层孔隙度和饱和度数据进行描述性统计分析,包括均值、方差、偏度等。
2. 概率分布拟合:使用概率分布测试(如Kolmogorov-Smirnov测试)来确定这些参数的最佳理论分布(如正态分布、对数正态分布等)。
3. 空间变异性分析:应用地统计学方法,如变异函数分析,来研究这些参数在空间上的变化规律。
问题三:估计天然气水合物资源量的概率分布
建模思路

2. 概率分布模拟:根据上述参数的概率分布,使用蒙特卡洛模拟来生成天然气水合物资源量的概率分布。
3. 不确定性分析:分析和报告资源量估计的不确定性,提供置信区间或预测区间。
问题四:安排新增钻井的位置
建模思路
1. 地质信息最大化:选择在地质信息稀缺或变异性高的区域新增钻井,以增加资源评估的准确性和减少不确定性。
2. 优化模型:运用优化技术,如遗传算法或模拟退火,找出在满足技术和经济条件下,能最大化信息增益的井位配置。
3. 决策支持系统:可能还需要构建一个支持多目标决策的模型,考虑成本、预期收益和技术可行性。
OK,上述思路的文档领取、视频讲解以及后续的完整成品论文预定请点击我的下方个人卡片查看↓::
相关文章:
2024数维杯数学建模选题建议及各题思路来啦!
大家好呀,2024数维杯数学建模挑战赛开始了,来说一下初步的选题建议吧: 首先定下主基调, 本次数维杯建议选B。难度上C>A>B。B题目是比较经典的数据分析类题目,主要做统计分析差异显著性以及相关…...

centos的常用命令
CentOS是一个基于Red Hat Enterprise Linux(RHEL)的开源操作系统,常用于服务器环境。以下是一些CentOS中常用的命令: 文件和目录管理: ls:列出目录中的文件。 ls -l:以长格式列出文件和目录的…...

【Android】使用Handler实现一个定时器
需求 实现一个定时任务,每隔一秒执行一次 实现 使用Handler实现 private Handler topUIHandler;private void initTopUiHandler() {topUIHandler new Handler(getMainLooper()) {Overridepublic void handleMessage(Message msg) {//执行这个定时任务updateTop…...

Java | Leetcode Java题解之第80题删除有序数组中的重复项II
题目: 题解: class Solution {public int removeDuplicates(int[] nums) {int n nums.length;if (n < 2) {return n;}int slow 2, fast 2;while (fast < n) {if (nums[slow - 2] ! nums[fast]) {nums[slow] nums[fast];slow;}fast;}return sl…...

java后端15问!
前言 最近一位粉丝去面试一个中厂,Java后端。他说,好几道题答不上来,于是我帮忙整理了一波答案 G1收集器JVM内存划分对象进入老年代标志你在项目中用到的是哪种收集器,怎么调优的new对象的内存分布局部变量的内存分布Synchroniz…...

OmniPlan Pro 4 for Mac中文激活版:项目管理的新选择
OmniPlan Pro 4 for Mac作为一款专为Mac用户设计的项目管理软件,为用户提供了全新的项目管理体验。其直观易用的界面和强大的功能特性,使用户能够轻松上手并快速掌握项目管理要点。 首先,OmniPlan Pro 4 for Mac支持自定义视图,用…...

二叉树的广度优先遍历 - 华为OD统一考试(D卷)
OD统一考试(D卷) 分值: 200分 题解: Java / Python / C++ 题目描述 有一棵二叉树,每个节点由一个大写字母标识(最多26个节点)。 现有两组字母,分别表示后序遍历(左孩子->右孩子->父节点)和中序遍历(左孩子->父节点->右孩子)的结果,请输出层次遍历的结…...
代码随想录-算法训练营day31【贪心算法01:理论基础、分发饼干、摆动序列、最大子序和】
代码随想录-035期-算法训练营【博客笔记汇总表】-CSDN博客 第八章 贪心算法 part01● 理论基础 ● 455.分发饼干 ● 376. 摆动序列 ● 53. 最大子序和 贪心算法其实就是没有什么规律可言,所以大家了解贪心算法 就了解它没有规律的本质就够了。 不用花心思去研究其…...
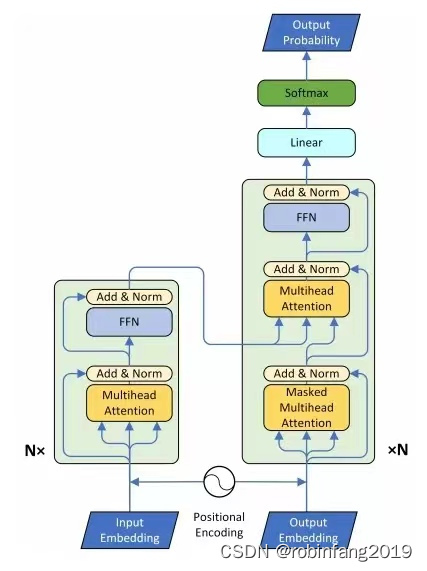
如何使用Transformer-TTS语音合成模型
1、技术原理及架构图 Transformer-TTS主要通过将Transformer模型与Tacotron2系统结合来实现文本到语音的转换。在这种结构中,原始的Transformer模型在输入阶段和输出阶段进行了适当的修改,以更好地处理语音数据。具体来说,Transformer-TT…...

【Python】JSON数据的使用
一、JSON JSON是什么: JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它以易于理解和生成的文本格式来描述数据对象。JSON最初是由Douglas Crockford在2001年提出的,它的设计受到了JavaScript对象字面量…...

C语言头文件的引入使用<>和““有什么区别
在C语言中,引入头文件时使用<>和""有以下主要区别: 搜索路径不同: 当使用#include <filename.h>时,编译器会首先在系统目录中搜索头文件。这些系统目录通常包含了标准库的头文件,如stdio.h、std…...

Qt 类的设计思路详解
Qt 是一个跨平台的 C++ 应用程序开发框架,它提供了丰富的类库和工具,用于开发图形用户界面、网络应用、数据库集成和文件 I/O 等功能。Qt 的设计思路涉及到诸多方面,包括跨平台性、模块化、可扩展性、性能等。本文将从这些方面详细说明 Qt 类的设计思路。 1. 跨平台性 Qt 最…...

五一超级课堂---Llama3-Tutorial(Llama 3 超级课堂)---第一节 Llama 3 本地 Web Demo 部署
课程文档: https://github.com/SmartFlowAI/Llama3-Tutorial 课程视频: https://space.bilibili.com/3546636263360696/channel/collectiondetail?sid2892740&spm_id_from333.788.0.0 操作平台: https://studio.intern-ai.org.cn/consol…...

Redis20种使用场景
Redis20种使用场景 1缓存2抽奖3Set实现点赞/收藏功能4排行榜5PV统计(incr自增计数)6UV统计(HeyperLogLog)7去重(BloomFiler)8用户签到(BitMap)9GEO搜附近10简单限流11全局ID12简单分…...

vue3获取原始值
在 Vue 3 中,_rawValue 是 ref 内部的一个属性,它用来存储 ref 的原始值,也就是未经响应式处理的值。这个属性主要用于 Vue 的内部逻辑,以帮助区分 ref 的当前值 (value) 和原始输入值 (_rawValue)。对于大多数开发者来说…...
“感恩遇到你,郭护士!”佛山市一医院 护士回家途中救了位老奶奶
“感恩遇见你,我感谢郭护士关爱长者、热心助人的高尚行为……”看着信件上感谢的话语,郭琳玲的内心感动不已。而这一封亲笔手写的感谢信,是来自一位将近八十岁的老奶奶。 郭琳玲是佛山市第一人民医院创伤重症功能神经外科的一名护士。4月30日…...

Java面试常见问题
操作系统 1.Q: 在操作系统中,什么时候会发生用户态到内核态的切换 A: 操作系统中,用户态和内核态是两种不同的权限级别,他们对应着不同的执行环境和执行权限。用户态事指程序在一般的运行情况下的的级别,它具有别较低的权限级别&…...
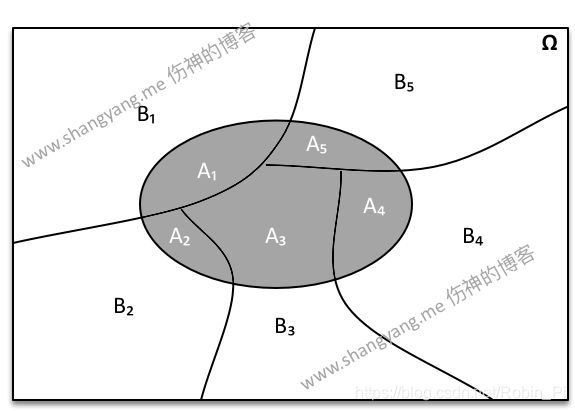
概率论 科普
符号优先级 概率公式中一共有三种符号:分号 ; 、逗号 , 、竖线 | 。 ; 分号代表前后是两类东西,以概率P(x;θ)为例,分号前面是x样本,分号后边是模型参数。分号前的 表示的是这个式子用来预测分布的随机变量x,分号后的…...
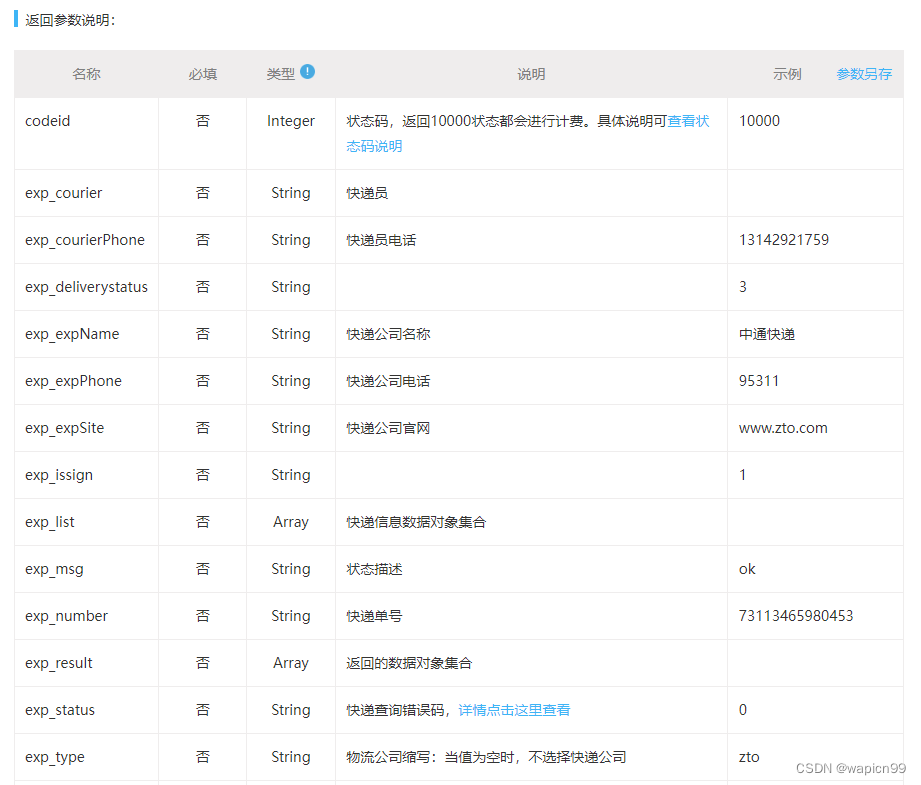
全面解读快递查询API接口,帮你轻松查询快递物流信息
随着电子商务的快速发展,快递业务正变得越来越重要。无论是买家还是卖家,都希望能够及时了解自己的快递物流信息,以便更好地掌控商品的运输过程。而现在,通过快递查询API接口,我们可以实现快速、准确地查询几百家国内快…...

【图书推荐】《JSP+Servlet+Tomcat应用开发从零开始学(第3版)》
本书目的 系统讲解JSPServletTomcat开发技术,帮助读者用最短的时间掌握Java Web应用开发技能。 内容简介 本书全面系统地介绍JSPServletTomcat开发中涉及的相关技术要点和实战技巧。本书内容讲解循序渐进,结合丰富的示例使零基础的读者能够熟练掌握JSP…...

终极指南:Windows平台APK安装器如何让安卓应用无缝运行
终极指南:Windows平台APK安装器如何让安卓应用无缝运行 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在Windows电脑上运行安卓应用曾经是一个技术难题&am…...

SmarterRouter:基于软件定义与模块化构建智能路由器系统
1. 项目概述:一个更聪明的路由器,它到底想做什么?如果你和我一样,折腾过家里的网络,从刷第三方固件到组软路由,那你肯定对“路由器”这三个字有复杂的感情。它本该是默默无闻的网络基石,却常常因…...

3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验
3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验 【免费下载链接】TaskbarX Center Windows taskbar icons with a variety of animations and options. 项目地址: https://gitcode.com/gh_mirrors/ta/TaskbarX 你是否厌倦了Windows任务栏图标总是靠左…...

UEFITool深度解析:实战指南与高效使用技巧
UEFITool深度解析:实战指南与高效使用技巧 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool UEFITool是一款专为UEFI固件分析设计的开源工具,能够将复杂的二进制固件映像…...

Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行
Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为macOS软件安装更新而烦恼吗?…...

JetBrains IDE试用期重置终极指南:3种简单方法实现30天无限续杯
JetBrains IDE试用期重置终极指南:3种简单方法实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否在使用IntelliJ IDEA、PyCharm、WebStorm等JetBrains IDE时遇到过试用期突然结束…...

飞书自动化脚本开发指南:从API集成到智能审批机器人实战
1. 项目概述:飞书自动化,从“手动”到“自动”的效能革命 如果你每天的工作,有超过30%的时间是在飞书里重复点击、复制粘贴、手动发送消息和整理表格,那么“cicbyte/feishu-atuo”这个项目,很可能就是你一直在寻找的“…...

自托管链接管理平台Linko:Go+React技术栈部署与核心功能解析
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫monsterxx03/linko。乍一看这个名字,可能有点摸不着头脑,但如果你经常需要管理一堆链接、书签,或者在做内容聚合、个人知识库,那这个工具很可能就是你一直在…...

Lua-RTOS-ESP32:用脚本语言快速开发物联网硬件的实践指南
1. 项目概述:当Lua遇上RTOS,在ESP32上构建轻量级物联网开发新范式如果你是一名嵌入式开发者,或者对物联网(IoT)设备编程感兴趣,那么你一定对ESP32这颗明星芯片不陌生。它凭借强大的双核处理能力、丰富的无线…...
CircuitPython与NeoPixel实战:从硬件连接到动态灯光效果
1. 项目概述:用Python点亮你的硬件创意如果你玩过Arduino,可能会觉得C/C的语法和库管理有点门槛;如果你熟悉Python,又觉得它和硬件之间隔着一层纱。那么,当Raspberry Pi Pico这块性价比极高的微控制器,遇上…...