论文阅读:The Unreasonable Ineffectiveness of the Deeper Layers 层剪枝与模型嫁接的“双生花”
作者实证研究了针对流行的开放式预训练 LLM 系列的简单层修剪策略,发现在不同的 QA 基准上,直到去掉一大部分(最多一半)层(Transformer 架构)后,性能的下降才会降到最低。为了修剪这些模型,作者通过考虑各层之间的相似性来确定要修剪的最佳层;然后,为了“治愈”损伤,进行了少量的微调。特别是 PEFT 方法,尤其是量化和低秩适配器(QLoRA),这样每个实验都可以在单张 A100 GPU 上完成。
从实用的角度来看,这些结果表明,层剪枝方法一方面可以补充其他 PEFT 策略,进一步减少微调的计算资源,另一方面可以改善推理的显存开销和生成时延。从科学角度看,这些 LLM 对层删除的鲁棒性意味着,要么当前的预训练方法没有正确利用网络深层的参数,要么浅层在存储知识方面起着关键作用。
方法
作者在论文中写道:移除层的直觉来自于将表征视为层索引的缓慢变化函数,特别是 transformer 层与层之间的表征变化由一个残差迭代方程给出:
x ( l + 1 ) = x ( l ) + f ( x ( l ) , θ ( l ) ) x^{(l + 1)} = x^{(l)} + f(x^{(l)}, \theta^{(l)}) x(l+1)=x(l)+f(x(l),θ(l))
注意:现在的 LLM 大都是 pre-norm 形式,具体原因可参考苏神的博客 为什么Pre Norm的效果不如Post Norm?。
其中, ( x ( l ) , θ ( l ) ) (x^{(l)}, \theta^{(l)}) (x(l),θ(l))分别是层 ℓ 的多维输入向量和参数向量, f ( x , θ ) f(x, \theta) f(x,θ)描述了一个多头自注意和 MLP 层的变换。与任何残差网络一样,如果展开这一迭代,就会发现在总共 L 层之后,输出被描述为所有层的变换之和。
x ( L ) = x ( 0 ) + ∑ l = 0 L − 1 f ( x ( l ) , θ ( l ) ) , (2) x^{(L)} = x^{(0)} + \sum_{l=0}^{L-1} f(x^{(l)}, \theta^{(l)}), \tag{2} x(L)=x(0)+l=0∑L−1f(x(l),θ(l)),(2)
如果总和中的项很多(L >> 1),而且相互独立,例如,如果块(transformer block)函数是整个输入的函数 f ( x ( 0 ) , θ ( l ) ) f(x^{(0)}, \theta^{(l)}) f(x(0),θ(l)),那么对总和公示 (2) 的任何特定贡献都可以忽略不计。当然,它们并不是完全独立的:如果我们删除层 ℓ - 1,那么现在必须将该层的旧输入 x ( ℓ − 1 ) x^{(ℓ-1)} x(ℓ−1)连接到层 ℓ 的块函数中,即:
x ( ℓ + 1 ) = x ( ℓ − 1 ) + f ( x ( ℓ − 1 ) , θ ( ℓ ) ) , (3) x^{(ℓ + 1)} = x^{(ℓ - 1)} + f(x^{(ℓ - 1)}, \theta^{(ℓ)}), \tag{3} x(ℓ+1)=x(ℓ−1)+f(x(ℓ−1),θ(ℓ)),(3)
其中,为了清晰起见,尽管删除了输入,作者并没有重新标记层或输入。一般来说,原始输入和新输入之间的这种不匹配会对网络造成极大的破坏。但是,如果在经过一定数量的初始层后,表征收敛到一个与层索引相关的缓慢变化函数。
x ( ℓ ) ≈ x ( ℓ − 1 ) + ϵ , (4) x^{(ℓ)} \approx x^{(ℓ - 1)} + \epsilon, \tag{4} x(ℓ)≈x(ℓ−1)+ϵ,(4)
无论如何,任何层的删除都会产生级联效应:因为剪枝后 x ( ℓ + 1 ) x^{(ℓ+1)} x(ℓ+1) 的计算函数与之前不同,参见 (1) 与 (3),而且 x ( ℓ + 1 ) x^{(ℓ+1)} x(ℓ+1) 会直接或间接输入到后续层,ℓ + 2, … , L,删除浅层的影响应该比删除深层的影响大得多。
由此,作者提出了以下假设,并将对其进行实验验证:
- 我们应该能够剪枝残差网络的层。
- 我们应该能够更成功地剪枝较深的层。
- 成功剪枝的层块应该具有与其输入相似的输出。
Layer-pruning 算法
层剪枝算法非常简单:
- 选择要剪枝的层数 n。
- 在中性的预训练数据集或代表下游任务的数据集上,计算层 l 输入与层 l + n 输入之间的角距离 d ( x ( l ) , x ( l + n ) ) d(x^{(l)}, x^{(l + n)}) d(x(l),x(l+n)),参见下文公式(7)。
- 找出最小化该距离的层 l ∗ l^* l∗:
ℓ ⋆ ( n ) ≡ arg min ℓ d ( x ( ℓ ) , x ( ℓ + n ) ) . (6) \ell^{\star}(n) \equiv \underset{\ell}{\arg \min } \ d\left(x^{(\ell)}, x^{(\ell+n)}\right). \tag{6} ℓ⋆(n)≡ℓargmin d(x(ℓ),x(ℓ+n)).(6)
4. 将层 l ∗ l^* l∗ drop 到 l ∗ + n − 1 l^* + n - 1 l∗+n−1;将层 l ∗ l^* l∗ 的旧输入连接到旧第 ( l ∗ + n ) (l^* + n) (l∗+n) 层块(层通常包含在一个数据结构中,例如 PyTorch 中的 ModuleList,要删除这些层,只需定义一个新的 ModuleList,删除从 l ∗ l^* l∗ 到 l ∗ + n − 1 l^* + n - 1 l∗+n−1 的层)。
5. (可选)在中性预训练数据集或感兴趣的特定数据集上进行少量微调,修复层 l ∗ + n l^* + n l∗+n 上的不匹配(可以理解为,在对模型架构“动刀”后,模型的效果会出现下降,通过在原有或下游领域的数据集上微调,使“动刀”后的模型适应这种新的架构)。
详细说明第一步,长度为 T 的单个序列的角距离为:
d ( x ( ℓ ) , x ( ℓ + n ) ) ≡ 1 π arccos ( x T ( ℓ ) ⋅ x T ( ℓ + n ) ∥ x T ( ℓ ) ∥ ∥ x T ( ℓ + n ) ∥ ) , (7) d\left(x^{(\ell)}, x^{(\ell+n)}\right) \equiv \frac{1}{\pi} \arccos \left(\frac{x_{T}^{(\ell)} \cdot x_{T}^{(\ell+n)}}{\left\|x_{T}^{(\ell)}\right\|\left\|x_{T}^{(\ell+n)}\right\|}\right), \tag{7} d(x(ℓ),x(ℓ+n))≡π1arccos xT(ℓ) xT(ℓ+n) xT(ℓ)⋅xT(ℓ+n) ,(7)
其中,内积是序列最后 token T 的模型隐藏维度,||-||表示 L2 正则化,1/π 是约定俗成的系数。然后,应将这一距离与一定数量的示例相加,该数量应足够大,以获得低波动估计值,但总体上应相当小。
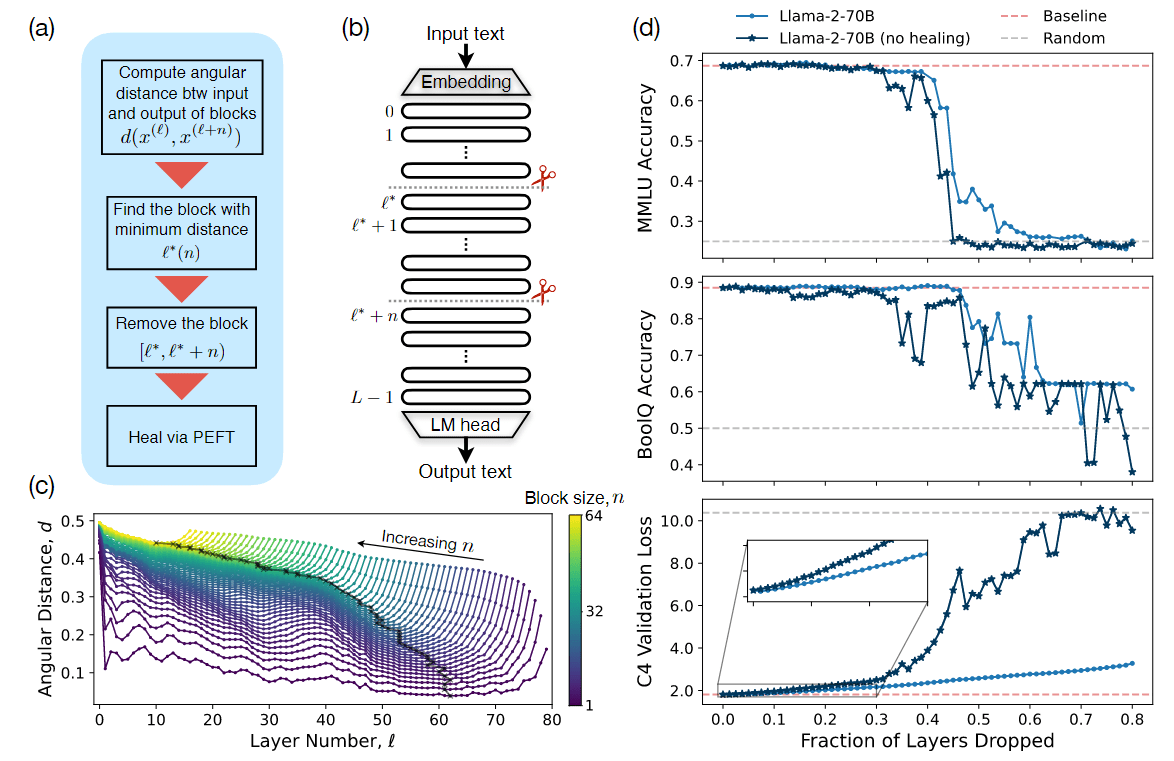
图 1 层剪切策略概述和示例结果:(a)描述算法的流程图:如果要删除 n 层,我们要找到使层 ℓ 和 ℓ+n 之间角距离 d 最小的层 ℓ∗;然后从层 ℓ∗ 开始删除 n 层;最后,如果有必要,我们可以通过少量(参数有效的)微调来 "治愈 "损伤。
在详细阐述最后一步的“可选”时,作者发现,参照图 1(d) 和实验部分的 QA 基准上几乎没有性能下降的情况,可以通过少量微调扩展到更大的剪枝分数。根据资源限制和修剪后模型的预期应用,这可能不是必须的。不过,愈合过程确实会对 PPL 产生重大影响,参见图 1(d) 和实验部分的 next token 预测损失。
对于角距离测量和愈合,如果最终目标是针对下游任务对模型进行监督微调(SFT),那么评估该数据集样本的距离,然后将愈合过程与 SFT 结合起来,可能会很有用。相比之下,为了获得最大的通用性,最自然的做法是使用近似于模型最初预训练时的统计数据的预训练数据集来测量距离并进行修复。
最后,作者还研究了一种更简单的剪枝策略,其灵感来自于对不同模型角距离的分析:放弃最深的层,不包括 LLM head 之前的最后一层,然后(非选择性地)愈合损失。为了完全清楚起见,这意味着如果要从一个 L 层模型中剪枝 n 层,可以移除 (L - n) 至 (L - 1) 层,包括 (L - 1) 层。
实验结果
在本节中,作者在不同的问题解答(QA)基准上证明了剪枝策略的有效性,并强调了由剪枝驱动的性能转变,与此相反,作者发现愈合剪枝模型的自回归 PPL 在其转变点上是连续的;然后,在比较了不同模型大小和模型族中不同层之间的相似性统计之后,将主要相似性信息剪枝策略与更简单的去除最深层策略进行了对比。
QA 基准的准确率
第一组结果如图 2 所示,图中绘制了 5-shot MMLU 准确率与被移除层数的函数关系图:左图是 Llama-2 系列模型,中图是 Qwen 系列模型,右图是 Mistral-7B 和 Phi-2 模型。为了更好地比较不同总层数的模型,在这些图中,选择用移除层数的百分比(而不是移除层数的绝对值)来归一化 x 轴。请注意,由于 MMLU 包含四个可能回答的多选题,随机猜测的预期准确率为 25%。
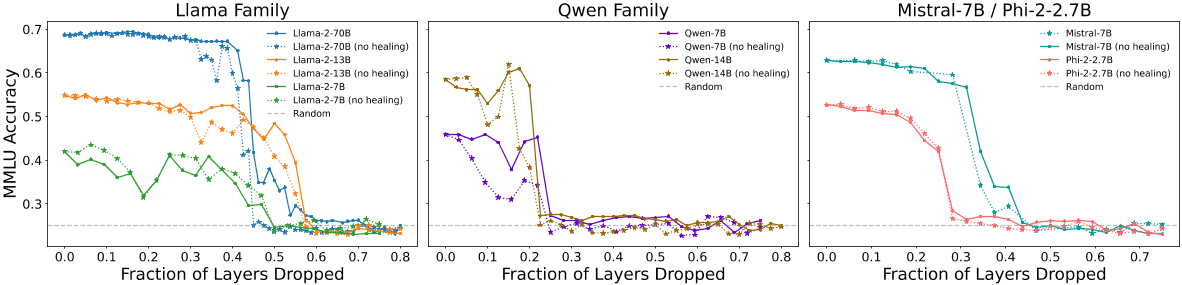
图 2:不同模型系列的 MMLU 准确率(5-shot)与移除层数的关系(左:Llama-2 系列;中:Qwen 系列;右:Mistral-7B 和 Phi-2)。(实线表示移除层数并愈合后的性能,虚线表示只移除图层(不愈合)后的性能,灰色虚线是随机猜测的得分。对于这些模型来说,愈合带来的改进不大,而且性能相当稳定,直到剪枝百分比达到 20%-55% 时(取决于模型族和大小),性能才会过渡到随机猜测。
重要的是,在 Llama-2 家族的模型中,看到了一个具有特征性的稳健性能的平坦区域,然后在剪枝百分比约为 45%-55% 时急剧过渡到随机猜测;在 Mistral 7B 中为 35%;在 Phi-2 中为 25%;在 Qwen 家族的模型中为 20%。这意味着,获得模型最高分所需的基本知识并不会因为大量移除层而被移除——尽管移除的部分可能相当大——直到最终在一个与模型有关的临界值上失去了这些知识。对比有愈合和无愈合的曲线,可以发现,微调提供了适度的改进,它更好地保持了未剪枝的性能,并延缓了向随机猜测的转变。
大体上,发现对于较大和较深的模型,例如 Llama-2-13B 和 Llama-2-70B,层剪枝是更稳健的,作者假设这可能与以下事实有关:或者较小的模型更过度训练,使得参数冗余较少,或者较深的模型在绝对意义上可以承受损失更多的层。此外,Qwen 家族也很奇怪,将在下文的表征之间的角度距离进一步阐述。
我理解较小的模型并不是参数冗余较少,而是层数较少,每一层都对最终输出起到一定的作用,无非是作用的大与小。较深的模型训练的难度大,反向传播时很难训练到模型的浅层,使得中间层的输出区别并不大,因此在模型嫁接中往往会对这一部分动刀。
问题:什么是模型嫁接呢?
回答:GPT-4-1106-preview 的回答——在深度学习领域,通常指的是修改已经训练好的神经网络模型的结构,以便重新利用或优化模型。这种技术可以用于多种场景,比如迁移学习、模型压缩、修正模型缺陷或者适应新的任务等。读者们也可以看看张俊林大佬在知乎上写的关于模型嫁接的想法 SOLAR 这种“模型嫁接”很有意思。
今年年初的时候,SOLAR 火爆一时,我所在的公司也尝试过模型嫁接的方式,同事在线上应用后,表示业务指标效果一般。后来,我查看了相关的实验报告,发现很可能是选择的层有问题。
后面的层(深层)往往和业务场景的关联较深,直接复制后面 16 层效果不会太好。看社区里面的融合方式,通常是前 24 层 + 后 24 层,让中间层重叠。最近 Yi 发出的技术报告显示,他们是通过评估每一层输入和输出之间的余弦相似度,来寻找适合进行复制的层,把余弦相似度接近 1 的层进行复制,从而扩展到 48 层(通常是 10B 左右)。接着 continue pretraining。如果资源不足,可以在大规模的 SFT 数据集上微调,让中间重叠层能够有所区别,起到作用。
在 Yi 的技术报告中也写到一项技术 Depth Upscaling,他们发现:
- 在扩展宽度后,模型的性能显著下降;
- 在对原始模型进行深度加强(通过选择适当的层)后,新层的输入/输出余弦越接近 1.0,即放大模型的性能可以保持原始模型的性能,性能损失很小。
于是,Yi 团队对 6B 模型进行 depth up-scaling,得到 Yi-9B。方法来自于 SOLAR 10.7B,将原来的 32 层扩展到 48 层。通过评估每一层输入和输出之间的余弦相似度,来寻找适合用来进行复制的层,把余弦相似度接近 1 的层进行复制。这样扩展得到的 9B 模型只需要很轻量的二阶段训练(0.4T 文本+代码,0.4T 文本+代码+数学)就能得到很不错的性能。
那么,通过这种方式来扩展层数,同样也可以基于此来减少层数,这就是这篇论文所要讲述的核心内容。
next token 预测损失
在本节中,将在 C4 验证集的一个子集上评估层剪枝对预训练优化目标(next-token 预测的交叉熵损失)的影响。为了公平地比较不同规模词汇表 V 的模型,作者用 log V 对损失进行了归一化处理,这相当于以均匀概率随机抽样 token 的损失。
在图 3 中,作者绘制了所有七个模型在愈合后(左图)和愈合前(右图)的归一化 C4 验证损失,并将其作为移除部分层的函数。在未进行愈合的情况下,可以看到每个模型都会在大约剪枝分数处急剧(等同于)过渡到随机猜测,而 QA 基准准确率也会在这一分数处急剧过渡到随机猜测,这表明模型在这一点上已无药可救,参见图 2。
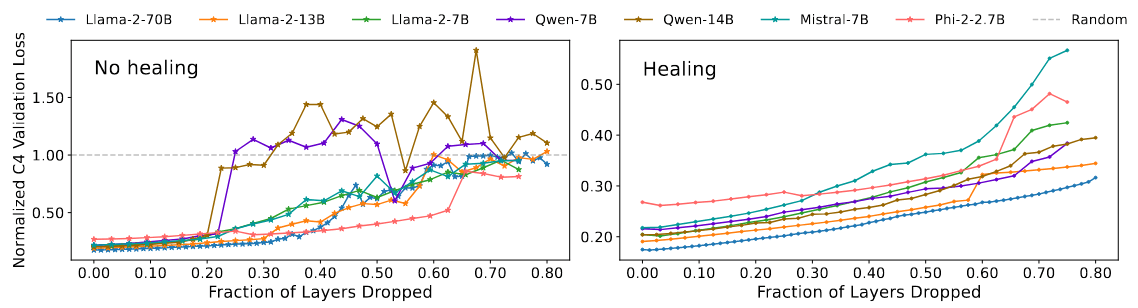
图 3:愈合前(左图)和愈合后(右图)归一化 C4 验证损失与移除层数的关系;每条曲线都根据从模型词汇中均匀采样的交叉熵损失进行了归一化。在愈合前的实验中,每个模型的损失都在大致相同的修剪分数上过渡到随机猜测(灰色虚线),而 QA 基准则过渡到随机猜测;愈合后,QA 任务的急剧过渡区域具有连续性,参见图 2。对比两幅图的整体比例,可以明显看出,修复后,next token 预测的性能显著恢复到接近未剪枝的水平。
接下来,对比两幅图的比例,可以看到,愈合显著地将所有模型的 next token 预测能力恢复到了接近未修剪的水平,损失随着层数的下降缓慢地线性增加。从科学的角度来看,最引人注目的是愈合后修剪分数的连续性,而之前发现 QA 基准的修剪分数有急剧的变化:这种脱钩说明了下游任务(如 MMLU 和 BoolQ)的性能与连续性能测量(如交叉熵损失)之间脱节(或产生误判)的一种方式。
表征之间的角度距离
鉴于角度距离(公式(7))在剪枝策略中发挥着核心作用,让我们分节来看看七个模型的角度距离。在这项分析中,每个模型的角度距离都是 C4 验证集 10k 个样本的平均值。
回顾之前的图 1©: 对于 Llama-2-70B,在 n = 1 到 n = 64 的区块大小的所有初始索引 ℓ 中,绘制了比较第 ℓ 层和第 (ℓ + n) 层的角距离 d ( x ( ℓ ) , x ( ℓ + n ) ) d(x^{(ℓ)}, x^{(ℓ+n)}) d(x(ℓ),x(ℓ+n));曲线的最小值 ℓ ∗ ( n ) ℓ^*(n) ℓ∗(n) 给出了给定 n 时的最佳剪枝块,参见公式 (6)。
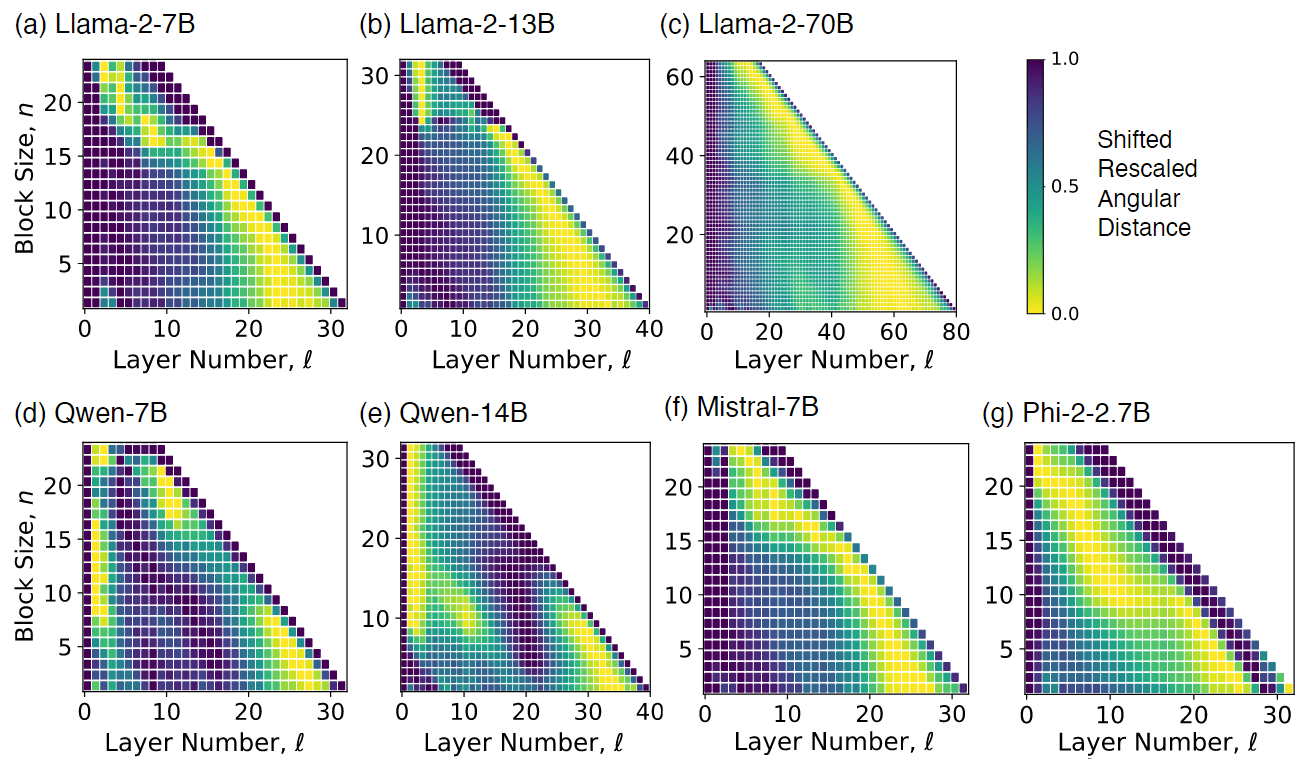
图 4:评估的七个模型中,每个模型的初始层 ℓ(x 轴)与块大小 n(y 轴)的归一化角距离 (7);每个 n 的距离都被移动和重标以跨越相同的范围 [0,1](从黄色到紫色):最佳剪枝块 ℓ ∗ ( n ) ℓ^∗(n) ℓ∗(n) 对应于每行最深的黄色。在不同的模型中,深层往往非常相似,但包括最后一层(沿外对角线的方格)在内的最深块(接近)最大差异。
图 4 的热图以更简洁的方式显示了相同的数据:每个正方形都用颜色标出了在所有可能的 ℓ 和 n 中,层 ℓ 和 ℓ + n 之间的行归一化角度距离,而 n 则是层总数的很大一部分;在给定块大小的情况下,最佳剪枝层 ℓ ∗ ( n ) ℓ^*(n) ℓ∗(n) 与每行中的最小距离相对应。
在不同的模型中,作者总结出两点:
- 深层块之间的距离最小,这意味着深层块之间通常非常相似,可以更容易地放弃;
- 最深层块(包括最后一层的块)之间的距离取最大值或接近最大值,这意味着永远不应该放弃最后一层。
作者总结出的第二点与论文《LIMA:Less is More for Alignment》提出的“表层对齐假说”观点也吻合,现在的大部分对齐微调,可能只是调整了模型的表层,即最后一层,使其输出符合人类的偏好格式。
但也有少数例外。对于某些模型,如 Phi-2-2.7B,或某些模型中最大的块,如 Llama-2-7B,最后几层似乎很重要。如前所述,Qwen 家族有些不寻常:在这里可以看到,对于浅区块,有一些奇特的高相似性“孤岛”;这可能是图 2 中较短的稳健性能区域的原因。
后续如果有时间,可以深入研究 Qwen 模型,探究下为啥会有些“不寻常”。
简单的剪枝策略
受近期结论的启发,作者尝试了一种非常简单的启发式剪枝策略:(1)如果要从一个 L 层模型中剪枝 n 层,则将层数(L - n)降至(L - 1),以移除不包括最后一层的最深块;然后(2)像之前一样进行少量微调愈合。与主要相似性信息剪枝策略相比,这种更简单的启发式算法的优势在于,从业人员无需将未剪枝模型加载到 GPU 或进行推理。它还对优化修剪块的重要性进行了有意义的消减。
在图 5 中,作者对两种剪枝策略进行了对比,包括愈合前(左侧面板)和愈合后(右侧面板)的 QA 基准(MMLU/BoolQ,顶部/中间面板)和自回归损失(C4 验证,底部面板)。
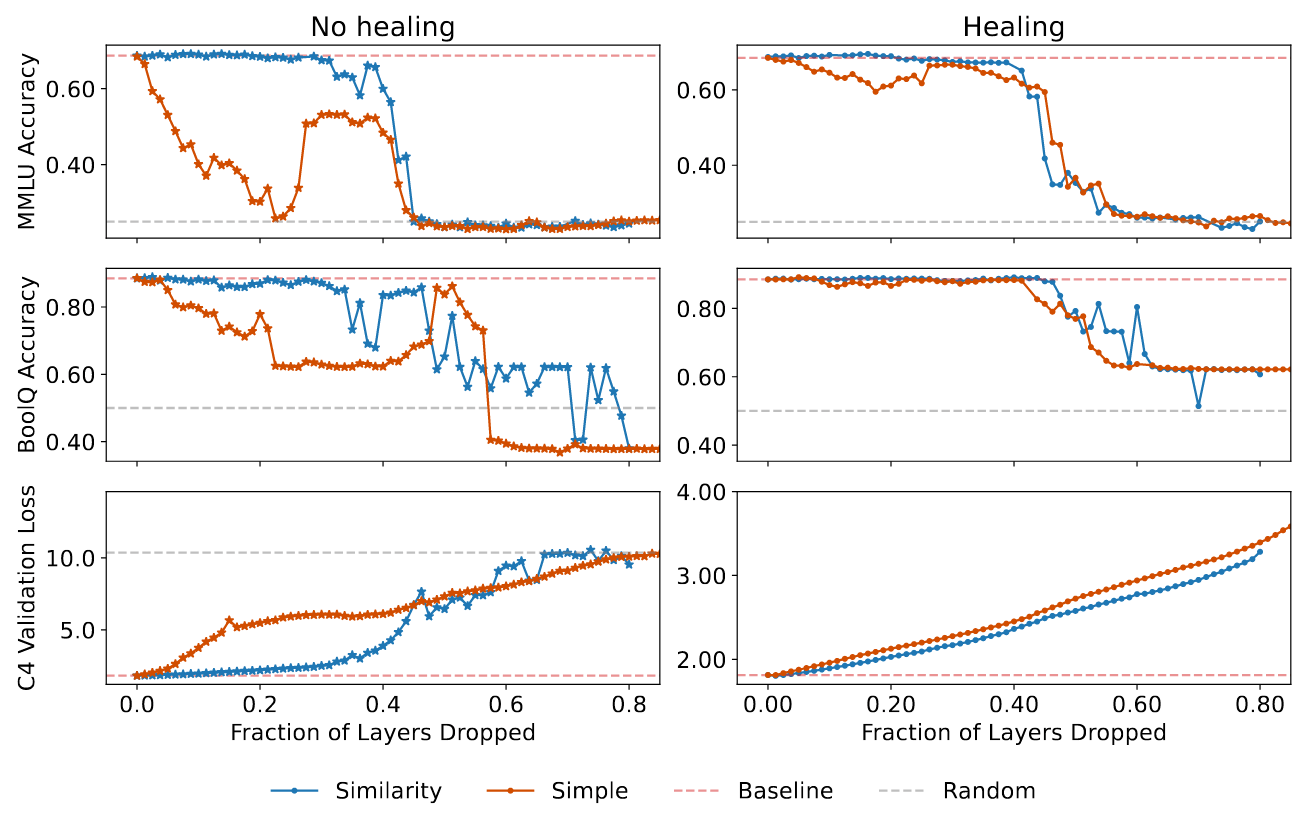
图 5:使用简单剪枝启发式(红色实线)对 Llama-2-70B 进行的评估,同时显示的还有相似性信息剪枝策略(蓝色实线)的得分、未经剪枝的 Llama-2-70B 的得分(红色虚线)以及随机猜测的得分(灰色虚线)。(左:愈合前,右:愈合后;上:MMLU,中:BoolQ,下:MMLU: BoolQ, Bottom: C4 验证损失)。在未进行愈合的情况下,简单启发式在所有测试中的表现都很差;而在进行愈合后,两种方法的得分非常接近。
- 一方面,简单启发式在没有愈合剪枝造成损伤的情况下表现相当糟糕:随着剪枝分数的增加,QA 基准的准确率迅速下降到(接近)随机水平,即使进行少量剪枝,loss 也开始迅速增加。
- 另一方面,两种剪枝策略在不同评估中的结果在愈合后相当:
- 对于 QA 基准,相似性信息算法略微更好地保持了阶段转换前的准确性,尽管简单算法可能将阶段转换推向了略微更大的剪枝派别;
- 对于 loss,曲线几乎相互重叠,尽管相似性信息策略在所有剪枝量下都略微优于其他策略。这些实验有力地证明,剪枝后微调的目的是愈合剪枝造成的损伤,而不是获取额外的知识。
相关文章:
论文阅读:The Unreasonable Ineffectiveness of the Deeper Layers 层剪枝与模型嫁接的“双生花”
作者实证研究了针对流行的开放式预训练 LLM 系列的简单层修剪策略,发现在不同的 QA 基准上,直到去掉一大部分(最多一半)层(Transformer 架构)后,性能的下降才会降到最低。为了修剪这些模型&…...
Python批量备份华为设备配置到FTP服务器
Excel表格存放交换机信息: 备份文件夹效果图: Windows系统配置计划任务定时执行python脚本: Program/script:C:\Python\python.exe Add arguments (optional): D:\Python_PycharmProjects\JunLan_pythonProje…...
中确保资源及时释放的策略)
Java虚拟机(JVM)中确保资源及时释放的策略
在Java虚拟机(JVM)中,内存管理主要是通过垃圾回收(Garbage Collection, GC)来自动处理的。Java开发者通常不需要(也不应该)显式地释放对象内存,因为JVM的垃圾回收器会自动处理不再使…...

04-Fortran基础--Fortran数组和矩阵运算
04-Fortran基础--Fortran数组和矩阵运算 fortarn中对数组和矩阵的主要操作和内置运算包括: 数组的声明和初始化:fortarn中可以通过声明和初始化来创建数组。例如: integer :: my_array(3) [1, 2, 3] ! 声明一个包含3个整数的数组并初始化数…...
el-select选项框内容过长
利用popper-class实现选项框内容过长,截取显示功能: <el-select popper-class"popper-class" :popper-append-to-body"false" v-model"value" placeholder"请选择"><el-optionv-for"item in opt…...

K8S面试题学习5
参考K8S面试题(史上最全 持续更新)_kubernetes常见面试题-CSDN博客做的个人总结,规划是每天看10题,thx! 1. 请详述kube-proxy原理? 每个node节点都会运行一个kube-proxy的进程,核心功能是将service的访问…...
字符以及字符串函数
字符以及字符串函数 求字符串长度strlen 长度不受限制的字符串函数strcpystrcatstrcmp 长度受限制的字符串函数strncpystrncatstrncmp 字符串查找strstrstrtok 错误信息报告strerror 字符分类函数字符转换函数tolowertoupper 内存操作函数memcpymemmovememcmpmemset 这篇文章注…...

记录解决问题--redis ssl连接
1.问题场景 springboot连接redis启动报错,感觉是没连上redis,本地是正常启动的,但是本地不是ssl连接。 2.redis ssl连接知识 ①一般不开启ssl的连接,直接连接即可,有密码输密码。 ②不受信的ssl连接,也就…...

买卖股票的最佳时机
dp[i][0] 表示第i天持有股票所得最多现金,相当于买的价格最低,卖的价格最高 持有股票状态为0,不持有为1 用二维数组表示天数和是否持有, i-1天就持有,或者第i天买入 class Solution {public int maxProfit(int[] p…...

Linux部署安装
Linux部署安装 Linux中有两种软件安装包 一、源码包 软件的源代码是软件的原始数据,但是源代码不能直接在计算机中直接运行安装。 需要通过编译将源代码转换为计算机可以识别的机器语言,之后才可以进行安装。 源码包安装的方式可以在安装过程中发根据…...

docker搭建mysql集群实现主从复制
前言 随着业务的增长,一台数据服务器已经满足不了需求了,负载过重。这个时候就需要减压了,实现负载均衡和读写分离,一主一丛或一主多从。 主服务器只负责写,而从服务器只负责读,从而提高了效率减轻压力。 …...
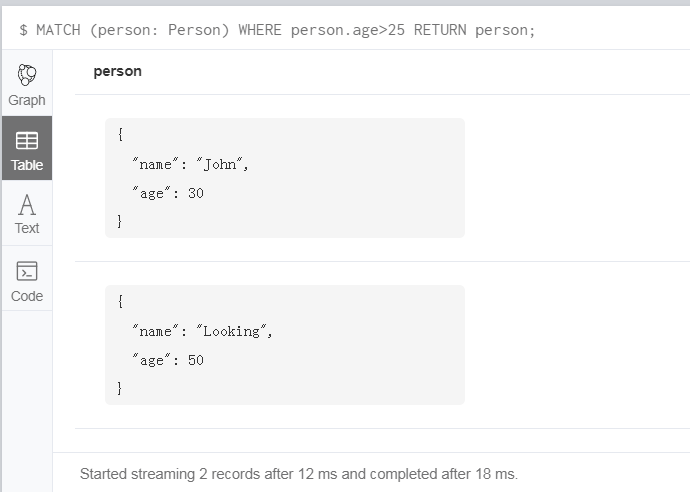
Neo4j 之安装和 CQL 基本命令学习
正常使用结构化的查询语言 SQL(Structured Query Language)较多一些,但是像 Neo4j 这种非结构化的图形数据库来说,就不得不学习下 CQL(Cypher Query Language)语言了。如果你之前学过 《离散数学》或《图论…...
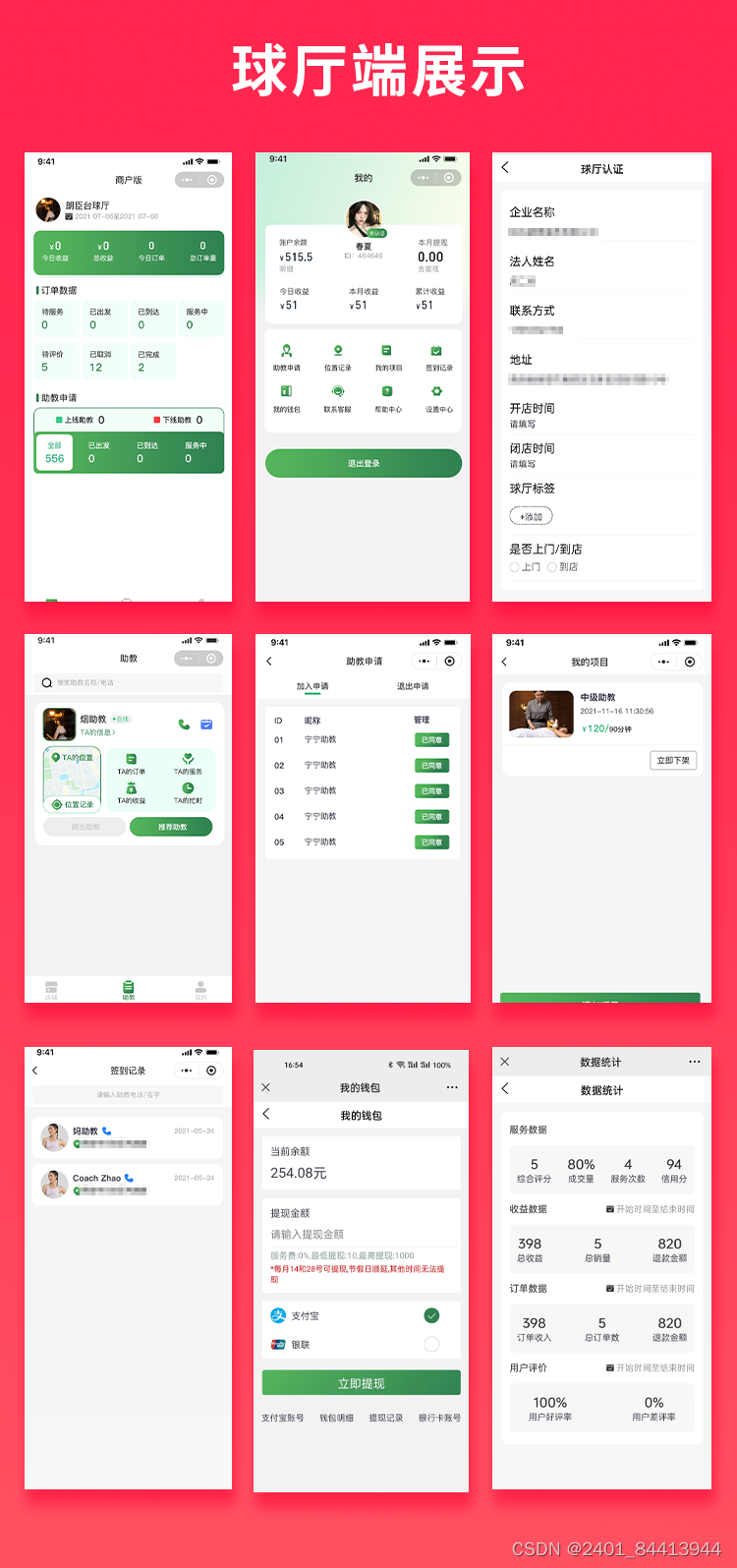
【全开源】JAVA台球助教台球教练多端系统源码支持微信小程序+微信公众号+H5+APP
功能介绍 球厅端:球厅认证、教练人数、教练的位置记录、助教申请、我的项目、签到记录、我的钱包、数据统计 教练端:我的页面,数据统计、订单详情、保证金、实名认证、服务管理、紧急求助、签到功能 用户端:精准分类、我的助教…...

机器学习-如何为模型选择评估指标?
为机器学习模型选择评估指标是一个关键步骤,因为它直接关联到如何衡量模型的性能。以下是选择评估指标的一些建议: 1、理解问题类型: 分类问题:对于二分类问题,常见的评估指标包括准确率、精确率、召回率、F1分数、R…...

【AutoGPT】踩坑帖(follow李鱼皮)
本文写于2024年5月7日 参考视频:AutoGPT傻瓜式使用教程真实体验! 对应文章:炸裂的AutoGPT,帮我做了个网站! 平台:GitPod 云托管服务 原仓库已经改动很大,应使用的Repo为:Auto-GPT-ZH…...

机器学习-L1正则/L2正则
机器学习-L1正则/L2正则 目录 1.L1正则 2.L2正则 3.结合 1.L1正则 L1正则是一种用来约束模型参数的技术,常用于机器学习和统计建模中,特别是在处理特征选择问题时非常有用。 想象一下,你在装备行囊准备去旅行,但你的行囊有一…...
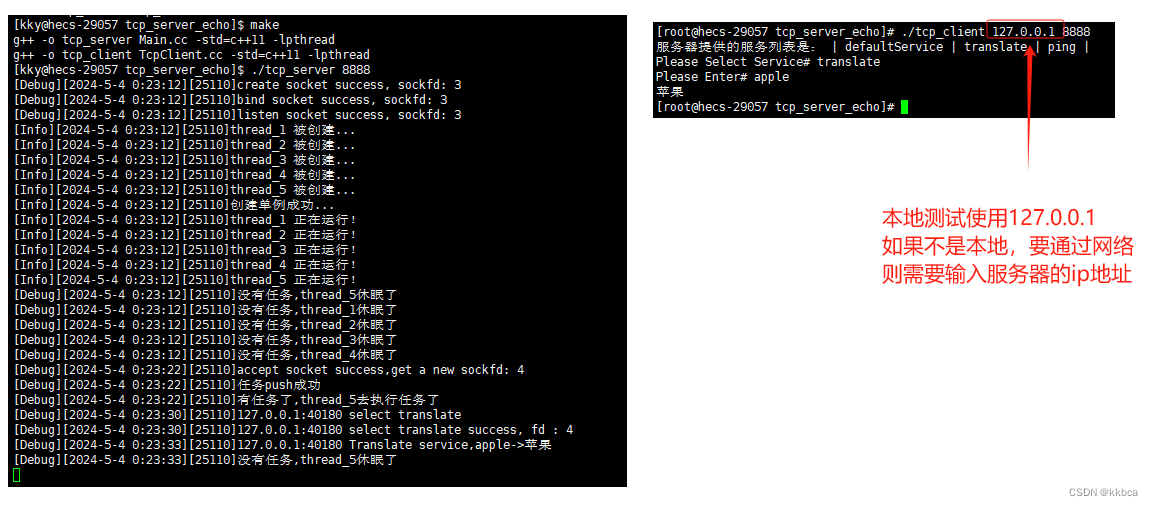
Linux——socket编程之tcp通信
前言 前面我们学习socket的udp通信,了解到了socket的概念与udp的实现方法,今天我们来学习一下面向连接的tcp通信。 一、tcp套接字创建 UDP和TCP都是通过套接字(socket)来实现通信的,因此TCP也得使用socket()接口创建…...

HTTP协议介绍
文章目录 http协议http协议格式GET请求POST请求http客户端实现 http协议 http协议是应用层协议,一般建立在tcp协议的基础之上(当然你的实现非要基于udp也是可以的),也就是说http协议的数据收发是通过tcp协议的。 http协议也分为h…...

elasticsearch安装配置注意事项
安装Elasticsearch时,需要注意以下几个重要事项: 1、版本选择:选择与你系统和其他组件(如Logstash、Kibana)兼容的Elasticsearch版本。 2、Java环境:Elasticsearch是基于Java构建的,因此确保已…...
Istio 流量管理(请求路由、流量转移、请求重试、流量镜像、故障注入、熔断等)介绍及使用
一、Istio 流量管理 Istio是一个开源的服务网格,它为分布式微服务架构提供了网络层的抽象。它使得服务之间的通信变得更为可靠、安全,并且提供了细粒度的流量管理、监控和策略实施功能。Istio通过在服务之间插入一个透明的代理(Envoy&#x…...

Mergo入门指南:10分钟学会Go结构体与映射合并技巧
Mergo入门指南:10分钟学会Go结构体与映射合并技巧 【免费下载链接】mergo Mergo: merging Go structs and maps since 2013 项目地址: https://gitcode.com/gh_mirrors/me/mergo Mergo是一个强大的Go语言库,专门用于合并结构体(struct…...

如何生成USearch API文档的PDF手册:快速创建可打印版本指南
如何生成USearch API文档的PDF手册:快速创建可打印版本指南 【免费下载链接】usearch Fastest Open-Source Search & Clustering engine for Vectors & 🔜 Strings in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoLang,…...

SimpleMem:基于语义无损压缩的三阶段 Agent 终身记忆框架
📌 一句话总结: 本工作提出 SimpleMem,一个基于语义结构化压缩的终身记忆系统,通过“压缩—合成—规划”三阶段机制,在固定上下文预算下显著提升 LLM Agent 的长期交互能力与检索效率。 🔍 背景问题&…...

中科蓝讯AB565X蓝牙耳机通话电流音、回声、杂音?手把手教你用PC工具调通它
中科蓝讯AB565X蓝牙耳机通话问题全解析:从硬件排查到参数调优实战指南 当你手握一款基于中科蓝讯AB565X芯片的蓝牙耳机样机,却在通话测试中遭遇电流音、回声和杂音时,那种挫败感我深有体会。作为深耕音频调试领域多年的工程师,我经…...

QT:Tab Widget的进阶应用与实战技巧
1. Tab Widget的动态管理技巧 第一次用QT做带标签页的界面时,我习惯在设计器里把Tab页都固定好。直到接手一个需要动态加载配置文件的仪表盘项目,才发现动态增删Tab才是真实开发中的常态。比如用户点击"新建图表"按钮时,我们需要实…...
)
Origin绘图进阶:如何在现有图形上叠加散点图与等高线(附完整操作步骤)
Origin高级绘图技巧:散点图与等高线的完美叠加实战指南 科研数据可视化中,单一图表往往难以全面展示复杂数据关系。当您需要在同一坐标系中同时呈现离散数据点与连续趋势时,散点图与等高线的组合堪称黄金搭档。这种混合图表特别适合展现发动机…...

别再手动传文件了!用MinIO Java SDK的预签名URL功能,5分钟搞定安全文件分享
别再手动传文件了!用MinIO Java SDK的预签名URL功能,5分钟搞定安全文件分享 上周团队新来的架构师老张给我看了一个令人后怕的日志:某个内部系统的文件下载接口在24小时内被调用了17万次,而实际业务需求只有不到200次。调查发现是…...

Anthropic泄露新一代Claude Mythos 模型,具备网络安全漏洞检测优势
配置错误曝光新模型Anthropic PBC 内容管理系统的一处配置错误意外泄露了其正在测试的新型大语言模型 Claude Mythos。该公司周四向《财富》杂志证实,工程师已完成该模型的训练工作,目前正与早期客户进行试点测试。Anthropic 强调这是其"迄今为止构…...

AudioLDM-S与LangGraph:构建音效生成工作流引擎
AudioLDM-S与LangGraph:构建音效生成工作流引擎 1. 引言 想象一下这样的场景:电影制作人需要为一场雨夜追逐戏配乐,传统的工作流程需要先搜索音效库,筛选合适的雨声、脚步声、轮胎摩擦声,然后进行剪辑、混音…...

自动驾驶模拟平台模型配置全指南:从技术选型到场景验证
自动驾驶模拟平台模型配置全指南:从技术选型到场景验证 【免费下载链接】alpasim 项目地址: https://gitcode.com/GitHub_Trending/al/alpasim 一、AlpaSim核心价值:构建自动驾驶研发闭环 AlpaSim作为开源自动驾驶模拟平台,通过模块…...