Elasticsearch入门基础和集群部署
Elasticsearch入门基础和集群部署
- 简介
- 基础概念
- 索引(Index)
- 类型(Type)(逐步弃用)
- 文档(Document)
- 字段(Field)
- 映射(Mapping)
- 分片(Shard)
- 副分片(Replica)
- 集群和节点(Cluster&Node)
- DSL(Domain Specific Language,领域特定语言)
- 请求过程
- 对比关系型数据库
- 部署安装
- 单机部署
- 集群部署
简介
ElasticSearch 是一个开源的 分布式、支持RESTful 搜索和分析引擎,可以用来解决使用数据库进行模糊搜索时存在的性能问题,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。
ElasticSearch 使用 Java 语言开发,基于 Lucene。ES 早期版本需要 JDK,在 7.X 版本后已经集成了 JDK,已无需第三方依赖。
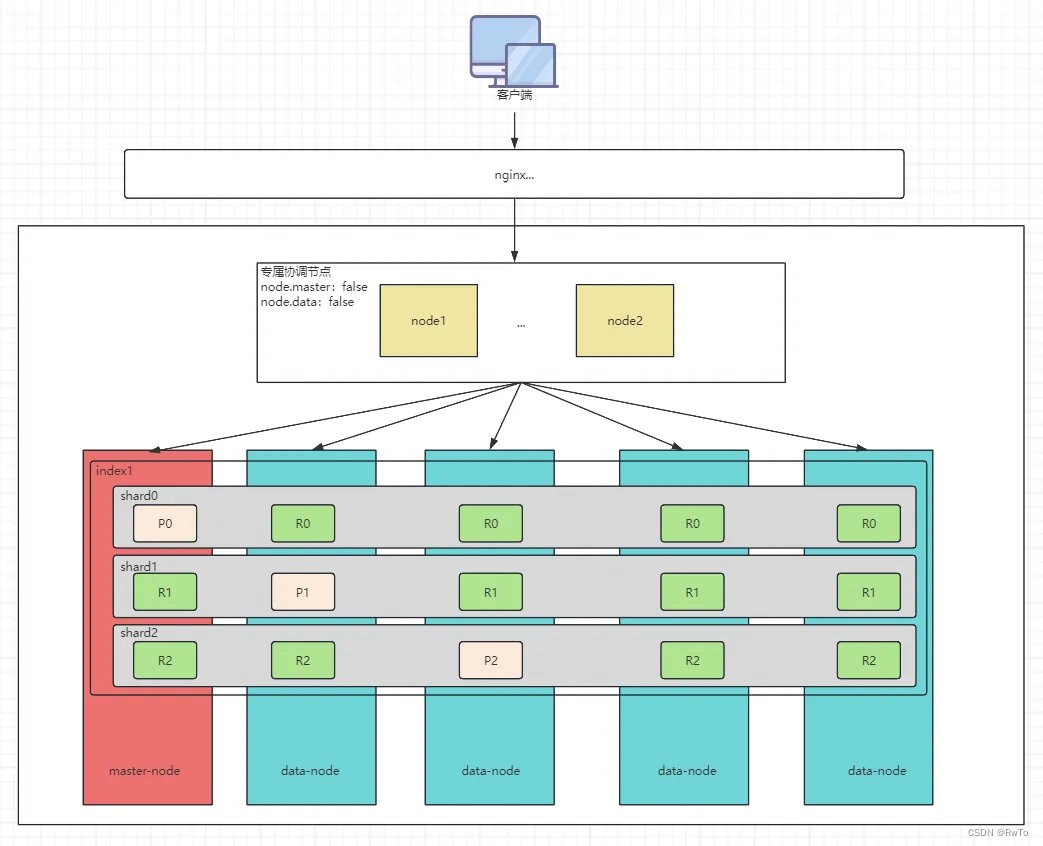
结构图:
基础概念
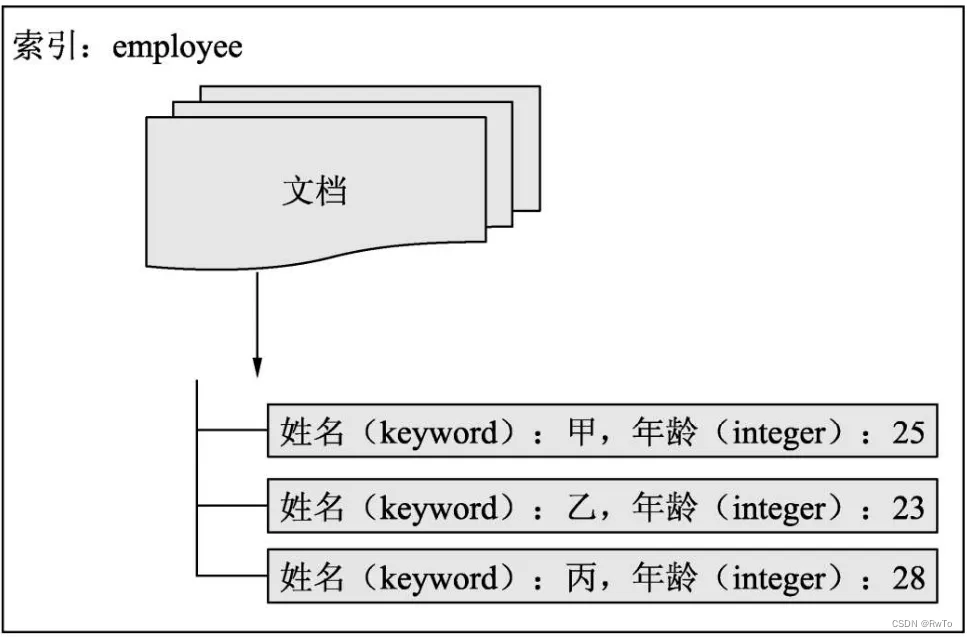
索引(Index)
等价于关系型数据库中的数据库
存储文档信息,是一系列文档的集合。
类型(Type)(逐步弃用)
为了与 关系数据库中的 表 对应
ES设计之初,每个文档都存储在一个索引中,并分配了一个映射类型。
然而,
关系型数据库中的表是独立存储的,不同的表字段相互独立,互不干扰。而ES中同一个Index中的不同Type是存储于同一个索引文件(Lucene索引文件)中的。
因此同一个Index中 不同Type中 相同名字的 字段的映射(Mapping)必须相同。
同时 不同类型的字段存储于同一个索引中,会造成数据稀疏,影响Lucene压缩文档的能力。
所以 ES自6.0 开始,Type被逐步弃用,7.0开始一个索引只能创建一个Type: _doc 。8.0之后,Type被完全删除。
官方解释:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/removal-of-types.html
文档(Document)
相当于关系型数据库中的表记录(行)。
ES的文档可以有一个或多个字段,每个字段可以是各种类型,是用户操作的最小单位。
ES中文档自带版本的概念,初始版本为1,每次写操作都会使版本号+1。
(ES不支持事务,版本号机制用来实现乐观锁,以此来保证数据的一致性)
每次查询文档,ES返回用户最新版本的文档。
字段(Field)
相当于关系型数据库中的 表字段。
一个文档可以包含一个或多个字段,每个字段都有一个类型与之对应。
ES提供了多种数据类型,常用的有:字符串,文本,数值。同时还提高数组,经纬度,IP地址等类型。
对于不同的类型,ES支持不同的搜索功能,例如:对于文本类型ES可以按照某种分词方式对数据进行搜索。并可以设定打分因子来影响最终的排序。
下图为索引,文档,字段之间的关系。
映射(Mapping)
相当于关系型数据库中的表结构。
建立索引时需要定义文档的数据结构,这个结构叫做映射。
在映射中,文档的字段类型一旦设定后就不能更改,因为字段类型定义后,ES已经针对定义的类型建立了特定的索引结构(倒排索引),这种结构不能更改。
ES提供了自动映射功能,即在添加数据时,如果该字段没有定义类型,ES会更加用户提供的字段的真实数据猜测可能的类型,从而自动进行定义。
分片(Shard)
Index 被分为多个碎片存储在不同的Node节点上的分片中,以此来提高性能和吞吐量。
为了实现ES集群,需要将数据切分,并存储到不同的计算机中。
在ES中,一个分片对应一个Lucene索引,每个分片可以设置多个副分片,当主分片发生故障,副分片会充当主分片继续工作。
索引的分片个数只能设置一次,之后不能更改。(因为路由规则的限制,下面有介绍)
默认情况下,ES 6.X 每个索引有5个主分片,1个副分片,ES 7.X 每个索引有 1个主分片 ,1个副分片
副分片(Replica)
每个分片可以设置多个副分片,当主分片发生故障,副分片会充当主分片继续工作。
在一个索引中,副分片是没有限制的,用户可以按需设置。
默认情况下,ES默认副分片数为1。副分片数是可以修改的。
一个分片的主分片和副分片分别存储于不同的节点上。
ES不允许Primary和它的Replica放在同一个节点中,
并且同一个节点不接受完全相同的两个Replica
集群,节点,分片,副分片的关系 见 下图
某个索引设置了三个分片,编号分别为0,1,2。P代表主分片,R代表副分片

集群和节点(Cluster&Node)
一个节点等价于一个ES实例。
ES节点分为三类:
- master 节点:
集群中的一个节点会被选为 master 节点,负责管理集群范畴的变更
例如创建或删除索引,添加节点到集群或从集群删除节点。
master 节点无需参与文档层面的变更和搜索,这意味着仅有一个 master 节点并不会因流量增长而成为瓶颈。
配置node.master 为 true(默认)的节点都可能成为master节点。
- data 节点:
持有数据和倒排索引,操作文档数据,对内存和IO消耗较大。
每个节点都可通过配置文件中的 node.data 属性为 true (默认)成为数据节点。
- 协调 节点:
协调节点负责将请求转发给其他节点,并最终将结果汇总给客户端。
默认情况下,任意节点都可以是协调节点。
它的生命周期是一个单独的ES请求。也就是说,当客户端向集群中某个节点发送请求后,这个节点就是当前请求的协调节点,当请求结束后,协调节点的生命周期也结束。
为了 降低集群的负载,可以设置某些节点为单独的协调节点。
将 node.master 属性和 node.data 属性全部设置为 false,那么该节点就是一个协调节点,扮演一个负载均衡的角色,只负责将到来的请求路由到集群中的各个节点。如下图

多个节点构成一个ES集群,这些节点在同一个网络内,集群名字需要相同。
在分布式系统中,为了完成海量数据的存储和计算,同时提高系统的高可用,需要多台计算机集成在一起协作,这种形式成为集群。目的是解决单台计算机存储和性能的瓶颈。
DSL(Domain Specific Language,领域特定语言)
DSL是在特定领域执行特定任务的语言,例如:HTML,CSS,DSL。
ES中的DSL使用JSON进行表达。简单明了,同时屏蔽了各种编程语言之间数据通信的差异。
请求过程
协调节点内部会维护一份分片-节点路由表,记录着分片和节点的对应关系。
当客户端将请求发送到协调节点后,ES经过路由算法,找到对应的主分片序号,根据分片-节点路由表找到对应的节点,执行相应的任务
- 读请求:使用随机轮询算法,从主/副分片中 选择一个 进行数据读取。(增加副分片可以提高读请求的吞吐量)
- 写请求:主分片处理写请求,同时将请求同步给副分片,所有分片都写成功后,返回请求给客户端。(副分片越多,写入越慢)
路由算法:
shard=hash(routing) % number_of_primary_shards
路由公式参数说明:
shard:最终选择分片序号
routing:路由ID,不指定则为文档ID
number_of_primary_shards:主分片数量
上述公式中,对主分片数量取余,所以主分片数量确定后,就不能修改,否则会导致数据找不到
对比关系型数据库
-
索引方式:
关系型数据库大多使用B+树,ES使用倒排索引。
倒排索引:ES在数据分词后 记录每个词 对应的文档id。

-
事务:
ES不支持事务。ES在更新文档时,先读取文档再进行修改,然后再为文档重建索引。
ES使用乐观锁解决并发问题。每次更新先增加文档版本号,增加成功才进行下一步操作。 -
SQL 和 DSL
DSL 可以支持更复杂的查询 -
扩展
关系型数据库的扩展,需要借助第三方组件进行分库分表。
ES本身就支持分片集群。 -
查询速度和实时性
ES基于倒排索引实现,对于模糊查询明显快于关系型数据库
ES在内存和磁盘之间有一层系统缓存。ES写入数据后,会先存储在内存中,此时数据还不能被搜索到,内存中每隔一段时间(默认1s)刷新到系统缓存,此时才能被搜索到,因此ES的写入是准实时的。
部署安装
官网下载:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-10-2
出于安全性考虑,ES不允许root账户启动,应该创建其他账户启动ES
# 增加组
groupadd es
# 创建用户es 并将用户添加到es组
useradd es -g es
# 设置密码
passwd es
# 切换用户
su es
# 上传es压缩包并解压
tar -zxvf elasticsearch-7.10.2-linux-x86_64.tar.gz
# 如果提示缺少权限的使用chmod 添加相应权限
解压后各目录见下图:

单机部署
ES进程比较吃内存,默认占用内存为1G。如果机器内存较小,可以修改config/jvm.options的配置文件
修改其中的-Xms 和-Xmx参数
vim config/jvm.options
-Xms256m
-Xmx256m
修改完成后,执行bin目录下elasticsearch命令即可启动ES。
# 前台启动
./elasticsearch
# 后台启动
./elasticsearch -d
ES启动完成后,在安装目录下会多一个data目录,用于存放索引数据文件
使用 curl 127.0.0.1:9200验证是否启动完成

自此便完成了ES的单机部署。
集群部署
这里使用一台计算机部署伪集群,实际效果和集群相同。
# 若部署多台计算机实例的,可以省略下面步骤
# 创建集群目录
mkdir -p es-cluster/es0
mkdir -p es-cluster/es1
mkdir -p es-cluster/es2
# 复制配置文件到 集群配置目录下
cp -r elasticsearch-7.10.2/* es-cluster/es0/
cp -r elasticsearch-7.10.2/* es-cluster/es1/
cp -r elasticsearch-7.10.2/* es-cluster/es2/
分别修改各节点配置文件 config/elasticsearch.yml
es0
# 集群名称,同一个集群要求集群名称相同
cluster.name: es-cluster
# 节点名称,同一集群不同实例名称不能相同
node.name: es0
# 指定该节点是否存储索引数据,默认为true。
node.data: true
# 指定该节点是否有资格被选举成为node 默认是true
node.master: true
# 数据存储位置
path.data: /opt/work/es-cluster/es0/data
# 日志存储位置
path.logs: /opt/work/es-cluster/es0/logs
# 锁定物理内存,防止操作系统将内存交换到磁盘上
bootstrap.memory_lock: true
# 网络访问的IP
network.host: 127.0.0.1
# HTTP访问的端口
http.port: 9200
# 集群内部通信的端口
transport.tcp.port: 9300
# 当节点启动时,传递一个初始主机列表来执行发现
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
# 写入候选主节点的设备地址,来开启服务时就可以被选为主节点
cluster.initial_master_nodes: ["es0", "es1", "es2"]
es1
cluster.name: es-cluster
node.name: es1
node.data: true
node.master: true
path.data: /opt/work/es-cluster/es1/data
path.logs: /opt/work/es-cluster/es1/logs
bootstrap.memory_lock: true
network.host: 127.0.0.1
http.port: 9201
transport.tcp.port: 9301
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
cluster.initial_master_nodes: ["es0", "es1", "es2"]
es2
cluster.name: es-cluster
node.name: es2
node.data: true
node.master: true
path.data: /opt/work/es-cluster/es2/data
path.logs: /opt/work/es-cluster/es2/logs
bootstrap.memory_lock: true
network.host: 127.0.0.1
http.port: 9202
transport.tcp.port: 9302
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
cluster.initial_master_nodes: ["es0", "es1", "es2"]
启动集群
# 分别启动三台ES实例
./elasticsearch -d
特别提醒:如果之前使用单机启动过,记得删除已经生成的data/目录
启动成功后,使用 curl http://127.0.0.1:9200/_cat/nodes?v 命令查看节点信息

自此ES集群搭建成功
相关文章:
Elasticsearch入门基础和集群部署
Elasticsearch入门基础和集群部署 简介基础概念索引(Index)类型(Type)(逐步弃用)文档(Document)字段(Field)映射(Mapping)分片&#x…...

12、24年--信息系统治理——IT治理
主要考选择题,2分左右,案例、论文涉及概率不大,需要认证读课本原文。 1、IT治理基础 IT治理是描述组织采用有效的机制对信息技术和数据资源开发利用,平衡信息化发展和数字化转型过程中的风险,确保实现组织的战略目标的过程。 1.1 IT治理的驱动因素 1)存在很多问题: 信…...

Electron学习笔记(三)
文章目录 相关笔记笔记说明 五、界面1、获取 webContents 实例(1)通过窗口对象的 webContent 属性获取 webContent 实例:(2)获取当前激活窗口的 webContents 实例:(3)在渲染进程中获…...

【Redis】Redis键值存储
大家好,我是白晨,一个不是很能熬夜,但是也想日更的人。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!💪💪💪…...
C++系统编程篇——Linux初识(系统安装、权限管理,权限设置)
(1)linux系统的安装 双系统---不推荐虚拟机centos镜像(可以使用)云服务器/轻量级云服务器(强烈推荐) ①云服务器(用xshell连接) ssh root公网IP 然后输入password ①添加用户: addus…...

No Cortex-M SW Device Found
将DIO和CLK管脚调换一下...

提升写作效率的秘密武器:一个资深编辑的AI写作体验
有句话说:“写作是一项你坐在打字机前流血的工作。”而如今,各类生成式软件的涌现似乎打破了写作这一古老的艺术形式壁垒。过去,作家们独自在书桌前冥思苦想,如今,一款名为“玲珑AI工具”的ai写作助手正悄然改变着文案写作行业的创作生态,成为提升写作效率的秘密武器。 在传统…...

Python sort() 和 sorted() 的区别应用实例详解
大家好,今天针对 Python 中 sort() 和 sorted() 之间的区别,来一个实例详细解读。sort — 顾名思义就是排序的意思,它可以接收的对象为可迭代的数据类型。今天以列表为例子演示两者的不同点、相同点,以及其中一些常用的高级参数使…...
七、Redis三种高级数据结构-HyperLogLog
Redis HyperLogLog是用来做基数统计的算法,HyperLogLog在优点是,在输入的元素的数量或者体积非常大时,计算基数占用的空间总是固定的、并且非常小。在Redis里每个HyperLogLog键只需花费12KB内存,就可以计算接近 264 个元素的基数。…...

2024年【金属非金属矿山(露天矿山)安全管理人员】模拟考试题库及金属非金属矿山(露天矿山)安全管理人员作业模拟考试
题库来源:安全生产模拟考试一点通公众号小程序 金属非金属矿山(露天矿山)安全管理人员模拟考试题库参考答案及金属非金属矿山(露天矿山)安全管理人员考试试题解析是安全生产模拟考试一点通题库老师及金属非金属矿山&a…...

网站DDoS攻击应对策略:全面防护与恢复指南
随着互联网的发展,网络安全问题日益凸显,其中DDoS(分布式拒绝服务)攻击成为了网站安全的主要威胁之一。当网站遭受DDoS攻击时,可能会面临服务中断、性能下降、数据泄露等严重后果。因此,了解并掌握DDoS攻击…...
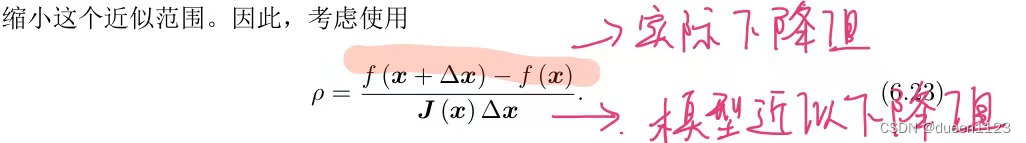
线性/非线性最小二乘 与 牛顿/高斯牛顿/LM 原理及算法
最小二乘分为线性最小二乘和非线性最小二乘 最小二乘目标函数都是min ||f(x)||2 若f(x) ax b,就是线性最小二乘;若f(x) ax2 b / ax2 bx 之类的,就是非线性最小二乘; 1. 求解线性最小二乘 【参考】 2. 求解非线性最小二乘…...

mysqldump: Error 2013 导致mysql停止运行
https://www.cnblogs.com/DataArt/p/10173957.html 1 查询表大小 SELECT table_name AS "表名", round(((data_length index_length) / 1024 / 1024), 2) AS "大小(MB)" FROM information_schema.tables WHERE table_schema your_database_name AND …...

2023年数维杯国际大学生数学建模挑战赛D题洗衣房清洁计算解题全过程论文及程序
2023年数维杯国际大学生数学建模挑战赛 D题 洗衣房清洁计算 原题再现: 洗衣房清洁是人们每天都要做的事情。洗衣粉的去污作用来源于一些表面活性剂。它们可以增加水的渗透性,并利用分子间静电排斥机制去除污垢颗粒。由于表面活性剂分子的存在ÿ…...

python 两种colorbar 最大最小和分类的绘制
1 colorbar 按照自定义的最值绘制 归一化方法使用Normalize(vmin0, vmax40.0) import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt import matplotlib.cm as cm import matplotlib.colors as mcolors from matplotlib import rcParams from matplot…...

Linux-基础IO
🌎Linux基础IO 文章目录: Linux基础IO C语言中IO交互 常用C接口 fopen fputs fwrite fgets 当前路径 三个文件流 系统文件IO open函数 …...
等级考试试卷(二级))
202006青少年软件编程(Python)等级考试试卷(二级)
第 1 题 【单选题】 以下程序的运行结果是?( ) l ["兰溪","金华","武义","永康","磐安","东阳","义乌","浦江"]for s in l:if"义"in s:print(…...

【LeetCode】每日一题:2244.完成所有任务需要的最少轮数
给你一个下标从 0 开始的整数数组 tasks ,其中 tasks[i] 表示任务的难度级别。在每一轮中,你可以完成 2 个或者 3 个 相同难度级别 的任务。 返回完成所有任务需要的 最少 轮数,如果无法完成所有任务,返回 -1 。 英文原题…...

百度文心一言 java 支持流式输出,Springboot+ sse的demo
参考:GitHub - mmciel/wenxin-api-java: 百度文心一言Java库,支持问答和对话,支持流式输出和同步输出。提供SpringBoot调用样例。提供拓展能力。 1、依赖 <dependency> <groupId>com.baidu.aip</groupId> <artifactId…...
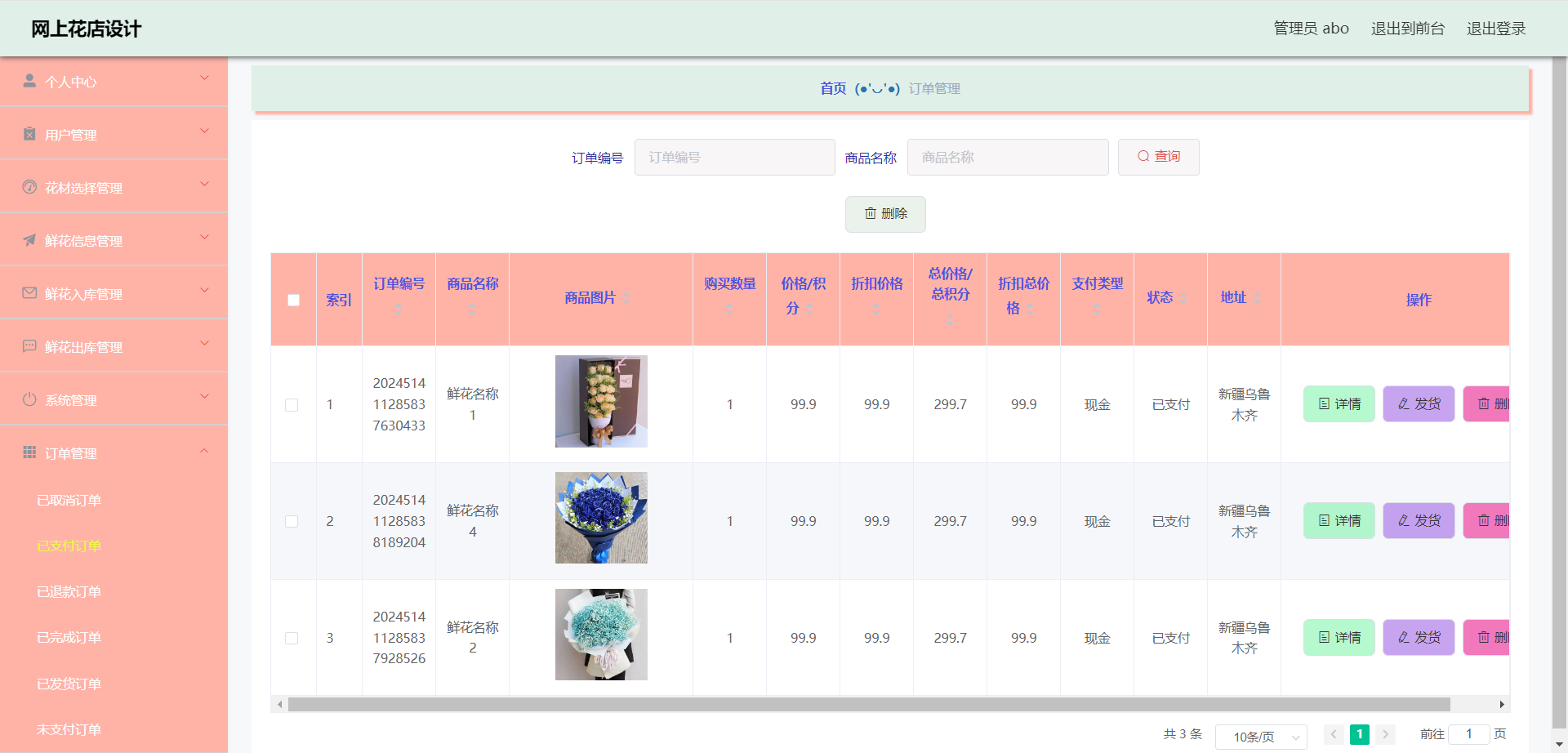
59.基于SSM实现的网上花店系统(项目 + 论文)
项目介绍 本站是一个B/S模式系统,网上花店是在MySQL中建立数据表保存信息,运用SSMVue框架和Java语言编写。并按照软件设计开发流程进行设计实现充分保证系统的稳定性。系统具有界面清晰、操作简单,功能齐全的特点,使得基于SSM的网…...

深入解析ReID核心评价指标:从Rank1到mINP的实战应用
1. ReID评价指标入门:为什么我们需要这么多指标? 第一次接触ReID(行人重识别)的朋友可能会被各种评价指标搞得头晕——Rank1、mAP、ROC、mINP...这些字母组合到底在说什么?其实这些指标就像医生给病人做体检时的不同检…...

精选 Skills 推荐:10 个让 Coding Agent 如虎添翼的Skills + 优质来源分享
精选 Skills 推荐:10 个让 Coding Agent 如虎添翼的Skills 优质来源分享 本篇是 Vibecoding 系列教程 的工具导向专题篇。 前篇:进阶教程(一):MCP Skills 让 coding agent 有自己的工具系列合集:Vibecodi…...

AI合规 I 算法备案、大模型备案和登记的区别,双备案又是什么?
开头附上完整阅读链接:AI合规 I 算法备案、大模型备案和登记的区别,双备案又是什么?https://mp.weixin.qq.com/s/QjjnWhbeDvPGduz31O49dQ 公司马上要上线一个新的AI产品,但是突然发现:"我好像需要做备案…...

Linux系统学习:38张思维导图构建核心知识体系
1. Linux学习思维导图概述作为一名从嵌入式开发转战云计算的老兵,我深知系统化学习Linux的重要性。最近整理硬盘时翻出一套珍藏多年的学习资料——38张涵盖Linux核心知识体系的思维导图,这些图纸曾帮助我顺利通过RHCE认证,也指导过团队新人快…...

芯片缺货潮下的应对策略与国产替代方案
1. 芯片缺货潮下的行业现状最近我的一个产品项目中,原本采购价仅5元的ST品牌MCU(微控制器)价格飙升至70元,涨幅高达14倍。这个案例并非个例,而是当前全球半导体行业供应链危机的缩影。作为从业十余年的硬件工程师&…...
)
Polars 2.0清洗性能天花板在哪?实测对比Dask/Modin/Vaex:单机1TB数据清洗仅需11.3秒(附完整安装脚本)
第一章:Polars 2.0 大规模数据清洗技巧Polars 2.0 引入了更严格的惰性执行模型、增强的字符串与时间处理能力,以及原生支持多线程 I/O 的 LazyFrame API,显著提升了 TB 级数据清洗的吞吐与可控性。相比 Pandas,其列式内存布局与零…...

实战指南:基于快马平台生成git自动化部署脚本,实现ci/cd流水线
今天想和大家分享一个实战中特别实用的技巧:如何用git结合自动化脚本来简化版本发布和部署流程。这个方案在我们团队的实际项目中已经稳定运行了大半年,效果非常不错。 版本号自动打tag功能 这个脚本的核心功能之一就是自动读取项目中的版本号文件&…...

3步实现跨平台日历同步:从需求到落地
3步实现跨平台日历同步:从需求到落地 【免费下载链接】ics iCalendar (ics) file generator for node.js 项目地址: https://gitcode.com/gh_mirrors/ic/ics 场景需求:现代日程管理的痛点与解决方案 在数字化办公环境中,日程管理面临…...

突破限制的完整方案:开源工具免费解锁Cursor Pro功能实战指南
突破限制的完整方案:开源工具免费解锁Cursor Pro功能实战指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached y…...

5分钟掌握:PowerToys Image Resizer让图片批量处理效率提升10倍
5分钟掌握:PowerToys Image Resizer让图片批量处理效率提升10倍 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/GitHub_Trending/po/…...