哈希表(unordered_set、unordered_map)
文章目录
- 一、unordered_set、unordered_map的介绍
- 二、哈希表的建立方法
- 2.1闭散列
- 2.2开散列(哈希桶/拉链法)
- 三、闭散列代码(除留余数法)
- 四、开散列代码(拉链法/哈希桶)
一、unordered_set、unordered_map的介绍
1.unordered_set、unordered_map的底层是哈希表,哈希表是一种关联式容器(与前面的二叉搜索树、AVL树、红黑树一样,数据与数据之间有很强的关联性)
2.单向迭代器(map、set是双向迭代器)
3.哈希表的查找顺序是O(1),性能比红黑树(logn)好一些(在数据接近与有序的情况下与哈希表一样)。
二、哈希表的建立方法
2.1闭散列
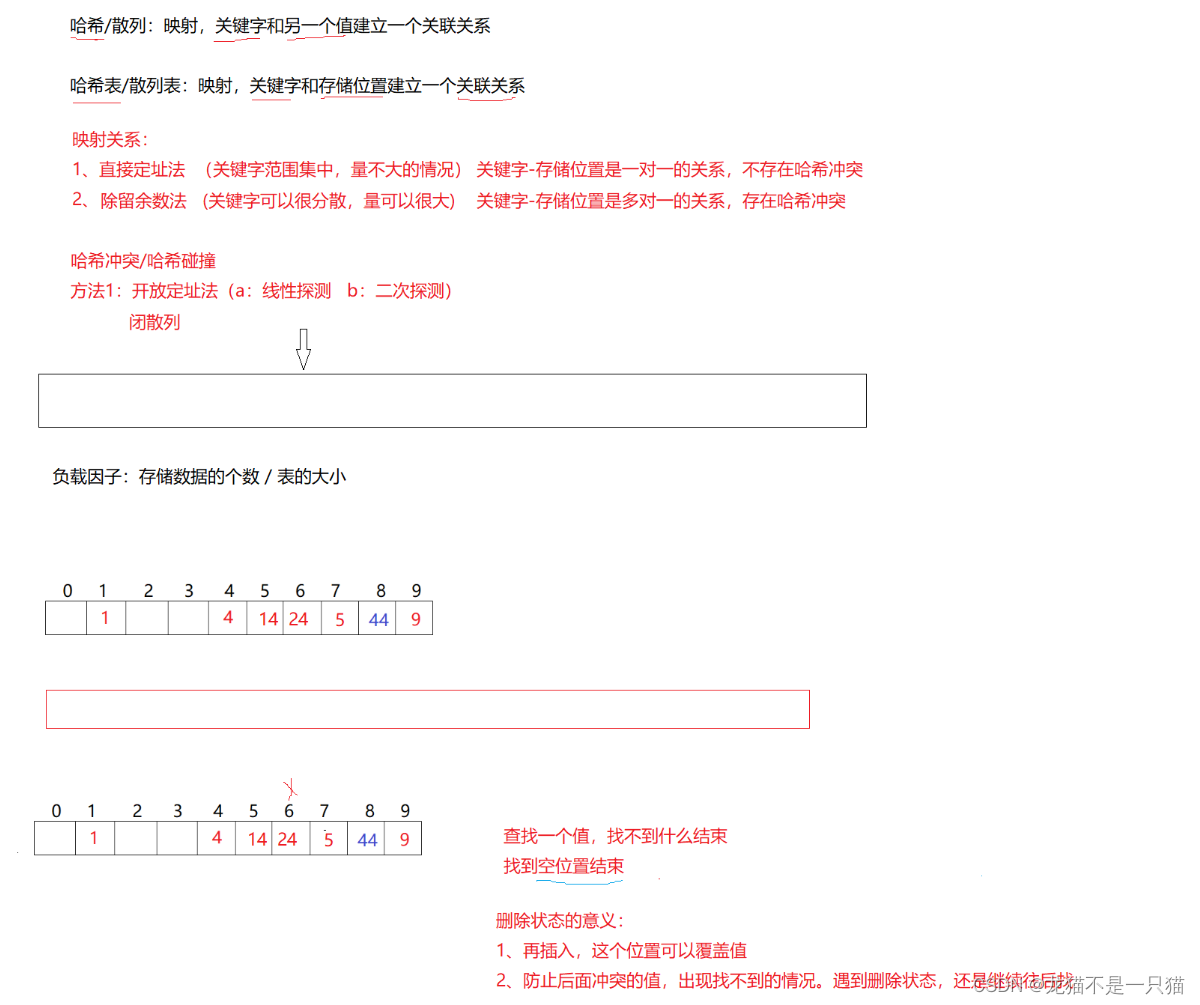
缺点:值很分散,直接定址会导致空间开很大,浪费。
2.2开散列(哈希桶/拉链法)
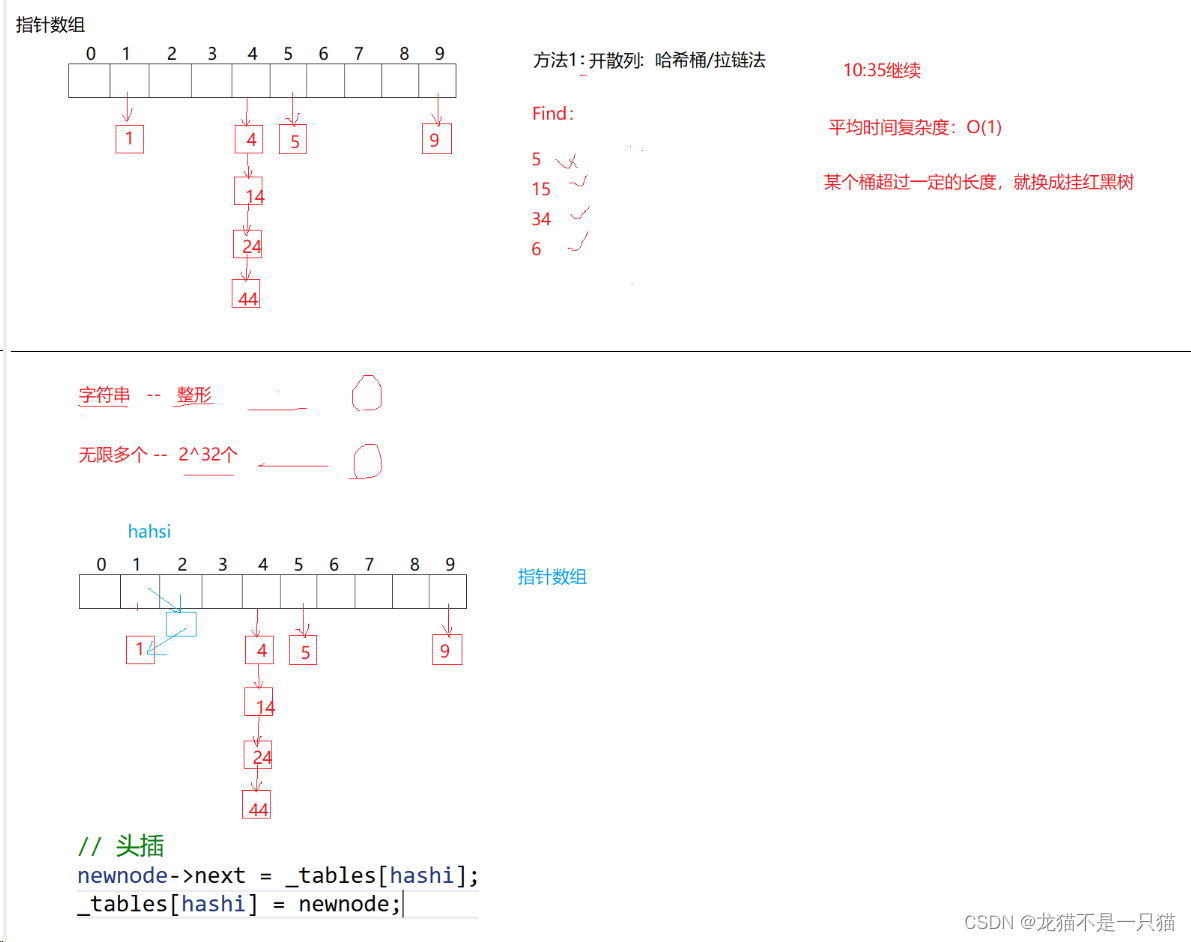
除留余数法会发生哈希碰撞(关键字可以很分散,量可以很大,关键字-存储位置是多对一的关系,存在哈希冲突):不同的值映射到相同的位置上去。
负载因子(存储数据的个数/表的大小,也就是空间的占用率):存储关键字的个数/空间大小
三、闭散列代码(除留余数法)
#pragma once
#include<iostream>
#include<vector>
#include<string>
using namespace std;template<class K>
struct HashFunc
{size_t operator()(const K& key){return key;}
};template<>
struct HashFunc<string>
{size_t operator()(const string& kv){size_t hashi = 0;for (auto e : kv){hashi *= 31;hashi += e;}return hashi;}
};namespace close
{enum Status{EMPTY,EXIST,DELETE};template<class K,class V>struct HashData{pair<K, V> _kv;Status _s;//表示状态};template<class K,class V,class Hash = HashFunc<K>>class HashTable{public:typedef HashData<K, V> data;HashTable(){_tables.resize(10);}data* find(const K key){size_t hash = key % _tables.size();while (_tables[hash]._s!=EMPTY){if (_tables[hash]._s == EXIST && _tables[hash]._kv.first == key)return &_tables[hash];hash++;hash %= _tables.size();}return nullptr;}bool insert(const pair<K,V>& kv){Hash hf;if (find(kv.first))return false;if (_n * 10 / _tables.size() == 7){//建新表HashTable<K,V,Hash> newtable;newtable._tables.resize(_tables.size() * 2);for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._s == EXIST)newtable.insert(_tables[i]._kv);}_tables.swap(newtable._tables);}size_t hash = hf(kv.first) % _tables.size();//线性探测while (_tables[hash]._s != EMPTY){hash++;hash %= _tables.size();}_tables[hash]._kv = kv;_tables[hash]._s = EXIST;_n++;return true;}bool erase(const K& key){data* ret = find(key);if (ret){_n--;ret->_s == DELETE;return true;}return false;}void Print(){for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._s == EXIST){//printf("[%d]->%d\n", i, _tables[i]._kv.first);cout << "[" << i << "]->" << _tables[i]._kv.first << ":" << _tables[i]._kv.second << endl;}else if (_tables[i]._s == EMPTY){printf("[%d]->\n", i);}else{printf("[%d]->D\n", i);}}cout << endl;}private:vector<data> _tables;size_t _n = 0;};}四、开散列代码(拉链法/哈希桶)
namespace hash_bucket
{template<class K,class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next;};template<class K,class V,class Hash = HashFunc<K>>class HashTable{public:typedef HashNode<K, V> Node;HashTable(){_tables.resize(10, nullptr);}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];if (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}Node* find(const K& key){Hash hf;size_t hash = hf(key) % _tables.size();Node* cur = _tables[hash];while (cur){if (hf(cur->_kv.first) == hf(key))return cur;cur = cur->_next;}return nullptr;}bool insert(pair<K,V>& kv){Hash hf;if (find(kv.first))return false;if (_bucket == _tables.size()){HashTable newtable;newtable._tables.resize(_tables.size() * 2, nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){size_t hash = hf(cur->_kv.first) % newtable._tables.size();cur->_next = newtable._tables[hash];newtable._tables[hash] = cur;cur = cur->_next;}}_tables.swap(newtable._tables);}size_t hash = hf(kv.first) % _tables.size();Node* cur = new Node(kv);cur->_next = _tables[hash];_tables[hash] = cur;_bucket++;return true;}bool erase(const K& key){Hash hf;size_t hash = hf(key) % _tables.size();Node* cur = _tables[hash];Node* prev = nullptr;while (cur){if (hf(key) == hf(_tables[hash]->_kv.first)){_tables[hash] = cur->_next;delete cur;return true;}else{if (hf(key) == hf(cur->_kv.first)){prev->_next = cur->_next;delete cur;return true;}prev = cur;cur = cur->_next;}}_bucket--;return false;}private:vector<Node*> _tables;size_t _bucket = 0;};}
代码解读:这里的插入节点是头插(效率高一些)
相关文章:
哈希表(unordered_set、unordered_map)
文章目录 一、unordered_set、unordered_map的介绍二、哈希表的建立方法2.1闭散列2.2开散列(哈希桶/拉链法) 三、闭散列代码(除留余数法)四、开散列代码(拉链法/哈希桶) 一、unordered_set、unordered_map的…...
Docker 加持的安卓手机:随身携带的知识库(一)
这篇文章聊聊,如何借助 Docker ,尝试将一台五年前的手机,构建成一个随身携带的、本地化的知识库。 写在前面 本篇文章,我使用了一台去年从二手平台购入的五年前的手机,K20 Pro。 为了让它能够稳定持续的运行…...
本地连接服务器Jupyter【简略版】
首先需要在你的服务器激活conda虚拟环境: 进入虚拟环境后使用conda install jupyter命令安装jupyter: 安装成功后先不要着急打开,因为需要设置密码,使用jupyter notebook password命令输入自己进入jupyter的密码: …...

sql 注入 1
当前在email表 security库 查到user表 1、第一步,知道对方goods表有几列(email 2 列 good 三列,查的时候列必须得一样才可以查,所以创建个临时表,select 123 ) 但是你无法知道对方goods表有多少列 用order …...
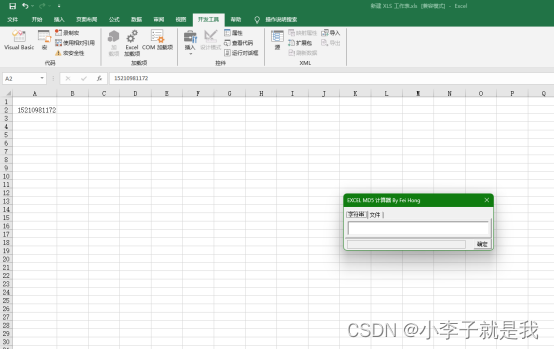
Excel中实现md5加密
1.注意事项 (1)在Microsoft Excel上操作 (2)使用完,建议修改的配置全部还原,防止有风险。 2.准备MD5宏插件 MD5加密宏插件放置到F盘下(直接F盘下,不用放到具体某一个文件夹下) 提示:文件在文章顶部&…...

写SQL的心得
1、统计 COUNT(列名) 和COUNT(*)均可,区别是前者只会统计非NULL。 2、where后面不能跟聚合函数,用的话应该在Having使用,因此需要先分组GroupBy where是基于行过滤,having是基于分…...
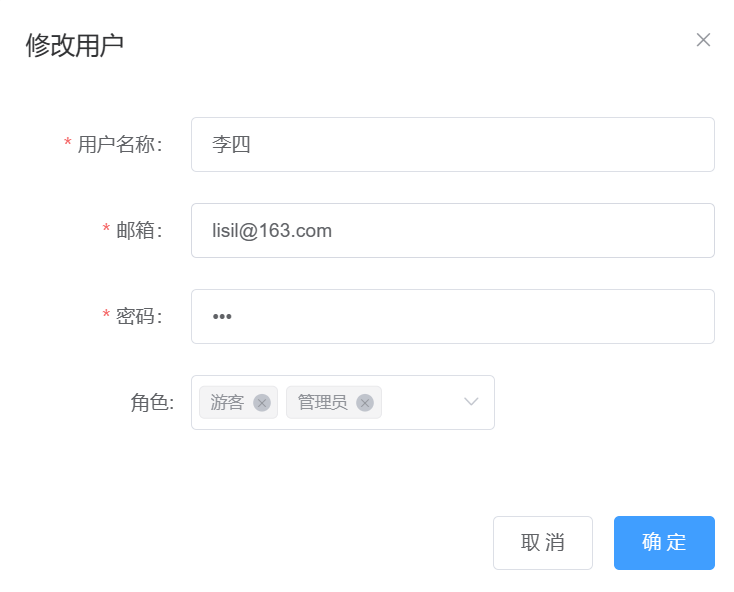
经典权限五张表功能实现
文章目录 用户模块(未使用框架)查询功能实现步骤代码 新增功能实现步骤代码 修改功能实现步骤代码实现 删除功能实现步骤代码实现 用户模块会了,其他两个模块与其类似 用户模块(未使用框架) 查询功能 这里将模糊查询和分页查询写在一起 实现步骤 前端࿱…...
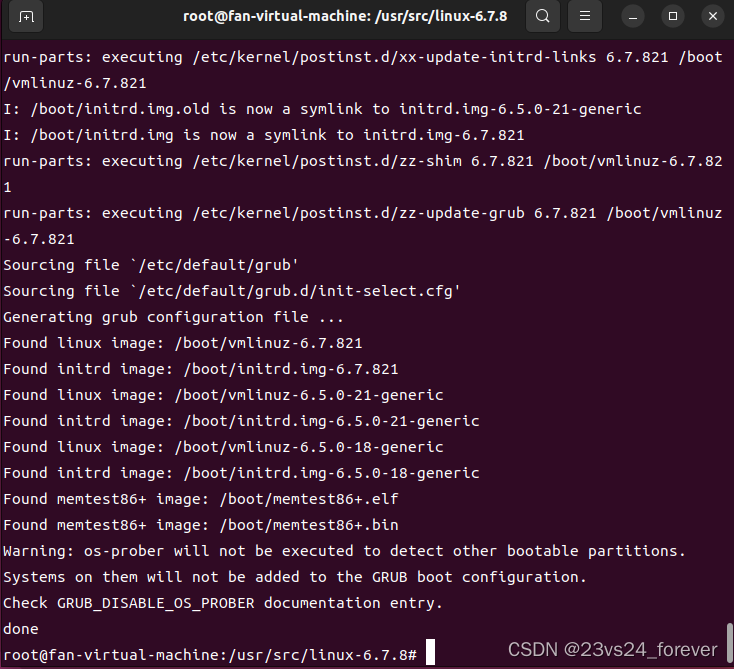
实验八 Linux虚拟内存 实验9.1:统计系统缺页次数成功案例
运行环境: VMware17.5.1 build-23298084Ubuntu 16.04LTS ubuntu版本下载地址Linux-4.16.10 linux历史版本下载地址虚拟机配置:硬盘一般不少于40G就行 内核版本不同内核文件代码也有出入,版本差异性令c文件要修改,如若要在linux6.7…...

SD-WAN提升Microsoft 365用户体验
随着数字化时代的到来,SaaS应用如Microsoft 365已经成为各类企业的主流选择。在这一趋势下,企业需要以更加灵活、高效的方式使用Microsoft 365,以满足日益增长的业务需求。而传统的网络基础设施可能无法满足这一需求,因此…...

C#中的异步编程模型
在C#中,async和await关键字是用于异步编程的重要部分,它们允许你以同步代码的方式编写异步代码,从而提高应用程序的响应性和吞吐量。这种异步编程模型在I/O密集型操作(如文件读写、网络请求等)中特别有用,因…...

博通Broadcom (VMware VCP)注册约考下载证书操作手册
博通Broadcom(VMware) CertMetrics 注册约考下载证书等操作指导手册(发布日期:2024-5-11) 目录 一、原 Mylearn 账号在新平台的激活… 1 二、在新平台查看并下载证书… 5 三、在新平台注册博通账号… 6 四、在新平台下注册考试… 10 一、原…...

Xilinx FPGA底层逻辑资源简介(1):关于LC,CLB,SLICE,LUT,FF的概念
LC:Logic Cell 逻辑单元 Logic Cell是Xilinx定义的一种标准,用于定义不同系列器件的大小。对于7系列芯片,通常在名字中就已经体现了LC的大小,在UG474中原话为: 对于7a75t芯片,LC的大小为75K,6输…...
简介)
SSH(安全外壳协议)简介
一、引言 SSH(Secure Shell)是一种加密的网络传输协议,用于在不安全的网络中提供安全的远程登录和其他安全网络服务。SSH最初由芬兰程序员Tatu Ylnen开发,用于替代不安全的telnet、rlogin和rsh等远程登录协议。通过SSH࿰…...

JavaScript异步编程——08-Promise的链式调用【万字长文,感谢支持】
前言 实际开发中,我们经常需要先后请求多个接口:发送第一次网络请求后,等待请求结果;有结果后,然后发送第二次网络请求,等待请求结果;有结果后,然后发送第三次网络请求。以此类推。…...

现代制造之数控机床篇
现代制造 有现代技术支撑的制造业,即无论是制造还是服务行业,添了现代两个字不过是因为有了现代科学技术的支撑,如发达的通信方式,不断发展的互联网,信息化程度加强了,因此可以为这两个行业增加了不少优势…...

Rust的协程机制:原理与简单示例
在现代编程中,协程(Coroutine)已经成为实现高效并发的重要工具。Rust,作为一种内存安全的系统编程语言,也采用了协程作为其并发模型的一部分。本文将深入探讨Rust协程机制的实现原理,并通过一个简单的示例来…...

学习成长分享-以近红外光谱分析学习为例
随着国家研究生招生规模的扩大,参与或接触光谱分析方向的研究生日益增多,甚至有部分本科生的毕业设计也包含以近红外光谱分析内容。基于对近红外光谱分析的兴趣,从2018年开始在CSDN博客(陆续更新自己学习的浅显认识,到…...
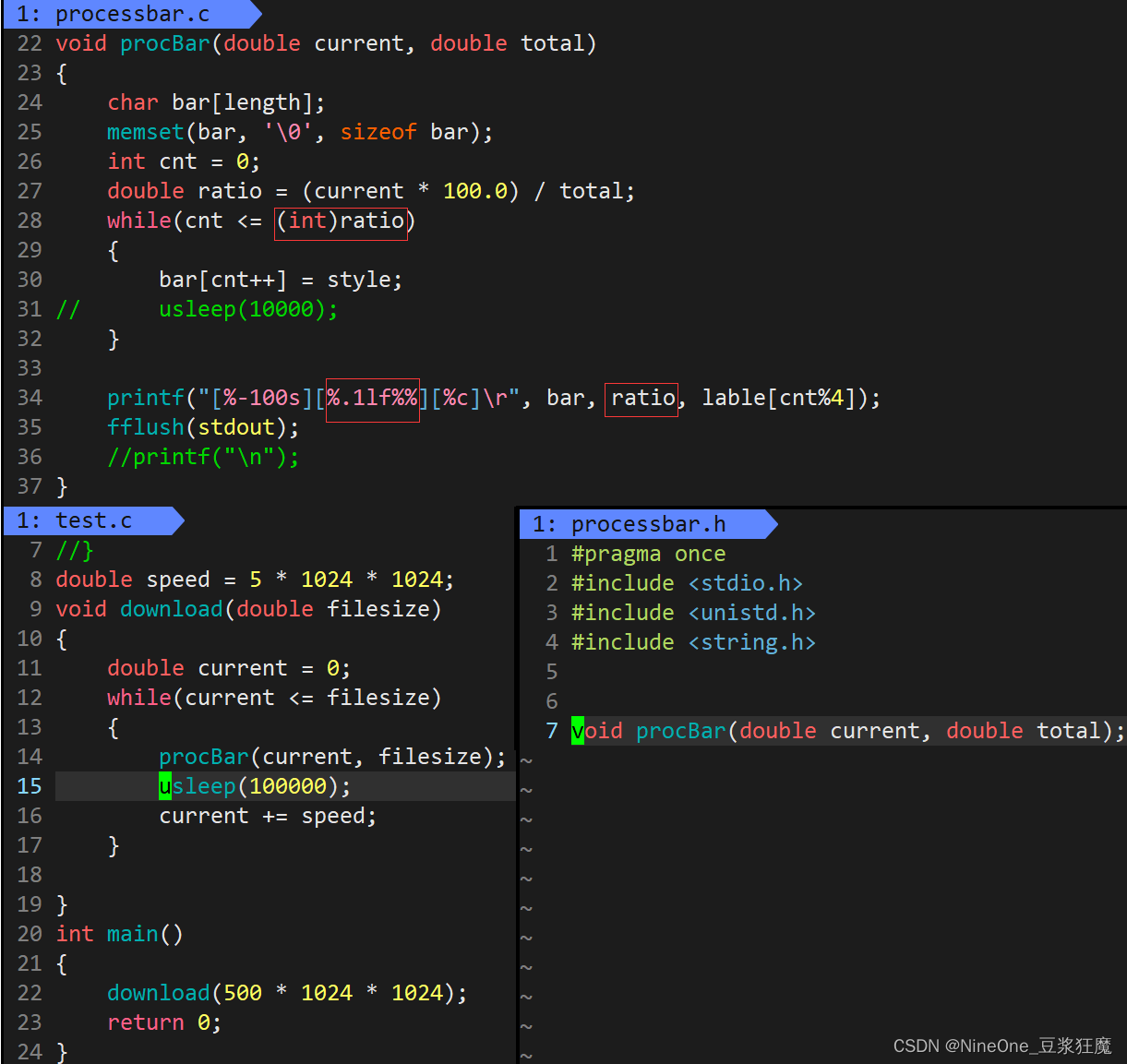
Linux makefile进度条
语法 在依赖方法前面加上就不会显示这一行的命令 注意 1.make 会在当前目录下找名为“makefile” 或者 “Makefile” 的文件 2.为了生成第一依赖文件,如果依赖文件列表有文件不存在,则会到下面的依赖关系中查找 3..PHONY修饰的依赖文件总是被执行的 …...

Ollama 可以设置的环境变量
Ollama 可以设置的环境变量 0. 引言1. Ollama 可以设置的环境变量 0. 引言 在Ollama的世界里,环境变量如同神秘的符文,它们是控制和定制这个强大工具的关键。通过精心设置这些环境变量,我们可以让Ollama更好地适应我们的需求,就像…...
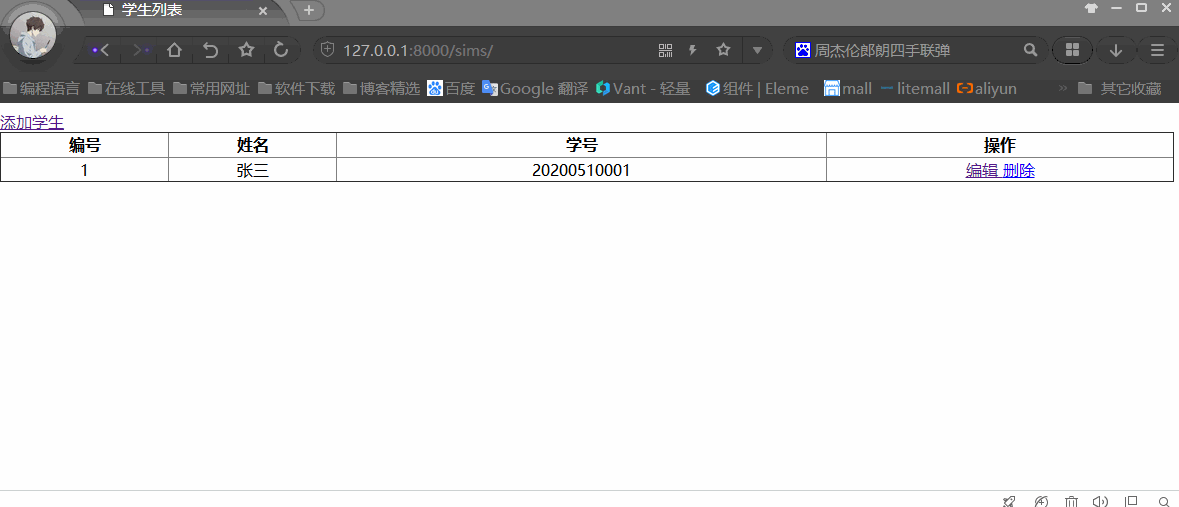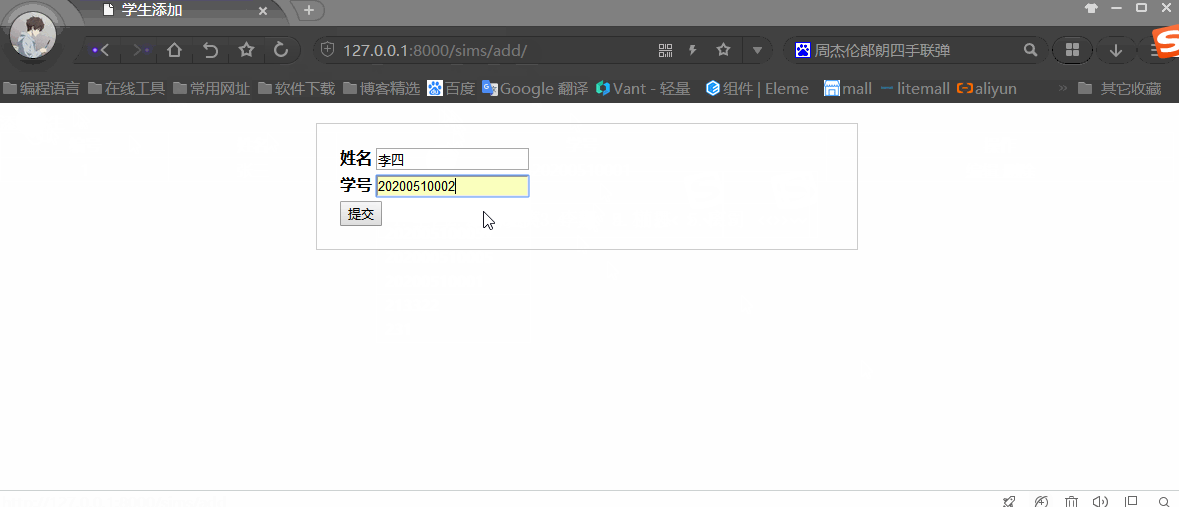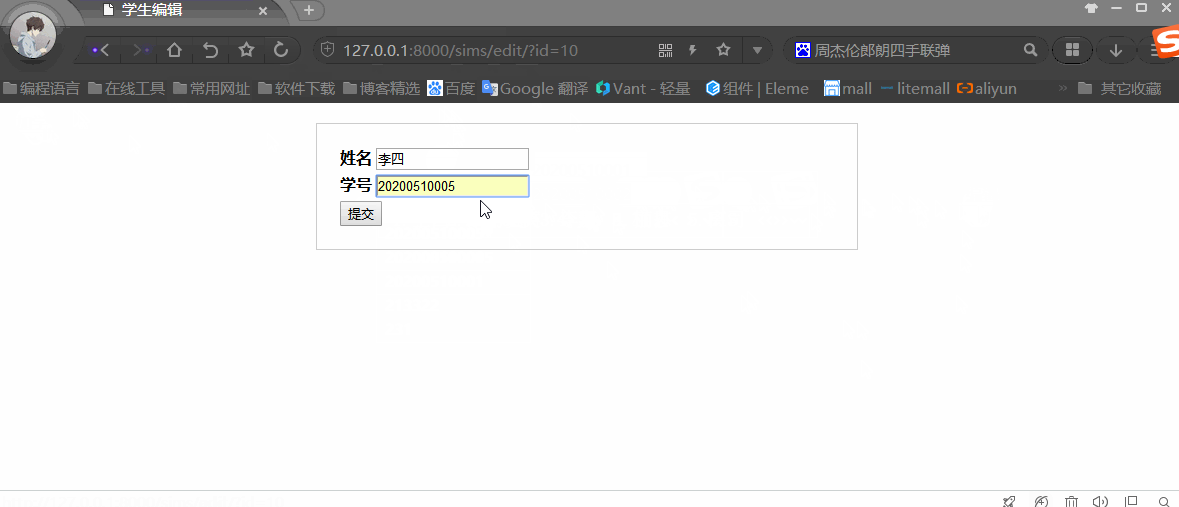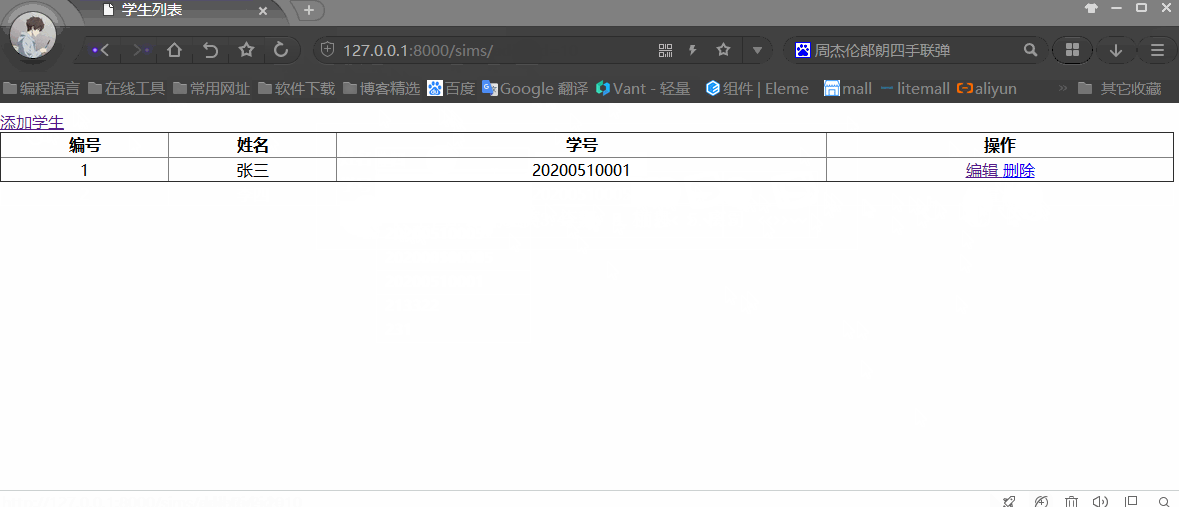
基于Python+Django+MySQL实现Web版的增删改查
Python Web框架Django连接和操作MySQL数据库学生信息管理系统(SMS),主要包含对学生信息增删改查功能,旨在快速入门Python Web。 开发环境 开发工具:Pycharm 2020.1开发语言:Python 3.8.0Web框架:Django 3.0.6数据库:…...
HSTracker:为macOS炉石传说玩家打造的数据智能助手
HSTracker:为macOS炉石传说玩家打造的数据智能助手 【免费下载链接】HSTracker A deck tracker and deck manager for Hearthstone on macOS 项目地址: https://gitcode.com/gh_mirrors/hs/HSTracker 在瞬息万变的炉石传说对局中,你是否曾因忘记对…...

告别B站界面混乱:3步找回经典小电视播放器
告别B站界面混乱:3步找回经典小电视播放器 【免费下载链接】Bilibili-Old 恢复旧版Bilibili页面,为了那些念旧的人。 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Old 你是否对B站新版界面感到无所适从?那些复杂的推荐算法…...

还在熬夜改论文格式?okbiye 本科毕业论文写作功能,一键搞定你的毕业难题
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 当查重报告里飘红的句子、学校格式手册里密密麻麻的排版要求、凌晨三点还没理顺的论文大纲,成为每个本科生毕业季的共同记忆时&…...

别再死记硬背公式了!用Python实战SCS模型,5分钟搞定城市降雨径流估算
用Python实战SCS模型:5分钟自动化城市降雨径流分析 水文工程师们是否厌倦了手动查表计算CN值?环境分析师是否还在为重复的径流公式推导头疼?今天我们将用Python彻底改变传统工作流——无需记忆复杂公式,只需5行核心代码即可完成从…...

母线槽核心部件解析 —— 高纯铜导体与绝缘层的技术价值
在低压配电系统中,母线槽凭借大电流传输能力、高安全性及长寿命特性,成为大型基建、工业厂房、商业建筑等场景的核心配电设备。 扬中金展电气深耕母线槽研发生产 16 年,以严苛的材质标准与精密工艺,打造高可靠母线槽产品ÿ…...

终极指南:5分钟掌握XUnity自动翻译器,轻松实现Unity游戏汉化
终极指南:5分钟掌握XUnity自动翻译器,轻松实现Unity游戏汉化 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为看不懂的日语游戏剧情而烦恼吗?面对满屏英文的游戏界…...

Gradiant宣布完成E轮融资,公司估值达20亿美元,助力加快AI、半导体以及工业水务基建领域布局
随着Gradiant依托AI基建和先进制造业务实现业绩大幅增长,新资金将用于支持战略性并购、新一代技术研发以及上市筹备工作 Gradiant今日宣布完成E轮融资,公司估值达到20亿美元。本轮融资由Safar Partners和Hostplus Superannuation Fund领投,C…...

别再死记硬背了!用这5个HBase Shell实战场景,轻松搞定日常数据操作
HBase Shell实战手册:5个真实场景解锁高效数据操作 在数据爆炸式增长的时代,HBase作为分布式NoSQL数据库的佼佼者,凭借其高吞吐、低延迟的特性,成为处理海量结构化数据的首选方案。然而,许多开发者虽然掌握了基础命令&…...
零成本构建自己的视频切割数据集:我是如何用FFmpeg和TransNet V2训练专属模型的
零成本构建视频切割数据集:FFmpeg与TransNet V2实战指南 在视频内容爆炸式增长的今天,自动检测视频中的镜头切换点(cuts)和渐变过渡(dissolves)成为内容分析的基础需求。无论是影视制作团队需要自动化剪辑&…...

东山精密冲刺港股:第一季营收131亿 净利11亿 市值超4000亿
雷递网 雷建平 5月20日苏州东山精密制造股份有限公司(简称:“东山精密”)日前更新招股书,准备在港交所上市。截至目前,东山精密股价为219.33元,市值约4016亿元。一旦在港股上市,东山精密将形成“AH”的格局…...