神经网络模型与前向传播函数
1.概念
在神经网络中,模型和前向传播函数是紧密相关的概念。模型定义了网络的结构,而前向传播函数描述了数据通过网络的流动方式。以下是这两个概念的详细解释:
1.1 神经网络模型
神经网络模型是指构成神经网络的层、权重、偏置和连接的集合。在 PyTorch 中,模型通常是 torch.nn.Module 的子类。这个类提供了一个框架来定义网络结构,包括:
- 层:网络中的每个层可以是一个
nn.Module,如nn.Linear(全连接层)、nn.Conv2d(卷积层)等。 - 权重和偏置:这些是网络的参数,需要在训练过程中学习。
- 正向传播:数据通过网络的流动方式,通常由
forward方法实现。
1.2 前向传播函数
前向传播函数(forward function)是神经网络中的核心,它定义了输入数据如何通过网络层进行处理以产生输出。在 PyTorch 中,前向传播函数通常在自定义的 nn.Module 子类的 forward 方法中实现。
以下是前向传播函数的关键点:
- 输入:前向传播函数接收输入数据,这通常是张量(tensor)。
- 处理:输入数据通过网络中的层进行处理。这些层可能包括线性变换、激活函数、卷积、池化等。
- 输出:经过一系列处理后,前向传播函数产生输出,这通常是另一个张量。
2.组成
2.1 神经网络模型
神经网络模型是指构成神经网络的层、权重、偏置和连接的集合。为了更深入地理解这个概念,让我们详细探讨一下这些组成部分:
-
层(Layers):
- 神经网络由多个层组成,每一层都包含了一系列的处理单元。
- 常见的层类型包括全连接层(
nn.Linear)、卷积层(nn.Conv2d)、循环层(如nn.LSTM、nn.GRU)和池化层(如nn.MaxPool2d)。
-
权重(Weights):
- 权重是网络中的参数,它们在训练过程中被调整以最小化损失函数。
- 在全连接层中,权重可以看作是输入和输出之间的线性变换矩阵。
- 在卷积层中,权重通常表示为一系列的滤波器或卷积核。
-
偏置(Biases):
- 偏置也是网络中的参数,它们通常与权重一起使用,为网络提供平移不变性。
- 在全连接层中,偏置向每个输出单元添加一个常数,以调整其输出。
-
连接(Connections):
- 连接定义了层之间的数据流动方式。
- 每个神经网络层的输出都会根据网络结构连接到下一层的输入。
-
激活函数(Activation Functions):
- 激活函数是应用于神经网络每一层的输出的非线性函数,如ReLU、sigmoid或tanh。
- 它们引入了非线性,使得网络能够学习和执行更复杂的任务。
-
损失函数(Loss Functions):
- 损失函数衡量了神经网络的预测与真实值之间的差异。
- 常见的损失函数包括均方误差(MSE)、交叉熵(Cross-Entropy)等。
-
优化器(Optimizers):
- 优化器用于在训练过程中更新网络的权重和偏置。
- 常用的优化器包括梯度下降(SGD)、Adam和RMSprop。
-
正向传播(Forward Propagation):
- 正向传播是指数据从输入层通过网络的一系列层流向输出层的过程。
- 在这个过程中,每一层都会对其输入进行一定的计算,并将结果传递给下一层。
-
反向传播(Backpropagation):
反向传播是训练神经网络的关键算法,它通过计算损失函数关于网络参数的梯度,并使用这些梯度来更新权重和偏置。 -
模型训练(Model Training):
模型训练是一个迭代过程,包括前向传播、计算损失、反向传播和参数更新。
在 PyTorch 中,神经网络模型通常通过定义一个继承自 torch.nn.Module 的类来实现。这个类中的 __init__ 方法用于初始化网络的层、权重和偏置,而 forward 方法定义了数据通过网络的流动方式。通过组合这些基本组件,可以构建出能够解决各种复杂问题的神经网络模型。
2.2 前向传播函数
前向传播函数(通常称为 forward 方法)是神经网络的核心,它负责定义模型如何处理输入数据以产生输出。在 PyTorch 中,forward 方法是 torch.nn.Module 子类的一个特殊方法,它被用来指定模型的前向传播过程。
以下是前向传播函数的一些关键点:
-
输入:
forward方法接收输入数据,这通常是张量(tensor)的形式。 -
处理:输入数据通过网络中的层进行处理。这些层可以是线性层、卷积层、循环层、激活函数层等。
-
输出:经过一系列层的处理后,
forward方法产生输出,这通常也是一个张量。 -
自定义:用户可以根据自己的需求自定义
forward方法,这为设计复杂的网络结构提供了灵活性。 -
自动梯度计算:PyTorch 的自动微分系统(Autograd)会在
forward方法执行期间自动计算梯度,这对于训练神经网络至关重要。 -
损失计算:
forward方法的输出通常用于计算损失,这是通过损失函数来实现的。 -
训练与推理:在训练阶段,
forward方法的输出用于计算损失并进行反向传播以更新模型参数。在推理(或测试)阶段,forward方法被用来生成预测而不需要计算梯度。
通过定义 forward 方法,我们可以灵活地构建各种复杂的神经网络架构,以解决不同的机器学习问题。以下是 forward 方法在构建神经网络时的几个关键作用:
-
数据流定义:
forward方法定义了数据通过网络的流动路径。这包括数据如何通过每一层,以及层与层之间的交互。 -
层间连接:在
forward方法中,你可以选择哪些层是顺序连接的,哪些层可能在某个点合并或分支。 -
动态行为:
forward方法可以根据输入数据或其他条件逻辑来动态地改变网络的行为。 -
自定义操作:允许在模型中实现自定义操作,如自定义激活函数、正则化技术或特殊的数学运算。
-
多输入和多输出:
forward方法可以设计为接受多个输入张量,或产生多个输出张量,这在多任务学习等场景中非常有用。 -
集成复杂结构:可以构建包含循环、跳跃连接(如残差连接)或多尺度处理的复杂网络结构。
-
模块化设计:通过将
forward方法分解为单独的函数或模块,可以提高代码的可读性和可维护性。 -
易于集成:定义好的
forward方法可以很容易地集成到更大的机器学习管道中,如数据预处理、特征提取或模型部署。 -
可视化和理解:清晰定义的
forward方法有助于可视化网络结构,帮助研究人员和开发者更好地理解和解释模型的行为。 -
研究和实验:在研究新算法或进行实验时,自定义
forward方法可以快速尝试不同的网络架构和训练策略。
2.1 代码示例
下面是一个使用 forward 方法构建具有残差连接的网络的例子:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass ResNetBlock(nn.Module):def __init__(self, in_channels, out_channels, stride=1):super(ResNetBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)# 残差连接使用的层self.shortcut = nn.Sequential()if stride != 1 or in_channels != out_channels:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(out_channels))def forward(self, x):out = F.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))out = out + self.shortcut(x) # 残差连接out = F.relu(out)return out# 假设输入特征图的通道数为 16
input_tensor = torch.randn(1, 16, 32, 32)# 创建残差块实例
res_block = ResNetBlock(in_channels=16, out_channels=16, stride=1)# 前向传播
output_tensor = res_block(input_tensor)print(output_tensor.shape) 在这个例子中,ResNetBlock 类定义了一个残差网络块,它包含两个卷积层和两个批量归一化层。forward 方法实现了残差连接,它将输入 x 与经过两个卷积层的输出相加。这种设计允许网络训练得更深,同时减少了训练过程中的梯度消失问题。
2.2 自定义的forward 方法
通过自定义 forward 方法,你可以构建几乎任何可以想象到的神经网络架构,以适应你的具体需求。
自定义 forward 方法是 PyTorch 中构建和实现神经网络架构的核心机制。这种方法提供了高度的灵活性,允许研究人员和开发者实现各种复杂的网络结构和算法。以下是一些可以利用自定义 forward 方法实现的神经网络特性和架构:
-
自定义层:创建新的层类型或修改现有层的行为,以适应特定的任务需求。
-
非线性激活:实现自定义的非线性激活函数,或使用特殊的激活函数组合。
-
残差连接:在网络中添加残差连接(如 ResNet 中的那样),以提高训练深层网络的能力。
-
多输入/多输出:构建具有多个输入和/或多个输出的网络,适用于多任务学习或数据融合。
-
跳跃连接:实现跳跃连接或其他复杂的连接模式,如 U-Net 中的连接。
-
注意力机制:集成注意力机制,如 Transformer 模型中的自注意力。
-
循环和序列模型:为序列数据设计循环网络,如 LSTM 或 GRU。
-
动态网络:构建动态网络,其行为可以根据输入数据或其他条件变化。
-
正则化技术:集成各种正则化技术,如 Dropout、权重衰减或批量归一化。
-
损失函数的定制:在
forward方法中直接集成损失函数,以便于计算和优化。 -
混合模型:结合不同的模型类型,如卷积网络和循环网络,以处理多模态数据。
-
条件模型:实现条件模型,其输出依赖于附加的条件输入。
-
生成模型:构建生成对抗网络(GANs)、变分自编码器(VAEs)等生成模型。
-
强化学习模型:为强化学习任务设计特定的网络架构。
-
图神经网络:实现图卷积网络(GCNs)和其他图神经网络架构。
-
分布式和并行训练:设计模型以支持在多个 GPU 或 TPU 上并行训练。
通过自定义 forward 方法,你可以精确控制数据如何通过网络流动,以及如何计算最终的输出。这不仅使得 PyTorch 成为一个强大的研究工具,也为实际应用中的模型创新提供了可能。在自定义 forward 方法时,你可以利用 PyTorch 提供的所有构建块,如层、函数和自动微分,来实现你的创意。
相关文章:

神经网络模型与前向传播函数
1.概念 在神经网络中,模型和前向传播函数是紧密相关的概念。模型定义了网络的结构,而前向传播函数描述了数据通过网络的流动方式。以下是这两个概念的详细解释: 1.1 神经网络模型 神经网络模型是指构成神经网络的层、权重、偏置和连接的集…...

跟我学C++中级篇——内联补遗
一、内联引出的问题 在将一个内联变量定义到编译单元时,然后再按正常的方式使用时,编译会报一个错误“odr-used”。ODR,One Definition Rule,单一定义规则。在C/C程序中,变量的定义只能有一处,至于ODR的规…...

SLAM 面试题
持续完善 SLAM的基本概念和组成部分 描述一下什么是SLAM以及它的基本任务。 SLAM系统主要由哪些部分组成?SLAM的类型和算法 请解释滤波器SLAM(如粒子滤波)和图优化SLAM(如Google的Cartographer)之间的区别。 你如何区…...

csapp proxy lab part 1
host, hub, 路由器,和 交换机 当手机连接到局域网中时,它需要找到网络中的交换机(Switch)。这通常是通过 DHCP(动态主机配置协议)完成的。DHCP服务器负责向手机分配IP地址、子网掩码、网关地址等网络配置信…...
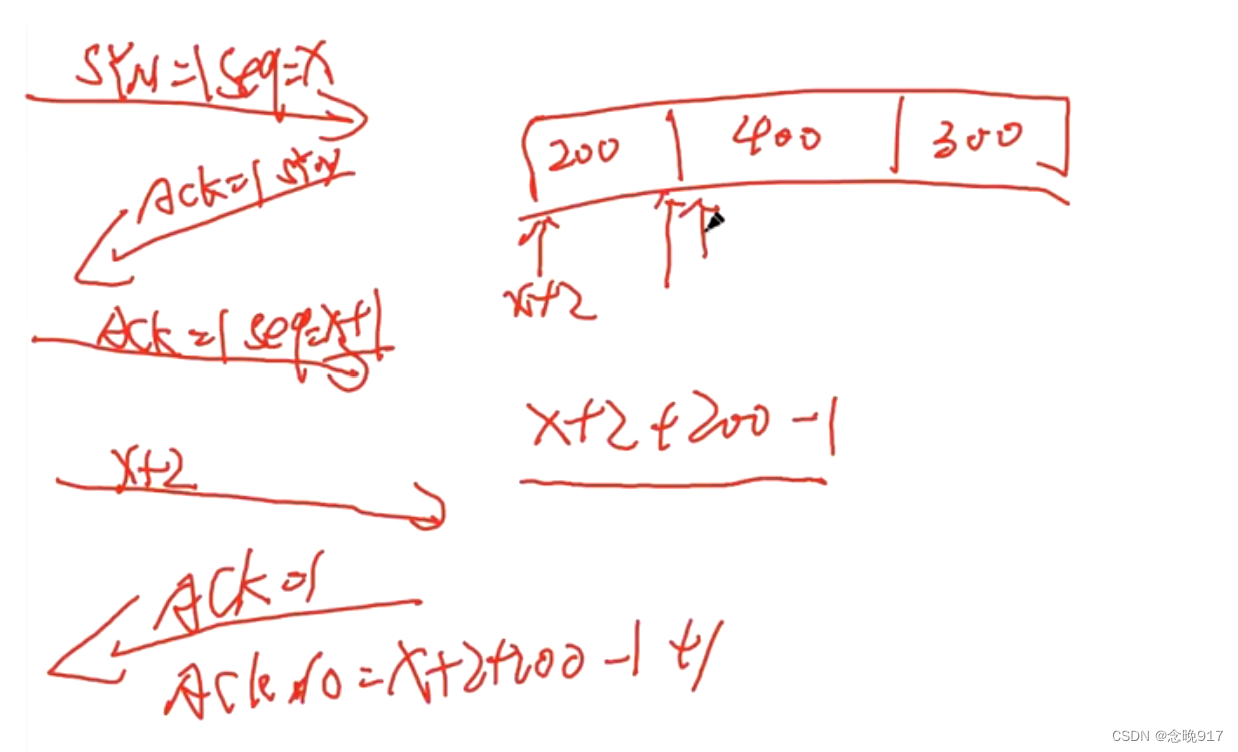
TCP三次握手四次挥手 UDP
TCP是面向链接的协议,而UDP是无连接的协议 TCP的三次握手 三次传输过程是纯粹的不涉及数据,三次握手的几个数据包中不包含数据内容。它的应用层,数据部分是空的,只是TCP实现会话建立,点到点的连接 TCP的四次挥手 第四…...
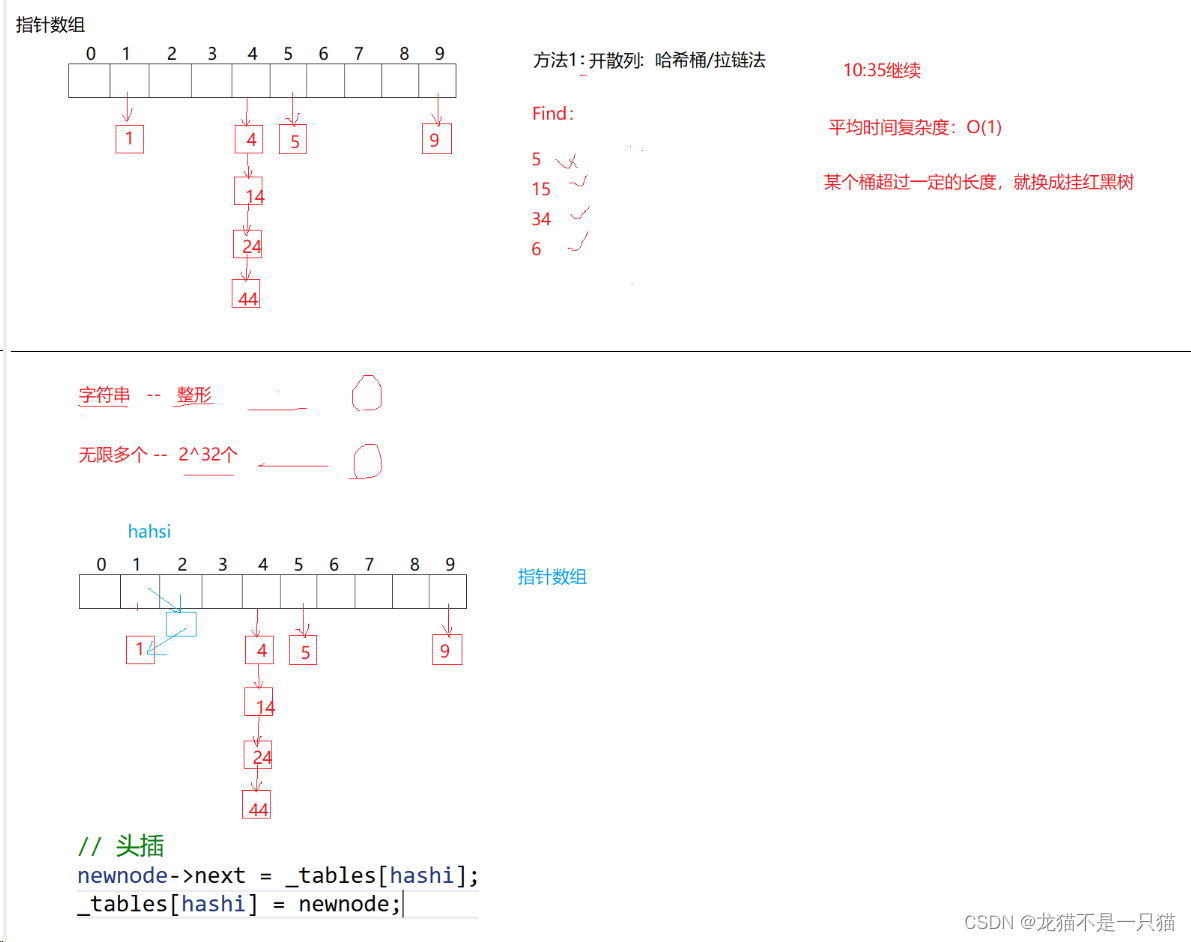
哈希表(unordered_set、unordered_map)
文章目录 一、unordered_set、unordered_map的介绍二、哈希表的建立方法2.1闭散列2.2开散列(哈希桶/拉链法) 三、闭散列代码(除留余数法)四、开散列代码(拉链法/哈希桶) 一、unordered_set、unordered_map的…...
Docker 加持的安卓手机:随身携带的知识库(一)
这篇文章聊聊,如何借助 Docker ,尝试将一台五年前的手机,构建成一个随身携带的、本地化的知识库。 写在前面 本篇文章,我使用了一台去年从二手平台购入的五年前的手机,K20 Pro。 为了让它能够稳定持续的运行…...
本地连接服务器Jupyter【简略版】
首先需要在你的服务器激活conda虚拟环境: 进入虚拟环境后使用conda install jupyter命令安装jupyter: 安装成功后先不要着急打开,因为需要设置密码,使用jupyter notebook password命令输入自己进入jupyter的密码: …...

sql 注入 1
当前在email表 security库 查到user表 1、第一步,知道对方goods表有几列(email 2 列 good 三列,查的时候列必须得一样才可以查,所以创建个临时表,select 123 ) 但是你无法知道对方goods表有多少列 用order …...
Excel中实现md5加密
1.注意事项 (1)在Microsoft Excel上操作 (2)使用完,建议修改的配置全部还原,防止有风险。 2.准备MD5宏插件 MD5加密宏插件放置到F盘下(直接F盘下,不用放到具体某一个文件夹下) 提示:文件在文章顶部&…...

写SQL的心得
1、统计 COUNT(列名) 和COUNT(*)均可,区别是前者只会统计非NULL。 2、where后面不能跟聚合函数,用的话应该在Having使用,因此需要先分组GroupBy where是基于行过滤,having是基于分…...
经典权限五张表功能实现
文章目录 用户模块(未使用框架)查询功能实现步骤代码 新增功能实现步骤代码 修改功能实现步骤代码实现 删除功能实现步骤代码实现 用户模块会了,其他两个模块与其类似 用户模块(未使用框架) 查询功能 这里将模糊查询和分页查询写在一起 实现步骤 前端࿱…...
实验八 Linux虚拟内存 实验9.1:统计系统缺页次数成功案例
运行环境: VMware17.5.1 build-23298084Ubuntu 16.04LTS ubuntu版本下载地址Linux-4.16.10 linux历史版本下载地址虚拟机配置:硬盘一般不少于40G就行 内核版本不同内核文件代码也有出入,版本差异性令c文件要修改,如若要在linux6.7…...

SD-WAN提升Microsoft 365用户体验
随着数字化时代的到来,SaaS应用如Microsoft 365已经成为各类企业的主流选择。在这一趋势下,企业需要以更加灵活、高效的方式使用Microsoft 365,以满足日益增长的业务需求。而传统的网络基础设施可能无法满足这一需求,因此…...

C#中的异步编程模型
在C#中,async和await关键字是用于异步编程的重要部分,它们允许你以同步代码的方式编写异步代码,从而提高应用程序的响应性和吞吐量。这种异步编程模型在I/O密集型操作(如文件读写、网络请求等)中特别有用,因…...

博通Broadcom (VMware VCP)注册约考下载证书操作手册
博通Broadcom(VMware) CertMetrics 注册约考下载证书等操作指导手册(发布日期:2024-5-11) 目录 一、原 Mylearn 账号在新平台的激活… 1 二、在新平台查看并下载证书… 5 三、在新平台注册博通账号… 6 四、在新平台下注册考试… 10 一、原…...

Xilinx FPGA底层逻辑资源简介(1):关于LC,CLB,SLICE,LUT,FF的概念
LC:Logic Cell 逻辑单元 Logic Cell是Xilinx定义的一种标准,用于定义不同系列器件的大小。对于7系列芯片,通常在名字中就已经体现了LC的大小,在UG474中原话为: 对于7a75t芯片,LC的大小为75K,6输…...
简介)
SSH(安全外壳协议)简介
一、引言 SSH(Secure Shell)是一种加密的网络传输协议,用于在不安全的网络中提供安全的远程登录和其他安全网络服务。SSH最初由芬兰程序员Tatu Ylnen开发,用于替代不安全的telnet、rlogin和rsh等远程登录协议。通过SSH࿰…...

JavaScript异步编程——08-Promise的链式调用【万字长文,感谢支持】
前言 实际开发中,我们经常需要先后请求多个接口:发送第一次网络请求后,等待请求结果;有结果后,然后发送第二次网络请求,等待请求结果;有结果后,然后发送第三次网络请求。以此类推。…...

现代制造之数控机床篇
现代制造 有现代技术支撑的制造业,即无论是制造还是服务行业,添了现代两个字不过是因为有了现代科学技术的支撑,如发达的通信方式,不断发展的互联网,信息化程度加强了,因此可以为这两个行业增加了不少优势…...

Legacy iOS Kit:让旧iPhone重获新生的终极降级工具
Legacy iOS Kit:让旧iPhone重获新生的终极降级工具 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit 你是…...

告别手动肝船!碧蓝航线自动化脚本Alas终极使用指南
告别手动肝船!碧蓝航线自动化脚本Alas终极使用指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝航…...
)
Perplexity名言警句搜索深度解析(2024年Q2最新API行为逆向实测报告)
更多请点击: https://intelliparadigm.com 第一章:Perplexity名言警句搜索深度解析(2024年Q2最新API行为逆向实测报告) Perplexity 在 2024 年第二季度对 /search 端点实施了细粒度的请求签名验证与上下文指纹绑定机制࿰…...

ArcGIS点符号压盖标注看不清?试试‘合并图层+制图表达’这个组合拳
ArcGIS点符号压盖标注看不清?试试‘合并图层制图表达’这个组合拳 在GIS制图工作中,点位数据密集区域的标注压盖问题堪称"地图美学杀手"。想象一下这样的场景:某村庄同时存在水文站、水位站和雨量站三个监测点,由于地理…...
)
RuoYi-Cloud项目导入避坑指南:从Maven配置到依赖下载的完整流程(附常见错误解决)
RuoYi-Cloud项目导入避坑指南:从Maven配置到依赖下载的完整流程 1. 项目准备与环境检查 在开始导入RuoYi-Cloud项目之前,确保你的开发环境已经准备就绪。这个微服务架构项目基于Spring Cloud Alibaba体系,对开发环境有特定要求: 基…...

实测对比:PC817自补偿 vs 专用线性光耦,在STM32/Arduino项目里到底该怎么选?
PC817自补偿 vs 专用线性光耦:嵌入式信号隔离方案实战指南 在STM32或Arduino项目中处理模拟信号隔离时,工程师们常陷入两难:是花时间用廉价光耦搭建自补偿电路,还是直接采购专用线性光耦模块?这个看似简单的选择背后&a…...

终极指南:如何用5分钟安装FF14动画跳过插件提升副本效率
终极指南:如何用5分钟安装FF14动画跳过插件提升副本效率 【免费下载链接】FFXIV_ACT_CutsceneSkip 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_ACT_CutsceneSkip 还在为《最终幻想14》国服副本中冗长的动画而烦恼吗?FFXIV_ACT_Cutscene…...

仓库盘点、物流交接?用UniApp+PDA扫码提升效率的实战配置与避坑指南
UniAppPDA扫码在仓储物流中的实战配置与效率提升指南 当仓储管理员小李第一次使用传统扫码枪配合PC系统进行月度盘点时,他需要反复核对Excel表格与实物位置,8小时的工作量常常延长到深夜。而现在,通过UniApp开发的移动端应用配合工业级PDA设备…...
)
从场景到代码:如何用研华Navigator为PCIE1751规划数据采集方案(AI/AO/DI/DO全解析)
从场景到代码:如何用研华Navigator为PCIE1751规划数据采集方案(AI/AO/DI/DO全解析) 在工业自动化领域,数据采集系统的设计往往面临一个核心矛盾:硬件性能的丰富性与实际需求的精准匹配。研华PCIE-1751作为一款多功能数…...

企业级RAG系统数据可信生死线:Perplexity验证功能内测权限仅剩最后17个——附白名单申请通道
更多请点击: https://kaifayun.com 第一章:企业级RAG系统数据可信生死线:Perplexity验证功能内测权限仅剩最后17个——附白名单申请通道 在企业级RAG(Retrieval-Augmented Generation)系统中,检索结果与生…...