Spring源码解析-Spring 循环依赖
Spring源码解析简图:

Spring 如何解决循环依赖,⽹上的资料很多,但是感觉写得好的极少,特别是源码解读⽅⾯,我就⾃⼰单独出⼀ 篇,这篇⽂章绝对肝!
文章目录:

一. 基础知识
1.1 什么是循环依赖 ?
⼀个或多个对象之间存在直接或间接的依赖关系,这种依赖关系构成⼀个环形调⽤,有下⾯ 3 种⽅式。

我们看⼀个简单的 Demo,对标“情况 2”。
@Service
public class Model1 {@Autowiredprivate Model2 model2;public void test1() {}
}
@Service
public class Model2 {@Autowiredprivate Model1 model1;public void test2() {}
}
复制代码这是⼀个经典的循环依赖,它能正常运⾏,后⾯我们会通过源码的⻆度,解读整体的执⾏流程。
1.2 三级缓存
解读源码流程之前,spring 内部的三级缓存逻辑必须了解,要不然后⾯看代码会蒙圈。
- 第⼀级缓存:singletonObjects,⽤于保存实例化、注⼊、初始化完成的 bean 实例;
- 第⼆级缓存:earlySingletonObjects,⽤于保存实例化完成的 bean 实例;
- 第三级缓存:singletonFactories,⽤于保存 bean 创建⼯⼚,以便后⾯有机会创建代理对象。
这是最核⼼,我们直接上源码:

执⾏逻辑:
- 先从“第⼀级缓存”找对象,有就返回,没有就找“⼆级缓存”;
- 找“⼆级缓存”,有就返回,没有就找“三级缓存”;
- 找“三级缓存”,找到了,就获取对象,放到“⼆级缓存”,从“三级缓存”移除。
1.3 原理执⾏流程
我把“情况 2”执⾏的流程分解为下⾯ 3 步,是不是和“套娃”很像 ?

整个执⾏逻辑如下:
- 在第⼀层中,先去获取 A 的 Bean,发现没有就准备去创建⼀个,然后将 A 的代理⼯⼚放⼊“三级缓存”(这个 A 其实是⼀个半成品,还没有对⾥⾯的属性进⾏注⼊),但是 A 依赖 B 的创建,就必须先去创建 B;
- 在第⼆层中,准备创建 B,发现 B ⼜依赖 A,需要先去创建 A;
- 在第三层中,去创建 A,因为第⼀层已经创建了 A 的代理⼯⼚,直接从“三级缓存”中拿到 A 的代理⼯⼚,获 取 A 的代理对象,放⼊“⼆级缓存”,并清除“三级缓存”;
- 回到第⼆层,现在有了 A 的代理对象,对 A 的依赖完美解决(这⾥的 A 仍然是个半成品),B 初始化成功;
- 回到第⼀层,现在 B 初始化成功,完成 A 对象的属性注⼊,然后再填充 A 的其它属性,以及 A 的其它步骤 (包括 AOP),完成对 A 完整的初始化功能(这⾥的 A 才是完整的 Bean)。
- 将 A 放⼊“⼀级缓存”。
为什么要⽤ 3 级缓存 ?我们先看源码执⾏流程,后⾯我会给出答案。
二. 源码解读
注意:Spring 的版本是 5.2.15.RELEASE,否则和我的代码不⼀样!!!
上⾯的知识,⽹上其实都有,下⾯才是我们的重头戏,让我们一起⾛⼀遍代码流程。
2.1 代码⼊⼝


这⾥需要多跑⼏次,把前⾯的 beanName 跳过去,只看 Model1。


2.2 第⼀层

进⼊ doGetBean(),从 getSingleton() 没有找到对象,进⼊创建 Bean 的逻辑。


进⼊ doCreateBean() 后,调⽤ addSingletonFactory()。

往三级缓存 singletonFactories 塞⼊ model1 的⼯⼚对象。



进⼊到 populateBean(),执⾏ postProcessProperties(),这⾥是⼀个策略模式,找到下图的策略对象。

正式进⼊该策略对应的⽅法。

下⾯都是为了获取 model1 的成员对象,然后进⾏注⼊。




进⼊ doResolveDependency(),找到 model1 依赖的对象名 model2

需要获取 model2 的 bean,是 AbstractBeanFactory 的⽅法。

正式获取 model2 的 bean。

到这⾥,第⼀层套娃基本结束,因为 model1 依赖 model2,下⾯我们进⼊第⼆层套娃。
2.3 第⼆层

获取 louzai2 的 bean,从 doGetBean(),到 doResolveDependency(),和第⼀层的逻辑完全⼀样,找到 model2 依赖的对象名 model1。
前⾯的流程全部省略,直接到 doResolveDependency()。

正式获取 model1 的 bean。

到这⾥,第⼆层套娃结束,因为 model2 依赖 model1,所以我们进⼊第三层套娃。
2.4 第三层

获取 model1 的 bean,在第⼀层和第⼆层中,我们每次都会从 getSingleton() 获取对象,但是由于之前没有初始 化 model1 和 model2 的三级缓存,所以获取对象为空。

敲重点!敲重点!!敲重点!!!
到了第三层,由于第三级缓存有 model1 数据,这⾥使⽤三级缓存中的⼯⼚,为 model2 创建⼀个代理对象,塞⼊ ⼆级缓存。

这⾥就拿到了 model1 的代理对象,解决了 model2 的依赖关系,返回到第⼆层。
2.5 返回第⼆层
返回第⼆层后,model2 初始化结束,这⾥就结束了么?⼆级缓存的数据,啥时候会给到⼀级呢?
甭着急,看这⾥,还记得在 doGetBean() 中,我们会通过 createBean() 创建⼀个 model2 的 bean,当 model2 的 bean 创建成功后,我们会执⾏ getSingleton(),它会对 model2 的结果进⾏处理。

我们进⼊ getSingleton(),会看到下⾯这个⽅法。

这⾥就是处理 model2 的 ⼀、⼆级缓存的逻辑,将⼆级缓存清除,放⼊⼀级缓存。

2.6 返回第⼀层
同 2.5,model1 初始化完毕后,会把 model1 的⼆级缓存清除,将对象放⼊⼀级缓存。

到这⾥,所有的流程结束,我们返回 model1 对象。
三. 原理深度解读
3.1 什么要有 3 级缓存 ?
这是⼀道⾮常经典的⾯试题,前⾯已经告诉⼤家详细的执⾏流程,包括源码解读,但是没有告诉⼤家为什么要⽤ 3 级缓存?
这⾥是重点!敲⿊板!!!
我们先说“⼀级缓存”的作⽤,变量命名为 singletonObjects,结构是 Map,它就是⼀个单例池, 将初始化好的对象放到⾥⾯,给其它线程使⽤,如果没有第⼀级缓存,程序不能保证 Spring 的单例属性。
“⼆级缓存”先放放,我们直接看“三级缓存”的作⽤,变量命名为 singletonFactories,结构是 Map>,Map 的 Value 是⼀个对象的代理⼯⼚,所以“三级缓存”的作⽤,其实就是⽤来存放对象的代 理⼯⼚。
那这个对象的代理⼯⼚有什么作⽤呢,我先给出答案,它的主要作⽤是存放半成品的单例 Bean,⽬的是为了“打破 循环”,可能⼤家还是不太懂,这⾥我再稍微解释⼀下。
我们回到⽂章开头的例⼦,创建 A 对象时,会把实例化的 A 对象存⼊“三级缓存”,这个 A 其实是个半成品,因为没 有完成依赖属性 B 的注⼊,所以后⾯当初始化 B 时,B ⼜要去找 A,这时就需要从“三级缓存”中拿到这个半成品的 A(这⾥描述,其实也不完全准确,因为不是直接拿,为了让⼤家好理解,我就先这样描述),打破循环
那我再问⼀个问题,为什么“三级缓存”不直接存半成品的 A,⽽是要存⼀个代理⼯⼚呢 ?答案是因为 AOP。
在解释这个问题前,我们看⼀下这个代理⼯⼚的源码,让⼤家有⼀个更清晰的认识。
直接找到创建 A 对象时,把实例化的 A 对象存⼊“三级缓存”的代码,直接⽤前⾯的两幅截图。


下⾯我们主要看这个对象⼯⼚是如何得到的,进⼊ getEarlyBeanReference() ⽅法。


最后⼀幅图太重要了,我们知道这个对象⼯⼚的作⽤:
- 如果 A 有 AOP,就创建⼀个代理对象;
- 如果 A 没有 AOP,就返回原对象。
那“⼆级缓存”的作⽤就清楚了,就是⽤来存放对象⼯⼚⽣成的对象,这个对象可能是原对象,也可能是个代理对 象。
我再问⼀个问题,为什么要这样设计呢?把⼆级缓存⼲掉不⾏么 ?我们继续往下看。
3.2 能⼲掉第 2 级缓存么 ?
@Service
public class A {@Autowiredprivate B b;@Autowiredprivate C c;public void test1() {}
}@Service
public class B {@Autowiredprivate A a;public void test2() {}
}@Service
public class C {@Autowiredprivate A a;public void test3() {}
}
复制代码根据上⾯的套娃逻辑,A 需要找 B 和 C,但是 B 需要找 A,C 也需要找 A。
假如 A 需要进⾏ AOP,因为代理对象每次都是⽣成不同的对象,如果⼲掉第⼆级缓存,只有第⼀、三级缓存:
- B 找到 A 时,直接通过三级缓存的⼯⼚的代理对象,⽣成对象 A1。
- C 找到 A 时,直接通过三级缓存的⼯⼚的代理对象,⽣成对象 A2。
看到问题没?你通过 A 的⼯⼚的代理对象,⽣成了两个不同的对象 A1 和 A2,所以为了避免这种问题的出现,我们搞个⼆级缓存,把 A1 存下来,下次再获取时,直接从⼆级缓存获取,⽆需再⽣成新的代理对象。
所以“⼆级缓存”的⽬的是为了避免因为 AOP 创建多个对象,其中存储的是半成品的 AOP 的单例 bean。
如果没有 AOP 的话,我们其实只要 1、3 级缓存,就可以满⾜要求。
4. 总结
我们再回顾⼀下 3 级缓存的作⽤:
- ⼀级缓存:为“Spring 的单例属性”⽽⽣,就是个单例池,⽤来存放已经初始化完成的单例 Bean;
- ⼆级缓存:为“解决 AOP”⽽⽣,存放的是半成品的 AOP 的单例 Bean;
- 三级缓存:为“打破循环”⽽⽣,存放的是⽣成半成品单例 Bean 的⼯⼚⽅法。
如果你能理解上⾯我说的三条,恭喜你,你对 Spring 的循环依赖理解得⾮常透彻!
关于循环依赖的知识,其实还有,因为篇幅原因,就不再写了,这篇⽂章的重点,⼀⽅⾯是告诉⼤家循环依赖的 核⼼原理,另⼀⽅⾯是让⼤家⾃⼰去 debug 代码,跑跑流程,挺有意思的。
这⾥说⼀下我看源码的⼼得:
- 需要掌握基本的设计模式;
- 看源码前,最好能找⼀些理论知识先看看;
- 英语能力,学会读英⽂注释,不会的话就百度翻译;
- debug 时,要克制⾃⼰,不要陷⼊⽆⽤的细节,这个最重要。
其中最难的是第 4 步,因为很多同学看 Spring 源码,每看⼀个⽅法,就想多研究研究,这样很容易被绕进去了, 这个要学会克制,有全剧意识,并能分辨哪⾥是核⼼逻辑,⾄于如何分辨,可以在⽹上先找些资料,如果没有的话, 就只能多看代码了。
相关文章:
Spring源码解析-Spring 循环依赖
Spring源码解析简图: Spring 如何解决循环依赖,⽹上的资料很多,但是感觉写得好的极少,特别是源码解读⽅⾯,我就⾃⼰单独出⼀ 篇,这篇⽂章绝对肝! 文章目录: 一. 基础知识 1.1 什么…...
从零开始学架构——架构设计的目的
软件架构的历史背景 软件架构真正流行是从20世纪90年代开始的,由于在Rational和Microsoft内部的相关活动,软件架构的概念开始越来越流行。 卡内基梅隆高校的玛丽肖(Mary Shaw)和戴维加兰 (David Garlan)对软件架构做了许多讨论,他们在 1994 年的一篇文章…...
)
Python 异步: 异步生成器(16)
动动发财的小手,点个赞吧! 生成器是 Python 的基本组成部分。生成器是一个至少有一个“yield”表达式的函数。它们是可以暂停和恢复的函数,就像协程一样。 实际上,Python 协程是 Python 生成器的扩展。Asyncio 允许我们开发异步生…...
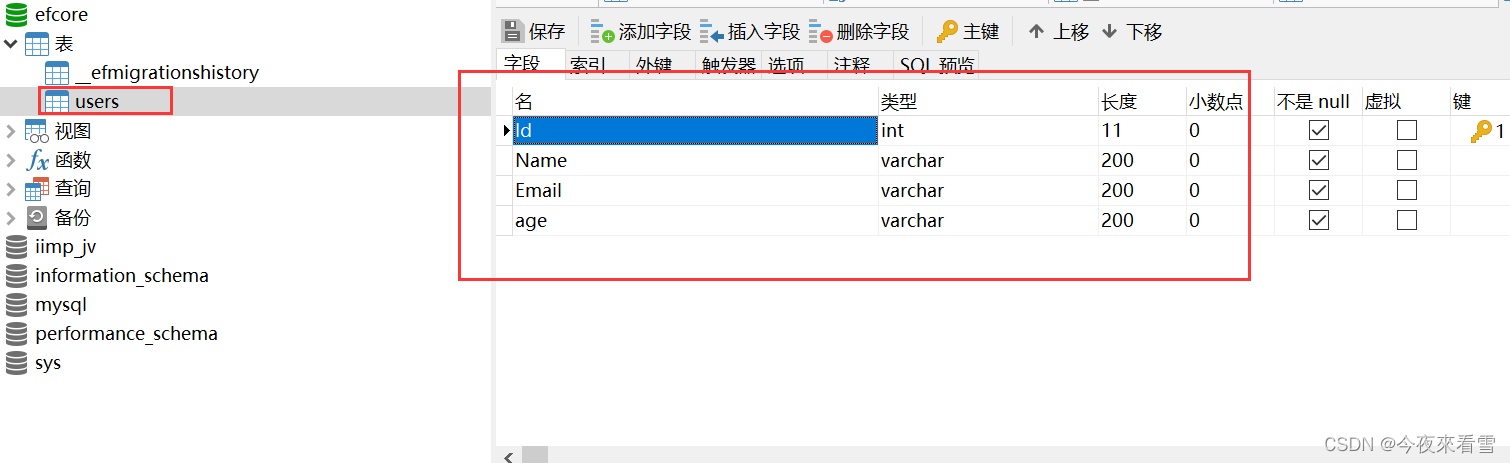
.net6 web api使用EF Core,根据model类自动生成表
1.安装EF Core和mysql数据库的nuget包 Microsoft.EntityFrameworkCore Pomelo.EntityFrameworkCore.MySql 2.创建models文件夹,在文件夹下创建实体类 public class Users{public int Id { get; set; }[Column(TypeName "varchar(200)"), Required]publ…...
计算机科学导论笔记(五)
目录 七、操作系统 7.1 引言 7.1.1 操纵系统 7.1.2 自举过程 7.2 演化 7.3 组成部分 7.3.1 用户界面 7.3.2 内存管理器 7.3.3 进程管理器 7.3.4 设备管理器 7.3.5 文件管理器 7.4 操作系统 7.4.1 UNIX 7.4.2 Linux 7.4.3 Windows 七、操作系统 7.1 引言 计算机…...

通过命令打Java可执行jar包
文章目录1.背景2.操作步骤2.1. 准备好java源文件2.2 确认java源文件中是否有包名2.3 编译java文件2.4 初步打包2.5 解压jar包,得到MANIFEST.MF文件2.6 修改MANIFEST.MF文件2.7 再次打包3.验证4.打包参数参考5.参考文章1.背景 今天,无意中翻出了N年之前年…...
 接口和抽象类)
java基础系列(九) 接口和抽象类
一. 接口 简单的说,接口就是一种被规范的标准,只要符合这个标准都可以通用,接口的表现 在于对行为的抽象. 1.1 创建接口的格式 格式1: public interface 接口名 格式2: interface 接口名 1.2 在JDK1.8之后, 在接口中可以定义实现的方…...

Docker启动问题docker is starting…
环境window 10 家庭最新版直接上官网安装的 Docker DeskTop问题启动应用后setting打开一直转圈圈;主界面一直显示 docker is starting…解决方案3.1 先确定hyper-v是否开启搜hyper-v,点击启动或关闭Windows功能如下,选中Hyper-V服务3.2 进入任务管理期&a…...

Django/Vue实现在线考试系统-03-开发环境搭建-MySQL安装
1.概述 MySQL是一种关系型数据库管理系统,所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型和大型网站的开发都选择 MySQL 作为网站数据库…...
python实现波士顿房价预测
波士顿房价预测 目标 这是一个经典的机器学习回归场景,我们利用Python和numpy来实现神经网络。该数据集统计了房价受到13个特征因素的影响,如图1所示。 对于预测问题,可以根据预测输出的类型是连续的实数值,还是离散值ÿ…...

Pinia不酸,保甜
为什么是Pinia 怎么说呢,其实在过往的大部分项目里面,我并没有引入过状态管理相关的库来维护状态。因为大部分的业务项目相对来说比较独立,哪怕自身功能复杂的时候,可能也仅仅是通过技术栈自身的提供的状态管理能力来处理业务场景…...

uniapp生命周期
uniapp生命周期 uniapp生命周期不同于vue生命周期,uniapp生命周期分为: 应用生命周期 页面生命周期 组件生命周期 应用生命周期(官网) 注意 应用生命周期仅可在App.vue中监听,在其它页面监听无效。 onlaunch里进行页面跳转,如遇白…...
)
经典卷积模型回顾11—Xception实现图像分类(matlab)
Xception是一种深度卷积神经网络,它采用了分离卷积来实现深度神经网络的高准确性和高效率。Xception的名称来自“extreme inception”,意思是更加极致的Inception网络。 在传统的卷积神经网络中,每个卷积层都有若干个滤波器(即卷…...

移动App性能测试包含哪些内容?App性能测试工具有哪些?
随着互联网高科技的蓬勃发展,移动app的的需求量和供给量都较大。但一款好app的成功上线以及为用户带来高效体验,性能测试起着关键性的作用。性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试࿰…...

AI测试的迷思
近年来,我一直关注AI相关的测试,并积极参与多个全国性测试社区和社群。在这些社区中,我与不同公司和领域的测试专家交流探讨AI测试相关话题,包括业界顶尖公司的专家和国内知名测试学者。我也参加了多个大会,聆听了许多…...

[ 红队知识库 ] 一些常用bat文件集合
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...
Qt广告机服务器(上位机)
目录功能结构adSever.promain.cpptcp_MSG.h 共用Tcp传输信息adsever.h 服务器adsever.cpp 服务器addate.h 时间处理addate.cpp 时间处理adtcp.h 客户端Socket处理adtcp.cpp 客户端Socket处理client.h 客户端信息类client.cpp 客户端信息类admsglist.h 信息记录模块admsglist.cp…...

SOA架构的理解
1. SOA概述 SOA(Service-Oriented Architecture,面向服务的架构)是一种在计算机环境中设计、开发、部署和管理离散模型的方法。SOA不是一种新鲜事物,它是在企业内部IT系统重复构建以及效率低下的背景下提出的。在SOA模型中&#x…...
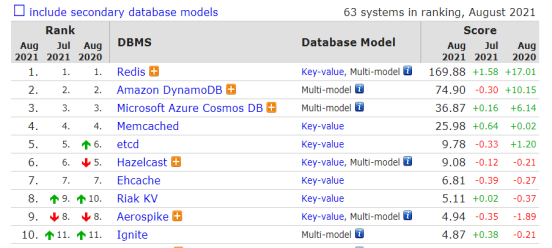
如何选择一款数据库?
1主流数据库技术介绍常见的数据库模型主要分为SQL关系型数据库和NoSQL非关系型数据库。其中关系型数据库分为传统关系数据库和大数据数据库,非关系型数据库分为键值存储数据库、列存储数据库、面向文档数据库、图形数据库、时序数据库、搜索引擎存储数据库及其他&am…...

week2
蓝桥2 递归*树的遍历约数之和分形之城并查集亲戚连通块中点的数量*食物链银河英雄传说哈希笨拙的手指模拟散列表单调队列剪裁序列滑动窗口最大子序和KMP周期递归 *树的遍历 中序遍历: 遍历左子树,根节点,右子树 后序遍历:遍历左子树,右子树,根节点 一个二叉树,树中每个…...

FlowState Lab参数调优实战:如何获得理想的模拟精度与速度
FlowState Lab参数调优实战:如何获得理想的模拟精度与速度 1. 为什么参数调优如此重要 在工程仿真领域,我们常常面临一个经典难题:精度与速度的权衡。FlowState Lab作为一款强大的流体动力学仿真工具,其参数设置直接影响着模拟结…...

YimMenu终极指南:GTA5免费辅助工具完整使用教程
YimMenu终极指南:GTA5免费辅助工具完整使用教程 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu …...

Flux Sea Studio 入门:十分钟完成星图平台镜像部署并生成首张图片
Flux Sea Studio 入门:十分钟完成星图平台镜像部署并生成首张图片 想试试最近很火的AI绘画,但又觉得本地部署太麻烦,显卡要求太高?今天咱们就来聊聊一个超级省事的办法——直接在云端用Flux Sea Studio。你不需要懂代码ÿ…...

AcousticSense AI避坑指南:常见问题解决,确保你的音乐识别流程顺畅运行
AcousticSense AI避坑指南:常见问题解决,确保你的音乐识别流程顺畅运行 关键词:AcousticSense AI、音乐流派识别、问题排查、音频处理、ViT模型、梅尔频谱图、故障解决、部署指南 摘要:部署AcousticSense AI进行音乐流派识别时&…...

彻底清理C盘自带软件方法:2026最新版强力卸载预装软件工具教程
电脑用着用着C盘就满了,开机小助手总提醒“磁盘空间不足”。点进控制面板一看,全是买电脑时自带的那些从未用过的软件,想卸载又怕卸不干净,甚至担心把系统搞崩溃。其实,彻底清理这些自带软件有章可循,关键是…...

如何用Dify工作流引擎解决多平台内容分发效率难题
如何用Dify工作流引擎解决多平台内容分发效率难题 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-Dify-Workflow 当…...

极客玩法:OpenClaw+Qwen3-32B实现命令行AI增强
极客玩法:OpenClawQwen3-32B实现命令行AI增强 1. 为什么需要命令行AI助手? 作为一个常年与终端打交道的开发者,我发现自己每天要重复输入大量命令:查日志、部署服务、处理数据……这些操作往往需要记住复杂的参数组合࿰…...

告别终端命令:Applite如何让macOS应用管理变得轻松有趣
告别终端命令:Applite如何让macOS应用管理变得轻松有趣 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 如果你曾因复杂的终端命令而对Homebrew望而却步,…...

将Windows 10打造成局域网精准时钟源:NTP服务器配置全攻略
1. 为什么需要局域网NTP服务器? 最近在帮朋友调试一个实验室的监控系统时,遇到了一个典型的时间不同步问题。十几台设备记录的视频时间戳相差从几秒到几分钟不等,排查故障时简直像在玩拼图游戏。这种场景在中小型办公网络、实验室环境特别常见…...

免费开源策略卡牌:如何在无名杀中创造你的专属三国战场
免费开源策略卡牌:如何在无名杀中创造你的专属三国战场 【免费下载链接】noname 项目地址: https://gitcode.com/GitHub_Trending/no/noname 在当今数字游戏世界中,有一款独特的开源策略卡牌游戏正悄然改变着玩家与游戏的关系。这款名为"无…...