缓存菜品操作
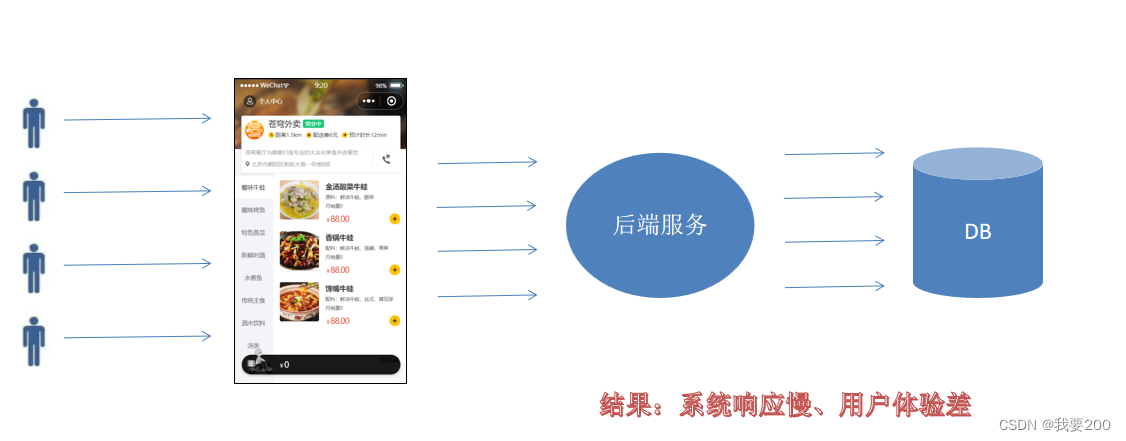
一:问题说明
用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大。
二:实现思路
通过Redis来缓存菜品数据,减少数据库查询操作。

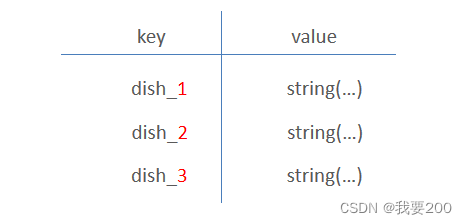
缓存逻辑分析:
- 每个分类下的菜品保存一份缓存数据
- 数据库中菜品数据有变更时清理缓存数据
三:具体的代码实现:
DishControll层(用户端):
我们需要在dishcontrol层加入缓存处理
- 注入redis
- 构造redis的key(根据我们上面的规则,redis中的key是为dish_ + 分类的id)
- 查询redis中是否有这个菜品
- 如果有,直接返回
- 如果没有,请求数据库,并且把这个菜品放到redis中
package com.sky.controller.user;import com.sky.constant.StatusConstant;
import com.sky.entity.Dish;
import com.sky.result.PageResult;
import com.sky.result.Result;
import com.sky.service.DishService;
import com.sky.vo.DishVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController("userDishController")
@RequestMapping("/user/dish")
@Api(tags = "菜品相关接口")
@Slf4j
public class DishController {@Autowiredprivate DishService dishService;@Autowiredprivate RedisTemplate redisTemplate;/*** 根据分类id查询菜品* @param categoryId* @return*/@GetMapping("/list")@ApiOperation("根据分类id查询菜品")public Result<List<DishVO>> selectById(Long categoryId){log.info("根据分类id查询菜品:{}",categoryId);//构造redis中的key ,规则:dish_分类idString key = "dish_" + categoryId;//查询redis中是否又菜品数据List<DishVO> dishVOList = (List<DishVO>) redisTemplate.opsForValue().get(key);if(dishVOList != null|| dishVOList.size()>0){//如果存在,直接返回,不用查询数据库return Result.success(dishVOList);}Dish dish = new Dish();dish.setCategoryId(categoryId);dish.setStatus(StatusConstant.ENABLE);/*这里的dish对象的作用就是充当一个判断条件我们返回的是一个List<DishVO>对象,那这个对象的条件是什么呢?是:这个dish的分类id和这个categoryId相等,并且呢,还得是在起售的产品*/List<DishVO> list = dishService.listWithFlavor(dish);//如果不存在,查询数据库,将查询到的数据放到redis中redisTemplate.opsForValue().set(key,list);return Result.success(list);}
}
清理缓存:
上面的操作有一个很大的问题就是,如果我们修改了数据库里面的数据,怎么同步到redis中
这就涉及到这个请求缓存的操作了
我们的解决方法是在服务端DishControll层(因为客户肯定不可能修改我的数据,只有客户端可以)进行清理缓存的操作。
那这个时候又要具体分析了,什么样的方法需要清理缓存,是不是对数据库能进行修改的操作嘞
(增删改)
所以我们在dishcontroll层对这三类方法采用的方法是:
只要你对这个数据库进行了操作,我们直接把相关的缓存全部删掉
DishControll层(服务端):
package com.sky.controller.admin;import com.github.pagehelper.Page;
import com.sky.dto.DishDTO;
import com.sky.dto.DishPageQueryDTO;
import com.sky.entity.Dish;
import com.sky.result.PageResult;
import com.sky.result.Result;
import com.sky.service.DishService;
import com.sky.vo.DishVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.*;import java.util.ArrayList;
import java.util.List;
import java.util.Set;@RestController("adminDishController")
@RequestMapping("/admin/dish")
@Api(tags = "菜品相关接口")
@Slf4j
public class DishController {@Autowiredprivate DishService dishService;@Autowiredprivate RedisTemplate redisTemplate;/*** 新增菜品操作* @param dishDTO* @return*/@PostMapping@ApiOperation("新增菜品操作")public Result save(@RequestBody DishDTO dishDTO){log.info("新增菜品:{}",dishDTO);dishService.insert(dishDTO);//清理缓存数据String pattern = "dish_"+dishDTO.getCategoryId();cleanCache(pattern);return Result.success();}/*** 分页查询菜品* @param dishPageQueryDTO* @return*/@GetMapping("/page")@ApiOperation("分页查询菜品操作")public Result<PageResult> page(DishPageQueryDTO dishPageQueryDTO){log.info("分页查询菜品");PageResult pageresult = dishService.page(dishPageQueryDTO);return Result.success(pageresult);}/*** 批量删除菜品* @param ids* @return*/@DeleteMapping@ApiOperation("批量删除菜品")public Result delete(@RequestParam List<Long> ids){log.info("批量删除菜品:{}",ids);dishService.deletebatch(ids);//清理缓存数据String pattern = "dish_*";cleanCache(pattern);return Result.success();}/*** 根据id查询菜品* @param id* @return*/@GetMapping("/{id}")@ApiOperation("根据id查询菜品接口")public Result<DishVO> selectById(@PathVariable Long id){log.info("根据id查询菜品:{}",id);DishVO dishVO = dishService.selectById(id);return Result.success(dishVO);}/*** 修改菜品* @param dishDTO* @return*/@PutMapping@ApiOperation("修改菜品接口")public Result update(@RequestBody DishDTO dishDTO){log.info("修改菜品:{}",dishDTO);dishService.updateWithFlavor(dishDTO);//清理缓存数据String pattern = "dish_*";cleanCache(pattern);return Result.success();}/*** 菜品起售停售* @param status* @param id* @return*/@PostMapping("/status/{status}")@ApiOperation("菜品起售停售")public Result<String> startOrStop(@PathVariable Integer status, Long id){dishService.startOrStop(status,id);//清理缓存数据String pattern = "dish_*";cleanCache(pattern);return Result.success();}/*** 清理缓存* @param pattern*/private void cleanCache(String pattern){final Set keys = redisTemplate.keys(pattern);redisTemplate.delete(keys);}
}
四:Spring Cache框架:
Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能
Spring Cache中的常用注解:

Spring Cache入门小程序:
@EnableCaching注解:
直接加在启动类上就行。
@Slf4j
@SpringBootApplication
@EnableCaching//启动缓存注解
public class CacheDemoApplication {public static void main(String[] args) {SpringApplication.run(CacheDemoApplication.class,args);log.info("项目启动成功...");}
}
@CachePut注解:
(cacheput这个注解一般加在插入数据的方法上)
@PostMapping@CachePut(cacheNames = "userNames",key = "#user.id")public User save(@RequestBody User user){userMapper.insert(user);return user;}这里的cacheNames其实就是这个缓存的名字。
key的生成:cacheNames::#user.id

我们这个使用的时候这个返回值的id,
@Insert("insert into spring_cache_demo.user(name,age) values (#{name},#{age})")@Options(useGeneratedKeys = true,keyProperty = "id")void insert(User user);这里需要注意的是,我们需要在mapper层中的插入方法下加入将id返回这个一个选项功能。
因为id是自增的,所以不一定要从前端传。
@Cacheable注解:
@GetMapping@Cacheable(cacheNames = "userNames",key = "#id")public User getById(Long id){User user = userMapper.getById(id);return user;}这里的两个参数就和刚刚的@CachePut的参数一样就行。
下面是我查询了一个id为1的数据,因为id为1的数据还没放到缓存中,所以还是从数据库里面查的

然后我查询了一个id为2的数据,控制台没有任何反应。
并且这个Cacheable注解还会把数据直接插入缓存中:
下面是我又查了一次id为1的数据。
控制台没有任何的反应
@Cacheable 这个注解使用了一个代理对象的技术(AOP),
就是当你给controller层的方法加了这个Cacheable注解,其实这个框架就会创建一个代理对象,我们查询的数据会先被这个代理对象接收,如果这个代理对象没查到,才会交给这个方法来查。
具体的体现就是,如果这个数据在这个缓存中,就连这个select的方法都不会调用(用断点的方式可以测出)
@CacheEvict注解:
@DeleteMapping@CacheEvict(cacheNames = "userNames",key = "#id")public void deleteById(Long id){userMapper.deleteById(id);}这个注解主要的作用就是帮我们清楚缓存,我们直接在发一条sql语句,同时能删除数据库中和redis中的数据。
@CacheEvict(cacheNames = "setmealCache",allEntries = true)
如果指定这个allEntries = true,那就代表把所有的缓存都给删掉
Spring Cache缓存套餐具体思路:
具体的实现思路如下:
- 导入Spring Cache和Redis相关maven坐标
- 在启动类上加入@EnableCaching注解,开启缓存注解功能
- 在用户端接口SetmealController的 list 方法上加入@Cacheable注解
- 在管理端接口SetmealController的 save、delete、update、startOrStop等方法上加入CacheEvict注解
相关文章:
缓存菜品操作
一:问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大。 二:实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: 每个分…...

达梦数据库常用命令整理
1.数据库自身信息 1.1 查询实例信息 SQL> select name inst_name from v$instance;行号 INST_NAME ---------- --------- 1 DMSERVER已用时间: 11.211(毫秒). 执行号:15.1.2 查询数据库当前状态 SQL> select status$ from v$instance;行号 STATUS$ -…...
Vue 组件的三大组成部分
Vue 组件通常由三大组成部分构成:模板(Template)、脚本(Script)、样式(Style) 模板部分是组件的 HTML 结构,它定义了组件的外观和布局。Vue 使用基于 HTML 的模板语法来声明组件的模…...

MoneyPrinter中的文字转声音国内替换方案
背景: 在进行MoneyPrinter项目国内环境搭建中,发现框架本身的TikTok文字转语音部分的代码已经不能用了,最好是能够找到国内网站的替换方案。 实现: 感谢网站:https://www.text-to-speech.cn/ 代码: # -*…...
消除试卷手写笔迹的软件免费的有哪些?这几款都不错
消除试卷手写笔迹的软件免费的有哪些?在数字化学习的浪潮中,学生们越来越频繁地利用电子设备来完成学习任务。然而,当纸质试卷需要被数字化并再次利用时,如何高效地消除手写笔迹便成为了一个有待解决的问题。那么,今天…...

智能创作时代:AI 如何重塑内容生成游戏规则
文章目录 前言一:自动化内容生成文章生成视频制作音频创作 二:内容分发与推广智能推荐系统社交媒体优化 三:内容分析与优化数据分析用户反馈质量控制 结语 前言 在数字化时代的浪潮中,内容生产与消费已成为信息传播的核心。随着人…...

大数据------JavaWeb------Tomcat(完整知识点汇总)
Web服务器——Tomcat Web服务器定义 它是一个应用程序(软件),对HTTP协议的操作进行封装,使得程序员不必直接对协议进行操作,让Web开发更便捷 Web服务器主要功能 封装HTTP协议操作,简化开发将Web项目部署到…...

LMDeploy笔记
随谈模型部署 模型部署包含的内容很多,来聊聊。 访存bottleneck 首先,基于transformer的计算是访存密集型任务。 so? 过去,我们表达模型的性能,通常会用ops,macs这些指标,也计算量来衡量模型的推理时间ÿ…...

Unity 状态机
文章目录 前言一、状态机二、应用1、场景切换2、人物行为切换3、宝箱、机关切换4、AI 三、人物行为总结 前言 提到Unity状态机,接触不久的开发者会想到Unity的动画状态机,而对于老油条来说,可能会回忆起自己实现的动画状态机。当然ÿ…...

一毛钱不到的FH8208C单节锂离子和锂聚合物电池一体保护芯片
前言 目前市场上电池保护板,多为分体方案,多数场合使用没有问题,部分场合对空间有进一步要求,或者你不想用那么多器件,想精简一些,那么这个芯片就很合适,对于充电电池来说,应在使用…...
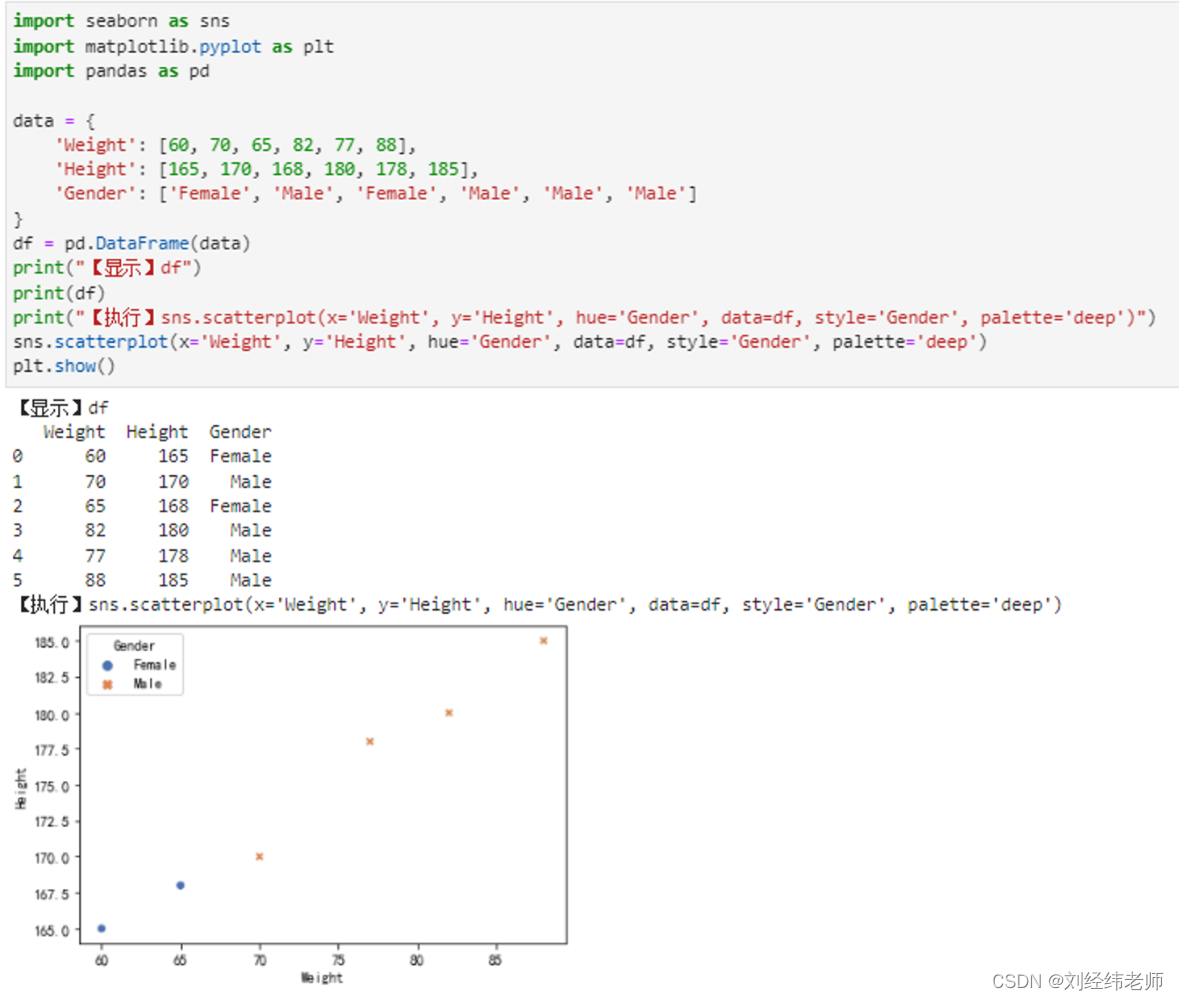
python数据可视化:显示两个变量间的关系散点图scatterplot()
【小白从小学Python、C、Java】 【计算机等考500强证书考研】 【Python-数据分析】 python数据可视化: 显示两个变量间的关系 散点图 scatterplot() [太阳]选择题 请问关于以下代码表述错误的选项是? import seaborn as sns import matplotlib.pyplot …...

【QT教程】QT6硬件高级编程入门 QT硬件高级编程
QT6硬件高级编程入门 使用AI技术辅助生成 QT界面美化视频课程 QT性能优化视频课程 QT原理与源码分析视频课程 QT QML C扩展开发视频课程 免费QT视频课程 您可以看免费1000个QT技术视频 免费QT视频课程 QT统计图和QT数据可视化视频免费看 免费QT视频课程 QT性能优化视频免费看…...
)
Android 蓝牙实战——蓝牙电话通话状态同步(二十四)
前面分析了蓝牙电话通话状态的广播,我们可以在蓝牙电话中实时监听蓝牙电话的状态,但如果是其他音乐类 APP 呢,在播放的时候也需要知道当前是否有通话正在进行,但是有完全没必要实时监听电话的状态,这就需要一个获取通话状态的方法。 一、通话状态处理 1、CallsManager …...
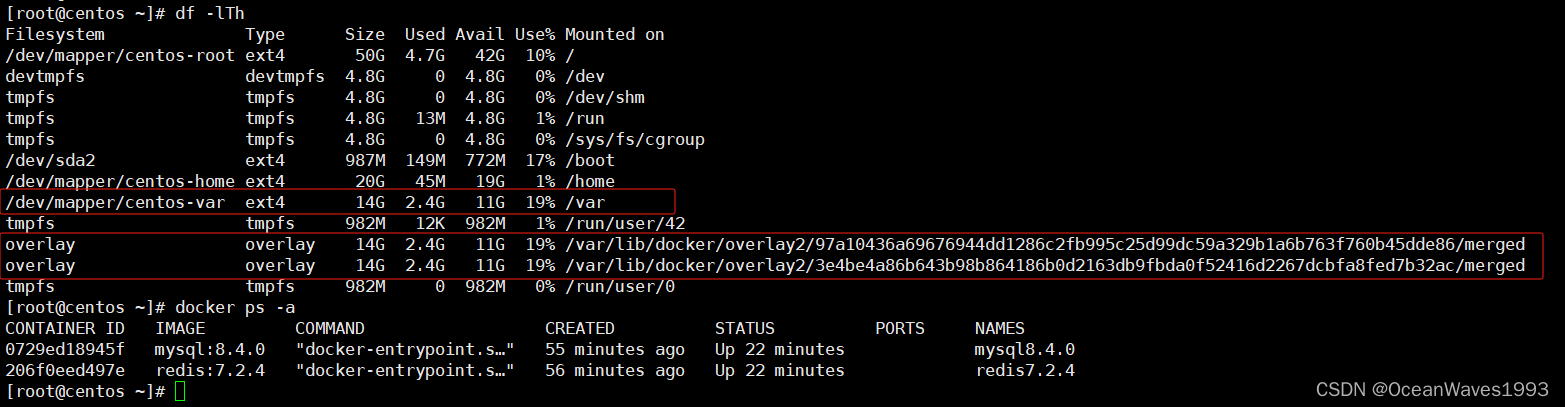
docker 指定根目录 迁移根目录
docker 指定根目录 迁移根目录 1、问题描述2、问题分析3、解决方法3.1、启动docker程序前就手动指定docker根目录为一个大的分区(支持动态扩容),事前就根本上解决根目录空间不够问题3.1.0、方法思路3.1.1、docker官网安装文档3.1.2、下载docker安装包3.1.3、安装doc…...

React 项目报错解决办法收录
React 使用 引入文件报错 (react 别名配置craco) react ,vue 初始项目都是不支持 别名引入文件的。 vue 一般项目初始化的时候会 在 vue.config.js 文件中配置好,所以不需要我们自己配置react 初始化的时候是没有配置的, 需要我们自己配置 …...
)
Linux专题-Makefile(1)
1.Makefile中的注释使用 # 2. Makefile中的静默执行。 makefile中,默认情况下执行一行命令前会先把这一行命令打印出来,然后再执行这条命令。如果不想看到打印的命令,则可以使用静默执 行的功能,即仅打印出命令执行的结果。使用方…...
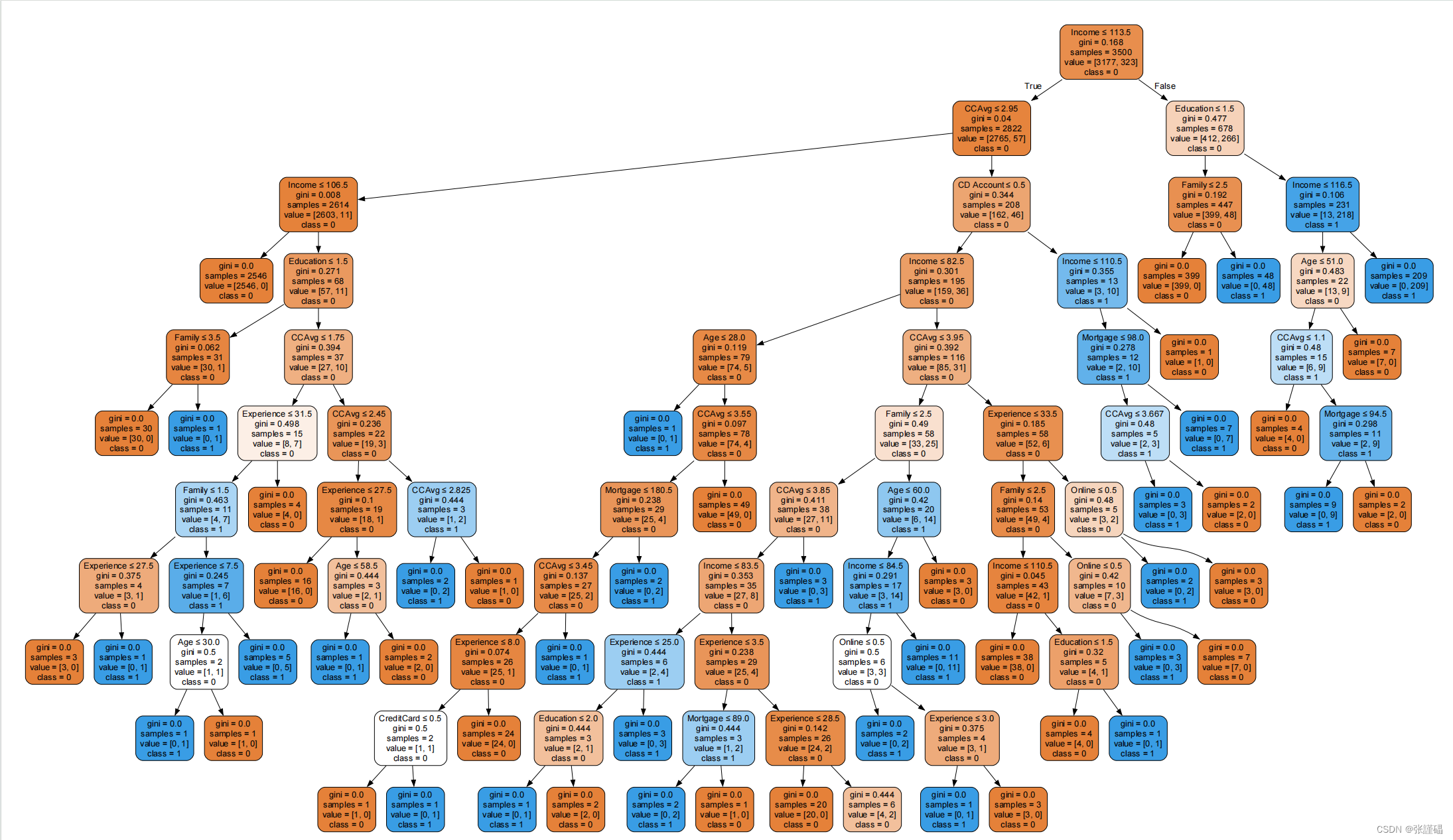
机器学习算法应用——CART决策树
CART决策树(4-2) CART(Classification and Regression Trees)决策树是一种常用的机器学习算法,它既可以用于分类问题,也可以用于回归问题。CART决策树的主要原理是通过递归地将数据集划分为两个子集来构建决…...
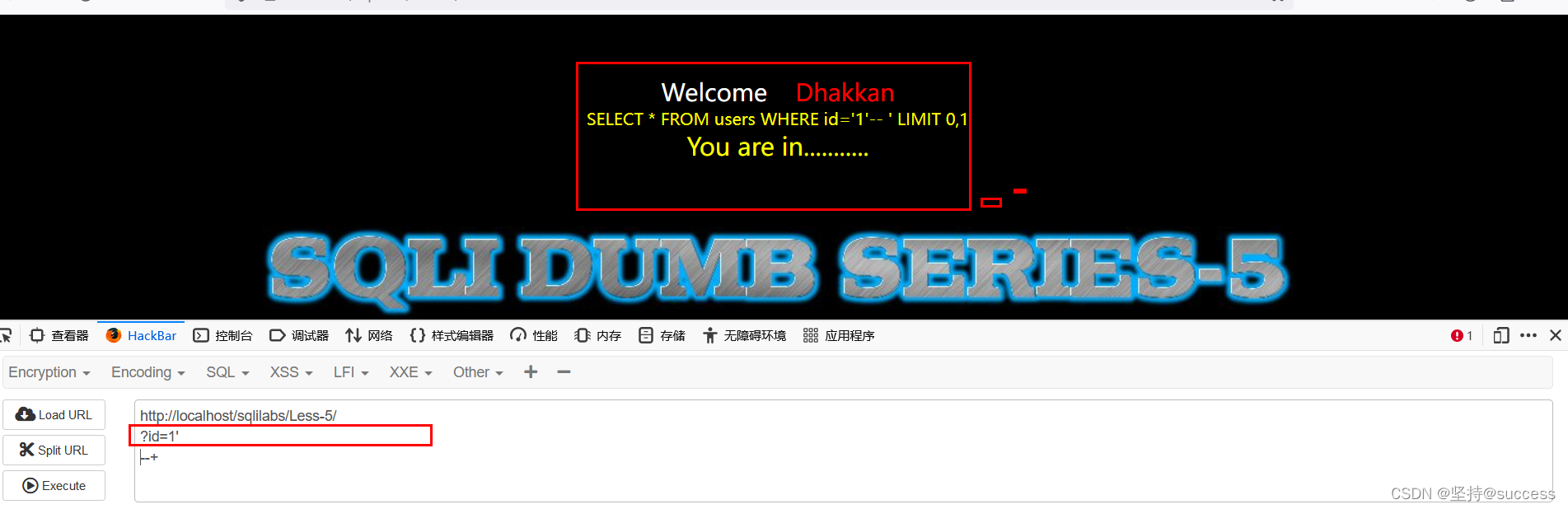
Sqli-labs第五,六关
目录 首先找到他们的闭合方式 操作 总结: 第五关根据页面结果得知是字符型但是和前面四关还是不一样是因为页面虽然有东西。但是只有对于请求对错出现不一样页面其余的就没有了。这个时候我们用联合注入就没有用,因为联合注入是需要页面有回显位。如果…...

上海AI Lab开源首个可替代GPT-4V的多模态大模型
与开源和闭源模型相比,InternVL 1.5 在 OCR、多模态、数学和多轮对话等 18 个基准测试中的 8 个中取得了最先进的结果。 上海AI Lab 推出的 InternVL 1.5 是一款开源的多模态大语言模型 (MLLM),旨在弥合开源模型和专有商业模型在多模态理解方面的能力差距…...

Python教程:一文了解PageObject模式
PageObject 模式是一种用于测试自动化的设计模式,它将页面的功能和页面的实现分开,提高了代码的可维护性和可重用性。本文将从基础概念开始,逐步介绍 Python 中的 PageObject 模式,并提供详细的代码示例。 1. 什么是 PageObject 模…...

90% 的开发者都在错误理解 async/await:协程本质与高并发实战指南
90% 的开发者都在错误理解 async/await:协程本质与高并发实战指南 很多人在第一次写 async def await 的时候,心里都暗暗期待:这下代码应该变快了吧? 结果写完一测,单个接口的响应时间和以前同步写法几乎一模一样&…...

Qwen3.5-9B Java面试宝典生成器:动态定制八股文与场景题
Qwen3.5-9B Java面试宝典生成器:动态定制八股文与场景题 1. 为什么需要智能面试助手 Java开发者求职路上,最头疼的莫过于海量面试题的整理和记忆。传统方式要么依赖网上零散的八股文合集,要么自己手动整理知识点,效率低下且难以…...
)
网络爬虫主流思路及反爬破解技术应用(新手速成)
网络爬虫的主流思路是模拟浏览器行为自动化抓取网页数据,而反爬破解技术则通过代理IP、请求伪装、动态渲染处理等方式绕过网站防护机制,实现稳定高效的数据采集 。一、主流爬虫技术思路 1.请求模拟与数据提取 使用 requests 或 urllib 构建H…...

如何高效保存B站视频?全功能跨平台工具BiliTools使用指南
如何高效保存B站视频?全功能跨平台工具BiliTools使用指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools …...

瑞芯微RK3399固件急救指南:用upgrade_tool搞定系统崩溃后的快速还原
RK3399固件灾难恢复实战:从分区表重建到全系统还原 当一块搭载RK3399的开发板因固件损坏而变砖时,那种面对黑屏的无力感,相信每个嵌入式开发者都深有体会。去年我们产线就遭遇过因批量升级失败导致30台设备集体罢工的紧急状况,正…...

LLM推理流式响应延迟骤降73%:FastAPI 2.0 + asyncpg + Redis Stream 实战调优,附可复用中间件代码库
第一章:LLM推理流式响应延迟骤降73%:FastAPI 2.0 asyncpg Redis Stream 实战调优,附可复用中间件代码库在高并发LLM服务场景中,传统同步I/O与阻塞式数据库访问常导致首字节延迟(TTFB)飙升。我们通过重构请…...

PP-DocLayoutV3参数详解:text/title/table/figure等11类版面区域置信度解析
PP-DocLayoutV3参数详解:text/title/table/figure等11类版面区域置信度解析 1. 引言:为什么版面分析需要“置信度”? 想象一下,你拿到一份扫描的合同,想用OCR(文字识别)把它变成可编辑的电子版…...

NVIDIA Profile Inspector实战指南:从参数调试到显卡性能极致释放
NVIDIA Profile Inspector实战指南:从参数调试到显卡性能极致释放 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 诊断性能瓶颈 显卡性能表现不佳往往是多种因素共同作用的结果,…...

WarcraftHelper:让魔兽争霸3重获新生的兼容性增强工具
WarcraftHelper:让魔兽争霸3重获新生的兼容性增强工具 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否曾在现代电脑上尝试重温魔兽争…...

Python中CSV文件处理的常见累积错误及修正方案
在使用 Python 的 csv 模块处理学生成绩数据时,一个极易被忽视却影响结果准确性的典型问题是变量作用域与重用逻辑错误。如原始代码所示,grades [] 被定义在 for row in reader: 循环外部,导致每次迭代都将新学生的成绩追加到同一个列表中—…...