IB 公式解析
IB损失
自我感悟
根据对决策边界的影响程度来分配权重。影响程度越大,分配到的权重越小;影响程度越小,分配到的权重越大。
最后其实就是平衡因子和交叉熵损失的输出的乘积
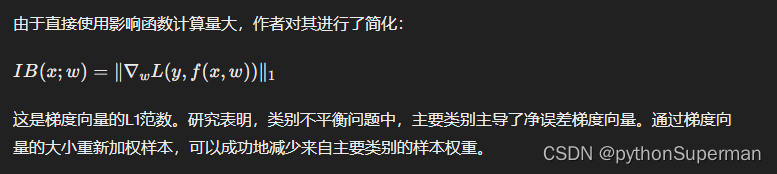
公式
3.2. Influence Function
影响函数允许我们在移除样本时估计模型参数的变化,而无需实际移除数据并重新训练模型。

3.3 影响平衡加权因子
3.4 影响平衡损失


3.5 类内重加权

m代表一个批次(batch)的大小,这意味着公式对一个批次中的所有样本进行计算,然后去平均值。

代码
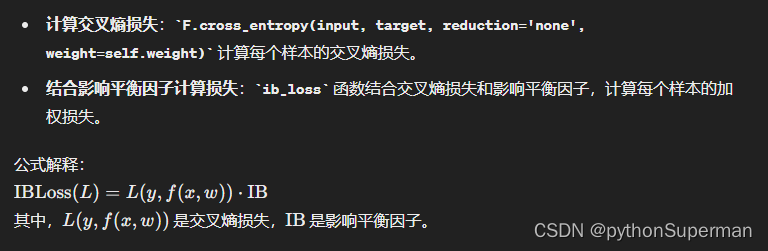
criterion_ib = IBLoss(weight=per_cls_weights, alpha=1000).cuda()def ib_loss(input_values, ib):"""Computes the focal loss"""loss = input_values * ibreturn loss.mean()class IBLoss(nn.Module):def __init__(self, weight=None, alpha=10000.):super(IBLoss, self).__init__()assert alpha > 0self.alpha = alphaself.epsilon = 0.001self.weight = weightdef forward(self, input, target, features):grads = torch.sum(torch.abs(F.softmax(input, dim=1) - F.one_hot(target, num_classes)),1) # N * 1ib = grads * features.reshape(-1)ib = self.alpha / (ib + self.epsilon)return ib_loss(F.cross_entropy(input, target, reduction='none', weight=self.weight), ib)
1.计算梯度 grads:
grads = torch.sum(torch.abs(F.softmax(input, dim=1) - F.one_hot(target, num_classes)), 1) # N * 1
- 计算 softmax 概率分布:
F.softmax(input, dim=1)将模型的输出转换为概率分布。 - 计算 one-hot 编码:
F.one_hot(target, num_classes)将目标标签转换为 one-hot 编码。 - 计算绝对差值:通过计算 softmax 输出与 one-hot 编码之间的绝对差值,得到每个样本的梯度,表示样本对模型的损失贡献。

2. 计算影响平衡因子(IB Factor)
ib = grads * features.reshape(-1)
ib = self.alpha / (ib + self.epsilon)

影响平衡因子(IB Factor)确实与梯度成反比。梯度越大,IB因子越小,分配给该样本的权重越小;梯度越小,IB因子越大,分配给该样本的权重越大。这一机制确保了模型在处理不平衡数据时,能够更有效地减小对多数类样本的过拟合,提升对少数类样本的泛化能力。
3. 计算最终损失
return ib_loss(F.cross_entropy(input, target, reduction='none', weight=self.weight), ib)
再理解
F.cross_entropy(input, target, reduction='none', weight=self.weight)
PyTorch 的 torch.nn.functional.cross_entropy 函数计算交叉熵损失。让我们详细解释这个函数的每个参数以及它们在这行代码中发生的事情。
参数解释
-
input:- 这是模型的输出,通常是对数几率(logits),即在应用 softmax 之前的原始得分。其形状通常为
(batch_size, num_classes)。
- 这是模型的输出,通常是对数几率(logits),即在应用 softmax 之前的原始得分。其形状通常为
-
target:- 这是真实的目标标签,通常是一个包含类别索引的张量,其形状通常为
(batch_size,)。每个元素的值是该样本的真实类别的索引。
- 这是真实的目标标签,通常是一个包含类别索引的张量,其形状通常为
-
reduction='none':- 这个参数指定了如何对计算出的每个样本的损失进行聚合。
'none'表示不进行聚合,返回每个样本的损失值。- 其他选项包括
'mean'和'sum',分别表示对损失取平均值和求和。
-
weight=self.weight:- 这是一个权重张量,用于对每个类别的损失进行加权。其形状为
(num_classes,)。 self.weight由之前定义的类别权重per_cls_weights设置。这些权重用于处理类别不平衡问题。
- 这是一个权重张量,用于对每个类别的损失进行加权。其形状为
发生了什么
在这行代码中,F.cross_entropy 函数计算交叉熵损失的步骤如下:
-
计算 softmax:

- 首先,对
input应用 softmax 函数,将对数几率转换为概率分布。
- 首先,对
-
取对数:
- 计算 softmax 概率的对数。

-
计算负对数似然:

这里,
x_y是input中对应于真实标签y的元素。
- 根据真实标签
target,计算负对数似然损失。
-
应用类别权重:
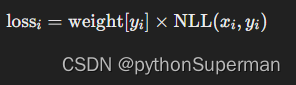
- 如果提供了
weight参数,则对每个类别的损失应用对应的权重。对于每个样本i,如果其真实标签为y_i,则对应的损失为:
-
返回每个样本的损失:
- 由于
reduction='none',不进行聚合,返回每个样本的损失值。结果是一个与target大小相同的张量,即(batch_size,)。
代码的作用
F.cross_entropy(input, target, reduction='none', weight=self.weight)- 计算
input(模型输出)与target(真实标签)之间的交叉熵损失。 - 每个样本的损失根据类别权重
self.weight进行加权,以处理类别不平衡问题。 - 返回每个样本的损失值,而不是将它们聚合成一个标量损失。
示例
假设有一个批次大小为 3,类别数为 4 的小批次数据:
import torch
import torch.nn.functional as F# 模型输出 (logits)
input = torch.tensor([[2.0, 1.0, 0.1, -1.0],[1.0, 3.0, 0.1, -0.5],[-1.0, -0.5, 2.0, 0.5]])# 真实标签
target = torch.tensor([0, 1, 2])# 类别权重
weight = torch.tensor([1.0, 2.0, 3.0, 4.0])# 计算加权交叉熵损失
loss = F.cross_entropy(input, target, reduction='none', weight=weight)
print(loss)
在这个例子中:
input是一个大小为(3, 4)的张量,表示批次大小为 3,每个样本有 4 个类别的对数几率。target是一个大小为(3,)的张量,表示每个样本的真实类别索引。weight是一个大小为(4,)的张量,表示每个类别的权重。
F.cross_entropy 函数将计算每个样本的交叉熵损失,并应用类别权重 weight。由于 reduction='none',返回每个样本的损失值。
总结
- 计算每个样本的交叉熵损失。
- 应用类别权重,处理类别不平衡问题。
- 返回每个样本的损失值,而不是将它们聚合成一个标量损失。
将论文中的公式与代码对应起来
论文中的公式:

对应代码
首先,我们来看影响平衡损失 IBLoss 的代码实现:
class IBLoss(nn.Module):def __init__(self, weight=None, alpha=10000.):super(IBLoss, self).__init__()assert alpha > 0self.alpha = alphaself.epsilon = 0.001self.weight = weightdef forward(self, input, target, features):grads = torch.sum(torch.abs(F.softmax(input, dim=1) - F.one_hot(target, num_classes)), 1) # N * 1ib = grads * features.reshape(-1)ib = self.alpha / (ib + self.epsilon)return ib_loss(F.cross_entropy(input, target, reduction='none', weight=self.weight), ib)
对应关系
-
批次大小 m
在代码中,批次大小由
train_loader或test_loader的批次大小参数决定。 -
数据集 𝐷𝑚
代码中的
train_loader或test_loader提供了批次数据。 -
类别权重因子 𝜆𝑘
在代码中,通过
per_cls_weights来实现:
per_cls_weights = 1.0 / np.array(cls_num_list)
per_cls_weights = per_cls_weights / np.sum(per_cls_weights) * len(cls_num_list)
per_cls_weights = torch.FloatTensor(per_cls_weights).cuda()
4.基本损失函数 𝐿(𝑦,𝑓(𝑥,𝑤))
代码中使用 torch.nn.CrossEntropyLoss 计算交叉熵损失:
base_loss = F.cross_entropy(input, target, reduction='none', weight=self.weight)
5.模型输出 𝑓(𝑥,𝑤)f(x,w)
在代码中,模型的输出为 input:
output, features = model(images)
6.模型输出与真实标签的 L1 范数 ∥𝑓(𝑥,𝑤)−𝑦∥1
在代码中,通过以下方式计算:
grads = torch.sum(torch.abs(F.softmax(input, dim=1) - F.one_hot(target, num_classes)), 1) # N * 1
7.隐藏层特征向量 ℎ 和其 L1 范数 ∥ℎ∥1**
在代码中,通过以下方式计算隐藏层特征向量的 L1 范数:
features = torch.sum(torch.abs(feats), 1).reshape(-1, 1)
8.最终影响平衡因子 IB
在代码中,通过以下方式计算:
ib = grads * features.reshape(-1)
ib = self.alpha / (ib + self.epsilon)
9.最终影响平衡损失 𝐿IB(𝑤)
通过自定义的 ib_loss 函数计算:
return ib_loss(F.cross_entropy(input, target, reduction='none', weight=self.weight), ib)

为什么类别权重因子要这样实现
per_cls_weights = 1.0 / np.array(cls_num_list)
per_cls_weights = per_cls_weights / np.sum(per_cls_weights) * len(cls_num_list)
per_cls_weights = torch.FloatTensor(per_cls_weights).cuda()类别权重因子的实现旨在通过加权样本来处理类别不平衡问题。以下是详细解释为什么要这样实现 per_cls_weights 以及每一步的作用:
代码实现
per_cls_weights = 1.0 / np.array(cls_num_list)
per_cls_weights = per_cls_weights / np.sum(per_cls_weights) * len(cls_num_list)
per_cls_weights = torch.FloatTensor(per_cls_weights).cuda()
每一步的解释
计算每个类别的逆频率:
per_cls_weights = 1.0 / np.array(cls_num_list)
cls_num_list是每个类别的样本数量列表。例如,如果有三个类别,且每个类别的样本数量为[100, 200, 50],则cls_num_list = [100, 200, 50]。- 通过取倒数
1.0 / np.array(cls_num_list),我们得到了每个类别的逆频率。例如,结果将是[0.01, 0.005, 0.02]。 - 逆频率反映了类别数量的稀少程度,样本数量少的类别(少数类)将得到更高的权重。
归一化权重:
per_cls_weights = per_cls_weights / np.sum(per_cls_weights) * len(cls_num_list)
- 首先,计算权重的总和
np.sum(per_cls_weights)。根据前面的例子,总和为0.01 + 0.005 + 0.02 = 0.035。 - 然后,将每个类别的权重除以总和,使得所有权重的和为 1。这是标准化步骤,使得权重变为
[0.01/0.035, 0.005/0.035, 0.02/0.035],即[0.2857, 0.1429, 0.5714]。 - 接下来,将这些标准化权重乘以类别的数量
len(cls_num_list)。在这个例子中,类别数量是 3。因此,最终的权重变为[0.2857*3, 0.1429*3, 0.5714*3],即[0.8571, 0.4286, 1.7143]。
这一步的作用是确保每个类别的权重和类别数量成正比,同时保持权重的总和为类别数量。
转换为 PyTorch 张量:
per_cls_weights = torch.FloatTensor(per_cls_weights).cuda()
- 将 NumPy 数组转换为 PyTorch 张量,以便在 PyTorch 中使用这些权重。
- 将权重张量移动到 GPU(如果可用),以加速计算。
归一化步骤的原因
归一化权重的目的是确保类别权重的相对比例合理,并且所有权重的总和与类别数量一致。这有助于避免某些类别被赋予过高或过低的权重,从而确保训练过程中的稳定性和效果。
处理类别不平衡的原因
类别不平衡问题是指在数据集中,不同类别的样本数量差异很大。在这种情况下,传统的损失函数往往会被多数类主导,导致模型在少数类上的性能较差。通过加权样本,特别是对少数类样本赋予更高的权重,可以平衡各类样本对损失的贡献,从而改善模型在少数类上的表现。
总结
- 逆频率权重:通过取样本数量的倒数,使得样本数量少的类别得到更高的权重。
- 归一化:将权重标准化,并确保权重的总和与类别数量一致,保持权重比例的合理性。
- 转换为张量:将权重转换为 PyTorch 张量,以便在训练过程中使用。
这种权重计算方法确保了在处理类别不平衡问题时,少数类样本对损失函数的贡献增加,从而提高模型对少数类的识别能力。
Focal损失
def focal_loss(input_values, gamma):"""Computes the focal loss"""p = torch.exp(-input_values)#loss = (1 - p) ** gamma * input_valuesloss = (1- p) ** gamma * input_values * 10return loss.mean()class FocalLoss(nn.Module):def __init__(self, weight=None, gamma=0.):super(FocalLoss, self).__init__()assert gamma >= 0self.gamma = gammaself.weight = weightdef forward(self, input, target):return focal_loss(F.cross_entropy(input, target, reduction='none', weight=self.weight), self.gamma)
交叉熵损失

cross_entropy 函数的内部计算步骤

FocalLoss 中的 focal_loss 函数
在 FocalLoss 中,我们有如下代码:
def focal_loss(input_values, gamma):"""Computes the focal loss"""p = torch.exp(-input_values)loss = (1 - p) ** gamma * input_values * 10return loss.mean()
解释
1.input_values:这是交叉熵损失的值,即负对数似然损失。
2.计算预测概率 p:
p = torch.exp(-input_values)
- 由于
input_values是负对数似然损失(即负的 ),我们可以通过取指数来恢复
),我们可以通过取指数来恢复  。
。
因此,p 确实是模型的预测概率。
3.应用调制因子:
loss = (1 - p) ** gamma * input_values * 10

 易区分的样本。
易区分的样本。
预测出来的概率越大,通常可以说明这个样本是易区分的样本。在分类任务中,模型对某个类别的预测概率越高,通常意味着模型对这个类别的预测越有信心,也就是说模型认为这个样本属于该类别的可能性很大。因此,这个样本相对来说更容易被模型正确分类。
易区分样本和难区分样本
-
易区分样本:
- 模型对其预测概率较高(接近1),表示模型对其预测结果非常有信心。
- 例如,对于一个二分类问题,如果模型对某个样本预测为正类的概率是0.95,那么模型对这个预测结果非常有信心,这个样本就是易区分样本。
-
难区分样本:
- 模型对其预测概率较低或接近中间值,表示模型对其预测结果没有太大信心。
- 例如,对于一个二分类问题,如果模型对某个样本预测为正类的概率是0.55,那么模型对这个预测结果的信心较低,这个样本就是难区分样本。
IB_Focal损失
自我感悟:
就是在focal损失的基础上乘上了平衡因子
class IB_FocalLoss(nn.Module):def __init__(self, weight=None, alpha=10000., gamma=0.):super(IB_FocalLoss, self).__init__()assert alpha > 0self.alpha = alphaself.epsilon = 0.001self.weight = weightself.gamma = gammadef forward(self, input, target, features):grads = torch.sum(torch.abs(F.softmax(input, dim=1) - F.one_hot(target, num_classes)),1) # N * 1ib = grads*(features.reshape(-1))ib = self.alpha / (ib + self.epsilon)return ib_focal_loss(F.cross_entropy(input, target, reduction='none', weight=self.weight), ib, self.gamma)def focal_loss(input_values, gamma):"""Computes the focal loss"""p = torch.exp(-input_values)#loss = (1 - p) ** gamma * input_valuesloss = (1- p) ** gamma * input_values * 10return loss.mean()class FocalLoss(nn.Module):def __init__(self, weight=None, gamma=0.):super(FocalLoss, self).__init__()assert gamma >= 0self.gamma = gammaself.weight = weightdef forward(self, input, target):return focal_loss(F.cross_entropy(input, target, reduction='none', weight=self.weight), self.gamma)
weight:类别权重,用于处理类别不平衡问题。alpha:影响平衡因子的超参数,控制样本的重要性。epsilon:一个小值,防止除零错误。gamma:Focal Loss 的调制因子,控制易分类样本的权重。
相关文章:
IB 公式解析
IB损失 自我感悟 根据对决策边界的影响程度来分配权重。影响程度越大,分配到的权重越小;影响程度越小,分配到的权重越大。 最后其实就是平衡因子和交叉熵损失的输出的乘积 公式 3.2. Influence Function 影响函数允许我们在移除样本时估…...

开发辅助工具的缩写
开发辅助工具的缩写有很多,这些工具通常是为了提高软件开发效率、代码质量和团队协作效率而设计的。以下是一些常见的开发辅助工具及其缩写: IDE - Integrated Development Environment(集成开发环境) VCS - Version Control Sys…...
)
linux程序分析命令(一)
linux程序分析命令(一) **ldd:**用于打印共享库依赖。这个命令会显示出一个可执行文件所依赖的所有共享库(动态链接库),这对于解决运行时库依赖问题非常有用。**nm:**用于列出对象文件的符号表。这个命令可以显示出定…...

MYSQL数据库-SQL语句
数据库相关概念 名称全称简称数据库存储数据的仓库,数据是有组织的进行存储DataBase(DB)数据库管理系统操纵和管理数据库的大型软件DataBase Management System(DBMS)SQL操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准Structured Quer…...

MyBatis认识
一、定义 MyBatis是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java O…...
【WEEK11】 【DAY6】Employee Management System Part 7【English Version】
2024.5.11 Saturday Continued from 【WEEK11】 【DAY5】Employee Management System Part 6【English Version】 Contents 10.8. Delete and 404 Handling10.8.1. Modify list.html10.8.2. Modify EmployeeController.java10.8.3. Restart10.8.4. 404 Page Handling10.8.4.1. …...

【52】Camunda8-Zeebe核心引擎-Clustering与流程生命周期
Clustering集群 Zeebe本质是作为一个brokers集群运行,形成一个点对点网络。在这个网络中,所有brokers的功能与服务都相同,没有单点故障。 Gossip协议 Zeebe实现了gossip协议,并借此知悉哪些broker当前是集群的一部分。 集群使用…...
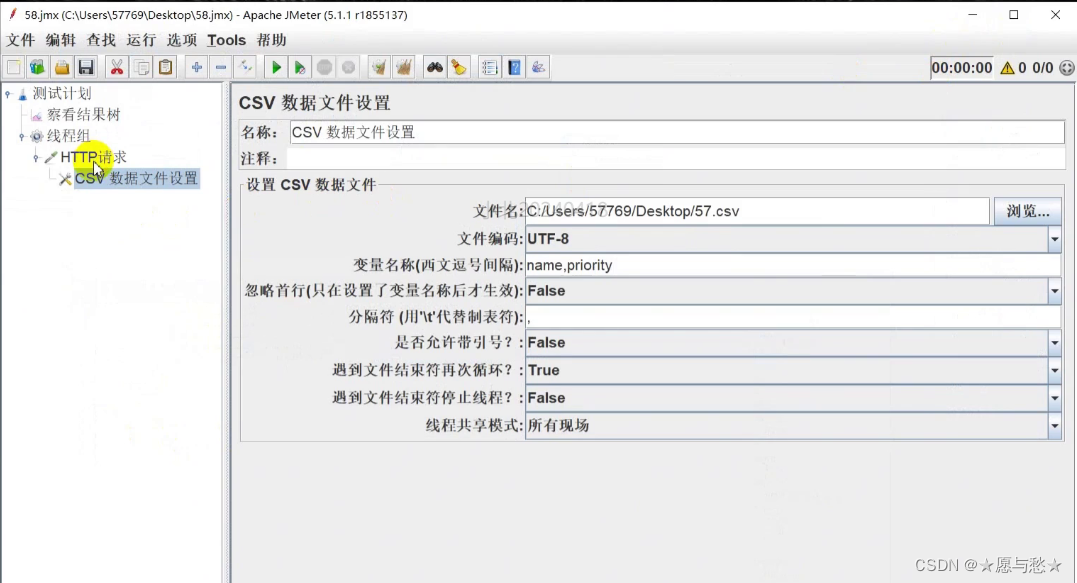
从零开始的软件测试学习之旅(八)jmeter线程组参数化及函数学习
jmeter线程组参数化及函数学习 Jmeter基础基本使用流程组件与元件 线程组线程的执行方式Jmeter组件执行顺序 常见属性设置查看结果数的作用域举例 Jmeter参数化实现方式1.用户定义参数2.用户参数3.函数4.csv数据文件设置 每日复习 Jmeter基础 基本使用流程 启动项目案例 启动…...

图文并茂:解析Spring Boot Controller返回图片的三种方式
欢迎来到我的博客,代码的世界里,每一行都是一个故事 图文并茂:解析Spring Boot Controller返回图片的三种方式 前言使用Base64编码返回图片使用byte数组返回图片使用Resource对象返回图片图片格式转换与性能对比 前言 在互联网的世界里&…...
.)
问题处理记录 | 表输出报错 Packet for query is too large (5,214,153 > 4,194,304).
这个错误是由于MySQL服务器接收到的查询数据包太大而引起的。具体来说,错误消息中提到的数据包大小为5,214,153字节,而MySQL服务器默认只接受最大为4,194,304字节的数据包。 要解决这个问题,你可以尝试通过修改MySQL服务器的配置来增大max_a…...

数据结构_栈和队列(Stack Queue)
✨✨所属专栏:数据结构✨✨ ✨✨作者主页:嶔某✨✨ 栈: 代码:function/数据结构_栈/stack.c 钦某/c-language-learning - 码云 - 开源中国 (gitee.com)https://gitee.com/wang-qin928/c-language-learning/blob/master/function/…...
基于docker 的elasticsearch冷热分离及生命周期管理
文章目录 冷热集群架构的应用场景冷热集群架构的优势冷热集群架构实战搭建集群 索引生命周期管理认识索引生命周期索引生命周期管理的历史演变索引生命周期管理的基础知识Rollover:滚动索引 冷热集群架构的应用场景 某客户的线上业务场景如下:系统每天增…...
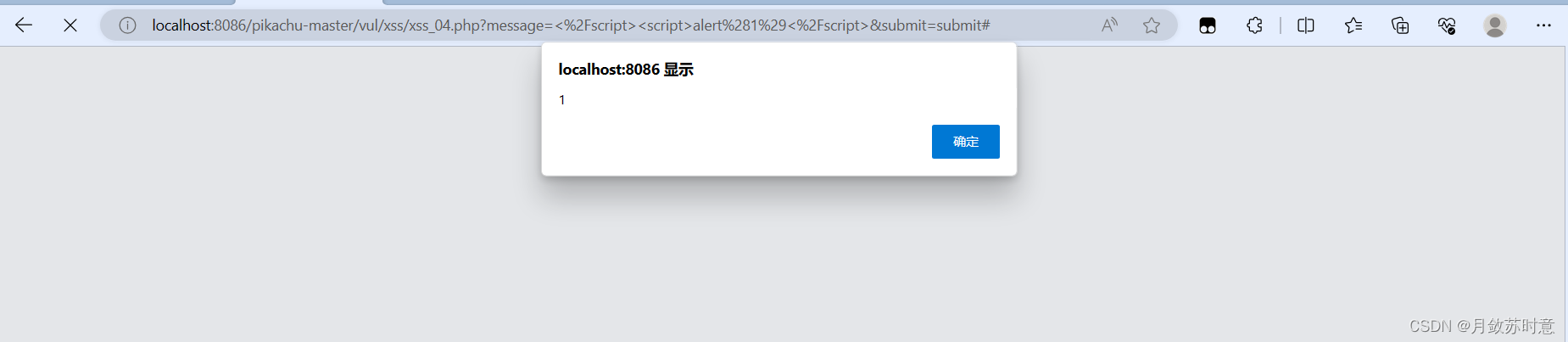
pikachu靶场(xss通关教程)
(注:若复制注入代码攻击无效,请手动输入注入语句,在英文输入法下) 反射型xss(get型) 1.打开网站 发现有个框,然后我们在框中输入一个“1”进行测试, 可以看到提交的数据在url处有显示…...

实验0.0 Visual Studio 2022安装指南
Visual Studio 2022 是一个功能强大的开发工具,对于计算机专业的学生来说,它不仅可以帮助你完成学业项目,还能为你将来的职业生涯打下坚实的基础。通过学习和使用 Visual Studio,你将能够更高效地开发软件,并在编程领域…...

数据结构之----线性表
线性表分为 顺序存储结构 和 链式存储结构 线性表的顺序存储结构: 线性表的顺序存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素。 1,顺序表的结构: #define MAXSIZE 20 typedef int El…...

thinkphp5.1 模型auto
在ThinkPHP5.1中,模型的自动完成功能可以通过在模型类中定义auto属性来实现。这个属性是一个数组,包含了需要自动填充的字段和对应的处理规则。 以下是一个简单的例子,展示了如何在ThinkPHP5.1的模型中使用自动完成功能: <?…...
企业微信创建应用(一)
登录到企业微信后台管理(https://work.weixin.qq.com/)进入自建应用(应用管理-应用-创建应用) 3.查看参数AgentId和 Secret 4.企业微信查看效果...

Cosmo Bunny Girl
可爱的宇宙兔女郎的3D模型。用额外的骨骼装配到Humanoid上,Apple混合了形状。完全模块化,包括不带衣服的身体。 技术细节 内置,包括URP和HDRP PDF。还包括关于如何启用URP和HDRP的说明。 LOD 0:面:40076,tris 76694,verts 44783 装配了Humanoid。添加到Humanoid中的其他…...

初始化linux数据盘(3TB)分区-格式化-挂载目录
场景说明:某云给我们服务器加载了一块3TB的硬盘扩容(没有直接扩,原因是原来的盘做的是mbr(什么年代了,谁干的)的分区,最大识别2TB) 确认磁盘 输入命令lsblk 查看数据盘信息 &#…...

NFS网络文件系统的应用
1.配置2台服务器要求如下: a)服务器1: 主机名:user-server.timinglee.org ip地址: 172.25.254.100 [rootserver100 桌面]# hostnamectl hostname user-server.timinglee.org [rootserver100 桌面]# ifconfig eth0: fl…...

5分钟解锁虚拟多屏生产力:Rust驱动打造Windows虚拟显示器终极方案
5分钟解锁虚拟多屏生产力:Rust驱动打造Windows虚拟显示器终极方案 【免费下载链接】virtual-display-rs A Windows virtual display driver to add multiple virtual monitors to your PC! For Win10. Works with VR, obs, streaming software, etc 项目地址: htt…...

Python核心技术难点与实战案例解析
Python核心技术难点梳理与实战落地案例解析 一、前言 Python凭借简洁易懂的语法、丰富齐全的第三方库、跨平台运行优势,成为当下后端开发、数据分析、自动化运维、人工智能等领域的主流编程语言。在实际项目开发与学习过程中,多数开发者常会遇到语法细节…...

Taskbar11完全指南:解锁Windows 11任务栏自定义的终极解决方案
Taskbar11完全指南:解锁Windows 11任务栏自定义的终极解决方案 【免费下载链接】Taskbar11 Change the position and size of the Taskbar in Windows 11 项目地址: https://gitcode.com/gh_mirrors/ta/Taskbar11 还在为Windows 11任务栏的严格限制感到困扰吗…...
)
告别HAL库:用GD32标准库为RT-Thread打造轻量级驱动(以F4系列为例)
告别HAL库:用GD32标准库为RT-Thread打造轻量级驱动(以F4系列为例) 在嵌入式开发领域,HAL库因其跨平台兼容性和易用性广受欢迎,但对于追求极致性能和精简代码的开发者而言,标准库往往能带来更直接的硬件控制…...
帮你一次搞定)
别再复制粘贴了!用LaTeX写IEEE论文,这份保姆级配置清单(含数学符号速查表)帮你一次搞定
IEEE论文LaTeX高效写作:从零配置到数学符号速查的全套解决方案 第一次用LaTeX写IEEE论文时,我在凌晨三点对着报错的红色文字和错位的公式几乎崩溃。直到一位博士生分享了他的配置文件,我才发现原来90%的常见问题都有现成解决方案。本文将把这…...

AzurLaneLive2DExtract:碧蓝航线Live2D资源提取的完整指南
AzurLaneLive2DExtract:碧蓝航线Live2D资源提取的完整指南 【免费下载链接】AzurLaneLive2DExtract OBSOLETE - see readme / 碧蓝航线Live2D提取 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneLive2DExtract 想要从碧蓝航线游戏中提取精美的Live2D…...

Windows热键冲突终结者:Hotkey Detective深度解析与实战指南
Windows热键冲突终结者:Hotkey Detective深度解析与实战指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 想…...

CLI-Anything与MCP服务器:打造强大后端的实战教程
CLI-Anything与MCP服务器:打造强大后端的实战教程 【免费下载链接】CLI-Anything "CLI-Anything: Making ALL Software Agent-Native" -- CLI-Hub: https://clianything.cc/ 项目地址: https://gitcode.com/GitHub_Trending/cl/CLI-Anything CLI-A…...

终极Ryzen调校指南:用SMUDebugTool解锁AMD平台隐藏性能
终极Ryzen调校指南:用SMUDebugTool解锁AMD平台隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://g…...

基于树莓派A+与3.5寸PiTFT打造便携式触摸屏设备全攻略
1. 项目概述与核心价值如果你和我一样,对嵌入式开发和硬件DIY有浓厚的兴趣,那么将一块功能强大的单板计算机(比如树莓派)变成一个可以揣在口袋里、随时掏出来就能用的便携式触摸屏设备,绝对是一个充满成就感的项目。这…...