网络爬虫概述与原理
网络爬虫概述与原理
- 网络爬虫简介
- 狭义上理解
- 功能上理解
- 常见用途
- 总结
- 网络爬虫分类
- 通用网络爬虫
- 聚焦网络爬虫
- 增量网络爬虫
- 深度网络爬虫
- 网络爬虫流程
- 网络爬虫采集策略
- 深度有限搜索策略
- 广度优先搜索策略
网络爬虫简介
通过有效地获取网络资源的方式,便是网络爬虫。网络爬虫(Web Crawler)又被称为网络蜘蛛(Web Spider)或Web信息采集器,是一种按照指定规则、自动抓取或下载网络资源的计算机程序或自动化脚本。
狭义上理解
利用标准网络协议(HTTP、HTTPS),根据网络超链接和信息检索方法(深度优先)遍历网络数据的软件程序。
功能上理解
确定待采集的URL队列,获取每个URL对应的网页内容(如HTML和JSON),根据用户要求解析网页中的字段(如标题),并存储解析得到的数据。
常见用途
大数据环境下舆情分析与监测
政府或企业基于网络爬虫技术,采集论坛评论、在线博客、新闻媒体和微博等网站中的海量数据,采用数据挖掘相关方法(如实体识别、词频统计、文本情感计算、主题识别与演化等),发掘舆情热点、跟踪目标话题,并根据一定的标准采取相应的舆情控制与引导措施。
大数据环境下的用户分析
企业利用网络爬虫技术,采集用户基本信息、用户对企业或商品的看法、观点以及态度等数据、用户之间的互动信息等。基于这些信息,企业可以对用户进行画像,如用户基本属性画像、用户产品特征画像、用户互动那个特征画像等,发掘用户对产品的个性化偏好与需求。同时,也可以分析企业自身产品的优势与顾客反馈情况等。
科研需求
针对网络大数据驱动、多源异构数据驱动的科学研究,必然涉及网络数据采集技术。例如,针对网络中的多源异构数据(如数字、文本、图片和视频等),如何更好地管理与存储所采集的数据、如何进行数据的过滤与融合、如何对数据的可用性进行评估、如何将数据应用到商业分析中等。
总结
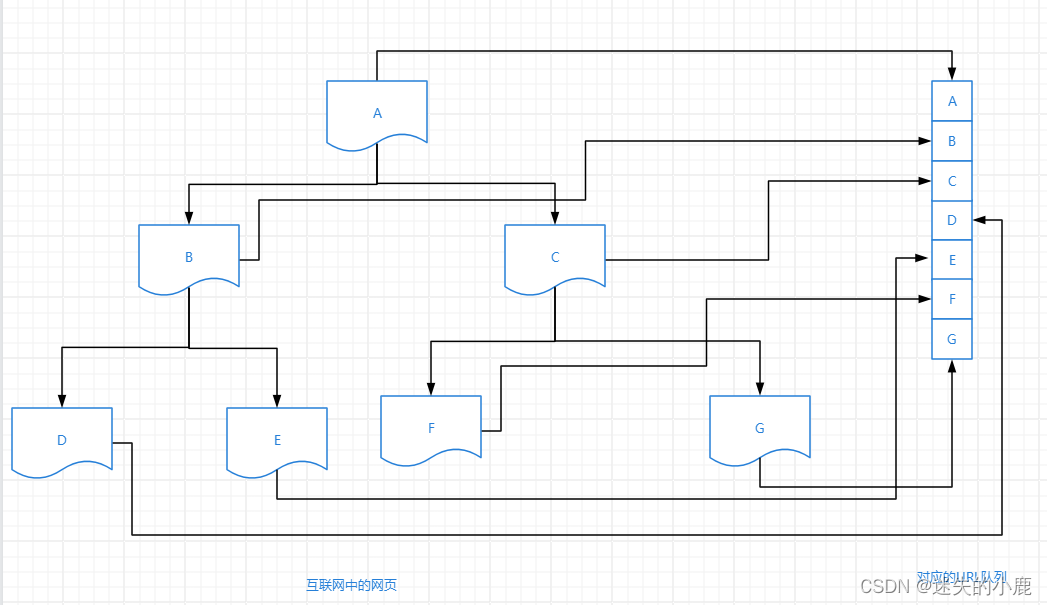
网络爬虫技术在搜索引擎中扮演着信息采集器的角色,是搜索引擎模块中的最基础的部分。搜索引擎Google、百度、必应(Bing)都采用网页爬虫技术采集海量的互联网数据。大致结构如下:

- 利用网络爬虫技术自动化地采集互联网中的网页信息
- 存储采集的信息,在存储过程中,往往需要检测重复内容,从而避免大量重复信息的采集;同时,玩也之间的链接关系也需要存储;原因是链接关系可用来计算网页内容的重要性。
- 数据预处理操作,即提取文字、分词、消除噪音以及链接关系计算等。
- 对预处理的数据建立索引库,方便用户快速查找,常用的索引方法有后缀数组、签名文件和倒排文件。
- 基于用户检索的内容(如用户输入的关键词),搜索引擎从网页索引库中查找符合该关键词的所有网页(结果集),通过对结果集的排序,将最相关的网页返回给用户
网络爬虫分类
网络爬虫按照系统结构和实现技术,可分为4类,即通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫
通用网络爬虫
又称为全网网络爬虫,其在采集数据时,由部分种子URL扩展到整个网络的全部页面,主要应用于搜索引擎数据的采集。这类网络爬虫的数据采集范围较广,数据采集量巨大,对数据采集的速度和存储空间有较高的要求,通常需要深度遍历网站的资源。例如,Apache的子项目Nutch就是一个高效的通用网络爬虫框架,其使用分布式的方式采集数据。
聚焦网络爬虫
又称为主题网络爬虫,是指选择性地采集那些与预先定义好的主题相关的页面。相比于通用网络爬虫,聚焦网络爬虫采集的网页资源少,主要用于满足特定人群对特定领域信息的需求。在聚焦网络爬虫中,需要设计过滤策略,即过滤与所定主题无关的页面。
增量网络爬虫
指对已下载网页采取增量式更新,只采集新产生的或者已发生变化网页的爬虫。增量网络爬虫能够在一定程度上避免了重复采集数据,历史已经采集过的页面不重复采集。增量网络爬虫避免了重复采集数据,可以减少时间和空间上的耗费。针对小规模特定网站的数据采集,在设计网络爬虫时,可构建一个基于时间戳判断是否更新的数据库,通过判断时间戳的先后,判断程序是否继续采集,同时更新数据库中的时间戳信息。
深度网络爬虫
Deep Web爬虫,指对大部分内容不能通过静态链接获取,只有用户提交表单信息才能获取Web页面的爬虫。
网络爬虫流程

- 选取部分种子URL(初始URL),将其放入待采集的队列中。如在java中,可以放入List、LinkedList及Queue中
- 判断URL队列是否为空,如果为空则结束程序的执行,否则执行下一步
- 从待采集的URL队列中取出一个URL,获取URL对应的网页内容。在此步骤中需要使用HTTP响应状态码(200和403)判断是否成功获得了数据,如响应成功则执行解析操作;如响应不成功,则将其重新放入待采集URL队列(这里需要过滤掉无效URL)
- 响应成功后获取的数据,执行源码解析操作。此步骤根据用户需求获取网页内容中的部分字段,如论坛帖子的id、标题和发表时间等
- 对解析后的数据进行数据存储操作
网络爬虫采集策略
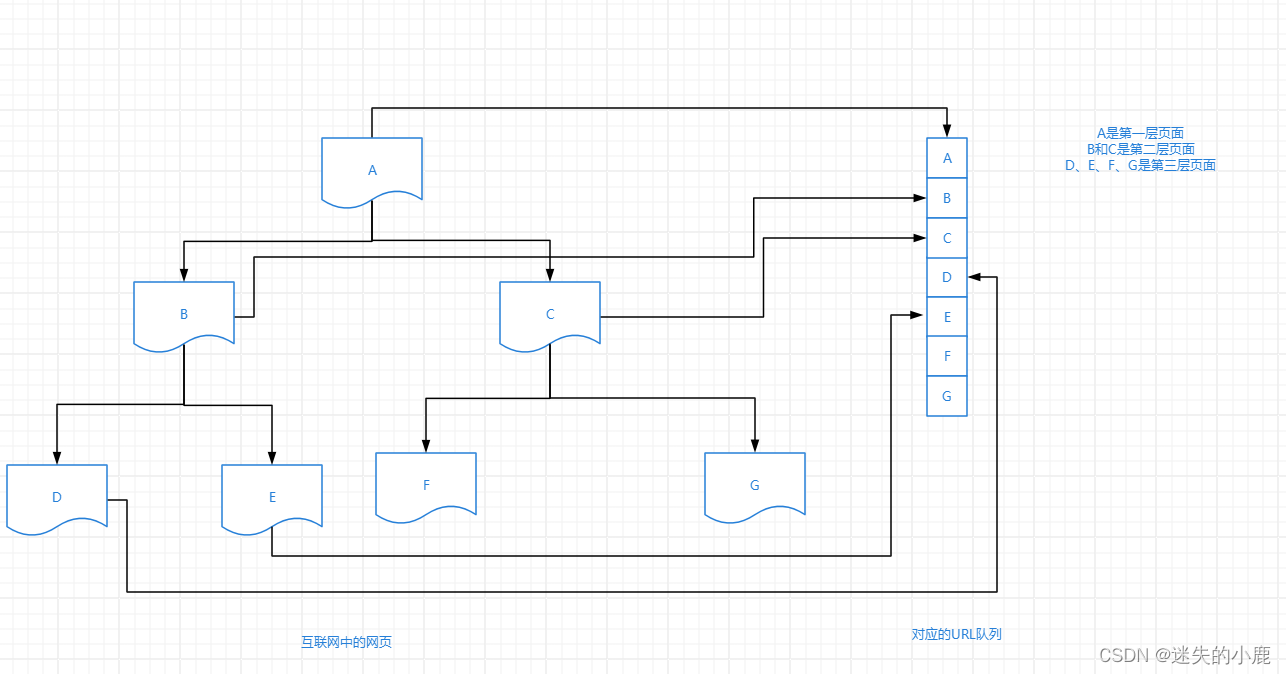
深度有限搜索策略
Depth-First Search,从根节点开始,根据优先级向下遍历该根节点对应的子节点。当访问到某一子节点时,以该子节点为入口,继续向下层遍历,直到没有新的子节点可以继续访问为止。接着使用回溯法,找到没有被访问的节点,以类似的方式进行搜索。
广度优先搜索策略
又称为宽度优先搜索策略,从根节点开始,沿着网络的宽度遍历每一层的节点,如果所有节点均被访问,则终止程序。
相关文章:
网络爬虫概述与原理
网络爬虫概述与原理 网络爬虫简介狭义上理解功能上理解常见用途总结 网络爬虫分类通用网络爬虫聚焦网络爬虫增量网络爬虫深度网络爬虫 网络爬虫流程网络爬虫采集策略深度有限搜索策略广度优先搜索策略 网络爬虫简介 通过有效地获取网络资源的方式,便是网络爬虫。网…...
可视化实验三 Matplotlib库绘图及时变数据可视化
1.1 任务一 1.1.1 恢复默认配置 #绘图风格,恢复默认配置 plt.rcParams.update(plt.rcParamsDefault)#恢复默认配置 或者 plt.rcdefaults() 1.1.2 汉字和负号的设置 import matplotlib.pyplot as plt plt.rcParams["font.sans-serif"]"SimH…...

开启多线程下变量共享与私有问题
开启多线程下变量共享与私有问题 🌵ThreadLocal和Atomic是Java中用于多线程编程的两个重要工具。 ThreadLocal是一个线程局部变量,它为每个线程提供了独立的变量副本,确保每个线程都可以访问自己的变量副本而不会影响其他线程的变量。在多线…...
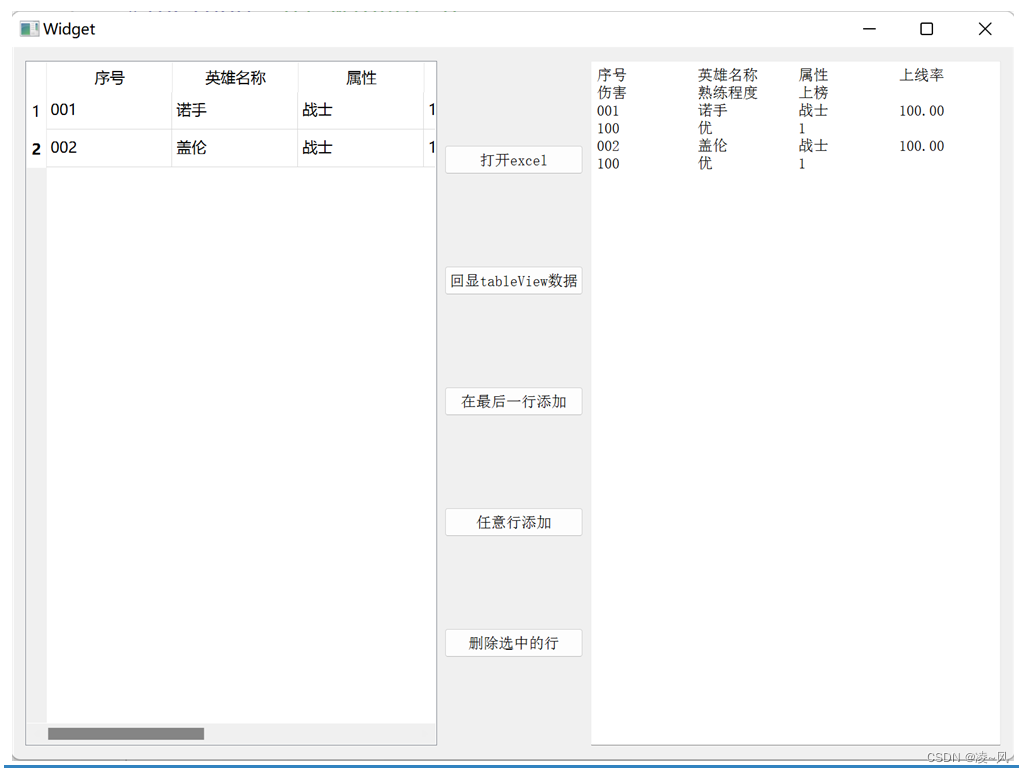
Qt模型视图代理之QTableView应用的简单介绍
往期回顾 Qt绘图与图形视图之绘制带三角形箭头的窗口的简单介绍-CSDN博客 Qt绘图与图形视图之Graphics View坐标系的简单介绍-CSDN博客 Qt模型视图代理之MVD(模型-视图-代理)概念的简单介绍-CSDN博客 Qt模型视图代理之QTableView应用的简单介绍 一、最终效果 二、设计思路 这里…...
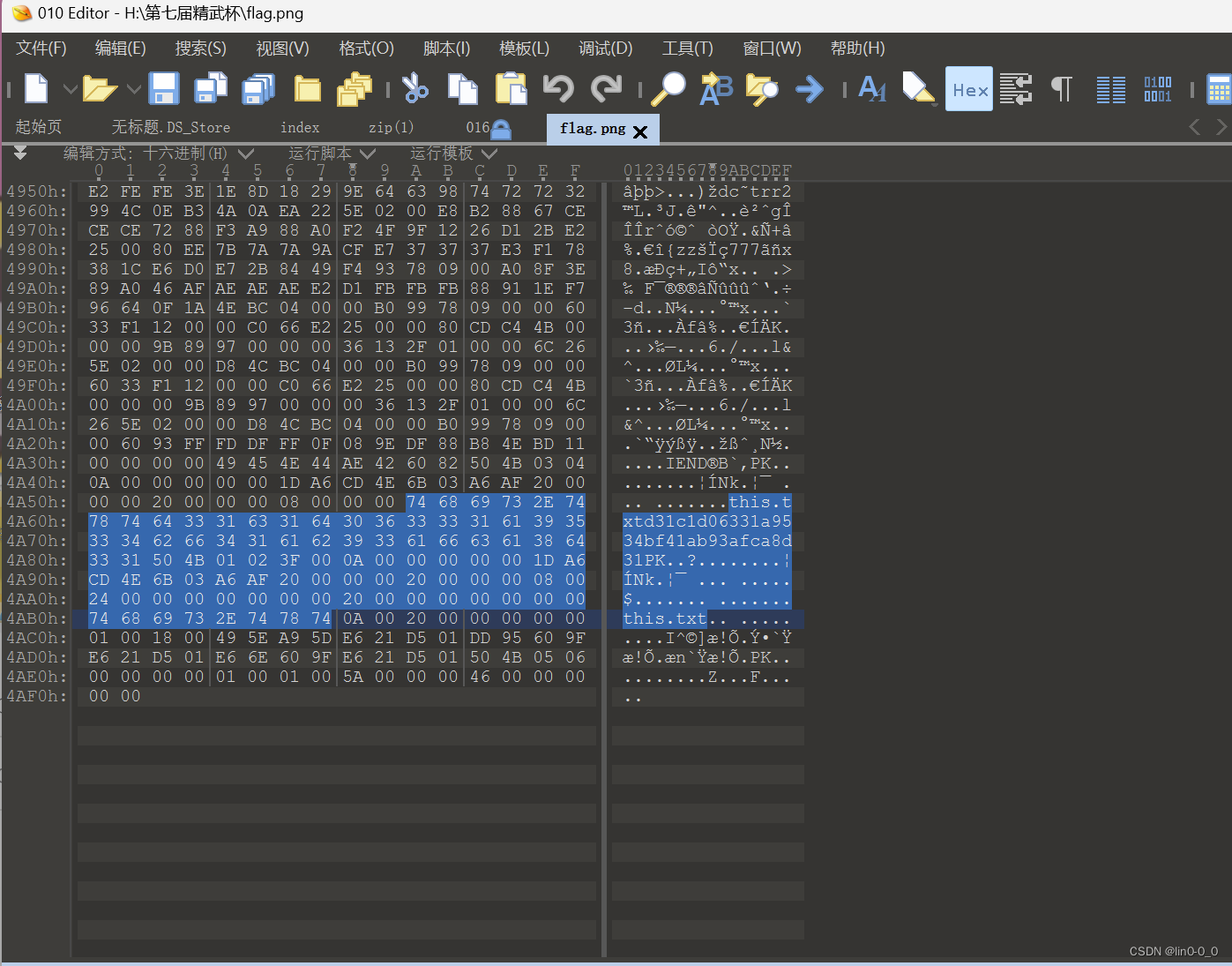
第七届精武杯部分wp
第一部分:计算机和手机取证 1.请综合分析计算机和手机检材,计算机最近一次登录的账户名是 答案:admin 创建虚拟机时直接给出了用户名 2. 请综合分析计算机和手机检材,计算机最近一次插入的USB存储设备串号是 答案:…...
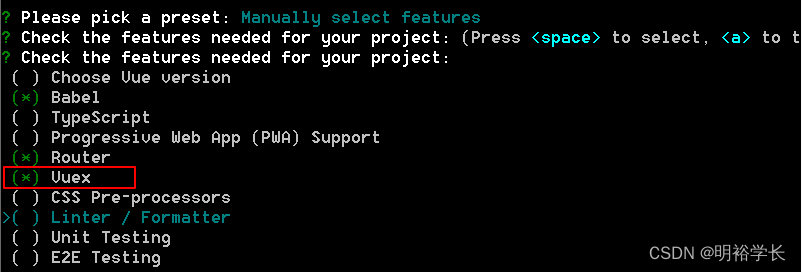
3.2Java全栈开发前端+后端(全栈工程师进阶之路)-前端框架VUE3框架-企业级应用- Vuex
Vuex简介 Vuex概述 Vuex是一个专门为Vue.js应用程序开发的状态管理模式, 它采用集中式存储管理所有组件的公共状态, 并以相应的规 则保证状态以一种可预测的方式发生变化. 试想这样的场景, 比如一个Vue的根实例下面有一个根组件名为App.vue, 它下面有两个子组件A.vue和B.vu…...

整合 Java, Python 和 Scrapy 爬虫以传递和使用参数
这篇博客将详细说明如何从 Java 应用程序调用一个 Python 脚本,并在此过程中传递参数给一个 Scrapy 爬虫。最终目标是让 Java 控制爬虫的行为,如爬取数量和特定的运行参数。 一、Scrapy 爬虫的修改 首先,我们需要确保 Scrapy 爬虫能接收从命…...
)
Android 蓝牙实战——蓝牙音乐播放进度(二十)
对于蓝牙音乐的开发来说,播放进度是一个比较重要的数据参数,这里我们就来分析一下蓝牙音乐播放进度的相关回调。 一、回调流程 1、AvrcpControllerService 源码位置:/packages/apps/Bluetooth/src/com/android/bluetooth/avrcpcontroller/AvrcpControllerService.java /…...
SQL注入实例(sqli-labs/less-1)
初始网页 从网页可知传递的参数名为 id,并且为数字类型 1、得知数据表有多少列 1.1 使用联合查询查找列数(效率低) http://localhost/sqli-labs-master/Less-1/?id1 union select 1,2 -- 1.2 使用order by查找列数(效率高&…...
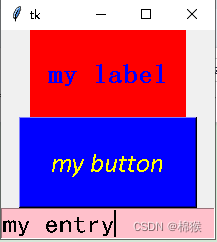
Python中tkinter编程入门3
在使用tkinter创建了窗口之后,可以将一些控件“放置”到窗口中。这些控件包括标签、按键以及输入框等。 1 在窗口中“放置”标签 在窗口中“放置”标签主要有两个步骤,一是创建标签控件,二是将创建好的标签“放置”到窗口上。 1.1 创建标签…...

XMind 2023 v23.05.2660软件安装教程(附软件下载地址)
软件简介: 软件【下载地址】获取方式见文末。注:推荐使用,更贴合此安装方法! XMind 2023 v23.05.2660被视为顶尖思维导图软件,其界面简洁清爽,功能布局直观简单,摒弃繁复不实。尽管体积小巧&a…...
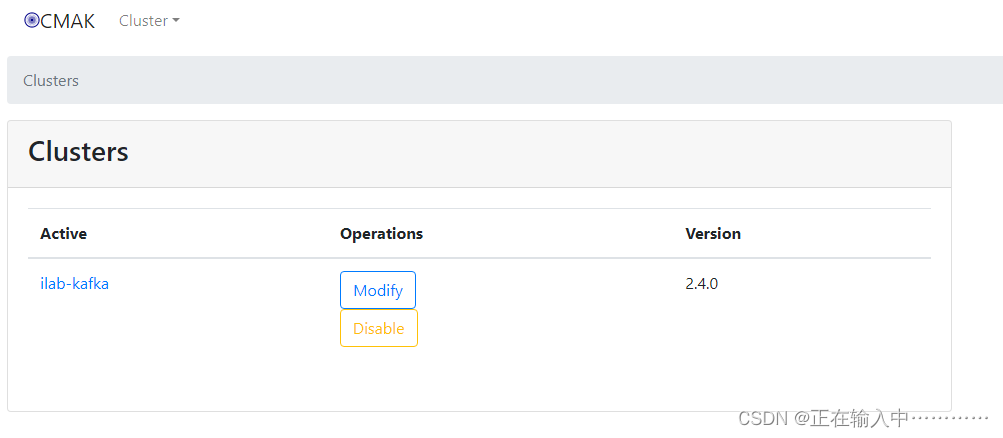
docker compose kafka集群部署
kafka集群部署 目录 部署zookeeper准备工作2、部署kafka准备工作3、编辑docker-compose.yml文件4、启动服务5、测试kafka6、web监控管理 部署zookeeper准备工作 mkdir data/zookeeper-{1,2,3}/{data,datalog,logs,conf} -p cat >data/zookeeper-1/conf/zoo.cfg<<EOF…...
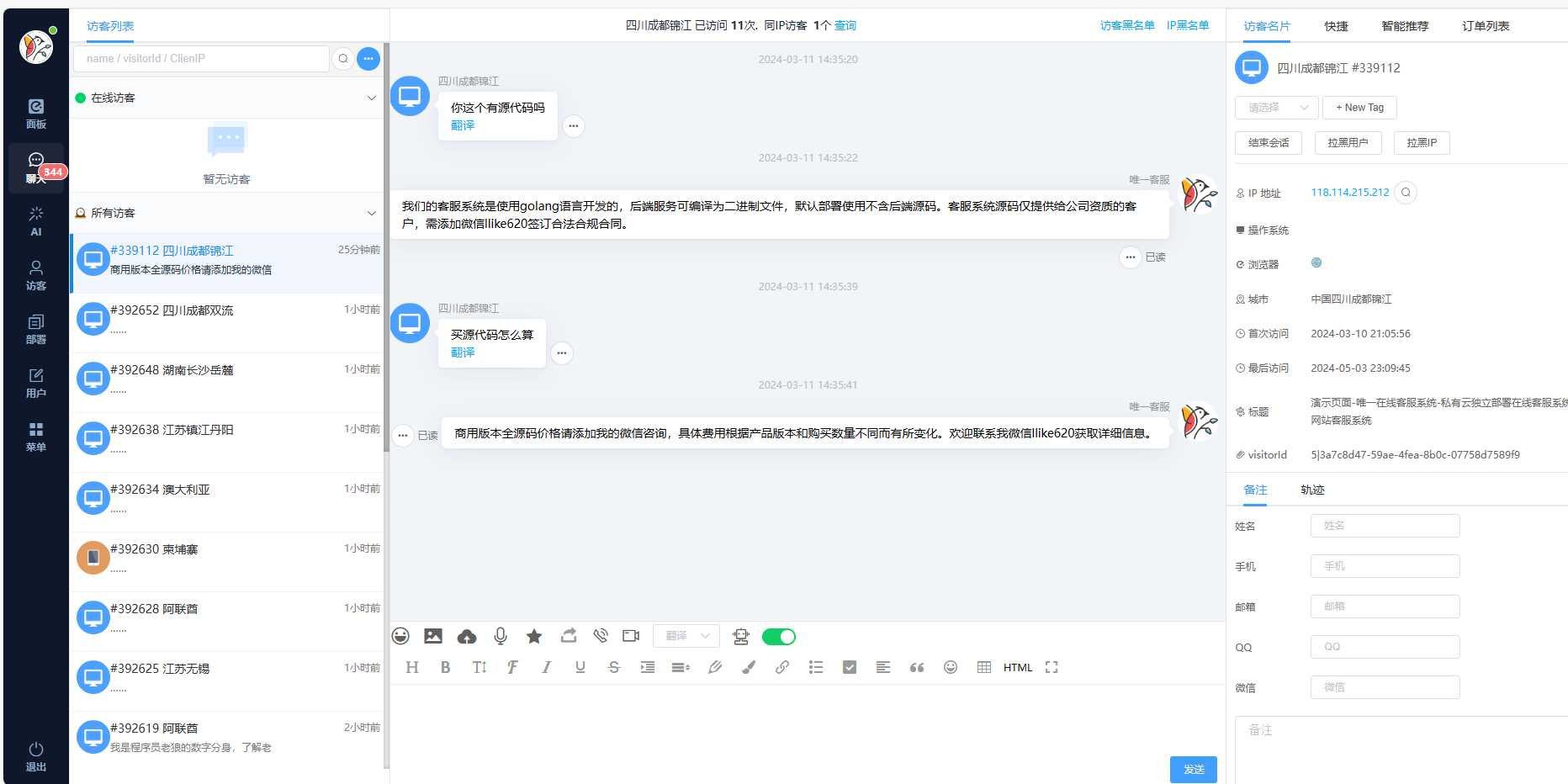
最新版在线客服系统源码
源码介绍 首发最新在线客服系统源码,优化更好并且重构源码布局UI 性能不吃cpu并发快,普通1H2G都能带动最新版只要是服务器都能带动 搭建即可使用,操作简单,易懂 修复了老版本bug 内附有搭建教程 gofly.v1kf.com 运行环境 Nginx 1.20 MySQL 5.7 演示截图...

【比邻智选】MR880A模组
🚀高性价比,5G/4G双模,稳定可靠 🌐功能丰富,5G特性一应俱全 🧩多封装兼容,适配性强,灵活升级智能设备...

超大文件去除重复数据
背景 一个超大200万行文件 第一列是文件名 第二列是文本 第一列有重复的文件名 如何删除重复的文件名和对应的文本 awk ‘!seen[$1]’ 使用一些命令行工具来处理大文件,如awk、sed、grep等。 使用awk命令来去除重复行: bash awk !seen[$1] your_file.…...
ICode国际青少年编程竞赛- Python-4级训练场-列表综合练习
ICode国际青少年编程竞赛- Python-4级训练场-列表综合练习 1、 Flyer[3].step(1) Flyer[7].step(2) Flyer[11].step(1) for i in range(4):Flyer[i * 2].step(1) Flyer[8].step(3)for i in range(3):Dev.turnRight()Dev.step(-5)2、 for i in range(5):Flyer[i5].step(Flyer[…...

苹果电脑怎么安装crossover 如何在Mac系统中安装CrossOver CrossOver Mac软件安装说明
很多Mac的新用户在使用电脑的过程中,常常会遇到很多应用软件不兼容的情况。加上自己以前一直都是用Windows系统,总觉得Mac系统用得很难上手。 其实,用户可以在Mac上安装CrossOver,它支持用户在Mac上运行Windows软件,例…...

C++学习————第十天(string的基本使用)
1、string 对象类的常见构造 (constructor)函数名称 功能说明: string() (重点) 构造空的string类对象,即空字符串 string(const char* s) (重点)…...

华为OD介绍
概念 华为OD是华为提出的一种新的用工方式,其全称是Outsourcing Dispacth,也可以简写为ODP,是华为和北京外企德科人力资源服务上海有限公司联合招聘的简称。华为OD岗位属于华为外包员工的一种,仅限于软件研发类岗位,类…...
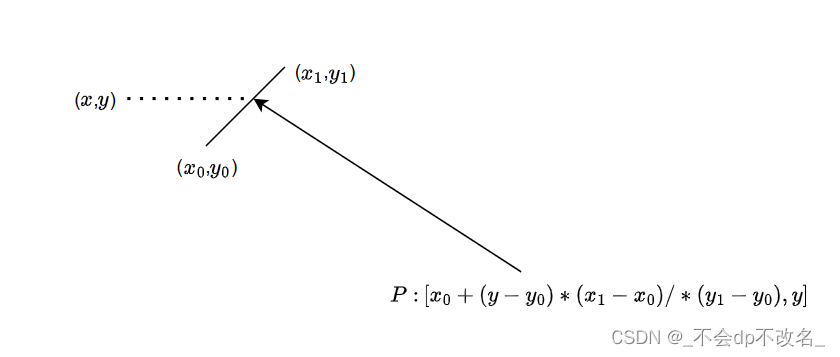
判断点在多边形内部
0. 介绍 网上资料很多,只简单介绍下,方便自己今后的理解。 1. 射线法 从该点引一条射线出来,如果和多边形有偶数个交点,则点在多边形外部。 因为有入必有出,所以从外部引进来的射线一定是交多边形偶数个点。 如图…...

告别繁琐输入:基于SmartConfig与微信的ESP8266/ESP32一键配网实战
1. 为什么我们需要一键配网技术? 每次拿到新的智能设备,最头疼的就是怎么把它连上家里的Wi-Fi。传统的配网方式通常需要你在手机App里手动输入Wi-Fi名称和密码,这个过程不仅繁琐,还容易出错。想象一下,你要给10个智能灯…...

五步解锁老旧Mac新生:OpenCore Legacy Patcher实战指南
五步解锁老旧Mac新生:OpenCore Legacy Patcher实战指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 如何让苹果官方已停更的老旧Mac设备重新焕…...

亿芸甄选商业模式系统开发
亿芸甄选商业模式系统开发:数字化驱动的新零售增长引擎在新零售行业加速数字化转型的背景下,亿芸甄选凭借其创新的商业模式与技术架构,成为美业等细分领域的增长。该系统以“级差分红智能运营”为核心,通过多层次激励机制与数字化…...

4个维度解析Lenovo Legion Toolkit:游戏本性能管理的轻量革命
4个维度解析Lenovo Legion Toolkit:游戏本性能管理的轻量革命 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 1.…...

ICLR 2025论文解读│PointOBB-v2:单点监督下的高效有向目标检测新突破
1. PointOBB-v2:单点监督的革命性突破 有向目标检测一直是计算机视觉领域的重要研究方向,特别是在遥感图像分析、自动驾驶和工业检测等实际应用中。传统的有向边界框(OBB)标注需要人工精确标注目标的旋转角度和四个顶点坐标&…...

GyroFlow:用陀螺仪数据重塑视频稳定技术
GyroFlow:用陀螺仪数据重塑视频稳定技术 【免费下载链接】gyroflow Video stabilization using gyroscope data 项目地址: https://gitcode.com/GitHub_Trending/gy/gyroflow 在数字影像创作领域,画面稳定性直接决定作品专业度。无论是运动相机拍…...

深入解析AUTOSAR通信模块:从信号抽象到多路CAN配置
1. AUTOSAR通信模块的核心价值 第一次接触AUTOSAR通信模块时,我被它复杂的层级关系绕得头晕。直到在实车上调试快充CAN信号时,才真正理解这种架构设计的精妙之处。简单来说,AUTOSAR的Com模块就像个智能邮局,负责把应用层产生的各种…...
)
Allegro PCB设计必备:3分钟搞定带钻孔数据的DXF文件导出(附常见错误排查)
Allegro PCB设计实战:高效导出带钻孔数据的DXF文件全攻略 在PCB设计领域,Allegro作为行业标杆工具,其文件输出质量直接关系到生产制造的准确性。特别是当设计需要与其他CAD系统协作或提交给PCB制造商时,DXF文件的完整性至关重要。…...

高压柔性输电系统中的6脉冲与12脉冲晶闸管控制HVDC仿真模型说明文档
高压柔性输电系统6脉冲,12脉冲晶闸管控制HVDC的仿真模型,说明文档江湖上流传着这么一句话:"搞HVDC不玩晶闸管,就像吃火锅不放辣"。今天咱们就扒一扒那些藏在MATLAB/Simulink里的6脉冲和12脉冲换流器秘密。先说个冷知识&…...

游戏存档终极备份指南:用Ludusavi保护你的游戏进度
游戏存档终极备份指南:用Ludusavi保护你的游戏进度 【免费下载链接】ludusavi Backup tool for PC game saves 项目地址: https://gitcode.com/gh_mirrors/lu/ludusavi 你是否曾因电脑重装、系统崩溃或误操作而丢失珍贵的游戏存档?数百小时的游戏…...