Linux之内存管理-malloc \kmalloc\vmalloc\dma
1、malloc 函数
1.1分配内存小于128k,调用brk
malloc是C库实现的函数,C库维护了一个缓存,当内存够用时,malloc直接从C库缓存分配,只有当C库缓存不够用; 当申请的内存小于128K时,通过系统调用brk,向内核申请,从堆空间申请一个vma;当申请内存大于128K时,通过系统调用mmap申请内存。先分析brk系统调用
malloc实现流程图
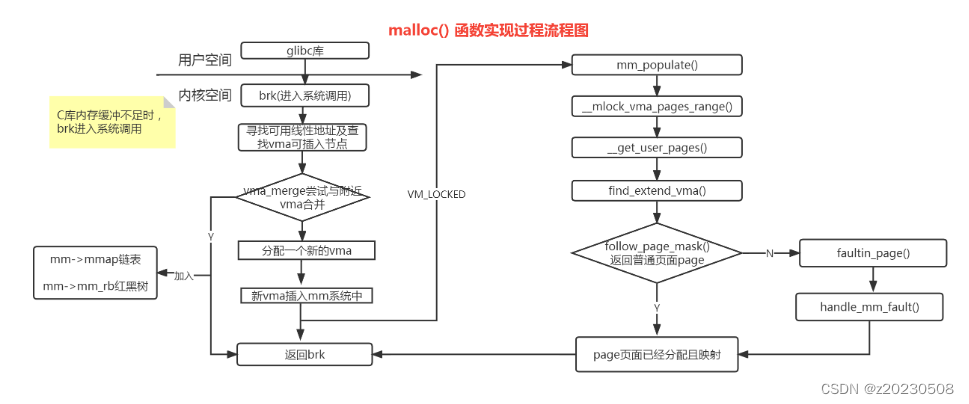
下面来看brk系统调用
经过平台相关实现,malloc最终会调用SYSCALL_DEFINE1宏,扩展为__arm64_sys_brk函数.扩展的函数名和架构相关。SYSCALL_DEFINE1 的数字1 代表参数个数,1代表一个参数。SYSCALL_DEFINEx,x最大是6.
路径:mm/mmap.c
SYSCALL_DEFINE1(brk, unsigned long, brk)
{
unsigned long retval;
unsigned long newbrk, oldbrk, origbrk;
struct mm_struct *mm = current->mm;
struct vm_area_struct *next;
unsigned long min_brk;
bool populate;
bool downgraded = false;
LIST_HEAD(uf);if (mmap_write_lock_killable(mm)) //申请写类型读写锁
return -EINTR;origbrk = mm->brk; //origbrk记录动态分配区的当前底部
#ifdef CONFIG_COMPAT_BRK
/*
* CONFIG_COMPAT_BRK can still be overridden by setting
* randomize_va_space to 2, which will still cause mm->start_brk
* to be arbitrarily shifted
*/
if (current->brk_randomized)
min_brk = mm->start_brk;
else
min_brk = mm->end_data;
#else
min_brk = mm->start_brk;
#endif
if (brk < min_brk)
goto out;/*
* Check against rlimit here. If this check is done later after the test
* of oldbrk with newbrk then it can escape the test and let the data
* segment grow beyond its set limit the in case where the limit is
* not page aligned -Ram Gupta
*/
if (check_data_rlimit(rlimit(RLIMIT_DATA), brk, mm->start_brk,
mm->end_data, mm->start_data))
goto out;newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);
if (oldbrk == newbrk) {
mm->brk = brk;
goto success;
}/*
* Always allow shrinking brk.
* __do_munmap() may downgrade mmap_lock to read.
*/
if (brk <= mm->brk) { //请求释放空间
int ret;/*
* mm->brk must to be protected by write mmap_lock so update it
* before downgrading mmap_lock. When __do_munmap() fails,
* mm->brk will be restored from origbrk.
*/
mm->brk = brk;
ret = __do_munmap(mm, newbrk, oldbrk-newbrk, &uf, true); //释放空间的真正函数
if (ret < 0) {
mm->brk = origbrk;
goto out;
} else if (ret == 1) {
downgraded = true;
}
goto success;
}/* Check against existing mmap mappings. */
next = find_vma(mm, oldbrk);
if (next && newbrk + PAGE_SIZE > vm_start_gap(next))//发现有重叠地址空间,不在寻找VMA
goto out;/* Ok, looks good - let it rip. */
if (do_brk_flags(oldbrk, newbrk-oldbrk, 0, &uf) < 0) //如果没有重叠,新分配一个VMA
goto out;
mm->brk = brk;success:
populate = newbrk > oldbrk && (mm->def_flags & VM_LOCKED) != 0;
if (downgraded)
mmap_read_unlock(mm);
else
mmap_write_unlock(mm);
userfaultfd_unmap_complete(mm, &uf);
if (populate) //调用mlockall()系统调用,mm_populate 会立刻分配物理内存。
mm_populate(oldbrk, newbrk - oldbrk);
return brk;out:
retval = origbrk;
mmap_write_unlock(mm);
return retval;
}
总结下__do_sys_brk()功能: (1)从旧的brk边界去查询,是否有可用vma,若发现有重叠,直接使用; (2)若无发现重叠,新分配一个vma; (3)应用程序若调用mlockall(),会锁住进程所有虚拟地址空间,防止内存被交换出去,且立刻分配物理内存;否则,物理页面会等到使用时,触发缺页异常分配;
do_brk_flags ()
(1)寻找一个可使用的线性地址; (2)查找最适合插入红黑树的节点; (3)寻到的线性地址是否可以合并现有vma,所不能,新建一个vma; (4)将新建vma插入mmap链表和红黑树中
/*
* this is really a simplified "do_mmap". it only handles
* anonymous maps. eventually we may be able to do some
* brk-specific accounting here.
*/
static int do_brk_flags(unsigned long addr, unsigned long len, unsigned long flags, struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
struct rb_node **rb_link, *rb_parent;
pgoff_t pgoff = addr >> PAGE_SHIFT;
int error;
unsigned long mapped_addr;/* Until we need other flags, refuse anything except VM_EXEC. */
if ((flags & (~VM_EXEC)) != 0)
return -EINVAL;
flags |= VM_DATA_DEFAULT_FLAGS | VM_ACCOUNT | mm->def_flags;//默认属性,可读写//返回未使用过的,未映射的线性地址空间的起始地址
mapped_addr = get_unmapped_area(NULL, addr, len, 0, MAP_FIXED);
if (IS_ERR_VALUE(mapped_addr))
return mapped_addr;error = mlock_future_check(mm, mm->def_flags, len);
if (error)
return error;/* Clear old maps, set up prev, rb_link, rb_parent, and uf */
//寻找适合插入的红黑树节点
if (munmap_vma_range(mm, addr, len, &prev, &rb_link, &rb_parent, uf))
return -ENOMEM;/* Check against address space limits *after* clearing old maps... */
if (!may_expand_vm(mm, flags, len >> PAGE_SHIFT))
return -ENOMEM;if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;if (security_vm_enough_memory_mm(mm, len >> PAGE_SHIFT))
return -ENOMEM;/* Can we just expand an old private anonymous mapping? */
//检查是否能合并到addr 到附近的vma,若不能,只能新建一个vma
vma = vma_merge(mm, prev, addr, addr + len, flags,
NULL, NULL, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;/*
* create a vma struct for an anonymous mapping
*/
vma = vm_area_alloc(mm); // 新建一个vma
if (!vma) {
vm_unacct_memory(len >> PAGE_SHIFT);
return -ENOMEM;
}vma_set_anonymous(vma);
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_pgoff = pgoff;
vma->vm_flags = flags;
vma->vm_page_prot = vm_get_page_prot(flags);
vma_link(mm, vma, prev, rb_link, rb_parent); // 新vma添加到mmap链表和红黑树中
out:
perf_event_mmap(vma);
mm->total_vm += len >> PAGE_SHIFT;
mm->data_vm += len >> PAGE_SHIFT;
if (flags & VM_LOCKED)
mm->locked_vm += (len >> PAGE_SHIFT);
vma->vm_flags |= VM_SOFTDIRTY;
return 0;
}
如果调用mlockall 系统调用,mm_populate 会立刻分配物理内存
mm_populate()
mm_populate
->_mm_populate
->populate_vma_page_range
->__get_user_pages
当设置VM_LOCKED标志时,表示要马上申请物理页面,并与vma建立映射; 否则,这里不操作,直到访问该vma时,触发缺页异常,再分配物理页面,并建立映射;
__get_user_pages()
static long __get_user_pages(struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
struct vm_area_struct **vmas, int *locked)
{
long ret = 0, i = 0;
struct vm_area_struct *vma = NULL;
struct follow_page_context ctx = { NULL };if (!nr_pages)
return 0;start = untagged_addr(start);
VM_BUG_ON(!!pages != !!(gup_flags & (FOLL_GET | FOLL_PIN)));
/*
* If FOLL_FORCE is set then do not force a full fault as the hinting
* fault information is unrelated to the reference behaviour of a task
* using the address space
*/
if (!(gup_flags & FOLL_FORCE))
gup_flags |= FOLL_NUMA;do { //依次处理每个页面
struct page *page;
unsigned int foll_flags = gup_flags;
unsigned int page_increm;/* first iteration or cross vma bound */
if (!vma || start >= vma->vm_end) {
vma = find_extend_vma(mm, start); //检查是否可以扩展VMA
if (!vma && in_gate_area(mm, start)) {
ret = get_gate_page(mm, start & PAGE_MASK,
gup_flags, &vma,
pages ? &pages[i] : NULL);
if (ret)
goto out;
ctx.page_mask = 0;
goto next_page;
}if (!vma || check_vma_flags(vma, gup_flags)) {
ret = -EFAULT;
goto out;
}
if (is_vm_hugetlb_page(vma)) { // 支持巨页
i = follow_hugetlb_page(mm, vma, pages, vmas,
&start, &nr_pages, i,
gup_flags, locked);
if (locked && *locked == 0) {
/*
* We've got a VM_FAULT_RETRY
* and we've lost mmap_lock.
* We must stop here.
*/
BUG_ON(gup_flags & FOLL_NOWAIT);
BUG_ON(ret != 0);
goto out;
}
continue;
}
}
retry:
/*
* If we have a pending SIGKILL, don't keep faulting pages and
* potentially allocating memory.
*/
if (fatal_signal_pending(current)) { //如果当前进程收到KILL 信号,直接退出
ret = -EINTR;
goto out;
}
cond_resched(); //判断是否需要调度,这个函数是为优化系统延迟//查看VMA的虚拟页面是否已经分配物理页面内存,返回已经映射的页面的page.
page = follow_page_mask(vma, start, foll_flags, &ctx);
if (!page) {/若无映射,主动触发虚拟页面到物理页面的映射
ret = faultin_page(vma, start, &foll_flags, locked);
switch (ret) {
case 0:
goto retry;
case -EBUSY:
ret = 0;
fallthrough;
case -EFAULT:
case -ENOMEM:
case -EHWPOISON:
goto out;
case -ENOENT:
goto next_page;
}
BUG();
} else if (PTR_ERR(page) == -EEXIST) {
/*
* Proper page table entry exists, but no corresponding
* struct page.
*/
goto next_page;
} else if (IS_ERR(page)) {
ret = PTR_ERR(page);
goto out;
}
if (pages) {
pages[i] = page;
flush_anon_page(vma, page, start);//分配完物理页面,刷新缓存
flush_dcache_page(page);
ctx.page_mask = 0;
}
next_page:
if (vmas) {
vmas[i] = vma;
ctx.page_mask = 0;
}
page_increm = 1 + (~(start >> PAGE_SHIFT) & ctx.page_mask);
if (page_increm > nr_pages)
page_increm = nr_pages;
i += page_increm;
start += page_increm * PAGE_SIZE;
nr_pages -= page_increm;
} while (nr_pages);
out:
if (ctx.pgmap)
put_dev_pagemap(ctx.pgmap);
return i ? i : ret;
}
follow_page_mask
->follow_p4d_mask
->follow_pud_mask
->follow_pmd_mask
->follow_page_pte
follow_page_pte
static struct page *follow_page_pte(struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd, unsigned int flags,
struct dev_pagemap **pgmap)
{
struct mm_struct *mm = vma->vm_mm;
struct page *page;
spinlock_t *ptl;
pte_t *ptep, pte;
int ret;/* FOLL_GET and FOLL_PIN are mutually exclusive. */
if (WARN_ON_ONCE((flags & (FOLL_PIN | FOLL_GET)) ==
(FOLL_PIN | FOLL_GET)))
return ERR_PTR(-EINVAL);
retry:
if (unlikely(pmd_bad(*pmd)))
return no_page_table(vma, flags);ptep = pte_offset_map_lock(mm, pmd, address, &ptl); //获得pte 和一个锁
pte = *ptep;
if (!pte_present(pte)) { //若此pte 不在内存中,作下面的处理
swp_entry_t entry;
/*
* KSM's break_ksm() relies upon recognizing a ksm page
* even while it is being migrated, so for that case we
* need migration_entry_wait().
*/
if (likely(!(flags & FOLL_MIGRATION)))
goto no_page;
if (pte_none(pte))
goto no_page;
entry = pte_to_swp_entry(pte);
if (!is_migration_entry(entry))
goto no_page;
pte_unmap_unlock(ptep, ptl);
migration_entry_wait(mm, pmd, address); //等待页面合并完成后再尝试
goto retry;
}
if ((flags & FOLL_NUMA) && pte_protnone(pte))
goto no_page;
if ((flags & FOLL_WRITE) && !can_follow_write_pte(pte, flags)) {
pte_unmap_unlock(ptep, ptl);
return NULL;
}//根据pte,返回物理页面page,只返回普通页面,特殊页面不参与内存管理
page = vm_normal_page(vma, address, pte);
if (!page && pte_devmap(pte) && (flags & (FOLL_GET | FOLL_PIN))) {
/*
* Only return device mapping pages in the FOLL_GET or FOLL_PIN
* case since they are only valid while holding the pgmap
* reference.
*/
*pgmap = get_dev_pagemap(pte_pfn(pte), *pgmap);//处理设备映射文件
if (*pgmap)
page = pte_page(pte);
else
goto no_page;
} else if (unlikely(!page)) {//处理vm_normal_page()没有返回有效页面情况
if (flags & FOLL_DUMP) {
/* Avoid special (like zero) pages in core dumps */
page = ERR_PTR(-EFAULT);
goto out;
}if (is_zero_pfn(pte_pfn(pte))) {//系统零页,不会返回错误
page = pte_page(pte);
} else {
ret = follow_pfn_pte(vma, address, ptep, flags);
page = ERR_PTR(ret);
goto out;
}
}if (flags & FOLL_SPLIT && PageTransCompound(page)) {
get_page(page);
pte_unmap_unlock(ptep, ptl);
lock_page(page);
ret = split_huge_page(page);
unlock_page(page);
put_page(page);
if (ret)
return ERR_PTR(ret);
goto retry;
}/* try_grab_page() does nothing unless FOLL_GET or FOLL_PIN is set. */
if (unlikely(!try_grab_page(page, flags))) {
page = ERR_PTR(-ENOMEM);
goto out;
}
/*
* We need to make the page accessible if and only if we are going
* to access its content (the FOLL_PIN case). Please see
* Documentation/core-api/pin_user_pages.rst for details.
*/
if (flags & FOLL_PIN) {
ret = arch_make_page_accessible(page);
if (ret) {
unpin_user_page(page);
page = ERR_PTR(ret);
goto out;
}
}
if (flags & FOLL_TOUCH) { //标记页面可访问
if ((flags & FOLL_WRITE) &&
!pte_dirty(pte) && !PageDirty(page))
set_page_dirty(page);
/*
* pte_mkyoung() would be more correct here, but atomic care
* is needed to avoid losing the dirty bit: it is easier to use
* mark_page_accessed().
*/
mark_page_accessed(page);
}
if ((flags & FOLL_MLOCK) && (vma->vm_flags & VM_LOCKED)) {/* Do not mlock pte-mapped THP */
if (PageTransCompound(page))
goto out;/*
* The preliminary mapping check is mainly to avoid the
* pointless overhead of lock_page on the ZERO_PAGE
* which might bounce very badly if there is contention.
*
* If the page is already locked, we don't need to
* handle it now - vmscan will handle it later if and
* when it attempts to reclaim the page.
*/
if (page->mapping && trylock_page(page)) {
lru_add_drain(); /* push cached pages to LRU */
/*
* Because we lock page here, and migration is
* blocked by the pte's page reference, and we
* know the page is still mapped, we don't even
* need to check for file-cache page truncation.
*/
mlock_vma_page(page);
unlock_page(page);
}
}
out:
pte_unmap_unlock(ptep, ptl);
return page;
no_page:
pte_unmap_unlock(ptep, ptl);
if (!pte_none(pte))
return NULL;
return no_page_table(vma, flags);
}
总结:
(1)malloc函数,从C库缓存分配内存,其分配或释放内存,未必马上会执行;
(2)malloc实际分配内存动作,要么主动设置mlockall(),人为触发缺页异常,分配物理页面;或者在访问内存时触发缺页异常,分配物理页面;
(3)malloc分配虚拟内存,有三种情况: a.malloc()分配内存后,直接读,linux内核进入缺页异常,调用do_anonymous_page函数使用零页映射,此时PTE属性只读; b.malloc()分配内存后,先读后写,linux内核第一次触发缺页异常,映射零页;第二次触发异常,触发写时复制; c.malloc()分配内存后, 直接写,linux内核进入匿名页面的缺页异常,调用alloc_zeroed_user_highpage_movable分配一个新页面,这个PTE是可写的;
1.2 分配内存大于128K,调用mmap函数
mmap一般用于用户程序分配内存,读写大文件,链接动态库,多进程内存共享等; 实现过程流程图:
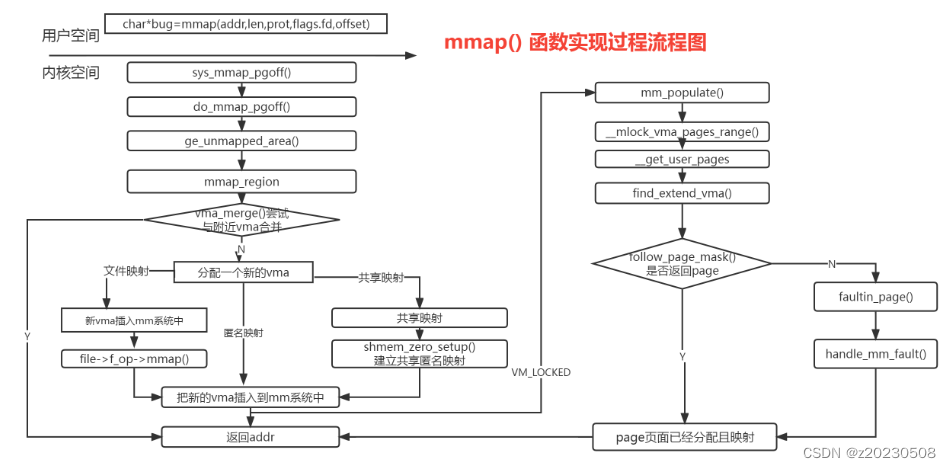
mmap根据文件关联性和映射区域是否共享等属性,其映射分为4类 :
1.私有匿名映射 fd=-1,且flags=MAP_ANONYMOUS|MAP_PRIVATE,创建的mmap映射是私有匿名映射; 用途是在glibc分配大内存时,如果需分配内存大于MMAP_THREASHOLD(128KB),glibc默认用mmap代替brk分配内存;
2.共享匿名映射 fd=-1,且flags=MAP_ANONYMOUS|MAP_SHARED; 常用于父子进程的通信,共享一块内存区域; do_mmap_pgoff()->mmap_region(),最终调用shmem_zero_setup打开/dev/zero设备文件;
另外直接打开/dev/zero设备文件,然后使用这个句柄创建mmap,也是最终调用shmem模块创建共享匿名映射;
3.私有文件映射 flags=MAP_PRIVATE; 常用场景是,加载动态共享库;
4.共享文件映射 flags=MAP_SHARED;有两个应用场景; (1)读写文件: 内核的会写机制会将内存数据同步到磁盘; (2)进程间通信: 多个独立进程,打开同一个文件,互相都可以观察到,可是实现多进程通信;
路径: mm/mmap.c
mmap_pgoff 宏定义
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
return ksys_mmap_pgoff(addr, len, prot, flags, fd, pgoff);
}
ksys_mmap_pgoff
->vm_mmap_pgoff
->do_mmap
->mmap_region
核心函数:
mmap_region
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev, *merge;
int error;
struct rb_node **rb_link, *rb_parent;
unsigned long charged = 0;/* Check against address space limit. */
if (!may_expand_vm(mm, vm_flags, len >> PAGE_SHIFT)) {
unsigned long nr_pages;/*
* MAP_FIXED may remove pages of mappings that intersects with
* requested mapping. Account for the pages it would unmap.
*/
nr_pages = count_vma_pages_range(mm, addr, addr + len);if (!may_expand_vm(mm, vm_flags,
(len >> PAGE_SHIFT) - nr_pages))
return -ENOMEM;
}/* Clear old maps, set up prev, rb_link, rb_parent, and uf */
if (munmap_vma_range(mm, addr, len, &prev, &rb_link, &rb_parent, uf))
return -ENOMEM;
/*
* Private writable mapping: check memory availability
*/
if (accountable_mapping(file, vm_flags)) {
charged = len >> PAGE_SHIFT;
if (security_vm_enough_memory_mm(mm, charged))
return -ENOMEM;
vm_flags |= VM_ACCOUNT;
}/*
* Can we just expand an old mapping?
*/
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX); //尝试合并VMA
if (vma)
goto out;/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
vma = vm_area_alloc(mm);// 分配VMA
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;if (file) { -----------------------------------------------文件映射
if (vm_flags & VM_DENYWRITE) {
error = deny_write_access(file);
if (error)
goto free_vma;
}
if (vm_flags & VM_SHARED) {
error = mapping_map_writable(file->f_mapping);
if (error)
goto allow_write_and_free_vma;
}/* ->mmap() can change vma->vm_file, but must guarantee that
* vma_link() below can deny write-access if VM_DENYWRITE is set
* and map writably if VM_SHARED is set. This usually means the
* new file must not have been exposed to user-space, yet.
*/
vma->vm_file = get_file(file);
error = call_mmap(file, vma);
if (error)
goto unmap_and_free_vma;/* Can addr have changed??
*
* Answer: Yes, several device drivers can do it in their
* f_op->mmap method. -DaveM
* Bug: If addr is changed, prev, rb_link, rb_parent should
* be updated for vma_link()
*/
WARN_ON_ONCE(addr != vma->vm_start);addr = vma->vm_start;
/* If vm_flags changed after call_mmap(), we should try merge vma again
* as we may succeed this time.
*/
if (unlikely(vm_flags != vma->vm_flags && prev)) {
merge = vma_merge(mm, prev, vma->vm_start, vma->vm_end, vma->vm_flags,
NULL, vma->vm_file, vma->vm_pgoff, NULL, NULL_VM_UFFD_CTX);
if (merge) {
/* ->mmap() can change vma->vm_file and fput the original file. So
* fput the vma->vm_file here or we would add an extra fput for file
* and cause general protection fault ultimately.*/
fput(vma->vm_file);
vm_area_free(vma);
vma = merge;
/* Update vm_flags to pick up the change. */
vm_flags = vma->vm_flags;
goto unmap_writable;
}
}vm_flags = vma->vm_flags;
} else if (vm_flags & VM_SHARED) { -------------共享映射
error = shmem_zero_setup(vma); -----------共享匿名映射
if (error)
goto free_vma;
} else {
vma_set_anonymous(vma); --------------匿名映射
}/* Allow architectures to sanity-check the vm_flags */
if (!arch_validate_flags(vma->vm_flags)) {
error = -EINVAL;
if (file)
goto unmap_and_free_vma;
else
goto free_vma;
}vma_link(mm, vma, prev, rb_link, rb_parent); ---------vma 加入mm系统
/* Once vma denies write, undo our temporary denial count */
if (file) {
unmap_writable:
if (vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
if (vm_flags & VM_DENYWRITE)
allow_write_access(file);
}
file = vma->vm_file;
out:
perf_event_mmap(vma);vm_stat_account(mm, vm_flags, len >> PAGE_SHIFT);
if (vm_flags & VM_LOCKED) {
if ((vm_flags & VM_SPECIAL) || vma_is_dax(vma) ||
is_vm_hugetlb_page(vma) ||
vma == get_gate_vma(current->mm))
vma->vm_flags &= VM_LOCKED_CLEAR_MASK;
else
mm->locked_vm += (len >> PAGE_SHIFT);
}if (file)
uprobe_mmap(vma);/*
* New (or expanded) vma always get soft dirty status.
* Otherwise user-space soft-dirty page tracker won't
* be able to distinguish situation when vma area unmapped,
* then new mapped in-place (which must be aimed as
* a completely new data area).
*/
vma->vm_flags |= VM_SOFTDIRTY;vma_set_page_prot(vma);
return addr;
unmap_and_free_vma:
vma->vm_file = NULL;
fput(file);/* Undo any partial mapping done by a device driver. */
unmap_region(mm, vma, prev, vma->vm_start, vma->vm_end);
charged = 0;
if (vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
allow_write_and_free_vma:
if (vm_flags & VM_DENYWRITE)
allow_write_access(file);
free_vma:
vm_area_free(vma);
unacct_error:
if (charged)
vm_unacct_memory(charged);
return error;
}
总结: 以上的malloc,mmap函数,若无特别设定,默认都是指建立虚拟地址空间,但没有建立虚拟地址空间到物理地址空间的映射; 当访问未映射的虚拟空间时,触发缺页异常,linxu内核会处理缺页异常,缺页异常服务程序中,会分配物理页,并建立虚拟地址到物理页的映射;
补充两个问题:
1.当mmap重复申请相同地址,为什么不会失败? find_vma_links()函数便利该进程所有的vma,当检查到当前要映射区域和已有vma重叠时,先销毁旧映射区,重新映射,所以第二次申请,不会报错。
2.mmap打开多个文件时,比如播放视频时,为什么会卡顿? mmap只是建立vma,并未实际分配物理页面读取文件内存,当播放器真正读取文件时,会频繁触发缺页异常,再从磁盘读取文件到页面高速缓存中,会导致磁盘读性能较差;
madvise(add,len,MADV_WILLNEED|MADV_SEQUENTIAL)对文件内容进行预读和顺序读;
但是内核默认的预读功能就可以实现;且madvise不适合流媒体,只适合随机读取场景;
能够有效提高流媒体服务I/O性能的方法是增大内核默认预读窗口;内核默认是128K,可以通过“blockdev --setra”命令修改;
3、mmap 访问文件为什么快?
mmap()系统调用用于在进程的虚拟地址空间中创建新的内存映射。内存分配器通常使用这个系统调用来创建私有匿名映射,以分配内存。内核会按照页面大小的倍数(通常为4096字节)来分配内存,函数原型如下:
#include <unistd\.h>void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);一旦建立了这种映射关系,进程就可以通过指针的方式来读写这段内存,而系统会自动将脏页(被修改的页)回写到相应的磁盘文件上。这意味着进程可以通过直接访问内存来完成对文件的操作,而无需再调用read、write等系统调用函数。
除了减少read、write等系统调用外,mmap()还可以减少内存拷贝的次数。例如,在使用read调用时,典型的流程是操作系统首先将磁盘文件内容读入页缓存,然后再将数据从页缓存复制到read传递的缓冲区中。然而,使用mmap()后,操作系统只需将磁盘数据读入页缓存,然后进程可以直接通过指针方式操作mmap映射的内存,从而减少了从内核态到用户态的数据拷贝。
2、kmalloc 函数
路径:include/linux/slab.h
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
#ifndef CONFIG_SLOB
unsigned int index;
#endif
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
#ifndef CONFIG_SLOB
index = kmalloc_index(size);if (!index)
return ZERO_SIZE_PTR;return kmem_cache_alloc_trace(
kmalloc_caches[kmalloc_type(flags)][index],
flags, size);
#endif
}
return __kmalloc(size, flags);
}
相关文章:
Linux之内存管理-malloc \kmalloc\vmalloc\dma
1、malloc 函数 1.1分配内存小于128k,调用brk malloc是C库实现的函数,C库维护了一个缓存,当内存够用时,malloc直接从C库缓存分配,只有当C库缓存不够用; 当申请的内存小于128K时,通过系统调用brkÿ…...

PyTorch中定义自己的数据集
文章目录 1. 简介2. 查看PyTorch自带的数据集(可视化)3. 准备材料3.1 图片数据3.2 标签数据 4. 方法 1. 简介 尽管PyTorch提供了许多自带的数据集,如MNIST、CIFAR-10、ImageNet等,但它们对于没有经验的用户来说,理解数据加载器的工作原理以及…...

助力数字农林业发展服务香榧智慧种植,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建香榧种植场景下香榧果实检测识别系统
作为一个生在北方但在南方居住多年的人,居然头一次听过香榧(fei)这种作物,而且这个字还不会念,查了以后才知道读音(fei),三声,这着实引起了我的好奇心,我相信…...
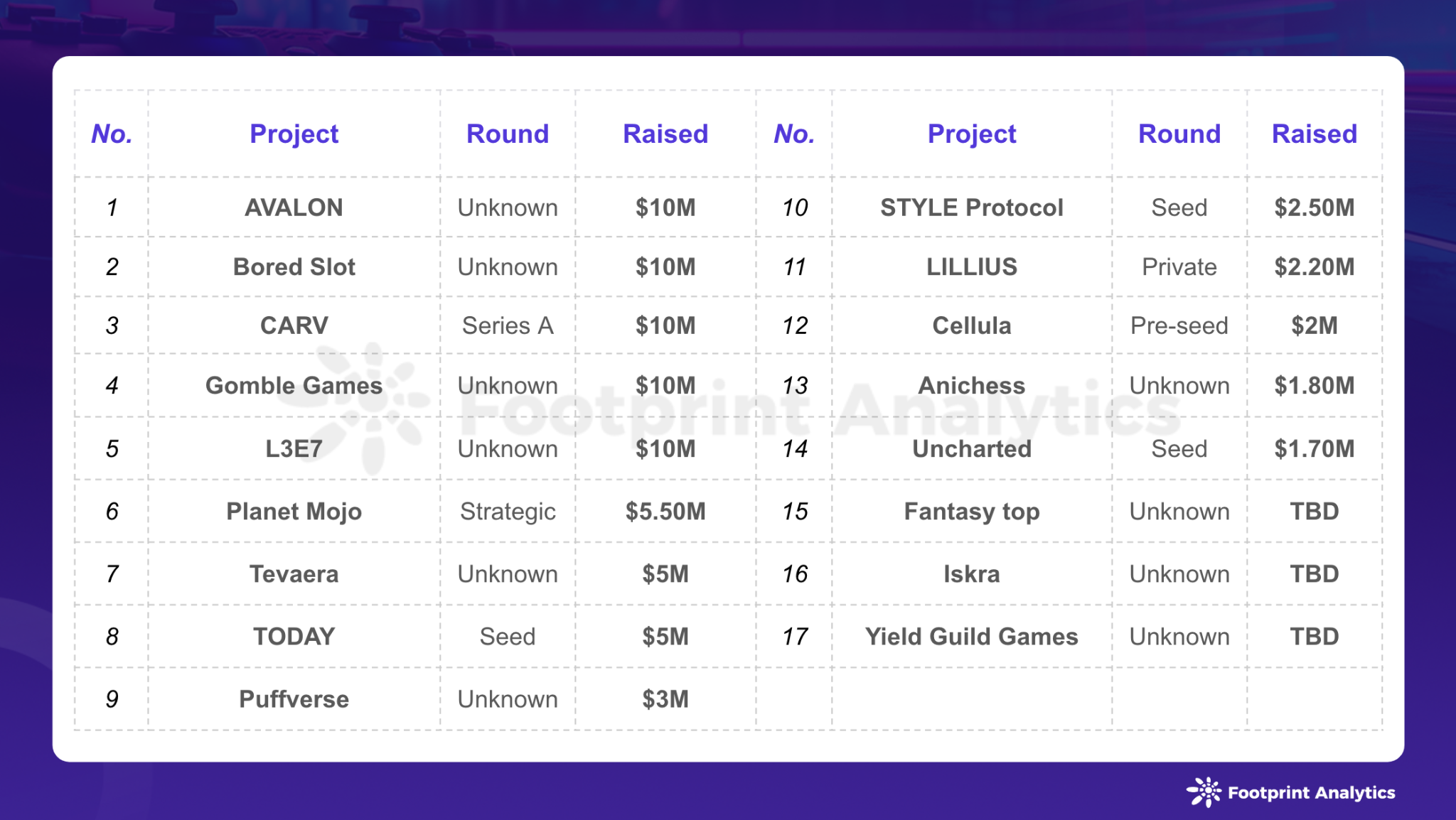
2024 年 4 月区块链游戏研报:市场低迷中活跃用户数创新高
2024 年 4 月区块链游戏研报 作者:stellafootprint.network 数据来源:GameFi 研究页面 2024 年 4 月,Web3 游戏领域在经历 3 月创纪录的表现后,迎来了显著波动。比特币自历史高位回调,月跌幅达到 10.4%。与此同时&a…...

排序(一)----冒泡排序,插入排序
前言 今天讲一些简单的排序,冒泡排序和插入排序,但是这两个排序时间复杂度较大,只是起到一定的学习作用,只需要了解并会使用就行,本文章是以升序为例子来介绍的 一冒泡排序 思路 冒泡排序是一种简单的排序算法,它重复地遍历要排序的序列,每次比较相邻…...

springcloud简单了解及上手
springcloud微服务框架简单上手 文章目录 springcloud微服务框架简单上手一、SpringCloud简单介绍1.1 单体架构1.2 分布式架构1.3 微服务 二、SpringCloud与SpringBoot的版本对应关系2022.x 分支2021.x 分支2.2.x 分支 三、Nacos注册中心3.1 认识和安装Nacos3.2 配置Nacos3.3 n…...

Halcon与深度学习框架结合进行图像分析
Halcon 是一款强大的机器视觉软件,而深度学习框架如 TensorFlow 或 PyTorch 在图像识别和分类任务中表现出色。结合两者的优势,可以实现复杂的图像分析任务。Halcon 负责图像预处理和特征提取,而深度学习框架则利用这些特征进行高级分析和识别…...
STL----push,insert,empalce
push_back和emplace_back的区别 #include <iostream> #include <vector>using namespace std; class testDemo { public:testDemo(int n) :num(n) {cout << "构造函数" << endl;}testDemo(const testDemo& other) :num(other.num) {cou…...
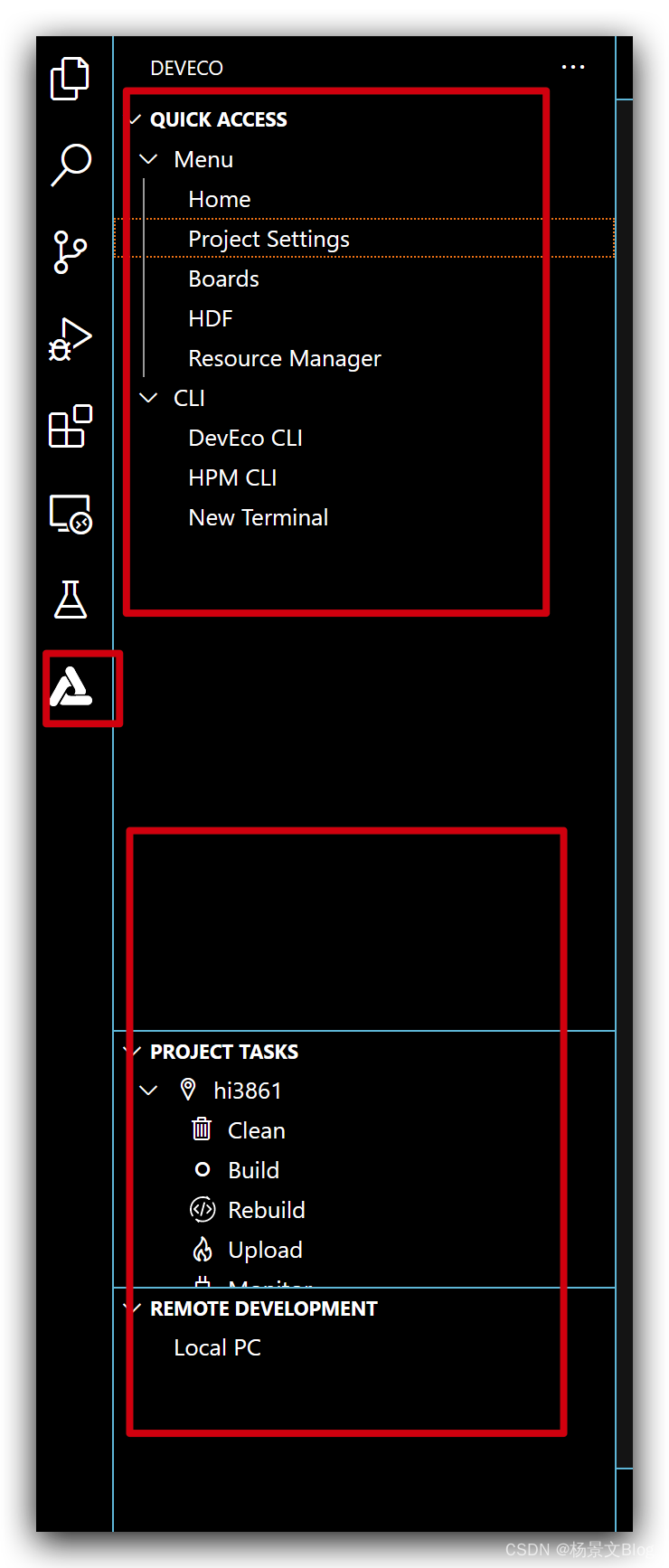
解决OpenHarmony设备开发Device Tools工具的QUICK ACCESS一直为空
今天重新安装了OpenHarmony设备开发的环境,在安装过程中,到了工程之后,QUICK ACCESS一直为空。如下图红色大方框的内容一开始没有。 解决方案: 在此记录我的原因,我的原因主要是deveco device tools的远程连接的是z…...

k8s拉起一个pod底层是如何运行的
在Kubernetes中,当你尝试启动一个Pod时,底层的运行方式是由Kubelet服务来管理的。以下是Pod启动过程的简化概述: Kubernetes API Server接收到创建Pod的请求。 API Server将Pod的元数据存储到etcd中,以便于Pod的调度和跟踪。 Sc…...
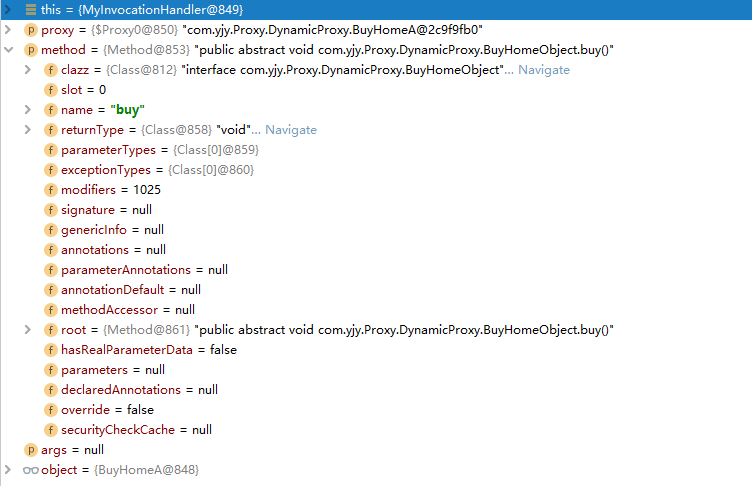
Java代理模式的实现详解
一、前言 1.1、说明 本文章是在学习mybatis框架源码的过程中,发现对于动态代理Mapper接口这一块的代理实现还是有些遗忘和陌生,因此在本文章中就Java实现代理模式的过程进行一个学习和总结。 1.2、参考文章 《设计模式》(第2版࿰…...
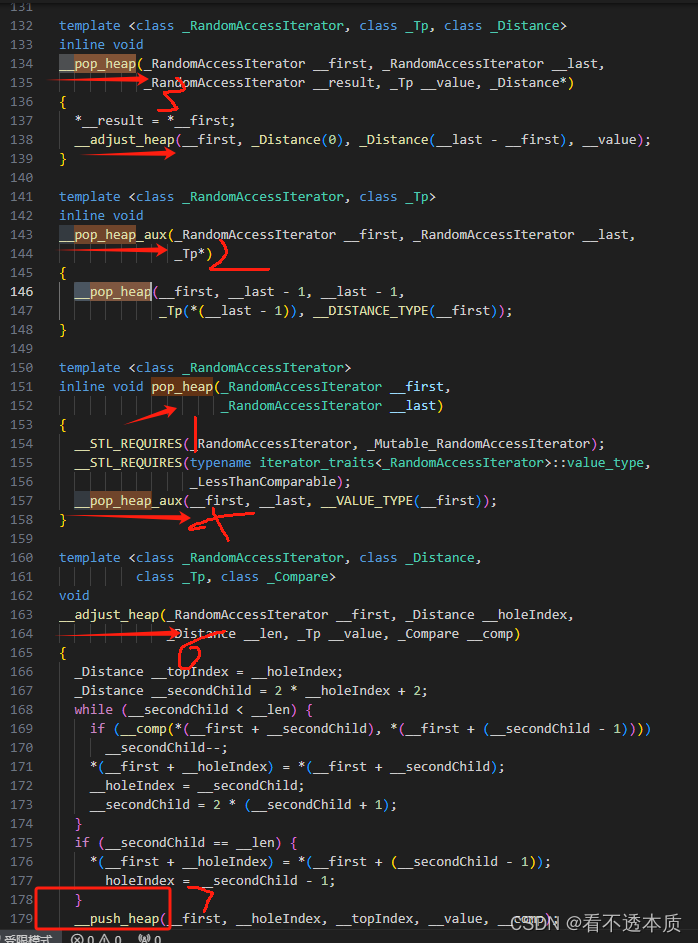
数据结构与算法===优先队列
文章目录 前言一、优先队列二、应用场景三、代码实现总结 前言 之前写过很多数据结构与算法相关的了,今天看一个新的数据结构,优先队列。优先队列类似队列,却又优先于队列,是堆实现的。接下来详细看看。 一、优先队列 优先队列一…...

HTML常用标签-超链接标签
超链接标签 点击后带有链接跳转的标签 ,也叫作a标签 href属性用于定义连接 href中可以使用绝对路径,以/开头,始终以一个固定路径作为基准路径作为出发点href中也可以使用相对路径,不以/开头,以当前文件所在路径为出发点href中也可以定义完整的URL target用于定义打开的方式 _b…...

财务管理|基于SprinBoot+vue的财务管理系统(源码+数据库+文档)
财务管理系统 目录 基于SprinBootvue的财务管理系统 一、前言 二、系统设计 三、系统功能设计 系统功能实现 1管理员功能模块 2员工功能模块 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍࿱…...
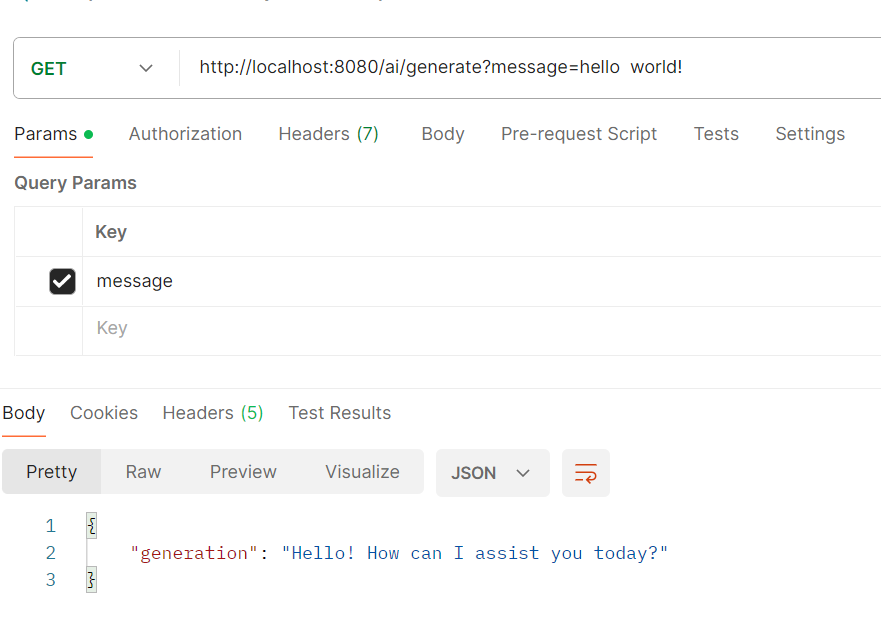
快速学习SpringAi
Spring AI是AI工程师的一个应用框架,它提供了一个友好的API和开发AI应用的抽象,旨在简化AI应用的开发工序,例如开发一款基于ChatGPT的对话应用程序。通过使用Spring Ai使我们更简单直接使用chatgpt 1.创建项目 jdk17 引入依赖 2.依赖配置 …...
谈谈 Spring 的过滤器和拦截器
前言 我们在进行 Web 应用开发时,时常需要对请求进行拦截或处理,故 Spring 为我们提供了过滤器和拦截器来应对这种情况。那么两者之间有什么不同呢?本文将详细讲解两者的区别和对应的使用场景。 (本文的代码实现首先是基于 Sprin…...

请介绍下H264的多参考帧技术及其应用场景,并请说明下为什么要有多参考帧?
H.264(也称为H.264/AVC)的多参考帧机制是其编码效率和质量提升的关键部分。这个机制允许编码器在编码当前帧时,参考多个之前已编码的帧。这种多参考帧的方法为编码器提供了更多的选择,使其能够更准确地预测当前帧的内容࿰…...

第6章 Elasticsearch,分布式搜索引擎【仿牛客网社区论坛项目】
第6章 Elasticsearch,分布式搜索引擎【仿牛客网社区论坛项目】 前言推荐项目总结第6章 Elasticsearch,分布式搜索引擎1.Elasticsearch入门2.Spring整合ElasticsearchDiscussPostRepositoryDiscussPostControllerEventConsumer 3.开发社区搜索功能 最后 前…...
)
odoo 全局调整list_controller中默认方法(form_controller和kanban_controller等亦可以同样操作)
需求说明 工作中遇到需要调整odoo原生的tree hearder button显示逻辑,又不可以直接跳转odoo源码,故新加个js全局替换对应的方法,以实现对应功能的同时不影响后期odoo版本升级。 odoo 全局调整list_controller方法示例 创建一个js放到stati…...

大模型日报2024-05-13
大模型日报 2024-05-13 大模型资讯 谷歌推出Gemini生成式AI平台 摘要: 生成式人工智能正在改变我们与技术的互动方式。谷歌最近推出了名为Gemini的新平台,该平台代表了其在生成式AI领域的最新进展。Gemini平台集成了一系列先进的工具和功能,旨在为用户提…...

工业级AI计算机如何支撑机场eGate系统:BOXER-6646-ADP硬件与部署解析
1. 项目概述:当“刷脸通关”成为现实,背后是谁在支撑?每次在机场国际出发或到达大厅,看到那些排着长队等待人工查验护照、盖章的队伍,你是不是也幻想过能像科幻电影里那样,走到一个闸机前,刷一下…...

通过curl命令快速测试Taotoken API为大赛创意生成提供灵感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken API为大赛创意生成提供灵感 对于赛事组织者而言,快速验证技术方案、获取创意灵感是日常…...
)
ESP8266 AT指令连接阿里云物联网平台,我踩过的那些坑(附client_id转义完整解决方案)
ESP8266 AT指令连接阿里云物联网平台的实战避坑指南 当ESP8266遇上阿里云物联网平台,本该是物联网开发的黄金组合,却总在AT指令的细节处暗藏杀机。记得第一次用ATMQTTUSERCFG配置客户端时,那个带着逗号的client_id让我在深夜的实验室里对着串…...
)
告别Rufus!在Ubuntu 22.04上用Ventoy打造你的万能Windows安装盘(附PE系统集成)
在Ubuntu 22.04上使用Ventoy打造全能Windows安装与维护工具盘 作为一名长期以Linux为主力系统的开发者,难免会遇到需要为朋友或备用机安装Windows的场景。传统方案往往要求我们临时切换到Windows环境使用Rufus等工具,既低效又违背Linux用户的习惯。本文将…...

终极免费窗口强制调整工具:如何突破Windows尺寸限制
终极免费窗口强制调整工具:如何突破Windows尺寸限制 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些无法拖拽的"顽固窗口"而烦恼吗?Wi…...

从信号处理到AI:卷积的含参积分本质,如何帮你理解PyTorch中的Conv1d层?
从信号处理到AI:卷积的含参积分本质,如何帮你理解PyTorch中的Conv1d层? 在信号处理领域,卷积操作早已是工程师们耳熟能详的工具。但当我们踏入深度学习的殿堂,面对PyTorch中的nn.Conv1d层时,是否曾疑惑过&a…...

从零开始:YY3568开发板刷写原生Linux系统全流程指南
1. 项目概述与核心价值 最近拿到了一块YY3568开发板,这是一款基于瑞芯微RK3568芯片的嵌入式开发平台,性能相当不错。很多朋友拿到开发板后,第一反应就是跟着官方文档跑个Demo,或者直接用板子预装的Android系统。但如果你和我一样&…...

Midjourney年度订阅避坑手册:92%用户不知的3大失效风险——自动续费陷阱、区域定价欺诈、账户绑定漏洞
更多请点击: https://intelliparadigm.com 第一章:Midjourney年度订阅优惠全景透视 Midjourney 作为当前主流的 AI 图像生成服务,其年度订阅计划长期受到创作者与团队用户的高度关注。相比月度订阅,年度方案不仅显著降低单月成本…...

WPF-Control核心架构思想
WPF-Control 项目架构详解 一、核心架构思想 这个项目的架构可以用一句话概括:控件负责显示,服务负责能力,模块负责组合,主题负责外观,ApplicationBase 负责生命周期,IOC 负责连接所有对象。这是一种典型的…...

Taotoken用量看板与账单追溯为团队开发带来的成本管控体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与账单追溯为团队开发带来的成本管控体验 对于依赖大模型API进行开发的团队而言,成本的可观测与可控性…...