golang中三种线程安全的MAP
一、map 是什么
map 是 Go 中用于存储 key-value 关系数据的数据结构,类似 C++ 中的 map,Python 中的 dict。Go 中 map 的使用很简单,但是对于初学者,经常会犯两个错误:没有初始化,并发读写。
1、未初始化的 map 都是 nil,直接赋值会报 panic。map 作为结构体成员的时候,很容易忘记对它的初始化。
2、并发读写是我们使用 map 中很常见的一个错误。多个协程并发读写同一个 key 的时候,会出现冲突,导致 panic。
Go 内置的 map 类型并没有对并发场景场景进行优化,但是并发场景又很常见,如何实现线程安全(并发安全)的 map就很重要了
二、三种线程安全的 map
1、加读写锁(RWMutex)
这是最容易想到的一种方式。常见的 map 的操作有增删改查和遍历,这里面查和遍历是读操作,增删改是写操作,因此对查和遍历需要加读锁,对增删改需要加写锁。
以 map[int]int 为例,借助 RWMutex,具体的实现方式如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
|
2、分片加锁
通过读写锁 RWMutex 实现的线程安全的 map,功能上已经完全满足了需要,但是面对高并发的场景,仅仅功能满足可不行,性能也得跟上。锁是性能下降的万恶之源之一。所以并发编程的原则就是尽可能减少锁的使用。当锁不得不用的时候,可以减小锁的粒度和持有的时间。
在第一种方法中,加锁的对象是整个 map,协程 A 对 map 中的 key 进行修改操作,会导致其它协程无法对其它 key 进行读写操作。一种解决思路是将这个 map 分成 n 块,每个块之间的读写操作都互不干扰,从而降低冲突的可能性。
Go 比较知名的分片 map 的实现是 orcaman/concurrent-map,它的定义如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
ConcurrentMap 其实就是一个切片,切片的每个元素都是第一种方法中携带了读写锁的 map。
这里面 GetShard 方法就是用来计算每一个 key 应该分配到哪个分片上。
再来看一下 Set 和 Get 操作。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
Get 和 Set 方法类似,都是根据 key 用 GetShard 计算出分片索引,找到对应的 map 块,执行读写操作。
3、sync 中的 map
分片加锁的思路是将大块的数据切分成小块的数据,从而减少冲突导致锁阻塞的可能性。如果在一些特殊的场景下,将读写数据分开,是不是能在进一步提升性能呢?
在内置的 sync 包中(Go 1.9+)也有一个线程安全的 map,通过将读写分离的方式实现了某些特定场景下的性能提升。
其实在生产环境中,sync.map 用的很少,官方文档推荐的两种使用场景是:
a) when the entry for a given key is only ever written once but read many times, as in caches that only grow.
b) when multiple goroutines read, write, and overwrite entries for disjoint sets of keys.
两种场景都比较苛刻,要么是一写多读,要么是各个协程操作的 key 集合没有交集(或者交集很少)。所以官方建议先对自己的场景做性能测评,如果确实能显著提高性能,再使用 sync.map。
sync.map 的整体思路就是用两个数据结构(只读的 read 和可写的 dirty)尽量将读写操作分开,来减少锁对性能的影响。
下面详细看下 sync.map 的定义和增删改查实现。
sync.map 数据结构定义
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
|
Map 的定义中,read 字段通过 atomic.Values 存储被高频读的 readOnly 类型的数据。dirty 存储
Store 方法
Store 方法用来设置一个键值对,或者更新一个键值对。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
|
第2-6行,通过 cas 进行键值对更新,更新成功直接返回。
第8-28行,通过互斥锁加锁来处理处理新增键值对和更新失败的场景(键值对被标记删除)。
第11行,再次检查 read 中是否已经存在要 Store 的 key(双检查是因为之前检查的时候没有加锁,中途可能有协程修改了 read)。
如果该键值对之前被标记删除,先将这个键值对写到 dirty 中,同时更新 read。
如果 dirty 中已经有这一项了,直接更新 read。
如果是一个新的 key。dirty 为空的情况下通过复制 read 创建 dirty,不为空的情况下直接更新 dirty。
Load 方法
Load 方法比较简单,先是从 read 中读数据,读不到,再通过互斥锁锁从 dirty 中读数据。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
这里需要注意的是,如果出现多次从 read 中读不到数据,得到 dirty 中读取的情况,就直接把 dirty 升级成 read,以提高 read 效率。
Delete 方法
下面是 Go1.13 中 Delete 的实现方式,如果 key 在 read 中,就将值置成 nil;如果在 dirty 中,直接删除 key。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
补充说明一下,delete() 执行完之后,e.p 变成 nil,下次 Store 的时候,执行到 dirtyLocked() 这一步的时候,会被标记成 enpunged。因此在 read 中 nil 和 enpunged 都表示删除状态。
sync.map 总结
上面对源码粗略的梳理了一遍,最后在总结一下 sync.map 的实现思路:
-
读写分离。读(更新)相关的操作尽量通过不加锁的 read 实现,写(新增)相关的操作通过 dirty 加锁实现。
-
动态调整。新写入的 key 都只存在 dirty 中,如果 dirty 中的 key 被多次读取,dirty 就会上升成不需要加锁的 read。
-
延迟删除。Delete 只是把被删除的 key 标记成 nil,新增 key-value 的时候,标记成 enpunged;dirty 上升成 read 的时候,标记删除的 key 被批量移出 map。这样的好处是 dirty 变成 read 之前,这些 key 都会命中 read,而 read 不需要加锁,无论是读还是更新,性能都很高。
总结了 sync.map 的设计思路后,我们就能理解官方文档推荐的 sync.map 的两种应用场景了。
三、总结
Go 内置的 map 使用起来很方便,但是在并发频繁的 Go 程序中很容易出现并发读写冲突导致的问题。本文介绍了三种常见的线程安全 map 的实现方式,分别是读写锁、分片锁和 sync.map。
较常使用的是前两种,而在特定的场景下,sync.map 的性能会有更优的表现。
相关文章:

golang中三种线程安全的MAP
一、map 是什么 map 是 Go 中用于存储 key-value 关系数据的数据结构,类似 C 中的 map,Python 中的 dict。Go 中 map 的使用很简单,但是对于初学者,经常会犯两个错误:没有初始化,并发读写。 1、未初始化的…...

C++笔试强训day16
目录 1.字符串替换 2.神奇数 3.DNA序列 1.字符串替换 链接 简单的遍历替换即可: class Solution { public:string formatString(string str, vector<char>& arg) {string ret;int k 0;for (int i 0; i < str.size(); i){if (str[i] %){ret arg…...

spsr 的恢复出错,导致 thumb 指令集的 it 条件运行指令运行异常,清晰的调试思路帮助快速解决问题
记一次调试过程 这是一个在 arm 架构上的 RTOS 上的调试过程。问题现象为使用 thumb 指令集的 libgcc 库的情况下,浮点运算随机出错。经过一番追踪调试,逐步缩小问题范围,最后定位问题,成功解决。 场景 在某款的国产 RTOS 上&a…...

mysql binlog 如何区分db
binlog不是InnoDB存储引擎特有的日志文件,是属于mysql server自己的日志文件。 提交事务的时候,同时会写入binlog 在MySQL中,Binary Log(binlog)记录了数据库更改操作的所有细节,对于实现数据复制、恢复以…...
ESP32 IDF linux下开发环境搭建
文章目录 介绍升级Python环境下载Python包配置编译环境及安装Python设置环境变量 ESPIDF环境搭建下载esp-idf 代码编译等待下载烧录成功查看串口打印 介绍 esp32 官方文档给的不是特别详细 参考多方资料 最后才完成开发 主要问题在于github下载的很慢本教程适用于ubuntu deban…...

光伏电站智能管理平台功能全面介绍
一、介绍 光伏电站智能管理平台专门为了光伏电站服务的融合了项目沟通、在线设计、施工管理、运维工单等多智能光伏管理系统,可以满足光伏电站建设前期沟通、中期建设和后续维护的一体化智能平台,同时通过组织架构对企业员工进行线上管理和数据同步&…...

SSL证书 购买流程
在购买SSL证书之前,需要知道一点相关的知识,通常包括以下几个环节: 一、确定需求 1、根据需要保护的域名数量,在以下三类中选择合适的证书类型: 单域名证书,只对一个域名(例如abc.com&#x…...
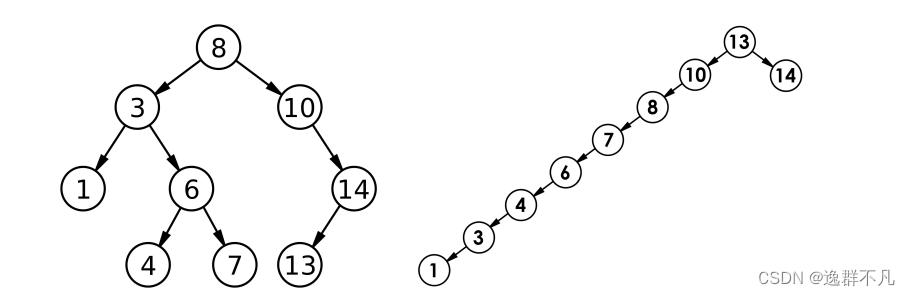
C++|二叉搜索树
一、二叉搜索树的概念 二叉搜索树又称为二叉排序树,它或者是一颗空树,或者是具有以下性质的二叉树: 若它的左子树不为空,则左子树上所有节点的值小于根节点的值若它的右子树不为空,则右子树上所有节点的值都大于根结…...

网页html版面分析-- BeauifulSoup(python 文档解析提取)
介绍 BeauifulSoup 是一个可以从HTML或XML 文件中提取数据的python库;它能通过转换器实现惯用的文档导航、查找、修改文档的方式。 BeauifulSoup是一个基于re开发的解析库,可以提供一些强大的解析功能;使用BeauifulSoup 能够提高提取数据的效…...

第五十八节 Java设计模式 - 适配器模式
Java设计模式 - 适配器模式 我们在现实生活中使用适配器很多。例如,我们使用存储卡适配器连接存储卡和计算机,因为计算机仅支持一种类型的存储卡,并且我们的卡与计算机不兼容。 适配器是两个不兼容实体之间的转换器。适配器模式是一种结构模…...

程序员的归宿。。
大家好,我是瑶琴呀。 相信每个进入职场的人都考虑过自己的职业生涯规划,在不同的年龄段可能面临不同挑战,这点对于 35 的人应该更为感同身受。 对于程序员来说,大部分人的职业道路主要是下面三种:第一条,…...
ROS服务器通信
目录 一、角色 二、流程 注意 三、例子描述 四、srv文件 编译配置文件 vscode配置 五、Server.cpp编写例子 编写CMakeList 六、观察server的效果 七、Client编写例子 编写CMakeList 八、观察Client的结果 九、Client优化(动态输入) 了解argc…...

双向带头循环链表(图解)
文章目录 头节点(哨兵位)双向循环结构头插尾插头删尾删在指定位置之前插入数据删除指定位置之前的数据销毁链表 全部代码结语 单链表地址 头节点(哨兵位) 什么是头节点呢?头节点也叫哨兵节点,他在链表中进行不了任何操作,只是用来放哨用的,在单链表中我们当我们尾插的时候我们…...
富文本编辑器 iOS
https://gitee.com/klkxxy/WGEditor-mobile#wgeditor-mobile 采用iOS系统浏览器做的一款富文本编辑器工具。 原理就是使用WKWebView加载一个本地的一个html文件,从而达到编辑器功能的效果! 由于浏览器的一些特性等,富文本编辑器手机端很难做…...

【OceanBase诊断调优】—— checksum error ret=-4103 问题排查
适用版本 OceanBase 数据库所有版本。 什么是 checksum data checksum:一个 SSTable 中所有宏块内存二进制计算出来的 checksum 值。反映了宏块中的数据和数据分布情况。如果宏块中数据一致但是数据分布不一致,计算出来的 checksum 也不相等。 column…...
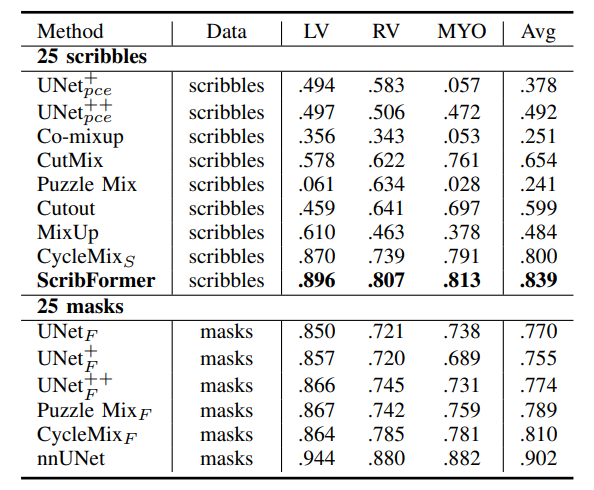
融合Transformer与CNN,实现各任务性能巅峰,可训练参数减少80%
论文er看过来,今天给各位推荐一个热门创新方向:CNNTransformer。 众所周知,CNN通过多层卷积自动学习空间层级特征,能够有效提取图像局部特征。而Transformer通过自注意力机制全局建模,能够有效处理长距离依赖关系。 …...

K8s 多租户管理
一、K8s 多租户管理 多租户是指在同一集群中隔离多个用户或团队,以避免他们之间的资源冲突和误操作。在K8s中,多租户管理的核心目标是在保证安全性的同时,提高资源利用率和运营效率。 在K8s中,该操作可以通过命名空间࿰…...

Java面试题:Synchronized和Lock的对比
Synchronized和Lock对比 语法层面 Synchronized是关键字,源码在jvm中,用c语言实现 使用时,退出同步代码块时会自动释放 Lock是接口,源码由jdk提供,用java语言实现 使用时,需要手动调用unlock方法进行释放 功能层面 都属于悲观锁,具备基本的互斥,同步,锁重入功能 但Lock…...
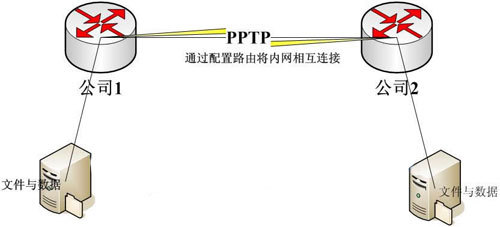
VPN方案和特点
VPN方案和特点 VPN,或者称为虚拟专用网络,是一种保护你的在线安全和隐私的技术。它可以创建一个加密的连接,使你的在线活动对其他人不可见。以下是一些常见的VPN协议和它们的特点: 开放VPN (OpenVPN):这是一种极为可…...
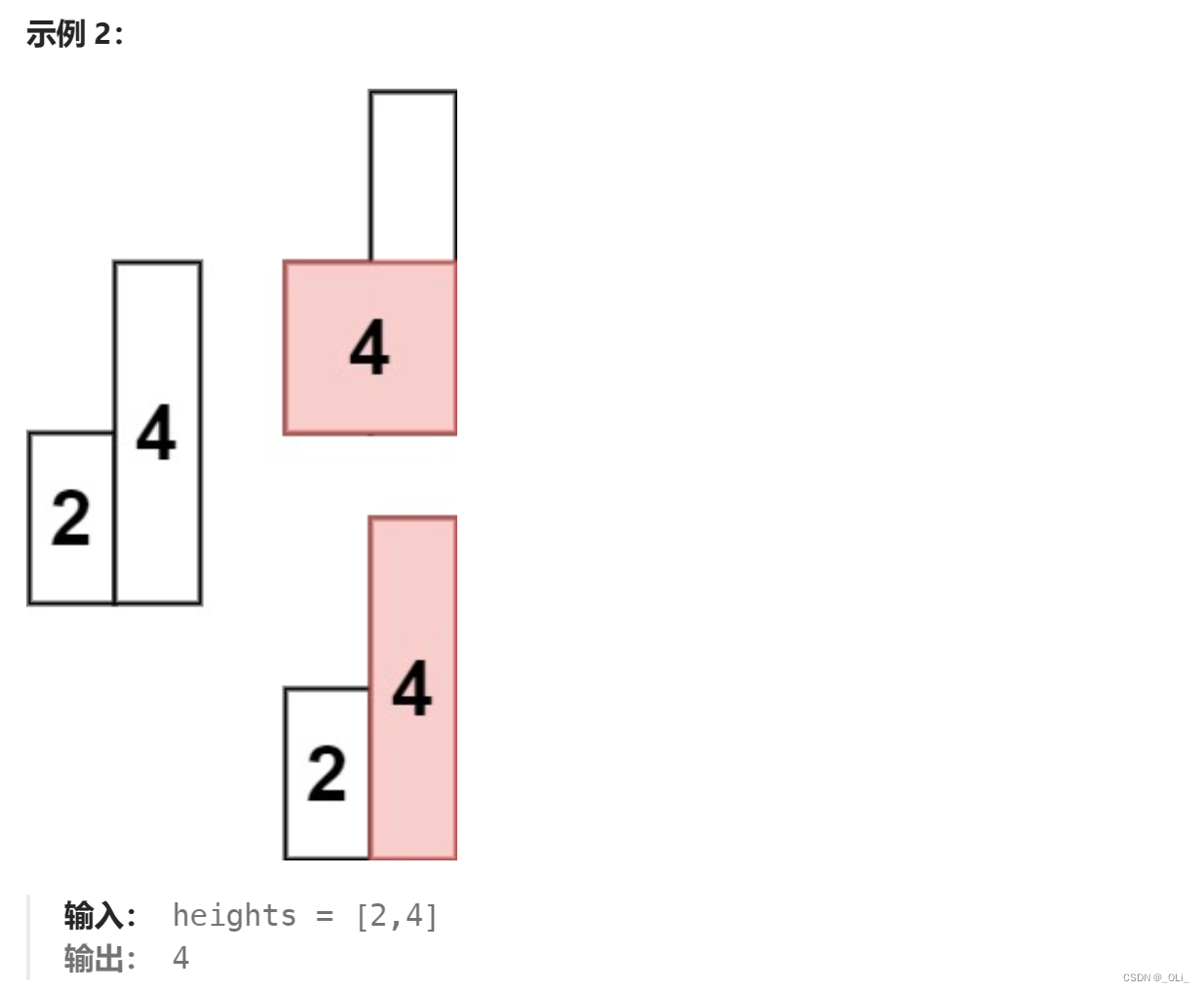
力扣HOT100 - 84. 柱状图中最大的矩形
解题思路: 单调栈 对于一个高度height[ i ],找左右两边均严格小于它的值。 class Solution {public int largestRectangleArea(int[] heights) {int n heights.length;int[] left new int[n];int[] right new int[n];Deque<Integer> mono_st…...

ESP8266红外TCP服务框架:轻量级协议网关设计
1. 项目概述IrServiceBase是专为 ESP8266 系列微控制器(包括 ESP-01、NodeMCU、Wemos D1 Mini 等)设计的 Arduino C 库,其核心定位并非直接驱动红外发射/接收硬件,而是构建一个可复用、可扩展的 TCP/IP 红外服务框架。该库不实现底…...

VectorBT:量化交易分析的高性能解决方案
VectorBT:量化交易分析的高性能解决方案 【免费下载链接】vectorbt Find your trading edge, using the fastest engine for backtesting, algorithmic trading, and research. 项目地址: https://gitcode.com/gh_mirrors/ve/vectorbt 在金融市场的快速变化…...

Realistic Vision V5.1 虚拟摄影棚:网络编程基础之构建简易图像生成API服务器
Realistic Vision V5.1 虚拟摄影棚:网络编程基础之构建简易图像生成API服务器 你是不是也遇到过这样的情况:本地跑通了Realistic Vision V5.1模型,生成效果很棒,但想分享给同事或者集成到自己的应用里,就得让对方也装…...

Wan2GP:革命性开源视频生成平台,仅需6GB VRAM即可创作好莱坞级影片
Wan2GP:革命性开源视频生成平台,仅需6GB VRAM即可创作好莱坞级影片 【免费下载链接】Wan2GP Wan 2.1 for the GPU Poor 项目地址: https://gitcode.com/gh_mirrors/wa/Wan2GP Wan2GP(GitHub加速计划)是一款专为GPU资源有限…...

ArcGIS Pro 3.0 气象数据处理实战:如何从365天的nc文件中提取单日降水数据
ArcGIS Pro 3.0 气象数据处理实战:从365天nc文件中精准提取单日降水数据 气象数据作为地理信息科学中的重要组成部分,其处理效率直接影响研究进度和成果质量。在众多气象数据格式中,NetCDF(.nc)因其结构化存储和多维数…...

Font-Awesome-SVG-PNG 核心原理:深入解析SVG到PNG的转换机制
Font-Awesome-SVG-PNG 核心原理:深入解析SVG到PNG的转换机制 【免费下载链接】Font-Awesome-SVG-PNG Font Awesome split to individual SVG and PNG files of different sizes along with Node.JS based generator 项目地址: https://gitcode.com/gh_mirrors/fo/…...

5分钟精通:phone2qq工具手机号查询QQ号全攻略
5分钟精通:phone2qq工具手机号查询QQ号全攻略 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 在数字化办公与社交日益融合的今天,当你需要登录历史QQ账号却只记得绑定手机号时,如何快速建立数字身…...

告别网线乱绕!实测Windows 10/11的‘移动热点’与‘网络共享’到底哪个更适合给开发板共享网络
Windows网络共享方案深度评测:移动热点 vs 适配器共享 每次在工作室调试开发板时,最头疼的就是网线缠绕的问题。作为嵌入式开发者,我们经常需要为各种开发板(比如STM32、树莓派或者RK3588套件)提供网络连接。Windows系…...

从学习到实战:用快马ai生成企业级java博客项目,打通知识应用最后一公里
今天想和大家分享一个特别实用的Java学习实战经验——如何用InsCode(快马)平台快速搭建一个企业级Java博客系统。这个项目完美覆盖了Java学习路线中的核心知识点,从基础框架到生产级功能一应俱全,特别适合想要通过实战巩固技能的朋友。 项目整体设计思路…...

AI金融分析与智能交易系统:TradingAgents-CN全攻略
AI金融分析与智能交易系统:TradingAgents-CN全攻略 【免费下载链接】TradingAgents-CN 基于多智能体LLM的中文金融交易框架 - TradingAgents中文增强版 项目地址: https://gitcode.com/GitHub_Trending/tr/TradingAgents-CN 在数字化投资时代,如何…...