大模型LLM之SFT微调总结
一. SFT微调是什么
-
在大模型的加持下现有的语义理解系统的效果有一个质的飞跃;相对于之前的有监督的Pre-Train模型;大模型在某些特定的任务中碾压式的超过传统nlp效果;由于常见的大模型参数量巨大;在实际工作中很难直接对大模型训练适配特定的任务
-
SFT (Supervised fine-tuning) 有监督微调 意味着使用有标签的数据来调整一个已预训练好的语言模型(LLM)使其更适应某一特定任务;通常LLM的预训练是无监督的,但微调过程往往是有监督的
-
在大模型应用中,SFT指令微调已成为预训练大模型在实际业务应用最重要的方式。众多垂直领域模型,都是在预训练模型的基础上,通过针对性的SFT指令微调,更好地适应最终任务和对齐用户偏好;现有的对话系统或者推荐系统中有较多的语义理解任务需要进行指令微调
-
SFT主要是激发模型在预训练中已学到的知识、让模型学习业务所需要的特定规则、以及输出格式稳定下文中会给出具体的例子
二、SFT微调的方案
-
参数高效微调(PEFT) Prefix/Prompt-Tuning,Adapter-Tuning、P-Tuning、LoRA、QLoRA
-
优点:轻量化,低资源
-
缺点:模型参与训练参数较少,部分任务微调效果可能会不及预期
-
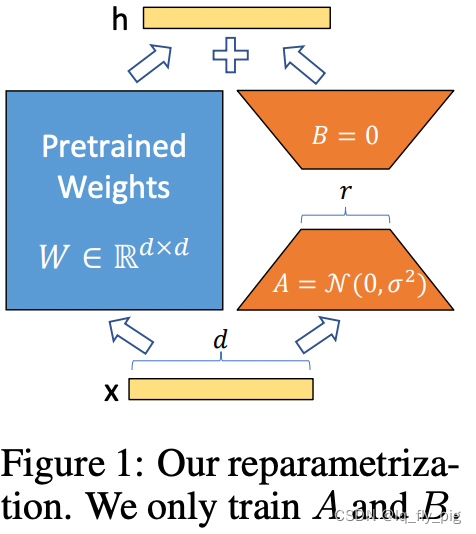
LoRA原理
-
低秩分解来模拟参数的改变量,使用比较小的参数来实现大模型的间接的训练
-
原始的PLM旁边增加一个新的通路,通过A矩阵和B矩阵进行相乘
-
第一个A矩阵进行降低维度,第二个矩阵B进行升维度,中间层维度为r
-
维度d经过fc 降低到r ,再从r 映射到d (其中 r << d)
-
矩阵的计算就是从 dxd 变成 dxr + rxd (参数量减少很多)
-
在下游任务训练时,固定模型的其他参数,只优化新增的两个矩阵的权重参数,将PLM跟新增的通路两部分的结果加起来作为最终的结果(两边通路的输入跟输出维度是一致的),即h=Wx+BAx
-
第一个矩阵的A的权重参数会通过高斯函数初始化,而第二个矩阵的B的权重参数则会初始化为零矩阵,这样能保证训练开始时新增的通路BA=0从而对模型结果没有影响
-
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原本PLM的W即可,对于推理来说,不会增加额外的计算资源
-

-

-
-
LoRA微调相关代码请参考https://github.com/hiyouga/LLaMA-Factory
-
三、SFT微调的训练心得经验
-
遇到的困难和挑战
-
SFT数据从0到1构建,怎么获取挖掘线上的badcase,补充筛选SFT高质量的数据
-
NLG过程中的幻觉 大模型的胡编乱造
-
prompt的效果迭代和Lora微调的超参数的调试
-
实际项目落地时候模型的推理加速(eg:大模型的量化手段、流量请求时候的预剪枝,减少大模型的请求)
-
-
效果优化思路
-
pompt的迭代
-
prompt优化主要在训练阶段,用于增强指令的多样性,让模型更好的理解指令
-
预测阶段的prompt优化主要用于无法进行finetune的场景,在开源的基座大模型上进行适配
-
对于特定下游任务,预测阶段建议与训练阶段保持一致或者接近的prompt
-
适当构建few shot 及COT(Chain of Thought) 数据加入训练,可以有助于模型的指令理解
-
-
prompt的例子
输入是:打开音乐和空调并帮我播放我喜欢的歌曲 输出是: 打开音乐、打开空调、播放我喜欢的歌曲
-
实际工作中的心得体会
-
prompt尽量给出指定模型扮演的角色,比如nlu理解任务时候说是语音助手,泛化数据的时候是语言大师等等
- 越详细越好,给到的定义越细越好,需要给出关于任务需求的详细信息,比如上面的分句改写任务,需要定义例子的输入和输出,给出详细的例子,还有嘱咐清楚
-
针对任务给出几个示例,符合few-shot 过程,有助于模型的很好理解;使用分隔符清晰的区分输入的不同部分
-
建立惩罚机制,比如 做错了扣分,不要胡编乱造等等
-
prompt中可以尝试让大模型step by step的先思考再决策提升效果
-
-
结论
-
结合ICL上下文学习,在prompt中加入输入输出对,让LLM能够通过理解这些演示样例去进行预测。
-
在prompt里增加一些角色信息相关的内容,让 AI 生成的内容更符合我们的需求。
-
输出格式尽可能是json、xml等等这样的结构化数据;便于后续的结果的解析和输出
-
优质Prompt能够提高模型的精度。通过精心设计的提示词或问题,可以引导模型关注到输入文本的关键信息,从而减少误判和误差
-
优质Prompt能够提高模型的泛化能力。在面对未曾训练过的场景时,优质Prompt可以帮助模型更好地适应新环境,减少过拟合现象
-
优质Prompt能够提高模型的可解释性。通过分析优质Prompt的输出结果,我们可以更好地理解模型的决策过程和推理逻辑,从而更好地评估模型的效果和可靠性
-
-
版本2
'你是一个专业的车载语音助手,任务是协助处理用户的文本输入,并将其抽取为触发条件conditions和执行指令actions两项内容 \你需要遵循下列这些注意事项 \ 1. 触发条件代表执行指令执行的触发时机,如果用户输入中不包含这部分,则不用输出conditions\ 2. 执行指令代表用户下达的执行指令,文本输入中一定包含这部分内容。 \ 3. 用户输入中可能会包含多个触发条件和执行指令,请仔细做好内容的识别和拆分,并以JSON格式输出 \ 4. 用户输入是由语音识别转写而来的,可能口语化、重复啰嗦等问题,在不影响语义的情况下,请把触发条件conditions中的`时`,`的时候`之类的词语,以及执行指令actions中的语气词、连词去掉(如`还有`,`同时`,`请帮我`等等),保证抽取结果尽量精简。 \ 5. 处理文本时应遵循用户的意图,不能编造和虚构不存在的内容;不需要解释和过程,严格按照示例的输出形式给出结果。如果输出指令不正确,则你将会被扣分! \下面是4个示例的输入输出:\ 输入:上车的时候自动播放QQ音乐 \ 输出:{"conditions":["上车"], "actions":["播放QQ音乐"]} \输入:每周五晚上下班时帮我导航回杭州的家调节空调再让NOMI给我周末的问候 \ 输出:{"conditions":["每周五晚上", "下班"], "actions":["导航回杭州的家", "调节空调", "播报周末的问候"]} \输入:打开车窗和空调还有香氛关闭阅读灯还有车门 \ 输出:{"actions":["打开车窗", "打开空调", "打开香氛", "关闭阅读灯", "关闭车门"]} \输入:打开座椅加热和通风再帮我设置导航目的地为人民广场 \ 输出:{"actions":["打开座椅加热", "打开座椅通风", "设置导航目的地为人民广场"]} \----示例结束---- \ 请你协助处理下面这一条用户输入,并直接给出JSON形式的输出 \ 输入:%s \ 输出:' % query -
版本1
经过多次效果迭代,版本2相对比版本1中的prompt,大模型的效果提升2%'你是智能车载语音助手机器人,你的任务是,基于用户输入的文本进行分句和改写需要把输入文本中多个意图的句子切分开,用逗号分隔,如果文本中没有多个意图的话,那就不需要进行切分。以下是需要进行切分和改写的句子:%s' % query
-
-
PEFT微调LoRA超参数的迭代
-
学习率设置
- 学习率是一个非常重要的参数 ,如果学习率设置不当,很容易让你的SFT模型效果较差。SFT数据集不是特别大的情况下,建议设置较小学习率,一般设置为pre-train阶段学习率的0.1左右,如在pre-train阶段的学习率为3e-4,则SFT学习率设置为3e-5
- warmup_ratio
- 通常pre-train训练的warmup_ratio 0.01~0.015之间,warmup-steps在2000左右。在SFT的时候,建议使用更小的ratio,因为相较于pre-train,SFT样本非常小,较小warmup_ratio可以使模型收敛更平滑。但如果你的学习率设置较大,那可以增大你的warmup_ratio,两者呈正相关
-
-
-
四、总结
-
SFT的主要是使用于领域相关能力的增强,如果通过大模型通用能力,例如embedding、prompt提取、Lang Chain等知识库的形式可以解决的,没有必要再进行SFT微调
-
通用大模型泛化性好,精度不够,SFT后的模型领域体验更佳,两者可能是并行存在较好
-
SFT中仅使用领域数据,会导致通用能力下降以及安全相关回复能力的下降甚至丢失,因此需要人工梳理,增加数据的多样性的同时并把握好SFT数据的质量,质量非常重要
-
SFT不要训练较多轮次,比如10万个样本2-3个epoch内为佳,2~5万个样本 一般是4-5个 epoch 并且领域增强的SFT数据不需要太多,质量一定要把握好,一般的领域总结回复的任务几百条数据即可( 个人经验 ),视情况而定;小数据量可以适当增大epoch,让模型充分收敛。
-
通用数据和领域数据增加数据之间的比例(7:1)左右
-
SFT数据质量的筛选数据质量可以通过ppl、reward model,文本质量分类模型等方式进行初步评估。经过人工进行后续筛选
-
过高的epoch可能会带来通用NLP能力的遗忘,需要根据实际需求核定,若您只需要下游能力提升,则通用NLP能力的略微下降影响不大
五、相关refer
-
https://zhuanlan.zhihu.com/p/692892489
-
https://zhuanlan.zhihu.com/p/635791164
-
https://zhuanlan.zhihu.com/p/649277113
-
https://zhuanlan.zhihu.com/p/662657529
-
https://zhuanlan.zhihu.com/p/682604566
-
https://hub.baai.ac.cn/view/31947
-
https://developer.baidu.com/article/details/2587180
-
https://zhuanlan.zhihu.com/p/676723672?utm_psn=1727814727898763264
-
https://cloud.baidu.com/doc/WENXINWORKSHOP/s/9liblgyh7
相关文章:
大模型LLM之SFT微调总结
一. SFT微调是什么 在大模型的加持下现有的语义理解系统的效果有一个质的飞跃;相对于之前的有监督的Pre-Train模型;大模型在某些特定的任务中碾压式的超过传统nlp效果;由于常见的大模型参数量巨大;在实际工作中很难直接对大模型训…...
【RocketMQ问题总结-2】
RocketMQ 消息持久化 Broker通过底层的Netty服务器获取到一条消息后,会把这条消息的内容写入到一个CommitLog文件里去(一个Broker进程就只有一个CommitLog文件,也就是说这个Broker上所有Topic的消息都会写入这个文件)。 同时&…...

掌握Android Fragment开发之魂:Fragment的深度解析(上)
Fragment是Android开发中用于构建动态和灵活界面的基石。它不仅提升了应用的模块化程度,还增强了用户界面的动态性和交互性,允许开发者将应用界面划分为多个独立、可重用的部分,每个部分都可以独立于其他部分进行操作。本文将从以下几个方面深…...

深度解读DreamFusion:一站式AI解决方案
DreamFusion是一款备受瞩目的人工智能解决方案,它整合了多种AI技术,为用户提供了一站式的解决方案。本文将全面解读DreamFusion,探讨其特点、功能和应用场景,助您深入了解这一创新工具。 1. 特点概述 DreamFusion具备以下显著特…...

JVM-02
字节码文件是一种特殊的文件格式,它包含了将源代码转换为机器可执行代码所需的指令集。字节码文件通常是由编译器将源代码编译为字节码的中间表示形式。 在Java中,字节码文件的扩展名为.class,它存储了编译后的Java代码。这些字节码文件可以在…...

【一起深度学习——NIN】
NIN神经网络 原理图:代码实现:输出结果: 原理图: 代码实现: import torch from torch import nn from d2l import torch as d2ldef nin_block(in_channels, out_channels, kernel_size, strides, padding):return nn.…...

数字工厂管理系统如何助力企业数据采集与分析
随着科技的不断进步,数字化已成为企业发展的重要趋势。在制造业领域,数字工厂管理系统的应用日益广泛,它不仅提升了生产效率,更在数据采集与分析方面发挥着举足轻重的作用。本文旨在探讨数字工厂管理系统如何助力企业数据采集与分…...

uniap之微信公众号支付
近来用uniapp开发H5的时候,需要接入支付,原来都是基于后端框架来做的,所以可谓是一路坑中过,今天整理下大致流程分享给大家。 先封装util.js,便于后面调用 const isWechat function(){return String(navigator.userA…...

Django知识点总结
因为最近在搞一个Python项目,使用的Django框架。所以快速学习了一下这个web框架。并做一些总结。 Django官网的介绍:Django is a high-level Python web framework that encourages rapid development and clean, pragmatic design. Built by experience…...
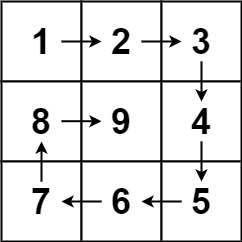
算法(C++
题目:螺旋矩阵(59. 螺旋矩阵 II - 力扣(LeetCode)) 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。 示例 1: 输入&am…...
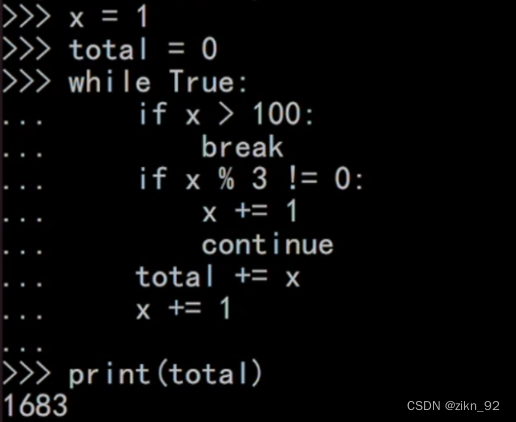
Python专题:六、循环语句(1)
补充知识 代码的注释 #描述性文字 阅读代码的人更好的理解代码 while循环语句 x<100条件控制语句,Totalx,Total自增加x,x1,x自增加1,x<100此条件满足时,执行while循环,当x101时,x101条…...

力扣2105---给植物浇水II(Java、模拟、双指针)
题目描述: Alice 和 Bob 打算给花园里的 n 株植物浇水。植物排成一行,从左到右进行标记,编号从 0 到 n - 1 。其中,第 i 株植物的位置是 x i 。 每一株植物都需要浇特定量的水。Alice 和 Bob 每人有一个水罐,最初是…...
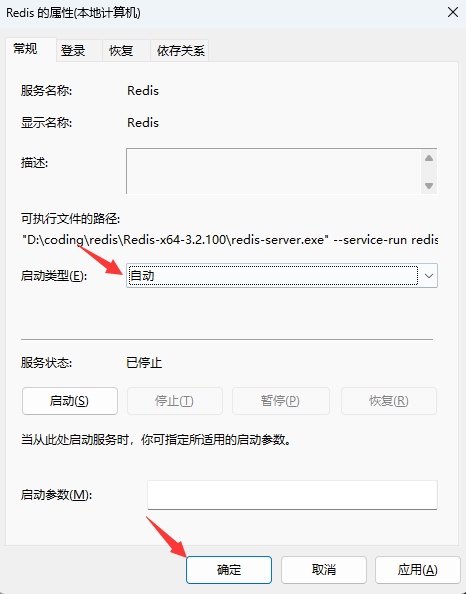
Windows设置Redis为开机自启动
前言 Redis作为当前最常用的当前缓存技术,基本上Web应用中都有使用。所以,每次我们在本地启动项目前,都必须将Redis服务端启动。但是,每次都要去启动Redis就很麻烦,有没有办法做到开机自动启动Redis呢?这当…...

行业早报5.10
1.鸿蒙智行 4 月交付 29632 辆蝉联中国新势力月销冠,问界 M9 超 13000 辆; 2.三星收购胎儿超声 AI 软件公司 Sonio,巩固尖端医疗设备领域的领先地位; 3.蔚来汽车 4 月交付 15620 辆新车,同比增长 134.6%; 4…...

Java+SpringBoot+JSP实现在线心理评测与咨询系统
前言介绍 随着互联网技术的高速发展,人们生活的各方面都受到互联网技术的影响。现在人们可以通过互联网技术就能实现不出家门就可以通过网络进行系统管理,交易等,而且过程简单、快捷。同样的,在人们的工作生活中,也就…...
机器学习算法应用——K近邻分类器(KNN)
K近邻分类器(KNN)(4-2) K近邻分类器(K-Nearest Neighbor,简称KNN)是一种基本的机器学习分类算法。它的工作原理是:在特征空间中,如果一个样本在特征空间中的K个最相邻的样…...
python数据分析——数据的选择和运算
数据的选择和运算 前言一、数据选择NumPy的数据选择一维数组元素提取示例 多维数组行列选择、区域选择示例 花式索引与布尔值索引布尔索引示例一示例二 花式索引示例一示例二 Pandas数据选择Series数据获取DataFrame数据获取列索引取值示例一示例二 取行方式示例loc() 方法示例…...

《CKA/CKAD应试指南/从docker到kubernetes 完全攻略》学习笔记 第8章 deployment
目录 前言 8.1创建和删除deployment 8.1.1通过yaml文件的方式创建deployment 8.1.2 deployment 健壮性测试...
步态识别论文(6)GaitDAN: Cross-view Gait Recognition via Adversarial Domain Adaptation
摘要: 视角变化导致步态外观存在显着差异。因此,识别跨视图场景中的步态是非常具有挑战性的。最近的方法要么在进行识别之前将步态从原始视图转换为目标视图,要么通过蛮力学习或解耦学习提取与相机视图无关的步态特征。然而,这些方法有许多约…...
)
K8S中的弹性云服务如何搭建,可能遇到的问题,如何解决!(稳啦!!!!全都稳啦!!!)
首先我们先来了解一下这玩意儿~~~ 啥是弹性云服务(Elastic Cloud Service)???? 弹性云服务(ECS)是一种基于云计算技术的虚拟服务器,由vCPU、内存、磁盘等组成的获取方便…...

电商人必看!RMBG-2.0轻量抠图实战:证件照换背景+短视频素材一键生成
电商人必看!RMBG-2.0轻量抠图实战:证件照换背景短视频素材一键生成 还在为商品图片抠图发愁吗?每天处理几十张产品图,用PS一点点抠边缘,既费时间又费眼睛?或者需要给员工批量制作证件照,但换背…...

7个实用技巧让Continue AI编程助手提升开发效率
7个实用技巧让Continue AI编程助手提升开发效率 【免费下载链接】continue ⏩ Source-controlled AI checks, enforceable in CI. Powered by the open-source Continue CLI 项目地址: https://gitcode.com/GitHub_Trending/co/continue 在当今快节奏的开发环境中&#…...

从零到一:NS2网络模拟器实战部署与场景构建指南
1. NS2网络模拟器入门指南 第一次接触NS2的朋友可能会被这个老牌网络模拟器的配置过程吓到。我刚开始用的时候,光是解决依赖问题就折腾了两天。不过别担心,跟着我的步骤走,你可以在半小时内完成基础环境搭建。 NS2本质上是一个离散事件网络模…...

当生物黑客入侵脑机接口:安全测试救了我们公司
在脑机接口(Brain-Computer Interface, BCI)技术飞速发展的今天,软件测试从业者正面临前所未有的安全挑战。作为一名资深测试工程师,我亲历了一场惊心动魄的生物黑客入侵事件——一场针对我们公司脑机接口产品的攻击险些导致灾难性…...
可行性验证)
亚洲美女-造相Z-Turbo可部署方案:适配信创环境(麒麟OS+昇腾910B)可行性验证
亚洲美女-造相Z-Turbo可部署方案:适配信创环境(麒麟OS昇腾910B)可行性验证 今天我们来聊聊一个挺有意思的话题:怎么把一个专门生成亚洲美女图片的AI模型,部署到咱们国产的信创环境里。这个模型叫“亚洲美女-造相Z-Tur…...

Fluent Meshing体网格生成失败?别慌,先检查你的几何模型是不是‘点接触’了
Fluent Meshing体网格生成失败?别慌,先检查你的几何模型是不是‘点接触’了 当你在Fluent Meshing中看到体网格生成失败的红色报错提示时,那种感觉就像考试时突然发现漏做了一整页题目。特别是当截止日期迫在眉睫,这种报错往往让人…...

科研绘图不止Origin:聊聊OriginPro 2021与Python/Matlab的共存与选择
科研绘图工具三选一:OriginPro 2021与Python/Matlab的深度对比指南 当科研工作者面临数据可视化需求时,往往会在OriginPro、Python(Matplotlib/Seaborn)和Matlab这三款主流工具之间犹豫不决。每种工具都有其独特的优势和应用场景…...

别再只盯着芯片手册了!用CC6902SO搭建电流检测电路,这些实测数据和避坑经验更重要
别再只盯着芯片手册了!用CC6902SO搭建电流检测电路,这些实测数据和避坑经验更重要 第一次用CC6902SO搭建电流检测电路时,我完全按照芯片手册推荐的电路设计,结果发现实际输出和理论值差了将近15%。这让我意识到,真正影…...

3个高效技巧:百度网盘秒传工具实现跨平台文件管理
3个高效技巧:百度网盘秒传工具实现跨平台文件管理 【免费下载链接】baidupan-rapidupload 百度网盘秒传链接转存/生成/转换 网页工具 (全平台可用) 项目地址: https://gitcode.com/gh_mirrors/bai/baidupan-rapidupload 在数字化时代,高效文件传输…...

AlphaFold单元测试:代码质量保证
AlphaFold单元测试:代码质量保证 【免费下载链接】alphafold Open source code for AlphaFold 2. 项目地址: https://gitcode.com/GitHub_Trending/al/alphafold 引言:为什么AlphaFold需要严格的单元测试? AlphaFold作为革命性的蛋白…...