如何训练一个大模型:LoRA篇
目录
写在前面
一、LoRA算法原理
1.设计思想
2.具体实现
二、peft库
三、完整的训练代码
四、总结
写在前面
现在有很多开源的大模型,他们一般都是通用的,这就意味着这些开源大模型在特定任务上可能力不从心。为了适应我们的下游任务,就需要对预训练模型进行微调。
全参数微调有两个问题:在新的数据集上训练,会破坏大模型原来的能力,使其泛化能力急剧下降;而且现在的模型参数动辄几十亿上百亿,要执行全参数微调的话,他贵啊!!

于是LoRA出现了, LoRA(Low-Rank Adaptation)是微软提出的一种参数有效的微调方法,可以降低微调占用的显存以及更轻量化的迁移。同时解决了上述两个问题,那它凭什么这么厉害?往下看吧。
一、LoRA算法原理
1.设计思想
论文地址:https://arxiv.org/pdf/2106.09685
模型是过参数化的,它们有更小的内在维度,模型主要依赖于这个低的内在维度(low intrinsic dimension)去做任务适配。假设模型在适配任务时参数的改变量是低秩的,由此引出低秩自适应方法lora,通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
上面那段话也许有点难以理解。简单来讲,LoRA是大模型的低秩适配器,或者就简单的理解为适配器,在图像生成中可以将lora理解为某种图像风格(比如SD社区中的各种漂亮妹子的lora,可插拔式应用,甚至组合式应用实现风格的融合)的适配器,在NLP中可以将其理解为某个任务的适配器(比如基于通用大模型训练的各个领域的专家大模型)。
2.具体实现
LoRA的实现方式是在基础模型的线性变换模块(全连接、Embedding、卷积)旁边增加一个旁路,这个旁路是由两个小矩阵做内积得来的,两个小矩阵的中间维度,就是秩!!
通过低秩分解(先降维再升维)来模拟参数的更新量。
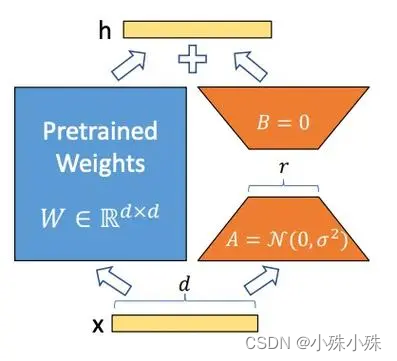
下面是LoRA的公式:
上面公式中x是这一层的输入,h是这一层的输出,是基础模型的权重参数;A和B是两个小矩阵,A的输入和B的输出形状跟
一样,A的输出和B的输入一样,称为秩,秩一般很小,微调的所有“新知识”都保存在A和B里面;
是一个缩放系数,这个数越大,LoRA权重的影响就越大。
下面就是经典的LoRA运算流程图:
我们以ChatGLM的attention模块的query_key_value(是一个linear(4096, 12288))为例,描述一下流程,其中输入4096、输出12288,LoRA的秩是8:
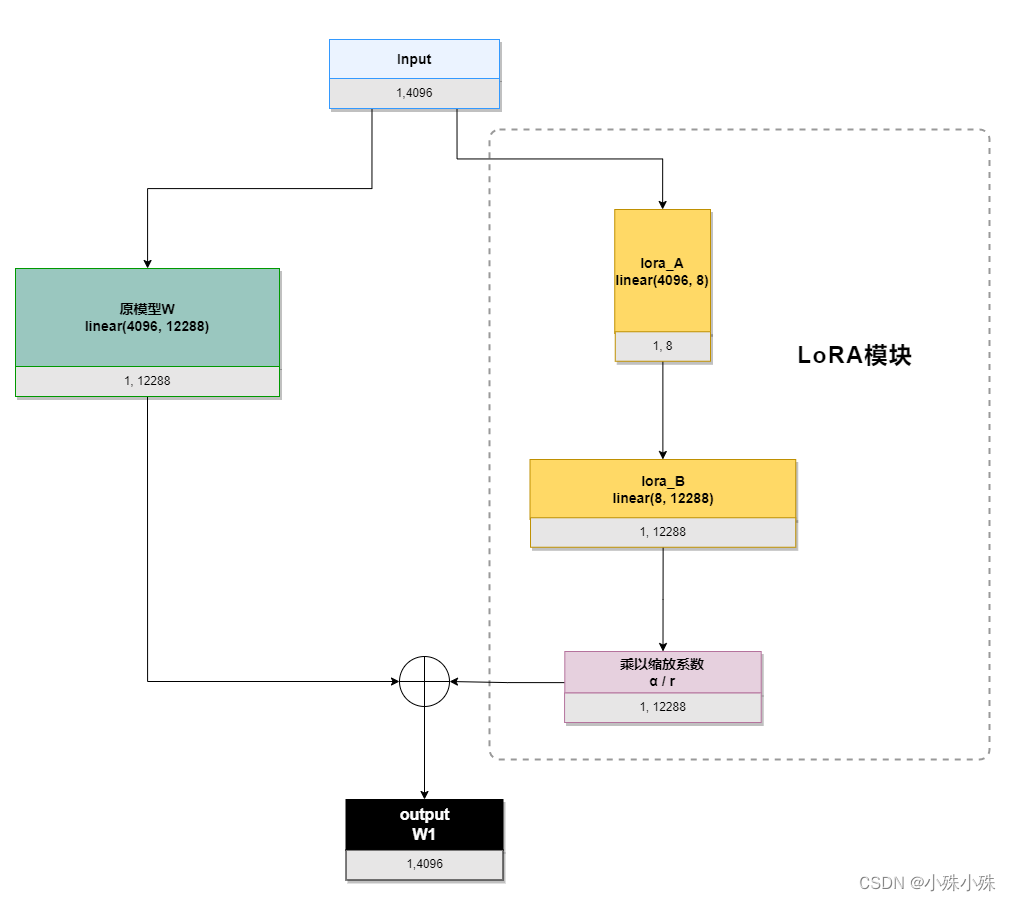
初始化时,lora_A采用高斯分布初始化,lora_B初始化为全0,保证训练开始时旁路为0矩阵;
训练时,原模型固定,只训练降维矩阵A和升维矩阵B;
推理时需要做参数合并,就是将AB的内积(一个与基础模型形状一样的低秩矩阵)加到原参数上,这样不引入额外的推理延迟。对于上图的例子,lora_A与lora_B做内积,得到4096x1228的参数矩阵,然后与基础模型W相加就可以了。
我们来算算需要训练多少参数,如果是全参数需要训练4096*12288=50331648个参数,LoRA需要训练4096*8+8*12288=131072,参数可是数量级的减少啊。
二、peft库
Pytorch中peft库实现了LoRA算法,而且使用非常方便,我们以ChatGLM代码为例,看一下LoRA对ChatGLM模型做了什么,直接上代码:
from peft import LoraConfig, TaskType, get_peft_model
from transformers import AutoModel, HfArgumentParser, TrainingArgumentsfrom finetune import CastOutputToFloat, FinetuneArgumentsdef count_params(model):for name, param in model.named_parameters():print(name, param.shape)def make_peft_model():# 初始化原模型model = AutoModel.from_pretrained("THUDM/chatglm-6b", load_in_8bit=False, trust_remote_code=True, device_map="auto", local_files_only=True).float()# 给原模型施加LoRApeft_config = LoraConfig(task_type=TaskType.CAUSAL_LM,inference_mode=True,r=8,lora_alpha=32,lora_dropout=0.1,target_modules=['query_key_value'],)model = get_peft_model(model, peft_config).float()count_params(model)if __name__ == '__main__':make_peft_model()输出如下:
base_model.model.transformer.word_embeddings.weight torch.Size([130528, 4096])
base_model.model.transformer.layers.0.input_layernorm.weight torch.Size([4096])
base_model.model.transformer.layers.0.input_layernorm.bias torch.Size([4096])
base_model.model.transformer.layers.0.attention.query_key_value.base_layer.weight torch.Size([12288, 4096])
base_model.model.transformer.layers.0.attention.query_key_value.base_layer.bias torch.Size([12288])
base_model.model.transformer.layers.0.attention.query_key_value.lora_A.default.weight torch.Size([8, 4096])
base_model.model.transformer.layers.0.attention.query_key_value.lora_B.default.weight torch.Size([12288, 8])
base_model.model.transformer.layers.0.attention.dense.weight torch.Size([4096, 4096])
base_model.model.transformer.layers.0.attention.dense.bias torch.Size([4096])
base_model.model.transformer.layers.0.post_attention_layernorm.weight torch.Size([4096])
base_model.model.transformer.layers.0.post_attention_layernorm.bias torch.Size([4096])
base_model.model.transformer.layers.0.mlp.dense_h_to_4h.weight torch.Size([16384, 4096])
base_model.model.transformer.layers.0.mlp.dense_h_to_4h.bias torch.Size([16384])
base_model.model.transformer.layers.0.mlp.dense_4h_to_h.weight torch.Size([4096, 16384])
base_model.model.transformer.layers.0.mlp.dense_4h_to_h.bias torch.Size([4096])
base_model.model.transformer.layers.1.input_layernorm.weight torch.Size([4096])
base_model.model.transformer.layers.1.input_layernorm.bias torch.Size([4096])......
可以看到模型中被添加了LoRA模块(红色部分),是根据全连接“query_key_value”生成的。因为query_key_value层输入是4096,输出是12288,而配置中LoRA的秩是8,所以两个LoRA块是(8,4096)和(12288, 8)
代码也很好理解,get_peft_model方法将原模型参数冻结并且根据配置向模型中添加LoRA模块。
解释一下配置LoraConfig,下面是这个对象的主要参数:
1.task_type:
SEQ_CLS:序列分类(Sequence Classification)任务。这种任务涉及对输入序列整体进行分类,例如情感分析、文本分类等。
SEQ_2_SEQ_LM:序列到序列语言建模(Sequence-to-Sequence Language Modeling)任务。这种任务能够将一个输入序列映射到另一个输出序列,例如机器翻译、文本摘要等。
CAUSAL_LM:因果语言建模(Causal Language Modeling)任务。这种任务涉及训练一个模型,使其能够预测给定先前上下文的下一个标记,例如自动补全、语言生成等。
TOKEN_CLS:标记分类(Token Classification)任务。这种任务涉及对输入序列中的每个标记进行分类,例如命名实体识别、词性标注等。
QUESTION_ANS:问答(Question Answering)任务。这种任务涉及根据给定的问题和相关的上下文文本来预测答案。输入是Prompt+问题。
FEATURE_EXTRACTION:特征提取(Feature Extraction)任务。这种任务涉及从文本或序列中提取有用的特征,以供其他任务或模型使用。
2.r:LoRA秩的维度,这数越大,微调带来的“影响”越强,但是需要训练的参数量会增加。
3.lora_alpha:LoRA在前向传播的过程中引入一个额外的扩展系数(scaling coefficient),用于将LoRA权重应用于预训练权重。这个数越大,LoRA权重的影响就越大。
4.target_modules:要施加LoRA的模块名称,需要注意的是,参数是字符串数组,模块类型必须是`torch.nn.Linear`, `torch.nn.Embedding`, `torch.nn.Conv2d`, `transformers.pytorch_utils.Conv1D`中的一个。比如这个例子中还可以填写"word_embeddings"和"dense"。
三、完整的训练代码
现在给出一个完整的基于LoRA的ChatGLM训练代码,peft库在原模型基础上添加LoRA非常方便,对代码的侵入也很小。下面的代码我添加了注释,流程还是很清楚的:
from transformers.integrations import TensorBoardCallback
from torch.utils.tensorboard import SummaryWriter
from transformers import TrainingArguments
from transformers import Trainer, HfArgumentParser
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn as nn
from peft import get_peft_model, LoraConfig, TaskType
from dataclasses import dataclass, field
import datasets
import ostokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)@dataclass
class FinetuneArguments:dataset_path: str = field(default="data/alpaca")model_path: str = field(default="output")lora_rank: int = field(default=8)class CastOutputToFloat(nn.Sequential):def forward(self, x):return super().forward(x).to(torch.float32)def data_collator(features: list) -> dict:len_ids = [len(feature["input_ids"]) for feature in features]longest = max(len_ids)input_ids = []labels_list = []for ids_l, feature in sorted(zip(len_ids, features), key=lambda x: -x[0]):ids = feature["input_ids"]seq_len = feature["seq_len"]labels = ([-100] * (seq_len - 1) + ids[(seq_len - 1) :] + [-100] * (longest - ids_l))ids = ids + [tokenizer.pad_token_id] * (longest - ids_l)_ids = torch.LongTensor(ids)labels_list.append(torch.LongTensor(labels))input_ids.append(_ids)input_ids = torch.stack(input_ids)labels = torch.stack(labels_list)return {"input_ids": input_ids,"labels": labels,}class ModifiedTrainer(Trainer):def compute_loss(self, model, inputs, return_outputs=False):return model(input_ids=inputs["input_ids"],labels=inputs["labels"],).lossdef save_model(self, output_dir=None, _internal_call=False):self.model.save_pretrained(output_dir)def main():writer = SummaryWriter()# 组织训练参数finetune_args, training_args = HfArgumentParser((FinetuneArguments, TrainingArguments)).parse_args_into_dataclasses()# init modelmodel = AutoModel.from_pretrained("THUDM/chatglm-6b", load_in_8bit=False, trust_remote_code=True, device_map="auto", local_files_only=True).float()model.gradient_checkpointing_enable()model.enable_input_require_grads()# 模型是可以并行化的。model.is_parallelizable = True# 启用模型的并行化。model.model_parallel = True# 将模型的 lm_head(语言模型头)的输出转换为浮点数类型。model.lm_head = CastOutputToFloat(model.lm_head)# 禁用模型配置中的缓存,用于禁止缓存中间结果,可以减少显存占用,但是训练时间会变长model.config.use_cache = (False # silence the warnings. Please re-enable for inference!)# LoRA配置peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM,inference_mode=False,r=finetune_args.lora_rank,lora_alpha=32,lora_dropout=0.1,)# 对模型使用LoRAmodel = get_peft_model(model, peft_config).float()# 使用alpaca数据集dataset = datasets.load_from_disk(finetune_args.dataset_path)print(f"\n{len(dataset)=}\n")# for d in dataset.iter(batch_size=1):# print("d:", d)# start traintrainer = ModifiedTrainer(model=model,train_dataset=dataset,args=training_args,callbacks=[TensorBoardCallback(writer)],data_collator=data_collator,)trainer.train()writer.close()# 存训练后的参数model.save_pretrained(training_args.output_dir)if __name__ == "__main__":main()
训练之后模型文件会保存在output_dir目录中。到这里我们发现一个问题,毕竟LoRA在原模型的基础上加了分支,这会带来推理效率的降低,其实我们调用merge_and_unload方法就能将LoRA的分支模块合并到基础模型,推理代码如下:
from peft import LoraConfig, TaskType, get_peft_model
from transformers import AutoModel, AutoModelForSeq2SeqLM
import torch
from transformers import AutoTokenizer# 加载基础模型
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)# 配置LoRA
peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM, inference_mode=True,target_modules=['query_key_value'],r=8, lora_alpha=32, lora_dropout=0.1
)
# 对模型使用LoRA
model = get_peft_model(model, peft_config).half()
# 加载LoRA参数
model.load_state_dict(torch.load("output/checkpoint-1000/adapter_model.bin", map_location=torch.device("cuda")), strict=False)
# 将LoRA的分支模块合并到基础模型
model.merge_and_unload()while True:prompt = input("Prompt: ")inputs = tokenizer(prompt, return_tensors="pt")model.params_dtype = torch.float32response = model.generate(input_ids=inputs["input_ids"],max_length=inputs["input_ids"].shape[-1] + 128)response = response[0, inputs["input_ids"].shape[-1]:]print("responseL", response)for r in response:print(r, ":", tokenizer.decode([r], skip_special_tokens=False))print("Response:", tokenizer.decode(response, skip_special_tokens=True))
四、总结
1.LoRA的实现方式是在原模型的线性变换模块(全连接、Embedding、卷积)旁边增加一个旁路,通过低秩分解(先降维再升维)来模拟参数的更新量。
2.LoRA模块由两个小矩阵组成,这两个矩阵内积的输入输出形状与原模型一致,大模型需要的“新知识”就存在这个模块中;
3.秩可以很小,有实验表明,就算秩=1,效果也不是很差;
4.尽量多的对模型中的线性变换模块使用秩很小LoRA;而不是对一个模块使用秩很大的LoRA;
5.推理时需要做参数合并,就是将AB的内积加到原参数上,从而不引入额外的推理延迟;
5.LoRA智能一定程度提升模型在某个领域的能力,并不能使模型发生根本性的能力提升。
LoRA就介绍到这里,关注不迷路(#^.^#)
关注订阅号了解更多精品文章

交流探讨、商务合作请加微信

相关文章:
如何训练一个大模型:LoRA篇
目录 写在前面 一、LoRA算法原理 1.设计思想 2.具体实现 二、peft库 三、完整的训练代码 四、总结 写在前面 现在有很多开源的大模型,他们一般都是通用的,这就意味着这些开源大模型在特定任务上可能力不从心。为了适应我们的下游任务,…...

Spring Cloud学习笔记(Nacos):基础和项目启动
这是本人学习的总结,主要学习资料如下 - 马士兵教育 1、基础和版本选择2、启动项目2.1、源码启动项目2.2、命令行启动 1、基础和版本选择 Nacos是用于服务发现和注册,是Spring Cloud Alibaba的核心模块。 根据文档,Spring Cloud Alibaba的版…...

音频提取特征
目录 音频提取特征 音频切割 依赖项: pip install librosa pip install transformers 音频提取特征 import librosa import numpy as np import torch from transformers import Wav2Vec2Processorprocessor Wav2Vec2Processor.from_pretrained("faceboo…...

AJAX前端与后端交互技术知识点以及案例
Promise promise对象用于表示一个异步操作的最终完成(或失败)及其结果值 好处: 逻辑更清晰了解axios函数内部运作机制成功和失败状态,可以关联对应处理程序能解决回调函数地狱问题 /*** 目标:使用Promise管理异步任…...
[AutoSar]BSW_Diagnostic_003 ReadDataByIdentifier(0x22)介绍
目录 关键词平台说明背景一、请求格式二、常用DID三、响应格式四、NRC五、case 关键词 嵌入式、C语言、autosar、OS、BSW、UDS、diagnostic 平台说明 项目ValueOSautosar OSautosar厂商vector , EB芯片厂商TI 英飞凌编程语言C,C编译器HighTec (GCC)au…...

买卖股票的最佳时机 II(LeetCode 122)
❤️❤️❤️ 欢迎来到我的博客。希望您能在这里找到既有价值又有趣的内容,和我一起探索、学习和成长。欢迎评论区畅所欲言、享受知识的乐趣! 推荐:数据分析螺丝钉的首页 格物致知 终身学习 期待您的关注 导航: LeetCode解锁100…...

Spring Boot:让微服务开发像搭积木一样简单!
带你一探 Spring Boot 的自动配置和 Starter POMs 的神奇之处,展示如何通过几个简单的步骤就能让你的微服务应用在云端翱翔! 文章目录 1. 引言1.1 简述Spring框架的起源与重要性1.2 阐述文章目的:深入解析Spring核心功能与应用实践2. 背景介绍…...

WordPress 、Typecho 站点的 MySQL/MariaDB 数据库优化
今天明月给大家分享一下 WordPress 、Typecho 站点的 MySQL/MariaDB 数据库优化,无论你的站点采用是 WordPress 还是 Typecho,都要用到 MySQL/MariaDB 数据库,我们以 MySQL 为主(MariaDB 其实跟 MySQL 基本没啥大的区别࿰…...

==与===的区别
在许多编程语言和脚本语言中,包括 JavaScript 和 PHP 等, 和 是用于比较值的操作符。 “” 是相等运算符,用于比较两个值是否相等。它比较值时会进行类型转换,如果两个值在类型转换后相等,那么它们就被认为是相等的。…...

什么是ACID及基本实现的示例
什么是ACID特性 ACID 是一个缩写词,代表数据库事务的四个关键特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。这些…...
【启明智显技术分享】SSD202核心板Rootfs下如何烧录mac地址
提示:作为Espressif(乐鑫科技)大中华区合作伙伴及sigmastar(厦门星宸)VAD合作伙伴,我们不仅用心整理了你在开发过程中可能会遇到的问题以及快速上手的简明教程供开发小伙伴参考。同时也用心整理了乐鑫及星宸…...

springboot3 集成spring-authorization-server (一 基础篇)
官方文档 Spring Authorization Server 环境介绍 java:17 SpringBoot:3.2.0 SpringCloud:2023.0.0 引入maven配置 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter…...
AVL树!
文章目录 1.AVL树的概念2.AVL树的插入和旋转3.AVL树的旋转3.1旋转的底层:3.2 右旋转3.3 左旋转3.4 双旋 4.AVL树的底层 1.AVL树的概念 当向二叉搜索树中插入新结点后,如果能保证每个结点的左右子树高度之差的绝对值不超过1(需要对树中的结点进行调整)&a…...

知识付费系统怎么安装教程,教师课堂教学该掌握哪些表达技巧?
课堂教学语言表达是教学艺术的一个基本且重要的组成部分。教师向学生传道、授业、解惑以及师生之间信息的传递和情感的交流,都离不开运用教学语言这一有力的工具,在课堂上,教师通过情趣盎然的表述,鞭辟入里的分析,恰到…...

基于MetaGPT的LLM Agent学习实战(一)
前言 我最近一直在做基于AI Agent 的个人项目, 因为工作加班较多,设计思考时间不足,这里借着Datawhale的开源学习课程《MetaGPT智能体理论与实战》课程,来完善自己的思路,抛砖引玉,和各位开发者一起学习&am…...
【IMX6ULL项目】IMX6ULL上Linux系统实现产测工具框架
电子产品量产测试与烧写工具。这是一套软件,用在我们的实际生产中, 有如下特点: 1.简单易用: 把这套软件烧写在 SD 卡上,插到 IMX6ULL 板子里并启动,它就会自动测试各个模块、烧写 EMMC 系统。 工人只要按…...

【Linux基础】Vim保姆级一键配置教程(手把手教你把Vim打造成高效率C++开发环境)
目录 一、前言 二、安装Vim 三、原始Vim编译器的缺陷分析 四、Vim配置 🥝预备知识----.vimrc 隐藏文件 🍋手动配置 Vim --- (不推荐) 🍇自动化一键配置 Vim --- (强烈推荐) ✨功能演示 五、共勉 一、前言 Vim作为…...
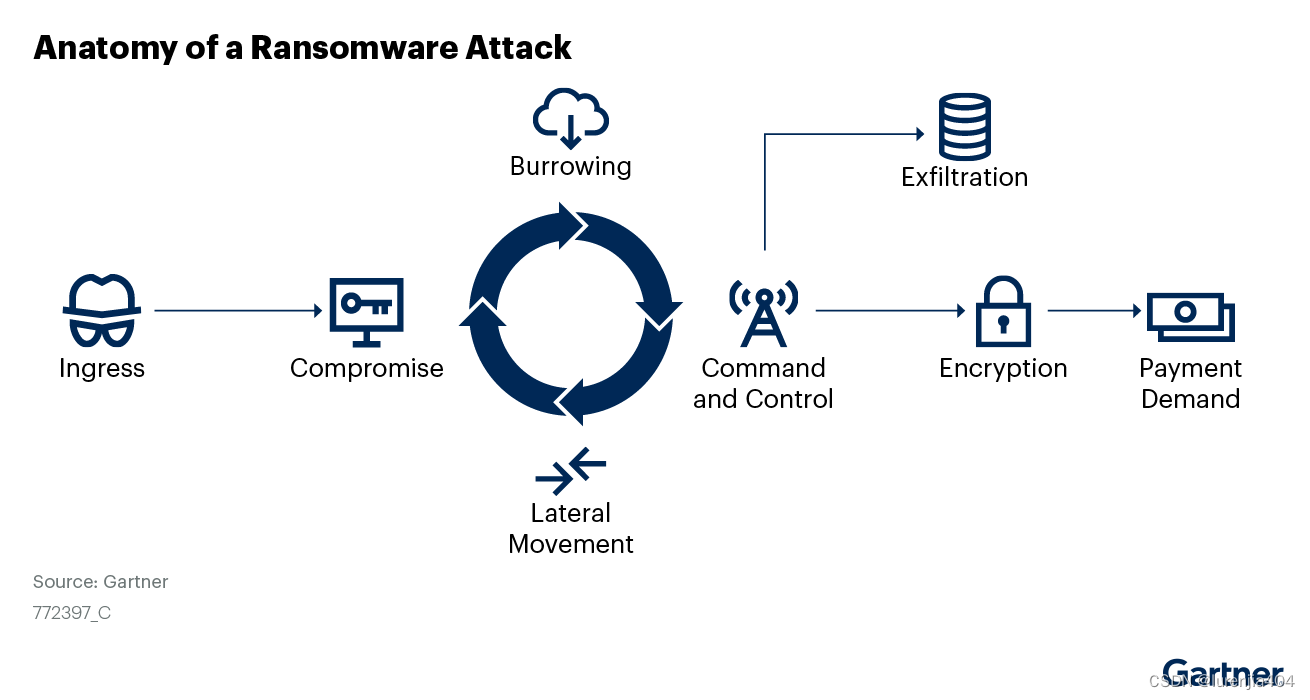
Gartner发布准备应对勒索软件攻击指南:勒索软件攻击的三个阶段及其防御生命周期
攻击者改变了策略,在某些情况下转向勒索软件。安全和风险管理领导者必须通过提高检测和预防能力来为勒索软件攻击做好准备,同时还要改进其事后应对策略。 主要发现 勒索软件(无加密的数据盗窃攻击)是攻击者越来越多地使用的策略。…...

IB 公式解析
IB损失 自我感悟 根据对决策边界的影响程度来分配权重。影响程度越大,分配到的权重越小;影响程度越小,分配到的权重越大。 最后其实就是平衡因子和交叉熵损失的输出的乘积 公式 3.2. Influence Function 影响函数允许我们在移除样本时估…...

开发辅助工具的缩写
开发辅助工具的缩写有很多,这些工具通常是为了提高软件开发效率、代码质量和团队协作效率而设计的。以下是一些常见的开发辅助工具及其缩写: IDE - Integrated Development Environment(集成开发环境) VCS - Version Control Sys…...

如何高效掌握FDS:开源火灾模拟的完整实战指南
如何高效掌握FDS:开源火灾模拟的完整实战指南 【免费下载链接】fds Fire Dynamics Simulator 项目地址: https://gitcode.com/gh_mirrors/fd/fds Fire Dynamics Simulator(FDS)是美国国家标准与技术研究院开发的权威火灾动力学模拟软件…...
)
蓝桥杯嵌入式备赛:手把手搞定AT24C02 EEPROM读写(附CubeMX配置与常见Bug修复)
蓝桥杯嵌入式竞赛实战:AT24C02 EEPROM高效读写全攻略 1. 赛前准备:理解I2C与EEPROM的核心机制 在蓝桥杯嵌入式竞赛中,AT24C02这类EEPROM器件常被用作非易失性存储解决方案。与常见Flash存储器不同,EEPROM支持字节级擦写…...

拆解安防摄像头的“眼睛”:从IMX290 Sensor到镜头,如何一步步调出通透画质?
拆解安防摄像头的“眼睛”:从IMX290 Sensor到镜头,如何一步步调出通透画质? 在安防监控领域,画质表现直接决定了产品的核心竞争力。当我们谈论"通透画质"时,实际上是在讨论一种光学与电子系统的协同优化艺术…...

深度解析nxdumptool:专业级Switch游戏卡带转储工具完全指南
深度解析nxdumptool:专业级Switch游戏卡带转储工具完全指南 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com/gh_mirror…...

电钢琴初学者买琴不踩坑攻略:高性价比型号清单及避坑推荐
一、「绝对不能踩的坑」(新手常犯的4个错误) 1.预算陷阱:低于1000元的「玩具琴」不能买 1000元以下的电钢琴,大多是手感音色差、会毁手型,浪费钱。 2.键盘:必须选「88键逐级重锤配重」 电钢琴的核心是「…...

你的耳机真的在发挥全部潜力吗?Equalizer APO带来的音频革命
你的耳机真的在发挥全部潜力吗?Equalizer APO带来的音频革命 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo 你有没有过这样的体验?花了几千块钱买来的高端耳机,播放…...

手把手拆解FD-SOI工艺流程:从SOI衬底到应变硅外延的保姆级图解
从SOI衬底到应变硅外延:FD-SOI工艺全流程拆解指南 想象一下建造一座微型城市,每一栋建筑只有头发丝直径的万分之一大小。这就是FD-SOI工艺工程师的日常工作——在硅片上用原子级精度"建造"晶体管。与传统的体硅工艺不同,FD-SOI&…...

从 JetBrains 全家桶用户视角,聊聊 DataGrip 那些被低估的『协同』技巧:共享查询、布局同步与团队规范
从 JetBrains 全家桶用户视角,聊聊 DataGrip 那些被低估的『协同』技巧:共享查询、布局同步与团队规范 在团队开发环境中,数据库操作往往被视为个人技能而非团队资产。当开发者频繁切换于 IntelliJ IDEA、PyCharm 和 DataGrip 之间时…...
)
企业自建内部知识库,最容易死在这8个问题上(管理+技术双维度)
很多企业想做内部知识库:把经验、图纸、方案、流程、故障案例沉淀下来,避免人员流失就丢技术、避免重复踩坑。但真正落地后,90%都变成了“僵尸文档库”——要么没人用、没人更,要么技术层面跟不上需求,AI模式形同虚设。…...

汽车电子工程师必看:ISO 16750-2023全套标准解读与实战应用指南
汽车电子工程师必看:ISO 16750-2023全套标准解读与实战应用指南 在汽车电子领域,每一次技术迭代都伴随着更严苛的可靠性要求。去年参与某新能源车企的域控制器项目时,我们团队曾因忽视化学负荷测试导致批量产品在盐雾试验中失效——这个价值七…...