SpringBoot自动配置源码解析+自定义Spring Boot Starter
@SpringBootApplication
Spring Boot应用标注 @SpringBootApplication 注解的类说明该类是Spring Boot 的主配置类,需要运行该类的main方法进行启动 Spring Boot 应用
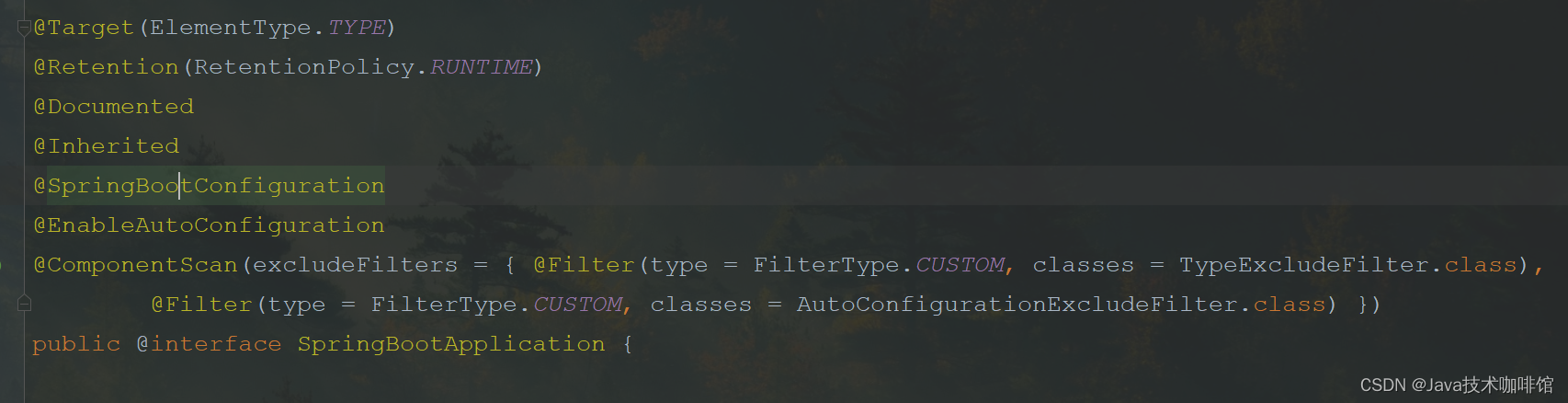
@SpringBootConfiguration
该注解标注表示标注的类是个配置类
@EnableAutoConfiguration
直译:开启自动配置
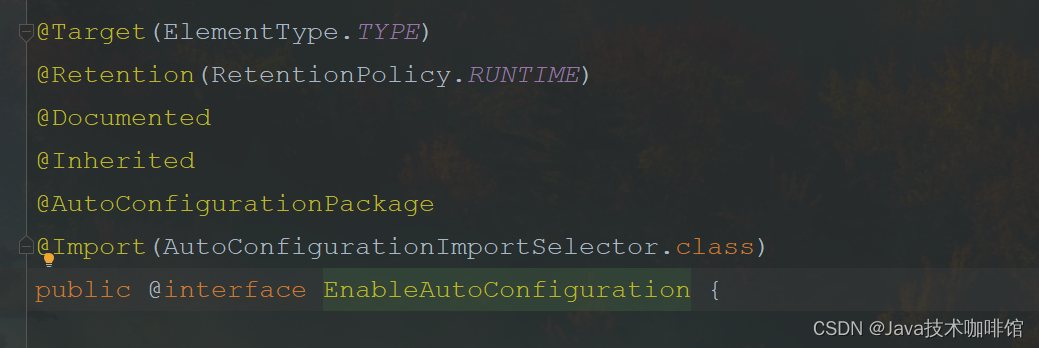
@AutoConfigurationPackage
将当前配置类所在的包保存在 basePackages 的Bean 中,提供给Spring 使用

@Import(AutoConfigurationPackages.Registrar.class)
注册一个保存当前配置类所在包的Bean
@Import(AutoConfigurationImportSelector.class)
使用@Import注解完成导入AutoConfigurationImportSelector类 的功能。AutoConfigurationImportSelector 实现了DeferredImportSelector类
注:在解析ImportSelector时,所导入的配置类会被直接解析,而DeferredImportSelector导入的配置类会延迟进行解析(延迟在其他配置类都解析完之后)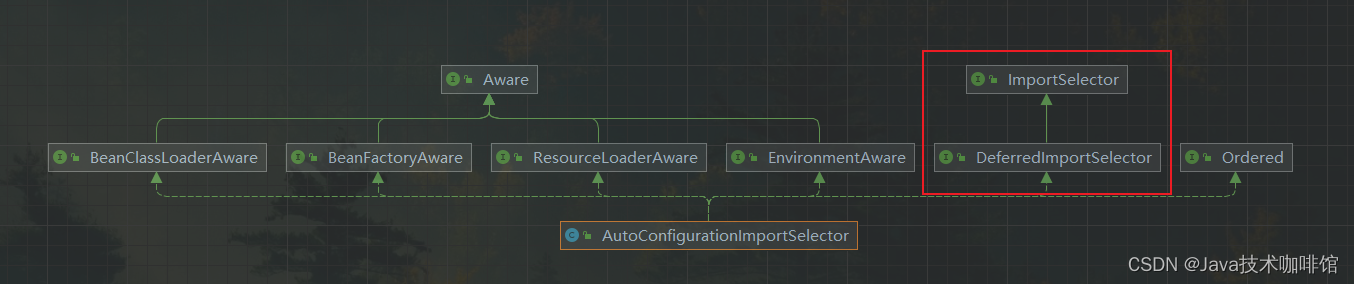
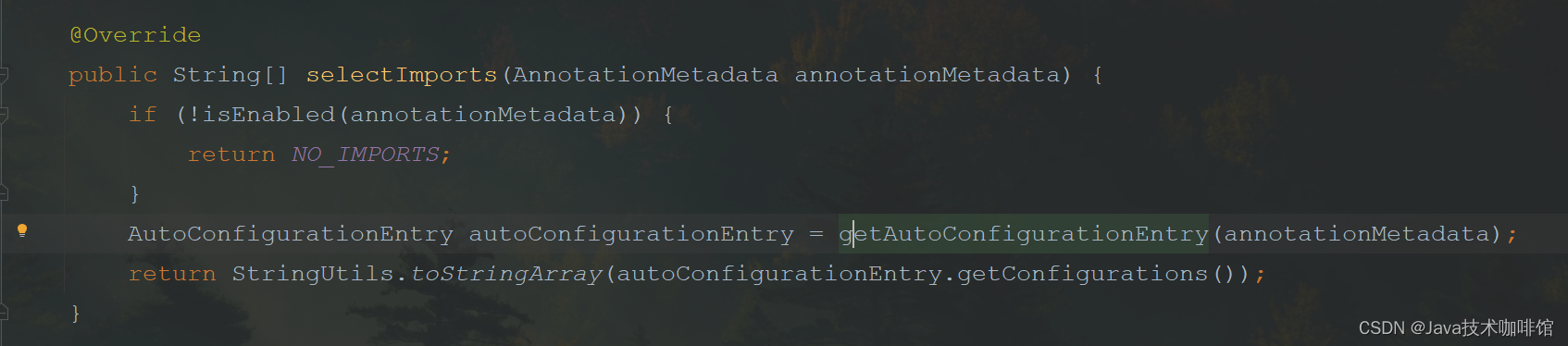 Spring容器在解析@Import时会去执行DeferredImportSelector 的 selectImports方法:
Spring容器在解析@Import时会去执行DeferredImportSelector 的 selectImports方法:
/*** Return the {@link AutoConfigurationEntry} based on the {@link AnnotationMetadata}* of the importing {@link Configuration @Configuration} class.* @param annotationMetadata the annotation metadata of the configuration class* @return the auto-configurations that should be imported*/protected AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) {if (!isEnabled(annotationMetadata)) {return EMPTY_ENTRY;}AnnotationAttributes attributes = getAttributes(annotationMetadata);// 从META-INF/spring.factories中获得候选的自动配置类List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes);//去重configurations = removeDuplicates(configurations);//根据EnableAutoConfiguration注解中exclude、excludeName属性、//spring.autoconfigure.exclude 配置的排除项Set<String> exclusions = getExclusions(annotationMetadata, attributes);checkExcludedClasses(configurations, exclusions);configurations.removeAll(exclusions);// 通过读取spring.factories 中 // OnBeanCondition\OnClassCondition\OnWebApplicationCondition进行过滤configurations = getConfigurationClassFilter().filter(configurations);fireAutoConfigurationImportEvents(configurations, exclusions);return new AutoConfigurationEntry(configurations, exclusions);}springboot应用中都会引入spring-boot-autoconfigure依赖,spring.factories文件就在该包的META-INF下面。spring.factories文件是Key=Value形式,多个Value时使用“,”逗号进行分割,该文件中定义了关于初始化、监听器、过滤器等信息,而真正使自动配置生效的key是org.springframework.boot.autoconfigure.EnableAutoConfiguration,如下所示:

Spring Boot 提供的自动配置类
https://docs.spring.io/spring-boot/docs/current/reference/html/auto-configuration-classes.html#appendix.auto-configuration-classes
Spring Boot 常用条件注解
ConditionalOnBean:是否存在某个某类或某个名字的Bean
ConditionalOnMissingBean:是否缺失某个某类或某个名字的Bean
ConditionalOnSingleCandidate:是否符合指定类型的Bean只有一个
ConditionalOnClass:是否存在某个类
ConditionalOnMissingClass:是否缺失某个类
ConditionalOnExpression:指定的表达式返回的是true还是false
ConditionalOnJava:判断Java版本
ConditionalOnWebApplication:当前应用是不是一个Web应用
ConditionalOnNotWebApplication:当前应用不是一个Web应用
ConditionalOnProperty:Environment中是否存在某个属性
我们也可以使用@Conditional注解进行自定义条件注解

条件注解可以写在类和方法上,如果某个@xxxCondition条件注解写在自动配置类上,那该自动配置类会不会生效就要看当前条件是否符合条件,或者条件注解写在某个@Bean修饰的方法上,那么Bean生不生效也要看当前的条件是否符条件。
Spring容器在解析某个自动配置类时,会先判断该自动配置类上是否有条件注解,如果有,则进一步判断条件注解所指定的条件当前情况是否满足,如果满足,则继续解析该配置类,如果不满足则不进行解析该配置类,于是配置类所定义的Bean也都得不到解析,那么在Spring容器中就不会存在该Bean。
同理,Spring在解析某个@Bean的方法时,也会先判断方法上是否有条件注解,然后进行解析,如果不满足条件,则该Bean也不会生效。
Spring Boot提供的自动配置,实际上就是Spring Boot源码中预先写好准备了一些常用的配置类,预先定义好了一些Bean,在用Spring Boot时,这些配置类就已经在我们项目的依赖中了,而这些自动配置类或自动配置Bean是否生效,就需要看具体指定的条件是否满足。
下面代码就是根据 @Conditional 确定是否应跳过忽略
/*** Determine if an item should be skipped based on {@code @Conditional} annotations.* @param metadata the meta data* @param phase the phase of the call* @return if the item should be skipped*/public boolean shouldSkip(@Nullable AnnotatedTypeMetadata metadata, @Nullable ConfigurationPhase phase) {if (metadata == null || !metadata.isAnnotated(Conditional.class.getName())) {return false;}if (phase == null) {if (metadata instanceof AnnotationMetadata &&ConfigurationClassUtils.isConfigurationCandidate((AnnotationMetadata) metadata)) {return shouldSkip(metadata, ConfigurationPhase.PARSE_CONFIGURATION);}return shouldSkip(metadata, ConfigurationPhase.REGISTER_BEAN);}List<Condition> conditions = new ArrayList<>();for (String[] conditionClasses : getConditionClasses(metadata)) {for (String conditionClass : conditionClasses) {Condition condition = getCondition(conditionClass, this.context.getClassLoader());conditions.add(condition);}}AnnotationAwareOrderComparator.sort(conditions);for (Condition condition : conditions) {ConfigurationPhase requiredPhase = null;if (condition instanceof ConfigurationCondition) {requiredPhase = ((ConfigurationCondition) condition).getConfigurationPhase();}if ((requiredPhase == null || requiredPhase == phase) &&
// 重点判断
!condition.matches(this.context, metadata)) {return true;}}return false;}以@ConditionalOnBean底层工作原理为示例
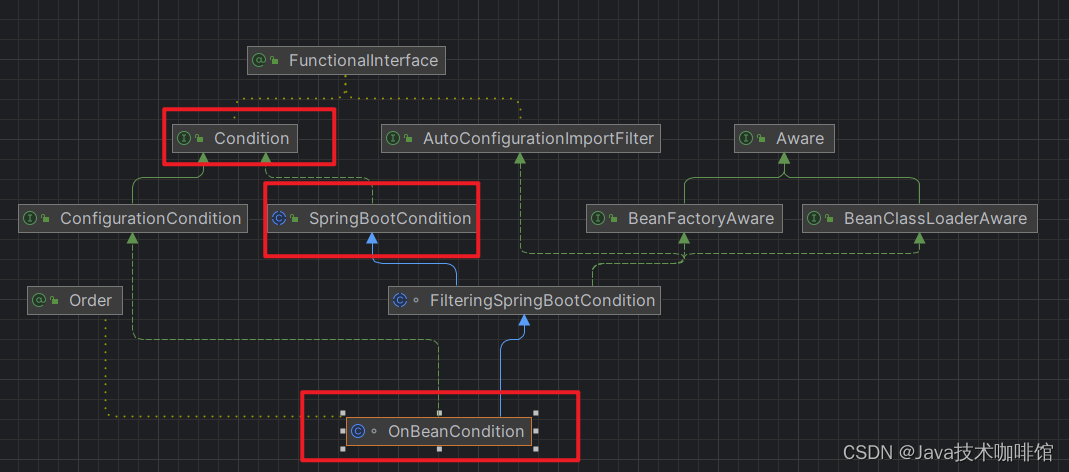
OnBeanCondition类继承了FilteringSpringBootCondition,FilteringSpringBootCondition类又继承SpringBootCondition,而SpringBootCondition实现了Condition接口,matches()方法也是在
SpringBootCondition这个类中实现的:
public abstract class SpringBootCondition implements Condition {private final Log logger = LogFactory.getLog(getClass());@Overridepublic final boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {
// 获取当前解析的类名或方法名String classOrMethodName = getClassOrMethodName(metadata);try {
// 进行具体的条件匹配,ConditionOutcome表示匹配结果ConditionOutcome outcome = getMatchOutcome(context, metadata);
//日志记录匹配结果logOutcome(classOrMethodName, outcome);recordEvaluation(context, classOrMethodName, outcome);
// 返回匹配结果 true/falsereturn outcome.isMatch();}catch (NoClassDefFoundError ex) {throw new IllegalStateException("Could not evaluate condition on " + classOrMethodName + " due to "+ ex.getMessage() + " not found. Make sure your own configuration does not rely on "+ "that class. This can also happen if you are "+ "@ComponentScanning a springframework package (e.g. if you "+ "put a @ComponentScan in the default package by mistake)", ex);}catch (RuntimeException ex) {throw new IllegalStateException("Error processing condition on " + getName(metadata), ex);}}
//....public abstract ConditionOutcome getMatchOutcome(ConditionContext context, AnnotatedTypeMetadata metadata);} 具体的条件匹配逻辑在getMatchOutcome方法中实现的,而SpringBootCondition类中的
getMatchOutcome方法是一个抽象方法,具体的实现逻辑就在子类OnBeanCondition:
@Overridepublic ConditionOutcome getMatchOutcome(ConditionContext context, AnnotatedTypeMetadata metadata) {ConditionMessage matchMessage = ConditionMessage.empty();MergedAnnotations annotations = metadata.getAnnotations();// 如果存在ConditionalOnBean注解if (annotations.isPresent(ConditionalOnBean.class)) {Spec<ConditionalOnBean> spec = new Spec<>(context, metadata, annotations, ConditionalOnBean.class);MatchResult matchResult = getMatchingBeans(context, spec);// 如果某个Bean不存在if (!matchResult.isAllMatched()) {String reason = createOnBeanNoMatchReason(matchResult);return ConditionOutcome.noMatch(spec.message().because(reason));}// 所有Bean都存在matchMessage = spec.message(matchMessage).found("bean", "beans").items(Style.QUOTE, matchResult.getNamesOfAllMatches());}// 如果存在ConditionalOnSingleCandidate注解if (metadata.isAnnotated(ConditionalOnSingleCandidate.class.getName())) {Spec<ConditionalOnSingleCandidate> spec = new SingleCandidateSpec(context, metadata, annotations);MatchResult matchResult = getMatchingBeans(context, spec);if (!matchResult.isAllMatched()) {return ConditionOutcome.noMatch(spec.message().didNotFind("any beans").atAll());}Set<String> allBeans = matchResult.getNamesOfAllMatches();if (allBeans.size() == 1) {matchMessage = spec.message(matchMessage).found("a single bean").items(Style.QUOTE, allBeans);}else {List<String> primaryBeans = getPrimaryBeans(context.getBeanFactory(), allBeans,spec.getStrategy() == SearchStrategy.ALL);if (primaryBeans.isEmpty()) {return ConditionOutcome.noMatch(spec.message().didNotFind("a primary bean from beans").items(Style.QUOTE, allBeans));}if (primaryBeans.size() > 1) {return ConditionOutcome.noMatch(spec.message().found("multiple primary beans").items(Style.QUOTE, primaryBeans));}matchMessage = spec.message(matchMessage).found("a single primary bean '" + primaryBeans.get(0) + "' from beans").items(Style.QUOTE, allBeans);}}// 存在ConditionalOnMissingBean注解if (metadata.isAnnotated(ConditionalOnMissingBean.class.getName())) {Spec<ConditionalOnMissingBean> spec = new Spec<>(context, metadata, annotations,ConditionalOnMissingBean.class);MatchResult matchResult = getMatchingBeans(context, spec);if (matchResult.isAnyMatched()) {String reason = createOnMissingBeanNoMatchReason(matchResult);return ConditionOutcome.noMatch(spec.message().because(reason));}matchMessage = spec.message(matchMessage).didNotFind("any beans").atAll();}return ConditionOutcome.match(matchMessage);}protected final MatchResult getMatchingBeans(ConditionContext context, Spec<?> spec) {ClassLoader classLoader = context.getClassLoader();ConfigurableListableBeanFactory beanFactory = context.getBeanFactory();boolean considerHierarchy = spec.getStrategy() != SearchStrategy.CURRENT;Set<Class<?>> parameterizedContainers = spec.getParameterizedContainers();if (spec.getStrategy() == SearchStrategy.ANCESTORS) {BeanFactory parent = beanFactory.getParentBeanFactory();Assert.isInstanceOf(ConfigurableListableBeanFactory.class, parent,"Unable to use SearchStrategy.ANCESTORS");beanFactory = (ConfigurableListableBeanFactory) parent;}MatchResult result = new MatchResult();Set<String> beansIgnoredByType = getNamesOfBeansIgnoredByType(classLoader, beanFactory, considerHierarchy,spec.getIgnoredTypes(), parameterizedContainers);for (String type : spec.getTypes()) {Collection<String> typeMatches = getBeanNamesForType(classLoader, considerHierarchy, beanFactory, type,parameterizedContainers);typeMatches.removeIf((match) -> beansIgnoredByType.contains(match) || ScopedProxyUtils.isScopedTarget(match));if (typeMatches.isEmpty()) {result.recordUnmatchedType(type);}else {result.recordMatchedType(type, typeMatches);}}for (String annotation : spec.getAnnotations()) {Set<String> annotationMatches = getBeanNamesForAnnotation(classLoader, beanFactory, annotation,considerHierarchy);annotationMatches.removeAll(beansIgnoredByType);if (annotationMatches.isEmpty()) {result.recordUnmatchedAnnotation(annotation);}else {result.recordMatchedAnnotation(annotation, annotationMatches);}}for (String beanName : spec.getNames()) {if (!beansIgnoredByType.contains(beanName) && containsBean(beanFactory, beanName, considerHierarchy)) {result.recordMatchedName(beanName);}else {result.recordUnmatchedName(beanName);}}return result;}getMatchingBeans方法中会利用BeanFactory去获取指定类型的Bean,如果没有指定类型的Bean,则会将该类型记录在MatchResult对象的unmatchedTypes集合中,如果有该类型的Bean,则会把该Bean的beanName记录在MatchResult对象的matchedNames集合中,所以MatchResult对象中记录了哪些类没有对应的Bean,哪些类有对应的Bean。
大概流程如下:
Spring在解析某个配置类,或某个Bean定义时如果发现它们上面用到了条件注解,就会取出所有的条件注解,并生成对应的条件对象,比如OnBeanCondition对象;
依次调用条件对象的matches方法,进行条件匹配,看是否符合条件
条件匹配逻辑中,会拿到@ConditionalOnBean等条件注解的信息,判断哪些Bean存在
然后利用BeanFactory来进行判断
最后只有所有条件注解的条件都匹配,那么当前Bean定义才算符合条件生效
自定义Spring Boot Starter
SpringBoot 最强大的功能就是把我们常用的业务场景抽取成了一个个starter(场景启动器),我们通过引入SpringBoot 提供的这些场景启动器,再进行少量的配置就能使用相应的功能。但是,SpringBoot 不能囊括我们所有的业务使用场景,往往我们需要自定义starter,来简化我们对springboot的使用。
下面是自定义starter的示例代码地址:
lp-springboot-start: 自定义Spring Boot Start
相关文章:
SpringBoot自动配置源码解析+自定义Spring Boot Starter
SpringBootApplication Spring Boot应用标注 SpringBootApplication 注解的类说明该类是Spring Boot 的主配置类,需要运行该类的main方法进行启动 Spring Boot 应用 SpringBootConfiguration 该注解标注表示标注的类是个配置类 EnableAutoConfiguration 直译&#…...

Kafka 环境配置与使用总结
# 部署教程参考 # 官方教程: https://kafka.apache.org/quickstart # 单机部署kafka参考: https://blog.csdn.net/u013416034/article/details/123875299 # 集群部署kafka参考: # https://blog.csdn.net/zhangzjx/article/details/123679453 # https://www.cnblogs.com/And…...

【算法】滑动窗口——串联所有单词的子串
今天来以“滑动窗口”的思想来详解一道比较困难的题目——串联所有单词的子串,有需要借鉴即可。 目录 1.题目2.下面是示例代码3.总结 1.题目 题目链接:LINK 这道题如果把每个字符串看成一个字母,就是另外一道中等难度的题目,即&…...

等保测评安全物理环境测评讲解
等保测评中的安全物理环境测评主要关注信息系统的物理安全保护措施,确保机房、设备和数据的物理安全。以下是安全物理环境测评的关键点讲解: 1. **物理位置选择**: - 机房应选择在具有防震、防风和防雨能力的建筑内。 - 应避免设在建筑…...

TensorRT-llm入门
一、目录 作用TensorRT-llm 为什么快?流程TensorRT-LLM 环境配置大模型 转换、编译与推理如何选择量化类型?lora 大模型如何合并?lora 大模型如何编译,使用?推理加速模型 tensorrRT-LLM、Vllm、fasterTransformer、Be…...

TinyXML-2介绍
1.简介 TinyXML-2 是一个简单、小巧的 C XML 解析库,它是 TinyXML 的一个改进版本,专注于易用性和性能。TinyXML-2 用于读取、修改和创建 XML 文档。它不依赖于外部库,并且可以很容易地集成到项目中。 tinyXML-2 的主要特点包括:…...
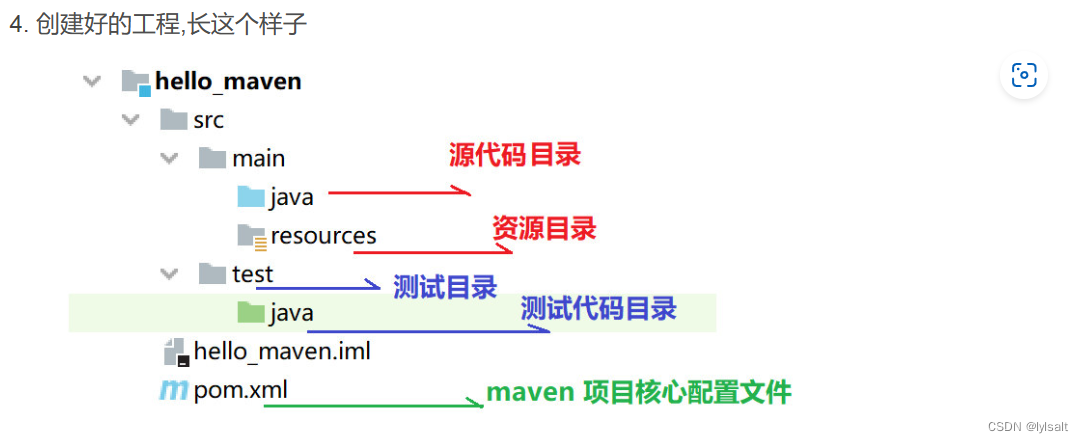
JAVA课程设计
一:Java连接mysql数据库 1.1点击进入mysql jar包下载官网 MySQL :: MySQL Community Downloads 将下载好的压缩包进行解压 解压之后下图就是连接数据库所用到的jar包: 将jar包复制到IDEA所用的项目下,放置jar包的目录为lib,需要…...
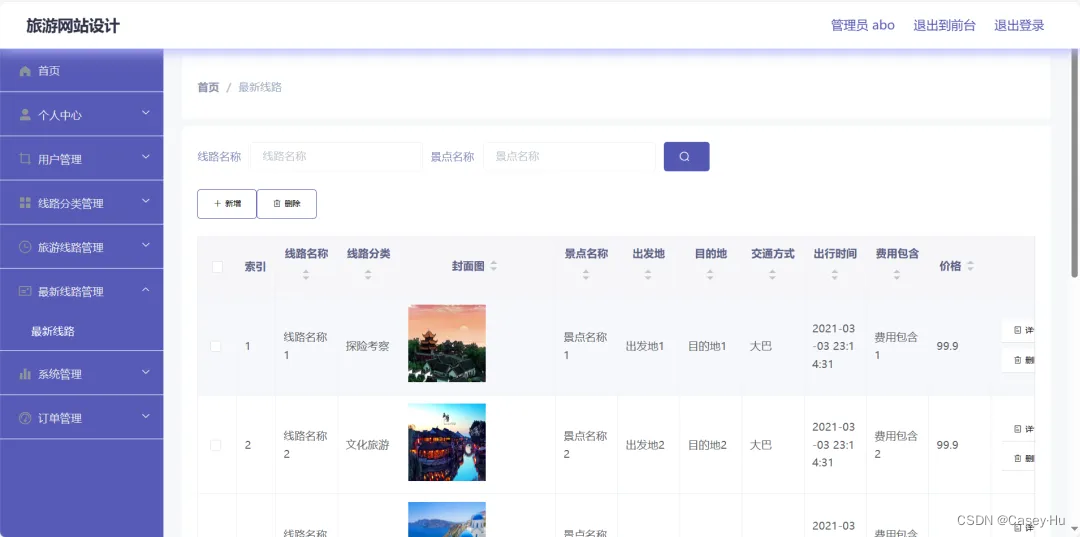
基于SpringBoot+Vue的旅游网站系统
初衷 在后台收到很多私信是咨询毕业设计怎么做的?有没有好的毕业设计参考? 能感觉到现在的毕业生和当时的我有着同样的问题,但是当时的我没有被骗, 因为现在很多人是被骗的,还没有出学校还是社会经验少,容易相信别人…...

http代理ip按流量划算还是个数划算?
随着科技的进步和互联网的发展,越来越多的企业在业务上都需要用到代理,那么http代理ip按流量划算还是个数划算?小编接下来就跟大家介绍一下: 首先我们得先了解http代理ip的按流量模式和个数模式分别是什么: 一、按流…...
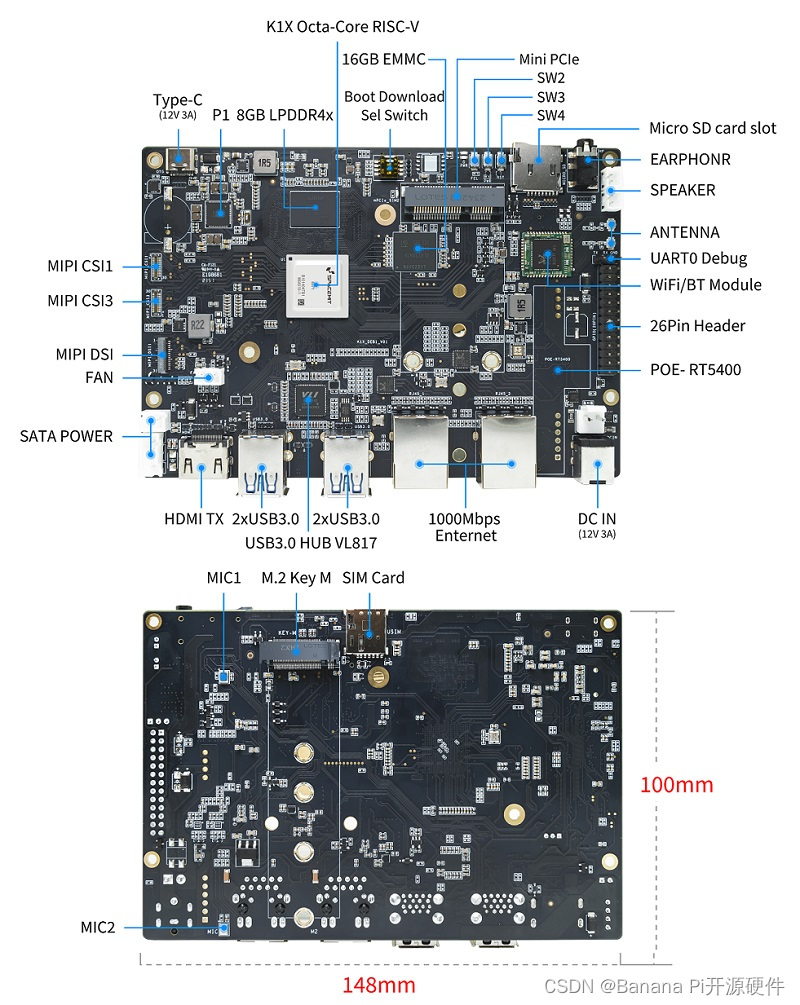
Banana Pi BPI-F3, 进迭时空K1芯片设计,定位工业级应用,网络通信及工业自动化
香蕉派BPI-F3是一款工业级 8核RISC-V开源硬件开发板,它采用进迭时空(SpacemiT) K1 8核RISC-V芯片设计,CPU集成2.0 TOPs AI计算能力。4G DDR和16G eMMC。2个GbE以太网接口,4个USB 3.0和PCIe M.2接口,支持HDM…...

安科瑞工业IT产品及解决方案—电源不接地,设备外壳接地【监测系统对地绝缘电阻】
低压配电系统分类及接地保护方案 国际电工委员会(iec)对各接地方式供电系统的规定规定:(低压:交流1000V以下) 低压配电接地、接零系统分为IT、TT、TN三种基本形式。TN分为TN-C,TN-S,TN-C-S三种…...
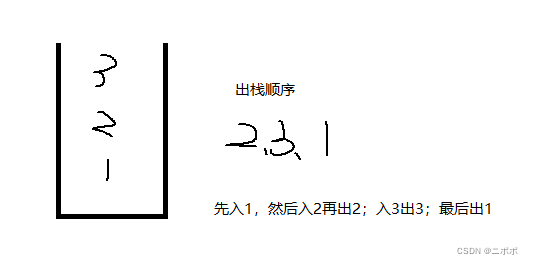
栈:概念与实现
1.概念 压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。出栈:栈的删除操作叫做出栈,出数据也在栈顶。栈的元素遵循后进先出LIFO(Last In First Out)的原则。后面进来的数据先出去 2.栈的实现 三种实现方法,数组…...

【Linux】查找服务器中某个文件的完整路径
方法一: 使用 -wholename 来搜索路径: find / -wholename */esm/data.py这个命令会搜索与 */esm/data.py 完全匹配的路径,其中 * 代表任意数量的任意字符。这应该会找到位于任何目录下的 esm/data.py 文件。 可以限定在某个目录下查找&…...

windows server 2019 安装 docker环境
一、根据官方说明进行安装 , 看起来过程相当简单, 但问题还是有的 准备 Windows 操作系统容器 | Microsoft Learn // 一个 powershell 脚本,该脚本配置环境以启用与容器相关的 OS 功能并安装 Docker 运行时。 Invoke-WebRequest -UseBasicParsing "https://r…...

【Linux】探索 Linux du 命令:管理磁盘空间的利器
给我一个拥抱 给我肩膀靠靠 你真的不需要 对我那么好 思念就像毒药 让人受不了的煎熬 我会迷恋上瘾赖在你怀抱 🎵 陶钰玉《深夜地下铁》 在 Linux 系统管理中,磁盘空间管理是一项基础而重要的任务。du(disk usage&#…...
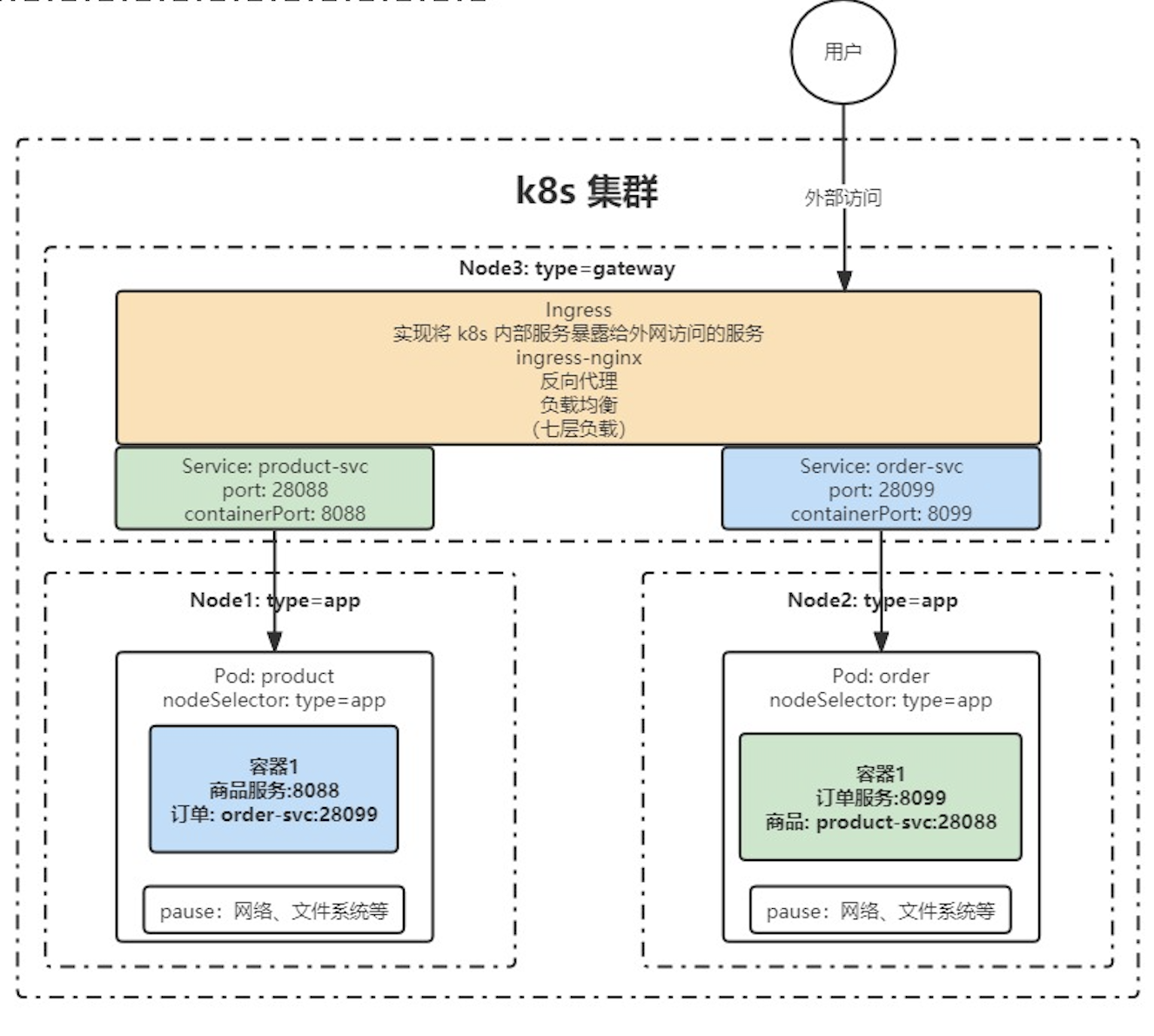
Service 和 Ingress
文章目录 Service 和 IngressServiceEndpointservice 的定义代理集群外部服务反向代理外部域名Service 常用类型 IngressIngress-nginx安装使用 Service 和 Ingress service 和 ingress 是kubernetes 中用来转发网络请求的两个服务,两个服务用处不同,se…...
)
C++(类和对象—封装)
C面向对象的三大特性 封装 继承 多态 C认为万事万物皆为对象,对象上有其属性和行为 什么是封装? 封装是C面向对象三大特性之一 封装的意义: 将属性和行为作为一个整体,表现生活中的事物 将属性和行为加以权限控制封装意义一: …...

如何训练一个大模型:LoRA篇
目录 写在前面 一、LoRA算法原理 1.设计思想 2.具体实现 二、peft库 三、完整的训练代码 四、总结 写在前面 现在有很多开源的大模型,他们一般都是通用的,这就意味着这些开源大模型在特定任务上可能力不从心。为了适应我们的下游任务,…...

Spring Cloud学习笔记(Nacos):基础和项目启动
这是本人学习的总结,主要学习资料如下 - 马士兵教育 1、基础和版本选择2、启动项目2.1、源码启动项目2.2、命令行启动 1、基础和版本选择 Nacos是用于服务发现和注册,是Spring Cloud Alibaba的核心模块。 根据文档,Spring Cloud Alibaba的版…...

音频提取特征
目录 音频提取特征 音频切割 依赖项: pip install librosa pip install transformers 音频提取特征 import librosa import numpy as np import torch from transformers import Wav2Vec2Processorprocessor Wav2Vec2Processor.from_pretrained("faceboo…...

2026 免费在线照片换背景底色怎么做?详细操作方法 + 工具实测
想要快速改变照片背景底色却不知道怎么操作?本文为你盘点了最实用的免费在线照片换背景底色工具,涵盖详细的操作步骤和使用场景,让你轻松搞定各类背景处理需求。为什么需要在线换背景底色?在日常生活中,很多时候我们拍…...
)
告别手动点点点:用pywinauto给微信做个自动化小助手(Python实战)
告别手动点点点:用pywinauto打造微信自动化小助手 微信作为日常高频使用的通讯工具,每天重复的"文件传输助手"转发、消息发送等操作消耗着大量时间。本文将带你用pywinauto构建一个能自动完成这些任务的Python脚本,解放双手的同时深…...

保姆级教程:用ESP32 AT固件实现手机蓝牙配对,从编译到连接一次搞定
ESP32蓝牙开发实战:从固件编译到手机配对的完整指南 在物联网设备开发中,蓝牙连接是最基础也最常用的功能之一。ESP32作为一款高性价比的Wi-Fi/蓝牙双模芯片,凭借其出色的性能和丰富的开发资源,已经成为智能家居、可穿戴设备等领域…...

探索工程图纸的数字化世界:DXF图纸的C++解析及OpenCV绘制
探索工程图纸的数字化世界:DXF图纸的C解析及OpenCV绘制 【下载地址】DXF图纸的C解析及OpenCV绘制 本仓库提供了一套解决方案,用于解析DXF(AutoCAD Drawing Interchange Format)图纸文件,并利用C编程语言结合OpenCV库将…...

JetBrains IDE试用期重置终极指南:三步实现无限开发体验
JetBrains IDE试用期重置终极指南:三步实现无限开发体验 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 还在为JetBrains IDE试用期到期而烦恼吗?ide-eval-resetter是你的理想解决方案&…...

XXMI-Launcher:多游戏Mod管理平台的终极指南
XXMI-Launcher:多游戏Mod管理平台的终极指南 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI-Launcher是一款专为热门游戏设计的Mod管理平台,支持《原…...

CircuitPython内存优化与PyCharm集成:嵌入式开发实战指南
1. 项目概述与核心挑战在嵌入式开发的世界里,CircuitPython以其极低的入门门槛和强大的硬件抽象能力,成为了连接创意与现实的桥梁。无论是驱动一串炫彩的NeoPixel灯带,还是读取传感器数据,CircuitPython都让这一切变得像在桌面Pyt…...

G-Helper深度解析:华硕笔记本的终极轻量级控制方案
G-Helper深度解析:华硕笔记本的终极轻量级控制方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exper…...

原生AI助手架构解析:从上下文感知到本地化部署的工程实践
1. 项目概述:一个“原生”的AI助手意味着什么?最近在GitHub上看到一个挺有意思的项目,叫natively-cluely-ai-assistant。光看这个名字,就透着一股“原教旨主义”的味道。在AI工具满天飞、各种套壳应用层出不穷的今天,一…...

猫抓浏览器扩展完全指南:5步掌握网页视频资源嗅探与下载
猫抓浏览器扩展完全指南:5步掌握网页视频资源嗅探与下载 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过想保存网页上…...