Hive大表join大表如何调优
目录
- 一、调优思路
- 1、SQL优化
- 1.1 大小表join
- 1.2 大大表join
- 2、insert into替换union all
- 3、排序order by换位sort by
- 4、并行执行
- 5、数据倾斜优化
- 6、小文件优化
- 二、实战
- 2.1 场景
- 2.2 限制所需的字段,间接mapjoin
- 2.2 解决异常值倾斜,如NULL加随机数打散
- 2.3 扩容解决数据倾斜
- 2.3.1 客户表扩大N倍
- 2.3.2 部分倾斜key扩容,大卖家扩容
- 2.3.3 推荐:分而治之:倾斜和非倾斜再union all
在Hive中,优化器会根据统计信息决定是将大表放在前面(Join的左边)还是小表放在前面。通常,优化器会选择数据量较小的表作为驱动表(小表作为左边),因为这样可以减少内存消耗并提高效率。
但是,如果你有特定的需求,比如你知道大部分数据能快速过滤掉,希望减少任务的执行时间,那么你可以强制指定某个表作为小表。在Hive中,可以使用/*+ MAPJOIN(table_name) */ 注释来强制将一个大表作为小表处理。
例如,如果你想要将big_table作为小表:
SELECT /*+ MAPJOIN(big_table) */a.column1, a.column2, b.column1, b.column2
FROMsmall_table a
JOINbig_table b
ONa.common_column = b.common_column;
一、调优思路
1、SQL优化
1.1 大小表join
1、mapjoin,小表使用mapjoin,或者强制hint
2、将大表放后头,原因:Hive假定查询中最后的一个表是大表。它会将其它表缓存起来,然后扫描最后那个表。因此通常需要将小表放前面,或者标记哪张表是大表:/*streamtable(table_name) */
3、过滤无效值:空值、不使用的字段等。
4、不能过滤的空值,将空值转化为随机数避免数据倾斜。
1.2 大大表join
1)创建第二张大表
create table bigtable2(id bigint,t bigint,uid string,keyword string,url_rank int,click_num int,click_url string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/data/bigtable' into table bigtable2;2)测试大表直接JOIN
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable a
join bigtable2 b
on a.id = b.id;
测试结果:Time taken: 72.289 seconds
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable a
join bigtable2 b
on a.id = b.id;3)创建分桶表1
create table bigtable_buck1(id bigint,t bigint,uid string,keyword string,url_rank int,click_num int,click_url string)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';load data local inpath '/opt/module/data/bigtable' into table bigtable_buck1;4)创建分桶表2,分桶数和第一张表的分桶数为倍数关系
create table bigtable_buck2(id bigint,t bigint,uid string,keyword string,url_rank int,click_num int,click_url string)
clustered by(id)
sorted by(id)
into 6 buckets
row format delimited fields terminated by '\t';load data local inpath '/opt/module/data/bigtable' into table bigtable_buck2;5)设置参数
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;6)测试 Time taken: 34.685 seconds
insert overwrite table jointable
select b.id, b.t, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
from bigtable_buck1 s
join bigtable_buck2 b
on b.id = s.id;
1、使用相同的连接键
- 当对3个或者更多个表进行join连接时,如果每个on子句都使用相同的连接键的话,那么只会产生一个MapReduce job。
2、过滤无效、未使用的数据:减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段。
加随机数打散
1)空值0值 或 关联不上的,用随机数
from a join b
on if(a.key=’’, rand(id)%10, a.key)=b.key
–rand() 0-1之间的小数(2)都是有用的key,则加随机数后缀
group by concat(key, cast(round(rand()*10) as int))
缺点是分成10份是提前写好的,数据变更大时,还是会跑得慢。
3、逻辑拆分,使用中间表计算
- 尽量原子化操作:多个表关联时,避免包含复杂逻辑大sql(因为无法控制中间job),最好分拆成小段,可以使用中间表来完成复杂的逻辑
- 写入HDFS之后:多次INSERT OVERWRITE TABLE写法参考:spark调优-小文件问题
4、列裁剪,避免使用select * 如果查询的是分区表,一定要记得带上分区条件
5、where条件写在子查询中:先过滤再关联(最好使用这种笨办法,虽然hive3.0自带谓词下推)
6、关联条件写在on中,而不是where中
- 非主表谓词下推情况下,可以理解为where是全部执行完在reduce中进行过滤,on是在关联过程中filter
7、数据量小时,用in代替join
8、使用semi join替代in/exists
inner join和left semi join的联系和区别
2、insert into替换union all
如果union all的部分个数大于2,或者每个union部分数据量大,应该拆成多个insert into 语句,效率有提升。
?insert into到不同分区?
3、排序order by换位sort by
order by:对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序),只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
sort by:局部排序,保证每个reducer的输出文件是有序的。
hive order by,sort by, distribute by, cluster by作用以及用法
4、并行执行
Hive会将一个查询转化成一个或者多个阶段。这样的阶段可以是MapReduce阶段、抽样阶段、合并阶段、limit阶段。或者Hive执行过程中可能需要的其他阶段。
默认情况下,Hive一次只会执行一个阶段。不过,某个特定的job可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个job的执行时间缩短。如果有更多的阶段可以并行执行,那么job可能就越快完成。
通过设置参数hive.exec.parallel值为true,就可以开启并发执行。在共享集群中,需要注意下,如果job中并行阶段增多,那么集群利用率就会增加。
set hive.exec.parallel=true; //打开任务并行执行
set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8。
set hive.exec.parallel=true
5、数据倾斜优化
spark-数据倾斜、
hadoop-hive-数据倾斜问题
6、小文件优化
spark调优-小文件问题
参考链接
HiveSQL大表join大表数据倾斜
二、实战
添加链接描述
2.1 场景
【背景】
A表为一个汇总表,汇总的是卖家买家最近N天交易汇总信息,即对于每个卖家最近N天,其每个买家共成交了多少单,总金额是多少,假设N取90天,汇总值仅取成交单数。
A表的字段有:buyer_id、seller_id、pay_cnt_90day。
B表为卖家基本信息表,其字段有seller_id、sale_level,其中sale_levels是卖家的一个分层评级信息,比如吧卖家分为6个级别:S0、S1、S2、S3、S4和S5。
要获得的结果是每个买家在各个级别的卖家的成交比例信息,比如:某买家:S0:10%;S1:20%;S2:20%;S3:10%;S4:20%;S5:10%。
【初始思路】
第一反应是直接join两表并统计:
selectm.buyer_id,sum(pay_cnt_90day) as pay_cnt_90day,sum(case when m.sale_level = 0 then pay_cnt_90day end) as pay_cnt_90day_s0,sum(case when m.sale_level = 1 then pay_cnt_90day end) as pay_cnt_90day_s1,sum(case when m.sale_level = 2 then pay_cnt_90day end) as pay_cnt_90day_s2,sum(case when m.sale_level = 3 then pay_cnt_90day end) as pay_cnt_90day_s3,sum(case when m.sale_level = 4 then pay_cnt_90day end) as pay_cnt_90day_s4,sum(case when m.sale_level = 5 then pay_cnt_90day end) as pay_cnt_90day_s5from (select a.buer_id, a.seller_id, b.sale_level, a.pay_cnt_90dayfrom ( select buyer_id, seller_id, pay_cnt_90day from table_A) ajoin(select seller_id, sale_level from table_B) bon a.seller_id = b.seller_id) mgroup by m.buyer_id
但是此SQL会引起数据倾斜,原因在于卖家的二八准则,某些卖家90天内会有几百万甚至上千万的买家,但是大部分的卖家90天内买家的数目并不多,join table_A和table_B的时候,ODPS会按照seller_id进行分发,table_A的大卖家引起了数据倾斜。但是数据本身无法用mapjoin table_B解决,因为卖家超过千万条,文件大小有几个GB,超过了1GB的限制。
2.2 限制所需的字段,间接mapjoin
思路:只看90天内有交易的卖家,不join全部的卖家表
局限:此方案在一些情况可以起作用,但是很多时候还是无法解决上述问题,因为大部分卖家尽管90天内买家不多,但还是有一些的,过滤后的B表仍然很多。
selectm.buyer_id,sum(pay_cnt_90day) as pay_cnt_90day,sum(case when m.sale_level = 0 then pay_cnt_90day end) as pay_cnt_90day_s0,sum(case when m.sale_level = 1 then pay_cnt_90day end) as pay_cnt_90day_s1,sum(case when m.sale_level = 2 then pay_cnt_90day end) as pay_cnt_90day_s2,sum(case when m.sale_level = 3 then pay_cnt_90day end) as pay_cnt_90day_s3,sum(case when m.sale_level = 4 then pay_cnt_90day end) as pay_cnt_90day_s4,sum(case when m.sale_level = 5 then pay_cnt_90day end) as pay_cnt_90day_s5from ( select /*+mapjoin(b)*/a.buer_id, a.seller_id, b.sale_level, a.pay_cnt_90dayfrom ( select buyer_id, seller_id, pay_cnt_90day from table_A) ajoin (select seller_id, sale_level from table_B b0join(select seller_id from table_A group by seller_id) a0on b0.seller_id = a0.selller_id) bon a.seller_id = b.seller_id) mgroup by m.buyer_id
2.2 解决异常值倾斜,如NULL加随机数打散
**思路:**核心是将这些引起倾斜的值随机分发到Reduce,join时对这些特殊值concat随机数,从而达到随机分发的目的。
**适用于:**倾斜的值是明确的而且数量很少,比如null值引起的倾斜。
**局限:**无法解决本问题场景的倾斜问题,因为倾斜的卖家大量存在而且动态变化。
此方案的核心逻辑如下:
select a.user_id, a.order_id, b.user_idfrom table_a a join table_b bon (case when a.user_is is null then concat('hive', rand(id)) else a.user_id end) = b.user_idHive 已对此进行了优化,只需要设置参数skewinfo和skewjoin参数,不修改SQL代码,例如,由于table_B的值“0” 和“1”引起了倾斜,值需要做如下设置:
set hive.optimize.skewinfo=table_B:(selleer_id) [ ( "0") ("1") ) ]
set hive.optimize.skewjoin = true;
2.3 扩容解决数据倾斜
推荐”2.3.3 推荐:分而治之:倾斜和非倾斜再union all“,可直接看。若不行,推荐方案2.3.2倾斜key扩容。
2.3.1 客户表扩大N倍
思路:按照seller_id分发会倾斜,那么再人工增加一列进行分发,这样之前倾斜的值的倾斜程度会减少到原来的1/10,可以通过配置numbers表改放大倍数来降低倾斜程度。
代码实现:建立一个numbers表,其值只有一列int 行,比如从1到10(具体值可根据倾斜程度确定),然后放大B表10倍,再取模join。
局限性:数据量翻倍,B表也会膨胀N倍。
SELECT m.buyer_id,sum(pay_cnt_90day) AS pay_cnt_90day,sum(case WHEN m.sale_level = 0 THEN pay_cnt_90day end) AS pay_cnt_90day_s0, sum(case WHEN m.sale_level = 1 THEN pay_cnt_90day end) AS pay_cnt_90day_s1,sum(case WHEN m.sale_level = 2 THEN pay_cnt_90day end) AS pay_cnt_90day_s2, sum(case when m.sale_level = 3 then pay_cnt_90day end) as pay_cnt_90day_s3,sum(case when m.sale_level = 4 then pay_cnt_90day end) as pay_cnt_90day_s4,sum(case when m.sale_level = 5 then pay_cnt_90day end) as pay_cnt_90day_s5
FROM (SELECT a.buer_id,a.seller_id,b.sale_level,a.pay_cnt_90dayFROM (SELECT buyer_id,seller_id,pay_cnt_90dayFROM table_A) aJOIN -- 将B表扩容N倍(SELECT /*+mapjoin(members)*/ seller_id,sale_level ,memberFROM table_BJOIN members -- 扩容N倍的表) bON a.seller_id = b.seller_idAND mod(a.pay_cnt_90day,10)+1 = b.number ) mGROUP BY m.buyer_id
2.3.2 部分倾斜key扩容,大卖家扩容
思路:把大卖家放大倍数即可:需要首先知道大卖家的名单,即先建立一个临时表动态存放每天最新的大卖家(比如dim_big_seller),同时此表的大卖家要膨胀预先设定的倍数(1000倍)。
代码实现:在A表和B表分别新建一个join列,其逻辑为:如果是大卖家,那么concat一个随机分配正整数(0到预定义的倍数之间,本例为0~1000);如果不是,保持不变。
局限性: 相比全部数据扩容,仅倾斜指标扩容的运行效率有提升,但代码复杂性高,必须首先建立大数据表。
SELECT m.buyer_id,sum(pay_cnt_90day) AS pay_cnt_90day,sum(case WHEN m.sale_level = 0 THEN pay_cnt_90day end) AS pay_cnt_90day_s0, sum(case WHEN m.sale_level = 1 THEN pay_cnt_90day end) AS pay_cnt_90day_s1,sum(case WHEN m.sale_level = 2 THEN pay_cnt_90day end) AS pay_cnt_90day_s2, sum(case when m.sale_level = 3 then pay_cnt_90day end) as pay_cnt_90day_s3,sum(case when m.sale_level = 4 then pay_cnt_90day end) as pay_cnt_90day_s4,sum(case when m.sale_level = 5 then pay_cnt_90day end) as pay_cnt_90day_s5pay_cnt_90day end) AS pay_cnt_90day_s5
FROM (SELECT a.buer_id,a.seller_id,b.sale_level,a.pay_cnt_90dayFROM (SELECT /*+mapjoin(big)*/ buyer_id,seller_id,pay_cnt_90day,if(big.seller_id is NOT null,concat( table_A.seller_id,'rnd', cast( rand() * 1000 AS bigint ), table_A.seller_id) AS seller_id_joinkeyFROM table_A left outerJOIN --big表seller_id有重复,请注意一定要group by 后再join,保证table_A的行数保持不变 ( SELECT seller_idFROM dim_big_sellerGROUP BY seller_id)bigON table_A.seller_id = big.seller_id ) aJOIN (SELECT /*+mapjoin(big)*/ seller_id,sale_level ,--big表的seller_id_joinkey生成逻辑和上面的生成逻辑一样 coalesce(seller_id_joinkey,table_B.seller_id) AS seller_id_joinkeyFROM table_B left out JOIN --table_B表join大卖家表后大卖家行数扩大1000倍,其它卖家行数保持不变 (SELECT seller_id,seller_id_joinkeyFROM dim_big_seller) bigON table_B.seller_id= big.seller_id ) bON a.seller_id_joinkey= b.seller_id_joinkeyAND mod(a.pay_cnt_90day,10)+1 = b.number ) mGROUP BY m.buyer_id
2.3.3 推荐:分而治之:倾斜和非倾斜再union all
思路:对倾斜的键值和不倾斜的键值分开处理,不倾斜的正常join即可,倾斜的把他们找出来做mapjoin,最后union all其结果即可。
代码实现:
局限性:较麻烦,代码复杂而且需要一个临时表存放倾斜的键值。
--1、构建临时表,由于数据倾斜,先找出90天买家超过10000的卖家
insert overwrite table temp_table_B
SELECT m.seller_id,n.sale_level
FROM (SELECT seller_idFROM (SELECT seller_id,count(buyer_id) AS byr_cntFROM table_AGROUP BY seller_id ) aWHERE a.byr_cnt >10000 ) mLEFT JOIN (SELECT seller_id,sale_levelFROM table_B ) nON m.seller_id = n.seller_id; --2、分而治之,不倾斜union all 倾斜。--对于90天买家超过10000的卖家直接mapjoin,对其它卖家直接正常join即可。SELECT m.buyer_id,sum(pay_cnt_90day) AS pay_cnt_90day,sum(case WHEN m.sale_level = 0 THEN pay_cnt_90day end) AS pay_cnt_90day_s0, sum(case WHEN m.sale_level = 1 THEN pay_cnt_90day end) AS pay_cnt_90day_s1,sum(case WHEN m.sale_level = 2 THEN pay_cnt_90day end) AS pay_cnt_90day_s2, sum(case when m.sale_level = 3 then pay_cnt_90day end) as pay_cnt_90day_s3,sum(case when m.sale_level = 4 then pay_cnt_90day end) as pay_cnt_90day_s4,sum(case when m.sale_level = 5 then pay_cnt_90day end) as pay_cnt_90day_s5
FROM (SELECT a.buer_id,a.seller_id,b.sale_level,a.pay_cnt_90dayFROM (SELECT buyer_id,seller_id,pay_cnt_90dayFROM table_A) aJOIN (SELECT seller_id,a.sale_levelFROM table_A aLEFT JOIN temp_table_B bON a.seller_id = b.seller_idWHERE b.seller_id is NULL -- 限制为不倾斜的卖家) bON a.seller_id = b.seller_idUNION allSELECT /*+mapjoin(b)*/ a.buer_id,a.seller_id,b.sale_level,a.pay_cnt_90dayFROM (SELECT buyer_id,seller_id,pay_cnt_90dayFROM table_A) aJOIN (SELECT seller_id,sale_levelFROM table_B -- 只看倾斜卖家) bON a.seller_id = b.seller_id) mGROUP BY m.buyer_id ) mGROUP BY m.buyer_id
相关文章:

Hive大表join大表如何调优
目录 一、调优思路1、SQL优化1.1 大小表join1.2 大大表join 2、insert into替换union all3、排序order by换位sort by4、并行执行5、数据倾斜优化6、小文件优化 二、实战2.1 场景2.2 限制所需的字段,间接mapjoin2.2 解决异常值倾斜,如NULL加随机数打散2.…...

SAF文件选择、谷歌PhotoPicker图片视频选择与真实路径转换
一、构建选择文件与回调方法 //文件选择回调ActivityResultLauncher<String[]> pickFile registerForActivityResult(new ActivityResultContracts.OpenDocument(), uri->{if (uri ! null) {Log.e("cxy", "返回的uri:" uri);Log.e("cxy&q…...

java可变参数
前言 我们虽然能够用重载实现,但多个参数无法弹性匹配 代码 class mycalculator{//下面的四个calculate方法构成了重载//计算2个数的和,3个数的和,4,5,6个数的和// public void calculate(int n1){// System.out.…...

Flutter 中的 Expanded 小部件:全面指南
Flutter 中的 Expanded 小部件:全面指南 在 Flutter 中,Expanded 是一个用于控制子控件占据可用空间的布局小部件,通常与 Row、Column 或 Flex 等父级布局小部件一起使用。Expanded 允许你创建灵活的布局,其中子控件可以按照指定…...
[Kubernetes] KubeKey 部署 K8s v1.28.8
文章目录 1.K8s 部署方式2.操作系统基础配置3.安装部署 K8s4.验证 K8s 集群5.部署测试资源 1.K8s 部署方式 kubeadm: kubekey, sealos, kubespray二进制: kubeaszrancher 2.操作系统基础配置 主机名内网IP外网IPmaster192.168.66.2139.198.9.7node1192.168.66.3139.198.40.17…...

C# 与 Qt 的对比分析
C# 与 Qt 的对比分析 目录 C# 与 Qt 的对比分析 1. 语言特性 2. 开发环境 3. 框架和库 4. 用户界面设计 5. 企业级应用 6. 性能考量 在软件开发领域,C# 和 Qt 是两种常用的技术栈,它们分别在.NET平台和跨平台桌面应用开发中占据重要位置。本文将深…...
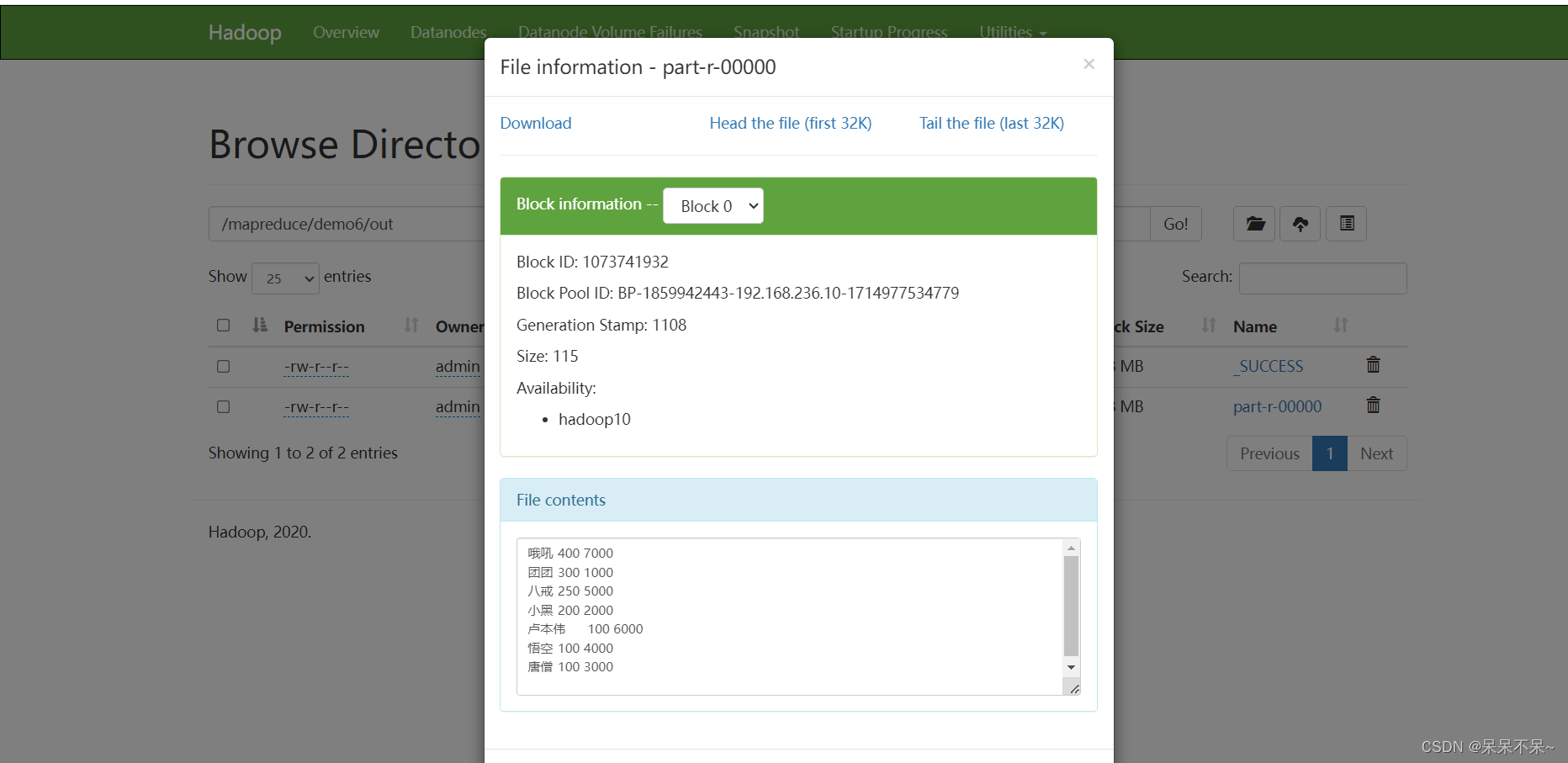
MapReduce | 二次排序
1.需求 主播数据--按照观众人数降序排序,如果观众人数相同,按照直播时长降序 # 案例数据 用户id 观众人数 直播时长 团团 300 1000 小黑 200 2000 哦吼 400 7000 卢本伟 100 6000 八戒 250 5000 悟空 100 4000 唐僧 100 3000 # 期望结果 哦吼 4…...

Java后端初始化项目(项目模板)
介绍 emmmm,最近看了一些网络资料,也是心血来潮,想自己手工搭建一个java后端的初始化项目模板来简化一下开发,也就发一个模板的具体制作流程,(一步一步搭建,从易到难) okÿ…...
)
electron 多窗口 vuex/pinia 数据状态同步简易方案(利用 LocalStorage)
全局 stroe 添加 mutations 状态同步方法 // 用于其他窗口同步 vuex 中的 DeviceTcpDataasyncDeviceTcpData(state: StateType, data: any) {state.deviceTcpData data},App.vue 里 onMounted(() > {console.log("App mounted");/*** vuex 多窗口 store 同步*//…...

自定义数据集图像分类实现
模型训练 要使用自己的图片分类数据集进行训练,这意味着数据集应该包含一个目录,其中每个子目录代表一个类别,子目录中包含该类别的所有图片。以下是一个使用Keras和TensorFlow加载自定义图片数据集进行分类训练的例子。 我们自己创建的数据集…...

【C++】手搓读写ini文件源码
【C】手搓读写ini文件源码 思路需求:ini.hini.cppconfig.confmian.cpp 思路 ini文件是一种系统配置文件,它有特定的格式组成。通常做法,我们读取ini文件并按照ini格式进行解析即可。在c语言中,提供了模板类的功能,所以…...

undolog
undolog回滚段 undolog执行的时间:在执行器操作bufferpool之前。 undolog页...

项目文档分享
Hello , 我是小恒。提前祝福妈妈母亲节快乐 。 本文写一篇初成的项目文档 (不是README.md哈),仅供参考 项目名称 脚本存储网页 项目简介 本项目旨在创建一个网页,用于存储和展示各种命令,用户可以通过粘贴复制命令到…...
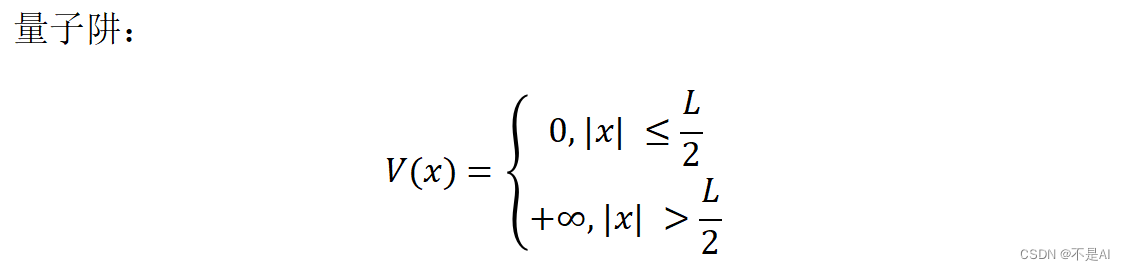
【深耕 Python】Quantum Computing 量子计算机(5)量子物理概念(二)
写在前面 往期量子计算机博客: 【深耕 Python】Quantum Computing 量子计算机(1)图像绘制基础 【深耕 Python】Quantum Computing 量子计算机(2)绘制电子运动平面波 【深耕 Python】Quantum Computing 量子计算机&…...

手写Spring5【笔记】
Spring5【笔记】 前言前言推荐Spring5【笔记】1介绍2手写 最后 前言 这是陈旧已久的草稿2022-12-01 23:32:59 这个是刷B站的时候,看到一个手写Spring的课程。 最后我自己好像运行不了,就没写。 现在2024-5-12 22:22:46,发布到[笔记]专栏中…...

2024中国(重庆)机器人展览会8月举办
2024中国(重庆)机器人展览会8月举办 邀请函 主办单位: 中国航空学会 重庆市南岸区人民政府 招商执行单位: 重庆港华展览有限公司 2024中国重庆机器人展会将汇聚机器人全产业链知名企业,世界科技领先的生产制造企业与来自多个国家和地区…...
)
Apache 开源项目文档中心 (英文 + 中文)
进度:持续更新中。。。 Apache Ambari 2.7.5 Apache Ambari Installation 2.7.5.0 (latest)Apache Ambari Installation 2.7.5.0 中文版 (latest) Apache DolphinScheduler Apache DolphinScheduler 1.2.0 中文版Apache DolphinScheduler 1.2.1 中文版...

蓝桥杯 算法提高 ADV-1164 和谐宿舍 python AC
贪心,二分 同类型题:蓝桥杯 算法提高 ADV-1175 打包 def judge(x):wood 0max_val 0ans_len 0for i in ll:if i > x:return Falseelif max(max_val, i) * (ans_len 1) < x:max_val max(max_val, i)ans_len 1else:wood 1max_val ians_len …...
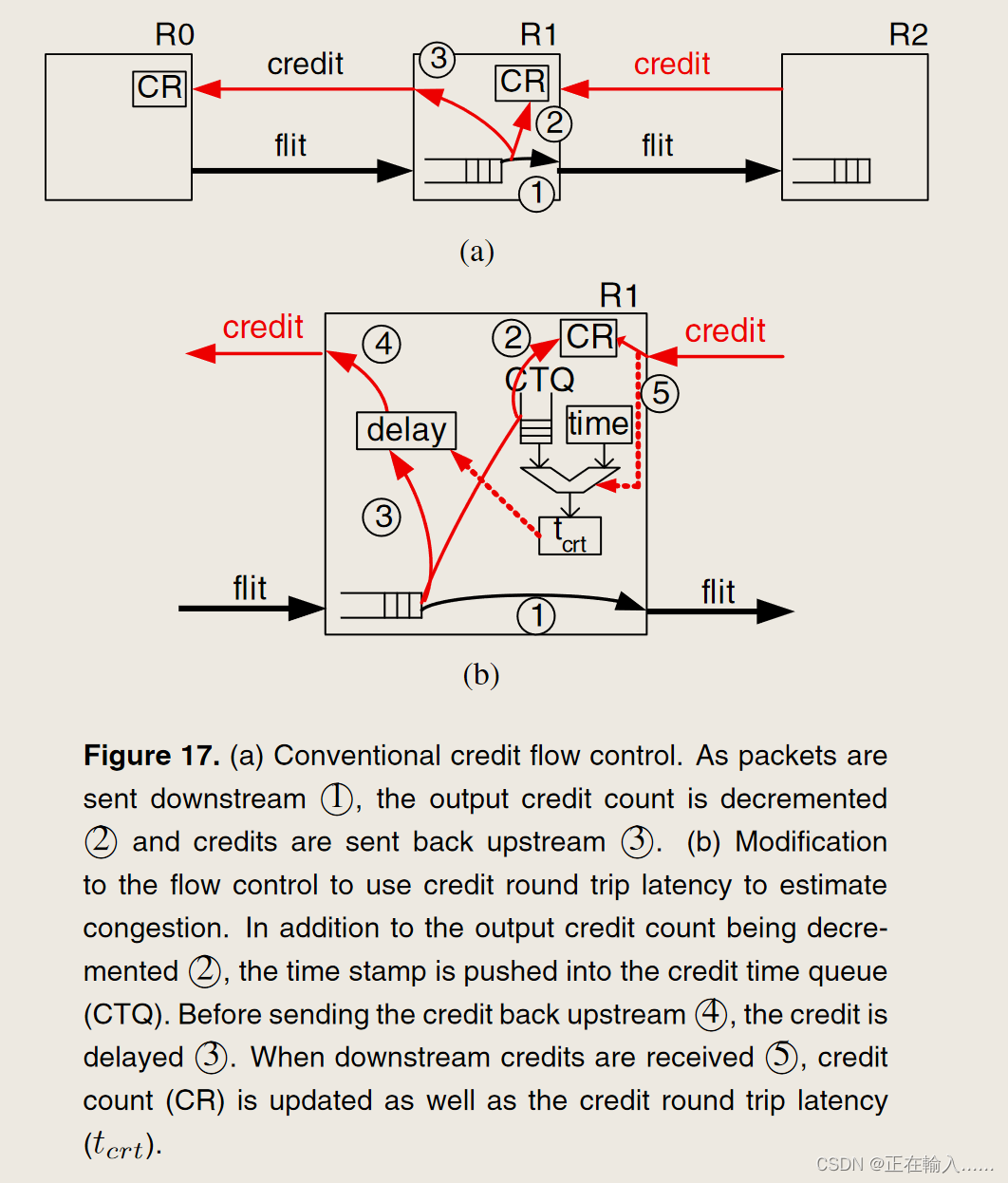
Dragonfly 拓扑的路由算法
Dragonfly 拓扑的路由算法 1. Dragonfly 上的路由 (1)最小路由(2)非最小路由 2. 评估3. 存在问题 (1)吞吐量限制(2)较高的中间延迟 references Dragonfly 拓扑的路由算法 John Kim, William J. Dally 等人在 2008 年的 ISCA 中提出技术驱动、高度可扩展的 Dragonfly 拓扑。而…...

android基础-服务
同样使用intent来传递服务 oncreate是服务第一次启动调用,onStartCommand是服务每次启动的时候调用,也就是说服务只要启动后就不会调用oncreate方法了。可以在myservice中的任何位置调用stopself方法让服务停止下来。 服务生命周期 前台服务类似于通知会…...

手机号逆向查QQ号:3分钟快速上手完整指南,告别繁琐登录验证!
手机号逆向查QQ号:3分钟快速上手完整指南,告别繁琐登录验证! 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 你是否曾忘记自己哪个QQ号绑定了某个手机?或者需要批量验证手机号与QQ的关…...

面试题目总结
面试心态 越是置自己于低位,就越难获得面试官的青睐。面试官其实更喜欢逻辑清晰,不卑不亢,带点锋芒的应聘者。 不要以通过面试为目的,不然很难摆脱被凝视的状态。要以自我成长与提升为中心。要记住,每一次面试不是成功…...

ADI CodeFusion Studio:图形化系统规划与数据溯源重塑嵌入式开发
1. 项目概述:当嵌入式开发遇上“系统规划”与“数据信任”在智能边缘设备爆炸式增长的今天,嵌入式开发者正面临着一个前所未有的“甜蜜的烦恼”。一方面,芯片性能越来越强,多核异构架构成为主流,这让我们能在更小的空间…...
)
保姆级教程:在Ubuntu上为Ouster激光雷达配置PTP时间同步(含linuxptp/phc2sys避坑指南)
在Ubuntu上为Ouster激光雷达实现纳秒级PTP时间同步的完整指南 当自动驾驶车辆以60公里时速行驶时,1毫秒的时间误差会导致1.7厘米的位置偏差——这正是我们需要为激光雷达实现纳秒级时间同步的原因。本文将手把手带您完成Ouster激光雷达在Ubuntu系统上的PTP精确时间…...

生成式 AI 的成本暗礁:FinOps 如何照亮从试点到规模化的全链路
前言 全球大模型市场正呈现爆发式增长态势。2025年全球大语言模型市场规模约140亿美元,预计到2032年将接近6910亿美元,未来六年年复合增长率(CAGR)高达74.9%。2026年第一季度,全球LLM月活跃用户已突破38亿人ÿ…...

生物医学论文降AI工具免费推荐:2026年生物医学毕业论文知网AIGC超标免费4.8元一次过完整方案
生物医学论文降AI工具免费推荐:2026年生物医学毕业论文知网AIGC超标免费4.8元一次过完整方案 整理了一份生物医学论文降AI的完整选购指南,按性价比排序。 首推嘎嘎降AI(www.aigcleaner.com),4.8元,99.26%…...

免费扩展Windows虚拟显示器:5分钟打造高效多屏工作空间
免费扩展Windows虚拟显示器:5分钟打造高效多屏工作空间 【免费下载链接】virtual-display-rs A Windows virtual display driver to add multiple virtual monitors to your PC! For Win10. Works with VR, obs, streaming software, etc 项目地址: https://gitco…...

SharpCompress实战:一个方法搞定C#里ZIP压缩打包,附赠RAR/7Z解压和TAR.GZ创建教程
C#压缩解压全能手册:用SharpCompress玩转ZIP/RAR/7Z/TAR.GZ 在开发日志管理系统、文件上传模块或数据备份工具时,文件压缩解压功能就像空气一样不可或缺。但面对ZIP、RAR、7Z、TAR.GZ这些格式各异的压缩包,不少开发者都会陷入API选择的困境。…...

SteamAutoCrack终极指南:5步掌握游戏DRM自动移除技术
SteamAutoCrack终极指南:5步掌握游戏DRM自动移除技术 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack 你是否曾为Steam游戏的DRM保护而烦恼?每次运行游戏都需要启…...

万维网免费开放30年:除了浏览器,我们还能从CERN的决策中学到什么开源哲学?
万维网开源决策的启示:从技术公共性到开发者行动指南 1993年4月30日,欧洲核子研究中心(CERN)宣布将万维网技术置于公共领域,这一决定彻底改变了人类获取信息的方式。当我们回溯这个历史性时刻,会发现它远不…...