【自然语言处理】【大模型】DeepSeek-V2论文解析
论文地址:https://arxiv.org/pdf/2405.04434
相关博客
【自然语言处理】【大模型】DeepSeek-V2论文解析
【自然语言处理】【大模型】BitNet:用1-bit Transformer训练LLM
【自然语言处理】BitNet b1.58:1bit LLM时代
【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer
【自然语言处理】【大模型】MPT模型结构源码解析(单机版)
【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版)
【自然语言处理】【大模型】BLOOM模型结构源码解析(单机版)
一、简介
- DeepSeek-V2是一个总参数为236B的MoE模型,每个token仅激活21B的参数,并支持128K的上下文长度。
- 提出了Multi-head Latent Attention(MLA),通过压缩kv cache至隐向量,从而保证高效推理。
- 相比于DeepSeek 67B,DeepSeek-V2实现了更好的表现,节约了42.5%的训练成本,降低了93.3%的kv cache,提升最大吞吐5.76倍。
- 预训练语料包含了8.1T tokens并进一步进行SFT和RL。
二、模型结构
1. MLA(Multi-Head Latent Attention)
传统Transformer采用MHA(Multi-Head Attention),但是kv cache会成为推理瓶颈。MQA(Multi-Query Attention)和GQA(Grouped-Query Attention)可以一定程度减少kv cache,但效果上不如MHA。DeepSeek-V2设计了一种称为MLA(Multi-Head Latent Attention)的注意力机制。MLA通过低秩key-value联合压缩,实现了比MHA更好的效果并且需要的kv cache要小很多。
1.1 标准MHA
令 d d d为embedding维度, n h n_h nh是注意力头的数量, d h d_h dh是每个头的维度, h t ∈ R d \textbf{h}_t\in\mathbb{R}^d ht∈Rd是注意力层中第 t t t个token的输入。标准MHA通过三个矩阵 W Q , W K , W V ∈ R d h n h × d W^Q,W^K,W^V\in\mathbb{R}^{d_h n_h\times d} WQ,WK,WV∈Rdhnh×d来产生 q t , k t , v t ∈ R d h n h \textbf{q}_t,\textbf{k}_t,\textbf{v}_t\in\mathbb{R}^{d_h n_h} qt,kt,vt∈Rdhnh。
q t = W Q h t k t = W K h t v t = W V h t \begin{align} \textbf{q}_t&=W^Q\textbf{h}_t \tag{1}\\ \textbf{k}_t&=W^K\textbf{h}_t \tag{2}\\ \textbf{v}_t&=W^V\textbf{h}_t \tag{3}\\ \end{align} \\ qtktvt=WQht=WKht=WVht(1)(2)(3)
在MHA中 q t , k t , v t \textbf{q}_t,\textbf{k}_t,\textbf{v}_t qt,kt,vt会被划分为 n h n_h nh个头:
[ q t , 1 ; q t , 2 ; … , q t , n h ] = q t [ k t , 1 ; k t , 2 ; … , k t , n h ] = k t [ v t , 1 ; v t , 2 ; … , v t , n h ] = v t o t , i = ∑ j = 1 t Softmax ( q t , i ⊤ k j , i d h ) v j , i u t = W O [ o t , 1 ; o t , 2 ; … , o t , n h ] \begin{align} &[\textbf{q}_{t,1};\textbf{q}_{t,2};\dots,\textbf{q}_{t,n_h}]=\textbf{q}_t \tag{4}\\ &[\textbf{k}_{t,1};\textbf{k}_{t,2};\dots,\textbf{k}_{t,n_h}]=\textbf{k}_t \tag{5}\\ &[\textbf{v}_{t,1};\textbf{v}_{t,2};\dots,\textbf{v}_{t,n_h}]=\textbf{v}_t \tag{6}\\ &\textbf{o}_{t,i}=\sum_{j=1}^t\text{Softmax}(\frac{\textbf{q}_{t,i}^\top\textbf{k}_{j,i}}{\sqrt{d_h}})\textbf{v}_{j,i} \tag{7}\\ &\textbf{u}_t=W^O[\textbf{o}_{t,1};\textbf{o}_{t,2};\dots,\textbf{o}_{t,n_h}] \tag{8}\\ \end{align} \\ [qt,1;qt,2;…,qt,nh]=qt[kt,1;kt,2;…,kt,nh]=kt[vt,1;vt,2;…,vt,nh]=vtot,i=j=1∑tSoftmax(dhqt,i⊤kj,i)vj,iut=WO[ot,1;ot,2;…,ot,nh](4)(5)(6)(7)(8)
其中 q t , i , k t , i , v t , i ∈ R d h \textbf{q}_{t,i},\textbf{k}_{t,i},\textbf{v}_{t,i}\in\mathbb{R}^{d_h} qt,i,kt,i,vt,i∈Rdh是第 i i i个注意力头的query、key和value, W O ∈ R d × d h n h W^O\in\mathbb{R}^{d\times d_h n_h} WO∈Rd×dhnh是输出投影矩阵。在推理时,所有的key和value都会被缓存来加速推理。对于每个token,MHA需要缓存 2 n h d h l 2n_h d_h l 2nhdhl个元素。
1.2 低秩Key-Value联合压缩

MLA通过低秩联合压缩key和value来减少kv cache:
c t K V = W D K V h t k t C = W U K c t K V v t C = W U V c t K V \begin{align} \textbf{c}_t^{KV}&=W^{DKV}\textbf{h}_t \tag{9}\\ \textbf{k}_t^C&=W^{UK}\textbf{c}_t^{KV} \tag{10}\\ \textbf{v}_t^C&=W^{UV}\textbf{c}_t^{KV} \tag{11}\\ \end{align} \\ ctKVktCvtC=WDKVht=WUKctKV=WUVctKV(9)(10)(11)
其中 c t K V ∈ R d c \textbf{c}_t^{KV}\in\mathbb{R}^{d_c} ctKV∈Rdc是用于压缩key和value的隐向量; d c ( ≪ d h n h ) d_c(\ll d_h n_h) dc(≪dhnh)表示KV压缩的维度; W D K V ∈ R d c × d W^{DKV}\in\mathbb{R}^{d_c\times d} WDKV∈Rdc×d是下投影矩阵, W U K , W U V ∈ R d h n h × d c W^{UK},W^{UV}\in\mathbb{R}^{d_h n_h\times d_c} WUK,WUV∈Rdhnh×dc表示上投影矩阵。在推理时,MLA仅需要缓存 c t K V \textbf{c}_t^{KV} ctKV,因此kv cache仅需要缓存 d c l d_c l dcl个元素。此外,在推理时可以把 W U K W^{UK} WUK吸收到 W Q W^Q WQ, W U V W^{UV} WUV吸收到 W O W^O WO中,这样甚至都不需要计算key和value。
关于推理时权重融合的理解:
这里不考虑具体注意力头,仅就单个头进行分析。先来分析 q t ⊤ k j C \textbf{q}_t^\top\textbf{k}_j^C qt⊤kjC,
q t ⊤ k j C = ( W Q h t ) ⊤ W U K c j K V = h t ⊤ W Q ⊤ W U K c j K V = h t ⊤ W Q U K c j K V \begin{align} \textbf{q}_t^\top\textbf{k}_j^C&=(W^Q\textbf{h}_t)^\top W^{UK}\textbf{c}_j^{KV} \\ &=\textbf{h}_t^\top {W^Q}^\top W^{UK} \textbf{c}_j^{KV} \\ &=\textbf{h}_t^\top W^{QUK} \textbf{c}_j^{KV} \\ \end{align} \\ qt⊤kjC=(WQht)⊤WUKcjKV=ht⊤WQ⊤WUKcjKV=ht⊤WQUKcjKV
推理时可以将 W Q ⊤ W U K {W^Q}^\top W^{UK} WQ⊤WUK预先计算出来,记为 W Q U K W^{QUK} WQUK。再来看整个注意力输出值的计算过程
u t = W O o t = W O ∑ j = 1 t Softmax j ( q t ⊤ k j d h ) v j = W O ∑ j = 1 t Softmax j ( q t ⊤ k j d h ) W U V c j K V = W O W U V ∑ j = 1 t Softmax j ( q t ⊤ k j d h ) c j K V = W O U V ∑ j = 1 t Softmax j ( q t ⊤ k j d h ) c j K V \begin{align} \textbf{u}_t&=W^O\textbf{o}_t \\ &=W^O\sum_{j=1}^t\text{Softmax}_j(\frac{\textbf{q}_t^\top\textbf{k}_j}{\sqrt{d_h}})\textbf{v}_j \\ &=W^O\sum_{j=1}^t\text{Softmax}_j(\frac{\textbf{q}_t^\top\textbf{k}_j}{\sqrt{d_h}})W^{UV}\textbf{c}_j^{KV} \\ &=W^OW^{UV}\sum_{j=1}^t\text{Softmax}_j(\frac{\textbf{q}_t^\top\textbf{k}_j}{\sqrt{d_h}})\textbf{c}_j^{KV} \\ &=W^{OUV}\sum_{j=1}^t\text{Softmax}_j(\frac{\textbf{q}_t^\top\textbf{k}_j}{\sqrt{d_h}})\textbf{c}_j^{KV} \\ \end{align} \\ ut=WOot=WOj=1∑tSoftmaxj(dhqt⊤kj)vj=WOj=1∑tSoftmaxj(dhqt⊤kj)WUVcjKV=WOWUVj=1∑tSoftmaxj(dhqt⊤kj)cjKV=WOUVj=1∑tSoftmaxj(dhqt⊤kj)cjKV
W O W U V W^O W^{UV} WOWUV的结果记为 W O U V W^{OUV} WOUV。通过这样的方式就不需要显式计算key和value。
此外,为了在训练时降低激活的显存占用,对query也进行低秩压缩,即使其不能降低kv cache。具体来说,
c t Q = W D Q h t q t C = W U Q c t Q \begin{align} \textbf{c}_t^Q&=W^{DQ}\textbf{h}_t \tag{12}\\ \textbf{q}_t^C&=W^{UQ}\textbf{c}_t^Q \tag{13} \\ \end{align} \\ ctQqtC=WDQht=WUQctQ(12)(13)
其中 c t Q ∈ R d c ′ \textbf{c}_t^Q\in\mathbb{R}^{d_c'} ctQ∈Rdc′是query的压缩后隐向量; d c ′ ( ≪ d h n h ) d_c'(\ll d_h n_h) dc′(≪dhnh)表示query的压缩维度; W D Q ∈ R d c ′ × d , W U Q ∈ R d h n h × d c ′ W^{DQ}\in\mathbb{R}^{d_c'\times d},W^{UQ}\in\mathbb{R}^{d_h n_h\times d_c'} WDQ∈Rdc′×d,WUQ∈Rdhnh×dc′是下投影矩阵和上投影矩阵。
1.3 解耦RoPE
RoPE与低秩KV压缩并不兼容。具体来说,RoPE对于query和key是位置敏感的。若将RoPE应用在 k t C \textbf{k}_t^C ktC上,等式10中的 W U K W^{UK} WUK将与位置敏感RoPE矩阵耦合。但是在推理时, W U K W^{UK} WUK就无法被吸收到 W Q W^Q WQ中,因为对当前生成token相关的RoPE矩阵将位于 W Q W^Q WQ和 W U K W^{UK} WUK之间,而矩阵乘法不满足交换律。因此,推理时必须重新计算前面token的key,这会显著影响推理效率。
关于RoPE与抵秩KV压缩不兼容的理解。
RoPE向 k t C \textbf{k}_t^C ktC注入位置信息的方式为 f ( k t C , t ) = R t k t C f(\textbf{k}_t^C,t)=R_t\textbf{k}_t^C f(ktC,t)=RtktC,其中 R t R_t Rt是一个位置敏感的矩阵。那么有
q t ⊤ f ( k j C , j ) = ( W Q h t ) ⊤ R j W U K c j K V = h t ⊤ W Q ⊤ R j W U K c j K V \begin{align} \textbf{q}_t^\top f(\textbf{k}_j^C,j)&=(W^Q\textbf{h}_t)^\top R_j W^{UK}\textbf{c}_j^{KV} \\ &=\textbf{h}_t^\top {W^Q}^\top R_j W^{UK} \textbf{c}_j^{KV} \\ \end{align} \\ qt⊤f(kjC,j)=(WQht)⊤RjWUKcjKV=ht⊤WQ⊤RjWUKcjKV
由于 R j R_j Rj是未知敏感的,导致 W Q ⊤ R j W U K {W^Q}^\top R_j W^{UK} WQ⊤RjWUK针对不同的token,取值不一样。无法像先前那样直接融合为 W Q U K W^{QUK} WQUK。
为了解决这个问题,提出使用额外的多头query q t , i R ∈ R d h R \textbf{q}_{t,i}^R\in\mathbb{R}^{d_h^R} qt,iR∈RdhR和共享key k t R ∈ R d h R \textbf{k}_t^R\in\mathbb{R}^{d_h^R} ktR∈RdhR来携带RoPE,其中 d h R d_h^R dhR表示解耦query和key的每个头的维度。在MLA中使用解耦RoPE策略的方式为:
q t R = [ q t , 1 R ; q t , 2 R ; … ; q t , n h R ] = RoPE ( W Q R c t Q ) k t R = RoPE ( W K R h t ) q t , i = [ q t , i C ; q t , i R ] k t , i = [ k t , i C ; k t R ] o t , i = ∑ j = 1 t Softmax j ( q t , i ⊤ k j , i d h + d h R ) v j , i C u t = W O [ o t , 1 ; o t , 2 ; … ; o t , n h ] \begin{align} \textbf{q}_t^R&=[\textbf{q}_{t,1}^R;\textbf{q}_{t,2}^R;\dots;\textbf{q}_{t,n_h}^R]=\text{RoPE}(W^{QR}\textbf{c}_t^Q) \tag{14}\\ \textbf{k}_t^R&=\text{RoPE}(W^{KR}\textbf{h}_t) \tag{15}\\ \textbf{q}_{t,i}&=[\textbf{q}_{t,i}^C;\textbf{q}_{t,i}^R] \tag{16}\\ \textbf{k}_{t,i}&=[\textbf{k}_{t,i}^C;\textbf{k}_t^R] \tag{17} \\ \textbf{o}_{t,i}&=\sum_{j=1}^t\text{Softmax}_j(\frac{\textbf{q}_{t,i}^\top\textbf{k}_{j,i}}{\sqrt{d_h+d_h^R}})\textbf{v}_{j,i}^C \tag{18} \\ \textbf{u}_t&=W^O[\textbf{o}_{t,1};\textbf{o}_{t,2};\dots;\textbf{o}_{t,n_h}] \tag{19}\\ \end{align} \\ qtRktRqt,ikt,iot,iut=[qt,1R;qt,2R;…;qt,nhR]=RoPE(WQRctQ)=RoPE(WKRht)=[qt,iC;qt,iR]=[kt,iC;ktR]=j=1∑tSoftmaxj(dh+dhRqt,i⊤kj,i)vj,iC=WO[ot,1;ot,2;…;ot,nh](14)(15)(16)(17)(18)(19)
其中 W Q R ∈ R d h R n h × d c ′ W^{QR}\in\mathbb{R}^{d_h^R n_h\times d_c'} WQR∈RdhRnh×dc′和 W K R ∈ R d h R × d W^{KR}\in\mathbb{R}^{d_h^R\times d} WKR∈RdhR×d是用于产生解耦query和key的矩阵; RoPE ( ⋅ ) \text{RoPE}(\cdot) RoPE(⋅)表示应用RoPE的操作; [ ⋅ ; ⋅ ] [\cdot;\cdot] [⋅;⋅]表示拼接操作。在推理时,解耦的key也需要被缓存。因此,DeekSeek-V2需要的总kv cache包含 ( d c + d h R ) l (d_c+d_h^R)l (dc+dhR)l个元素。
1.4 结论
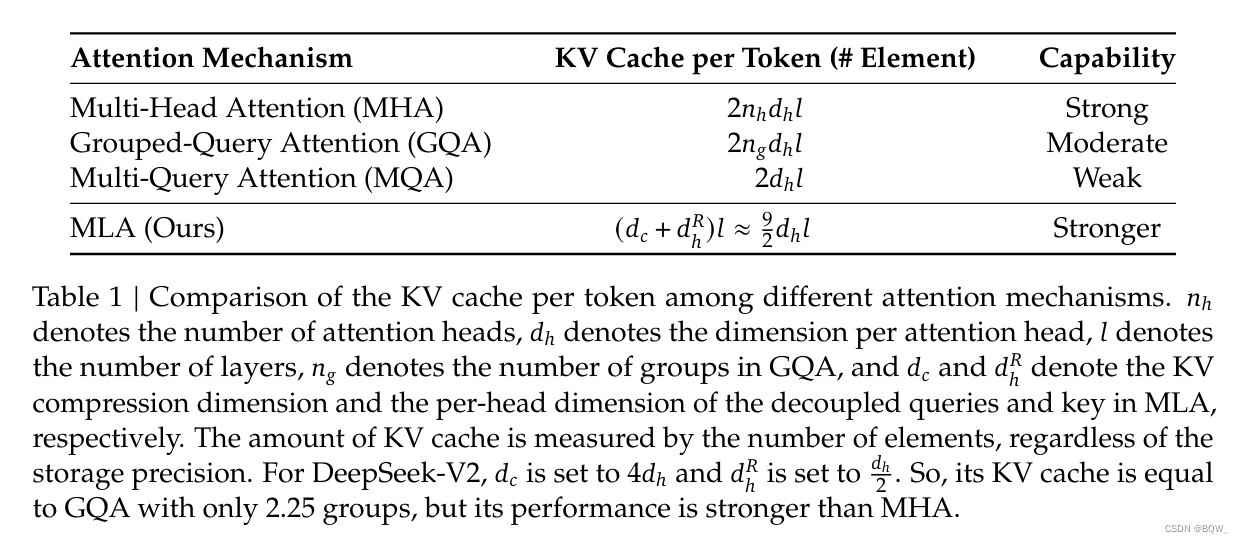
MLA能够通过更少的kv cache实现比MHA更好的效果。
2. 整体结构
2.1 基础结构
对于FFN层,利用DeepSeekMoE架构,即将专家划分为更细粒度,从而获得更专业化的专家以及获取更准确的知识。在具有相同激活和总专家参数的情况下,DeepSeekMoE能够大幅度超越传统MoE架构。
令 u t \textbf{u}_t ut是第t个token对FFN的输入,那么计算FFN的输出 h t ′ \textbf{h}_t' ht′为:
h t ′ = u t + ∑ i = 1 N s FFN i ( s ) ( u t ) + ∑ i = 1 N r g i , t FFN i ( r ) ( u t ) g i , t = { s i , t , s i , t ∈ Topk ( { s j , t ∣ 1 ≤ j ≤ N r } , K r ) 0 , otherwise s i , t = Softmax i ( u t ⊤ e i ) \begin{align} \textbf{h}_t'&=\textbf{u}_t+\sum_{i=1}^{N_s}\text{FFN}_i^{(s)}(\textbf{u}_t)+\sum_{i=1}^{N_r}g_{i,t}\text{FFN}_{i}^{(r)}(\textbf{u}_t) \tag{20}\\ g_{i,t}&=\begin{cases} s_{i,t},& s_{i,t}\in\text{Topk}(\{s_{j,t}|1\leq j\leq N_r\},K_r)\\ 0,&\text{otherwise} \end{cases}\tag{21}\\ s_{i,t}&=\text{Softmax}_i(\textbf{u}_t^\top \textbf{e}_i) \tag{22}\\ \end{align} \\ ht′gi,tsi,t=ut+i=1∑NsFFNi(s)(ut)+i=1∑Nrgi,tFFNi(r)(ut)={si,t,0,si,t∈Topk({sj,t∣1≤j≤Nr},Kr)otherwise=Softmaxi(ut⊤ei)(20)(21)(22)
其中 N s N_s Ns和 N r N_r Nr表示共享专家和路由专家的数量; FFN i ( s ) ( ⋅ ) \text{FFN}_i^{(s)}(\cdot) FFNi(s)(⋅)和 FFN i ( r ) ( ⋅ ) \text{FFN}_i^{(r)}(\cdot) FFNi(r)(⋅)表示第i个共享专家和第i个路由专家; K r K_r Kr表示激活路由专家的数量; g i , t g_{i,t} gi,t是第i个专家的门限值; e i \textbf{e}_i ei是当前层第i个路由专家的中心。
2.2 设备受限路由
设计了一种设备受限路由机制来控制MoE相关的通信成本。当采用专家并行时,路由专家将分布在多个设备上。对于每个token,MoE相关的通信频率与目标专家覆盖的设备数量成正比。由于在DeepSeekMoE中细粒度专家划分,激活专家的数量会很大,因此应用专家并行时,与MoE相关的通信将更加昂贵。
对于DeepSeek-V2,除了路由专家会选择top-K个以外,还会确保每个token的目标专家最多分布在M个设备上。具体来说,对于每个token,先选择包含最高分数专家的M个设备。然后在这M个设备上执行top-K选择。在实践中,当 M ≥ 3 M\geq 3 M≥3时,设备受限路由能够实现与不受限top-K路由大致一致的良好性能。
2.3 用于负载均衡的辅助loss
不平衡的负载会增加路由坍缩的风险,使一些专家无法得到充分的训练和利用。此外,当使用专家并行时,不平衡的负载降低计算效率。在DeepSeek-V2训练时,设计了三种辅助损失函数用于控制专家级别负载均衡 ( L ExpBal ) (\mathcal{L}_{\text{ExpBal}}) (LExpBal)、设备级别负载均衡 ( L DevBal ) (\mathcal{L}_{\text{DevBal}}) (LDevBal)和通信均衡 L CommBal \mathcal{L}_{\text{CommBal}} LCommBal。
专家级均衡loss。专家级均衡loss用于缓解路由坍缩问题:
L ExpBal = α 1 ∑ i = 1 N r f i P i , f i = N r K r T ∑ t = 1 T 1 (Token t selects Expert i) P i = 1 T ∑ t = 1 T s i , t \begin{align} \mathcal{L}_{\text{ExpBal}}&=\alpha_1\sum_{i=1}^{N_r}f_iP_i, \tag{23} \\ f_i&=\frac{N_r}{K_r T}\sum_{t=1}^T\mathbb{1}\text{(Token t selects Expert i)} \tag{24} \\ P_i&=\frac{1}{T}\sum_{t=1}^T s_{i,t} \tag{25} \\ \end{align} \\ LExpBalfiPi=α1i=1∑NrfiPi,=KrTNrt=1∑T1(Token t selects Expert i)=T1t=1∑Tsi,t(23)(24)(25)
其中 α 1 \alpha_1 α1是称为专家级均衡因子的超参数; 1 ( ⋅ ) \mathbb{1}(\cdot) 1(⋅)是指示函数; T T T是序列中token的数量。
设备级均衡loss。除了专家级均衡loss以外,也设计了设备级别均衡loss来确保跨设备均衡计算。在DeepSeek-V2训练过程中,将所有的专家划分至 D D D组 { E 1 , E 2 , … , E D } \{\mathcal{E}_1,\mathcal{E}_2,\dots,\mathcal{E}_D\} {E1,E2,…,ED}并在单个设备上部署每个组。设备级均衡loss计算如下:
L DevBal = α 2 ∑ i = 1 D f i ′ P i ′ f i ′ = 1 E i ∑ j ∈ E i f j P i ′ = ∑ j ∈ E i P j \begin{align} \mathcal{L}_{\text{DevBal}}&=\alpha_2\sum_{i=1}^D f_i' P_i'\tag{26} \\ f_i'&=\frac{1}{\mathcal{E}_i}\sum_{j\in\mathcal{E}_i}f_j \tag{27} \\ P_i'&=\sum_{j\in\mathcal{E}_i}P_j \tag{28} \\ \end{align} \\ LDevBalfi′Pi′=α2i=1∑Dfi′Pi′=Ei1j∈Ei∑fj=j∈Ei∑Pj(26)(27)(28)
其中 α 2 \alpha_2 α2是称为设备级均衡因子的超参数。
通信均衡loss。通信均衡loss能够确保每个设备通信的均衡。虽然设备限制路由机制能够确保每个设备发送信息有上限,但是当某个设备比其他设备接收更多的tokens,那么实际通信效率将会有影响。为了缓解这个问题,设计了一种通信均衡loss如下:
L CommBal = α 3 ∑ t = 1 D f i ′ ′ P i ′ ′ f i ′ ′ = D M T ∑ t = 1 T 1 (Token t is sent to Device i) P i ′ ′ = ∑ j ∈ E i P j \begin{align} \mathcal{L}_{\text{CommBal}}&=\alpha_3\sum_{t=1}^D f_i''P_i''\tag{29} \\ f_i''&=\frac{D}{MT}\sum_{t=1}^T\mathbb{1}\text{(Token t is sent to Device i)}\tag{30} \\ P_i''&=\sum_{j\in\mathcal{E}_i}P_j\tag{31} \\ \end{align} \\ LCommBalfi′′Pi′′=α3t=1∑Dfi′′Pi′′=MTDt=1∑T1(Token t is sent to Device i)=j∈Ei∑Pj(29)(30)(31)
其中 α 3 \alpha_3 α3是称为通信均衡因子的超参数。设备受限路由机制操作主要确保每个设备至多向其他设备传输MT个hidden states。同时,通信均衡loss用来鼓励每个设备从其他设备接受MT个hidden states。通信均衡loss确保设备间信息均衡交换,实现高效通信。
2.4 Token-Dropping策略
虽然均衡loss的目标是确保均衡负载,但是其并不能严格确保负载均衡。为了进一步缓解由于不均衡导致的计算浪费,在训练时引入了设备级别的token-dropping策略。该方法会先计算每个设备的平均计算预算,这意味着每个设备的容量因子等于1.0。然而,在每个设备上drop具有最低affinity分数的token,直到达到计算预算。此外,确保大约10%的训练序列的token永远不会被drop。这样,可以根据效率要求灵活地决定是否在推理过程中drop token,并确保训练和推理的一致性。
三、预训练
1. 实验设置
1.1 数据构造
数据处理过程同DeepSeek 67B,并进一步扩展数据量和质量。采用与DeepSeek 67B相同的tokenizer。预训练语料包含8.1T tokens,中文token比英文多12%。
1.2 超参数
略
1.3 Infrastructures
DeepSeek-V2训练基于HAI-LLM框架。利用16路0气泡流水并行、8路专家并行和ZeRO-1数据并行。考虑到DeepSeek-V2具有相对较少的激活参数,并且对一部分操作进行重计算来节约激活显存,因此可以不使用张量并行,从而降低通信开销。此外,为了进一步提高训练效率,使用专家并行all-to-all通信来重叠共享专家的计算。使用定制化的CUDA核来改善通信、路由算法和不同专家之间融合线性计算。此外,MLA基于改善版本的FlashAttention-2进行优化。
1.4 长上下文扩展
使用YaRN将上下文窗口尺寸从4K扩展至128K。
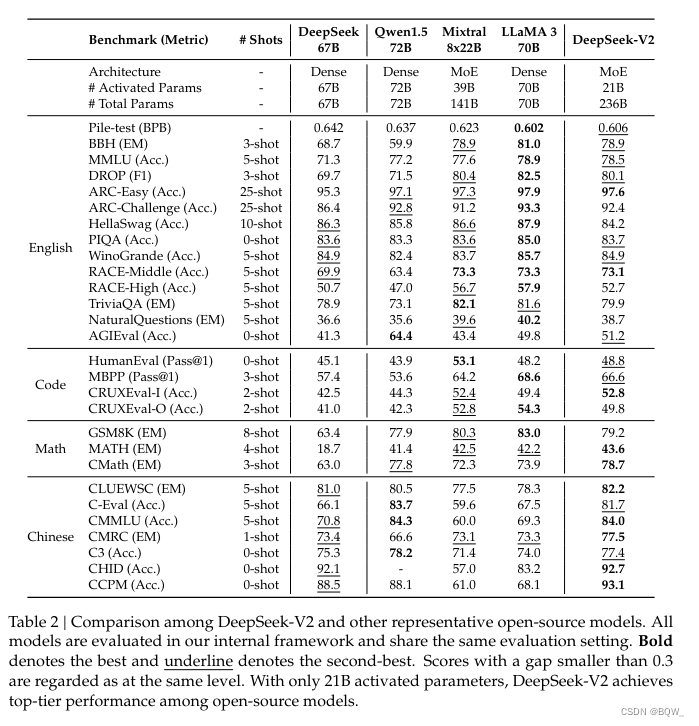
2. 评估
四、对齐
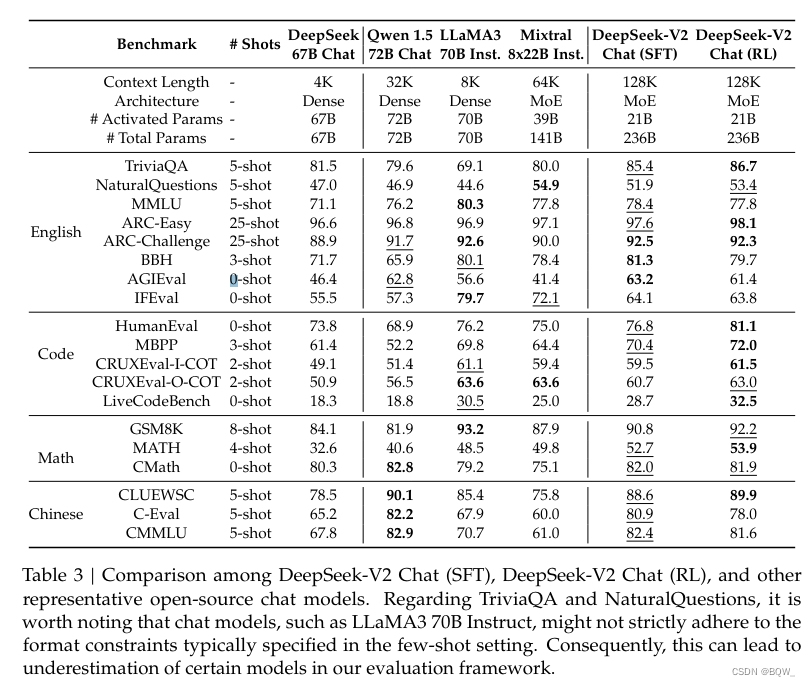
SFT。 使用了150万样本的微调数据,其中120万是用于有用性,30万则用于安全性。
强化学习。仍然采用GRPO。
结果。
相关文章:
【自然语言处理】【大模型】DeepSeek-V2论文解析
论文地址:https://arxiv.org/pdf/2405.04434 相关博客 【自然语言处理】【大模型】DeepSeek-V2论文解析 【自然语言处理】【大模型】BitNet:用1-bit Transformer训练LLM 【自然语言处理】BitNet b1.58:1bit LLM时代 【自然语言处理】【长文本…...

前端面试题日常练-day10 【面试题】
题目 希望这些选择题能够帮助您进行前端面试的准备,答案在文末。 1. 下面哪个CSS属性用于设置元素的字体样式? a) font-size b) font-color c) font-style d) font-weight2. 如何在JavaScript中判断一个变量的类型? a) typeOfb) getTypec)…...

conan2 基础入门(04)-指定编译器(gcc为例)
conan2 基础入门(04)-指定编译器(gcc为例) 文章目录 conan2 基础入门(04)-指定编译器(gcc为例)⭐准备生成profile文件预备文件和Code ⭐使用指令预览正确执行结果可能出现的问题 ⭐具体讲解conancmake ENDsettings.yml ⭐准备 生成profile文件 # 生成默认profile文件…...

谈谈std::map的lower_bound
我们知道std::map内部是一个红黑树,放到std::map里的数据等有一个能比较大小的方法。它相当于java里面的TreeMap。 它里面有个lower_bound方法,返回一个迭代器,它指向map里第一个大于等于参数的元素。 方法的签名很简单,但是在不同…...

不知道代理IP怎么挑?一文带你了解挑选的关键点!
IP代理在如今的网络环境中扮演者至关重要的角色。通过使用代理IP,可以增强用户个人信息和网络的安全。但想要挑选到适合自己的代理IP,并非是一件易事。今天就为大家带来挑选代理IP的关键注意点,帮你轻松筛选出最佳的选择。 稳定性与速度&…...
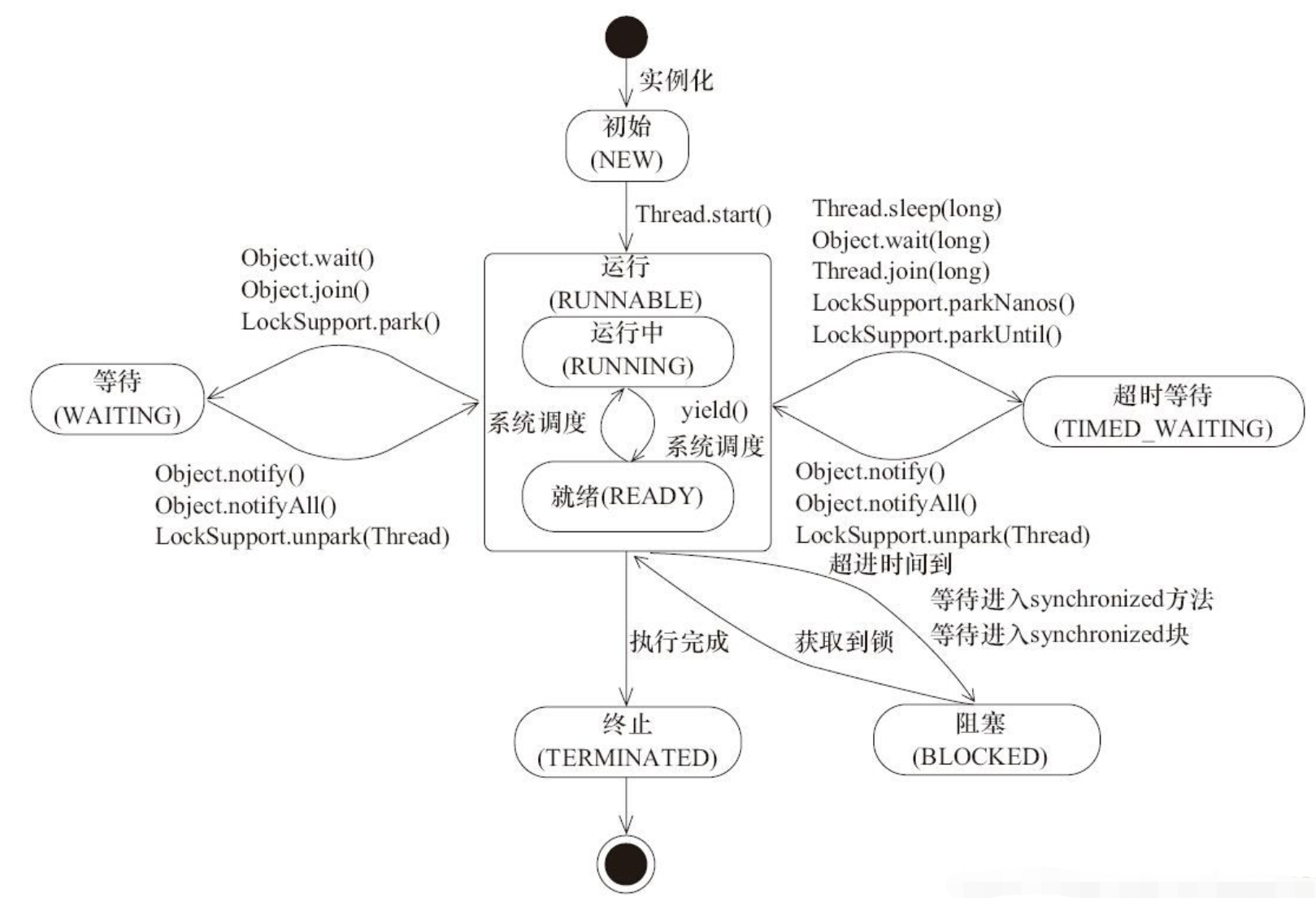
java 并发线程应用
java 并发线程相关 线程状态 新建(NEW): 创建后尚未启动。可运行(RUNABLE): 正在 Java 虚拟机中运行。但是在操作系统层面,它可能处于运行状态,也可能等待资源调度(例如处理器资源),资源调度完成就进入运行状态。所以该状态的可运行是指可以被运行,具体有没有运行要看底层…...

Java面试八股文(SpringCloud篇)
****************************************************...

PWRWER
编译烧录完代码之后,按下复位键屏幕会进行刷新,数据不会丢失 如果按下按键,进行页擦除,之后再按下复位键,发现屏幕不会再进行刷新,原因是程序已经被擦除,损毁,无法运行,此…...

怎样恢复E盘里删了的文件夹,2024让EasyRecovery来帮你轻松恢复
使用EasyRecovery易恢复进行数据恢复非常简单。首先,用户需要选择需要恢复的数据类型,如文档、图片、视频等。然后,软件会对选定的存储设备进行全面扫描,以寻找可恢复的数据。在扫描过程中,用户可以预览部分已找到的文…...
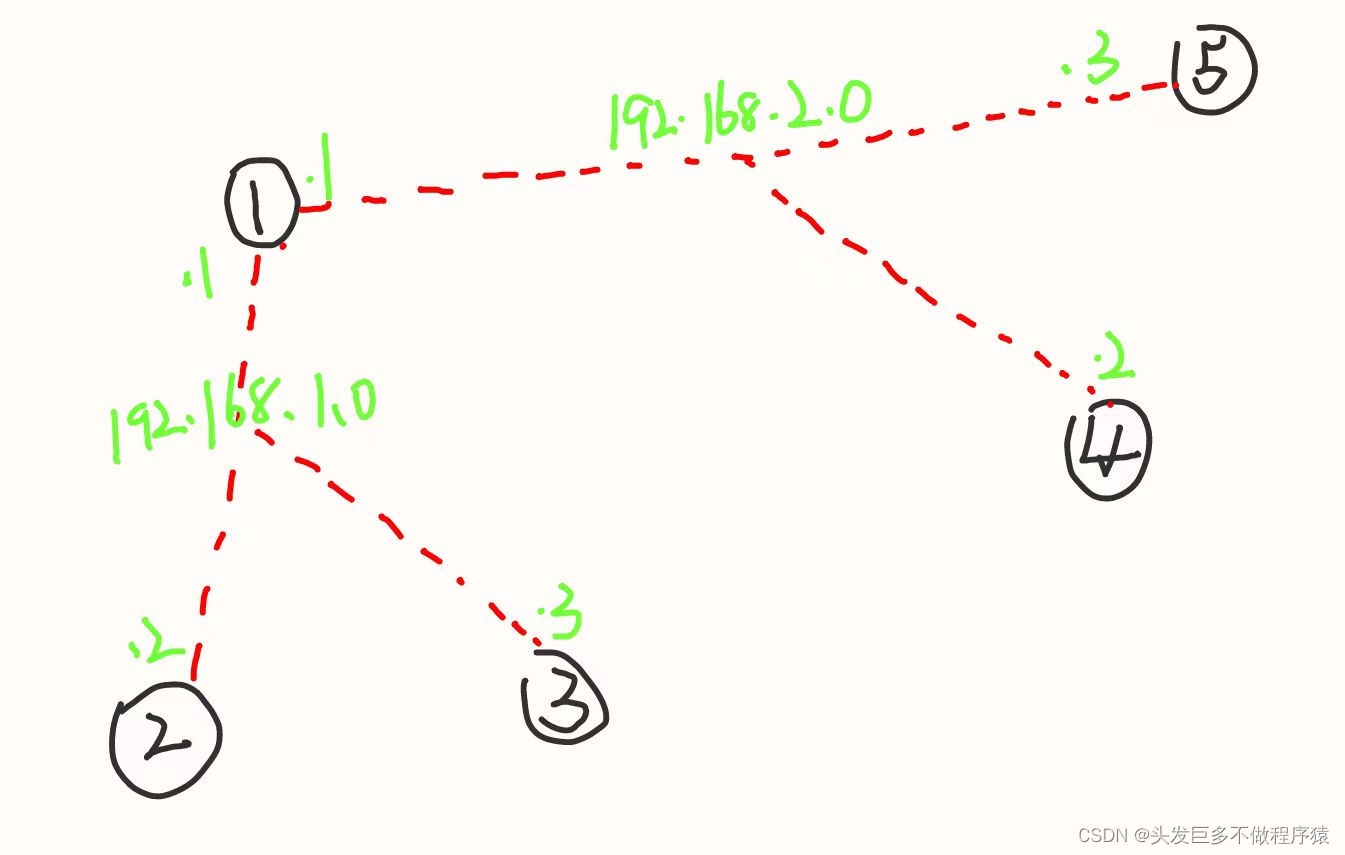
OSPF实验
需求: 1、R6为ISP只能配置IP地址,R1-R5的环回为私有网段。 2、R1/4/5为全连的MGRE结构,R1/2/3为星型的拓扑结构,R1为中心站点。 3、所有私有的网段可以互相通讯,私有网段使用OSPF协议完成。 第一步、搭建拓扑并按如…...

喜茶·茶坊黑金首店入驻北京三里屯,率先引入珍稀娟姗奶制茶
发布 | 大力财经 近日,喜茶茶坊 BLACK 在北京三里屯开业,这是喜茶新业态的首家黑金店型。该店在延续喜茶茶坊“鲜、茶、纯”的精品茗茶特色和宋代茶文化审美意趣的基础上,首次升级呈现了铜锅手煮烹茶工艺、娟姗牛乳制茶等创新尝试࿰…...

C++(week3):数据结构与算法
文章目录 (十一) 常用数据结构1.动态数组(1)模型(2).h与.c(3)实现 2.链表(1)模型(2)分类(3)基本操作(API)(4)实现(5)链表常见面试题(6)空间与时间 3.栈(1)模型(2)基本操作(3)实现(4)栈的应用 4.队列(1)模型(2)基本操作(API)(3)实现(4)队列的应用 5.哈希表(1)哈希表的提出原因(2…...
✅HTTPS和HTTP的区别是什么?
一、问题解析 HTTP和HTTPS是两种协议,分别是Hypertext Transfer Protocol和HyperText Transfer Protocol Secure。 HTTPS还经常被称之为HTTP over SSL或者HTTP over TSL,HTTPS经由HTTP进行通信,但利用SSL/TLS来加密数据包。 他们的区别主要…...

AIGC、LLM 加持下的地图特征笔记内容生产系统架构设计
文章目录 背景构建自动化内容生产平台系统架构设计架构详细设计流程介绍笔记来源笔记抓取干预 笔记 AIGC 赋能笔记 Rule 改写笔记特征库构建 附录Bash Cron 定时任务Golang 与 Pyhon AIGC 实践 小结 背景 在大模型的浪潮下,ChatGPT、Sora、Gemini、文言一心 等新技…...
快速入门go语言学习笔记
文章目录 1、初识go1.1、go语言1.2 第一个Go程序 2、基础类型2.1、命名2.2、变量2.2.1 变量声明2.2.2 变量初始化2.2.3 变量赋值2.2.4 匿名变量 2.3、常量2.3.1 字面常量(常量值)2.3.2 常量定义2.3.3 iota枚举 2.4、基础数据类型2.4.1 分类2.4.2 布尔类型2.4.3 整型2.4.4 浮点型…...

MS41908M替代AN41908
产品简述 MS41908M 是一款用于网络摄像机和监控摄像机的镜头 驱动芯片他可完全替代AN41908。 芯片内置光圈控制功能;通过电压驱动方式以及扭矩纹 波修正技术,实现了噪声微步驱动。 主要特点 电压驱动方式,256 微步驱动电路(两通道…...
---排序(去重/复制到新数组))
Lc33---- 414. 第三大的数(java版)---排序(去重/复制到新数组)
1.题目描述 给你一个非空数组,返回此数组中 第三大的数 。如果不存在,则返回数组中最大的数。 示例 1: 输入:[3, 2, 1] 输出:1 解释:第三大的数是 1 。 示例 2: 输入:[1, 2] 输出…...
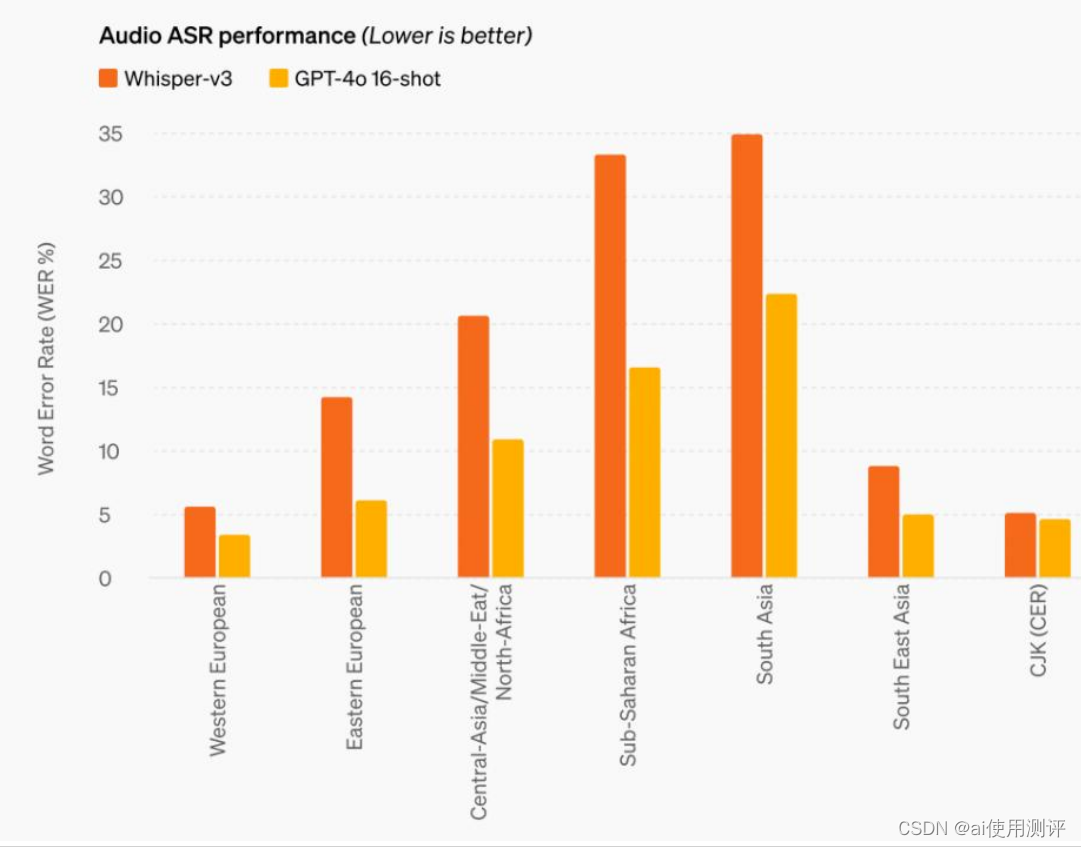
OpenAI新模型GPT-4o“炸裂登场” 响应速度堪比真人 关键还免费!
GPT-4o模型基于来自互联网的大量数据进行训练,更擅长处理文本和音频,并且支持50种语言。更值得一提的是,GPT-4o最快可以在232毫秒的时间内响应音频输入,几乎达到了人类的响应水平。 GPT-4o有多“炸裂”?核心能力有三 G…...

C语言收尾 预处理相关知识
一. 预处理详解 1.1 预定义符号 FILE //进行编译的源文件LINE //文件当前的行号DATE //文件被编译的日期TIME //文件被编译的时间FUNCTION //文件当前所在的函数STDC //如果编译器遵循ANSI C标准,其值为1,否则未定义 这些预定义符号都是语言内置的 我们…...
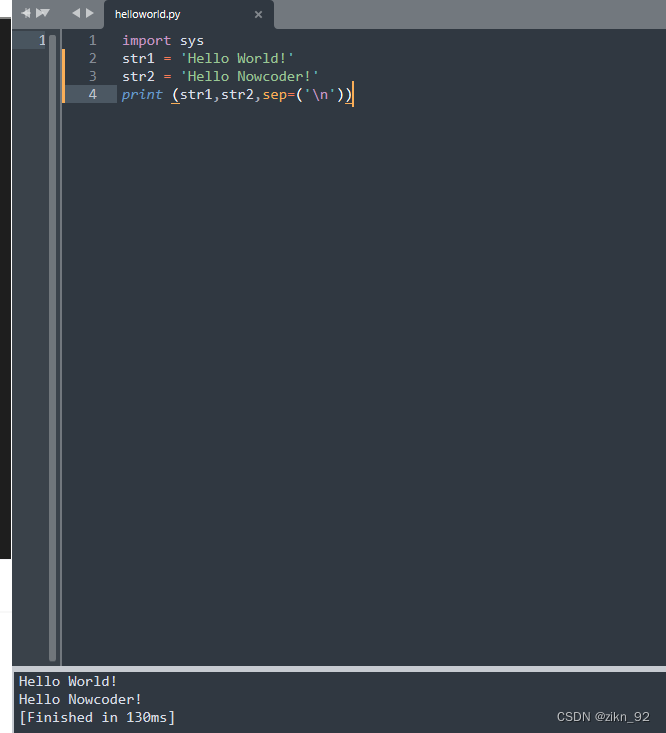
Python代码:二、多行输出
1、题目 将字符串 Hello World! 存储到变量str1中,再将字符串 Hello Nowcoder! 存储到变量str2中,再使用print语句将其打印出来(一行一个变量)。 2、代码 import sys str1 Hello World! str2 Hello Nowcoder! print (str1,st…...

Git忽略文件失效?一招解决!
场景: 在某次 Git 提交时,忘记在 .gitignore 文件中添加上某个原本应该被忽略的文件夹或者文件,于是后一次的提交时在 .gitignore 加上了这些文件,但是在远程的仓库中这些文件夹、文件却并没有消失。这个属于属于什么问题…...

B-CAST: 瓶颈交叉注意力机制如何重塑视频动作识别的时空建模
1. 视频动作识别的核心挑战 视频动作识别一直是计算机视觉领域的重要研究方向。与静态图像识别不同,视频理解需要模型同时具备空间和时间两个维度的分析能力。想象一下,当我们要判断视频中的人是在"放下奶酪"还是"放下番茄酱"时&…...

3步掌握QQ音乐解析:Python工具免费获取全网音乐资源
3步掌握QQ音乐解析:Python工具免费获取全网音乐资源 【免费下载链接】MCQTSS_QQMusic QQ音乐解析 项目地址: https://gitcode.com/gh_mirrors/mc/MCQTSS_QQMusic 你是否曾为音乐平台的各种限制而烦恼?付费会员、下载限制、跨平台不兼容……这些痛…...

告别本地调试:手把手教你将Flink Java应用打包成JAR并提交到YARN集群
从IDE到YARN集群:Flink Java应用全流程部署实战指南 当你在IntelliJ IDEA中完成了Flink流处理程序的调试,看着本地控制台输出的结果一切正常时,接下来的挑战才刚刚开始——如何将这个精心编写的程序部署到真实的分布式环境中运行?…...
)
告别手写代码!用Roboflow的Auto-Orient和Mosaic增强你的YOLO数据集(附完整流程)
零代码实现YOLO数据集增强:Roboflow自动化工具全解析 在目标检测领域,数据质量往往直接决定模型性能上限。传统数据增强方法需要开发者手动编写Python脚本调整图像方向、处理标注格式,不仅耗时耗力,还容易因格式兼容性问题导致训练…...

高效解决Windows 11 LTSC系统Microsoft Store缺失的完整实战指南
高效解决Windows 11 LTSC系统Microsoft Store缺失的完整实战指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows 11 24H2 LTSC版本以其卓越的…...

【亲测免费】 YMODEM发送端程序C代码
YMODEM发送端程序C代码 【下载地址】YMODEM发送端程序C代码 YMODEM发送端程序C代码 项目地址: https://gitcode.com/open-source-toolkit/8ede80 资源文件介绍 文件名 YMODEM.7z 文件描述 本资源文件包含了一个完整的YMODEM发送端程序的C代码,适用于STM3…...

Google关键词能带来多少流量?大词和长尾词的真实流量比例
一家销售软件的公司耗费六个月将“CRM”排至谷歌首页第五名。该词每月产生50万次搜索。网页获得2100次点击。跳出率高达89%。停留时间仅12秒。投入资金4万美元。获得零份询盘。做“外贸企业定制管理软件”排名首页第一。此词汇每月搜索量150次。每月收获62次点击。停留时间4分3…...

立模框架三维扫描检测:构建装配式生产装备的数字化精度基准
在建筑工业化与智能建造协同发展的浪潮中,装配式建筑已成为行业转型升级的主旋律。作为PC构件生产的核心工装,立模框架的几何精度直接决定了预制墙板、叠合梁柱等构件的成型质量,进而影响施工现场的装配效率与结构安全。图片来源网络…...

STC32G单片机开发实战:GPIO模式配置与寄存器详解
1. STC32G单片机GPIO基础认知 第一次拿到STC32G开发板时,我习惯性地想用STM32那套HAL库来操作GPIO,结果发现根本行不通。这就像拿着汽车钥匙去开保险箱,虽然都是"开锁",但机制完全不同。STC32G作为增强型8051架构单片机…...