1分钟搞定Pandas DataFrame创建与索引

1.DataFrame介绍
DataFrame 是一个【表格型】的数据结构,可以看作是【由Series组成的字典】(共用同一个索引)。DataFrame 由按一定顺序排列的多列数据组成。设计初衷是将 Series 的使用场景从一维扩展到多维。DataFrame 既有行索引,也有列索引。
-
行索引:index
-
列索引:columns
-
值:values(NumPy的二维数组)
2.DataFrame的创建
-
最常见的方法是传递一个字典来创建。DataFrame 以字典的创建作为每一【列】的名称,以字典的值(一个数组)作为每一列。此外,DataFrame 会自动加上每一行的索引(和Series一样)。
-
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN。
d = {"name":["tfos","Python","Pandas"],"age":[11,30,20],
}
df = pd.DataFrame(d)
df
# 执行结果
# 每一行是一条数据
# 每一列表示一种属性-
DataFrame的基本属性和方法:
-
values 值,二维 ndarray 数组
-
columns 列索引
-
index 行索引
-
shape 形状
-
head() 查看前几条数据,默认5条
-
tail() 查看后几条数据,默认5条
-
display(df)
# 二维数组的数据
df.values
# 执行结果
array([['tfos', 11],['Python', 30],['Pandas', 20]], dtype=object)# 列索引
df.columns
# 执行结果
Index(['name', 'age'], dtype='object')# 行索引
df.index
# 执行结果
RangeIndex(start=0, stop=3, step=1)# 形状:3行2列
df.shape
# 执行结果
(3, 2)# 查看前2条数据
df.head(2)
# 查看最后2条数据
df.tail(2)
# 设置 index 行索引
df.index = list("ABC")
df
# 设置 columns 列索引
df.columns = ["name2","age2"]
df
# 创建 DataFrame 时同时设置行和列的索引
d = {"name":["tfos","Python","Pandas"],"age":[11,30,20]
}
df = pd.DataFrame(d,index=list("ABC"))
df-
其他创建 DataFrame 的方式
df = pd.DataFrame(data = np.random.randint(10,100,size=(4,6)),index = ["小明","小红","小黄","小绿"],columns = ["语文","数学","英语","化学","物理","生物"]
)
df3.对列进行索引
-
通过类似字典的方式
-
通过属性的方式
可以将 DataFrame 的列获取为一个 Series。返回的 Series 拥有原 DataFrame 相同的索引,且 name 属性也已经设置好了,就是相应的列名。
df = pd.DataFrame(data = np.random.randint(10,100,size=(4,6)),index = ["小明","小红","小黄","小绿"],columns = ["语文","数学","英语","化学","物理","生物"]
)
df# Series类型
df.语文
# 执行结果
小明 47
小红 32
小黄 12
小绿 33
Name: 语文, dtype: int32df["语文"]
# 执行结果
小明 47
小红 32
小黄 12
小绿 33
Name: 语文, dtype: int32# 使用2个中括号得到的类型是 DataFrame
df[["语文","化学"]]df[["语文"]]4.对行进行索引
-
使用 .loc[] 加 index 来进行行索引
-
使用 .iloc[] 加整数来进行行索引
同样返回一个Series, index为原来的columns。
# 不可以直接取行索引
# df.小明
# df["小明"]
# DataFrame默认是先取列索引
# 取行索引值为 Series 类型
df.loc["小明"]
# 执行结果
语文 47
数学 63
英语 62
化学 17
物理 84
生物 24
Name: 小明, dtype: int32df.iloc[0]
# 执行结果
语文 47
数学 63
英语 62
化学 17
物理 84
生物 24
Name: 小明, dtype: int32# 使用2个中括号取到的值是 DataFrame 类型
df.loc[["小明","小绿"]]df.loc[["小明"]]df.iloc[[0,-1]]df.iloc[[0,3]]df.iloc[[0]]5.对元素索引的方法
-
使用列索引
-
使用行索引(iloc[3,1]相对于两个参数;iloc[[3,3]]里面的[3,3]看作一个参数)
-
使用 values 属性(二维 NumPy 数组)
# 先取列,再取行
df["语文"]["小明"]
# 执行结果
47df["语文"][0]
# 执行结果
47df.语文[0]
# 执行结果
47df.语文.小明
# 执行结果
47# 先取行,再取列
df.loc["小明"]["语文"]
# 执行结果
47df.loc["小明","语文"]
# 执行结果
47df.loc["小明"][0]
# 执行结果
47df.iloc[0][0]
# 执行结果
47df.iloc[0,0]
# 执行结果
47df.iloc[0]["语文"]
# 执行结果
47相关文章:
1分钟搞定Pandas DataFrame创建与索引
1.DataFrame介绍 DataFrame 是一个【表格型】的数据结构,可以看作是【由Series组成的字典】(共用同一个索引)。DataFrame 由按一定顺序排列的多列数据组成。设计初衷是将 Series 的使用场景从一维扩展到多维。DataFrame 既有行索引ÿ…...

【贪心算法】哈夫曼编码Python实现
文章目录 [toc]哈夫曼编码不同编码方式对比前缀码构造哈夫曼编码哈夫曼算法的正确性贪心选择性质证明 最优子结构性质证明 总结 Python实现时间复杂性 哈夫曼编码 哈夫曼编码是广泛用于数据文件压缩的十分有效的编码方法,其压缩率通常为 20 % 20\% 20%到 90 % 90\%…...

【RAG 博客】RAG 应用中的 Routing
Blog:Routing in RAG-Driven Applications ⭐⭐⭐⭐ 根据用户的查询意图,在 RAG 程序内部使用 “Routing the control flow” 可以帮助我们构建更实用强大的 RAG 程序。路由模块的关键实现就是一个 Router,它根据 user query 的查询意图&…...

鸿蒙ArkUI:【编程范式:命令式->声明式】
命令式 简单讲就是需要开发用代码一步一步进行布局,这个过程需要开发全程参与。 开发前请熟悉鸿蒙开发指导文档:gitee.com/li-shizhen-skin/harmony-os/blob/master/README.md点击或者复制转到。 Objective-C ObjectiveC 复制代码 UIView *cardView …...

【练习2】
1.汽水瓶 ps:注意涉及多个输入,我就说怎么老不对,无语~ #include <cmath> #include <iostream> using namespace std;int main() {int n;int num,flag,kp,temp;while (cin>>n) {flag1;num0;temp0;kpn;while (flag1) {if(kp<2){if(…...

oracle 新_多种块大小的支持9i
oracle 新_多种块大小的支持 conn sys/sys as sysdba SHOW PARAMETER CACHE ALTER SYSTEM SET DB_CACHE_SIZE16M; ALTER SYSTEM SET DB_4K_CACHE_SIZE8M; CREATE TABLESPACE K4 DATAFILE F:\ORACLE\ORADATA\ZL9\K4.DBF SIZE 2M BLOCKSIZE 4K; CREATE TABLE SCOTT.A1 TABLESP…...

Collections工具类
类java.util.Collections提供了对Set、List、Map进行排序、填充、查找元素的辅助方法。 方法名说明void sort(List)对List容器内的元素排序,排序规则是升序void shuffle(List)对List容器内的元素进行随机排列void reverse(List)对List容器内的元素进行逆序排列void…...
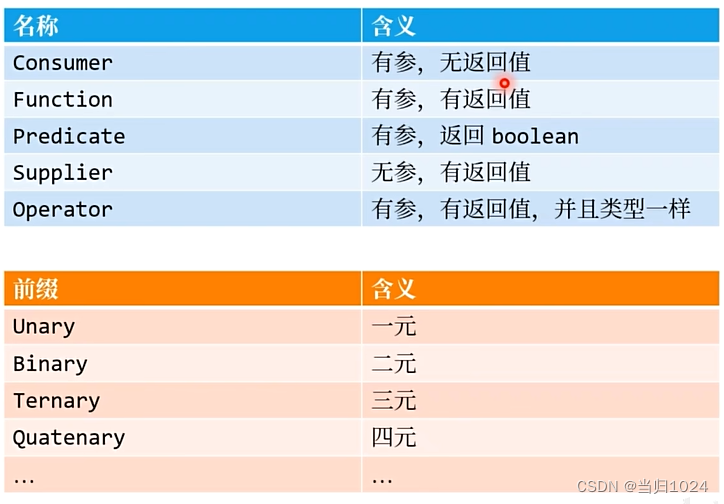
java-函数式编程-jdk
背景 函数式接口很简单,但是不是每一个函数式接口都需要我们自己来写jdk 根据 有无参数,有无返回值,参数的个数和类型,返回值的类型 提前定义了一些通用的函数式接口 IntPredicate 参数:有一个,类型是int类…...

qiankun实现微前端,vue3为主应用,分别引入vue2和vue3微应用
1、vue3主应用配置 1、安装 qiankun yarn add qiankun # 或者 npm i qiankun -S2、在主应用中注册微应用 import { registerMicroApps, start } from "qiankun" const apps [{ name: vue2App, // 应用名称 xs_yiqing_vue2entry: //localhost:8080, // vue 应用…...

写了 1000 条 Prompt 之后,我总结出了这 9 个框架【建议收藏】
如果你对于写 Prompt 有点无从下手,那么,本文将为你带来 9 个快速编写 Prompt 的框架,你可以根据自己的需求,选择任意一个框架,填入指定的内容,即可以得到一段高效的 Prompt,让 LLM 给你准确满意…...

事件代理 浅谈
事件代理是一种将事件处理委托给父元素或祖先元素来管理的技术。当子元素触发特定事件时,该事件不会直接在子元素上进行处理,而是会冒泡到父元素或祖先元素,并在那里进行处理。这样做的好处是可以减少事件处理函数的数量,提高性能…...

一对多在线教育系统,疫情后,在线教育有哪些变革?
疫情期间,全面开展的在线教育经历了从不适应到认可投入并常态化的发展过程。如何发挥在线教学优势,深度融合线上与线下教育,将在线教育作为育人方式变革动力,提升育人服务水平,是复学复课后学校教育教学面临的关键问题…...
RabbitMQ(安装配置以及与SpringBoot整合)
文章目录 1.基本介绍2.Linux下安装配置RabbitMQ1.安装erlang环境1.将文件上传到/opt目录下2.进入/opt目录下,然后安装 2.安装RabbitMQ1.进入/opt目录,安装所需依赖2.安装MQ 3.基本配置1.启动MQ2.查看MQ状态3.安装web管理插件4.安装web管理插件超时的解决…...

JUC下的BlockingQueue详解
BlockingQueue是Java并发包(java.util.concurrent)中提供的一个接口,它扩展了Queue接口,增加了阻塞功能。这意味着当队列满时尝试入队操作,或者队列空时尝试出队操作,线程会进入等待状态,直到队列状态允许操作继续。这…...

ChatGPT理论分析
ChatGPT "ChatGPT"是一个基于GPT(Generative Pre-trained Transformer)架构的对话系统。GPT 是一个由OpenAI 开发的自然语言处理(NLP)模型,它使用深度学习来生成文本。以下是对ChatGPT进行理论分析的几个主…...

算法提高之魔板
算法提高之魔板 核心思想:最短路模型 将所有状态存入队列 更新步数 同时记录前驱状态 #include <iostream>#include <cstring>#include <algorithm>#include <unordered_map>#include <queue>using namespace std;string start&qu…...
服务器内存占用不足会怎么样,解决方案
在当今数据驱动的时代,服务器对于我们的工作和生活起着举足轻重的作用。而在众多影响服务器性能的关键因素当中,内存扮演着极其重要的角色。 服务器内存,也称RAM(Random Access Memory),是服务器核心硬件部…...

elasticsearch文档读写原理大致分析一下
文档写简介 客户端通过hash选择一个node发送请求,专业术语叫做协调节点 协调节点会对document进行路由,将请求转发给对应的primary shard primary shard在处理完数据后,会将document 同步到所有replica shard 协调节点将处理结果返回给…...

1 开发环境
开发环境(platformio python arduino框架)的搭建可以参考b站upESP32超详细教程-使用VSCode(基于Arduino框架)哔哩哔哩bilibili 这里推荐离线安装esp32库文件,要不然要等很久(b站教程很多) 搭…...

云视频,也称为视频云服务,是一种基于云计算技术理念的视频流媒体服务
云视频,也称为视频云服务,是一种基于云计算技术理念的视频流媒体服务。它基于云计算商业模式,为视频网络平台服务提供强大的支持。在云平台上,所有的视频供应商、代理商、策划服务商、制作商、行业协会、管理机构、行业媒体和法律…...

机器学习在非洲传染病预测与监测中的实战应用
1. 项目概述:当AI遇见非洲传染病防控在公共卫生领域,时间就是生命,资源就是防线。对于非洲大陆而言,这句话的分量尤为沉重。这里常年承受着全球最沉重的传染病负担,从水源性传播的霍乱、致命性极高的埃博拉,…...

2026年小程序多少钱对比:精选5大权威推荐帮你选对平台
小程序开发方案的选择直接影响功能匹配度与成本效益,2026年主流服务商主要分为模板化与定制化两类路径。本文将从开发费用构成、五大平台核心方案及选择策略三方面展开分析,帮助您快速定位适合自身业务阶段与预算的选项。内容涵盖基础功能解析、价格对比…...

用Python和NumPy手搓一个光流可视化工具:从理解数组到生成动态箭头图
用Python和NumPy手搓光流可视化工具:从数组操作到动态运动解析 光流分析是计算机视觉中理解物体运动的核心技术之一。想象一下,当你观看一段足球比赛视频时,如何用代码让计算机"看到"球员的跑动轨迹?这就是光流技术要解…...

【AI原生应用CI/CD黄金标准】:SITS2026权威白皮书首度解密——7大不可绕过的工程范式跃迁
更多请点击: https://intelliparadigm.com 第一章:SITS2026白皮书核心定位与范式革命性意义 SITS2026(Semantic-Integrated Trustworthy Systems 2026)白皮书并非传统技术路线图的延伸,而是面向AI原生时代构建可信系统…...

训练篇第1节:梯度累积——用小批量模拟大批量的训练技巧
显存不够?batch size太大?梯度累积让你用时间换空间,训练更大的模型 前言 从本节开始,我们正式进入训练篇。框架篇让你掌握了PyTorch/TensorFlow的GPU加速原理和自定义算子开发,但训练大模型时,你还会遇到一个更棘手的问题:显存不够。 当你尝试增大batch size以提高训…...

创优必看!鲁班奖工程的八项基本要求
创优必看!鲁班奖工程的八项基本要求 作为建筑工程行业的最高级别奖项,鲁班奖的评选工作严格贯彻执行国家有关基本建设的法律、法规和方针政策,以及国家、行业现行的技术标准、施工规范和技术规程。那么,什么样的工程才能荣获鲁班奖呢? 本文根据《鲁班奖评选工作细则》总…...

KMS_VL_ALL_AIO实战指南:Windows与Office智能激活高效方案
KMS_VL_ALL_AIO实战指南:Windows与Office智能激活高效方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾为Windows系统激活问题而烦恼?Office软件突然变成只读…...

3步解锁Switch离线观影:揭秘wiliwili如何破解掌机视频播放四大难题
3步解锁Switch离线观影:揭秘wiliwili如何破解掌机视频播放四大难题 【免费下载链接】wiliwili 第三方B站客户端,目前可以运行在PC全平台、PSVita、PS4 、Xbox 和 Nintendo Switch上 项目地址: https://gitcode.com/GitHub_Trending/wi/wiliwili 你…...
Translumo:让游戏外语对话秒变母语的神奇翻译助手
Translumo:让游戏外语对话秒变母语的神奇翻译助手 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 还在为看不懂…...
)
手把手教你用checksts.py脚本,提前给VMware vCenter的STS证书做‘体检’(避坑指南)
企业级vCenter运维:STS证书主动检测与全生命周期管理实践 当vCenter突然弹出503 Service Unavailable错误时,多数运维团队的第一反应是检查服务状态和网络连接,却很少有人会想到——这可能是由那个"沉默的定时炸弹"STS证书过期引发…...