C++进阶:哈希(1)
目录
- 1. 简介unordered_set与unordered_map
- 2. 哈希表(散列)
- 2.1 哈希表的引入
- 2.2 闭散列的除留余数法
- 2.2.1 前置知识补充与描述
- 2.2.2 闭散列哈希表实现
- 2.3 开散列的哈希桶
- 2.3.1 结构描述
- 2.3.2 开散列哈希桶实现
- 2.3.3 哈希桶的迭代器与key值处理仿函数
- 3. unordered_set与unordered_map的封装
- 3.1 哈希桶的细节调整
- 3.2 具体封装
1. 简介unordered_set与unordered_map
- 在C++库中,除开map与set这两个关联式容器外,还存在着另外两个此类容器,unordered_set,unordered_map。
- unordered中文释义为无序的,这也正是这一对容器使用时的表征特点,这一对容器分别对应set与map,即K模型与KV模型的存储数据结点。
- 那么,除开使用迭代器遍历时,其内存储数据无序外,这一对容器与map与set容器有何不同,为什么要在已有map与set的情况下,再向库中加入这一对乍看功能冗余且劣于原本map与set的容器呢?我们来看下面的一组对照试验。
- unordered_set与unordered_map其的关键性常用接口与使用和map,set相同,不同的是其只支持正向迭代器且多了一些桶,负载因子相关的接口。
#include <iostream>
using namespace std;
#include <unordered_set>
#include <set>
#include <stdlib.h>
#include <time.h>
#include <vector>int main()
{const int N = 1000000;vector<int> data(N);set<int> s;unordered_set<int> us;srand((unsigned int)time(NULL));for (int i = 0; i < N; i++){//data.push_back(rand());//重复数据多//data.push_back(rand() + i);//重复数据少data.push_back(i);//有序数据}//插入int begin1 = clock();for (auto e : data){s.insert(e);}int end1 = clock();int begin2 = clock();for (auto e : data){us.insert(e);}int end2 = clock();cout << "insert number:" << s.size() << endl << endl;//查找int begin3 = clock();for (auto e : data){s.find(e);}int end3 = clock();int begin4 = clock();for (auto e : data){us.find(e);}int end4 = clock();int begin5 = clock();for (auto e : data){s.erase(e);}int end5 = clock();int begin6 = clock();for (auto e : data){us.erase(e);}int end6 = clock();cout << "set Insert:" << end1 - begin1 << endl;cout << "unordered Insert:" << end2 - begin2 << endl << endl;cout << "set Find:" << end3 - begin3 << endl;cout << "unordered Find:" << end4 - begin4 << endl << endl;cout << "set Erase:" << end5 - begin5 << endl;cout << "unordered Erase:" << end6 - begin6 << endl << endl;return 0;
}
运行结果:
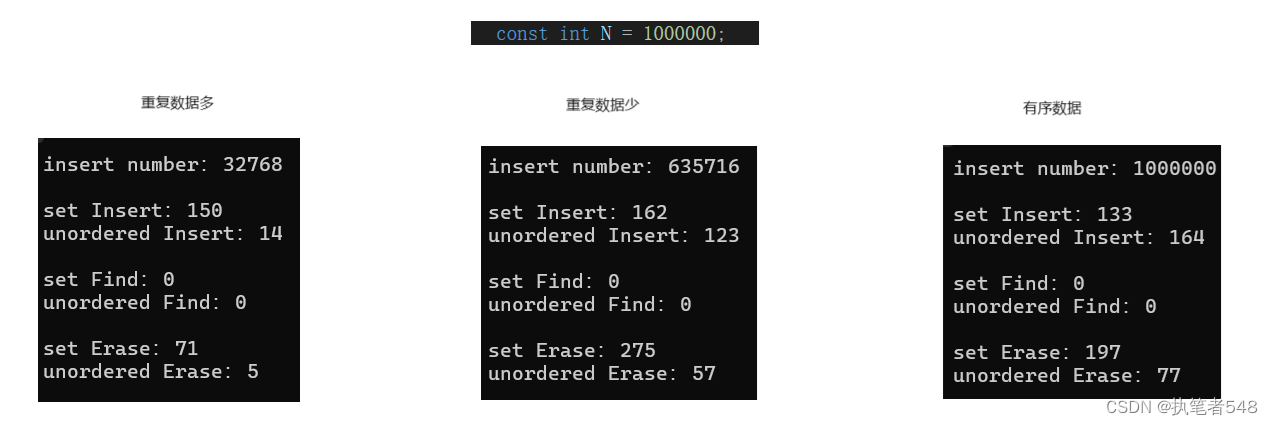
- 由运行结果可得
<1> 当数据无序时在重复数据较多的情况下,unordered系列的容器,插入删除效率更高
<2> 当数据无序但重复数据较少的情况下,两种类型的容器,两者插入数据效率仿佛
<3> 当数据有序时,红黑树系列的容器插入效率更高- 在日常的应用场景中,很少出现有序数据情况,虽然map,set有着遍历自得有序这一优势,但关联式容器的主要功能为映射关系与快速查询,其他优点尽是附带优势。所以,unordered系列容器的加入与学习是必要的。
2. 哈希表(散列)
2.1 哈希表的引入
- 在初阶数据结构的学习中,我们学习了一种排序方式,叫做基数排序,其使用数组下标表示需排序数据,下标对应的元素代表相应数据的出现次数。以此映射数据并排序,时间复杂度只有O(n)。
- 基数排序创建的数据存储数组,除可以用于数据排序外,我们不难发现其用来查询一个数据在或不再,可以通过访问下标对应数据直接得到,查询效率及其高。
- 这一为排序所创建的存储数组,就是一个简单的哈希表,我们也称之为散列,即数据并非连续而是散列在一段连续的空间中。
- 哈希表中的哈希,是指一种数据结构的设计思想,为通过某种映射关系为存储数据创建一个key值,其的映射关系不一,但都可以通过key值找到唯一对应的一个数据,且使得数据散列在存储空间中。
- 上述的存储结构为常见哈希表结构的一种,我们称之为直接定址法哈希表,但此种哈希表其使用上存在诸多限制,当存储数据的范围跨度较大时,就会使得空间浪费十分严重。接下来,我们来学习几种在其基础上进行优化具有实用价值的常用哈希表结构。
2.2 闭散列的除留余数法
2.2.1 前置知识补充与描述
- 除留余数法:为了解决存储数据大小范围跨度过大的问题,我们不再直接使用存储数据左key值映射,而是通过存储数据除以哈希表大小得到的余数做key值。这样就能将所有数据集中映射至一块指定大小的空间中。
- 哈希冲突/哈希碰撞:取余数做key值的方式虽然能够使得数据映射到一块指定空间中,并大幅度减少空间的浪费,可是这也会产生一个无法避免的问题,那就是不同数据的经过取余得到的余数可能相同,如此就会导致同一key值映射多个数据,使得无法进行需要的存储与查询。这一问题就被称为哈希碰撞。
- 线性探测与二次探测:哈希碰撞的解决存在多种方法策略,这里我们简单了解两种常用方式
<1> 线性探测:当前key值对应数据位被占用时,向后遍历(hashi + i),直至找到为空的数据位再将数据存入,而探测查询时,也以线性逻辑搜索直至遍历至空,则代表查询数据不存在,越界回绕。
<2> 二次探测:当前key指对数据位被占用时,当前key值依次加正整数的平方(hashi + i 2 i^2 i2)直至遍历至空存入,探测查询时,依次逻辑或至空结束,越界回绕。- 补充:
<1> 负载因子:哈希表中存储数据个数与哈希表长度的比值,一般控制在0.7左右,若负载因子超过,进行扩容
<2> 线性探测容易导致数据的拥堵与踩踏,二次探测的方式为对此的优化
<3> 处理非数字类型数据,将其转换为size_t类型后,再进行key值映射,采用仿函数的方式
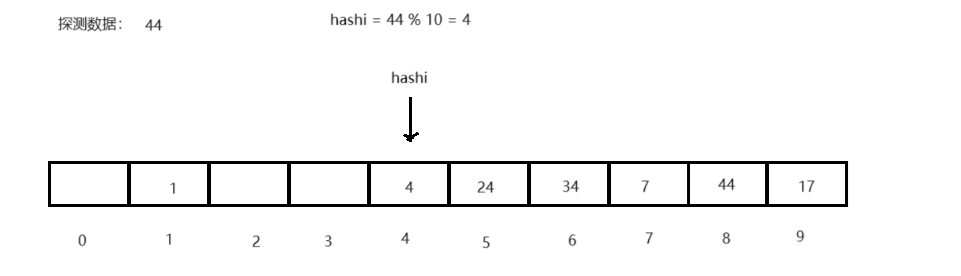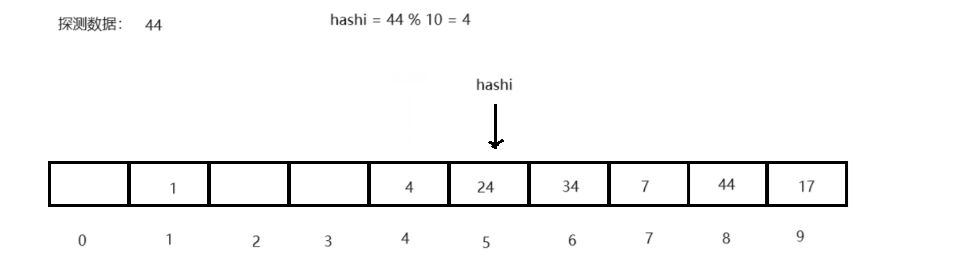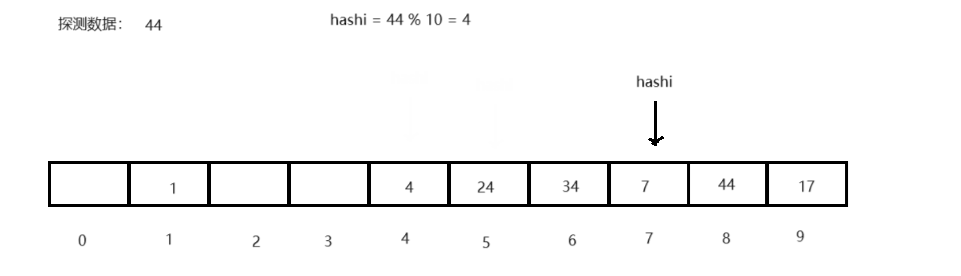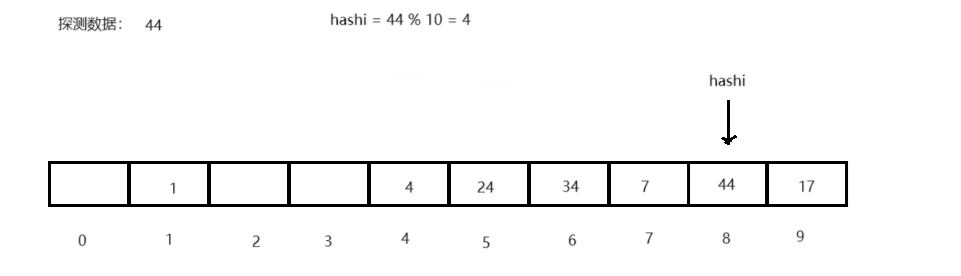
2.2.2 闭散列哈希表实现
- 哈希表结构
//结点状态
enum State
{EMPTY,//可插入,查询结束EXIST,//不可插入,向后查询DELETE//可插入,向后查询
};//数据结点
template<class K, class V>
struct HashNode
{pair<K, V> _kv;State _state;HashNode(const pair<K, V>& kv = make_pair(K(), V())):_kv(kv),_state(EMPTY){}
};//哈希表
template<class K, class V, class hash = HashFunc<K>>
class HashTable
{typedef HashNode<K, V> HashNode;typedef Hash_iterator<K, V, hash> iterator;
public:HashTable(size_t n = 10){_table.resize(n);}//迭代器相关iterator begin();iterator end(); //查找HashNode* Find(const K key);//插入bool Insert(const pair<K, V>& kv);//删除bool Erase(const K key);private:vector<HashNode> _table;//结点size_t n = 0;//存储数据个数hash hs;//仿函数,处理key值
};
- 操作实现
//查找
HashNode* Find(const K key)
{int hashi = hs(key) % _table.size();while (_table[hashi]._state != EMPTY){if (_table[hashi]._state == EXIST && hs(_table[hashi]._kv.first) == hs(key)){return &_table[hashi];}hashi++;hashi %= _table.size();}return nullptr;
}//插入
bool Insert(const pair<K, V>& kv)
{//扩容,类型转换//重新建立映射关系,插入(现代写法)if ((double)n / (double)_table.size() >= 0.7){HashTable<K, V, hash> newtable(_table.size() * 2);//迭代器for (auto& e : _table){newtable.Insert(e._kv);}_table.swap(newtable._table);}//找到要插入的位置int hashi = hs(kv.first) % _table.size();//线性探测while (_table[hashi]._state == EXIST){if (_table[hashi]._kv.first == kv.first){return false;}//可能越界,需要回绕hashi++;hashi %= _table.size();}//插入,单参数的构造函数支持隐式类型转换_table[hashi] = kv;_table[hashi]._state = EXIST;n++;return true;
}//删除
bool Erase(const K key)
{//将要删除结点的状态改为deleteint hashi = key % _table.size();//复用findHashNode* ret = Find(key);if (ret){ret->_state = DELETE;n--;return true;}else{return false;}
}
- 迭代器相关接口
iterator begin()
{for (size_t i = 0; i < _table.size(); i++){HashNode* cur = _table[i];if (cur){return iterator(cur, this);}}return end();//补
}iterator end()
{return iterator(nullptr, this);
}
- key指出,类型转换仿函数
//仿函数
template<class K>//数字类型
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//string类型全特化,常用
template<>
struct HashFunc<string>
{size_t operator()(string str){size_t key = 0;for (auto e : str){key += e;key *= 131;}return key;}
};//其他类型,自定义类型
struct Date
{int _year;int _month;int _day;
};struct HashDate
{size_t operator()(const Date& d){size_t key = 0;key += d._day;key *= 131;//科学建议值key += d._month;key *= 131;key += d._year;key *= 131;return key;}
};struct Person
{int name;int id;//有唯一项用唯一项,无唯一项,乘权值拼接int add;int tel;int sex;
};
2.3 开散列的哈希桶
2.3.1 结构描述
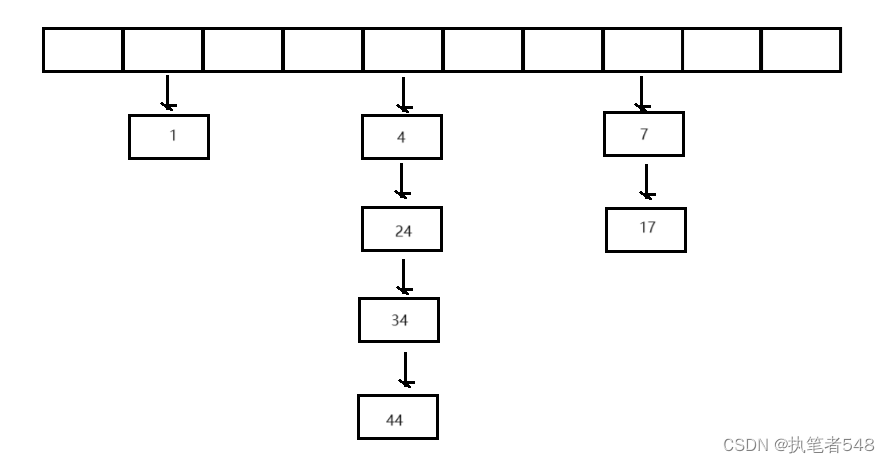
- 除留余数法后线性探测的存储方式会导致数据的拥堵踩踏,随着数据存储数量的增加,踩踏与拥挤的现象会越来越频繁,二次探测的优化也仅仅只是饮鸩止渴。
- 由此,我们来学习一种新的哈希结构也是使用最广泛的一种,其存储方式为:
顺序表中存储链表指针,相同key值的数据构造成链表结构的数据结点,挂入同一链表中,此种数据结构就被称为哈希桶
2.3.2 开散列哈希桶实现
- 哈希桶结构
//数据结点
template <class K, class V>
struct HashNode
{pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const pair<K, V>& kv):_kv(kv),_next(nullptr){}
};//哈希桶结构
template <class K, class V, class hash = HashFunc<K>>
class HashTable
{typedef HashNode<K, V, hash> HashNode;
public://构造HashTable(size_t n = 10){_table.resize(n, nullptr);_n = 0;}//析构~HashTable(){for (size_t i = 0; i < _table.size(); i++){HashNode* cur = _table[i];while (cur){HashNode* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}private:vector<HashNode*> _table;size_t _n;//插入数据个数,计算负载因子与扩容hash hs;//非数字类型,key值处理friend struct iterator;//迭代器会需要访问存储数据的vector
};
- 操作实现
//插入
bool Insert(const pair<K, V>& kv)
{//不支持键值冗余if (Find(kv.first))return false;//何时扩容,负载因子到1就扩容,插入数据个数if (_n == _table.size()){vector<HashNode*> newtable(2 * _table.size());//不再重新申请创建结点,而是搬运for (size_t i = 0; i < _table.size(); i++){HashNode* cur = _table[i];while (cur){HashNode* next = cur->_next;size_t hashi = hs(cur->_kv.first) % newtable.size();cur->_next = newtable[hashi];newtable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable);}//计算插入位置size_t hashi = hs(kv.first) % _table.size();//头插HashNode* newnode = new HashNode(kv);newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;return true;
}//查找
HashNode* Find(const K& key)
{for (size_t i = 0; i < _table.size(); i++){HashNode* cur = _table[i];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}}return nullptr;
}//删除
bool Erase(const K& key)
{size_t hashi = hs(key) % _table.size();HashNode* cur = _table[hashi];HashNode* prev = nullptr;while (cur){if (cur->_kv.first == key){if (prev){prev->_next = cur->_next;}else{_table[hashi] = cur->_next;}delete cur;_n--;return true;}prev = cur;cur = cur->_next;}return false;
}
2.3.3 哈希桶的迭代器与key值处理仿函数
- 迭代器结构
//将迭代器代码写于哈希桶之前
//迭代器与哈希桶存在互相引用,添加前置声明
template<class K, class V, class hash>
class HashTable;template<class K, class V, class hash = HashFunc<K>>
struct Hash_iterator
{typedef HashNode<K, V> HN;typedef HashTable<K, V, hash> HT;typedef Hash_iterator Self;HN* _node;HT* _ht;hash hs;Hash_iterator(HN* node, HT* ht):_node(node),_ht(ht){}//前置++Self& operator++();V& operator*();pair<K, V>* operator->();bool operator!=(const Self& it);};
- 操作实现
//前置++
Self& operator++()
{if (_node->_next){_node = _node->_next;}else{size_t hashi = hs(_node->_kv.first) % _ht->_table.size() + 1;_node = nullptr;//注while (hashi < _ht->_table.size()){if (_ht->_table[hashi]){_node = _ht->_table[hashi];break;}hashi++;}//后续没有元素,越界//_node = _ht->_table[hashi];}return *this;
}V& operator*()
{return _node->_kv.second;
}pair<K, V>* operator->()
{return &_node->_kv;
}bool operator!=(const Self& it)
{return _node != it._node;
}
- 缺省的key值处理仿函数
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//特化,常用string类型
template<>
struct HashFunc<string>
{size_t operator()(const string& str){size_t key = 0;for (auto e : str){key += e;key *= 131;}return key;}
};
3. unordered_set与unordered_map的封装
3.1 哈希桶的细节调整
- 使用哈希桶unordered_set与unordered_map的封装方式与红黑树封装map,set相似,调整模板参数,使得仅用一套模板即可封装出u_map与u_set,具体操作如下:
- 数据结点结构的调整
template <class T>//改
struct HashNode
{T _kv;HashNode<T>* _next;HashNode(const T& kv):_kv(kv),_next(nullptr){}
};
- 迭代器结构的调整
template<class K, class T, class KeyOfT, class hash = HashFunc<K>>
struct Hash_iterator
{typedef HashNode<T> HN;typedef HashTable<K, T, KeyOfT, hash> HT;typedef Hash_iterator Self;HN* _node;HT* _ht;hash hs;KeyOfT kot;//其后细节随之调整
};
- 哈希桶结构的调整
//将hash模板参数的缺省值提维
template <class K, class T, class KeyOfT, class hash>
class HashTable
{typedef HashNode<T> HashNode;typedef Hash_iterator<K, T, KeyOfT, hash> iterator;
private:vector<HashNode*> _table;size_t _n;hash hs;KeyOfT kot;friend struct iterator; public://其他内部方法细节随之调整//为适配上层unordered_map的operator[],返回值与实现细节做调整pair<iterator, bool> Insert(const T& kv);iterator Find(const K& key);
};
3.2 具体封装
- unordered_set
//缺省提维的原因
//并非直接使用哈希桶,而是通过us,um来间接使用**
template<class K, class hash = HashFunc<K>>
class myordered_set
{struct KeyOfT{K operator()(const K& key){return key;}};typedef Hash_iterator<K, K, KeyOfT, hash> iterator;typedef HashNode<K> HashNode;
public:iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> Insert(const K& key){return _ht.Insert(key);}iterator Find(const K& key){return _ht.Find(key);}bool Erase(const K& key){return _ht.Erase(key);}
private:HashTable<K, K, KeyOfT, hash> _ht;
};
- unordered_map
template<class K, class V, class hash = HashFunc<K>>
class myordered_map
{struct KeyOfT{K operator()(const pair<K, V>& kv){return kv.first;}};typedef Hash_iterator<K, pair<K, V>, KeyOfT, hash> iterator;typedef HashNode<pair<K, V>> HashNode;
public:iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> Insert(const pair<K, V>& kv){return _ht.Insert(kv);}iterator Find(const K& key){return _ht.Find(key);}V& operator[](const K& key){pair<iterator, bool> ret = Insert(make_pair(key, V()));return (ret.first)->second;}bool Erase(const K& key){return _ht.Erase(key);}private:HashTable<K, pair<K, V>, KeyOfT, hash> _ht;
};
相关文章:
C++进阶:哈希(1)
目录 1. 简介unordered_set与unordered_map2. 哈希表(散列)2.1 哈希表的引入2.2 闭散列的除留余数法2.2.1 前置知识补充与描述2.2.2 闭散列哈希表实现 2.3 开散列的哈希桶2.3.1 结构描述2.3.2 开散列哈希桶实现2.3.3 哈希桶的迭代器与key值处理仿函数 3.…...
第三节课,功能2:开发后端用户的管理接口-- postman--debug测试
一、如何使用postman 网址: https://www.postman.com/downloads/ 【Postman小白教程】五分钟学会如何使用Postman~_哔哩哔哩_bilibili postman安装使用_bowser agent在postman哪里-CSDN博客 二、下载后 登录,开始测试 2.1 关于postman 报错&#…...
Docker-compsoe部署prysm-beacon-chain + geth服务(geth版本v1.14.0)
1、创建目录结构 ~ # mkdir -p /data/docker-compose/eth ~ # cd /data/docker-compose/eth /data/docker-compose/eth# mkdir beacondata eth ethdata prysm2、编写prysm-beacon-chain Dockerfile和启动脚本文件 /data/docker-compose/eth# vim Dockerfile /data/docker-…...

前端人员如何理解进程和线程
进程和线程的概念: 进程和线程本质都是cpu工作过程的时间片。 进程可以理解为cpu在运行指令即加载保存上下文所要用的时间。也可以理解为一个应用程序运行的实例。 线程是进程中更小的单位,描述一段指令所需要的时间。 进程是资源分配的最小单位…...

Linux下网络命令
目录 需求1-查看本机是否存在22端口解法1解法2解法3 需求2-查看其他主机是否存在22端口解法1解法2解法3 需求3-查看TCP连接解法1/2 需求4-统计80端口tcp连接次数解法 需求5-查看总体网络速度解法 需求6-查看进程流量解法 需求7-dns解法 需求8-traceroute到baidu解法 需求9-查看…...

Php swoole和mqtt
在 PHP 中使用 Swoole 处理 MQTT 订阅消息是一种高效的方式,可以充分利用 Swoole 协程的非阻塞特性和高性能 I/O 处理能力。下面是一个示例代码,演示了如何使用 Swoole 的 MQTT 客户端来订阅消息,并加以详细说明。 1. 安装 Swoole 首先&…...

Spring STOMP-连接到消息代理
STOMP 代理中继维护一个与消息代理的“系统”TCP 连接。这个连接仅用于来自服务器端应用程序的消息,不用于接收消息。您可以为此连接配置STOMP凭据(即STOMP帧的login和passcode头部)。这在XML命名空间和Java配置中都以systemLogin和systemPas…...

Excel中的`MMULT`函数
Excel中的MMULT函数是一个用于执行矩阵乘法运算的函数。矩阵乘法是线性代数中的一个基本运算,它允许我们计算两个矩阵的乘积,得到一个新的矩阵。与普通的标量乘法不同,矩阵乘法涉及到行与列的对应元素相乘然后求和的过程。MMULT函数在进行数据…...

孩子多大可以接触python?学习python的好处
孩子接触Python的年龄并没有明确的界限,一般来说,6岁以上的孩子可以开始学习Python编程。虽然Python是一门高级编程语言,但它的语法简单易懂,适合初学者入门。通过学习Python编程,孩子可以培养逻辑思维、创造力和解决问…...

四川汇昌联信:拼多多网点怎么开?大概需要多少钱?
想要开一家拼多多网点,你肯定很关心需要准备多少资金。下面,我们就来详细解答这个问题,并从多个角度分析开设网点的要点。 一、 开设拼多多网点,首要任务是确定启动资金。根据不同的经营模式和地区差异,成本会有所不同…...
ROS 2边学边练(43)-- 利用GTest写一个基本测试(C++)
前言 在ROS(Robot Operating System)中,gtest(Google Test)是一个广泛使用的C测试框架,用于编写和执行单元测试。这些测试可以验证ROS节点、服务和消息等的正确性和性能。 如果我们需要在写的包中添加测试&…...

3.整数运算
系列文章目录 信息的表示和处理 : Information Storage(信息存储)Integer Representation(整数表示)Integer Arithmetic(整数运算)Floating Point(浮点数) 文章目录 系列文章目录前…...
返回一个列表(List))
uri.getQueryParameters(name)返回一个列表(List)
uri.getQueryParameters(name)返回一个列表(List)而不是单个值的原因在于URI(统一资源标识符)中查询参数(query parameters)的设计允许同一个名称(name)对应多个值。这意味着一个查询…...

鸿蒙ArkUI开发:常用布局【主轴】
ArkUI中常用布局容器 线性布局(Row/Column) 线性布局的子元素在线性方向上(水平方向和垂直方向)依次排列线性布局容器包括[Row]和[Column]。Column容器内子元素按照垂直方向排列,Row容器内子元素按照水平方向排列开发…...

Spring Security 入门 2
1.项目实战 就以RuoYi-Vue 为例吧,主要以下几点原因: 基于 Spring Security 实现。 基于 RBAC 权限模型,并且支持动态的权限配置。 基于 Redis 服务,实现登录用户的信息缓存。 前后端分离。同时前端采用 Vue ,相对来…...
C++初阶学习第七弹——探索STL奥秘(二)——string的模拟实现
标准库中的string:C初阶学习第六弹——string(1)——标准库中的string类-CSDN博客 前言: 在前面我们已经学习了如何使用标准库中的string类,但作为一个合格的程序员,我们不仅要会用,还要知道如…...

5.nginx常用命令和日志定时切割
一. nginx常用的相关命令介绍 1.强制关闭nginx: ./nginx -s stop 2.优雅的关闭nginx: ./nginx -s quit 3.检查配置文件是否正确: ./nginx -t 4.查看nginx版本: ./nginx -v 5.查看nginx版本相关的配置环境信息:./nginx -V 6.nginx帮助信…...

Redis-详解(基础)
文章目录 什么是Redis?用Redis的特点?用Redis可以实现哪些功能?Redis的常用数据类型有哪些?Redis的常用框架有哪些?本篇小结 更多相关内容可查看 什么是Redis? Redis(Remote DictionaryServer)是一个开源…...
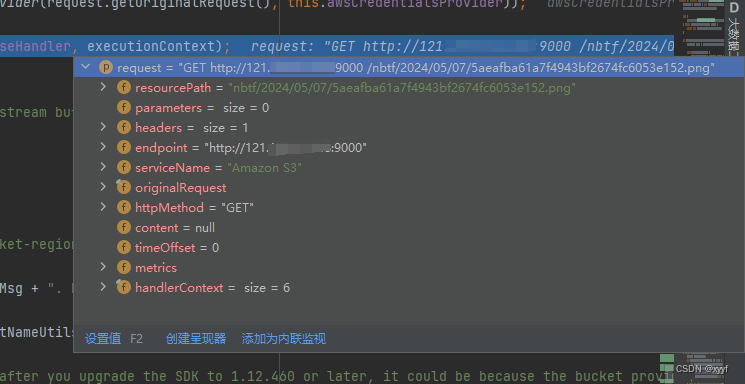
记录minio的bug(Object name contains unsupported characters.)
场景是我将后端服务从121.xxx.xxx.xxx服务器上转移到了另一台服务器10.xxx.xxx.xxx 但图片都还在121.xxx.xxx.xxx服务器上,同样我10.xxx.xxx.xxx也安装了minio并且我的后端服务配置的minio地址也是10.xxx.xxx.xxx 此时有一个业务通过minio客户端获取图片…...

【嵌入式开发 Linux 常用命令系列 7.6 -- sed 替换指定字符串】
请阅读【嵌入式开发学习必备专栏】 文章目录 sed 替换指定字符串 sed 替换指定字符串 背景: 找到当前目录下所有的.h 和 .c 文件 将他们中的字符 print_log替换为 demo_log 可以使用find命令结合sed命令在Linux环境下完成这项任务。下面是一个命令行示例ÿ…...

28 岁大专逆袭转行网络安全 资深前辈避坑忠告
网络安全行业 “人才缺口 300 万 、平均年薪超 25 万” 的红利,让无数职场人动了转行心思。尤其是学历普通(如大专)的群体,既面临原有岗位的天花板,又渴望通过技术转型实现薪资跃迁。但网安行业看似门槛低,…...

如何用开源歌词滚动姬3步制作专业LRC歌词:完全免费跨平台指南
如何用开源歌词滚动姬3步制作专业LRC歌词:完全免费跨平台指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker **歌词滚动姬(LRC Maker&#…...
)
保姆级教程:在Ubuntu 22.04上用Netplan搞定Bond+VLAN+Bridge混合网络(附H3C交换机配置)
企业级网络架构实战:Ubuntu 22.04下BondVLANBridge混合部署指南 在虚拟化环境和云计算基础设施中,网络架构的可靠性和灵活性至关重要。本文将深入探讨如何在Ubuntu 22.04系统上,通过Netplan配置工具实现Bond(链路聚合)…...

嵌入式开发新趋势:从硬件参数到场景方案,AI与可靠性成关键
1. 展会现场与行业风向初探上周,我作为飞凌嵌入式的一名老员工,亲身参与了2024上海国际嵌入式展。这不仅仅是一次简单的产品展示,更像是一场行业同仁的“华山论剑”。从人头攒动的展台到技术论坛上激烈的讨论,你能清晰地感受到&am…...

牛客周赛 Round 142 C题及D题题解
首先是C题: 咱们先看题目: 链接:https://ac.nowcoder.com/acm/contest/133790/C 来源:牛客网。 这道题其实特别简单,我们只需要按顺序遍历数组,统计能依次被 1、2、3... 整除的元素数量,即…...

PdrER算法:扩展解析在模型检查中的高效应用
1. PdrER算法核心原理与技术突破1.1 传统PDR算法的局限性分析Property Directed Reachability(PDR,也称为IC3)是当前最先进的模型检查算法之一,广泛应用于硬件和软件系统的安全属性验证。该算法通过构建归纳不变量(ind…...
)
STM32F4实战:用CubeMX和HAL库搞定MT6825磁编码器的SPI读取(附完整代码)
STM32F4实战:用CubeMX和HAL库搞定MT6825磁编码器的SPI读取(附完整代码) 在工业自动化、机器人控制和精密测量领域,高精度角度传感器是不可或缺的核心部件。MT6825作为一款14位绝对式磁旋转编码器芯片,以其SPI接口、0.3…...

从LR寄存器到问题函数:一次完整的Cortex-M HardFault调试实录与内存分析心得
从LR寄存器到问题函数:一次完整的Cortex-M HardFault调试实录与内存分析心得 引言:当MCU突然"罢工"时 那是一个周五的深夜,产品量产前的最后一周。测试工程师突然报告设备在特定操作序列下会无规律死机,串口日志最后一行…...

Qwen-Image-2512+LoRA:构建Godot 4.x原生像素编译工作流
1. 这不是“AI画图”,而是一次像素艺术工作流的底层重构你有没有试过在Godot 4.x里导入一张Stable Diffusion生成的“像素风”图,结果放大一看全是模糊的伪像素、边缘发虚、色阶溢出,连8-bit调色板都对不上?我去年帮三个独立游戏团…...

开源架构企业管理软件适合哪些类型的公司
开源架构企业管理软件适合哪些类型的公司 很多人一听到“开源架构”,第一反应是技术人员、开发者、极客项目。放到企业管理软件里,其实开源架构更像一种长期可控的建设方式:企业能看见系统如何运行,也能在需要时改造它。 对中小…...