变色龙还是树懒:揭示大型语言模型在知识冲突中的行为
你是知识变色龙还是树懒?我今天在ICLR学到一个很有趣的术语,叫做证据顺序(order of evidence)。
大模型RAG处理知识冲突的探讨:
在检索增强生成(Retrieval-Augmented Generation, RAG)的过程中,技术团队会将检索到的前几名文档作为证据,并提示(prompt)给大型语言模型(Large Language Models, LLMs)。通常提示的顺序是基于余弦相似度(cosine similarity)的:匹配度最高的文档总是最先被提示。
然而,不同的大型语言模型可能对证据的顺序有不同的"偏好":
- ChatGPT偏好排名最前面的证据,这很好。
- GPT-4对证据的顺序没有偏好,这意味着相似度分数并没有被考虑,你只需要决定前K个证据,所有证据都会被平等对待。
- 令人惊讶的是,Llama2和PaLM偏好最后一个证据,所以你需要先反转排名列表,然后再提示给大型语言模型:)
该研究提出一个系统性的框架,用于引出大型语言模型的参数记忆(parametric memory),并构建相应的反记忆(counter-memory)。技术团队设计了一系列检查,如从参数记忆到答案的蕴涵(entailment),以确保引出的参数记忆确实是大型语言模型的内部信念。对于反记忆,该研究没有采用启发式地编辑参数记忆,而是直接指示大型语言模型生成一个与参数记忆在事实上相矛盾的连贯段落。
摘要
通过向大型语言模型(LLMs)提供外部信息,工具增强(包括检索增强)已成为解决LLMs静态参数记忆局限性的一个有前景的解决方案。然而,当外部证据与其参数记忆冲突时,LLMs对这种外部证据的接受程度如何?我们对LLMs在知识冲突下的行为进行了第一次全面和受控的调查。我们提出了一个系统的框架来引出LLMs的高质量参数记忆,并构建相应的反记忆,从而使我们能够进行一系列受控实验。我们的调查揭示了LLMs看似矛盾的行为。一方面,与先前的观点不同,我们发现如果外部证据连贯且令人信服,LLMs可以高度接受外部证据,即使那与它们的参数记忆相矛盾。另一方面,当存在一些与其参数记忆一致的信息时,尽管同时被提供相矛盾的证据,LLMs也表现出强烈的确认偏差。这些结果为进一步开发和部署工具增强型和检索增强型LLMs提出了值得仔细考虑的重要启示。相关资源可在https://github.com/OSU-NLP-Group/LLM-Knowledge-Conflict 找到。

https://arxiv.org/pdf/2305.13300
1 引言
在大规模语料库上预训练后,大型语言模型(LLMs) 已经形成了丰富的参数记忆,例如常识和事实知识。然而,这种参数记忆可能是不准确的或随时间过时,原因是预训练语料库中的错误信息或参数记忆的静态性质,众所周知这是幻觉的主要原因。
工具1或检索增强已成为一个有前景的解决方案,通过向LLMs提供新证据的外部信息,如ChatGPT插件和New Bing。然而,外部证据不可避免地会与LLMs的参数记忆发生冲突。我们将与参数记忆冲突的外部证据称为反记忆。在本文中,我们试图回答以下问题:LLMs对外部证据,尤其是反记忆的接受程度如何?对这一问题有一个扎实的理解是工具增强型LLMs更广泛应用的重要基石。这不仅与克服LLMs静态参数记忆的局限性有关,而且还与直接的安全问题相关。例如,如果第三方工具,无论是开发人员还是被攻击者劫持,故意返回虚假信息会怎样?LLMs会被欺骗吗?
我们对LLMs在遭遇反记忆时的行为进行了第一次全面和受控的调查。构建反记忆的一个关键挑战在于如何构建它。先前的工作采用各种启发式方法,如否定注入和实体替换,发现语言模型(无论是大型还是小型)都倾向于固执己见,坚持自己的参数记忆。然而,这种启发式的词级编辑会导致反记忆不连贯(见第4.1节中的一个例子),这可能使LLMs很容易检测到并因此忽略构建的反记忆。目前尚不清楚先前的结论如何转化为现实场景,在这些场景中,反记忆更加连贯和令人信服。
我们提出了一个系统的框架来引出LLMs的参数记忆,并构建相应的反记忆。我们设计了一系列检查,如从参数记忆到答案的蕴涵,以确保引出的参数记忆确实是LLMs的内部信念。对于反记忆,我们没有启发式地编辑参数记忆,而是指示LLM直接生成一个与参数记忆在事实上相矛盾的连贯段落。
在获得大量参数记忆和反记忆对之后,我们随后检查LLMs在不同的知识冲突场景下的行为,包括1)当只有反记忆作为外部证据时,以及2)当参数记忆和反记忆都存在时。我们的调查得出了一系列有趣的新发现。我们强调以下几点:
-
如果反记忆是唯一以连贯方式呈现的证据,LLMs对外部证据的接受度很高,即使它与其参数记忆相矛盾。这与先前的观点相矛盾(Longpre et al., 2021),我们将其归因于我们的框架构建的更连贯、更有说服力的反记忆。另一方面,这也表明LLMs可能很容易受到误导,例如来自恶意(第三方)工具的虚假信息。
-
然而,当参数记忆的支持证据和与之矛盾的证据共存时,LLMs表现出强烈的确认偏差(Nickerson, 1998),倾向于坚持其参数记忆。这揭示了LLMs在公正协调多个可能相互矛盾的证据方面可能面临的挑战,这是生成式搜索引擎常见的情况。
2 相关工作
语言模型中的参数记忆
在预训练之后,语言模型已经将大量知识内化到它们的参数中,也称为参数记忆。许多过去的研究探索了语言模型中参数记忆的引出,例如常识或事实知识探测。这种参数记忆可以帮助解决下游任务。然而,先前的工作发现,由于模型有限的记忆能力,语言模型只记住了预训练过程中所接触到的知识的一小部分。此外,参数记忆可能会过时。这种不正确和过时的参数记忆可能表现为幻觉。尽管提出了一些编辑语言模型中知识的方法,但它们通常需要对模型权重进行额外的修改,而不评估对模型其他方面的影响,如性能,并且仅限于事实知识。
工具增强型语言模型 为了解决参数记忆的局限性,外部工具如检索器被用于使用最新信息增强语言模型,即工具增强或检索增强语言模型。这种框架在增强大型语言模型方面的有效性已得到证明,并在New Bing和ChatGPT插件等现实世界的应用中得到采用。不可避免地,外部证据可能与参数记忆冲突。然而,LLMs在知识冲突情况下的行为仍有待探索,揭示它对于工具增强型LLMs的更广泛应用具有重要意义。
知识冲突 为了进行受控实验,知识冲突通常通过在参数记忆的基础上构建反记忆来模拟。以前的工作开发了启发式的反记忆构建方法,如否定注入。此外,实体替换用其他实体替换参数记忆中的所有答案实体提及,以构建反记忆。然而,这些方法仅限于词级编辑,导致反记忆的整体连贯性较低。相比之下,我们指示LLMs从头开始生成反记忆,以确保高连贯性。
3 实验设置
在本节中,我们描述了引出LLMs的高质量参数记忆、构建相应反记忆以及评估指标的框架。
3.1 数据集
继先前工作 ,我们采用问答(QA)任务作为知识冲突实验的测试平台。除了一个以实体为中心的QA数据集(POPQA),我们还包括一个多步推理数据集(STRATEGYQA)以增加研究中的问题的多样性。具体来说,
-
POPQA (Mallen et al., 2022) 是一个以实体为中心的QA数据集,包含14K个问题。POPQA的数据源自Wikidata的三元组。作者采用自定义模板, 根据关系类型构建问题,通过替换知识三元组中的主语来构建问题。POPQA根据与问题中提到的实体相关的每月Wikipedia页面浏览量来定义问题的流行度。
-
STRATEGYQA (Geva et al., 2021) 是一个多步事实推理基准,需要将问题隐式分解为推理步骤。问题围绕Wikipedia术语构建,涵盖了广泛的策略,需要模型有效地选择和整合相关知识的能力。语言模型需要提供一个True或False的答案。
3.2 参数记忆引出
图1中的步骤1说明了我们如何引出参数记忆:在封闭书问答方式下,LLMs在没有任何外部证据的情况下回忆其参数记忆来回答问题。具体来说,对于一个问题,例如"谁是Google DeepMind的首席科学家",LLMs被指示提供一个答案"Demis Hassabis"及其支持的背景信息,详细说明Demis如何创立和领导DeepMind。我们将详细的背景作为参数记忆,因为答案只代表了参数记忆对给定问题的结论。

表1显示了LLMs在POPQA和STRATEGYQA上的封闭书结果。值得注意的是,当上下文中没有提供任何证据时,LLMs可能会回应"Unknown",特别是在ChatGPT中。这种答案弃权表明 LLMs未能回忆起与给定问题相关的有效记忆,因此我们将其丢弃。为了全面起见,我们还保留了 LLMs在封闭书范式中回答错误的样本,因为错误的答案和相关记忆也存储在模型参数中。
3.3 反记忆构建
如图1所示,在第2步中,我们将记忆答案"Demis Hassabis"重新构建为反答案(例如"Jeff Dean")。具体来说,对于POPQA,我们用同类型的实体替换记忆答案中的实体(例如,从Demis到Jeff);而在STRATEGYQA中,我们翻转记忆答案(例如,从肯定句到否定句)。有了反答案"Jeff Dean",我们指示ChatGPT2编造支持Jeff Dean担任DeepMind首席科学家的证据。我们将与参数记忆相矛盾的这种证据称为反记忆。
由于反记忆是由强大的生成型LLMs从头生成的,与先前基于词级编辑的方法相比,它更加连贯。生成的参数记忆和反记忆都可以作为后续LLMs知识冲突实验的外部证据。请参考附录B.1了解每个数据集中证据构建的更多细节。
3.4 答案-证据蕴涵检查
理想的证据应该强烈支持其答案。例如,关于Demis和DeepMind的参数记忆应该清楚地支持相应的记忆答案,即Demis是DeepMind的首席科学家。同样,反记忆也应该清楚地支持相应的反答案。因此,对于图1中所示的步骤3,我们利用自然语言推理(NLI)模型进行支持检查,以确保证据确实蕴含答案。具体来说,我们使用最先进的NLI模型DeBERTa-V23来确定参数记忆和反记忆是否都支持它们各自的答案。我们只保留两个答案都支持的样本用于后续实验。
为了确保所选NLI模型的可靠性,我们手动评估了200个随机样本,观察到该模型的准确率为99%。更多细节请参考附录B.5。
3.5 记忆答案一致性
我们采用另一项检查(图1的步骤4)进一步确保数据质量。如果我们引出的参数记忆确实是LLM的内部信念,将其明确地作为证据呈现应该使LLM提供与封闭书设置(步骤1)中相同的答案。因此,在基于证据的QA任务格式中,我们使用参数记忆作为唯一证据,并指示LLMs再次回答同一个问题。例如,给定关于Demis和DeepMind的参数记忆,LLMs应该有一个与先前记忆答案一致的响应,即Demis是DeepMind的首席科学家。

然而,表3中的答案不一致结果表明,当在步骤1中获得的参数记忆被明确呈现为证据时,LLMs可能仍会改变其答案。这表明LLM对这个参数记忆的内部信念可能并不坚定(例如,基于LLM,可能存在同样合理的竞争答案)。我们过滤掉此类样本,以确保剩余的样本能很好地捕捉LLM的坚定参数记忆。
经过蕴涵和答案一致性检查后,剩余的样本可能代表坚定的参数记忆和高质量的反记忆,为后续的知识冲突实验奠定了坚实的基础。表2显示了最终POPQA数据中的一些样本,表4显示了最终数据集的统计信息。关于步骤3和4的更多细节和样本,请参阅附录B.2。
3.6 评估指标
LLM的单个生成可能同时包含记忆答案和反答案,这对自动确定LLM的确切答案构成挑战。为了解决这个问题,我们将自由形式的QA转换为多项选择QA格式,提供几个选项作为可能的答案。这限制了生成空间,并有助于确定LLMs提供的答案。具体而言,对于来自两个数据集的每个问题,LLMs被指示从记忆答案(Mem-Ans.)、反答案(Ctr-Ans.)和"不确定"中选择一个答案。此外,为了量化LLMs坚持其参数记忆的频率,我们采用记忆率指标:
M R = f r a c f m f m + f c M R=frac{f_m}{f_m+f_c} MR=fracfmfm+fc
(1)
其中 f m f_m fm是记忆答案的频率, f c f_c fc是反答案的频率。记忆率越高,表示LLMs越依赖其参数记忆,而记忆率越低则表明更频繁地采用反记忆。
4 实验
4.1 单一来源证据
我们在单一来源证据设置下对LLMs进行实验,其中反记忆是呈现给LLMs的唯一证据。当LLMs使用返回单一外部证据(如Wikipedia API)的工具增强时,会发生此类知识冲突。特别是对于反记忆构建,我们将应用1)实体替换反记忆方法,这是之前工作中广泛应用的策略,以及2)我们基于生成的方法。
当遇到基于实体替换的反记忆时,LLMs很固执。继先前工作,我们用同类型的随机实体替换参数记忆中完全匹配的ground truth实体提及。然后将反记忆作为唯一证据供LLMs回答问题。这里有一个例子:
证据:华盛顿特区伦敦,美国的首都,有华盛顿纪念碑。
问题:美国的首都是哪里?ChatGPT的回答:华盛顿特区。

图2显示了在POPQA数据集上使用这种方法的结果。显然,尽管指令明确指导LLMs根据给定的反记忆回答问题,但LLMs仍然坚持自己的参数记忆,尤其是三个封闭源LLMs(ChatGPT、GPT-4和PaLM2)。这一观察结果与先前的工作一致。原因可能源于基于替换构建的证据的不连贯性:在给定的例子中,尽管"Washington D.C.“成功替换为"London”,但包含Washington Monument和USA的上下文仍然与原始实体高度相关,阻碍了LLMs生成London作为答案。此外,当比较Llama2-7B和Vicuna-7B与同系列的较大模型(即Llama2-70B和Vicuna-33B)时,我们观察到较大的LLMs更倾向于坚持其参数记忆。我们假设,由于记忆和推理能力的增强,较大的LLMs对不连贯的句子更敏感。
LLMs对生成的连贯反记忆的接受度很高。为了缓解上述反记忆的不连贯性问题,我们指示LLMs直接生成连贯的反记忆,遵循前面提到的步骤(图1)。图2显示了使用基于生成的反记忆的实验结果,我们可以得到以下观察结果:
首先,如果以连贯的方式呈现,即使与其参数记忆相矛盾,LLMs实际上对外部证据的接受度很高。这与先前的结论和图2所示的实体替换反记忆的观察结果相矛盾。这种高接受性反过来表明,通过我们的框架构建的反记忆确实更加连贯和令人信服。我们手动检查了50个固执(即"Mem-Ans.")案例,发现其中大多数是由于反记忆中的歧义、导致无法接受反记忆的常识问题或高度暗示性的问题。详细分析见附录B.3。
其次,许多生成的反记忆都是误导LLMs产生错误答案的虚假信息。令人担忧的是,LLMs似乎容易受到这种虚假信息的欺骗。探索在使用外部工具时防止LLMs遭受此类攻击的方法值得在未来研究中给予重点关注。
第三,我们生成的反记忆的有效性也表明,LLMs可以生成令人信服的虚假或错误信息,足以误导自己。这引发了对LLMs潜在误用的担忧。
4.2 多源证据
多源证据是一种情况,其中呈现给LLMs的多个证据要么支持要么与参数记忆相矛盾。当LLMs与具有多样化甚至网络规模信息源的搜索引擎相结合时,这种知识冲突可能经常发生。我们从证据的不同方面研究LLMs的证据偏好,包括流行度、顺序和数量。默认情况下,如果未特别说明,第4.2节中所有实验中的证据顺序都是随机的。
LLMs在更流行的知识中表现出更强的确认偏差。图1中的步骤5说明了当参数记忆和反记忆都作为证据呈现时,我们如何指示LLMs回答问题。图3显示了不同LLMs关于POPQA上问题流行度的记忆率。
首先,与仅将生成的反记忆作为证据(单一来源)相比,当参数记忆也作为证据提供时(多源),LLMs都表现出明显更高的记忆率,尤其是GPT-4。换言之,当面临相互矛盾的证据时,LLMs经常偏好与其内部信念(参数记忆)一致的证据,而不是相矛盾的证据(反记忆),表现出强烈的确认偏差。这种特性可能会阻碍工具增强型LLMs对外部证据的公正使用。
其次,对于涉及更受欢迎实体的问题,LLMs表现出更强的确认偏差。特别是,GPT-4对最受欢迎的问题显示出80%的记忆率。这可能表明,LLMs对更受欢迎实体的事实形成了更强的信念,可能是因为它们在预训练期间更频繁地看到这些事实和实体,从而导致更强的确认偏差。
LLMs对证据顺序表现出明显的敏感性。先前的工作已经表明,工具增强型语言模型倾向于选择呈现在首位的证据,以及LLMs中的顺序敏感性。为了揭示证据呈现顺序对LLMs的影响,我们分别将参数记忆和反记忆放在多源设置中的第一个证据位置。作为参考,表5也报告了从两者中随机选择第一个证据的结果。与流行度实验一致,使用相同的LLMs。
该研究观察到,除了GPT-4之外,其他模型都表现出明显的顺序敏感性,波动幅度超过5%。特别令人担忧的是,PaLM2和Llama2-7B的变化超过30%。当证据首先呈现时,ChatGPT倾向于偏好它;然而,PaLM2和Llama2-7B倾向于后面的证据。这种对上下文中证据的顺序敏感性可能不是工具增强型LLMs的理想特性。默认情况下,本节中其他实验中的证据顺序是随机的。
LLMs随大流,选择有更多证据支持的一方。除了LLM生成的证据(参数记忆和反记忆),还扩展到人工制作的证据,如Wikipedia。这些高度可信和容易获取的人工撰写文本很可能被真实世界搜索引擎工具检索为证据。采用POPQA提供的Wikipedia段落,并对STRATEGYQA的人工标注事实进行后处理,以确保可以推断出正确答案。请参阅附录B.4了解更多处理细节。

为了平衡支持记忆答案和反答案的证据数量,我们通过第3.3节中提到的方法创建额外的证据,目标是在参数记忆和反记忆证据之间最多实现2:2的平衡分割。表6显示了在参数记忆一致证据和反记忆之间不同比例下的记忆率。我们有三个主要观察结果:1)LLMs通常提供由大多数证据支持的答案。支持特定答案的证据比例越高,LLMs返回该答案的可能性就越大。2)随着参数记忆证据数量的增加,确认偏差变得越来越明显,尽管保持了一致的相对比例(例如, f r a c 12 frac{1}{2} frac12 vs. f r a c 24 frac{2}{4} frac24。3)与其他LLMs相比,GPT-4和Vicuna-33B在所有证据比例下对反记忆的接受度较低。特别是,无论有更多的证据支持反答案(比例 f r a c 13 frac{1}{3} frac13),这两个模型仍然明显地坚持自己的参数记忆。这些观察结果再次表明了LLMs中存在的确认偏差。
LLMs会被无关证据分散注意力。进一步实验了更复杂的知识冲突场景。感兴趣的问题是:如果向LLMs呈现无关证据会怎样?当呈现无关证据时,LLMs应该1)如果没有证据明确支持任何答案,则避免回答;2)忽略无关证据,根据相关证据回答问题。为了设置,将Sentence-BERT嵌入检索到的与问题相关性最高的无关段落视为无关证据(即与问题中显示的实体无关的句子)。POPQA上的实验结果如表7所示。发现:1)仅提供无关证据时,LLMs会被它们分散注意力,提供无关答案。而且这个问题在Llama2-7B中尤其令人担忧。同时,随着引入更多无关证据,LLMs不太可能根据其参数记忆回答。2)同时提供相关和无关证据时,LLMs可以在一定程度上过滤掉无关证据。这一观察结果与Shi等人(2023a)关于LLMs如何在数学问题中被无关上下文分散注意力的研究一致。此外,发现随着无关证据数量的增加,这种能力会降低,尤其是在Llama2-7B的情况下。

5 结论
在这项工作中,提出了一个系统的框架来引出LLMs的参数记忆,构建相应的反记忆,并设计一系列检查以确保其质量。将这些参数记忆和反记忆作为外部证据,我们模拟全面的场景作为受控实验,以揭示LLMs在知识冲突下的行为。发现当反记忆以连贯的方式作为唯一证据呈现时,LLMs对其高度接受。然而,当参数记忆的支持证据和与之矛盾的证据都存在时,LLMs也表现出对参数记忆的强烈确认偏差。此外,表明LLMs的证据偏好受到证据的流行度、顺序和数量的影响,这些都可能不是工具增强型LLMs所希望的特性。最后,框架的有效性也证明了LLMs可以生成令人信服的错误信息,这带来了潜在的道德风险。希望为未来理解、改进和部署工具增强型LLMs提供一个可靠的评估基准和有用的见解。
可重复性声明
实验利用了三个通过API访问的封闭源LLMs,以及五个开源的LLMs。为了提高可重复性,我们在附录C中包含了实验中使用的提示。关于封闭源LLMs的版本,我们在所有测试中使用了ChatGPT-0301、GPT-4-0314和PaLM2的Chat-Bison-001。
参考文献
略
附录
A 讨论
A.1 更广泛的影响和潜在的解决方案
我们观察到LLMs在知识冲突中的两种行为:(1)对单一外部证据的高接受性和(2)对多个外部证据的确认偏差,我们将详细讨论其影响和潜在的解决方案。
首先,高接受性是一把双刃剑。一方面,它意味着可以有效地补救LLMs的过时或不正确的参数知识,这对于检索增强生成等方法是有益的。另一方面,随着LLMs越来越多地与外部工具连接,例如ChatGPT插件和最近的语言代理如AutoGPT,高度接受外部输入引起了担忧——LLMs可能很容易被来自恶意第三方工具的误导或操纵信息所欺骗。
确认偏差是一个非常不受欢迎的特性,特别是对于生成式搜索引擎或LLMs的类似应用(例如多文档摘要),在这些应用中,以公正的方式协调多个可能相互矛盾的信息非常重要。
在潜在的解决方案方面,对于高接受性带来的风险,应该采用验证和监控系统,以防止第三方工具向LLMs提供不当信息。对于确认偏差,根据部署场景,通过微调或人类反馈强化学习(RLHF)进一步调整以减少偏差可能是一个有前景的方向。最后,从生成式搜索引擎的角度来看,引用答案的来源并让用户更加知情,并判断最终答案,可能是一种更可靠的方式。
A.2 额外的知识冲突讨论

图A.1:报告了ChatGPT在分割证据前后的证据偏好变化。OthersToWhole表示ChatGPT现在偏好支持不同答案的完整证据,这与分割之前的偏好不一致。
图A.2:不同参数记忆和反记忆长度比下ChatGPT的回答分布。
LLMs很少考虑简短的反记忆,而它们采用任何长度的参数记忆。作为说服力的代表,证据的长度可能会影响LLMs的偏好。为了验证这一点,我们根据参数记忆和反记忆之间的长度比将样本分类,即<0.8、>1.2和[0.8, 1.2],这些在数据样本中是可区分的。
图A.2显示了每个类别内的答案分布。很明显,ChatGPT倾向于采用较长的一方,特别是在STRATEGYQA中,较长的证据通常表示更多的推理步骤。
为了探索证据长度的最大影响,进一步探索极短证据的场景。具体来说,将答案直接作为证据呈现给LLMs,并研究它们是否在没有任何具体解释的情况下采用这种简短证据。交替将参数记忆或反记忆替换为它们各自支持的答案,同时保持另一个不变。这导致记忆答案vs.反记忆和反答案vs.参数记忆。表A.1显示了POPQA的结果:较短的反记忆证据(反答案)不太可能被LLMs考虑(从56.7%到18.8%)。然而,将参数记忆证据缩短为记忆答案并不会影响LLMs的偏好;有趣的是,LLMs甚至更偏好它(从42.7%到43.9%)。换句话说,说服LLMs接受反记忆需要信息丰富且可靠的证据。相比之下,与参数记忆一致的简短证据对LLMs来说已经足够可以接受,因为相关的记忆已经编码在参数中。这一观察表明,我们引出的参数记忆可能很好地捕捉了LLMs的坚定信念。更重要的是,这种对证据的不平等接受性进一步凸显了LLMs中存在强烈确认偏差,当它们用于工具增强型应用时,这可能是一个潜在的重大局限性。

LLMs在信息整合方面表现出缺陷。在现实场景中,复杂的查询可能需要从不同来源收集的片段化证据才能得到最终答案。作为一个多步推理数据集,STRATEGYQA为这种探索提供了理想的样本数据集。
在标准模式下,合并这些事实以构建一个完整的证据片段。然而,在这种设置中,将每个事实视为一个单独的证据,没有任何合并。图A.1的结果清楚地表明:在ChatGPT使用的原始证据(参数记忆或反记忆)被分割后,ChatGPT在38.2%的样本中转而考虑另一个完整的证据(反记忆或参数记忆),表明LLMs整合证据片段的能力有限。这一观察结果还表明,在工具增强型系统中,不同格式(分散或整体)的相同外部证据可能对LLMs产生不同的影响。因此,从外部工具的角度来看,未来值得探索以LLMs易于使用的格式呈现证据。
LLMs对自己的回应充满信心。除了观察文本回应外,我们还研究了LLMs对自己回应的信心程度。以Llama2-7B为案例研究,我们报告了它生成的token的对数概率,在表示记忆答案、反答案和不确定的三个token上进行归一化。具体来说,我们主要探索两种场景:

-
首先,在反记忆作为唯一证据的单源设置中,从Llama2-7B给出反答案的1000个样本中采样。在图A.3中,Llama2-7B在生成反答案时表现出高度自信,91.3%的样本的记忆答案概率为95%或更高。这表明了对外部证据的高度接受性,即使它与LLM的参数记忆相矛盾。
-
其次,在呈现两个支持证据和两个矛盾证据的多源场景中,我们从Llama2-7B偏好反答案的1000个实例中采样。图A.4显示,基于token对数概率,Llama2-7B对其记忆答案响应充满信心。例如,96.3%的样本显示反答案的对数概率为95%或更高。使用与记忆一致的证据的高频率(表6中的65%)和高置信度都表明LLMs可能存在确认偏差。
B 实验设置细节
B.1 反记忆构建细节
为了构建高质量的反记忆,我们引入ChatGPT作为生成器,以生成人类书写水平的文本。具体来说,首先重新构建记忆答案以构建反答案。对于不同的数据集,采用不同的策略。
由于POPQA是一个以实体为中心的QA数据集,采用以下原则:(i)如果记忆答案是错误的,直接采用POPQA提供的三元组。(ii)如果记忆答案是正确的,用来自ground truth的同一关系的实体替换三元组中的对象实体(同一关系类别中的对象具有一致的实体类型)。应用基于精确匹配的过滤器,以防止所选实体与候选ground truth之间的任何重叠。随后,使用模板根据三元组生成自然语言格式的主张。
考虑到STRATEGYQA的输出是"True"或"False",它不能直接用作主张。因此,使用ChatGPT分别生成对应于"True"和"False"的两个主张。根据输出,动态地将生成的主张分类为记忆答案和反答案。为了确保高质量和控制格式,我们采用上下文学习策略,使用三个演示。
获得反答案后,我们指示ChatGPT生成反记忆。
B.2 数据集细节

表B.3展示了每个步骤的数据集规模。我们还在表B.5中报告了不一致类型的分布情况。表B.6展示了一些LLMs在答案不一致方面的示例。在表B.7中,我们展示了最终数据集中的更多样本。
B.3 固执于参数记忆的回应示例
在表B.8中,我们展示了一些即使在只给出反记忆证据的情况下,LLMs仍然固执地给出记忆答案的例子。通过人工仔细审查50个随机选择的样本,我们发现其中34个例子是由于反记忆中的歧义、导致无法接受反记忆的常识问题或高度暗示性的问题。这意味着只有一小部分LLMs在单源设置下对参数记忆表现出固执,再次证实了LLMs在此设置下保持开放。
B.4 人工撰写证据的处理
尽管POPQA数据集中提供了检索到的Wikipedia段落,但并非所有问题都有高质量的推理段落(即包含ground truth)。对于这些实例,我们从Wikipedia重新获取相关段落,确保其包含ground truth。然而,即使在Wikipedia上,也有一小部分数据(约400个实例)缺乏推理段落。对于这个数据子集,我们使用来自Wikidata的相应三元组,由ChatGPT生成自然语言文本。
至于STRATEGYQA,其中的事实是人工编写的,确保每个事实都支持ground truth,因此不需要额外的修改。
B.5 NLI模型准确性的人工评估细节
为了确保实验中使用的合成证据的质量,我们使用最先进的自然语言推理(NLI)模型来过滤掉不太合格的样本。为了估计NLI模型用于此目的的有效性,我们随机抽取200个生成的样本,并手动标注生成的内容(包括参数记忆和反记忆)是否蕴含相应的主张(记忆答案和反答案)。标签为支持(NLI任务中的蕴含)或不支持(NLI任务中的中性或矛盾)。然后我们在这个数据集上评估最先进的NLI模型,并计算其准确性。

B.6 LLMs在知识冲突下的不确定答案比率
在表B.4中,我们报告了LLMs在遇到多个证据时的不确定答案比率。我们观察到,三个封闭源语言模型在面临知识冲突时倾向于表现出不确定性。

B.7 无关证据
我们从人工语料库(即POPQA提供的Wikipedia段落)中为问题收集无关证据。具体来说,我们使用SentenceBERT检索与问题相似度最高的前3个句子。我们将搜索范围限制在相同问题类型的数据内。请注意,我们排除了任何包含参数记忆或反记忆中提到的实体的证据,因为它会影响我们选项的安排。构建无关证据选项的方法基于表B.2中提供的模板。

B.8 分散的证据
STRATEGYQA数据集结合了与每个子问题相关的人工编写的事实。在标准模式下,我们合并这些事实以构建一个完整的证据片段。然而,在A.2节中,我们将每个事实视为一个单独的证据,没有任何合并。

C 提示列表
在表C.9中,我们提供了本研究中使用的所有提示的完整列表,为理解我们的实验方法提供了清晰的参考。

简要总结一下这篇论文的主要内容:
这篇论文研究了大型语言模型(LLMs)在面对外部知识与其内部记忆相矛盾时的行为反应。作者设计了一个系统化的实验,通过构建高质量的参数记忆和与之矛盾的反记忆,考察了不同场景下LLMs的表现。
主要发现包括:
如果反记忆是唯一呈现的、足够连贯有说服力的外部证据,LLMs会高度接受,即使那与其内部记忆相矛盾。这说明LLMs可能容易被误导性信息欺骗。
但当同时存在支持和反对其内部记忆的外部证据时,LLMs会表现出强烈的确认偏差,倾向于坚持自己原有的记忆。这可能妨碍LLMs公正地处理相互矛盾的信息。
LLMs对证据的偏好还受到证据的流行度、顺序、数量等因素影响,这些并非理想特性。
实验表明LLMs能生成令人信服的虚假信息,这带来潜在的滥用风险。
这项研究系统地考察了知识冲突下LLMs的行为表现,揭示了一些值得关注的问题,为今后开发和部署工具增强型LLMs提供了有益启示。作者呼吁研究界和业界共同应对LLMs可能被滥用的风险。
我认为这是一篇有重要参考价值的论文,对于理解和改进LLMs在知识整合等方面的能力很有帮助。同时文中提出的实验框架,为后续在这一方向的研究提供了思路。
个人观感
首先,正如你所指出的,该研究揭示了当前这类模型在处理外部证据时存在的一些问题,如确认偏差和对不一致证据的处理能力不足等。这提醒我们在开发和部署此类系统时需要格外谨慎,并持续优化其知识融合机制。未来的研究可以探索如何减少偏差,提高鲁棒性,设计更加先进可靠的算法。
其次,你提到了大型语言模型潜在的道德风险,这一点非常关键。由于其强大的生成能力,如果被恶意利用,可能产生令人信服但错误有害的信息,造成严重的负面影响。因此从业者必须高度重视这一风险,并采取必要的应对措施,如加强数据规范、模型管控和可解释性等。这需要研究界、业界乃至整个社会的共同努力。
最后,工具增强型大型语言模型作为一个新兴方向,其发展前景广阔但仍存在诸多不确定性。正如你所言,一方面要充分发掘其在问答、对话、知识图谱等领域的应用潜力,不断拓展场景、优化性能;另一方面也要高度关注其发展动向,评估可能带来的社会影响,未雨绸缪。这需要我们保持开放、审慎、负责任的态度。
这项研究虽聚焦于一个具体问题,但反映了当前工具增强型大型语言模型所面临的一些普遍挑战。它启发我们在追求模型能力提升的同时,也要兼顾其可控性、可解释性和伦理属性,这对于该领域的长远发展至关重要。未来的研究可以在这些发现的基础上,进一步探索模型改进、风险防控和价值对齐等问题,推动工具增强型大型语言模型在造福社会的同时,尽可能降低其负面影响。这需要多方携手,共同努力。
相关文章:
变色龙还是树懒:揭示大型语言模型在知识冲突中的行为
你是知识变色龙还是树懒?我今天在ICLR学到一个很有趣的术语,叫做证据顺序(order of evidence)。 大模型RAG处理知识冲突的探讨: 在检索增强生成(Retrieval-Augmented Generation, RAG)的过程中,技术团队会将检索到的前几名文档作为证据,并提示(prompt)给大型语言模型(Large La…...
OMX Core)
Android OpenMAX(四)OMX Core
假设我们已经写好了所有的OMX组件,有vdec、venc、adec、aenc,接下来问题来了,我们应该如何管理这些组件呢(创建、销毁)?这一篇文章我们向上一层学习OMX Core提供的标准API。 OMX Core代码位于 OMX_Core.h OMX Core在OpenMAX IL架构中的位置位于IL Client与实际的OMX组件之…...

【Linux】轻量级应用服务器如何开放端口 -- 详解
一、测试端口是否开放 1、测试程序 TCP demo 程序(可参考:【Linux 网络】网络编程套接字 -- 详解-CSDN博客) 2、测试工具 Windows - cmd 窗口 输入命令:telnet [云服务器的公网ip] [port] 二、腾讯云安全组开放端口 1、安全组设…...

git如何查看密码
git查看用户名、邮箱 git config user.name git config user.email 也可以在系统,用户文件夹下面 gitconfig查看 通常无法查看git密码,运行以下命令 git config credential.helper 查看储存的方式,如果是manage 或manage-store则说明是…...

redis脑裂问题
1. 前言 脑裂就是指在主从集群中,同时有两个主节点,它们都能接收写请求。而脑裂最直接的影响,就是客户端不知道应该往哪个主节点写入数据,结果就是不同的客户端会往不同的主节点上写入数据。而且,严重的话,…...

日本率先研发成功6G设备,刺痛了谁?为何日本能率先突破?
日本率先研发成功6G设备,无线数据速率是5G的百倍,这让日本方面兴奋莫名,毕竟日本在科技方面从1990年代以来太缺少突破的创新了,那么日本为何如今在6G技术上能率先突破呢? 日本在1980年代末期达到顶峰,它的科…...
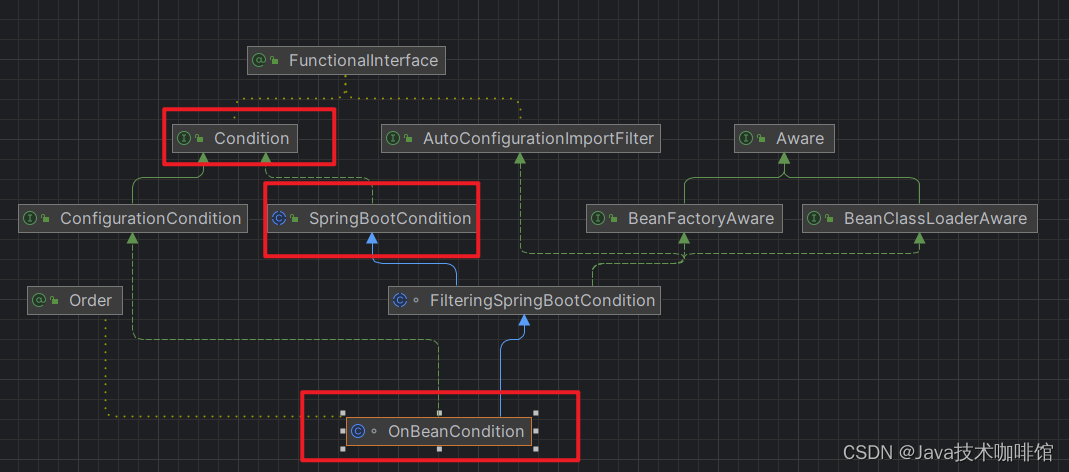
SpringBoot自动配置源码解析+自定义Spring Boot Starter
SpringBootApplication Spring Boot应用标注 SpringBootApplication 注解的类说明该类是Spring Boot 的主配置类,需要运行该类的main方法进行启动 Spring Boot 应用 SpringBootConfiguration 该注解标注表示标注的类是个配置类 EnableAutoConfiguration 直译&#…...

Kafka 环境配置与使用总结
# 部署教程参考 # 官方教程: https://kafka.apache.org/quickstart # 单机部署kafka参考: https://blog.csdn.net/u013416034/article/details/123875299 # 集群部署kafka参考: # https://blog.csdn.net/zhangzjx/article/details/123679453 # https://www.cnblogs.com/And…...

【算法】滑动窗口——串联所有单词的子串
今天来以“滑动窗口”的思想来详解一道比较困难的题目——串联所有单词的子串,有需要借鉴即可。 目录 1.题目2.下面是示例代码3.总结 1.题目 题目链接:LINK 这道题如果把每个字符串看成一个字母,就是另外一道中等难度的题目,即&…...

等保测评安全物理环境测评讲解
等保测评中的安全物理环境测评主要关注信息系统的物理安全保护措施,确保机房、设备和数据的物理安全。以下是安全物理环境测评的关键点讲解: 1. **物理位置选择**: - 机房应选择在具有防震、防风和防雨能力的建筑内。 - 应避免设在建筑…...

TensorRT-llm入门
一、目录 作用TensorRT-llm 为什么快?流程TensorRT-LLM 环境配置大模型 转换、编译与推理如何选择量化类型?lora 大模型如何合并?lora 大模型如何编译,使用?推理加速模型 tensorrRT-LLM、Vllm、fasterTransformer、Be…...

TinyXML-2介绍
1.简介 TinyXML-2 是一个简单、小巧的 C XML 解析库,它是 TinyXML 的一个改进版本,专注于易用性和性能。TinyXML-2 用于读取、修改和创建 XML 文档。它不依赖于外部库,并且可以很容易地集成到项目中。 tinyXML-2 的主要特点包括:…...
JAVA课程设计
一:Java连接mysql数据库 1.1点击进入mysql jar包下载官网 MySQL :: MySQL Community Downloads 将下载好的压缩包进行解压 解压之后下图就是连接数据库所用到的jar包: 将jar包复制到IDEA所用的项目下,放置jar包的目录为lib,需要…...
基于SpringBoot+Vue的旅游网站系统
初衷 在后台收到很多私信是咨询毕业设计怎么做的?有没有好的毕业设计参考? 能感觉到现在的毕业生和当时的我有着同样的问题,但是当时的我没有被骗, 因为现在很多人是被骗的,还没有出学校还是社会经验少,容易相信别人…...

http代理ip按流量划算还是个数划算?
随着科技的进步和互联网的发展,越来越多的企业在业务上都需要用到代理,那么http代理ip按流量划算还是个数划算?小编接下来就跟大家介绍一下: 首先我们得先了解http代理ip的按流量模式和个数模式分别是什么: 一、按流…...
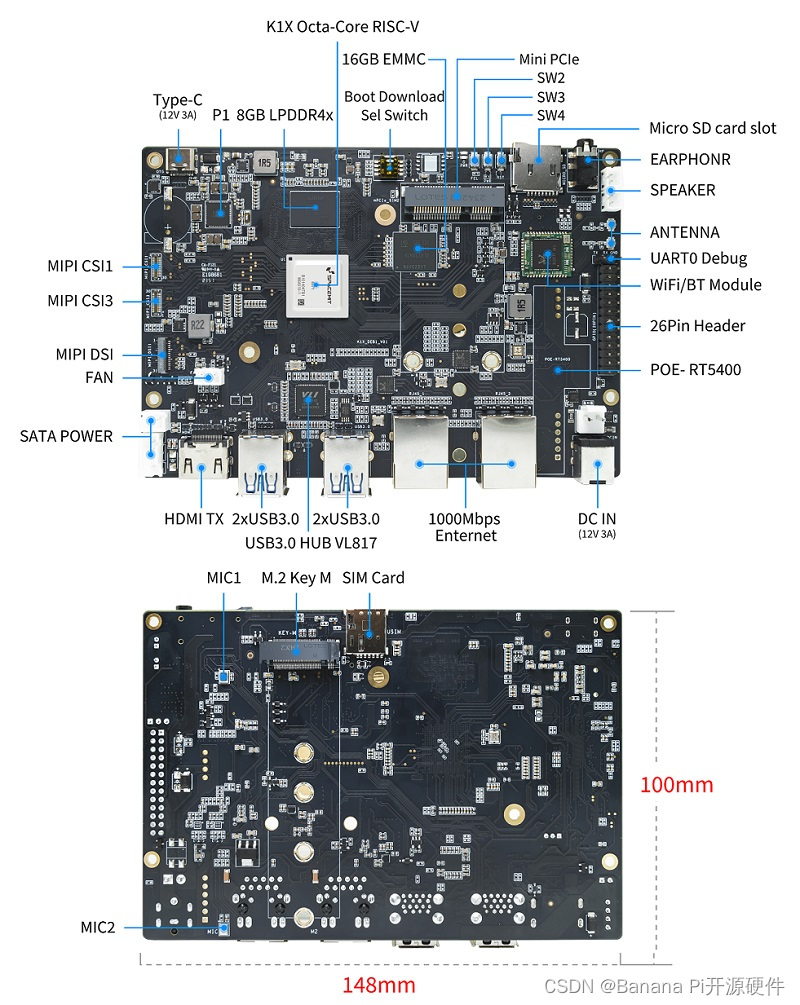
Banana Pi BPI-F3, 进迭时空K1芯片设计,定位工业级应用,网络通信及工业自动化
香蕉派BPI-F3是一款工业级 8核RISC-V开源硬件开发板,它采用进迭时空(SpacemiT) K1 8核RISC-V芯片设计,CPU集成2.0 TOPs AI计算能力。4G DDR和16G eMMC。2个GbE以太网接口,4个USB 3.0和PCIe M.2接口,支持HDM…...

安科瑞工业IT产品及解决方案—电源不接地,设备外壳接地【监测系统对地绝缘电阻】
低压配电系统分类及接地保护方案 国际电工委员会(iec)对各接地方式供电系统的规定规定:(低压:交流1000V以下) 低压配电接地、接零系统分为IT、TT、TN三种基本形式。TN分为TN-C,TN-S,TN-C-S三种…...
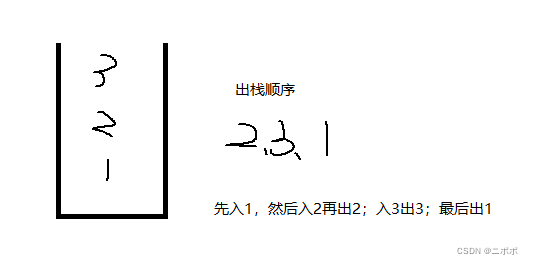
栈:概念与实现
1.概念 压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。出栈:栈的删除操作叫做出栈,出数据也在栈顶。栈的元素遵循后进先出LIFO(Last In First Out)的原则。后面进来的数据先出去 2.栈的实现 三种实现方法,数组…...

【Linux】查找服务器中某个文件的完整路径
方法一: 使用 -wholename 来搜索路径: find / -wholename */esm/data.py这个命令会搜索与 */esm/data.py 完全匹配的路径,其中 * 代表任意数量的任意字符。这应该会找到位于任何目录下的 esm/data.py 文件。 可以限定在某个目录下查找&…...

windows server 2019 安装 docker环境
一、根据官方说明进行安装 , 看起来过程相当简单, 但问题还是有的 准备 Windows 操作系统容器 | Microsoft Learn // 一个 powershell 脚本,该脚本配置环境以启用与容器相关的 OS 功能并安装 Docker 运行时。 Invoke-WebRequest -UseBasicParsing "https://r…...
)
别再只用ARIMA了!用Python+statsmodels搞定SARIMA预测电商销量(附完整代码)
电商销量预测实战:用PythonSARIMA破解季节性销售波动 电商销量预测的痛点与SARIMA的破局之道 每逢大促季节,电商运营团队总会陷入两难困境:备货不足错失销售良机,库存积压又导致资金周转困难。传统ARIMA模型在预测日常销量时表现尚…...

4步快速上手ESP32 Arduino开发:从零基础到第一个物联网项目
4步快速上手ESP32 Arduino开发:从零基础到第一个物联网项目 【免费下载链接】arduino-esp32 Arduino core for the ESP32 family of SoCs 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 还在为ESP32开发环境的复杂配置而烦恼吗࿱…...

测试09测试09测试09测试09测试09
测试09测试09测试09测试09测试09...
模仿学习新思路:拆解ACT算法中的CVAE与Transformer如何联手生成平滑动作序列
模仿学习新范式:ACT算法中CVAE与Transformer的协同进化 在机器人精细操作领域,如何生成连贯平滑的动作序列一直是核心挑战。斯坦福ALOHA团队提出的动作分块算法ACT(Action Chunking with Transformers)通过融合条件变分自编码器&…...

5分钟精通英雄联盟信息修改:LeaguePrank新手完全使用指南
5分钟精通英雄联盟信息修改:LeaguePrank新手完全使用指南 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 你是否曾在英雄联盟中羡慕别人的华丽段位边框,却苦于自己的段位不够理想?你是否想要…...
)
告别Excel!用Python复现地理探测器,手把手教你分析空间数据(附完整代码)
告别Excel!用Python复现地理探测器,手把手教你分析空间数据(附完整代码) 空间数据分析在地理信息科学、生态学和城市规划等领域扮演着关键角色。传统的地理探测器分析往往依赖Excel工具包,但这种方式存在诸多限制&…...

Pydantic序列化避坑大全:从‘按声明类型序列化’到灵活exclude/include的5个常见误区
Pydantic序列化深度避坑指南:从类型陷阱到安全控制的实战解析 深夜调试代码时,你是否遇到过这样的场景:明明在内存中完整的对象,通过API返回给前端时却莫名丢失了关键字段?或者当你在日志中打印包含敏感信息的模型时&a…...

【免费下载】 探索高效CAN通信:PCAN PRO/PRO FD USB2CAN固件实现
探索高效CAN通信:PCAN PRO/PRO FD USB2CAN固件实现 项目介绍 PCAN PRO/PRO FD USB2CAN固件实现是一个专为基于STM32F4的廉价硬件设计的开源项目。该项目旨在为使用STM32F407/405开发板的用户提供一个高效、稳定的USB2CAN通信解决方案。通过该固件,用户可…...

实战心得Laravel 10.x 新特性全解析:解锁 PHP 开发新境界
在 PHP 开发领域,Laravel 一直是备受瞩目的框架之一。它以其优雅的语法、强大的功能和便捷的开发体验,赢得了众多开发者的青睐。随着技术的不断发展,Laravel 也在持续更新和进化。今天,我们就来全面解析 Laravel 10.x 的新特性&am…...

从 JetBrains 全家桶用户视角,聊聊 DataGrip 那些被低估的『协同』技巧:共享查询、布局同步与团队规范
从 JetBrains 全家桶用户视角,聊聊 DataGrip 那些被低估的『协同』技巧:共享查询、布局同步与团队规范 在团队开发环境中,数据库操作往往被视为个人技能而非团队资产。当开发者频繁切换于 IntelliJ IDEA、PyCharm 和 DataGrip 之间时…...