教你使用三种方式写一个最基本的spark程序
当需要处理大规模数据并且需要进行复杂的数据处理时,通常会使用Hadoop生态系统中的Hive和Spark来完成任务。在下面的例子中,我将说明如何使用Spark编写一个程序来处理Hive中的数据,以满足某个特定需求。
假设我们有一个Hive表,其中包含每个人每天的体重记录,我们需要从中计算出每个人的平均体重。为了完成这个任务,我们可以使用Spark来读取Hive表中的数据,并使用Spark进行计算。
下面是具体的开发过程:
一.第一种方式:Spark DataFrame:
1.首先,我们需要在Spark中创建一个SparkSession对象,并使用它来连接到Hive。
from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("HiveToSpark").config("spark.sql.warehouse.dir", "/user/hive/warehouse").enableHiveSupport().getOrCreate()
然后,我们可以使用Spark进行数据转换和计算。在这个例子中,我们将按人员分组,并计算每个人的平均体重。
from pyspark.sql.functions import avgdf_avg_weight = df.groupBy("person").agg(avg("weight"))
最后,我们可以将结果写回到Hive表中。
df_avg_weight.write.mode("overwrite").saveAsTable("my_hive_table_average_weight")
完整的代码如下:
from pyspark.sql import SparkSession
from pyspark.sql.functions import avgspark = SparkSession.builder.appName("HiveToSpark").config("spark.sql.warehouse.dir", "/user/hive/warehouse").enableHiveSupport().getOrCreate()df = spark.sql("SELECT * FROM my_hive_table")df_avg_weight = df.groupBy("person").agg(avg("weight"))df_avg_weight.write.mode("overwrite").saveAsTable("my_hive_table_average_weight")
二:第二种方式.使用sparkRDD
首先,我们使用SparkContext对象创建一个Spark RDD对象hive_rdd,通过执行SQL查询从Hive表中读取数据。接下来,我们将hive_rdd转换为一个(k, v)对的RDD,其中k是person字段,v是一个元组(weight, 1),表示每个人的体重和体重数量。然后,我们使用reduceByKey()函数将元组聚合为总体重和总体重数量,然后使用map()函数计算每个人的平均体重。最后,我们将结果保存到HDFS中。
from pyspark import SparkConf, SparkContextconf = SparkConf().setAppName("HiveToRDD")
sc = SparkContext(conf=conf)hive_rdd = sc.sql("SELECT * FROM my_hive_table").rdd
avg_weight_rdd = hive_rdd.map(lambda x: (x[0], (x[1], 1))) \.reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1])) \.map(lambda x: (x[0], x[1][0] / x[1][1]))avg_weight_rdd.saveAsTextFile("hdfs://path/to/output")
三:sparksql
直接写入到hive中的表
INSERT OVERWRITE TABLE my_hive_table_average_weight
SELECT person, AVG(weight) as avg_weight
FROM my_hive_table
GROUP BY person
如果没有这个表,可以使用以下Spark SQL语法来创建一个新表并将结果写入该表中:
CREATE TABLE my_hive_table_average_weight
AS
SELECT person, AVG(weight) as avg_weight
FROM my_hive_table
GROUP BY person
上述SQL查询使用CREATE TABLE AS命令创建一个新的Hive表my_hive_table_average_weight,并将查询结果写入该表中。这个命令将自动创建表的结构和数据类型,因此不需要预先定义表的结构。只需要确保表名和字段名与查询结果一致即可。
但是,这种方法可能会导致性能问题,因为它需要将所有查询结果加载到Spark内存中,然后再将其写入到Hive表中。如果数据量非常大,可能会导致内存不足的问题。因此,如果需要处理大数据集,请考虑使用其他更高效的方式,如Spark RDD或DataFrame API。
相关文章:

教你使用三种方式写一个最基本的spark程序
当需要处理大规模数据并且需要进行复杂的数据处理时,通常会使用Hadoop生态系统中的Hive和Spark来完成任务。在下面的例子中,我将说明如何使用Spark编写一个程序来处理Hive中的数据,以满足某个特定需求。假设我们有一个Hive表,其中…...

软件设计师错题集
软件设计师错题集一、计算机组成与体系结构1.1 浮点数1.2 Flynn分类法1.3 指令流水线1.4 层次化存储体系1.4.1 程序的局限性1.5 Cache1.6 输入输出技术1.7 总线系统1.8 CRC循环冗余校验码二、数据结构与算法基础2.1 队列与栈2.2 树与二叉树的特殊性2.3 最优二叉树(哈…...
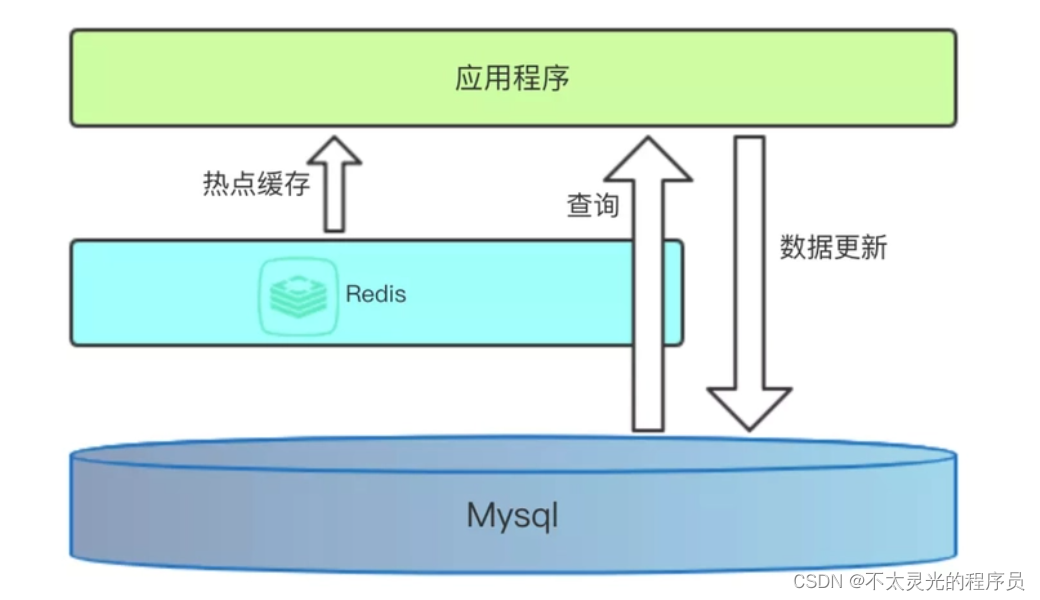
【华为机试真题详解 Python实现】静态扫描最优成本【2023 Q1 | 100分】
文章目录前言题目描述输入描述输出描述示例 1输入:输出:示例 2输入:输出:题目解析参考代码前言 《华为机试真题详解》专栏含牛客网华为专栏、华为面经试题、华为OD机试真题。 如果您在准备华为的面试,期间有想了解的…...
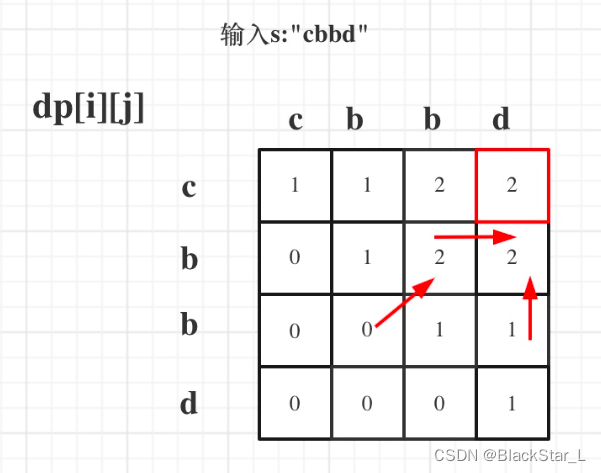
算法刷题总结 (四) 动态规划
算法总结4 动态规划一、动态规划1.1、基础问题11.1.1、509. 斐波那契数列1.1.2、70. 爬楼梯1.1.3、746. 使用最小花费爬楼梯1.2、基础问题21.2.1、62. 不同路径1.2.2、63. 不同路径Ⅱ1.2.3、343. 整数拆分1.2.4、96. 不同的二叉搜索树1.3、背包问题1.3.1、01背包1.3.1.1、单次选…...

Grafana 转换数据的工具介绍
转换数据 Grafana 可以在数据显示到面板前对数据进行处理 1、点击Transform选项卡 2、选择要使用的转换类型,不同的转换类型配置不同 3、要新增转换类型,点击Add transformation 4、使用右上角调式按钮可以调式转换 支持的转换类型: Add f…...

Linux 学习笔记
一、 概述 1. 操作系统 ① 计算机由硬件和软件组成 ② 操作系统属于软件范畴,主要作用是协助用户调度硬件工作,充当用户和计算机硬件之间的桥梁 ③ 常见的操作系统 🤠 PC端:Windows、Linux、MacOS🤠 移动端&#…...

HTML注入专精整理
目录 HTML注入介绍 抽象解释 HTML注入的影响 HTML注入与XSS的区别 HTML元素流程图...
看完这篇我不信你不会二叉树的层序遍历【C语言】
目录 实现思路 代码实现 之前介绍了二叉树的前、中、后序三种遍历,采用的是递归的方式。今天我们来学习另外一种遍历方式——层序遍历。层序遍历不容小觑,虽然实现方法并不难,但是它所采取的思路是很值得学习的,与前三者不同&am…...
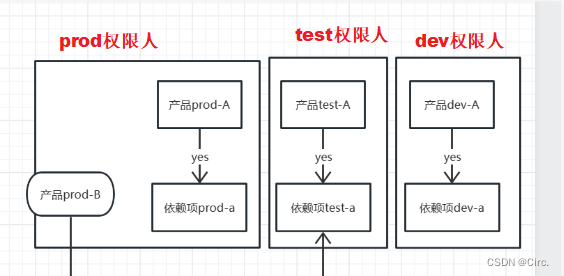
案例17-环境混用带来的影响
目录一、背景介绍背景事故二、思路&方案三、过程四、总结nginx做转发fastdfs(文件上传下载)五、升华一、背景介绍 本篇博客主要介绍开发中项目使用依赖项环境闭一只带来的恶劣影响,在错误中成长进步。 背景 本公司另外一个产品开发God…...

知识蒸馏论文阅读:DKD算法笔记
标题:Decoupled Knowledge Distillation 会议:CVPR2022 论文地址:https://ieeexplore.ieee.org/document/9879819/ 官方代码:https://github.com/megvii-research/mdistiller 作者单位:旷视科技、早稻田大学、清华大学…...
Sentinel架构篇 - 熔断降级
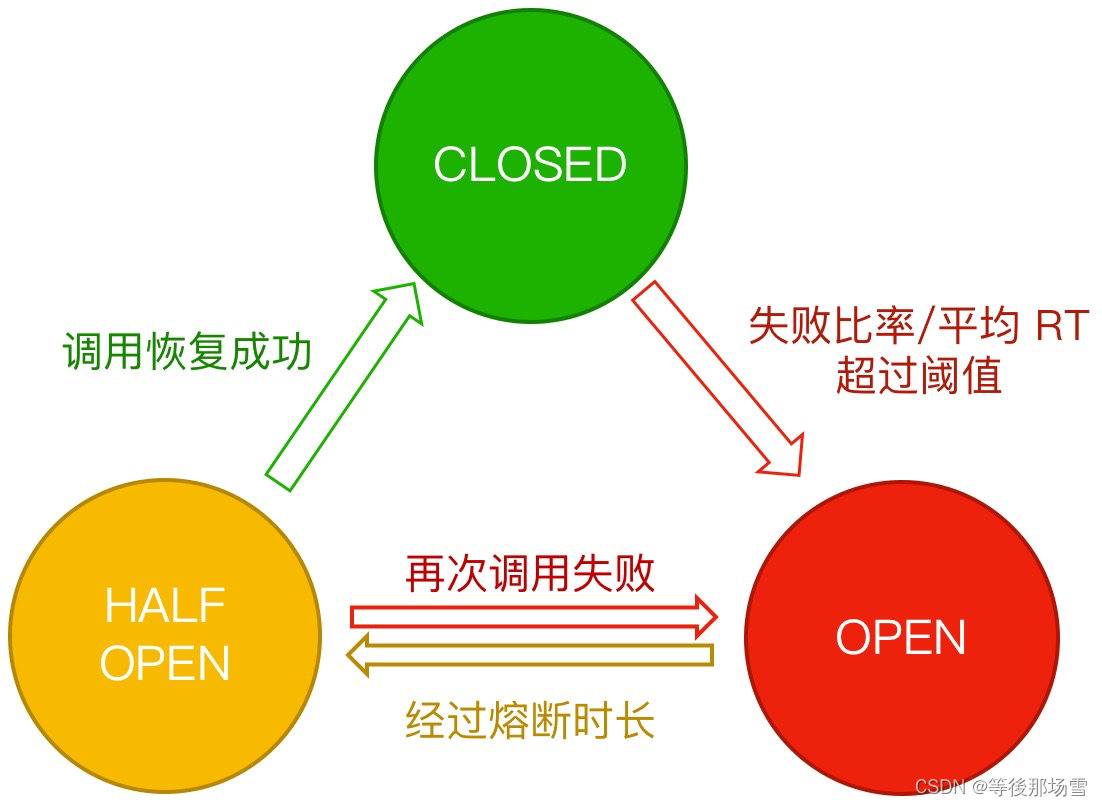
熔断降级 概念 除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。一个服务常常会调用其它模块,可能是一个远程服务、数据库、或者第三方 API 等。然而,被依赖的服务的稳定性是不能保证的。如果依赖的服…...

shell脚本的一些记录 与jenkins的介绍
shell 脚本的执行 sh ***.sh shell脚本里面的命令 其实就是终端执行一些命令 shell 连接服务器 可以直接ssh连接 但是这样最好是无密码的 不然后面的命令就不好写了 换而言之有密码得 不好写脚本 需要下载一些expect的插件之类的才可以 判断语句 的示例 需要注意的是…...

JVM的了解与学习
一:jvm是什么 jvm是java虚拟机java Virtual Machine的缩写 jdk包含jre和java DevelopmentTools 二:什么是java虚拟机 虚拟机是一种抽象化的计算机,通过在实际的计算机上仿真模拟各种计算机功能来实现的。java虚拟机有自己完善的硬体结构,如处理器、堆栈、寄存器等,还有…...

提升数字品牌的5个技巧
“品牌”或“品牌推广”的概念通常用于营销。因为建立您的企业品牌对于产品来说极其重要,品牌代表了您与客户互动的身份和声音。今天,让我们来看看在数字领域提升品牌的一些有用的技巧。如何在数字领域提升您的品牌?在了解这些技巧之前&#…...

java通过反射获取加了某个注解的所有的类
有时候我们会碰到这样的情况:有n个场景,每个场景都有自己的逻辑,即n个处理逻辑,这时候我们就需要通过某个参数的值代表这n个场景,然后去加载每个场景不同的bean对象,即不同的类,这些类中都有一个…...

Warshall算法
🚀write in front🚀 📜所属专栏:> 算法 🛰️博客主页:睿睿的博客主页 🛰️代码仓库:🎉VS2022_C语言仓库 🎡您的点赞、关注、收藏、评论,是对我…...
vector中迭代器失效的问题及解决办法
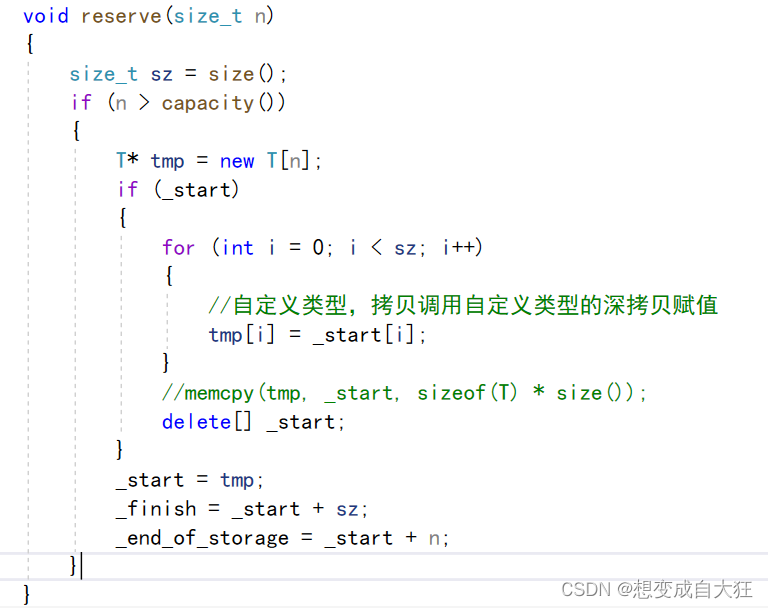
目录 vector常用接口 vector 迭代器失效问题 vector中深浅拷贝问题 vector的数据安排以及操作方式,与array非常相似。两者的唯一差别在于空间的运用的灵活性。array 是静态空间,一旦配置了就不能改变;要换个大(或小) 一点的房子&#x…...
【蓝桥杯刷题训练营】day05
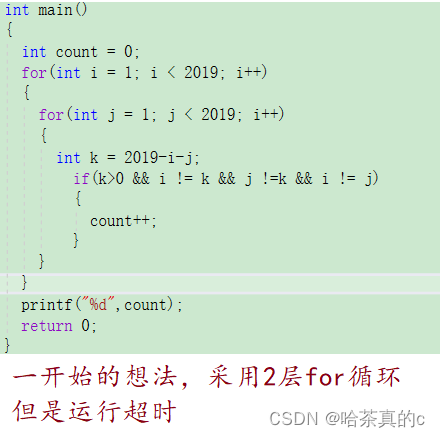
1 数的分解 拆分成3个数相加得到该数 然后采用了一种巨愚蠢的办法: int main() {int count 0;int a 2;int b 0;int c 1;int d 9;int a1, a2, a3;int c1, c2, c3;int d1, d2, d3;for (a1 0; a1 < 2; a1){for (a2 0; a2 < 2; a2){for (a3 0; a3 <…...

线程中断interrupt导致sleep产生的InterruptedException异常
强制当前正在执行的线程休眠(暂停执行),以“减慢线程”。 Thread.sleep(long millis)和Thread.sleep(long millis, int nanos)静态方法当线程睡眠时,它睡在某个地方,在苏醒之前不会返回到可运行状态。 当睡眠时间到期…...
ubuntu的快速安装与配置
文章目录前言一、快速安装二 、基础配置1 Sudo免密码2 ubuntu20.04 pip更新源3 安装和配置oneapi(infort/mpi/mkl) apt下载第一次下载的要建立apt源apt下载(infort/mpi/mkl)4 安装一些依赖库等5 卸载WSLpython总结前言 win11系统 ubuntu20.04 提示:以下…...

Dark Reader终极指南:轻松为任何网站开启完美深色模式
Dark Reader终极指南:轻松为任何网站开启完美深色模式 【免费下载链接】darkreader Dark Reader Chrome and Firefox extension 项目地址: https://gitcode.com/gh_mirrors/da/darkreader Dark Reader是一款广受欢迎的浏览器扩展,它能智能分析网页…...

LoRA 部署:微调后的模型怎么上线
本文基于昇腾CANN和昇腾NPU,围绕 cann-recipes-infer 仓库的相关技术展开。 LoRA 训练完出来两个东西——基础模型权重不动,外加一个小 rank 矩阵。部署时你不能直接丢原始权重,LoRA 矩阵要合并进去或者通过算子注入。CANN 上 LoRA 部署有两种…...
)
解锁Midjourney V6复古风生产力:3步精准控制颗粒度、褪色曲线与时代错位感(附12组实测Prompt参数表)
更多请点击: https://codechina.net 第一章:Midjourney V6复古美学的底层逻辑重构 Midjourney V6 并非简单迭代,而是对“视觉时间性”的一次系统性重编码——其复古美学并非依赖滤镜叠加或风格迁移模型,而是将胶片颗粒、暗房化学…...

DiskSpd深度解析:企业级存储性能调优的架构视角与实战指南
DiskSpd深度解析:企业级存储性能调优的架构视角与实战指南 【免费下载链接】diskspd DISKSPD is a storage load generator / performance test tool from the Windows/Windows Server and Cloud Server Infrastructure Engineering teams 项目地址: https://gitc…...

linux系统之进程管理详解
进程(Process) 是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。 在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描…...

为什么你的Gemini总在“浅层回答”?揭秘深度研究模式的3层激活机制与强制触发密钥
更多请点击: https://intelliparadigm.com 第一章:为什么你的Gemini总在“浅层回答”? 当你反复向 Gemini 提问却只得到泛泛而谈、回避细节或机械复述提示词的答案时,问题往往不在模型本身,而在于**交互范式与上下文工…...

【Lindy人力资源自动化方案】:20年HR Tech专家亲授,3大落地陷阱与5步零失败实施路径
更多请点击: https://codechina.net 第一章:Lindy人力资源自动化方案全景图 Lindy 是一款面向中大型企业的开源人力资源自动化平台,聚焦于招聘管理、员工生命周期编排、组织架构动态建模与合规性审计四大核心能力。其架构采用云原生设计&…...

3分钟搞定3D视频转2D:终极免费工具让普通设备也能体验VR沉浸感
3分钟搞定3D视频转2D:终极免费工具让普通设备也能体验VR沉浸感 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.c…...
5分钟掌握Windows字体清晰度优化:Better ClearType Tuner终极指南
5分钟掌握Windows字体清晰度优化:Better ClearType Tuner终极指南 【免费下载链接】BetterClearTypeTuner A better way to configure ClearType font smoothing on Windows 10. 项目地址: https://gitcode.com/gh_mirrors/be/BetterClearTypeTuner 还在为Wi…...

SolveSpace参数化CAD设计:5大核心功能深度解析与实战指南
SolveSpace参数化CAD设计:5大核心功能深度解析与实战指南 【免费下载链接】solvespace Parametric 2d/3d CAD 项目地址: https://gitcode.com/gh_mirrors/so/solvespace SolveSpace是一款功能强大的开源参数化CAD软件,专为二维和三维建模设计而生…...