Unicode字符集和UTF编码
文章目录
- 前言
- 一、字符集和编码方式
- 二、unicode字符集
- utf32编码
- utf8编码
- utf8编码函数示例
- utf8解码函数示例
- utf16编码
- utf16编码解码函数示例
- 总结
前言
本文详细介绍 u n i c o d e unicode unicode 字符集和其相关的三种编码方式: u t f 8 utf8 utf8, u t f 16 utf16 utf16 和 u t f 32 utf32 utf32,并给出一个编码和解码的参考程序。
一、字符集和编码方式
字符集是一些字符的集合,字符集中每一个字符有一个唯一的字符编码表示该字符,编码方式规定了计算机存储该字符集中字符编码的规则,也是计算机解读一串二进制序列的规则。
1: A S C I I ASCII ASCII 码用 7 b i t ( 0 x 00 − 0 x 7 f ) 7bit \ (0x00-0x7f) 7bit (0x00−0x7f) 存储英文字符,字符集为 128 128 128 个英文字符,即 A S C I I ASCII ASCII 字符集。 A S C I I ASCII ASCII 码的编码方式类似直接映射,字母 A A A 对应的字符编码是 65 65 65,在 A S C I I ASCII ASCII 编码下为 0 x 41 0x41 0x41。字符编码的值也是 A S C I I ASCII ASCII 码值。
2: A S C I I ASCII ASCII 字符集的缺陷非常直观:只包含英文字符。
3: U n i c o d e Unicode Unicode 是国际标准字符集,它将世界各种语言的每个字符定义一个唯一的字符编码,以满足跨语言、跨平台的文本信息转换。 2023 2023 2023 年 9 9 9 月发表的 15.1 15.1 15.1 版本中定义了 149813 149813 149813 个字符。规定 U n i c o d e Unicode Unicode 字符编码存储方式的规则主要有三种: u t f 8 utf8 utf8, u t f 16 utf16 utf16, u t f 32 utf32 utf32
二、unicode字符集
U n i c o d e Unicode Unicode 为每一个字符分配一个唯一的字符编码,称为在编码空间中的一个码点 ( c o d e p o i n t ) (code \ point) (code point), U n i c o d e Unicode Unicode 标准给定编码空间为 U+0000 - U+10FFFF。码点以 U + U+ U+ 开头,最少用 4 4 4 个十六进制数表示,若有前导 0 0 0 不可省略。例如: U + 00 F 7 U+00F7 U+00F7 表示除法符号 ÷ ÷ ÷ 。
编码空间中有效码点个数为: 2 20 + ( 2 16 − 2 11 ) = 1112064 2^{20} + (2^{16} − 2^{11}) = 1112064 220+(216−211)=1112064。其减掉的 2 11 2^{11} 211 主要原因在于 u t f 16 utf16 utf16 编码的编码方式限制,在范围 U+D800 - U+DFFF 内 U n i c o d e Unicode Unicode 并未编码字符。
下表随机列了几个 U n i c o d e Unicode Unicode 码点和其表示的字符之间的对应关系:
| 码点 | Value |
|---|---|
| U+2118 | P \huge\mathscr{P} P |
| U+A015 | ꀕ |
| U+FE18 | ︘ |
另外,按照码点范围区分了不同平面,以下为具体平面名称:
| 码点范围 | 平面 |
|---|---|
| U+0000-U+FFFF | 基本多文种平面 |
| U+10000-U+1FFFF | 多文种补充平面 |
| U+20000-U+2FFFF | 表意文字补充平面 |
| U+30000-U+DFFFF | 表意文字第三平面 |
| U+E0000-U+EFFFF | 特别用途补充平面 |
| U+F0000-U+FFFFF | 保留作为私人使用区域A区 |
| U+100000-U+10FFFF | 保留作为私人使用区域B区 |
基本多文种平面包含了绝大部分常用字符,例如: U + 0980 − U + 09 F F U+0980-U+09FF U+0980−U+09FF 为孟加拉文, U + 25 A 0 − U + 25 F F U+25A0-U+25FF U+25A0−U+25FF 为几何图形, U + 1800 − U + 18 A F U+1800-U+18AF U+1800−U+18AF 为蒙古文,等等。具体见:Unicode符号表
utf32编码
u t f 32 utf32 utf32 编码方式非常简单直观:用 32 b i t 32bit 32bit 直接表示一个 U n i c o d e Unicode Unicode 码点,因此其也被称为定长编码。
1 1 1: U n i c o d e Unicode Unicode 标准规定的编码空间: U+0000 - U+10FFFF。最长需要 3 3 3 个字节表示, 4 4 4 字节完全够用。
2 2 2:以码点 U + 0041 U+0041 U+0041 字符 A A A 为例,其 u t f 32 utf32 utf32 编码结果为: 0 x 00000041 0x00000041 0x00000041。直观来讲, u t f 32 utf32 utf32 编码方式相当于把码点零扩展到 32 b i t 32bit 32bit。类似的, A S C I I ASCII ASCII 码也是一样的,零扩展到 7 b i t 7bit 7bit 表示。
缺点:
1 1 1: u t f 32 utf32 utf32 编码最大的缺点在于占用空间过大。假设一个文件内容只包含 A S C I I ASCII ASCII 字符集中的字符,那么用 u t f 8 utf8 utf8 来存储所需的空间是用 u t f 32 utf32 utf32 来存储的 1 / 4 1/4 1/4。
2 2 2: u t f 32 utf32 utf32 不兼容 A S C I I ASCII ASCII 码。即:同样一个十六进制表示 0 x 41 0x41 0x41,在 A S C I I ASCII ASCII 和 u t f 8 utf8 utf8 两种编码中表示内容一样且都为字符 A A A 的合法编码。
utf8编码
u t f 8 utf8 utf8 编码和 u t f 16 utf16 utf16 都为变长编码。 u t f 8 utf8 utf8 用 1 − 4 1-4 1−4 字节来表示一个特定字符。具体编码规则如下所示:
| 码点范围 | 码点二进制表示 | 编码规则 | 字节数 |
|---|---|---|---|
| U + 0000 − U + 007 F U+0000-U+007F U+0000−U+007F | 0 b x x x x x x x 0bxxxxxxx 0bxxxxxxx | 0 b 0 x x x x x x x 0b0xxxxxxx 0b0xxxxxxx | 1字节 |
| U + 0080 − U + 07 F F U+0080-U+07FF U+0080−U+07FF | 0 b x x x x x x x x x x x 0bxxx \ xxxx\ xxxx 0bxxx xxxx xxxx | 0 b 110 x x x x x 10 x x x x x x 0b110xxxxx \ 10xxxxxx 0b110xxxxx 10xxxxxx | 2字节 |
| U + 0800 − U + F F F F U+0800-U+FFFF U+0800−U+FFFF | 0 b x x x x x x x x x x x x x x x x 0bxxxx\ xxxx \ xxxx \ xxxx 0bxxxx xxxx xxxx xxxx | 0 b 1110 x x x x 10 x x x x x x 10 x x x x x x 0b1110xxxx \ 10xxxxxx \ 10xxxxxx 0b1110xxxx 10xxxxxx 10xxxxxx | 3字节 |
| U + 01 0000 − U + 10 F F F F U+01 \ 0000-U+10 \ FFFF U+01 0000−U+10 FFFF | 0 b x x x x x x x x x x x x x x x x x x x x x 0bx \ xxxx \ xxxx \ xxxx \ xxxx\ xxxx 0bx xxxx xxxx xxxx xxxx xxxx | 0 b 11110 x x x 10 x x x x x x 10 x x x x x x 10 x x x x x x 0b11110xxx \ 10xxxxxx \ 10xxxxxx \ 10xxxxxx 0b11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 4字节 |
1 1 1:编码时只需根据码点范围按照码点二进制表示,高位补 0 0 0,填充编码规则中所需的空缺即可。
2 2 2:解码时只需要考虑首字节中最高位 0 b i t 0bit 0bit 左侧 1 b i t 1bit 1bit 的个数,即为当前字符所占用字节数。
例如:编码 U + 00 E 9 U+00E9 U+00E9 对于字符为 e ˊ é eˊ。根据范围知道其需要二字节编码, 0 0 0 扩展到 11 b i t 11bit 11bit 为 0 b 000 1110 1001 0b000 \ 1110 \ 1001 0b000 1110 1001。依次填充可知该字符 u t f 8 utf8 utf8 编码结果为 0 b 11000011 10101001 = 0 x c 3 a 9 0b11000011 \ 10101001=0xc3a9 0b11000011 10101001=0xc3a9。
utf8编码函数示例
下面给出编码函数如下所示:
参数buf为待填入编码值的缓冲区,c为32位unicode码点
返回值为该字符所需编码长度
int encode_utf8(char *buf, uint32_t c) {// 一字节编码if (c <= 0x7F) {buf[0] = c;return 1;}// 二字节编码,首字节待填充5位,第二字节待填充6位if (c <= 0x7FF) {buf[0] = 0b11000000 | (c >> 6);buf[1] = 0b10000000 | (c & 0b00111111);return 2;}// 三字节编码,首字节待填充4位,第二字节待填充6位,第三字节待填充6位if (c <= 0xFFFF) {buf[0] = 0b11100000 | (c >> 12);buf[1] = 0b10000000 | ((c >> 6) & 0b00111111);buf[2] = 0b10000000 | (c & 0b00111111);return 3;}// 四字节编码,首字节待填充3位,第二字节待填充6位,第三字节待填充6位,第四字节待填充6位buf[0] = 0b11110000 | (c >> 18);buf[1] = 0b10000000 | ((c >> 12) & 0b00111111);buf[2] = 0b10000000 | ((c >> 6) & 0b00111111);buf[3] = 0b10000000 | (c & 0b00111111);return 4;
}
可通过如下主函数测试该编码函数的正确性:
int main(){char buf[4];int len=encode_utf8(buf,0x000000E9);system("chcp 65001"); // 终端使用utf8编码for(int i=0;i<len;i++)printf("%x",(unsigned char)buf[i]);std::cout<<std::endl;std::cout<<buf<<std::endl;return 0;
}
用 v s c o d e + m i n g w vscode+mingw vscode+mingw 的环境下有输出如下所示:

utf8解码函数示例
下面给出解码函数如下所示:
参数buf为给定utf8编码序列
返回值为该字符unicode码点
uint32_t decode_utf8(char *p) {// 单字节编码if ((unsigned char)*p < 128) {return *p;}int len;uint32_t c;if ((unsigned char)*p >= 0b11110000) { // 四字节编码,起始11110xxx,3bit有效len = 4;c = *p & 0b111;} else if ((unsigned char)*p >= 0b11100000) { // 三字节编码,起始1110xxxx,4bit有效len = 3;c = *p & 0b1111;} else if ((unsigned char)*p >= 0b11000000) { // 二字节编码,起始110xxxxx,5bit有效len = 2;c = *p & 0b11111;} else {std::cout<<"invalid UTF-8 sequence"<<std::endl;}for (int i = 1; i < len; i++) {if ((unsigned char)p[i] >> 6 != 0b10)std::cout<<"invalid UTF-8 sequence"<<std::endl;c = (c << 6) | (p[i] & 0b111111);}return c;
}
可通过如下主函数测试该编码函数的正确性:
int main(){unsigned char buf[4]={0xc3,0xa9,0x00,0x00};uint32_t code=decode_utf8((char*)buf);system("chcp 65001");std::cout<<buf<<std::endl;std::cout<<std::hex<<code<<std::endl;return 0;
}
用 v s c o d e + m i n g w vscode+mingw vscode+mingw 的环境下有输出如下所示:

utf16编码
u t f 16 utf16 utf16 为变长编码,采用 2 2 2 字节或 4 4 4 字节编码。不兼容 A S C I I ASCII ASCII 码。
上文提到,码点范围从 U + 0000 U+0000 U+0000 到 U + F F F F U+FFFF U+FFFF 为基本多文种平面,包括绝大多数常用字符。 u t f 16 utf16 utf16 编码对常用的基本多文种平面直接使用 2 2 2 字节编码,超过这个范围的码点使用 4 4 4 字节编码。
具体编码规则如下所示:
| 码点范围 | 码点二进制表示 | 编码规则 | 字节数 |
|---|---|---|---|
| U + 0000 − U + F F F F U+0000-U+FFFF U+0000−U+FFFF | 0 b x x x x x x x x x x x x x x x x 0bxxxxxxxx \ xxxxxxxx 0bxxxxxxxx xxxxxxxx | 0 b x x x x x x x x x x x x x x x x 0bxxxxxxxx \ xxxxxxxx 0bxxxxxxxx xxxxxxxx | 2字节 |
| U + F F F F − U + 10 F F F F U+FFFF-U+10FFFF U+FFFF−U+10FFFF | c o d e p o i n t − 0 x 10000 = 0 b y y y y y y y y y y x x x x x x x x x x code \ point - 0x10000=0byyyy \ yyyy \ yyxx \ xxxx \ xxxx code point−0x10000=0byyyy yyyy yyxx xxxx xxxx | 0 x D 800 + 0 b y y y y y y y y y y 0xD800+0byyyy \ yyyy \ yy 0xD800+0byyyy yyyy yy 0 x D C 00 + 0 b x x x x x x x x x x 0xDC00+0bxx \ xxxx \ xxxx 0xDC00+0bxx xxxx xxxx | 4字节 |
1 1 1:这里四字节编码中码点需要减去 0 x 10000 0x10000 0x10000 ,最大码点 0 x 10 F F F F − 0 x 10000 = 0 x F F F F F 0x10FFFF-0x10000=0xFFFFF 0x10FFFF−0x10000=0xFFFFF。
2 2 2:上文提及 u t f 16 utf16 utf16 编码特性使得 U n i c o d e Unicode Unicode 标准中有 2 11 2^{11} 211 个码点未编码实际字符,该未编码字符的码点范围为: U + D 800 U+D800 U+D800 到 U + D F F F U+DFFF U+DFFF。用来作为 u t f 16 utf16 utf16 四字节编码的范围。
utf16编码解码函数示例
下面给出编码函数如下所示:
参数buf为待填入编码值的缓冲区,缓冲区单元为2字节单元,c为32位unicode码点
返回值为该字符所需编码长度
int encode_utf16(uint16_t *buf, uint32_t c) {int len=0;if (c < 0x10000) {// 2字节编码buf[len++] = c;return 2;} else {// 4字节编码c -= 0x10000;buf[len++] = 0xd800 + ((c >> 10) & 0x3ff);buf[len++] = 0xdc00 + (c & 0x3ff);return 4;}
}
下面给出解码函数如下所示:
参数buf为填入编码值的缓冲区,缓冲区单元为2字节单元
返回值为该字符的unicode码点
uint32_t decode_utf16(uint16_t *buf) {uint32_t code;if ((*buf) >= 0xD800 && (*buf) <= 0xDBFF) {code = ((*buf)-0xD800)&0x3ff;buf++;if (!(*buf) >= 0xDC00 && (*buf) <= 0xDFFF){std::cerr<<"error utf16 code"<<std::endl;return 0;}code = (code<<10)|(((*buf)-0xDC00)&0x3ff);return code+0x10000;} else {return *buf;}
}
可通过如下主函数测试该编码解码函数的正确性:
int main(){uint16_t buf[2];int len=encode_utf16(buf,0x10ABC);for(int i=0;i<len/2;i++)printf("%x",buf[i]);printf("\n");uint32_t code=decode_utf16(buf);printf("0x%08x",code);printf("\n");return 0;
}
v s c o d e + m i n g w vscode+mingw vscode+mingw 输出如下图所示:

注:关于 u t f 32 utf32 utf32 编码到 U n i c o d e Unicode Unicode 码点的转换则不需要程式,直接通过无符号扩展到 32 b i t 32bit 32bit 即可,不再给出。
总结
完结撒花!
相关文章:
Unicode字符集和UTF编码
文章目录 前言一、字符集和编码方式二、unicode字符集utf32编码utf8编码utf8编码函数示例utf8解码函数示例 utf16编码utf16编码解码函数示例 总结 前言 本文详细介绍 u n i c o d e unicode unicode 字符集和其相关的三种编码方式: u t f 8 utf8 utf8,…...

echarts默认图例(横线+圈圈)
修改echarts 图例样式 项目里折线图需要去掉圆点, 但是图例样式需要是默认样式(横线和圈圈) 原始代码:(只展示series 和legend配置 ) series: [{name: chartObj.names[ind_one],yAxisIndex: yIndex,type: ele_one,barMaxWidth: 15,tooltip: {show: true},data: chartObj.yAx…...
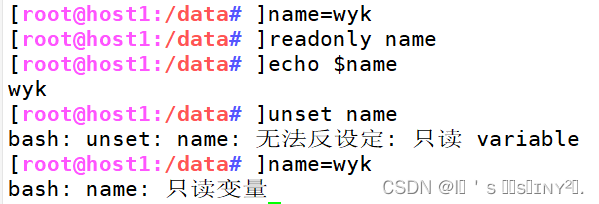
Shell脚本的基础和变量
1.shell脚本基础 1.1 shell的作用 Linux 系统中的 Shell 是一个特殊的应用程序,它介于操作系统内核与用户之间,充当 了一个“命令解释器”的角色,负责接收用户输入的操作指令(命令)并进行解释,将需要执 行的…...
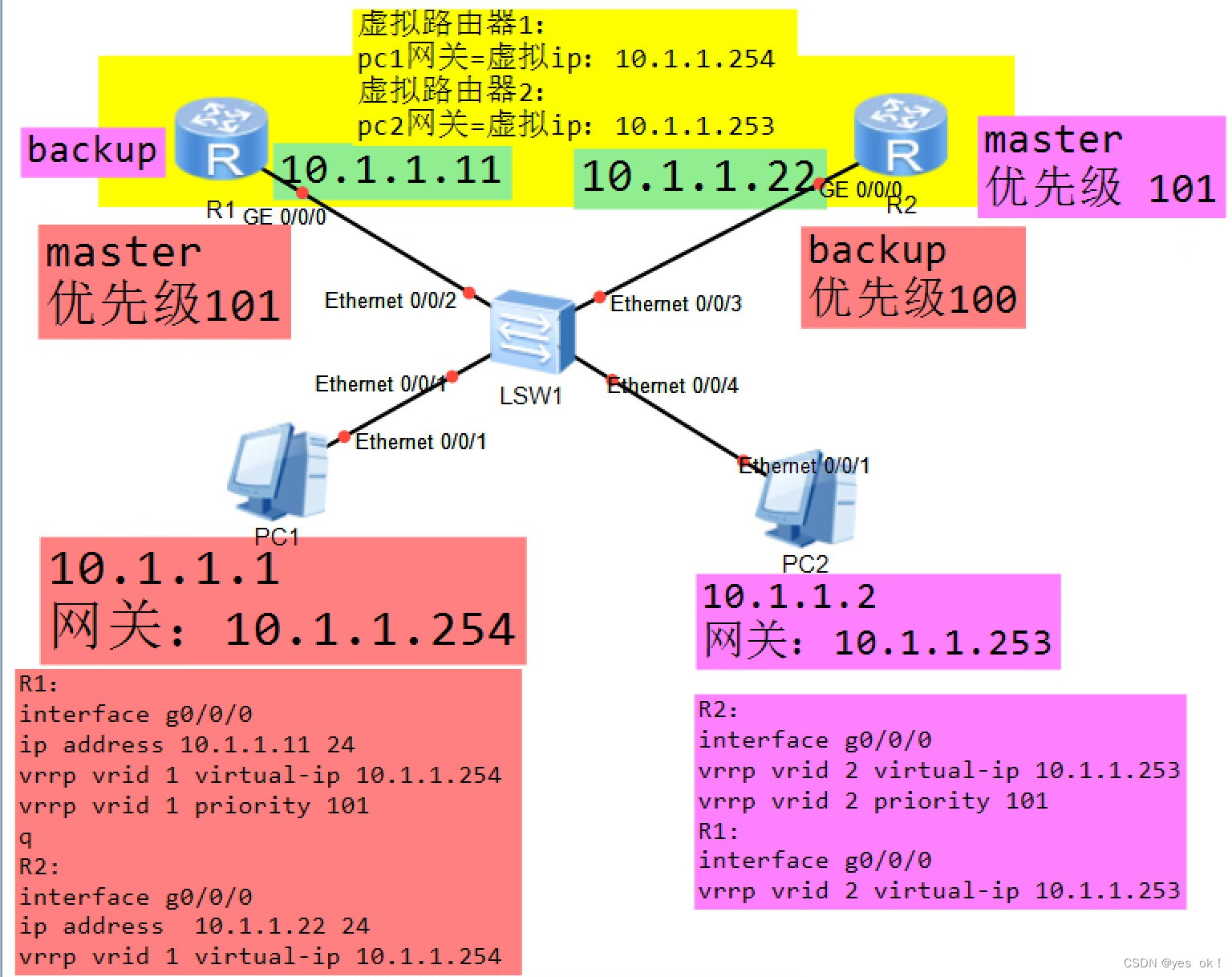
VRRP协议-负载分担配置【分别在路由器与交换机上配置】
VRRP在路由器与交换机上的不同配置 一、使用路由器实现负载分担二、使用交换机实现负载分担一、使用路由器实现负载分担 使用R1与R2两台设备分别进行VRRP备份组 VRRP备份组1,虚拟pc1的网关地址10.1.1.254 VRRP备份组2,虚拟pc2的网关地址10.1.1.253 ①备份组1的vrid=1,vrip=…...
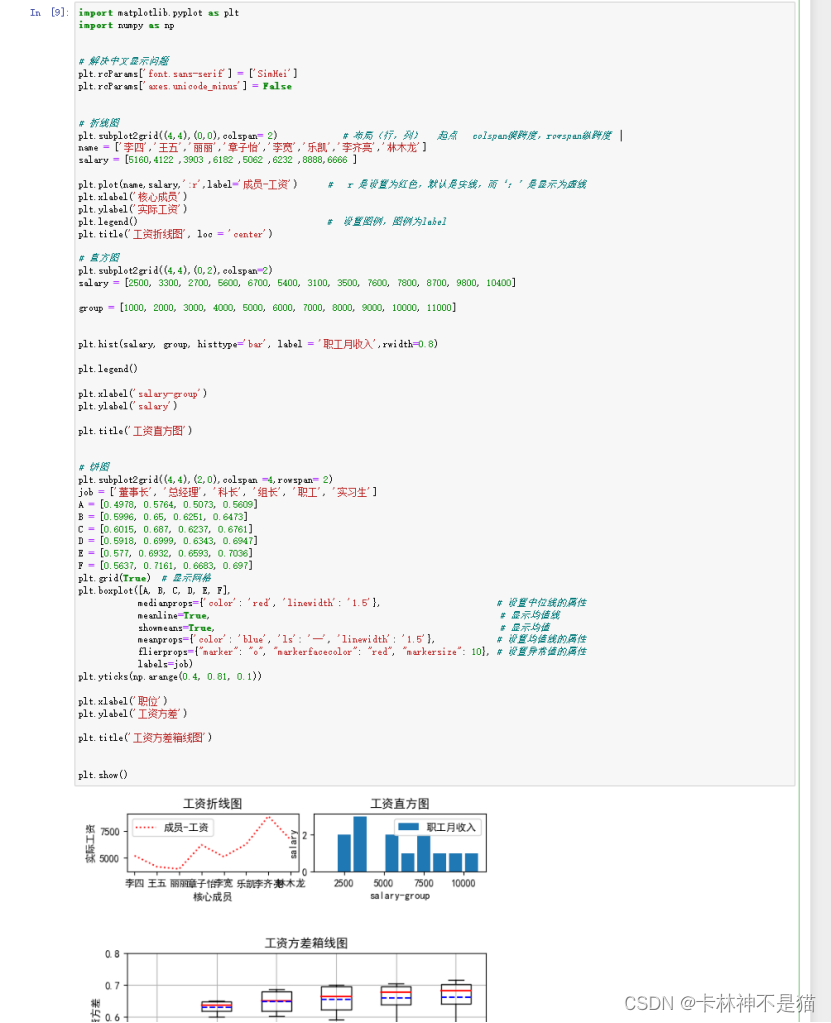
商务分析方法与工具(十):Python的趣味快捷-公司财务数据最炫酷可视化
Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊! 喜欢我的博客的话,记得…...
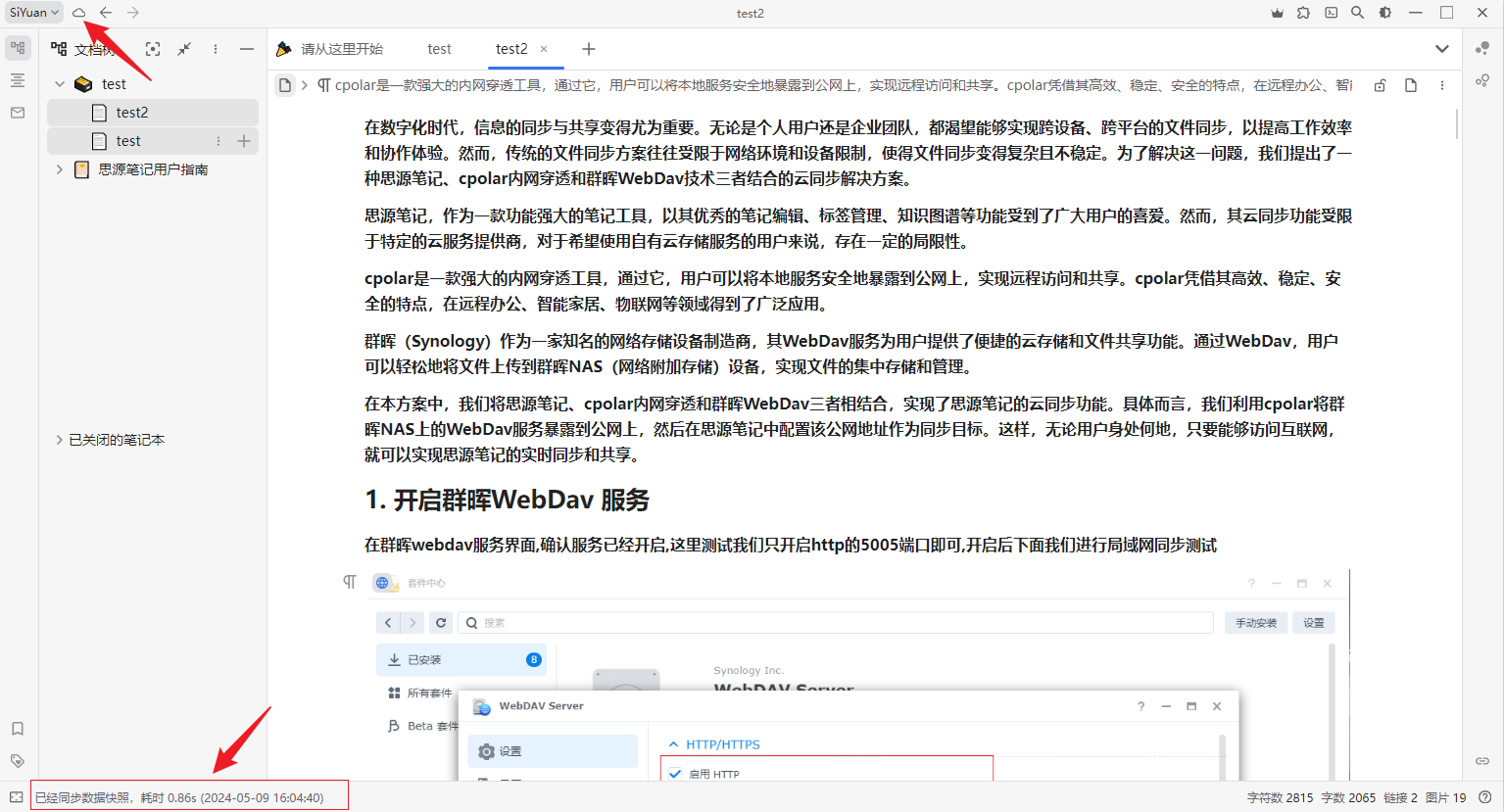
思源笔记如何结合群晖WebDav实现云同步数据
文章目录 1. 开启群晖WebDav 服务2. 本地局域网IP同步测试3. 群晖安装Cpolar4. 配置远程同步地址5. 笔记远程同步测试6. 固定公网地址7. 配置固定远程同步地址 在数字化时代,信息的同步与共享变得尤为重要。无论是个人用户还是企业团队,都渴望能够实现跨…...
)
Electron Forge | 跨平台实战详解(中)
简介 上篇 介绍了 Electron 和 Electron Builder 的基本用法,本篇将介绍更常用也更方便的打包工具,Electron Forge 。 Electron Forge 是一个为 Electron 应用的开发、打包和分发而设计的全功能工具集。它整合了多个底层 Electron 工具到一个统一的命令…...

stable diffusion教程
Stable Diffusion 是一种流行的图像生成模型,它可以根据文本提示生成高质量的图片。如果你想了解如何使用 Stable Diffusion,这里有一些基本的步骤和资源,可以帮助你开始使用: ### 1. 安装 Stable Diffusion 首先,你需…...
)
音频文件分析-- whisper(python 文档解析提取)
使用whisper转文本,这里使用的是large-v3版本 pip install githttps://github.com/openai/whisper.git import whisper import os from tqdm import tqdmmodel whisper.load_model("large-v3")path "rag_data" for fi in tqdm(os.listdir(pa…...
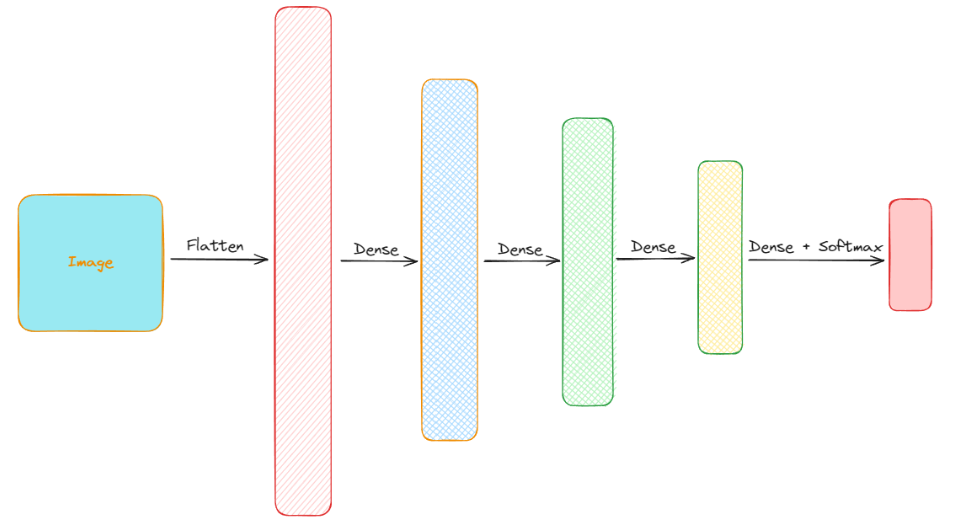
Python深度学习基于Tensorflow(3)Tensorflow 构建模型
文章目录 数据导入和数据可视化数据集制作以及预处理模型结构低阶 API 构建模型中阶 API 构建模型高阶 API 构建模型保存和导入模型 这里以实际项目CIFAR-10为例,分别使用低阶,中阶,高阶 API 搭建模型。 这里以CIFAR-10为数据集,C…...
火爆多年的抖音小店,2024年想要入驻需要什么条件呢?
大家好,我是电商糖果 我相信现在只要会上网的年轻人,对抖音小店一定不会感觉陌生。 它最近几年的风头,可是远远超过某宝,某多多了。 不少抖音用户也有了在抖音购物的习惯,现在的抖音上入驻了上百万家电商商家。 这…...
STM32G030C8T6:EEPROM读写实验(I2C通信)
本专栏记录STM32开发各个功能的详细过程,方便自己后续查看,当然也供正在入门STM32单片机的兄弟们参考; 本小节的目标是,系统主频64 MHZ,采用高速外部晶振,实现PB11,PB10 引脚模拟I2C 时序,对M24C08 的EEPRO…...
使用Git管理github的代码库-上
1、下载安装Git https://download.csdn.net/download/notfindjob/11451730?spm1001.2014.3001.5503 2、注册一个github的账号(已经注册的,可略过这一步) 3、打开git命令行,配置github账号 git config --global user.name &quo…...
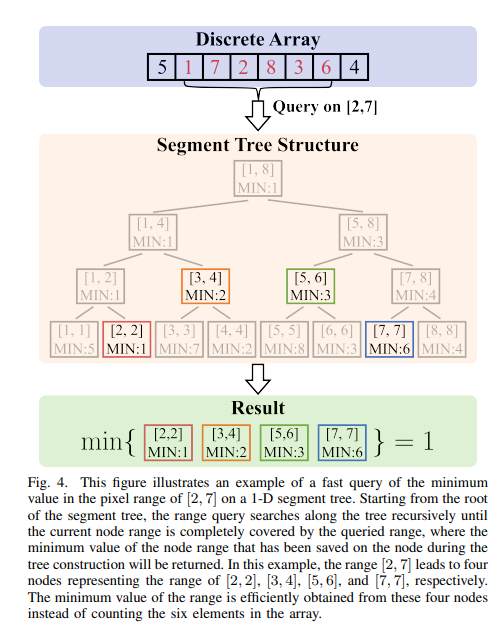
经典文献阅读之--D-Map(无需射线投射的高分辨率激光雷达传感器的占据栅格地图)
0. 简介 占用地图是机器人系统中推理环境未知和已知区域的基本组成部分。《Occupancy Grid Mapping without Ray-Casting for High-resolution LiDAR Sensors》介绍了一种高分辨率LiDAR传感器的高效占用地图框架,称为D-Map。该框架引入了三个主要创新来解决占用地图…...
开源免费的定时任务管理系统:Gocron
Gocron:精准调度未来,你的全能定时任务管理工具!- 精选真开源,释放新价值。 概览 Gocron是github上一个开源免费的定时任务管理系统。它使用Go语言开发,是一个轻量级定时任务集中调度和管理系统,用于替代L…...

从零开始详解OpenCV车道线检测
前言 车道线检测是智能驾驶和智能交通系统中的重要组成部分,对于提高道路安全、交通效率和驾驶舒适性具有重要意义。在本篇文章中将介绍使用OpenCV进行车道线的检测 详解 导入包 import cv2 import matplotlib.pyplot as plt import numpy as np读入图像并灰度化…...

【Java代码审计】逻辑漏洞篇
【Java代码审计】逻辑漏洞篇 逻辑漏洞概述常见逻辑漏洞点 逻辑漏洞概述 逻辑漏洞一般是由于源程序自身逻辑存在缺陷,导致攻击者可以对逻辑缺陷进行深层次的利用。逻辑漏洞出现较为频繁的地方一般是登录验证逻辑、验证码校验逻辑、密码找回逻辑、权限校验逻辑以及支…...

SSH简介
SSH,全名叫Secure Shell,你可以想象它是一个超级安全的管道,专门用来远程操控电脑的。就好比你在家用遥控器指挥远处的电视换台,但比这高级多了,因为它是专门为电脑设计的。 为什么需要SSH? 在互联网的早期…...

Oracle的高级分组函数grouping和grouping_id
在网上对Oracle的高级分组函数grouping和grouping_id的讲解并不多,特别是grouping_id,还有解说有误的。经过1天研究,已经完全掌握了两个函数的作用和用法,下面简单的讲述即可明白。下面给大家分享。 GROUPING 函数 语法:grouping(表达式) 作用: GROUPING将超聚…...

SqlServer 查询数据库 和 数据表 大小的语句
–Sqlserver 查询数据库 大小 SELECT * FROM (SELECT DB_NAME(database_id) AS DatabaseName,type_desc AS FileType,name AS FileName,size * 8 / 1024/1024 AS FileSizeGBFROM sys.master_filesWHERE type 0 -- 数据文件AND state 0 -- 在线状态 ) T1 ORDER BY FileSizeG…...

利用快马平台与vscode codex快速构建react待办事项应用原型
最近在尝试用AI工具快速验证产品原型,发现InsCode(快马)平台配合VSCode Codex能实现惊人的开发效率。以React待办事项应用为例,从零到可交互原型只用了不到10分钟,分享下具体实现思路和操作过程。 需求拆解与AI描述 首先将待办事项应用的7个核…...
:从原理到落地)
模型剪枝实战指南(一):从原理到落地
1. 模型剪枝的本质:为什么能剪? 我第一次接触模型剪枝时,最困惑的问题是:神经网络训练出来的参数不都是有用的吗?凭什么能随便删?后来在移动端部署ResNet模型时才发现,原来大多数神经网络都存在…...

北京联通IPTV组播配置实战:OpenWRT与udpxy的完美结合
1. 为什么需要OpenWRTudpxy方案 家里换了新电视后,突然想把闲置的北京联通IPTV利用起来。传统机顶盒接线麻烦不说,还占用了宝贵的HDMI接口。经过实测,用OpenWRT路由器配合udpxy插件转换组播信号,才是真正的"一劳永逸"解…...

DAMOYOLO-S快速上手:移动端浏览器访问Web服务与触屏操作适配说明
DAMOYOLO-S快速上手:移动端浏览器访问Web服务与触屏操作适配说明 1. 开篇:一个能“看懂”世界的AI助手 想象一下,你正用手机拍一张街景照片,屏幕上立刻就能标出“汽车”、“行人”、“交通灯”,甚至“手提包”。这不…...

TradingAgents-CN智能交易系统:3种部署方案让你5分钟开启AI投资分析
TradingAgents-CN智能交易系统:3种部署方案让你5分钟开启AI投资分析 【免费下载链接】TradingAgents-CN 基于多智能体LLM的中文金融交易框架 - TradingAgents中文增强版 项目地址: https://gitcode.com/GitHub_Trending/tr/TradingAgents-CN 还在为复杂的金融…...

OWL ADVENTURE Node.js环境配置与模型服务封装
OWL ADVENTURE Node.js环境配置与模型服务封装 1. 引言 如果你是一名Node.js开发者,最近对AI模型服务感兴趣,想把像OWL ADVENTURE这样的模型集成到自己的应用里,那你来对地方了。你可能已经看过一些模型介绍,知道它功能挺强&…...
)
Windows 10 64位系统下Neo4j社区版与桌面版安装全攻略(2023最新版)
1. Neo4j简介与安装准备 如果你正在寻找一款强大的图数据库来管理复杂的关系数据,Neo4j绝对是个不错的选择。作为目前最流行的开源图数据库,它用起来就像在画一张巨大的网络图——每个节点代表实体(比如人或产品),每条…...

Phi-4-reasoning-vision-15B部署教程:开源大模型镜像适配国产GPU方案
Phi-4-reasoning-vision-15B部署教程:开源大模型镜像适配国产GPU方案 1. 模型介绍 Phi-4-reasoning-vision-15B是微软推出的视觉多模态推理模型,具备强大的图像理解和分析能力。这个15B参数规模的模型特别擅长处理需要结合视觉和语言理解的复杂任务。 …...

LFM2.5-1.2B-Thinking-GGUF开源生态初探:与Ollama等工具的对比与集成
LFM2.5-1.2B-Thinking-GGUF开源生态初探:与Ollama等工具的对比与集成 1. 开源大模型本地部署生态概览 近年来,开源大模型本地部署工具呈现百花齐放的局面。从早期的单一模型加载器,发展到如今功能丰富的模型管理生态系统,开发者…...
)
CasADi实战:用Python搞定机器人路径规划中的数值优化问题(附IPOPT配置)
CasADi实战:用Python搞定机器人路径规划中的数值优化问题(附IPOPT配置) 机器人路径规划的核心在于如何在复杂环境中找到一条既安全又高效的轨迹。这本质上是一个带约束的数值优化问题——我们需要最小化某种代价函数(如路径长度或…...