【408精华知识】速看!各种排序的大总结!

文章目录
- 一、插入排序
- (一)直接插入排序
- (二)折半插入排序
- (三)希尔排序
- 二、交换排序
- (一)冒泡排序
- (二)快速排序
- 三、选择排序
- (一)简单选择排序
- (二)堆排序
- 四、归并排序
- 五、基数排序
- 六、计数排序
- 七、外部排序
一、插入排序
(一)直接插入排序
算法思想:每次将一个待排序元素按其关键字大小插入到已排好序的序列中,直至所有元素都被排完。
1.排序过程:1)比较:将待排序元素与其左侧的已排序序列从后向前比较,直至找到它的位置;2)移动:将其待放位置的原元素与右侧元素全部右移一位;3)对下一个待排序元素继续执行1)、2)操作。
2.举个例子:

3.算法特点:待排序元素左边的序列是已排好序的序列,右边的序列是未排序序列。
4.时间复杂度:
1)最好情况:最好情况是有序序列,每个元素只需要和其左侧第一个元素比较一次,无需移动,故这种情况下的时间复杂度是O(n)。
2)最坏情况:最坏情况是倒序序列,每个元素要每个元素要和其左侧所有元素比较,故这种情况下的时间复杂度是O(n2)。
3)平均情况:取上述最好与最坏情况的平均值作为平均情况下的时间复杂度,故这种情况下的时间复杂度是O(n2)。
5.空间复杂度:仅使用了常数个辅助单元,因而空间复杂度为O(1)。
6.是否稳定: 因为每次插入元素时总是从后往前先比较再移动,所以不会出现相同元素相对位置发生变化的情况,即直接插入排序是一个稳定的排序算法。
7.适用性:适用于顺序存储和链式存储的线性表,采用链式存储时无须移动元素。
8.C语言代码:
void InsertSort(ElemType A[],int n){int i,j;for(i=2;i<=n;i++){ //依次将A[2]-A[n]插入前面已排序的序列 if(A[i]<A[i-1]){ //若A[i]关键码小于其前驱,将A[i]插入有序表 A[0]=A[i]; //复制为哨兵,A[0]不存放元素 for(j=i-1;A[0]<A[j];--j){ //从后向前查找待插入元素 A[j+1]=A[j]; //向后挪位 }A[j+1]=A[0]; //复制到插入位置 }}
}
(二)折半插入排序
算法思想:对直接插入排序进行改进,折半查找出元素的待插入位置,然后统一地移动待插入位置之后的所有元素。
1.排序过程:1)比较:将待排序元素与其左侧的已排序序列折半比较,直至找到它的位置;2)移动:将其待放位置的原元素与右侧元素全部右移一位;3)对下一个待排序元素继续执行1)、2)操作。
2.举个例子:

3.算法特点:对直接插入排序的改进,仅减少了比较元素的次数,可以提交时间效率,对于数据量不很大的排序表,折半插入排序往往能表现出很好的性能。
4.时间复杂度:
1)最好情况:最好情况是有序序列,折半插入排序减少了元素的平均比较次数,且折半插入的比较次数与初始状态无关,其移动次数与直接插入排序是一样的,故在最好情况下,每个元素需要比较,时间复杂度为O( n l o g 2 n nlog_2{n} nlog2n),其中n是元素个数,O( l o g 2 n log_2{n} log2n)是每个元素需要比较的次数。
2)最坏情况:最坏情况是倒序序列,共n个元素,此时每个元素需要比较O( l o g 2 n log_2{n} log2n)次,但每个元素需要移动O(n)次,所以总的时间复杂度和直接插入排序一样,还是O(n2)。
3)平均情况:取上述最好与最坏情况的平均值作为平均情况下的时间复杂度,故这种情况下的时间复杂度是O(n2)。
5.空间复杂度:仅使用了常数个辅助单元,因而空间复杂度为O(1)。
6.是否稳定:同样值的元素,左侧的一定会出现在右侧的前面,故是稳定的。
7.适用性:涉及到给定数组下标找相应的数组元素的问题,所以只适用于顺序存储的线性表。
8.C语言代码:
void InsertSort(ElemType A[],int n){int i,j,low,high,mid;for(i=2;i<=n;i++){ //依次将A[2]-A[n]插入前面已排序的序列 A[0]=A[i]; //暂存至A[0]low=1;high=i-1; //设置折半查找的范围while(low<=high){mid=(low+high)/2; //取中间点if(A[mid]>A[0]){high=mid-1; //查找左半子表 } else loe=mid+1; //查找右半子表 } for(j=i-1;j>=high+1;--j){A[j+1]=A[j]; //统一后移元素,空出插入位置 }A[high+1]=A[0]; //插入操作 }
}
(三)希尔排序
算法思想:从前面的分析可知,直接插入排序算法的时间复杂度为O(n2),但若待排序列为“正序”时,其时间效率可提高至O(n),由此可见它更适用于基本有序的排序表和数据量不大的排序表。希尔排序正是基于这两点分析对直接插入排序进行改进而得来的,先将待排序表分割成若干形如L[i,i+d,i+2d,⋯,i+kd]的“特殊”子表,即把相隔某个“增量”的记录组成一个子表,对各个子表分别进行直接插入排序,当整个表中的元素已呈“基本有序”时,再对全体记录进行一次直接插入排序。
1.排序过程:取增量d,使所有距离为d的元素为一组,进行直接插入排序,直至d取到1。
2.举个例子:

3.算法特点:根据希尔排序的特点,可以发现,在希尔排序的过程中,是按增量段有序的,可以通过这个特点判断一个排序过程是否是希尔排序或者是以多大增量进行插入排序的希尔排序。
4.时间复杂度:因为希尔排序的时间复杂度依赖于增量序列的函数,这涉及数学上尚未解决的难题,所以其时间复杂度分析比较困难。当n在某个特定范围时,希尔排序的时间复杂度约为O(n1.3)。在最坏情况下希尔排序的时间复杂度为O(n2)。
5.空间复杂度:仅使用了常数个辅助单元,因而空间复杂度为O(1)。
6.是否稳定: 由于是按增量进行插入排序,可能导致相同值元素相对位置发生变化,因此是不稳定的。
7.适用性:涉及到给定数组下标找相应的数组元素的问题,所以只适用于顺序存储的线性表。
8.C语言代码:
void ShellSort(ElemType A[],int n){
//A[0]只是暂存单元,不是哨兵,当j<=0时,插入位置已到 for(dk=n/2;dk>=1;dk=dk/2){ //步长变化 for(i=dk+1;i<n;++i){if(A[i]<A[i-dk]){ //需将A[i]插入有序增量子表 A[0]=A[i]; //暂存在A[0]; for(j=i-dk;j>0&&A[0]<A[j];j-=dk){A[j+dk]=A[j]; //记录后移,寻找插入的位置 }A[j+dk]=A[0]; //插入 }}}
}
二、交换排序
(一)冒泡排序
算法思想:冒泡排序恰如其名,是将最大(最小)元素一个个浮上水面,最终得到有序序列。
1.排序过程:从后往前(或从前往后)两两比较相邻元素的值,若为逆序(即
A[i-1]>A[i]),则交换它们,直到序列比较完,这称为一次冒泡。重复冒泡,直至成为有序序列。
2.举个例子:
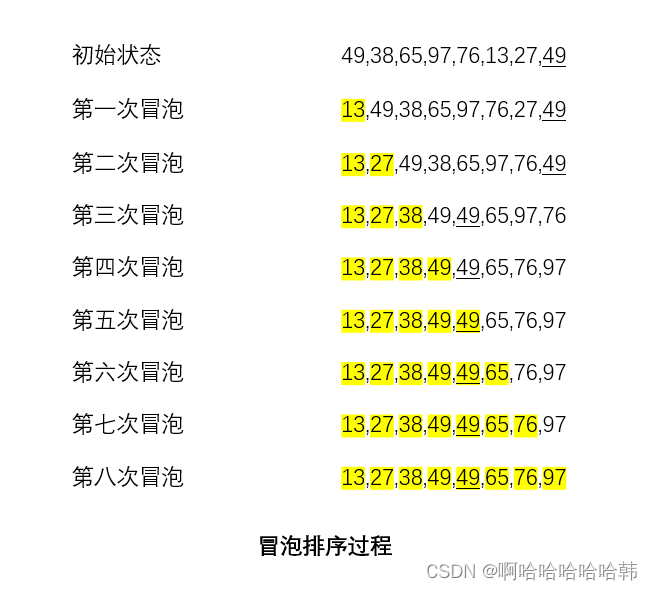
3.算法特点:冒泡排序中所产生的有序子序列一定是全局有序的(不同于直接插入排序),也就是说,有序子序列中的所有元素的关键字一定小于(或大于)无序子序列中所有元素的关键字,这样每趟排序都会将一个元素放置到其最终的位置上,因此会有前面的部分元素或者后面的部分元素是有序的。
4.时间复杂度:
1)最好情况:当初始序列有序时,显然第一趟冒泡后flag依然为false(本趟没有元素交换),从而直接跳出循环,比较次数为n-1,移动次数为0,从而最好情况下的时间复杂度为O(n)。
2)最坏情况:最坏情况是逆序序列,此时每个元素需要比较和交换O(n)次,所有元素排完序后比较和交换O(n2)次,也即时间复杂度为O(n2)。
3)平均情况:取上述最好与最坏情况的平均值作为平均情况下的时间复杂度,故这种情况下的时间复杂度是O(n2)。
5.空间复杂度:仅使用了常数个辅助单元,因而空间复杂度为O(1)。
6.是否稳定: 如果是从后往前排,假如是同值元素,后面的元素无法浮到前面的元素的前面,也就是相对位置不会改变,即算法稳定。
7.适用性:冒泡排序适用于顺序存储和链式存储的线性表。
8.C语言代码:
void BubbleSort(ElemType A[],int n){for(i=0;i<n-1;i++){flag=false;//表示本趟冒泡是否发生交换的标志for(j=n-1;j>i;j--){ //一趟冒泡过程 if(A[j-1]>A[j]){ //若为逆序 swap(A[j-1],A[j]); //交换 flag=true;}}if(flag==false) return; //本趟遍历后没有发生交换,说明表已有序 }
}
(二)快速排序
算法思想:基于分治法,其中分是划分为两部分,治是在这两部分上分别采用快速排序。在待排序表L[1.n]中任取一个元素 pivot 作为枢轴(或称基准,通常取首元素),通过一趟排序将待排序表划分为独立的两部分L[1⋯k-1]和L[k+1⋯n],使得L[1⋯k-1]中的所有元素小于pivot,L[k+1.n]中的所有元素大于或等于pivot,则pivot放在了其最终位置L(k)上,这个过程称为一次划分。然后分别递归地对两个子表重复上述过程,直至每部分内只有一个元素或为空为止,即所有元素放在了其最终位置上。
1.排序过程:
1)设两个指针i和j,初值分别为low和 high,取第一个元素(值为low)为枢轴赋值到变量 pivot;
2)指针j从high往前搜索找到第一个小于枢轴的元素,将其交换到i所指位置;指针i从low往后搜索找到第一个大于枢轴的元素,将其交换到j所指位置;
3)重复2),直至i==j;
4)对pivot两边的元素再从1)开始进行快排。
2.举个例子:

3.算法特点:快速排序是所有内部排序算法中平均性能最优的排序算法,其每趟排序都能确定枢轴元素的最终位置。
4.时间复杂度:快速排序的运行时间与划分是否对称有关,有很多方法可以提高算法的效率:一种方法是尽量选取一个可以将数据中分的枢轴元素,如从序列的头尾及中间选取三个元素,再取这三个元素的中间值作为最终的枢轴元素;或者随机地从当前表中选取枢轴元素,这样做可使得最坏情况在实际排序中几乎不会发生。
1)最好情况:在最理想的状态下,即Partition()能做到最平衡的划分,得到的两个子问题的大小都不可能大于 n/2,在这种情况下,快速排序的运行速度将大大提升,此时,时间复杂度为O( n l o g 2 n nlog_2{n} nlog2n)。
2)最坏情况:快速排序的最坏情况发生在两个区域分别包含n-1个元素和0个元素时,这种最大限度的不对称性若发生在每层递归上,即对应于初始排序表基本有序或基本逆序时,就得到最坏情况下的时间复杂度为O(n2)。
3)平均情况:平均情况下为O(n2)。
5.空间复杂度:由于快速排序是递归的,因此需要借助一个递归工作栈来保存每层递归调用的必要信息,其容量与递归调用的最大层数一致。
1)最好情况:最好情况下为O( l o g 2 n log_2{n} log2n);
2)最坏情况:最坏情况下,要进行n-1次递归调用,因此栈的深度为O(n);
3)平均情况:平均情况下为O( l o g 2 n log_2{n} log2n)。
6.是否稳定:在划分算法中,若右端区间有两个关键字相同,且均小于基准值的记录,则在交换到左端区间后,它们的相对位置会发生变化,即快速排序是一种不稳定的排序算法。
7.适用性:涉及到给定数组下标找相应的数组元素的问题,所以只适用于顺序存储的线性表。
8.C语言代码:
void QuickSort(ElemType A[],int low,int high){if(low<high){ //递归跳出的条件 //Partition()是划分操作,将表A划分为满足上述条件的两个子表int p=Partition(A,low,high); //划分QuickSort(A,low,p-1); //依次对两个子表进行递归排序QuickSort(A,p+1,high); }
}int Partition(ElemType A[],int low,int high){ //一趟划分 ElemType pivot=A[low]; //将表中第一个元素设置为枢轴,对表进行划分while(low<high){ //循环跳出条件 while(low<high&&A[high]>=pivot) --high;A[low]=A[high]; //将比枢轴元素小的移动至左端 while(low<high&&A[low]<=pivot) ++low;A[high]=A[hlow]; //将比枢轴元素大的移动至右端 } A[low]=pivot; //枢轴元素存放至最终位置
}三、选择排序
(一)简单选择排序
算法思想::每一趟(如第i趟)在后面n-i+1(i=1,2,⋯,n-1)个待排序元素中选取关键字最小的元素,作为有序子序列的第i个元素,直到第n-1趟做完,待排序元素只剩下1个,就不用再选。
1.排序过程:假设排序表为L[1⋯n],第i趟排序即从L[i⋯n]中选择关键字最小的元素与L(i)交换,每一趟排序可以确定一个元素的最终位置,这样经过n-1趟排序就可使得整个排序表有序。
2.举个例子:
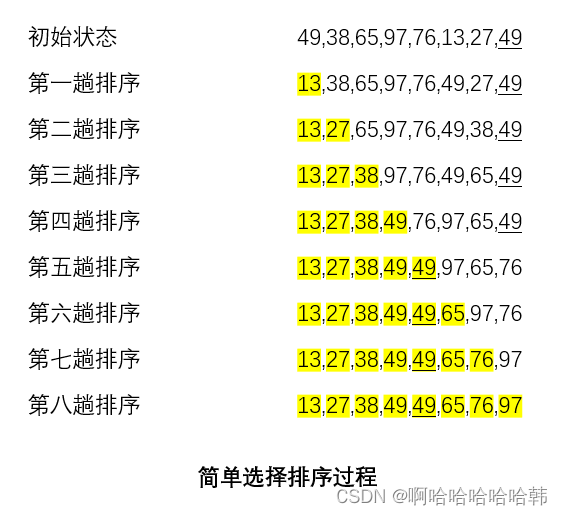
3.算法特点:排序过程中前面部分或者后面部分的元素是有序的。
4.时间复杂度:从上述伪码中不难看出,在简单选择排序过程中,元素移动的操作次数很少,不会超过3(n-1)次,最好的情况是移动0次,此时对应的表已经有序;但元素间比较的次数与序列的初始状态无关,始终是n(n-1)/2次,因此时间复杂度始终是O(n2)。
5.空间复杂度:仅使用常数个辅助单元,所以空间效率为O(1)。
6.是否稳定: 在第i趟找到最小元素后,和第i个元素交换,可能会导致第i个元素与含有相同关键字的元素的相对位置发生改变,简单选择排序是一种不稳定的排序算法。
7.适用性:简单选择排序适用于顺序存储和链式存储的线性表,以及关键字较少的情况。
8.C语言代码:
void SelectSort(ElemType A[],int n){for(i=0;i<n-1;i++){ //共进行n-1趟 min=i; //记录最小元素位置 for(j=i+1;j<n;j++){ //在A[]中选择最小的元素 if(A[j]<A[min]) min=j; //更新最小元素位置 }if(min!=i)swap(A[i],A[min]);}
}
(二)堆排序
算法思想:堆排序的思路很简单:先初始化堆,然后调整堆。
1.排序过程:
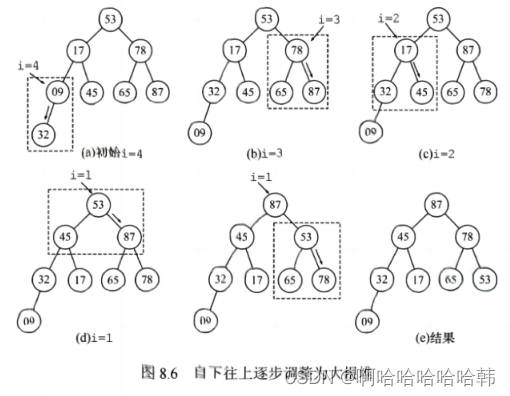
1)初始化堆:将存放在L[1⋯n]中的元素从上至下按层排列成一个堆,然后从下至上依次比较左右结点并将较大元素与其对应的父结点交换((以大顶堆为例)),因为堆本身的特点,所以堆顶元素就是最大值。
2)输出堆顶元素后,通常将堆底元素送入堆顶,此时根结点已不满足大顶堆的性质,堆被破坏,将堆顶元素向下调整使其继续保持大顶堆的性质,再输出堆顶元素。如此重复,直到堆中仅剩一个元素为止。
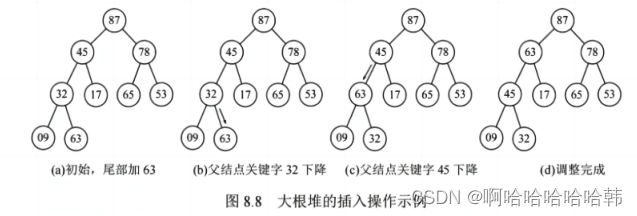
3)如果后续再插入,先将新结点放在堆的末端,再对这个新结点向上执行调整操作。
2.举个例子:
1)初始化堆:
2)调整堆:

3)插入元素:
3.算法特点:每趟都能确定一个元素在其最终位置。
4.时间复杂度:建堆时间为O(n),之后有n-1次向下调整操作,每次调整的时间复杂度为O(h),所以在最好、最坏和平均情况下,堆排序的时间复杂度为O( n l o g 2 n nlog_2{n} nlog2n)。
5.空间复杂度:仅使用了常数个辅助单元,所以空间复杂度为O(1)。
6.是否稳定: 进行筛选时,有可能把后面相同关键字的元素调整到前面,所以堆排序算法是一种不稳定的排序算法。
7.适用性:堆排序仅适用于顺序存储的线性表。
8.C语言代码:
void HeadAdjust(ElemType A[],int k,int len){//函数将k为根的子树进行调整A[0]=A[k]; //A[0]暂存子树的根节点for(i=2*k;i<=len;i*=2){if(i<len&&A[i]<A[i+1]){i++; //取key较大的子结点的下标 }if(A[0]>=A[i]) break; //筛选结束else{A[k]=A[i]; //将A[i]调整到双亲结点上k=i; } } A[k]=A[0]; //将筛选结点的值放入最终位置
}void BuildMaxHeap(ElemType A[],int len){for(int i=len/2;i>0;i--){ //从i=[n/2]--1,反复调整堆 HeadAdjust(A,i,len);}
}void HeapSort(ElemType A[],int len){BuildMaxHeap(A,len); //初始建堆for(i=len;i>1;i--){ //n-1趟的交换和建堆的过程 Swap(A[i],A[1]); //输出堆顶元素(和堆底元素交换) HeadAdjust(A,1,i-1); //调整,把剩余的i-1个元素整理成堆 }
}
四、归并排序
算法思想:归并排序与上述基于交换、选择等排序的思想不一样,归并的含义是将两个或两个以上的有序表合并成一个新的有序表。
1.排序过程:假定待排序表含有n个记录,则可将其视为n个有序的子表,每个子表的长度为1,然后两两归并,得到「n/2]个长度为2或1的有序表;继续两两归并⋯⋯如此重复,直到合并成一个长度为n的有序表为止,这种排序算法称为二路归并排序。
2.举个例子:

3.算法特点:逐段有序。
4.时间复杂度:每趟归并的时间复杂度为O(n),共需进行「log?n]趟归并,因此算法的时间复杂度为O( n l o g 2 n nlog_2{n} nlog2n)。
5.空间复杂度:Merge()操作中,辅助空间刚好为n个单元,因此算法的空间复杂度为O(n)。
6.是否稳定: 由于 Merge()操作不会改变相同关键字记录的相对次序,因此二路归并排序算法是一种稳定的排序算法。
7.适用性:归并排序适用于顺序存储和链式存储的线性表。
8.C语言代码:
int *B=(int *)malloc(n*sizeof(int)); //辅助数组B//A[low...mid]和A[mid+...high]各自有序,将两个部分归并
void Merge(int A[],int low,int mid,int high){int i,j,k;for(k=low;k<high;k++)B[k]=A[k]; //将A中所有元素复制到B中for(i=low,j=mid+1,k=i;i<mid&&j<=high;k++){if(B[i]<=B[j])A[k]=B[i++]; //将较小值复制到A中elseA[k]=B[j++]; } while(i<=mid) A[k++]=B[i++];while(j<=high) A[k++]=B[j++];
} void MergeSort(int A[],int low,int high){if(low<high){int mid=(low+high)/2; //从中间划分MergeSort(A,low,mid); //对左半部分进行归并排序MergeSort(A,mid+1,high); //对右半部分进行归并排序Merge(A,low,mid,high); //归并 }
}
五、基数排序
算法思想:基数排序是一种很特别的排序算法,它不基于比较和移动进行排序,而基于关键字各位的大小进行排序。基数排序是一种借助多关键字排序的思想对单逻辑关键字进行排序的方法。
1.排序过程:

2.举个例子:
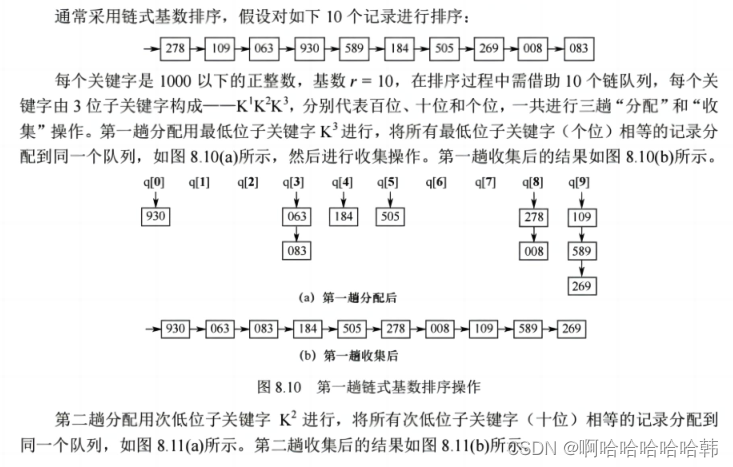
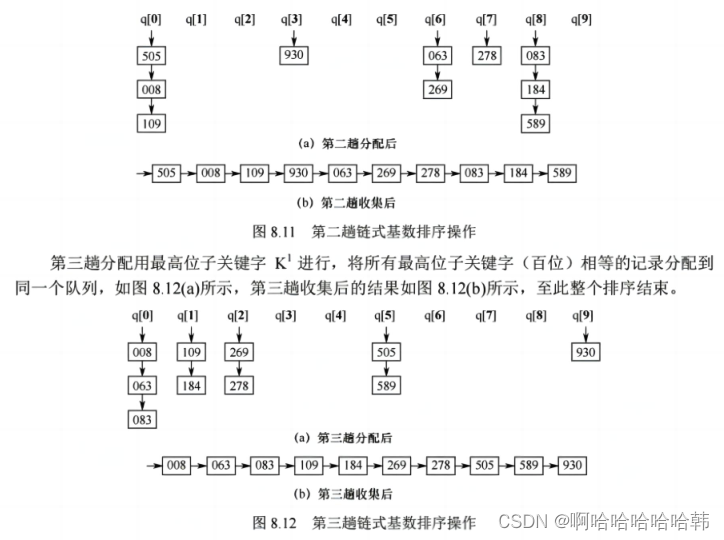
3.算法特点:逐位有序。
4.时间复杂度:基数排序需要进行d趟“分配”和”收集”操作。一趟分配需要遍历所有关键字,时间复杂度为O(n);一趟收集需要合并r个队列,时间复杂度为O®。因此基数排序的时间复杂度为O(d(n+r)),它与序列的初始状态无关。
5.空间复杂度:一趟排序需要的辅助存储空间为r(r个队列:r个队头指针和r个队尾指针),但以后的排序中会重复使用这些队列,所以基数排序的空间复杂度为O®。
6.是否稳定: 每一趟分配和收集都是从前往后进行的,不会交换相同关键字的相对位置,因此基数排序是一种稳定的排序算法。
7.适用性:基数排序适用于顺序存储和链式存储的线性表。
8.C语言代码:
void RadixSort(int* arr, int n){//max为数组中最大值int max = arr[0];int base = 1;//找出数组中的最大值for (int i = 0; i < n; i++){if (arr[i] > max){max = arr[i];}}//循环结束max就是数组最大值//临时存放数组元素的空间int* tmp = (int*)malloc(sizeof(int)*n);//循环次数为最大数的位数while (max / base > 0){//定义十个桶,桶里面装的不是数据本身,而是每一轮排序对应(十、白、千...)位的个数//统计每个桶里面装几个数int bucket[10] = { 0 };for (int i = 0; i < n; i++){//arr[i] / base % 10可以取到个位、十位、百位对应的数字bucket[arr[i] / base % 10]++;}//循环结束就已经统计好了本轮每个桶里面应该装几个数//将桶里面的元素依次累加起来,就可以知道元素存放在临时数组中的位置for (int i = 1; i < 10; i++){bucket[i] += bucket[i - 1];}//循环结束现在桶中就存放的是每个元素应该存放到临时数组的位置//开始放数到临时数组tmpfor (int i = n - 1; i >= 0; i--){tmp[bucket[arr[i] / base % 10] - 1] = arr[i];bucket[arr[i] / base % 10]--;}//不能从前往后放,因为这样会导致十位排好了个位又乱了,百位排好了十位又乱了//把临时数组里面的数拷贝回去for (int i = 0; i < n; i++){arr[i] = tmp[i];}base *= 10;}free(tmp);
}
六、计数排序
算法思想:计数排序也是一种不基于比较的排序算法。计数排序的思想是:对每个待排序元素x,统计小于x的元素个数,利用该信息就可确定x的最终位置。
1.排序过程:假设输入是一个数组 A[n],序列长度为 n,我们还需要两个数组:B[n]存放输出的排序序列,c[k]存储计数值。用输入数组A中的元素作为数组c的下标(索
引),而该元素出现的次数存储在该元素作为下标的数组c中。
2.举个例子:
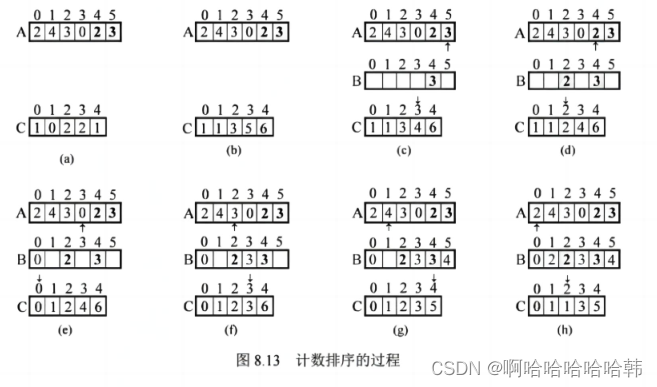
3.算法特点:计数排序适用于序列中的元素是整数。
4.时间复杂度:上述代码的第1个和第3个 for循环所花的时间为O(k),第2个和第4个 for 循环所花的时间为O(n),总时间复杂度为O(n+k)。因此,当k=O(n)时,计数排序的时间复杂度为O(n);但当k>O(nlogn)时,其效率反而不如一些基于比较的排序(如快速排序、堆排序等)。
5.空间复杂度:计数排序是一种用空间换时间的做法。输出数组的长度为n;辅助的计数数组的长度为k,空间复杂度为O(n+k)。若不把输出数组视为辅助空间,则空间复杂度为O(k)。
6.是否稳定: 相同元素在输出数组中的相对位置不会改变,因此计数排序是一种稳定的排序算法。
7.适用性:计数排序更适用于顺序存储的线性表。计数排序适用于序列中的元素是整数且元素范围(0~k-1)不能太大,否则会造成辅助空间的浪费。
8.C语言代码:
void CountSort(ElemType A[],ElemType B[],int n,int k){int i,c[k];for(i=0;i<k;i++){c[i]=0; //初始化计数数组} for(i=0;i<n;i++){ //遍历输入数组,统计每个元素出现的次数C[A[i]]++; //c[A[i]]保存的是等于A[i]的元素个数}for(i=1;i<k;i++){c[i]=C[i]+C[i-1]; //C[x]保存的是小于或等于x的元素个数}for(i=n-1;i>=0;i--){ //从后往前遍历输入数组B[C[A[i]-1]]=A[i]; //将元素A[i]放在输出数组 B[]的正确位置上C[A[i]]=C[A[i]]-1;}
}
七、外部排序
算法思想:上述排序算法都是内部排序,而在许多应用中,经常需要对大文件进行排序,因为文件中的记录很多,无法将整个文件复制进内存中进行排序。因此,需要将待排序的记录存储在外存上,排序时再把数据一部分一部分地调入内存进行序,在排序过程中需要多次进行内存和外存之间的交换。这种排序算法就称为外部排序。
1.排序过程:外部排序通常采用归并排序算法。它包括两个阶段:①根据内存缓冲区大小,将外存上的文件分成若干长度为C的子文件,依次读入内存并利用内部排序算法对它们进行排序,并将排序后得到的有序子文件重新写回外存,称这些有序子文件为归并段或顺串;②对这些归并段进行逐趟归并,使归并段(有序子文件)逐渐由小到大,直至得到整个有序文件为止。
为减少平衡归并中外存读/写次数以提高排序速度所采取的方法:增大归并路数和减少归并段个数。
①利用败者树增大归并路数;
②利用置换-选择排序增大归并段长度来减少归并段个数;
③由长度不等的归并段进行多路平衡归并,需要构造最佳归并树。
关于提高外部排序速度的三种方式,我将在下一篇文章中说明:【408精华知识】提高外部排序速度的三种方式
3.时间效率:文件通常是按块存储在磁盘上的,操作系统也是按块对磁盘上的信息进行读/写的。因为磁盘读/写的机械动作所需的时间远远超过在内存中进行运算的时间(相比而言可以忽略不计),因此在外部排序过程中的时间代价主要考虑访问磁盘的次数,即 I/O 次数。
小总结
1)我们大致可以发现,与二叉树、折半有关的排序,其时间复杂度都有log,这可以帮助我们记忆各种排序的时间复杂度。
2)在排序过程中,每趟都能确定一个元素在其最终位置的有冒泡排序、简单选择排序、堆排序、快速排序,其中前三者能形成全局有序的子序列,后者能确定枢轴元素的最终位置。
3)内部排序(在内存中进行的排序)包括插入、交换、选择、归并、基数、计数。
写在后面
这个专栏主要是我在学习408真题的过程中总结的一些笔记,因为我学的也很一般,如果有错误和不足之处,还望大家在评论区指出。希望能给大家的学习带来一点帮助,共同进步!!!
参考文献
[1]王道408教材(2025版)
相关文章:
【408精华知识】速看!各种排序的大总结!
文章目录 一、插入排序(一)直接插入排序(二)折半插入排序(三)希尔排序 二、交换排序(一)冒泡排序(二)快速排序 三、选择排序(一)简单选…...
【STM32 |程序实例】按键控制、光敏传感器控制蜂鸣器
目录 前言 按键控制LED 光敏传感器控制蜂鸣器 前言 上拉输入:若GPIO引脚配置为上拉输入模式,在默认情况下(GPIO引脚无输入),读取的GPIO引脚数据为1,即高电平。 下拉输入:若GPIO引脚配置为下…...

Spring boot使用websocket实现在线聊天
maven依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spr…...

品牌设计理念和logo设计方法
一 品牌设计的目的 设计是为了传播,让传播速度更快,传播效率更高,减少宣传成本 二 什么是好的品牌设计 好的设计是为了让消费者更容易看懂、记住的设计, 从而辅助传播, 即 看得懂、记得住。 1 看得懂 就是让别人看懂…...

Python | Leetcode Python题解之第88题合并两个有序数组
题目: 题解: class Solution:def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:"""Do not return anything, modify nums1 in-place instead."""p1, p2 m - 1, n - 1tail m n - 1whi…...

vscode新版本remotessh服务端报`GLIBC_2.28‘ not found解决方案
问题现象 通过vscode的remotessh插件连接老版本服务器(如RHEL7,Centos7)时,插件会报错,无法连接。 查看插件的错误日志可以看到类似如下的报错信息: dc96b837cf6bb4af9cd736aa3af08cf8279f7685/node: /li…...
盘他系列——oj!!!
1.Openjudge 网站: OpenJudge 2.洛谷 网站: 首页 - 洛谷 | 计算机科学教育新生态 3.环球OJ 网站: QOJ - QOJ.ac 4. 北京大学 OJ:Welcome To PKU JudgeOnline 5.自由OJ 网站: https://loj.ac/ 6.炼码 网站:LintCode 炼码 8.力扣 网站: 力扣 9.晴练网首页 - 晴练网...

洛谷 P2657 [SCOI2009] windy 数 题解 数位dp
[SCOI2009] windy 数 题目背景 windy 定义了一种 windy 数。 题目描述 不含前导零且相邻两个数字之差至少为 2 2 2 的正整数被称为 windy 数。windy 想知道,在 a a a 和 b b b 之间,包括 a a a 和 b b b ,总共有多少个 windy 数&…...

Python爬虫入门:网络世界的宝藏猎人
今天阿佑将带你踏上Python的肩膀,成为一名网络世界的宝藏猎人! 文章目录 1. 引言1.1 简述Python在爬虫领域的地位1.2 阐明学习网络基础对爬虫的重要性 2. 背景介绍2.1 Python语言的流行与适用场景2.2 网络通信基础概念及其在数据抓取中的角色 3. Python基…...
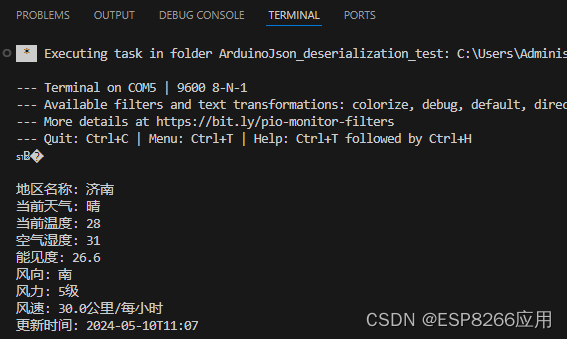
【NodeMCU实时天气时钟温湿度项目 6】解析天气信息JSON数据并显示在 TFT 屏幕上(心知天气版)
今天是第六专题,主要内容是:导入ArduinoJson功能库,借助该库解析从【心知天气】官网返回的JSON数据,并显示在 TFT 屏幕上。 如您需要了解其它专题的内容,请点击下面的链接。 第一专题内容,请参考&a…...

重构四要素:目的、对象、时机和方法
目录 1.引言 2.重构的目的:为什么重构(why) 3.重构的对象:到底重构什么(what) 4.重构的时机:什么时候重构(when) 5.重构的方法:应该如何重构(how) 6.思考题 1.引言 一些软件工程师对为什么要重构(why)、到底重构什么(what)、什么时候重构(when)应该如何重构(how)等问题的…...
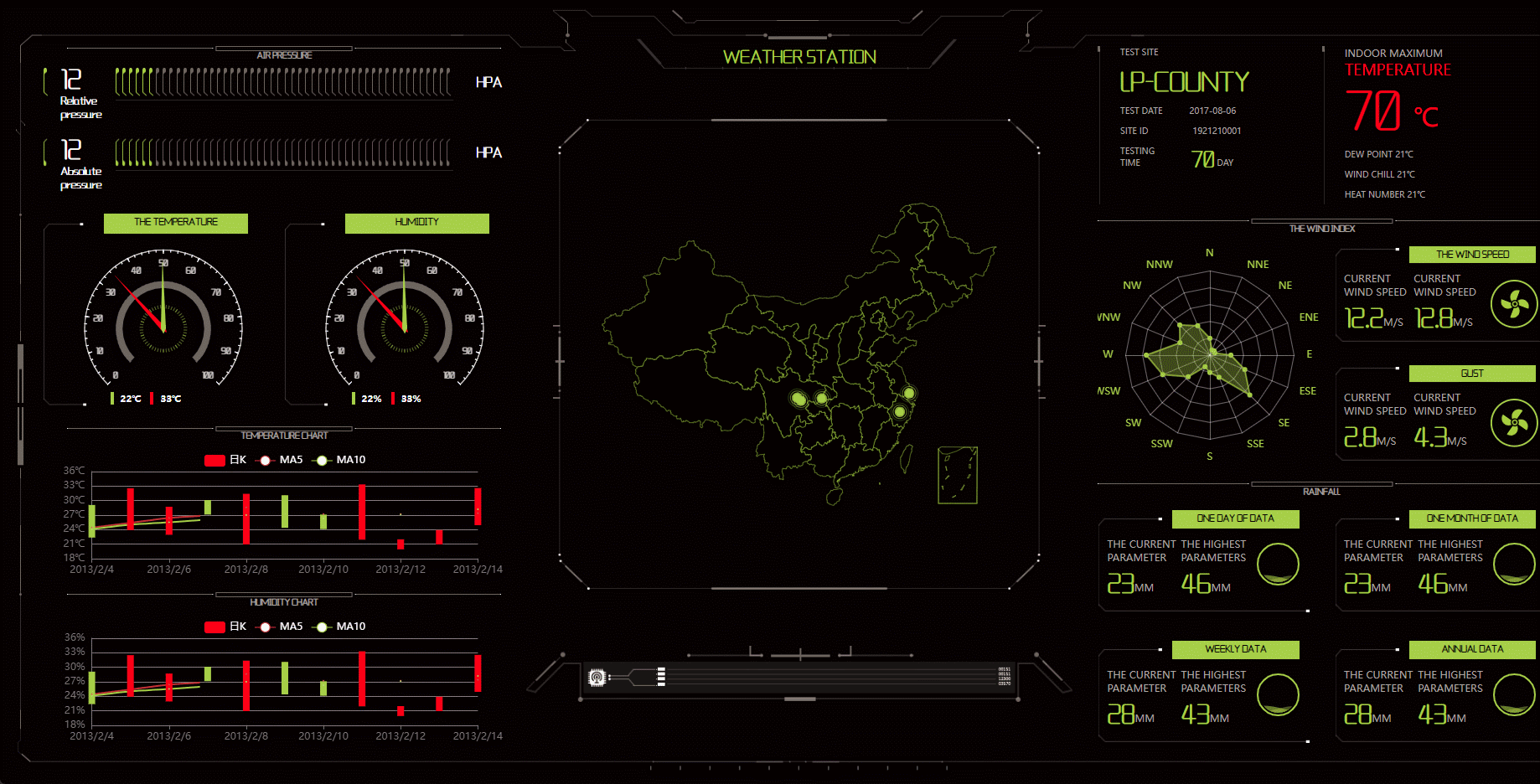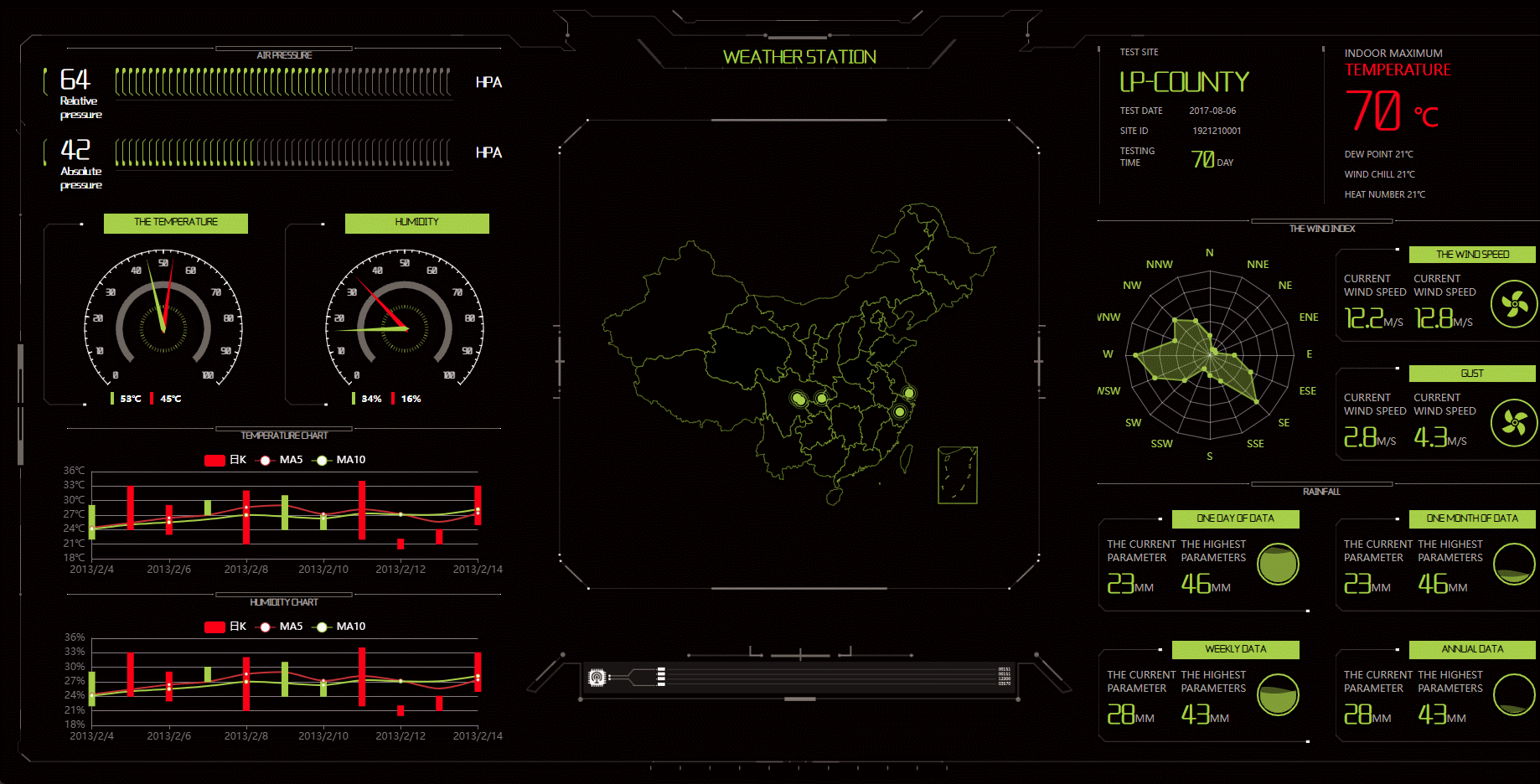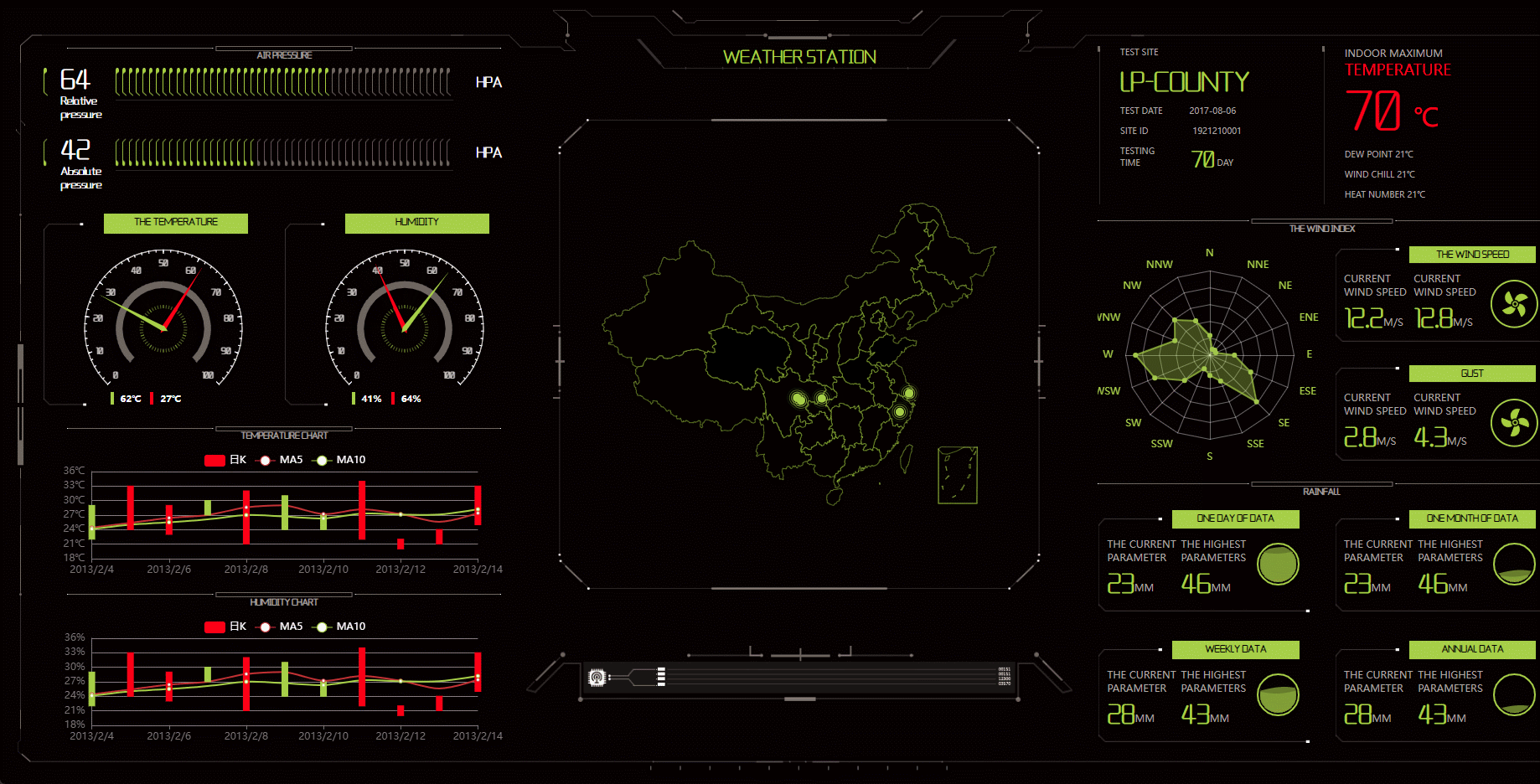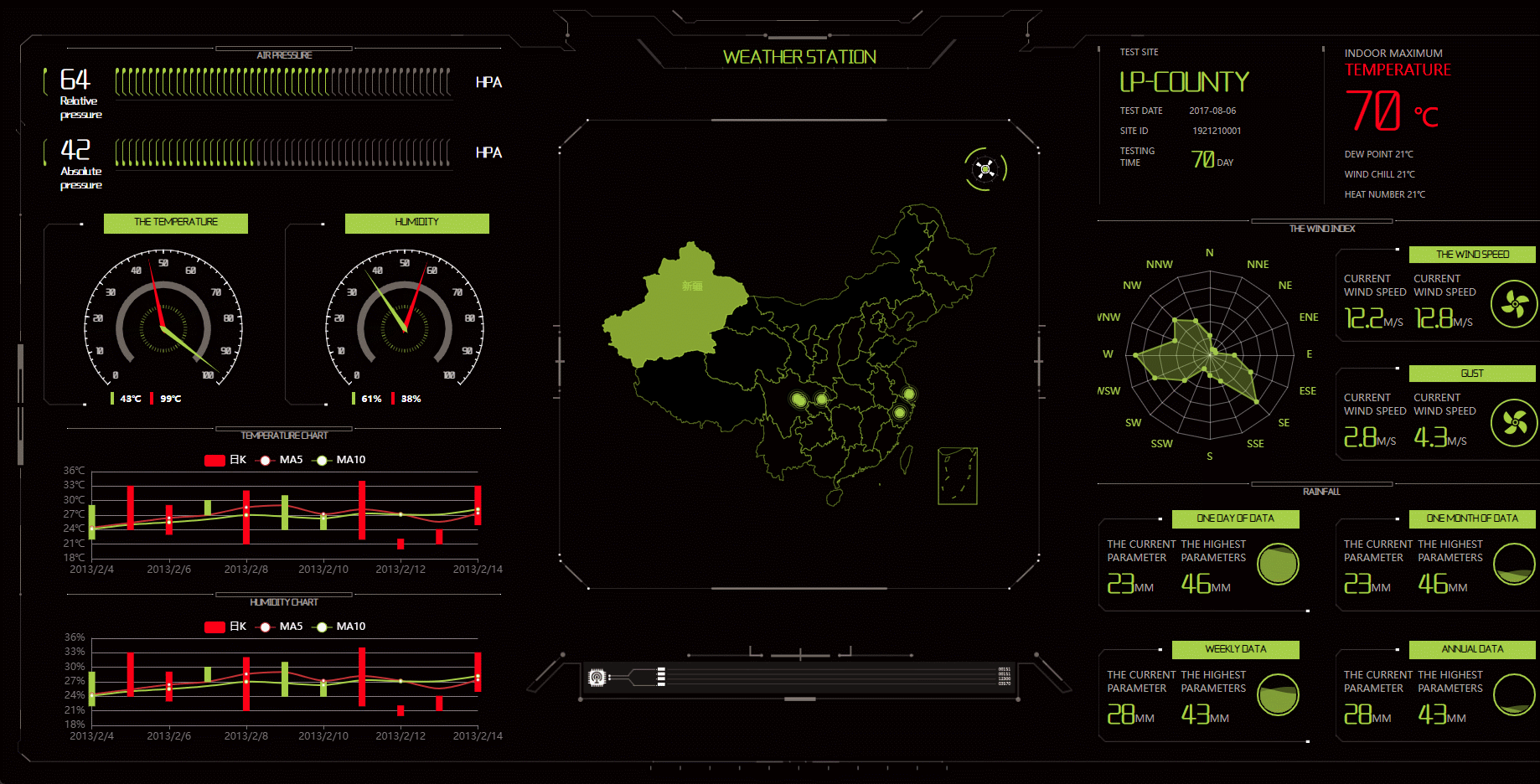
基于Echarts的大数据可视化模板:服务器运营监控
目录 引言背景介绍研究现状与相关工作服务器运营监控技术综述服务器运营监控概述监控指标与数据采集可视化界面设计与实现数据存储与查询优化Echarts与大数据可视化Echarts库以及其在大数据可视化领域的应用优势开发过程和所选设计方案模板如何满足管理的特定需求模板功能与特性…...

Python3 笔记:Python的常量
常量(constant):跟变量相对应,指第一次赋予值后就保持固定不变的值。 Python里面没有声明常量的关键字,其他语言像C/C/Java会有const修饰符,但Python没有。 Python中没有使用语法强制定义常量,…...

【Linux】自动化构建工具make/Makefile和git介绍
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12625432.html 目录 前言 Linux项目自动化构建工具-make/Makefile 举例 .PHONY 常见符号 依赖关系…...
)
C语言—关于字符串(编程实现部分函数功能)
0.前言 当我们使用这些函数功能时,可以直接调用头文件---#include<string.h>,然后直接使用就行了,本文只是手动编写实现函数的部分功能 1.strlen函数功能实现 功能说明:strlen(s)用来计算字符串s的长度,该函数计数不会包括最…...
picoCTF-Web Exploitation-Trickster
Description I found a web app that can help process images: PNG images only! 这应该是个上传漏洞了,十几年没用过了,不知道思路是不是一样的,以前的思路是通过上传漏洞想办法上传一个木马,拿到webshell,今天试试看…...

SSH 免密登录,设置好仍然需要密码登录解决方法
说明: ssh秘钥登录设置好了,但是登录的时候依然需要提供密码 查看系统安全日志,定位问题 sudo cat /var/log/auth.log或者 sudo cat /var/log/secure找到下面的信息 Authentication refused: bad ownership or modes...(网上的…...

【斑马打印机】web前端页面通过BrowserPrint API连接斑马打印机进行RFID条形码贴纸打印
web前端页面通过BrowserPrint API连接斑马打印机进行RFID条形码贴纸打印 在现代物流、仓储和零售行业中,RFID和二维码技术发挥着至关重要的作用。这些技术不仅提高了效率,还增强了追踪和管理的能力。本文将介绍如何使用JavaScript和斑马打印机的BrowserPrint API来打印RFID二…...
DigitalOcean 应用托管更新:应用端到端运行时性能大幅改进
DigitalOcean 希望可以为企业提供所需的工具和基础设施,以帮助企业客户加速云端的开发,实现业务的指数级增长。为此 DigitalOcean 在 2020 年就推出了App Platform。 App Platform(应用托管) 是一个完全托管的 PaaS 解决方案&…...
)
c/c++对于char*的理解(联合string容器)
在C和C中,char*是一个指向字符(char)的指针。它经常被用来处理C风格的字符串,这种字符串是以空字符(\0)结尾的字符数组。以下是关于char*的一些关键点: C风格的字符串: C风格的字符…...

商业空间吸音地毯怎么选?16 年品牌雅尔居靠谱
商业空间装修,噪音控制是刚需。办公室人声嘈杂、酒店走廊脚步声扰客、工装大堂回音重,都会直接影响空间体验与使用效率。选对吸音地毯,既能高效降噪,又能提升空间质感,是商业空间地面材料的优选。今天就来聊聊吸音地毯…...

9大网盘直链解析:免费高效的完整下载解决方案
9大网盘直链解析:免费高效的完整下载解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅…...

观察Taotoken在多模型聚合调用下的稳定性与路由表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的稳定性与路由表现 1. 引言 在构建依赖大模型能力的应用时,服务的连续性与稳定性是开…...

终极开源RGB灯光控制指南:一个软件统一管理所有硬件设备
终极开源RGB灯光控制指南:一个软件统一管理所有硬件设备 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgrammer1/OpenRGB. Rele…...
)
ChatGPT高质量输出的隐藏开关:基于IEEE写作标准的11项自动校验清单(附可运行Python验证脚本)
更多请点击: https://kaifayun.com 第一章:ChatGPT高质量输出的底层逻辑与认知前提 ChatGPT生成高质量响应并非依赖“魔法”,而是建立在三个核心支柱之上:大规模语言建模的统计涌现能力、人类反馈强化学习(RLHF&#…...

医用超声图像干扰处理方法:原理、技术与实践
引言 超声成像作为一种无创、实时、无辐射的医学影像技术,在临床诊断中发挥着至关重要的作用。然而,超声图像在采集过程中极易受到各种物理和电子干扰,导致图像质量下降,影响医生的诊断准确性。常见的干扰包括斑点噪声、混响伪影、声影、镜面伪影以及由患者呼吸、运动引起…...

API调用总失败?ChatGPT官方Rate Limit机制深度拆解,4类高频报错代码级诊断手册
更多请点击: https://kaifayun.com 第一章:API调用总失败?ChatGPT官方Rate Limit机制深度拆解,4类高频报错代码级诊断手册 ChatGPT API 的速率限制(Rate Limit)并非黑盒策略,而是由 OpenAI 明确…...
:零服务器搭建个人/团队通用大模型API驱动的论文阅读与推荐平台)
AI Daily Paper Reader(ADPR):零服务器搭建个人/团队通用大模型API驱动的论文阅读与推荐平台
一、背景 AI领域论文每日增长数量惊人,arXiv 上仅计算机科学相关的新论文每天就有上百篇。对于科研人员、研究生或AI从业者来说,如何高效筛选、阅读并跟踪与自己研究方向相关的论文,已成为日常工作中最耗时的一环。 传统的解决方案…...

Kolmogorov-Arnold网络:函数表示论驱动的可解释神经架构
1. 这不是又一个“万能网络”——Kolmogorov-Arnold 网络到底在解决什么真问题?你可能刚在某篇预印本论文里看到“Kolmogorov-Arnold Network”这个名词,心里一咯噔:又来?又是那种名字听着像数学史课件、实操起来连 loss 曲线都跑…...

Foobar2000终极歌词体验:三平台逐字歌词完整配置指南
Foobar2000终极歌词体验:三平台逐字歌词完整配置指南 【免费下载链接】ESLyric-LyricsSource Advanced lyrics source for ESLyric in foobar2000 项目地址: https://gitcode.com/gh_mirrors/es/ESLyric-LyricsSource 还在为Foobar2000找不到高质量的逐字歌词…...