Kafka 入门 (一)
Kafka 入门(一)
Apache Kafka起源于LinkedIn,后来于2011年成为开源Apache项目,然后于2012年成为First-class Apache项目。Kafka是用Scala和Java编写的。 Apache Kafka是基于发布订阅的容错消息系统。 它是快速,可扩展和设计分布。
什么是Kafka?
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在集群内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
优点
高吞吐量和低延迟(High throughput and low lattency):Kafka 设计时就考虑了高吞吐量和低延迟的特点,能够处理高并发的消息传递,同时支持快速、实时的数据处理和分析。
可靠性和容错性 (Reliability and fault-tolerance):Kafka 采用分布式架构,允许多个节点组成集群,支持数据的分区和副本备份,提供了高可用性和容错性。即使某个节点出现故障,也不会影响整个系统的正常运行。
可扩展性 (Scalability):Kafka 集群可以根据实际需求进行水平扩展,只需要增加节点即可。同时,Kafka 的设计也支持多数据中心的部署方式,可以将数据传递到不同的数据中心,以满足不同的需求。
灵活性(Flexibility):Kafka 支持多种数据源和数据格式,可以处理各种类型的数据,包括结构化数据、半结构化数据和非结构化数据。同时,Kafka 也支持多种消费者和生产者的语言和协议,如 Java、Python、C++、REST 等。
可定制性(Customizability):Kafka 提供了可插拔的 API 和插件机制,用户可以自定义各种插件,如自定义序列化和反序列化插件、自定义存储插件等。
易于使用和管理(Easy to use and management):Kafka 的 API 和配置都相对简单,使用和管理起来相对容易。同时,Kafka 还提供了丰富的监控和管理工具,如 Kafka Manager、Kafka Monitor 等,方便用户进行管理和监控。
通常使用场景
消息传递(Messing):将数据从一个系统传输到另一个系统。例如,一个应用程序可以将消息写入Kafka主题,另一个应用程序可以从该主题读取这些消息并执行相应的操作。这个用例可以用于许多不同的场景,如应用程序集成、实时流处理、日志处理等。与RabbitMQ不同之处,RabbitMQ只能消费一次,Kafka可以多次消费。
网站活动跟踪(Website Activity Tracking):收集和处理网站活动跟踪数据。网站活动跟踪数据通常以事件的形式生成,例如页面浏览、搜索、购物车添加等。这些事件可以写入Kafka主题,然后可以用于实时监控、实时处理或离线处理和报告生成。
数据指标(Metrics):聚合和处理各种数据指标。例如,一些应用程序会将指标数据写入Kafka主题,例如应用程序的请求响应时间、错误率、吞吐量等。这些数据可以用于监控应用程序性能和健康状况,并根据需要进行实时或离线处理和报告生成。
日志聚合(Log Aggregation):聚合和处理各种日志数据。许多应用程序会将日志数据写入Kafka主题,例如应用程序日志、服务器日志、安全日志等。这些数据可以用于实时监控、离线处理和报告生成、故障排除等。
流处理(Stream Processing):流处理是一种数据处理模式,可以在数据到达时立即对其进行处理。Kafka提供了流处理库,如Kafka Streams和KSQL,可以用于构建实时流处理应用程序。这些应用程序可以用于各种场景,如实时监控、实时报警、实时分析等。
事件源(Event sourcing):事件源是一种数据源,它以事件的形式生成数据。例如,一个传感器可以生成事件,指示当前温度或湿度。Kafka可以用于收集和处理这些事件,然后将其转换为有用的信息。
提交日志 (Commit Log):提交日志是一种记录系统状态的机制,它可以用于恢复系统状态或进行故障排除。例如,Kafka消费者将消费偏移量写入提交日志中,以便在发生故障时可以恢复到正确的位置。
基本概念
主题(Topic):消息的逻辑容器,每个消息都属于一个主题。主题可以看作是消息流的类别,可以拥有多个生产者和消费者。
分区(Partition):每个主题可以被分成多个分区,每个分区是一个有序的消息队列。分区可以提供更高的并发性和伸缩性,同时还可以实现数据冗余和备份。
生产者(Producer):负责向主题中写入消息的应用程序,可以将消息发送到指定的主题和分区。
消费者(Consumer):从主题中读取消息的应用程序,可以订阅一个或多个主题和分区,并从中读取消息。
代理(Broker):Kafka 集群中的每个节点都是一个代理,负责接收来自生产者和消费者的消息,并将其存储在本地磁盘上的分区中。
偏移量(Offset):每个分区中的每条消息都有一个唯一的偏移量,表示该消息在分区中的位置。消费者可以通过偏移量来跟踪其读取的位置。
消费者组(Consumer Group):多个消费者可以组成一个消费者组来共同消费一个或多个主题。在一个消费者组中,每个消费者都负责消费其中一个或多个分区中的消息。
复制(Replication):使用副本机制来提高数据的可靠性和容错性。每个分区可以配置多个副本,其中一个副本作为领导者(Leader),负责处理生产者和消费者的请求,其他副本作为追随者(Follower),复制领导者的数据并提供备份。
Kafka及生成消费Topic事件
1. 获取 Kafka
下载 Kafka
2. Kafka 安装并启动
$ tar -xzf kafka_2.13-3.4.0.tgz
$ cd kafka_2.13-3.4.0
# Start zookeeper
$ bin/zookeeper-server-start.sh config/zookeeper.properties
# open a new session
# generate random cluster id
$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
$ echo $KAFKA_CLUSTER_ID
PiqNzmreRbqqlua4uUt3ZQ
# delete files under /tmp as below
$ rm -rf /tmp/kafka-logs /tmp/zookeeper /tmp/kraft-combined-logs
# modify config/kraft/server.properties relevant ip
# controller.quorum.voters=1@192.168.79.177:9093
# listeners=PLAINTEXT://192.168.79.177:9092,CONTROLLER://192.168.79.177:9093
# advertised.listeners=PLAINTEXT://192.168.79.177:9092
$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
Formatting /tmp/kraft-combined-logs with metadata.version 3.4-IV0.
$ bin/kafka-server-start.sh config/kraft/server.properties
3. 创建Topic
$ bin/kafka-topics.sh --create --topic first-events --bootstrap-server 192.168.79.177:9092
Created topic first-events.
$ bin/kafka-topics.sh --create --topic second-events --bootstrap-server 192.168.79.177:9092
Created topic second-events.
4. 查看Topic
$ bin/kafka-topics.sh --list --bootstrap-server 192.168.79.177:9092
first-events
second-events
5. 查看Topic 分区
$ bin/kafka-topics.sh --describe --topic first-events --bootstrap-server 192.168.79.177:9092
Topic: first-events TopicId: mRi_1FdLTkS45ay3haaUrA PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824Topic: first-events Partition: 0 Leader: 1 Replicas: 1 Isr: 1
$ bin/kafka-topics.sh --describe --topic second-events --bootstrap-server 192.168.79.177:9092
Topic: second-events TopicId: 8J2iMtGMQdKD2MjsyCXzyw PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824Topic: second-events Partition: 0 Leader: 1 Replicas: 1 Isr: 1
6. 生产事件/消息
$ bin/kafka-console-producer.sh --topic first-events --bootstrap-server 192.168.79.177:9092
>first-events 01
>first-events 02
# Ctrl+D or Ctrl+C 退出
7. 消费事件/消息
$ bin/kafka-console-consumer.sh --topic first-events --from-beginning --bootstrap-server 192.168.79.177:9092
first-events 01
first-events 02
# open a new session and run the same command
$ bin/kafka-console-consumer.sh --topic first-events --from-beginning --bootstrap-server 192.168.79.177:9092
first-events 01
first-events 02
# Ctrl+C Exit to
多个消费者消费同一个Topic,可以消费无数次,可以用于事件流。
8. 删除topic
$ bin/kafka-topics.sh --delete --topic second-events --bootstrap-server 192.168.79.177:9092
$ bin/kafka-topics.sh --list --bootstrap-server 192.168.79.177:9092
first-events
相关文章:
)
Kafka 入门 (一)
Kafka 入门(一) Apache Kafka起源于LinkedIn,后来于2011年成为开源Apache项目,然后于2012年成为First-class Apache项目。Kafka是用Scala和Java编写的。 Apache Kafka是基于发布订阅的容错消息系统。 它是快速,可扩展…...
)
linux内核开发入门二(内核KO模块介绍、开发流程以及注意事项)
linux内核开发入门二(内核KO模块介绍、开发流程以及注意事项) 一、什么是内核模块 内核模块:ko模块(Kernel Object Module)是Linux内核中的可加载模块,它可以动态地向内核添加功能。在运行时,可…...
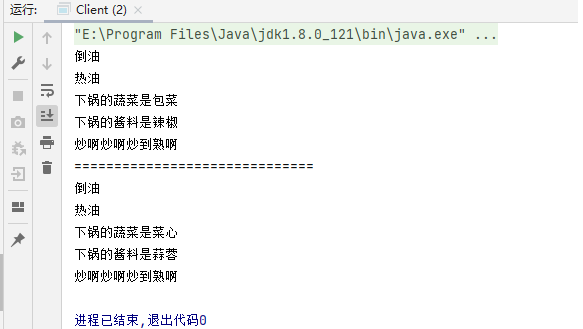
设计模式(十七)----行为型模式之模板方法模式
行为型模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。 行为型模式分为类行为模式和对象行为模式,前者采用继承机制来在类间分派行为&…...

【嵌入式Linux内核驱动】01_内核模块
内核模块 宏内核&微内核 微内核就是内核中的一部分功能放到应用层 内核小,精简,可扩展性好,安全性好 相互之间通信损耗多 内核模块 Linux是宏内核操作系统的典型代表,所有内核功能都整体编译到一起,优点是效…...
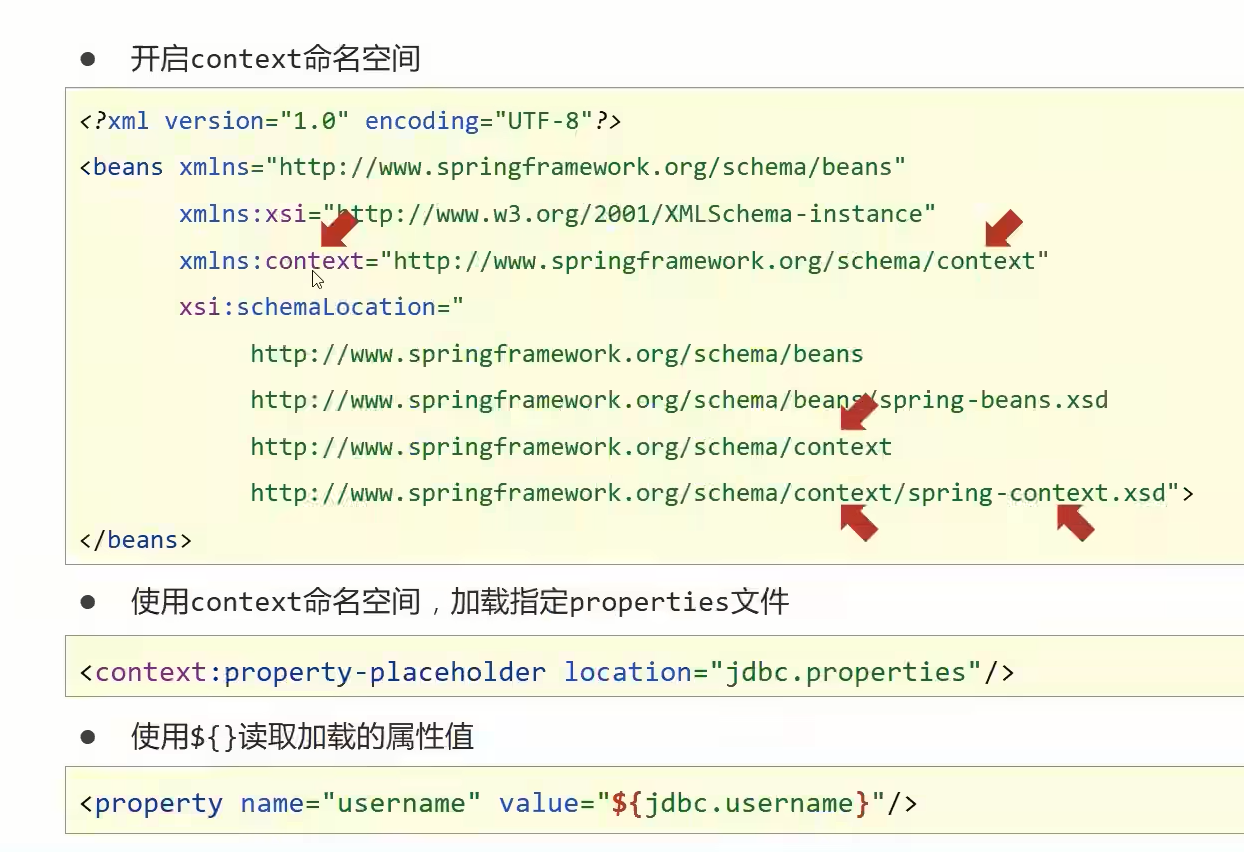
Spring——数据源对象管理和Spring加载properties文件
前面一直都是在管理自己内部创建的对象,这个是管理外部的对象。 这里先使用阿里巴巴的druid来演示。需要在pom.xml中添加如下的依赖 <dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1…...
Zeek安装、使用与压力测试
Zeek安装与压力测试Zeek安装、简单使用与压力测试环境Zeek安装zeek简单运行安装PF_RING修改Zeek配置文件,使用PF_RING,实现集群流量压力测试查看zeek日志Zeek安装、简单使用与压力测试 科研需要,涉及到Zeek的安装、使用和重放流量压力测试评…...

【javaEE初阶】第三节.多线程 (进阶篇 ) 死锁
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、"死锁"出现的典型场景二、产生 "死锁" 的必要条件 三、解决 "死锁" 问题的办法 总结前言 今天对于多线程进阶的学习&#…...
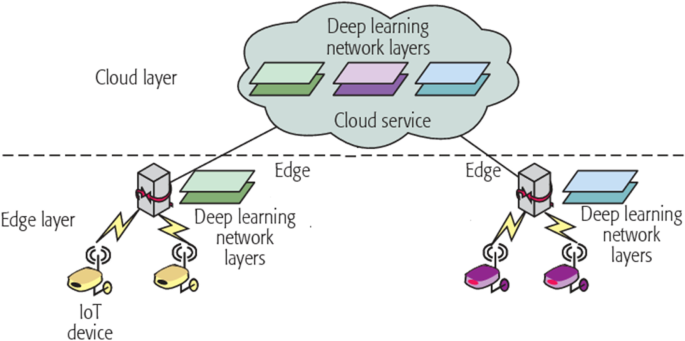
基于密集连接的轻量级卷积神经网络,用于使用边云架构的露天煤矿服务识别
遥感是快速检测非法采矿行为的重要技术工具。由于露天煤矿的复杂性,目前关于露天煤矿自动开采的研究较少。基于卷积神经网络和Dense Block,我们提出了一种用于从Sentinel-2遥感图像中提取露天煤矿区域的轻量级密集连接网络-AD-Net,并构建了三…...

无刷高速风筒方案介绍--【PCBA方案】
疫情三年过去,春节后,一个新的开始,大家满怀希望畅谈今年好气象。 三年来一波一波的封城、隔离、核酸,经济压抑到了无以复加的地步,也导致了诸多社会问题的出现。消费力被磨平,人们小心翼翼的生活。 常跟…...

花括号展开II[栈模拟dfs]
栈模拟dfs前言一、花括号展开II二、栈模拟dfs总结参考资料前言 递归调用,代码非常的简洁。但是可以通过显式栈来模拟栈中的内容,锻炼自己的代码能力,清楚知道栈帧中需要的内容。 一、花括号展开II 二、栈模拟dfs 每碰到一个左括号…...
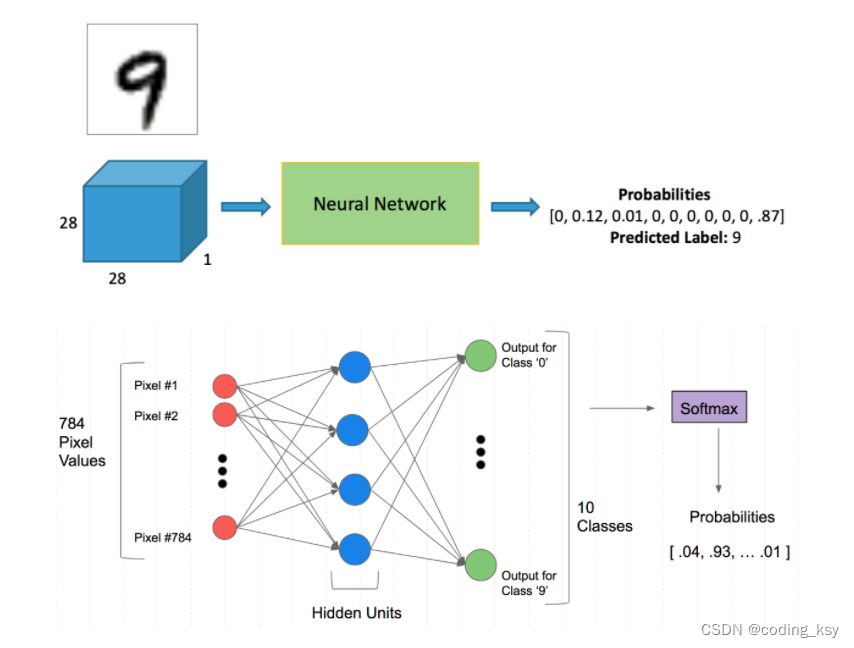
神经网络分类任务(手写数字识别)
1.Mnist分类任务 网络基本构建与训练方法,常用函数解析 torch.nn.functional模块 nn.Module模块 学习方法:边用边查,多打印,duogua 使用jupyter的优点,可以打印出每一个步骤。 2.读取数据集 自动下载 %matplotl…...
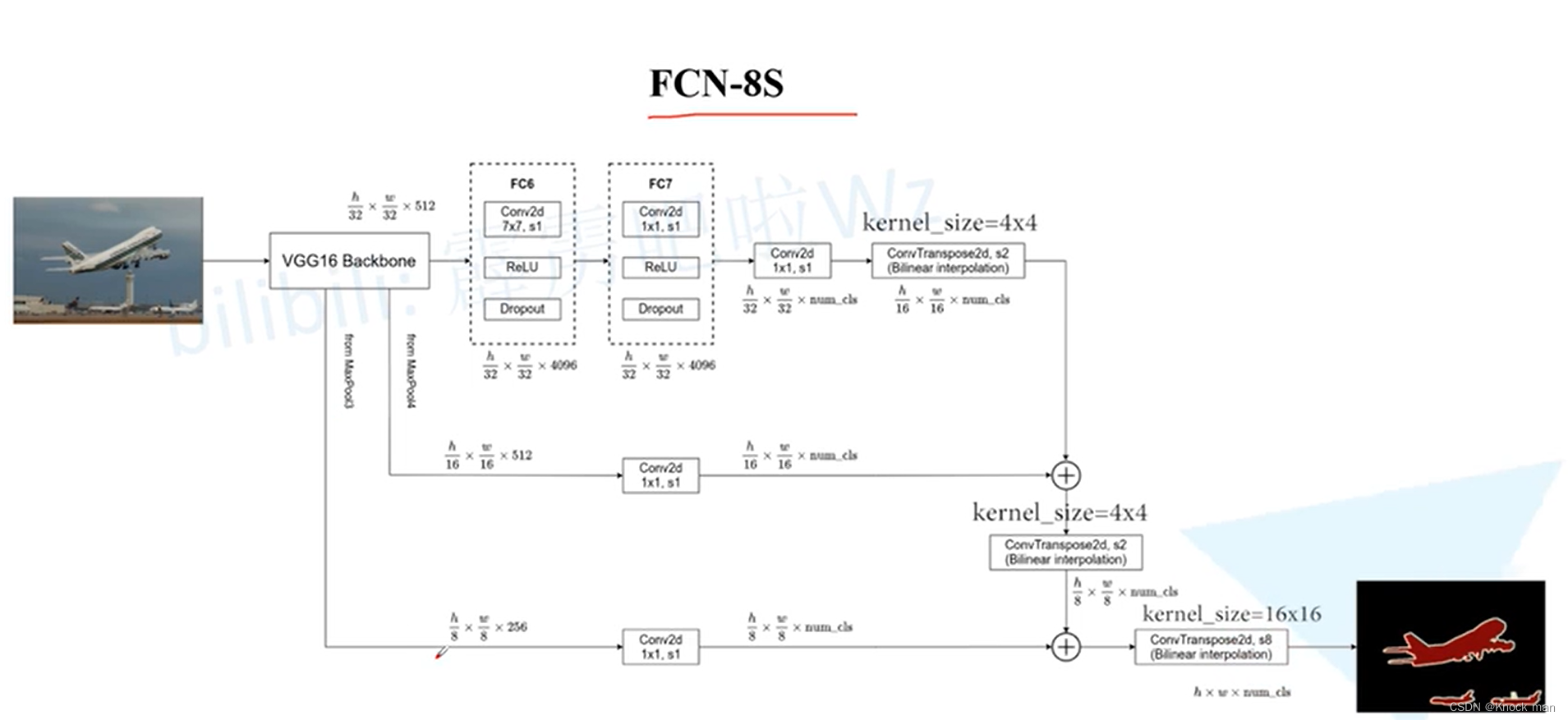
FCN网络(Fully Convolutional Networks)
首个端到端的针对像素级预测的全卷积网络 原理:将图片进行多次卷积下采样得到chanel为21的特征层,再经过上采样得到和原图一样大的图片,最后经过softmax得到类别概率值 将全连接层全部变成卷积层:通常的图像分类网络最后几层是全…...

随想录二刷Day15——二叉树
文章目录二叉树2. 递归遍历二叉树3. 二叉树的迭代遍历4. 二叉树的统一迭代法二叉树 2. 递归遍历二叉树 144. 二叉树的前序遍历 class Solution { public:vector<int> preorderTraversal(TreeNode* root) {vector<int> result;preorder(root, result);return res…...

docker-compose部署kafka服务时如何同时允许内外网访问?
背景 最近在学习kafka相关知识,需要搭建自己的kafka环境。综合考虑后决定使用docker-compose来管理维护这个环境。 docker-compose.yml Bitnami的yml文件就很不错,这里直接拿来用了。 version: "2"services:zookeeper:image: docker.io/bi…...
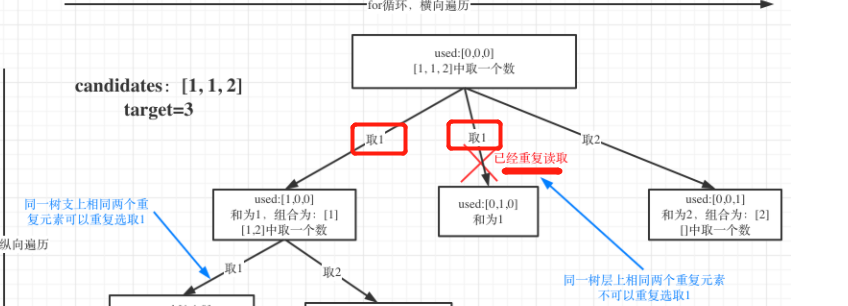
数据结构刷题(二十):17电话号码的字母组合、39组合总和、40组合总和II
一、电话号码的字母组合题目链接思路:回溯三部曲。确定回溯函数参数:题目中给的 digits,还要有一个参数就是int型的index(记录遍历第几个数字,就是用来遍历digits的,同时也代表了递归的深度)&am…...
)
Java面试总结(五)
sleep() 方法和 wait() 方法对比 相同点 两者都可以暂停线程的执行;两者都可以响应中断。 不同点 sleep()方法不会释放锁,wait()方法会释放锁; sleep()方法主要用于暂停线程的执行,wait()方法主要用于线程之间的交互/通信&…...
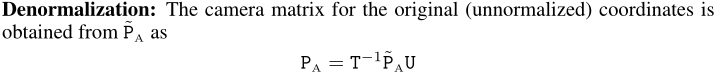
三维人脸实践:基于Face3D的渲染、生成与重构 <二>
face3d: Python tools for processing 3D face git code: https://github.com/yfeng95/face3d paper list: PaperWithCode 3DMM方法,基于平均人脸模型,可广泛用于基于关键点的人脸生成、位姿检测以及渲染等,能够快速实现人脸建模与渲染。推…...
在linux上部署Java项目
在Linux部署Java环境 要是想要部署java web程序,首先要配置环境 jdk tomcat mysql 安装jdk 推荐的方法是使用yum直接安装openjdk(开源的,与官方的jdk功能差不多),目前使用的最多的就是jdk8系列 yum list | grep jdk 在源上搜索所有关于jdk的文件 devel表示development的意思…...

线性表的接口
线性表的实现方式 顺序表 顺序表是一种线性表的实现方式,它是用一组地址连续的存储单元依次存储线性表中的数据元素,使得逻辑上相邻的元素在物理上也相邻⁴。顺序表可以用数组来实现,它的优点是可以快速定位第几个元素,但是缺点…...

spark三种操作模式的不同点分析
通常情况下,由于mapreduce计算引擎的效率问题,大部分公司使用的基本都是hive数仓spark计算引擎的方式搭建集群,所以对于spark的三种操作方式来进行简单的分析。在日常开发中,使用最多的方式取决于具体的需求和场景。以下是每种方式的一些常见用途:Spark …...

# 状态通道实战:用Solidity实现高效链下交易与链上结算 在区块链世界中,**扩展性瓶颈**一直是开发者绕
状态通道实战:用Solidity实现高效链下交易与链上结算 在区块链世界中,扩展性瓶颈一直是开发者绕不开的话题。传统智能合约每笔交互都需上链,不仅成本高昂,还导致网络拥堵。而**状态通道(State Channel)**技…...
)
Windows下用MSYS2编译axel多线程下载工具的保姆级教程(附常见错误解决方案)
Windows下MSYS2编译axel多线程下载工具全指南 如果你厌倦了商业下载工具的臃肿和限制,又对Python多线程下载的稳定性不满,那么编译一个原生的axel多线程下载工具可能是最佳选择。本文将带你从零开始在Windows环境下,通过MSYS2完整编译axel&a…...

STM32F103精英板实战:手把手教你移植开源Modbus主机库,实现稳定主从通信
STM32F103精英板实战:手把手教你移植开源Modbus主机库,实现稳定主从通信 Modbus协议作为工业自动化领域最常用的通信协议之一,其简单可靠的特性使其在各种嵌入式设备中广泛应用。对于使用STM32F103系列开发板的工程师来说,如何快速…...

Gauge常见问题解决:10个典型错误及修复方法
Gauge常见问题解决:10个典型错误及修复方法 【免费下载链接】gauge Light weight cross-platform test automation 项目地址: https://gitcode.com/gh_mirrors/ga/gauge Gauge作为一款轻量级跨平台测试自动化工具,在使用过程中可能会遇到各种错误…...
)
保姆级教程:在Ubuntu 22.04上用RTX 4090复现DepthAnything V2(含Open3D点云可视化避坑指南)
保姆级教程:在Ubuntu 22.04上用RTX 4090复现DepthAnything V2(含Open3D点云可视化避坑指南) 深度估计技术正在重塑计算机视觉领域,而DepthAnything V2凭借其轻量级架构和精细的深度预测能力,成为当前最受关注的开源模型…...

SHA-3:从海绵结构到抗量子密码学的基石
1. SHA-3的诞生背景与核心价值 2004年,密码学界发现SHA-1存在理论漏洞,这直接推动了NIST启动新一代哈希算法竞赛。经过5年激烈角逐,Keccak团队提出的海绵结构方案最终胜出。与传统哈希算法不同,SHA-3不是对SHA-2的简单升级&#x…...
)
NumPy 应用实例:用户行为数据分析(归一化和标准化处理)
在用户行为分析中,常常需要同时处理多个特征,例如访问次数、消费金额、停留时长、收藏数量等。这些特征虽然都能反映用户活跃程度或消费倾向,但它们的单位、量纲和取值范围通常并不一致。如果直接将原始数据用于综合评分或相似度计算…...
Transformers音频分类终极指南:3步实现智能环境音识别
Transformers音频分类终极指南:3步实现智能环境音识别 【免费下载链接】transformers huggingface/transformers: 是一个基于 Python 的自然语言处理库,它使用了 PostgreSQL 数据库存储数据。适合用于自然语言处理任务的开发和实现,特别是对于…...

responder使用教程
Responder是Kali Linux中一款强大的网络欺骗工具,主要用于在局域网中捕获各种网络协议的认证信息,特别是NTLM哈希。它通过响应LLMNR(链路本地多播名称解析)、NBT-NS(NetBIOS名称服务)和mDNS(多播…...

MS5803-14BA I²C驱动开发:嵌入式压力传感器实战指南
1. MS5803-14BA压力传感器库深度解析:面向嵌入式工程师的IC驱动开发实践1.1 传感器核心特性与工程定位MS5803-14BA是TE Connectivity(原Measurement Specialties)推出的高精度数字压力/温度复合传感器,采用MEMS压阻式传感原理与Δ…...