unetr_plus_plus(UNETR++、nnU-Net)系列数据处理理解汇总
unetr_plus_plus(UNETR++、nnU-Net)系列数据处理理解汇总,这是一个 3D 图像分割的任务系列集。
为什么说他们是一个系列集合呢?主要是因为:
- 论文的训练和评价数据集是一样的,都是来自于10全挑战赛;
- 数据的前处理工作基本是一致的,后续的文章都延续了nnU-Net的处理方式;
- 评价方式是一致的,具有可比性。
所以,如果你也在做3D 图像分割相关的任务,尤其是医学领域的任务,这部分就是必看的。最好是将自己的数据进行跑通测试对比下,应该会有新的感悟。
参考阅读论文:
- nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation
- nnFormer: Volumetric Medical Image Segmentation via a 3D Transformer
- UNETR++: Delving into Efficient and Accurate 3D Medical Image Segmentation
相关博客推荐阅读理解:
- 对于nnU-Net论文的理解,有CSDN会员的,可以去这里看:(一:2020.07.06)nnUNet论文主体解析(8.02更新认识)。没有的可以去这里看看:医学图像深度学习分割方法的自动设计(二)
- 数据处理部分解读:如何针对三维医学图像分割任务进行通用数据预处理:nnUNet中预处理流程总结及代码分析
- 哔哩哔哩也有一些介绍的视频,可以作为学习的理解参考
- 最最好的是nnU-Net这篇论文,介绍的很详细
本文后面的是参考unetr_plus_plus下面这个开源库的,不知道和原始的有啥区别,做个提醒。
- unetr_plus_plus的开源代码地址:github code of unetr_plus_plus
nnUNet 框架,三维医学图像分割的通用预处理可以分为四步,分别是:
- 数据格式的转换
- 裁剪crop
- 重采样resample
- 标准化normalization
后面的内容,是以unetr_plus_plus这个开源项目的数据处理部分展开的介绍,主要是自己对数据处理部分的一种记录,需要的可以往后看。
一、原始数据
输入的原始图像是img2667.nii.gz,以这个为参考,查看这个数据的变化。它的基本信息如下:
(512, 512, 55)
<class 'nibabel.nifti1.Nifti1Header'> object, endian='<'
sizeof_hdr : 348
data_type : b''
db_name : b''
extents : 0
session_error : 0
regular : b''
dim_info : 0
dim : [ 3 512 512 55 1 1 1 1]
intent_p1 : 0.0
intent_p2 : 0.0
intent_p3 : 0.0
intent_code : none
datatype : float64
bitpix : 64
slice_start : 0
pixdim : [1. 0.644531 0.644531 6. 1. 1. 1. 1. ]
vox_offset : 0.0
scl_slope : nan
scl_inter : nan
slice_end : 0
slice_code : unknown
xyzt_units : 0
cal_max : 0.0
cal_min : 0.0
slice_duration : 0.0
toffset : 0.0
glmax : 0
glmin : 0
descrip : b''
aux_file : b''
qform_code : unknown
sform_code : aligned
quatern_b : 0.0
quatern_c : 0.0
quatern_d : 1.0
qoffset_x : 167.4
qoffset_y : 165.0
qoffset_z : 78.85
srow_x : [ -0.644531 0. 0. 167.4 ]
srow_y : [ 0. -0.644531 0. 165. ]
srow_z : [ 0. 0. 6. 78.85]
intent_name : b''
magic : b'n+1' <class 'nibabel.nifti1.Nifti1Header'>
原始标注标签label0026.nii.gz的信息,最大值是类别数。比如有3个类别,那么:
- 像素值为0的,是背景
- 像素值为1的,是类别1
- 像素值为2的,是类别2
- 像素值为3的,是类别3
如果之前不是这么记录的,需要先转换到这种数据形式。下面是对应标签的信息,和图像信息一致就行。
(512, 512, 55)
<class 'nibabel.nifti1.Nifti1Header'> object, endian='<'
sizeof_hdr : 348
data_type : b''
db_name : b''
extents : 0
session_error : 0
regular : b''
dim_info : 0
dim : [ 3 512 512 55 1 1 1 1]
intent_p1 : 0.0
intent_p2 : 0.0
intent_p3 : 0.0
intent_code : none
datatype : float64
bitpix : 64
slice_start : 0
pixdim : [1. 0.644531 0.644531 6. 1. 1. 1. 1. ]
vox_offset : 0.0
scl_slope : nan
scl_inter : nan
slice_end : 0
slice_code : unknown
xyzt_units : 0
cal_max : 0.0
cal_min : 0.0
slice_duration : 0.0
toffset : 0.0
glmax : 0
glmin : 0
descrip : b''
aux_file : b''
qform_code : unknown
sform_code : aligned
quatern_b : 0.0
quatern_c : 0.0
quatern_d : 1.0
qoffset_x : 167.4
qoffset_y : 165.0
qoffset_z : 78.85
srow_x : [ -0.644531 0. 0. 167.4 ]
srow_y : [ 0. -0.644531 0. 165. ]
srow_z : [ 0. 0. 6. 78.85]
intent_name : b''
magic : b'n+1' <class 'nibabel.nifti1.Nifti1Header'>
二、原始数据拆分出各个模态存储
这个阶段是第一步的处理,它需要将原始输入数据转化成不同的模态进行保存。对于一般的情况下,都是只有一个模态,转换后的形式就是这样的,img2667_0000.nii.gz。
而对于Brats这个脑部数据集,就存在着多个模态的情况。尽管是不同的模态,但是他们都是同一时间节点,同时拍摄的。这样各个模态之间是一一对应的,也就是配准后的样子。如果有4个模态,那么就会有img2667_0000.nii.gz、img2667_0001.nii.gz、img2667_0002.nii.gz、img2667_0003.nii.gz。根据你自己的实际情况,得到不同的数据信息。
下面是img2667_0000.nii.gz的数据信息。
(512, 512, 55)
<class 'nibabel.nifti1.Nifti1Header'> object, endian='<'
sizeof_hdr : 348
data_type : b''
db_name : b''
extents : 0
session_error : 0
regular : b''
dim_info : 0
dim : [ 3 512 512 55 1 1 1 1]
intent_p1 : 0.0
intent_p2 : 0.0
intent_p3 : 0.0
intent_code : none
datatype : float64
bitpix : 64
slice_start : 0
pixdim : [1. 0.644531 0.644531 6. 1. 1. 1. 1. ]
vox_offset : 0.0
scl_slope : nan
scl_inter : nan
slice_end : 0
slice_code : unknown
xyzt_units : 0
cal_max : 0.0
cal_min : 0.0
slice_duration : 0.0
toffset : 0.0
glmax : 0
glmin : 0
descrip : b''
aux_file : b''
qform_code : unknown
sform_code : aligned
quatern_b : 0.0
quatern_c : 0.0
quatern_d : 1.0
qoffset_x : 167.4
qoffset_y : 165.0
qoffset_z : 78.85
srow_x : [ -0.644531 0. 0. 167.4 ]
srow_y : [ 0. -0.644531 0. 165. ]
srow_z : [ 0. 0. 6. 78.85]
intent_name : b''
magic : b'n+1' <class 'nibabel.nifti1.Nifti1Header'>
三、crop 操作后
crop是去除掉图像数据中,边缘为0的部分。比如CT 结节项目中,crop 掉肺区外的部分,只留下肺部的数据。这样剩下的图像就都是肺区的图像了,图像的数据量也就变小了。
如果,这部分你没有做非肺区的处理,那么经过crop后,图像部分的大小是不会发生改变的,还是和处理前的大小是一样的,这点不必惊讶。
3.1、npz 文件
DATASET_actTB/unetr_pp_raw/unetr_pp_cropped_data/Task002_Synapse 下img2667.npz文件记录的信息
读取代码,如下:
import numpy as np# 加载npz文件
data = np.load(npz_path)# 获取所有变量名称列表
variable_names = data.files
print("Variables in the file:", variable_names)# 选择特定的变量名称(如'array1')
selected_var = 'data'
if selected_var in variable_names:# 将选定的变量赋值给相应的变量array = data[selected_var]# 输出数组内容print(f"Array {selected_var}:")print(array.shape)
else:print(f"Variable '{selected_var}' does not exist.")
输出内容如下:
Variables in the file: ['data']
Array data:
(2, 55, 303, 426)
四维数组array(CXYZ)中:
- 最后一个维度存储的是分割标注信息,如array[-1,:,:,:]存储的是分割标注结果。
- 而第一个维度的前面存储不同模态的数据,如MRI数据中有
FLAIR、T1w、t1gd、 T2w等四种模态,array[0,:,:,:]表示FLAIR序列成像的强度数据,array[1,:,:,:]表示T1加权的强度数据,以此类推。 - 如果仅单模态,则四维数组第一维度长度仅为2,分别表示影像数据以及标注数据。四维数组array的后三个维度代表
x,y,z三个坐标表示的三维数据,对于原始影像数据,值大小代表强度 - 而对于标注结果,后三个维度的三维数据值分别为
0,1,2……表示不同的标注类别
3.2、pkl 文件
而pickle文件中存储该医学影像中其它的重要信息,是对numpy数组提供信息的补充。包含spacing,direction,origin等信息。
DATASET_actTB/unetr_pp_raw/unetr_pp_cropped_data/Task002_Synapse 下img2667.pkl文件记录的信息
OrderedDict([('original_size_of_raw_data', array([ 55, 512, 512], dtype=int64)),
('original_spacing', array([6. , 0.64453101, 0.64453101])),
('list_of_data_files', ['./unetr_plus_plus-main/DATASET_actTB/unetr_pp_raw/unetr_pp_raw_data/Task002_Synapse/imagesTr/img2667_0000.nii.gz']),
('seg_file', './unetr_plus_plusmain/DATASET_actTB/unetr_pp_raw/unetr_pp_raw_data/Task002_Synapse/labelsTr/label2667.nii.gz'),
('itk_origin', (-167.39999389648438, -165.0, 78.8499984741211)),
('itk_spacing', (0.6445310115814209, 0.6445310115814209, 6.0)),
('itk_direction', (1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0)),
('crop_bbox', [[0, 55], [94, 397], [54, 480]]),
('classes', array([-1., 0., 1.], dtype=float32)),
('size_after_cropping', (55, 303, 426)),
('use_nonzero_mask_for_norm', OrderedDict([(0, False)]))])
四、nnFormerData_plans_v2.1_2D_stage0
4.1、npz 文件
DATASET_actTB/unetr_pp_preprocessed/Task002_Synapse/nnFormerData_plans_v2.1_2D_stage0 img2667.npz同样数组大小。
Array data:
(2, 55, 273, 384)
4.2、pkl 文件
DATASET_actTB/unetr_pp_preprocessed/Task002_Synapse/nnFormerData_plans_v2.1_2D_stage0 img2667.pkl
OrderedDict([('original_size_of_raw_data', array([ 55, 512, 512], dtype=int64)),
('original_spacing', array([6. , 0.64453101, 0.64453101])),
('list_of_data_files', ['./unetr_plus_plus-main/DATASET_actTB/unetr_pp_raw/unetr_pp_raw_data/Task002_Synapse/imagesTr/img2667_0000.nii.gz']), ('seg_file', './unetr_plus_plusmain/DATASET_actTB/unetr_pp_raw/unetr_pp_raw_data/Task002_Synapse/labelsTr/label2667.nii.gz'),
('itk_origin', (-167.39999389648438, -165.0, 78.8499984741211)),
('itk_spacing', (0.6445310115814209, 0.6445310115814209, 6.0)),
('itk_direction', (1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0)),
('crop_bbox', [[0, 55], [94, 397], [54, 480]]),
('classes', array([-1., 0., 1.], dtype=float32)),
('size_after_cropping', (55, 303, 426)),
('use_nonzero_mask_for_norm', OrderedDict([(0, False)])),
('size_after_resampling', (55, 273, 384)),
('spacing_after_resampling', array([6. , 0.71484375, 0.71484375])),
('class_locations', {1: array([[ 40, 244, 61],[ 46, 224, 40],[ 48, 233, 70],...,[ 34, 253, 49],[ 41, 215, 21],[ 35, 241, 32]], dtype=int64), 2: []})])
五、unetr_pp_Data_plans_v2.1_stage0
5.1、npz 文件
DATASET_actTB/unetr_pp_preprocessed/Task002_Synapse/unetr_pp_Data_plans_v2.1_stage0 img2667.npz
Variables in the file: ['data']
Array data:
(2, 228, 189, 266)
六、unetr_pp_Data_plans_v2.1_stage1
6.1、npz 文件
DATASET_actTB/unetr_pp_preprocessed/Task002_Synapse/unetr_pp_Data_plans_v2.1_stage1 img2667.npz
输出内容如下(经历了一次spacing调整):
Variables in the file: ['data']
Array data:
(2, 330, 273, 384)
6.2、pkl 文件
DATASET_actTB/unetr_pp_preprocessed/Task002_Synapse/unetr_pp_Data_plans_v2.1_stage1 img2667.pkl
OrderedDict([('original_size_of_raw_data', array([ 55, 512, 512], dtype=int64)),
('original_spacing', array([6. , 0.64453101, 0.64453101])),
('list_of_data_files', ['/home/qlj/projects/unetr_plus_plus-main/DATASET_actTB/unetr_pp_raw/unetr_pp_raw_data/Task002_Synapse/imagesTr/img2667_0000.nii.gz']), ('seg_file', '/home/qlj/projects/unetr_plus_plus-main/DATASET_actTB/unetr_pp_raw/unetr_pp_raw_data/Task002_Synapse/labelsTr/label2667.nii.gz'),
('itk_origin', (-167.39999389648438, -165.0, 78.8499984741211)),
('itk_spacing', (0.6445310115814209, 0.6445310115814209, 6.0)),
('itk_direction', (1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0)),
('crop_bbox', [[0, 55], [94, 397], [54, 480]]),
('classes', array([-1., 0., 1.], dtype=float32)),
('size_after_cropping', (55, 303, 426)),
('use_nonzero_mask_for_norm', OrderedDict([(0, False)])),
('size_after_resampling', (330, 273, 384)),
('spacing_after_resampling', array([1. , 0.71484375, 0.71484375])),
('class_locations', {1: array([[149, 238, 54],[259, 230, 43],[246, 230, 66],...,[141, 255, 86],[294, 213, 20],[145, 250, 72]], dtype=int64), 2: []})])
各个key对应的含义:
original_size_of_raw_data原始图像大小,original_spacing原始图像的spacing,list_of_data_files原始图像各个模态的文件路径list,seg_file对应label的文件路径list,itk_origin, ‘itk_spacing’, ‘itk_direction’,crop_bbox去除原始图像四周为0的部分,z\y\x 对应的边界坐标,classes本例子包含的类别,-1是crop box去除的像素点填充,类别1、2就是标注类别,其他是0size_after_cropping裁剪后的size,use_nonzero_mask_for_norm是否使用非0的mask部分去norm 默认False,size_after_resampling使用resample操作后的size,spacing_after_resampling使用resample操作后的spacing,class_locations对应类别的坐标dict
七、preprocessed 文件
7.1、splits_final.pkl 文件
记录了k fold的中,每一个fold划分的train和val的数据名称,如下:
[OrderedDict([('train', array(['img0001', 'img0002', 'img0005', 'img0007', 'img0008', 'img0009','img0010', 'img0011', 'img0012', 'img0013', 'img0014', 'img0015','img0016', 'img0017', 'img0018', 'img0019', 'img0021', 'img0023','img0024', 'img0025', 'img0027', 'img0028', 'img0030', 'img0031','img0032', 'img0034', 'img0035', 'img0036', 'img0037', 'img0038','img0039', 'img0040'
], dtype = '<U7')), ('val', array(['img0003', 'img0004', 'img0006', 'img0020', 'img0022', 'img0026','img0029', 'img0033'
], dtype = '<U7'))]), OrderedDict([('train', array(['img0002', 'img0003', 'img0004', 'img0006', 'img0007', 'img0008','img0010', 'img0011', 'img0012', 'img0014', 'img0015', 'img0017','img0018', 'img0019', 'img0020', 'img0021', 'img0022', 'img0023','img0024', 'img0025', 'img0026', 'img0027', 'img0028', 'img0029','img0030', 'img0032', 'img0033', 'img0035', 'img0037', 'img0038','img0039', 'img0040'
], dtype = '<U7')), ('val', array(['img0001', 'img0005', 'img0009', 'img0013', 'img0016', 'img0031','img0034', 'img0036'
], dtype = '<U7'))]), OrderedDict([('train', array(['img0001', 'img0002', 'img0003', 'img0004', 'img0005', 'img0006','img0009', 'img0010', 'img0012', 'img0013', 'img0015', 'img0016','img0017', 'img0019', 'img0020', 'img0022', 'img0023', 'img0024','img0026', 'img0028', 'img0029', 'img0030', 'img0031', 'img0032','img0033', 'img0034', 'img0035', 'img0036', 'img0037', 'img0038','img0039', 'img0040'
], dtype = '<U7')), ('val', array(['img0007', 'img0008', 'img0011', 'img0014', 'img0018', 'img0021','img0025', 'img0027'
], dtype = '<U7'))]), OrderedDict([('train', array(['img0001', 'img0002', 'img0003', 'img0004', 'img0005', 'img0006','img0007', 'img0008', 'img0009', 'img0011', 'img0013', 'img0014','img0015', 'img0016', 'img0018', 'img0020', 'img0021', 'img0022','img0025', 'img0026', 'img0027', 'img0029', 'img0030', 'img0031','img0033', 'img0034', 'img0035', 'img0036', 'img0037', 'img0038','img0039', 'img0040'
], dtype = '<U7')), ('val', array(['img0010', 'img0012', 'img0017', 'img0019', 'img0023', 'img0024','img0028', 'img0032'
], dtype = '<U7'))]), OrderedDict([('train', array(['img0001', 'img0003', 'img0004', 'img0005', 'img0006', 'img0007','img0008', 'img0009', 'img0010', 'img0011', 'img0012', 'img0013','img0014', 'img0016', 'img0017', 'img0018', 'img0019', 'img0020','img0021', 'img0022', 'img0023', 'img0024', 'img0025', 'img0026','img0027', 'img0028', 'img0029', 'img0031', 'img0032', 'img0033','img0034', 'img0036'
], dtype = '<U7')), ('val', array(['img0002', 'img0015', 'img0030', 'img0035', 'img0037', 'img0038','img0039', 'img0040'
], dtype = '<U7'))])]
7.2、nnFormerPlansv2.1_plans_2D.pkl
pkl文件内存储的key的意义,如下:
num_stages stage的数量,num_modalities,modalities,normalization_schemes,dataset_properties记录了所有数据的属性信息,包括size\spacing\classes\modalities\intensityproperties\size_reductions,list_of_npz_files所有croped data 的npz图像路径,original_spacings原始的spacing,original_sizes原始的size,preprocessed_data_folder preprocessed data文件夹路径,num_classes分类数量,all_classes各个类别在mask中的数字,base_num_features,use_mask_for_norm,keep_only_largest_region,min_region_size_per_class,min_size_per_class,transpose_forward,transpose_backward,data_identifier:nnFormerData_plans_v2.1_2D,plans_per_stage,preprocessor_name
plans_per_stage 内记录的信息如下:
{0: {'batch_size': 8,'num_pool_per_axis': [5, 4, 5],'patch_size': array([128, 112, 160], dtype = int64),'median_patient_size_in_voxels': array([190, 187, 258], dtype = int64),'current_spacing': array([1.44507647, 1.03300388, 1.03300388]),'original_spacing': array([1., 0.71484375, 0.71484375]),'do_dummy_2D_data_aug': False,'pool_op_kernel_sizes': [[2, 2, 2],[2, 2, 2],[2, 2, 2],[2, 2, 2],[2, 1, 2]],'conv_kernel_sizes': [[3, 3, 3],[3, 3, 3],[3, 3, 3],[3, 3, 3],[3, 3, 3],[3, 3, 3]]},1: {'batch_size': 16,'num_pool_per_axis': [5, 4, 5],'patch_size': array([64, 128, 128], dtype = int64),'median_patient_size_in_voxels': array([275, 270, 373], dtype = int64),'current_spacing': array([1., 0.71484375, 0.71484375]),'original_spacing': array([1., 0.71484375, 0.71484375]),'do_dummy_2D_data_aug': False,'pool_op_kernel_sizes': [[2, 2, 2],[2, 2, 2],[2, 2, 2]],'conv_kernel_sizes': [[3, 3, 3],[3, 3, 3],[3, 3, 3],[3, 3, 3],[3, 3, 3],[3, 3, 3]]}
}
7.3、unetr_pp_Plansv2.1_plans_3D.pkl
记录内容,和7.2类似,我理解都是为了接下来的训练,做个准备配置
‘data_identifier’: ‘unetr_pp_Data_plans_v2.1’,
在训练阶段:
loading dataset of folder: /home/qlj/projects/unetr_plus_plus-main/DATASET_actTB_HU/unetr_pp_preprocessed/Task002_Synapse/unetr_pp_Data_plans_v2.1_stage1
7.3、dataset_properties.pkl
dict_keys([‘all_sizes’, ‘all_spacings’, ‘all_classes’, ‘modalities’, ‘intensityproperties’, ‘size_reductions’])
nnU-Net 这篇论文,对数据前处理和训练超参数的选择部分做了详细的介绍,对于后面的训练有很大的启发。作者认为:如果相应的管道pipeline设计得当,基本的U-Net仍然很难被击败。
意在指出:pipeline 设计的重要性。为此,设计了nnU-Net:一个深度学习框架,浓缩了当前的领域知识,并自主地做出关键决策,将基本架构转移到不同的数据集和分割任务。能够自动适应任意数据集,并基于两个关键贡献,实现开箱即用的分割:
- 我们用数据指纹(data fingerprint,代表数据集的关键属性)和管道指纹(pipeline fingerprint,代表分割算法的关键设计选择)来表述管道优化问题。
- 我们通过将领域知识(domain knowledge )压缩成一组启发式规则来明确它们之间的关系,这些规则可以在考虑相关硬件约束的情况下从相应的数据指纹稳健地生成高质量的管道指纹。
Automated Design, Without manual tuning。
nnU-Net是如何自动适应任何新的数据集呢?
data fingerprint,数据集指纹定义为包含关键属性的标准化数据集表示,如:
- 图像大小 image sizes
- 体素间距信息voxel spacing information
- 类别比率class ratios
pipeline fingerprint,管道指纹定义为方法设计期间所做出的整体选择,在nnU-Net中分为3个部分:
- blueprint parameters,例如:
- loss function
- optimizer
- training schedule
- data augmentation
- inferred parameters,推断参数,对新数据集进行必要的调整,例如:
- patch size
- batch size
- image preprocessing(resampling, normalization)
- architecture config
- empirrical parameters 经验主义参数,是通过对训练案例的交叉验证,自动识别的。包括后处理和整体策略。
数据指纹data fingerprint和推断参数inferred parameters之间的链接是通过执行一组启发式规则建立的,而不需要在应用于未见过的数据集时进行昂贵的重新优化。其中很多的设计选择是相互依赖的,例如(one instance):
- target image spacing 影响到 image size
- 进而又影响到 patch size
- 进而影响到 batch size
相关文章:
系列数据处理理解汇总)
unetr_plus_plus(UNETR++、nnU-Net)系列数据处理理解汇总
unetr_plus_plus(UNETR、nnU-Net)系列数据处理理解汇总,这是一个 3D 图像分割的任务系列集。 为什么说他们是一个系列集合呢?主要是因为: 论文的训练和评价数据集是一样的,都是来自于10全挑战赛ÿ…...

稻盛和夫《活法》读后感
最近几天又重读了一边稻盛和夫的《活法》,里面的观点让我感触颇多,现分享给诸君。 稻盛和夫毕业后,适逢经济萧条,没有好机会进入大公司深造,只能在一名教授的推荐下进入了一家做陶瓷绝缘体的公司,虽然公司…...

Smurf 攻击是不是真的那么难以防护
Smurf攻击是一种网络攻击方式,属于分布式拒绝服务(DDoS)攻击的变种。以 1990 年代流行的名为 Smurf 的漏洞利用工具命名。该工具创建的 ICMP 数据包很小,但可以击落大目标。 它利用ICMP协议中的回声请求(ping&#x…...

ASP.NET之图像控件
在ASP.NET中,用于显示图像的控件主要是Image控件,Image控件属于ASP.NET Web Forms的一部分,它允许你在Web页面上显示图像。以下是如何在ASP.NET Web Forms中使用 1. 添加Image控件到页面 在ASP.NET Web Forms页面上,你可以通过设…...
含真题解析)
二级Java第五套真题(乱序版)含真题解析
一. 单选题(共39题,39分) 1. (单选题, 1分) 阅读下列代码 public class Test implements Runnable { public void run (Thread t) { System.out.println("Running."); } public static void main (String[ ] args) { T…...
 使用示例)
【C++】GNU Debugger (GDB) 使用示例
文章目录 GDB 使用示例GDB的常用命令示例 GDB 使用示例 GDB的常用命令 GDB(GNU Debugger)是一种Unix下的程序调试工具,用于调试C、C等编程语言编写的程序。以下是一些GDB的常用命令: 启动和退出: run 或 r…...
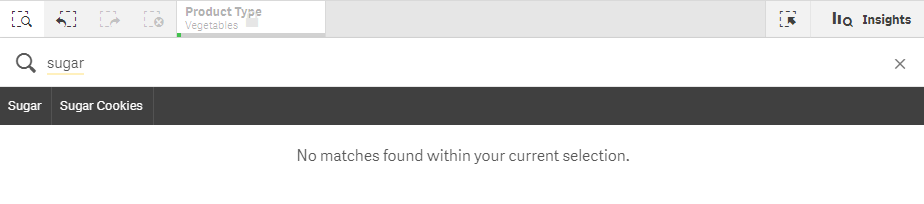
Qlik Sense :使用智能搜索Smart Search
智能搜索 智能搜索是 Qlik Sense 中的全局搜索工具,可让您从应用程序中的任何工作表搜索应用程序中的整个数据集。可通过点击 从工作表中的选择项栏使用智能搜索。 通过智能搜索字段,您可以从任何工作表搜索您的应用程序中的完整数据集。 信息注释 智…...

React 学习-1
安装--使用npm 元素渲染 React只定义一个根节点,由 React DOM 来管理。通过ReactDOM.render()方法将元素渲染到根DOM节点上。 React 元素都是不可变的。当元素被创建之后,你是无法改变其内容或属性的。目前更新界面的唯一办法是创建一个新的元素…...
Libcity 笔记:自定义模型
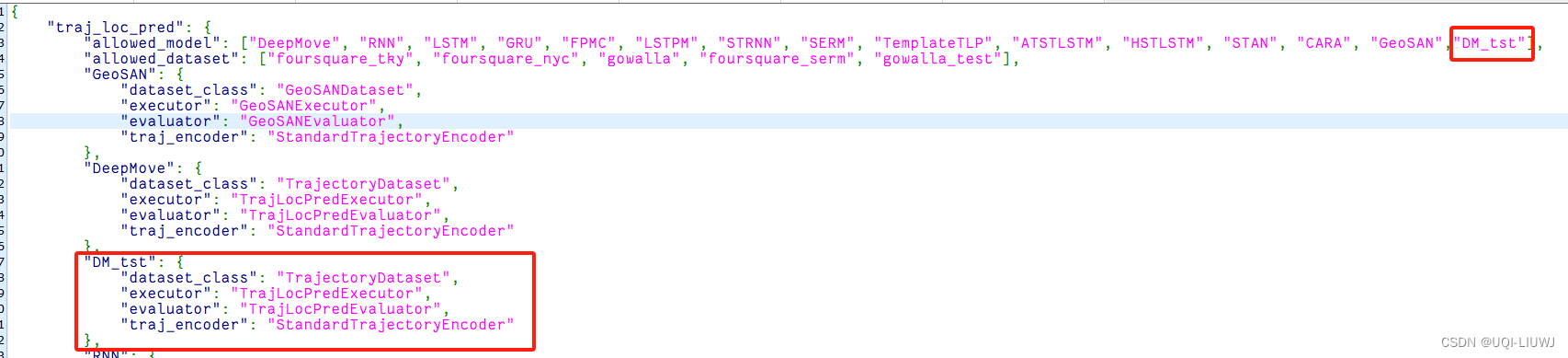
在/libcity/model/trajectory_loc_prediction/,我们复制一份Deepmove.py,得到DM_tst.py,我们不改变其中的机制,只动class name 然后修改相同目录下的__init__.py: 修改task_config文件: 在config/model/tra…...

易图讯科技三维电子沙盘系统
深圳易图讯科技有限公司(www.3dgis.top)创立于2013年,专注二三维地理信息、三维电子沙盘、电子地图、虚拟现实、大数据、物联网和人工智能技术研发,获得20多项软件著作权和软件检测报告,成功交付并实施了1000多个项目&…...
)
数据结构与算法学习笔记之线性表四---单链表的表示和实现(C++)
目录 前言 一、顺序表的优缺点 二、单链表的表示和实现 1.初始化 2.清空表 3.销毁 4.表长 5.表空 6.获取表中的元素 7.下标 8.直接前驱 9.直接后继 10.插入 11.删除 12.遍历链表 13.测试代码 前言 这篇博客主要介绍单链表的表示和实现。 一、顺序表的优缺点 线…...

go语言切片slice使用细节和注意事项整理
go语言中切片slice的使用是最为频繁的,效率也是最高的, 今天就给大家说说我们在使用过程中会忽略的一些细节。 先普及一下slice的核心基础知识, go语言中的切片是引用类型, 其底层数据的存储实际上是存储在一个数组 上(…...

C语言 | Leetcode C语言题解之第85题最大矩形
题目: 题解: int maximalRectangle(char** matrix, int matrixSize, int* matrixColSize) {int m matrixSize;if (m 0) {return 0;}int n matrixColSize[0];int left[m][n];memset(left, 0, sizeof(left));for (int i 0; i < m; i) {for (int j …...

2024-05-13四月初六周一
2024-05-13四月初六周一 06:30-08:30 coding 动态规划算法: 08:30-12:30 深兰Ai第五期 Part1:课时269:00:00:00 12:30-13:00 午饭烧水: 13:30-19:00 深兰Ai第五期: 20:00-23:00 coding 线性回归:...
Android性能:高版本Android关闭硬件加速GPU渲染滑动卡顿掉帧
Android性能:高版本Android关闭硬件加速GPU渲染滑动卡顿掉帧 如果在Androidmanifest.xml配置: <application android:hardwareAccelerated"false" > 或者某个特点View使用代码: myView.setLayerType(View.LAYER_TYPE_SOFT…...

对于FileUpload控件的一些bug
我写的程序,问题出现的也很神奇,就是我在上传已经存在在我指定目录下的就可以成功,如果不存在,上传仍是可以成功的,但是就会不显示,但是你重启服务器的时候又会再次显示。这种问题出现的原因我们就需要了解…...

哲学家就餐问题
哲学家就餐问题 问题信号量实现发生死锁版限制人数版规定取筷顺序 条件变量实现 问题 在一个圆桌上坐着五位哲学家,每个哲学家面前有一个碗装有米饭的碗和一个筷子。哲学家的生活包括思考和进餐两个活动。当一个哲学家思考时,他不需要任何资源。当他饿了…...
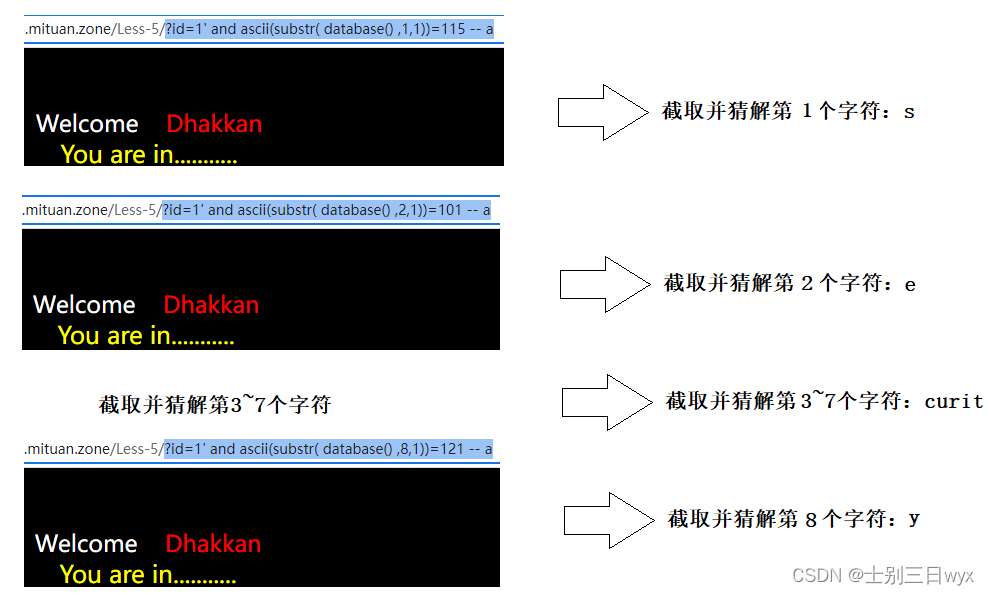
Web安全:SQL注入之布尔盲注原理+步骤+实战操作
「作者简介」:2022年北京冬奥会网络安全中国代表队,CSDN Top100,就职奇安信多年,以实战工作为基础对安全知识体系进行总结与归纳,著作适用于快速入门的 《网络安全自学教程》,内容涵盖系统安全、信息收集等…...

电商秒杀系统-案例04-redis下的session控制
前言: 在现代的Web应用中,安全和高效的用户身份验证机制是至关重要的。本文将深入探讨基于令牌的用户登录会话机制,特别是在使用Redis进行会话管理的情景。通过这一案例实战,我们将了解令牌如何在用户身份验证过程中发挥核心作用&…...

贪吃蛇(c实现)
目录 游戏说明: 第一个是又是封面,第二个为提示信息,第三个是游戏运行界面 游戏效果展示: 游戏代码展示: snack.c test.c snack.h 控制台程序的准备: 控制台程序名字修改: 参考:…...

精准定位无版权音乐,快速获取商用授权源,Perplexity音乐搜索避坑全手册,深度拆解7类常见误判场景
更多请点击: https://codechina.net 第一章:Perplexity音乐资源搜索的核心价值与定位 Perplexity 音乐资源搜索并非传统意义上的音频播放器或流媒体平台,而是一个面向开发者、音乐学者与内容创作者的语义化音乐元数据发现引擎。其核心价值在…...

保姆级教程:从Solidworks模型到Matlab SimMechanics仿真,搞定你的六轴机械臂动力学分析
六轴机械臂动力学仿真全流程:从Solidworks到Matlab SimMechanics实战指南 在工业自动化与机器人研发领域,机械臂的动力学仿真已成为验证设计合理性的关键环节。本文将手把手带你完成从Solidworks三维建模到Matlab SimMechanics动力学仿真的完整工作流&am…...

S32K3开发板三色LED点灯实战:从引脚配置到代码烧录的保姆级避坑指南
S32K3开发板三色LED点灯实战:从引脚配置到代码烧录的保姆级避坑指南 当一块崭新的S32K3开发板摆在面前,闪烁的LED往往是开发者与之对话的第一个"Hello World"。本文将带你用最直观的方式——控制RGB三色灯,快速建立对NXP这款车规级…...

AI 落地精准测试平台:从排障定位、回归决策到智能分析实战课系列导航
本目录沉淀了一套围绕“采集接入、报告分析、治理沉淀、智能运维”展开的教学文章系列。 共 120 篇,适合拆分发布,也适合按专题连续阅读。 AI 落地精准测试平台:从排障定位、回归决策到智能分析实战课 这套系列适合谁 测试工程师ÿ…...

【生产力跃升】Claude Code v2.1.143:允许禁用工作树隔离,插件依赖链强制执行与后台 Agent 补强
前言作为一款工业级的 AI 编程助手,Claude Code 的高频迭代一直在解决复杂工程中的痛点。在最新的 v2.1.143 版本中,开发团队带来了一项重磅底层配置:允许关闭后台 Agent 的 Git 工作树(Worktree)隔离。此外࿰…...

可穿戴声音装置DIY:用Adafruit Audio FX板制作互动节日毛衣
1. 项目概述:一件会“说话”的节日毛衣又到年底节日扎堆的时候了,除了琢磨穿什么衣服,你有没有想过让衣服本身成为节日气氛的一部分?我说的不是简单的亮片或印花,而是让衣服能发出声音——比如一按袖子就响起清脆的铃铛…...

基于Arduino与VS1053的宠物智能服装DIY:嵌入式系统集成实践
1. 项目概述与核心思路给宠物做一件会发光、会发声的智能服装,听起来像是科幻电影里的情节,但用今天触手可及的硬件和开源工具,这完全是一个可以亲手实现的周末项目。这个项目的核心,是将一个微小的“智能大脑”和一套声光系统&am…...

【亲测免费】 普冉PY32F002A移植FreeRTOS资源文件
普冉PY32F002A移植FreeRTOS资源文件 【下载地址】普冉PY32F002A移植FreeRTOS资源文件 本资源文件提供了将FreeRTOS V9.0移植到普冉M0芯片PY32F002A的完整示例。开发环境基于KEIL,并使用了LL库进行移植。该示例展示了如何在PY32F002A芯片上运行四个任务,并…...

创业团队如何借助Taotoken的多模型与透明计费快速验证AI产品原型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何借助Taotoken的多模型与透明计费快速验证AI产品原型 对于资源有限的创业团队而言,在产品开发初期快速验证…...

3分钟解锁音乐自由:ncmdump让网易云音乐NCM文件随处播放
3分钟解锁音乐自由:ncmdump让网易云音乐NCM文件随处播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的歌曲只能在特定客户端播放而烦恼吗?当您精心收藏的音乐被NCM加密格式束缚&…...