数据仓库项目---Day01
文章目录
- 框架的安装包
- 数据仓库概念
- 项目需求及架构设计
- 项目需求分析
- 项目框架
- 技术选型
- 系统数据流程设计
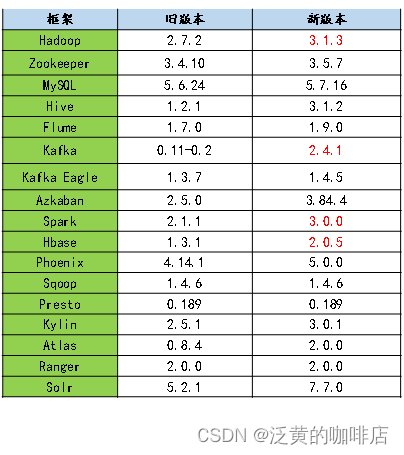
- 框架版本选型
- 集群资源规划设计
- 数据生成模块
- 数据埋点
- 主流埋点方式
- 埋点数据上报时机
- 服务器和JDK准备
- 搭建三台Linux虚拟机(VMWare)
- 编写集群分发脚本xsync
- SSH无密登录配置
- JDK准备
- 模拟数据
- 集群日志生成脚本
框架的安装包
链接:https://pan.baidu.com/s/18-WmBBgoTwOyucs-0Rmfew?pwd=4wf9
提取码:4wf9
数据仓库概念
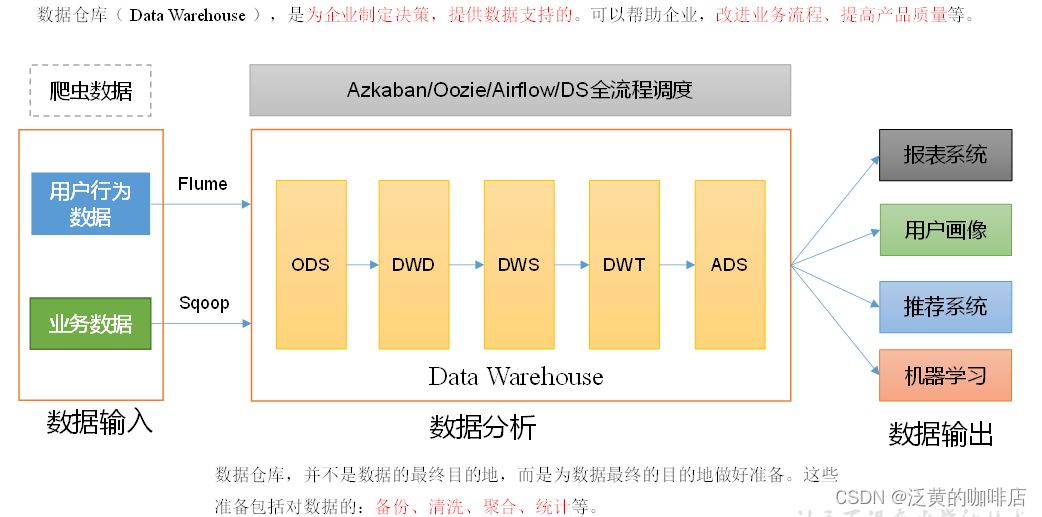
数据仓库( Data Warehouse ),是为企业制定决策,提供数据支持的。可以帮助企业,改进业务流程、提高产品质量等。
数据仓库的输入数据通常包括:业务数据、用户行为数据和爬虫数据等
-
业务数据:就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在MySQL、Oracle等数据库中。
-
用户行为数据:用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。
-
爬虫数据:通常事通过技术手段获取其他公司网站的数据。
项目需求及架构设计
项目需求分析

项目框架
技术选型
技术选型主要考虑因素:数据量大小、业务需求、行业内经验、技术成熟度、开发维护成本、总成本预算
- 数据采集传输:Flume,Kafka,Sqoop,Logstash,DataX
- 数据存储:MySQL,HDFS,HBase,Redis,MongoDB
- 数据计算:Hive,Tez,Spark, Flink, Storm
- 数据查询:Presto,Kylin,Impala,Druid,ClickHouse,Doris
- 数据可视化:Echarts,Superset,QuickBI,DataV
- 任务调度:Azkaban,Oozie,DolphinScheduler,Airflow
- 集群监控:Zabbix,Prometheus
- 元数据管理:Atlas
- 权限管理:Ranger,Sentry
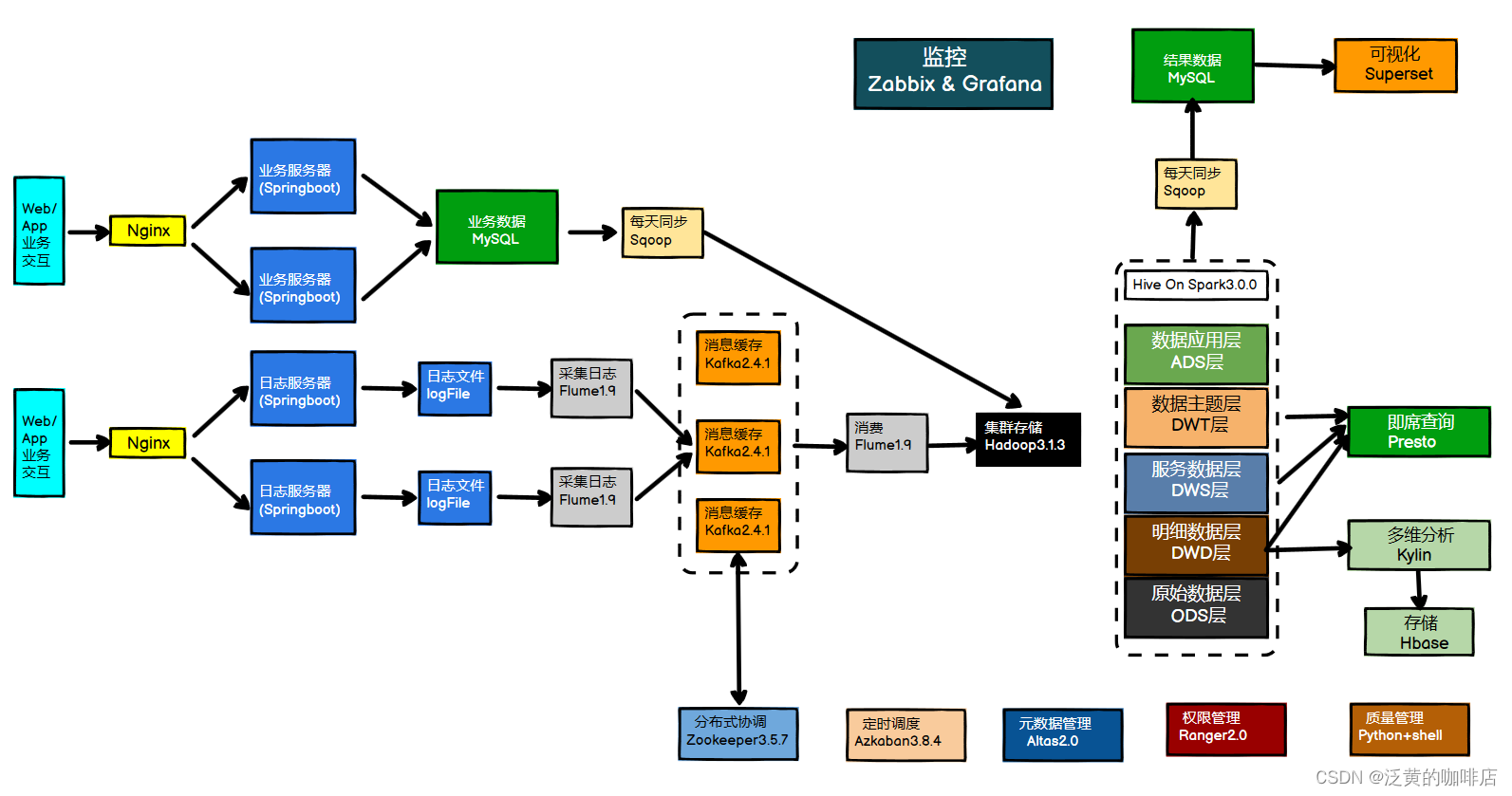
系统数据流程设计
框架版本选型
1)如何选择Apache/CDH/HDP版本?
(l)Apache:运维麻烦,组件间兼容性需要自己调研。(一般大厂使用,技术实力雄厚,有专业的运维人员)(建议使用)
(2)CDH:国内使用最多的版本,但CM不开源,今年开始收费,一个节点1万美金/年。
(3) HDP:开源,可以进行二次开发,但是没有CDH稳定,国内使用较少
2)云服务选择
(1)阿里云的EMR、MaxCompute、DataWorks
(2)亚马逊云EMR
(3)腾讯云EMR
(4)华为云EMR
Apache框架版本
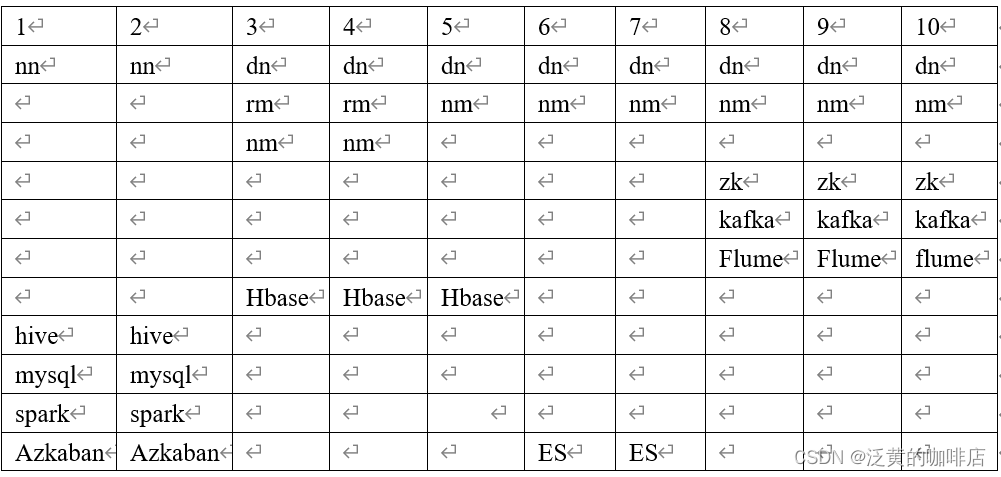
集群资源规划设计
通常会搭建一套生产集群和一套测试集群。生产集群运行生产任务,测试集群用于上线前代码编写和测试。
生产集群
- 消耗内存的分开
- 数据传输数据比较紧密的放在一起(Kafka 、Zookeeper)
- 客户端尽量放在一到两台服务器上,方便外部访问
- 有依赖关系的尽量放到同一台服务器(例如:Hive和Azkaban Executor)
测试集群服务器规划
| 服务名称 | 子服务 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|---|
| HDFS | NameNode | √ | ||
| HDFS | DataNode | √ | √ | √ |
| HDFS | SecondaryNameNode | √ | ||
| Yarn | NodeManager | √ | √ | √ |
| Yarn | Resourcemanager | √ | ||
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Flume(采集日志) | Flume | √ | √ | |
| Kafka | Kafka | √ | √ | √ |
| Flume(消费Kafka) | Flume | √ | ||
| Hive | Hive | √ | ||
| MySQL | MySQL | √ | ||
| Sqoop | Sqoop | √ | ||
| Presto | Coordinator | √ | ||
| Presto | Worker | √ | √ | |
| Azkaban | AzkabanWebServer | √ | ||
| Azkaban | AzkabanExecutorServer | √ | ||
| Spark | √ | |||
| Kylin | √ | |||
| HBase | HMaster | √ | ||
| HBase | HRegionServer | √ | √ | √ |
| Superset | √ | |||
| Atlas | √ | |||
| Solr | Jar | √ | ||
| 服务数总计 | 19 | 8 | 8 |
数据生成模块
数据埋点
主流埋点方式
目前主流的埋点方式,有代码埋点(前端/后端)、可视化埋点、全埋点三种。
代码埋点是通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用SDK提供的数据发送接口,来发送数据。
可视化埋点只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点是通过在产品中嵌入SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
埋点数据上报时机
埋点数据上报时机包括两种方式。
方式一,在离开该页面时,上传在这个页面产生的所有数据(页面、事件、曝光、错误等)。优点,批处理,减少了服务器接收数据压力。缺点,不是特别及时。
方式二,每个事件、动作、错误等,产生后,立即发送。优点,响应及时。缺点,对服务器接收数据压力比较大。
服务器和JDK准备
搭建三台Linux虚拟机(VMWare)
搭建教程
编写集群分发脚本xsync
1)xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析
①rsync命令原始拷贝:
rsync -av /opt/module root@hadoop103:/opt/
②期望脚本:
xsync要同步的文件名称
③说明:在/home/atguigu/bin这个目录下存放的脚本,yudan用户可以在系统任何地方直接执行。
(3)脚本实现
①在用的家目录/home/yudan下创建bin文件夹
[yudan@hadoop102 ~]$ mkdir bin
②在/home/yudan/bin目录下创建xsync文件,以便全局调用
[yudan@hadoop102 ~]$ cd /home/yudan/bin
[yudan@hadoop102 ~]$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done
③修改脚本xsync具有执行权限
[yudan@hadoop102 bin]$ chmod +x xsync
④测试脚本
[yudan@hadoop102 bin]$ xsync xsync
SSH无密登录配置
(1)hadoop102上生成公钥和私钥:
[yudan@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(2)将hadoop102公钥拷贝到要免密登录的目标机器上
[yudan@hadoop102 .ssh]$ ssh-copy-id hadoop102
[yudan@hadoop102 .ssh]$ ssh-copy-id hadoop103
[yudan@hadoop102 .ssh]$ ssh-copy-id hadoop104
(3)hadoop103上生成公钥和私钥:
[yudan@hadoop103 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(4)将hadoop103公钥拷贝到要免密登录的目标机器上
[yudan@hadoop103 .ssh]$ ssh-copy-id hadoop102
[yudan@hadoop103 .ssh]$ ssh-copy-id hadoop103
[yudan@hadoop103 .ssh]$ ssh-copy-id hadoop104
JDK准备
1)卸载现有JDK(3台节点)
[yudan@hadoop102 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps[yudan@hadoop103 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps[yudan@hadoop104 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
(1)rpm -qa:表示查询所有已经安装的软件包
(2)grep -i:表示过滤时不区分大小写
(3)xargs -n1:表示一次获取上次执行结果的一个值
(4)rpm -e --nodeps:表示卸载软件
2)解压JDK到/opt/module目录下
[yudan@hadoop102 software]# tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
3)配置JDK环境变量
(1)新建/etc/profile.d/my_env.sh文件
[yudan@hadoop102 module]# sudo vim /etc/profile.d/my_env.sh
添加如下内容,然后保存(:wq)退出
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
(2)让环境变量生效
[yudan@hadoop102 software]$ source /etc/profile.d/my_env.sh
4)测试JDK是否安装成功
[yudan@hadoop102 module]# java -version
如果能看到以下结果、则Java正常安装
java version “1.8.0_212”
5)分发JDK
[yudan@hadoop102 module]$ xsync /opt/module/jdk1.8.0_212/
6)分发环境变量配置文件
[yudan@hadoop102 module]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
7)分别在hadoop103、hadoop104上执行source
[yudan@hadoop103 module]$ source /etc/profile.d/my_env.sh
[yudan@hadoop104 module]$ source /etc/profile.d/my_env.sh
模拟数据
1)将application.yml、gmall2020-mock-log-2021-01-22.jar、path.json、logback.xml上传到hadoop102的/opt/module/applog目录下
(1)创建applog路径
[yudan@hadoop102 module]$ mkdir /opt/module/applog
(2)上传文件application.yml到/opt/module/applog目录
2)生成日志
(1)进入到/opt/module/applog路径,执行以下命令
[yudan@hadoop102 applog]$ java -jar gmall2020-mock-log-2021-01-22.jar
(2)在/opt/module/applog/log目录下查看生成日志
[yudan@hadoop102 log]$ ll
集群日志生成脚本
在hadoop102的/home/atguigu目录下创建bin目录,这样脚本可以在服务器的任何目录执行。
[yudan@hadoop102 ~]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/atguigu/.local/bin:/home/yudan/bin
(1)在/home/atguigu/bin目录下创建脚本lg.sh
[yudan@hadoop102 bin]$ vim lg.sh
(2)在脚本中编写如下内容
#!/bin/bash
for i in hadoop102 hadoop103; doecho "========== $i =========="ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-01-22.jar >/dev/null 2>&1 &"
done
注:
①/opt/module/applog/为jar包及配置文件所在路径
②/dev/null代表Linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”。
标准输入0:从键盘获得输入 /proc/self/fd/0
标准输出1:输出到屏幕(即控制台) /proc/self/fd/1
错误输出2:输出到屏幕(即控制台) /proc/self/fd/2
(3)修改脚本执行权限
[yudan@hadoop102 bin]$ chmod u+x lg.sh
(4)将jar包及配置文件上传至hadoop103的/opt/module/applog/路径
(5)启动脚本
[yudan@hadoop102 module]$ lg.sh
(6)分别在hadoop102、hadoop103的/opt/module/applog/log目录上查看生成的数据
相关文章:
数据仓库项目---Day01
文章目录 框架的安装包数据仓库概念项目需求及架构设计项目需求分析项目框架技术选型系统数据流程设计框架版本选型集群资源规划设计 数据生成模块数据埋点主流埋点方式埋点数据上报时机 服务器和JDK准备搭建三台Linux虚拟机(VMWare)编写集群分发脚本xsyncSSH无密登录配置JDK准…...
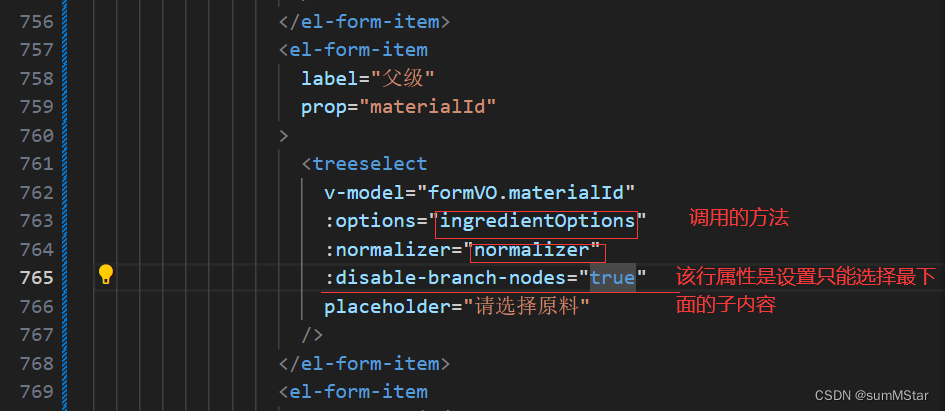
若依生成树表和下拉框选择树表结构(在其他页面使用该下拉框输入)
1.数据库表设计 生成树结构的主要列是id列和parent_id列,后者指向他的父级 2.来到前端代码生成器页面 导入你刚刚写出该格式的数据库表 3.点击编辑,来到字段 祖籍列表是为了好找到直接父类,不属于代码生成器方法,需要后台编…...

考研数学|李林《880》做不动,怎么办!?看这一篇!
在考研数学的备考过程中,遇到难题是很常见的情况,尤其是当你尝试解决李林880习题集中的问题时。他以其难度和深度著称,旨在帮助考生深入理解数学分析的复杂概念。 如果你在解题过程中感到困难,这并不是你个人的问题,而…...

paddle ocr 版面分析
教程 https://github.com/PaddlePaddle/PaddleOCR/blob/a4b7d3ba4a8333a23bab1fc1472aa18deec211d1/ppstructure/layout/README_ch.md 额外的模型,但是yolov2的模型缺少yml配置文件,找不到 https://github.com/PaddlePaddle/PaddleOCR/blob/main/ppstruc…...
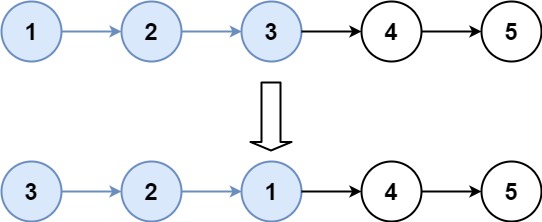
25. K 个一组翻转链表 - 力扣(LeetCode)
基础知识要求: Java:方法、while循环、for循环、if else语句 Python: 方法、while循环、for循环、if else语句 题目: 给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。 k 是一个…...
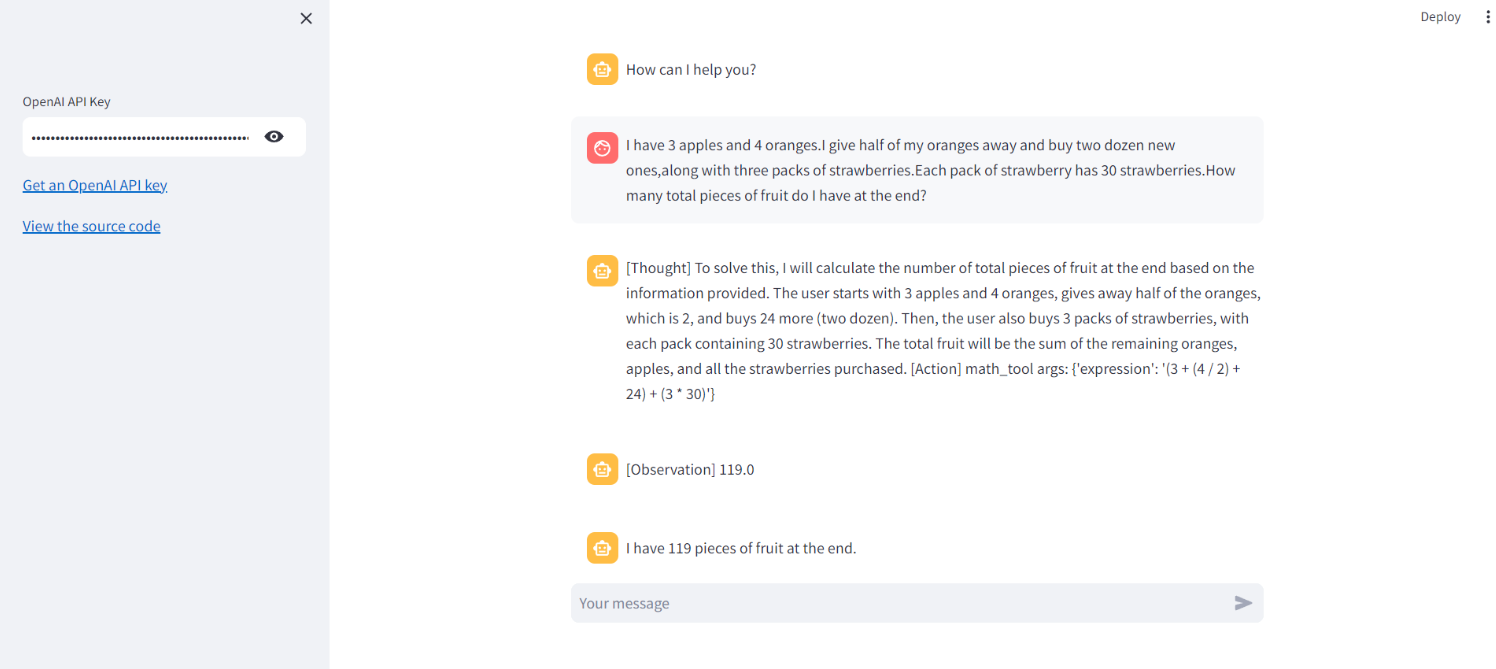
使用 GPT-4-turbo+Streamlit+wiki+calculator构建Math Agents应用【Step by Step】
💖 Brief:大家好,我是Zeeland。Tags: 大模型创业、LangChain Top Contributor、算法工程师、Promptulate founder、Python开发者。📝 CSDN主页:Zeeland🔥📣 个人说明书:Zeeland&…...

[240514] OpenAI 发布 GPT-4o,人机交互的历史性时刻 | 苹果芯片进军服务器剑指AI | 谷歌大会以AI为主
目录 OpenAI 发布 GPT-4o,人机交互的历史时刻苹果芯片进军服务器,剑指生成式 AI2024年谷歌开发者大会将围绕 AI 展开 OpenAI 发布 GPT-4o,人机交互的历史时刻 OpenAI 发布了 GPT-4o,大家一直都想要现在终于等到的语音助手 : 勿需…...

Maximo 在 Automation Script 中访问数据库
在 Automation Script 中我们通常使用 mbo 对象来操作数据,但有时候当数据量较大时,使用 mbo 对象来操作数据会比较慢。这时候,我们可以使用 JDBC 的方式来直接访问数据库,从而提高操作数据的效率。 下面看看使用 JavaScript 脚本…...
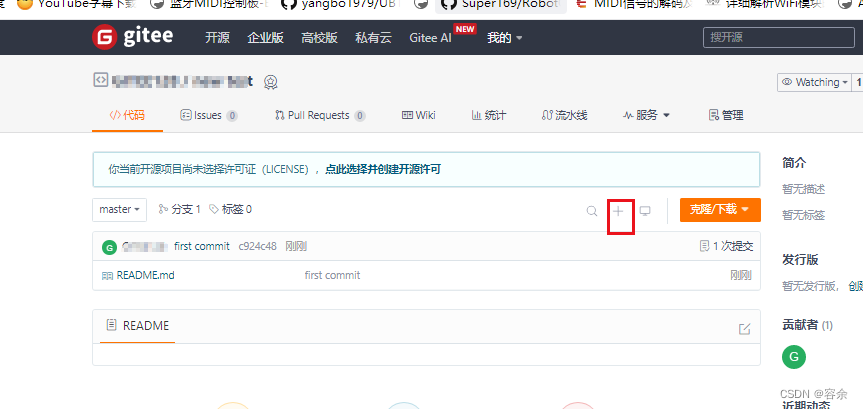
gitee 简易使用 上传文件
Wiki - Gitee.com 官方教程 1.gitee 注册帐号 (直接选择初始化选项即可,无需下载git) 2.下载git 安装 http://git-scm.com/downloads 3. 桌面 鼠标右键 或是开始菜单 open git bash here 输入(复制 ,粘贴) 运行…...

iOS Xcode 升级Xcode15报错: SDK does not contain ‘libarclite
一 iOS Xcode 升级Xcode15报错: SDK does not contain libarclite 1.1 报错信息 SDK does not contain libarclite at the path /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/ lib/arc/libarclite_iphonesimulator.a; try increasin…...

即插即用篇 | YOLOv8引入轴向注意力 Axial Attention | 多维变换器中的轴向注意力
本改进已集成到 YOLOv8-Magic 框架。 我们提出了Axial Transformers,这是一个基于自注意力的自回归模型,用于图像和其他组织为高维张量的数据。现有的自回归模型要么因高维数据的计算资源需求过大而受到限制,要么为了减少资源需求而在分布表达性或实现的便捷性上做出妥协。相…...

【芯片制造】【常用术语】CP、FT、WAT
背景: 在我们讲wafer加工好以后,需要进行相关测试,在此阶段,有很多提及到的常用术语,我们依次进行解释。主要单词含义: CP : Chip Probing(probe card),wafer…...
计算机vcruntime140.dll找不到如何修复,分享5种靠谱的修复教程
当您在运行某个应用程序或游戏时遇到提示“找不到vcruntime140.dll”,这通常意味着系统中缺少了Visual C Redistributable for Visual Studio 2015或更高版本的一个重要组件。这个错误通常发生在运行某些程序时,系统无法找到所需的动态链接库文件。小编将…...
超级简单的地图操作工具开发可疑应急,地图画点,画线,画区域,获取地图经纬度等
使用echars的地图画点,画线,画区域,获取地图经纬度等 解压密码:10086007 地图也是用临时的bmap.js和china.js纯离线二选一 一共就这么多文件 画点,画线,画区域 点击地图获取经纬度-打印到控制台,这样就能渲染航迹,多变形,结合其他算法算圆等等操作 下载资源:https://download…...

25_NumPy数组np.round将ndarray舍入为偶数
25_NumPy数组np.round将ndarray舍入为偶数 使用 np.round() 将 NumPy 数组 ndarray 的元素值舍入为任意位数。请注意,0.5 由于舍入到偶数而不是一般舍入而舍入为 0.0。 本文介绍了一般舍入的实现示例。 如何使用 np.round() 基本用法指定要舍入的位数:…...

Java字符串去除空格的方法
前言 在Java编程实践中,处理字符串中的空格是一项基本且频繁的操作。本文将深入探讨如何使用Java原生方法以及Apache Commons Lang库中的StringUtils类,全方位解决字符串去空格的需求,让你的代码更加健壮和高效。 1. Java原生方法 a. trim…...

【Python】【应用】Python应用之如何操作WiFi之一——使用pywifi
🐚作者简介:花神庙码农(专注于Linux、WLAN、TCP/IP、Python等技术方向)🐳博客主页:花神庙码农 ,地址:https://blog.csdn.net/qxhgd🌐系列专栏:Python应用&…...
)
2024OD机试卷-分割均衡字符串 (java\python\c++)
题目:分割均衡字符串 题目描述 均衡串定义: 字符串 中只包含两种字符,且这两种字符的个数相同。 给定一个均衡字符串,请给出可分割成新的均衡子串的最大个数。 约定:字符串中只包含大写的 X 和 Y 两种字符。 输入描述 字符串的长度:[2, 10000]。 给定的字符串均为均…...

完整版解答!2024年数维杯数学建模挑战赛B题
B题 生物质和煤共热解问题的研究 技术文档第一问1.1问题一分析1.2数据预处理1.3问题一Spearman相关性分析 数据代码资料获取 技术文档 第一问 1.1问题一分析 对于问题一,题目要求分析出正己烷不溶物对焦油产率、水产率、焦渣产率这三个指标是否有显著影响&#x…...

Android开发,日志级别
5个日志级别 Verbose (VERBOSE): 这是最低的日志级别,用于输出最为详尽的信息,包括开发和调试过程中的各种细节。在Log类中对应的方法是Log.v()。Debug (DEBUG): 此级别用于输出调试信息,帮助开发者理解程序运行流程或状态。通过Log.d()方法…...

【大语言模型系列·第 01 篇】全景图:从图灵测试到万亿参数的 AI 革命
【大语言模型系列第 01 篇】全景图:从图灵测试到万亿参数的 AI 革命 系列前言:大语言模型(LLM)是当今 AI 最重要的技术基石。从 2017 年 Transformer 论文到 2026 年的万亿参数 MoE 模型,LLM 用不到十年时间重塑了整个…...

告别FreeRTOS:在乐鑫ESP32-C3上为RT-Thread打上‘内核补丁’的完整指南
从FreeRTOS到RT-Thread:ESP32-C3内核替换的工程实践 在嵌入式开发领域,操作系统的选择往往决定了项目的技术栈和生态边界。对于习惯了ESP-IDF和FreeRTOS的开发者来说,RT-Thread以其模块化设计和丰富的中间件支持正成为颇具吸引力的替代方案。…...

2026年大模型内容精准收录实操,企业长效流量布局核心方法论
引言:大模型正在成为企业品牌认知的新前置入口。当越来越多用户绕过搜索引擎、直接向AI提问"哪家公司更适合""某个方案值不值得选"时,企业在AI回答中的位置、语气和引用来源,已经构成真实的竞争格局。本文将从大模型内容…...

Swift底层多线程:POSIX线程封装与安全并发实践
1. 项目概述:当Swift遇见POSIX线程如果你在Swift里用过DispatchQueue或者Thread,有没有想过它们背后到底是怎么运作的?特别是当你的应用需要处理高并发、低延迟的任务,或者需要在Linux服务器上跑一个Swift后端服务时,仅…...

面试官:你知道的限流算法有哪些?
为什么要有限流 一般做接口限流主要是为了应对突发流量,避免突发流量拖垮服务。如下面一些场景就有可能发生突发流量 微博热搜 恶意刷单 恶意爬虫 促销活动 接口限流的算法有如下几种 固定窗口计数器算法 这是最简单的限流算法。它将时间划分为固定的周期(窗口),并在每个…...

AOCODARC-F7MINI飞控固件编译踩坑记:从‘make arm_sdk_install’失败到成功编译
AOCODARC-F7MINI飞控固件编译实战:从工具链安装到烧录全流程解析 1. 环境准备与工具链安装 编译BetaFlight固件最令人头疼的环节往往不是代码本身,而是环境配置。以Ubuntu 20.04为例,我们需要先解决两个核心问题:基础编译环境和AR…...

统信UOS/麒麟KYLINOS用户看过来:除了Termius,这款开源免费的SSH工具electerm更香!
国产操作系统用户的SSH工具新选择:electerm深度体验报告 对于统信UOS和麒麟KYLINOS用户而言,远程服务器管理是日常工作中的高频需求。Termius作为老牌SSH工具确实表现不俗,但今天我们要探讨的electerm,或许能给你带来意想不到的惊…...
)
图吧工具箱下载安装和使用保姆级教程(2026实测)
图吧工具箱全名图拉丁吧硬件检测工具箱,简称 “图吧工具箱”,是国内硬件爱好者社区 “图拉丁吧” 开发维护的免费开源工具合集,2014 年首发,至今持续更新,是 DIY 玩家、装机员、普通用户公认的 “电脑硬件全能管家”。…...

8351健康管理中心用黑科技设备为企业家筑起生命防线
事业的成功固然值得骄傲,但如果没有健康作为根基,一切的辉煌都显得摇摇欲坠。对于每天在高压下决策、在商海中搏击的企业家而言,健康早已不是一句简单的口号,而是一场需要长期投入的战略投资。然而现实往往是,很多企业…...

rag 进行 全局聚合的结构性失败 解析
rag 进行 全局聚合的结构性失败 解析 目录 rag 进行 全局聚合的结构性失败 解析 一句话核心结论 逐句拆解原文含义 1. 前提:什么是"全局聚合"? 2. 致命问题:采样引入不可纠正的选择偏差 农情任务实例:直观感受结构性偏差 真实数据分布(12M农情CSV,共12000条上…...