如何编写BI项目之ETL文档
XXXXBI项目之ETL文档
xxx项目组
------------------------------------------------1----------------------------------------------------------------------
目录
一 、ETL之概述
1、ETL是数据仓库建构/应用中的核心过程
2、ETL的体系结构
3、ETL的设计原则
二、 XXXX数据仓库建构中的ETL:分析与设计
1、面临的问题
2、明确需求:需要哪些数据?
3、分析数据源:从何处获取数据?能获取怎样的数据?
4、基于数据源及数据仓库模型,建立从源到目标的映射模型:如何获取数据?5、元数据库模型的建构
三、xxxx数据仓库建构中的ETL:开发/实现
1、元数据驱动下的ETL基本实现
2、关于与OA及xxx传输工具接口的额外实现
3、元数据的配置、维护与管理
一、ETL 概述
1、ETL是数据仓库建构/应用中的核心过程
数据源具有多样性和可变性数据仓库系统是在业务系统的基础上发展而来的,其内部存储的数据来自于事务处理的 业务系统和外部数据源。因企业的业务系统是在不同时期、不同背景、面对不同应用、 不同开发商等各种客观前提下建立的,其数据结构、存储平台、系统平台均存在很大的 异构性。这导致企业内各源数据缺少统一的标准,因而其数据难以转化为有用的信息, 原始数据的不一致性导致决策时其可信度的降低。 此外,随着企业的不断发展,既有的业务系统、业务流程以及相关的信息结构都可能会 发生变化,这种变化将直接影响到后端数据仓库系统中的数据更新。如何有效的维护这 种变化,尽量控制数据仓库刷新操作的成本,也是数据仓库建构中极为重要的一个问题。
ETL 的核心功能定位
ETL 是建构企业数据仓库(Data Warehousing,即 DW)从而实现商务智能(Business Intelligence,即 BI)的核心和灵魂,它按照统一的规则集成数据并提高数据的价值,是 负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。如果 说数据仓库的模型设计是一座大厦的设计蓝图,数据是砖瓦的话,那么 ETL 就是建设 大厦的过程。在整个项目中最难的部分是用户需求分析和模型设计,而 ETL 规则设计 和实施则是工作量最大的,其工作量要占整个项目的 60%-80%,这是国内外从众多实践 中得到的普遍共识。 针对数据源的多样性和可变性,ETL 通过对从数据源到目标数据仓库间的映射规则进行 元数据级别上的建模,使得整个抽取、转换、装载过程在元数据驱动下能完全自动调度 执行,同时也便于维护和扩展。 同时,因分析的需要,数据仓库中的数据要求是面向主题的,具有集成性、一致性和时 间性,而所有这些都是在详细分析各种数据源,真正理解数据的业务含义基础上通过 ETL 过程来实现的
2、ETL 的体系结构
简单的讲,ETL 就是抽取、转换和装载,同时提供数据质量的管理,并且贯穿整个商务 智能解决方案的全过程,完成整个系统的数据处理、调度、监控及元数据管理等。 其体系结构如下图所示:

· Design manager: 提供一个图形化的映射环境,让开发者定义从源到目标的映射关系、 转换、处理流程。设计过程的各对象的逻辑定义存储在一个元数据资料库中。
· Meta data repository: 提供一个关于 ETL 设计和运行处理等相关定义、管理信息的元 数据资料库。ETL 引擎在运行时和其它应用都可参考此资料库中的元数据。
· Extract: 通过接口提取源数据,例如:ODBC、专用数据库接口和平面文件提取器。参 照元数据来决定提取何处的数据和怎样提取。
· Transform: 开发者将提取的数据按照业务需要转换为目标数据结构,并实现汇总。
· Load: 加载经转换和汇总的数据到目标数据仓库中,可实现 SQL 或批量加载。
· Transport services: 利用网络协议(TCP/IP 等)或文件协议(FTP 等),在源和目标系统之 间移动数据,利用内存(Data Caches 等)在 ETL 处理各组件中移动数据。
· Administration and operation:可让管理员基于事件和时间进行调度、运行、监测 ETL 作业、管理错误信息、从失败中恢复和调节从源系统的输出。
3、ETL 的设计原则
由于企业在自身的发展及信息化建设过程中,业务种类、业务流程以及相伴随的信 息结构将不断变化,这样就会导致多种平台的出现或多个信息系统同时或更替使用,使 得数据分散存储,这样多种数据源(包括数据库管理系统)的现象也会出现,而且随着 企业的继续发展,它们还可能继续变化。因此,如何对企业现有信息架构进行有效描述 以驱动 ETL 的自动调度执行,以及如何维护与管理这种架构描述以应对未来一段时间 内可能发生的变化,就显得至关重要了,而这方面的工作往往是通过设计元数据来完成 的,它也是 ETL 设计过程所要解决的主要问题。
ETL 的设计原则表现在如下几个方面:
元数据的定义:抽象与具体相结合的原则
元数据是关于数据的数据,它立足于一个较高的抽象层次对原始数据及其相关 特性进行描述,以便这些原始数据的使用者只要查看这些元数据就能知道如何使用 或操作这些原始数据。这样,原始数据的使用者就不必绑定于特定的原始数据,而 是分离开来,依靠元数据驱动,从而达到集成各种不同数据源的目的。这也是抽象 带来的好处。但应注意把握抽象的度,根据特定情况在某些方面适当具体化,以便 在实际应用中提高性能,同时尽量避免对原始数据使用者的修改维护。
元数据的格式或描述语言:开放性与可移植性的原则
一般,用 XML 等作为元数据的表现形式,以对其他数据进行描述,从而便于 元数据间的交换,但对 XML 的解析会有额外的性能消耗,因此也可根据具体情况, 选择其他方式来作为元数据的载体。
元数据的变化:可维护性与可扩展性的原则
首先,这里元数据的变化是指元数据内容的变化,它反映着原始数据结构的变 化。这样,由于原始数据的使用者已同原始数据分离,从而通过改变元数据的内容 就避免了对原始数据使用者的改变,使得整个过程可配置,方便维护。
元数据驱动的 ETL 过程:可跟踪性原则
应采用日志文件记录抽取过程所作的操作,便于诊断、跟踪数据抽取过程,保 证抽取数据的准确、抽取过程的优化。
与其他工具或系统的可集成性原则
应留有一定的接口,便于其他工具或系统调用。
二、×××数据仓库建构中的 ETL:分析与设计
1、面临的问题
项目启动之前,经初步了解,×××集团及各分公司的信息系统建设状况所呈现 的问题表现在如下几个方面:
(1)、信息系统建设、使用方面
除八家子公司外,集团所属其他分公司根本还未用上合适的信息系统; 八家子公司尽管都已上了 ERP 系统,但使用程度参差不齐,大都仅使用了部分模 块或子系统;
(2)、基础资料方面
物料编码不统一,物料信息不齐全;
科目编码不一致;
(3)、数据分析需求方面 集团各部门对数据的分析需求各不相同。
基于 BI 项目的特点及×××集团的实际情况,我们确定了如下的 ETL 设计过程, 使得整个项目进展有条不紊、衔接有序。
2、明确需求:需要哪些数据?
由于各业务系统中有许多数据是专为操作型业务服务和使用的,并不为分析所用,也不 一定具有分析的价值,因此并非业务系统中的所有数据都需要作 ETL,而是按需提取, 并使这一过程可配置可扩展,这样也使得整个 ETL 过程在可行性及性能上得到了保证。 按需提取,需从何来?严格来讲,它应该仅仅来自于数据仓库之所需。因此,数据仓库 模型的建构就必须首先执行。为此,我们在实践中总结出了如下针对 BI 项目的富有特 色的需求调研过程:
(1)、初步的需求调研:集团各部门需要看到什么?需要作哪些分析?大致分析到怎样 的细节程度?等等。 这期间也可进行初步的数据源状况的调查分析,以为后一阶段详细深入的数据源分析作 铺垫,但因缺乏明确的目标,不可能深入进行。
(2)、根据初步的展现需求,设计图形化的展现 DEMO,“秀”给各部门负责人/领到看, 征求修改意见及建议,推动需求向纵深发展;
(3)、总结各部门分析、展现之所需,形成原始的需求分析文档;
(4)、基于需求并高于需求,建构数据仓库模型,从而形成数据源分析的主导、ETL 过 程的目标及前端展现的发源地。
在调研过程中,要特别注意把握好关于数据的如下几方面需求:
数据需求:需要哪些种类的数据?哪些种类的数据是基础的,具有原子性,哪 些种类的数据可以通过其他数据计算出来?原子数据的覆盖面要广些,便于针 对可变的需求进行扩展。
分析维度需求:对每一种数据,需要从哪些角度去分析、展现?应用发散性思 维考虑得尽可能多些;
分析粒度需求:对每种数据的每一个分析维度,沿维的层次结构分析到何种级 别、粒度?
经过这样的调研后,我们对需求数据作了总结,归纳为如下几大类型:
(1)、出现在几种财务报表中的财务数据,与特定公司相关,而往往与产品无关,常要 求月度或以上级别的数据,直接按科目从总帐模块取得,比如资产、负债等;
(2)、业务数据,与公司及产品相关,要求明细级数据(每天甚至小时),最好从各业 务模块(如销售、采购等)所用的业务单据中取得,比如销售、采购、生产、库存、产 品成本构成等; (3)、财务指标类数据,与特定公司相关,往往与产品无关,月度或以上级别的数据, 常通过计算得到。
有了需求和目标,数据源分析的深入和细化就成为了可能。
3、分析数据源:从何处获取数据?能获取怎样的数据?
需求能否得到满足,还取决于数据源的状况。在前一阶段对集团各部门及其子公司 进行需求调研所获得的数据需求基础上,对各子公司的数据源进行详细的分析就成为必 要了。为此,我们将每个子公司的最新帐套收集上来,并以需求数据作为参照对象,以 抽取需求数据作为目标,对每个帐套作了如下分析:
(1)、需要怎样的数据?这些数据的分析维度有哪些?沿各维的分析粒度如何?
(2)、各子公司的业务系统如何?数据如何存储(Excel?Access?MS SQL SERVER? Oracle?等等)?
(3)、如果用的是×××公司 ERP 系统,那么版本如何?已上了哪些模块或子系统?
(4)、所需数据能否从数据源获得?是否有可能从数据源的多处获得?更具体的,是从哪些 表的哪些字段获得?是否需要作必要的转换?
(5)、抽取的数据能否满足维度分析的要求?如果不能满足,那么如何弥补?
(6)、抽取的数据能否达到所需要的分析粒度?如果不能满足,该如何弥补?
(7)、抽取数据的装载目标如何?为填充数据仓库事实表,还需要借助数据源中的哪些其他 表的其他数据?
在对每个子公司数据源进行详细分析的基础上,我们发现有如下基本问题需要解决:
(1)、数据的抽取源选择及数据的一致性问题
由于各子公司的×××公司 ERP 系统版本多样,且仅上了部分模块或子系统,这就导致同 样的数据在不同的子公司将可能从不同的地方或多个地方取到;
(2)、科目的标准化及科目的对应问题
因各子公司帐套的科目设置各不相同,而某些财务数据必须通过科目取得,这就需要解决科 目的标准化问题。
(3)、物料信息问题
有的子公司直接将物料信息设置进了科目,需要建立科目-物料的对应关系。
(4)、数据的分析粒度问题
由于某些子公司仅上了总帐等财务模块,而没有上业务模块,这就使得明细级的交易数据无 法被记录到系统中,从而使某些数据的分析粒度达不到要求。
经分析商讨,我们确定了如下关于取数的解决方案:
如果该子公司上了销售、采购、生产、库存或成本等模块,即系统记录下了明细级的交易数 据,那么有关销售、采购、生产、库存或成本等类型的数据一律从相应模块所涉及的表中获 取,即可满足分析维度和分析粒度的要求。否则,如果未上相应模块,那么就按科目从总帐 模块对应的科目余额表及科目数量金额表中取得,此时分析维度将依赖于科目所挂的核算项 目种类,而分析粒度则只能到月。如果仍无法取到,则只能考虑从 WEB 界面接口手工录入 或从相关 Excel 表导入。 各子公司详细的数据获取方案参见表。 有了对源和目标的分析,那么就可以进入关于 ETL 部分最关键也最为重要的一步:映射模 型的建构。
4、基于数据源及数据仓库模型,建立从源到目标的映射模型:如何 获取数据?
在需求分析及数据源分析的基础上,我们已得到了数据源与数据仓库目标间映射模型的轮 廓,但还需进一步细化到各字段以及某些字段间的转换处理等。
由于针对各子公司的数据获取方式有较大的差异,而且对每一种数据,在每个子公司中都存 在多个可能的来源(这是需要同各子公司进行确认的)。因此,如果直接构建映射模型,会 显得较为复杂,而且结构混乱,难以维护和扩展。为使最终构建出的映射模型尽量简化,层 次尽可能清晰,我们采用分而治之的方法,对需求数据按各种方式进行了分类,以便进行合 理的设计。
首先将数据按分析主题分为六类:销售、采购、库存、生产、成本、财务数据。
其中,财务数据又可分为财务报表数据和财务指标数据。
其次,按数据来源或数据获取方式可分为三类:
从各业务模块所包含的相应单据中获取;
从总帐财务模块按科目获取;
从外部手工补录;
与上述两类相应的,数据又可按分析上的时间粒度分为两类:
业务日期粒度级别的数据:来自于业务单据;
财务结算月度级别的数据:来自于财务科目余额表或科目数量金额表;
应该说,对数据的后两种分类是因为当前×××集团各子公司的信息系统建设状况参差不齐 所引起的,将随着集团及各子公司的发展而变化。 最后,出于上述部分数据同预算比较的需要,还有部分预算数据需要手工录入。 为此,基于上述分类及可扩展可维护的原则,我们在设计映射模型的时候也采用了分而治之 的思想,同时为方便前端分析展现的设计,我们也对数据仓库结构作了相应调整。 映射模型的总体描述如下表所示。
5、元数据库模型的建构
有了映射模型,似乎就可考虑 ETL 过程的实现了。其实不然!
如果此时就考虑实现 ETL 过程,那就相当于将相关元数据信息直接蕴涵到了实现过程,这 将不利于后续的维护和扩展。因此有必要基于映射模型及整个 ETL 的运作过程,设计专门 的元数据库,以便在驱动 ETL 过程的同时,统一管理、维护这些元数据。
基于上述对需求数据的各种分类以及×××集团及其各子公司数据源的实际情况,我们设计 的元数据将主要包含如下几类:
(1)、编码对应规则方面的元数据
这包括: 科目对应规则(所有一级科目及二级费用科目;部分其他二级科目对应),处理各子公 司间科目设置的不一致性问题; 科目-物料对应规则(需从财务按科目取数,但物料信息被设置为科目的子公司),处理 物料信息的统一、集成和一致性问题;
(2)、映射规则方面的元数据
这包括: 从客户基础资料表中取客户信息的元数据; 从供应商基础资料表中取供应商信息的元数据; 从财务按科目取财务报表类数据的元数据; 从财务按科目分别取销售、采购、库存、生产、成本类数据的元数据; 从各类业务单据中分别取销售、采购、库存、生产、成本类数据的元数据; 从 OA 系统中的各类表分别取合同采购、预算以及手工录入的上述各主题数据的元数 据; 从外部 Excel 表中取帐龄、现金流量等数据的元数据;
(3)、增量抽取方面的元数据
记录上次抽取的终止位置,以便下次抽取时从该点继续。它可能直接被包含在映射规则 元数据表中。
(4)、元数据的维护管理与工作流调度规则方面的元数据
这包括: 子公司系统配置、数据源信息及其相关映射表信息方面的元数据; ETL 过程工作流调度信息元数据; 基于 ETL 的设计原则以及上述映射模型,我们设计的元数据库模型如文档所示。
三、开发/实现
1、元数据驱动下的 ETL 基本实现
在需求数据及数据源分析的基础上,我们已经完成了元数据库模型的设计,而要真正实现数 据的抽取、转换、装载过程,还需作相应的编程实现,这也正是本节的主题。
(1)、元数据的配置
针对各数据源,按元数据库模型设计的基本要求将数据源信息、映射规则信息、编码对 应规则等等装入到元数据库。
(2)、实现方式选择
鉴于×××集团的实际情况,可选用三种方式来实现元数据驱动 ETL 的编程:
A:通过 DTS,并借助 ActiveX 脚本的编程来实现;
B:完全通过 VB 应用来实现数据的抽取、转换、装载;
C:DTS 与 VB 的结合。
方式 A:基于图形 GUI 界面,方便快速,易于管理维护,但功能及灵活性上可能会受 到影响;
方式 B:功能强大,实现灵活,但开发工作量较大,项目进度会受到影响,并且日后的 维护成本会较大;
方式 C:一般情况下,应是一种较好的选择,但对性能会有一定的影响。 综合考虑上述各种因素及客户方的成员构成,拟采用方式 A 进行开发。
(3)、ETL 基本流程及简述

增量抽取维度数据
这里的维度数据包括:主营业务科目、客户、供应商、仓库、物料、车间部门等维度数据。 其中,主营业务科目维度数据是直接将 ERP 账套的科目表的主营业务科目部分平面化即可。 而其他维度数据则从基础资料表中按不同的基础资料类别取得,其中的 ERP 内码设为增量 标志。相关数据源及目标信息、增量标志值均存放于元数据表中。
将基本事实数据增量装载到分段区表
将年月值作为所有事实数据抽取的增量标志。
这里的基本事实数据类型包括:销售、采购、库存、生产成本、出入库(从而发货、生产入 库、退货、采购入库等)、科目余额(财务类数据)等。
由于不涉及到清洗、转换及与维度表的关联,以及增量标志的运用,因此装载到分段区表的 过程是快速高效并无误的。
对分段区数据进行必要的清洗、转换
借助元数据表中配置的各子公司的特定抽取、转换要求,修改分段区表中的数据,并关联到 相应的维度表。
将清洗、转换后的分段区数据装载到数据仓库
由于不再需作任何修改,装载到数据仓库的过程是快速高效无误的。
构建数据集市
对抽取到数据仓库中的基本事实数据,按分析的(性能、功能方面)要求,汇总到若干数据 集市,这一过程由于有元数据的配置,也是增量进行的。
(4)、DTS 开发及其调用层次结构
根据项目计划,目前需要从集团下属的八个子公司中抽取各种数据到集团的数据仓库中供分 析监控系统采用。
这里就涉及到一个问题:是针对各子公司分别进行 DTS 的开发,还是站在一个整体统一的 高度寻求共性兼顾个性循环处理?前者的特点在于简单,不需要较多的元数据,也不需要考 虑多个子公司的不同情形所带来的复杂性,但可移植性差,重用度不高,且过多的 DTS 也 会带来维护、管理的较大工作量(一个子公司约需要 10 个左右的 DTS,八个子公司就是 80 个左右,而且这个数字还会随着子公司的增加而不断膨胀!)。后者的特点在于基于各子公司 的共性并兼顾个性,由元数据统一驱动循环进行抽取。尽管初期的元数据提炼、分析、设计 较为复杂并费时,但一旦设计好就事半功倍,可移植、可重用、可扩展。
为此,通过对各子公司的整体分析及抽象,并充分考虑到某些子公司业务的特殊性,我们开 发设计了如下 40 个 DTS。




DTS 调用层次结构图如下:


2、关于与 OA 及×××传输工具接口的额外实现
(1)、与×××OA 系统的接口
由于如下两个原因,×××BI 系统需要与×××OA 系统进行数据交流:
A、BI 系统需要的若干子公司的部分数据需从 OA 系统录入;
B、各子公司新增物料的若干物料属性需子公司用户在 OA 端补录或确认;
为此,针对 A,由于我们采用了元数据驱动 ETL 的方式,故只需要作适当额外的配置,就 可解决;针对 B,我们对现有 ETL 的物料维度数据抽取的 DTS 作了一定的扩展,并同 OA 系统共享一张用于交换物料信息数据的表,从而实现整个自动抽取过程。


3、元数据的配置、维护与管理
正如前文所述,随着企业的发展变化,业务流程从而信息流程及信息结构都会发生变化,这 些变化就会导致数据源的变化,因而必须在元数据库中通过元数据来反映这种变化。
(1)、对元数据库模型(即元数据库中的各张表、表结构、字段及其描述)的理解;
- 理解是维护与管理的基础。
- 详细信息可参见元数据模型。
(2)、元数据的配置与维护 一般而言,最关键的元数据信息是关于数据源、数据目标、增量抽取标志值等信息。由于我 们的数据源几乎都是 ERP 账套,因此可大大简化元数据模型,许多信息就不必要配置了。 下面便对相关配置信息作简要说明。










相关文章:
如何编写BI项目之ETL文档
XXXXBI项目之ETL文档 xxx项目组 ------------------------------------------------1---------------------------------------------------------------------- 目录 一 、ETL之概述 1、ETL是数据仓库建构/应用中的核心…...

【LeetCode】剑指 Offer 24. 反转链表 p142 -- Java Version
题目链接:https://leetcode.cn/problems/fan-zhuan-lian-biao-lcof/submissions/ 1. 题目介绍(24. 反转链表) 定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。 【测试用例】: 示…...
LAY-EXCEL导出excel并实现单元格合并
通过lay-excel插件实现Excel导出,并实现单元格合并,样式设置等功能。更详细描述,请去lay-excel插件文档查看,地址:http://excel.wj2015.com/_book/docs/%E5%BF%AB%E9%80%9F%E4%B8%8A%E6%89%8B.html一、安装这里使用Vue…...

配置VM虚拟机Centos7网络
配置VM虚拟机Centos7网络 第一步,进入虚拟机设置选中【网络适配器】选择【NAT模式】 第二步,进入windows【控制面板\网络和 Internet\网络连接】设置网络状态。 我们选择【VMnet8】 点击【属性】查看它的网络配置 2 .我们找到【Internet 协议版本 4(TCP…...
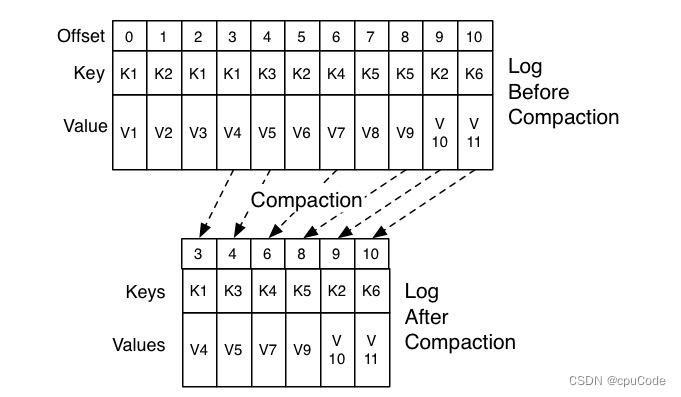
Kafka 位移主题
Kafka 位移主题位移格式创建位移提交位移删除位移Kafka 的内部主题 (Internal Topic) : __consumer_offsets (位移主题,Offsets Topic) 老 Consumer 会将位移消息提交到 ZK 中保存 当 Consumer 重启后,能自动从 ZK 中读取位移数据,继续消费…...
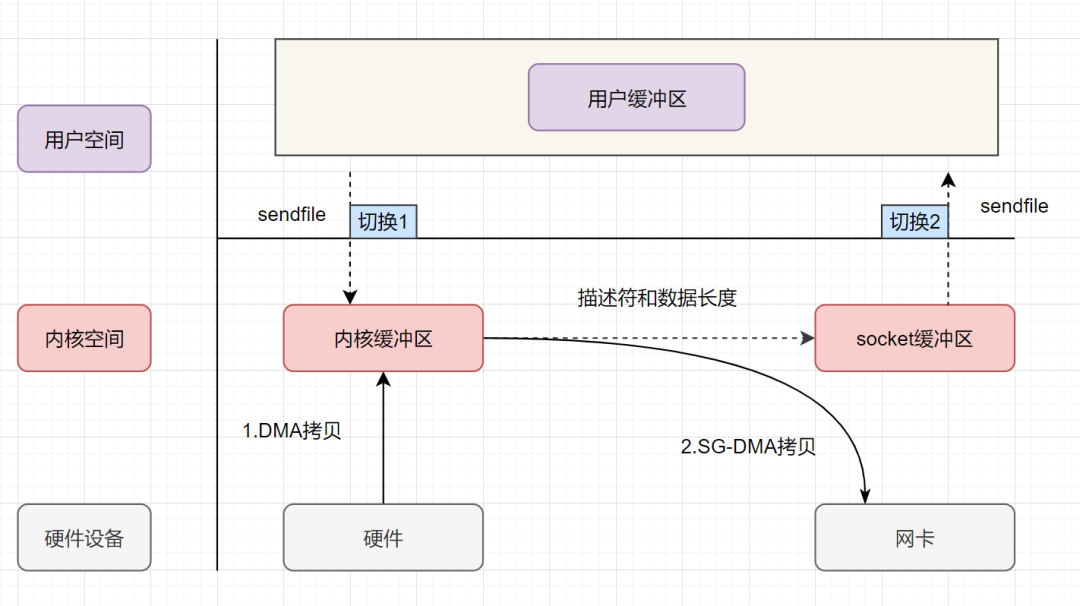
详细讲解零拷贝机制的进化过程
一、传统拷贝方式(一)操作系统经过4次拷贝CPU 负责将数据从磁盘搬运到内核空间的 Page Cache 中;CPU 负责将数据从内核空间的 Page Cache 搬运到用户空间的缓冲区;CPU 负责将数据从用户空间的缓冲区搬运到内核空间的 Socket 缓冲区…...

2023年场外个股期权研究报告
第一章 概况 场外个股期权(Over-the-Counter Equity Option),是指由交易双方根据自己的需求和意愿,通过协商确定行权价格、行权日期等条款的股票期权。与交易所交易的标准化期权不同,场外个股期权的合同内容可以根据交…...

k8s pod,ns,pvc 强制删除
一、强制删除pod$ kubectl delete pod <your-pod-name> -n <name-space> --force --grace-period0解决方法:加参数 --force --grace-period0,grace-period表示过渡存活期,默认30s,在删除POD之前允许POD慢慢终止其上的…...

力扣第99场双周赛题目记录(复盘)
第一题 2578.最小和分割 给你一个正整数 num ,请你将它分割成两个非负整数 num1 和 num2 ,满足: num1 和 num2 直接连起来,得到 num 各数位的一个排列。 换句话说,num1 和 num2 中所有数字出现的次数之和等于 num 中所…...

spring事务失效原因
一.抛出事务不支持的异常 原理: Spring事务默认支持RuntimeException异常,抛出的异常为RuntimeException异常及其子类异常事务均可生效,而我们日常常见的异常基本都继承自RuntimeException,所以无需指定异常类型事务也能生效。 但…...

pikachu靶场CSRF之TOKEN绕过
简介 Pikachu靶场中的CSRF漏洞环节里面有一关CSRF TOKEN,这个关卡和其余关卡稍微有点不一样,因为表单里面存在一个刷新就会变化的token,那么这个token是否能绕过呢?接下来我们来仔细分析分析 实战过程 简单尝试 先利用任意一个…...
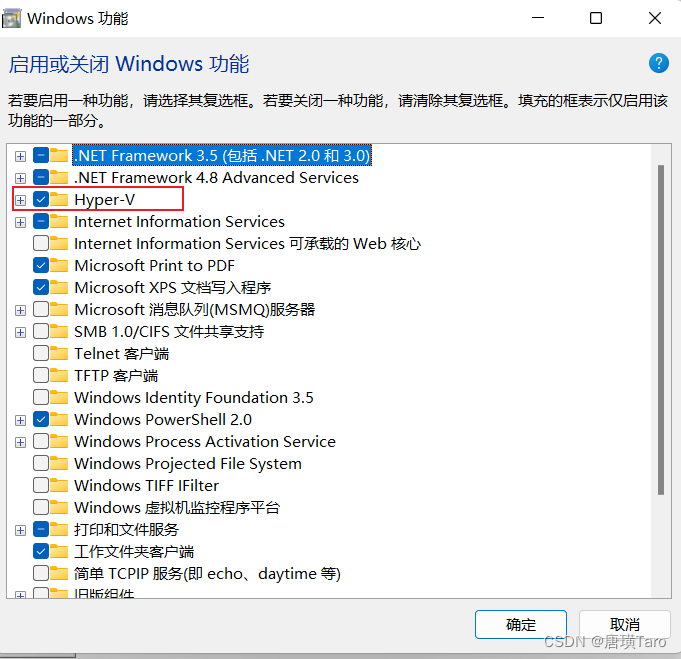
Windows中配置docker没有hyper-v功能解决方案
👨 作者简介:大家好,我是Taro,前端领域创作者 ✒️ 个人主页:唐璜Taro 🚀 支持我:点赞👍📝 评论 ⭐️收藏 文章目录前言解决步骤:1.新建文档2. 另存为3. 功能…...
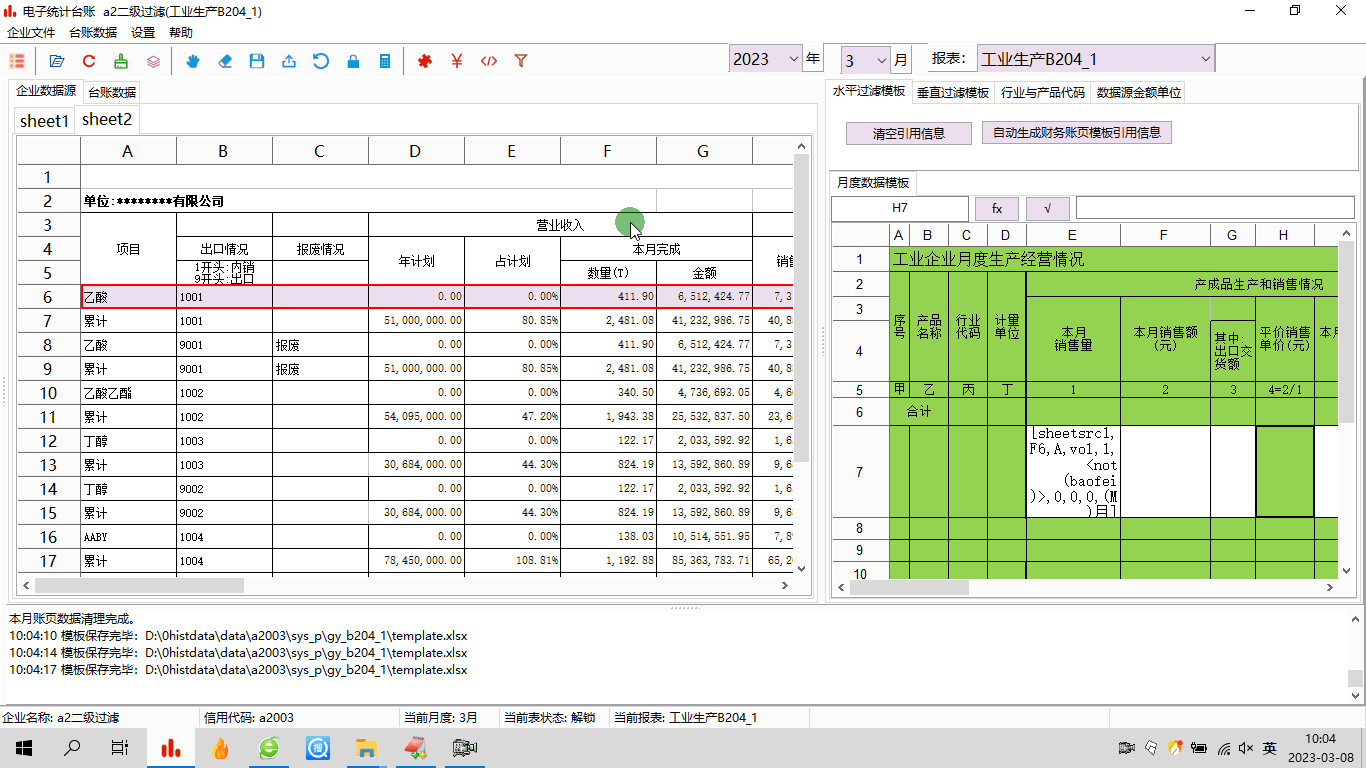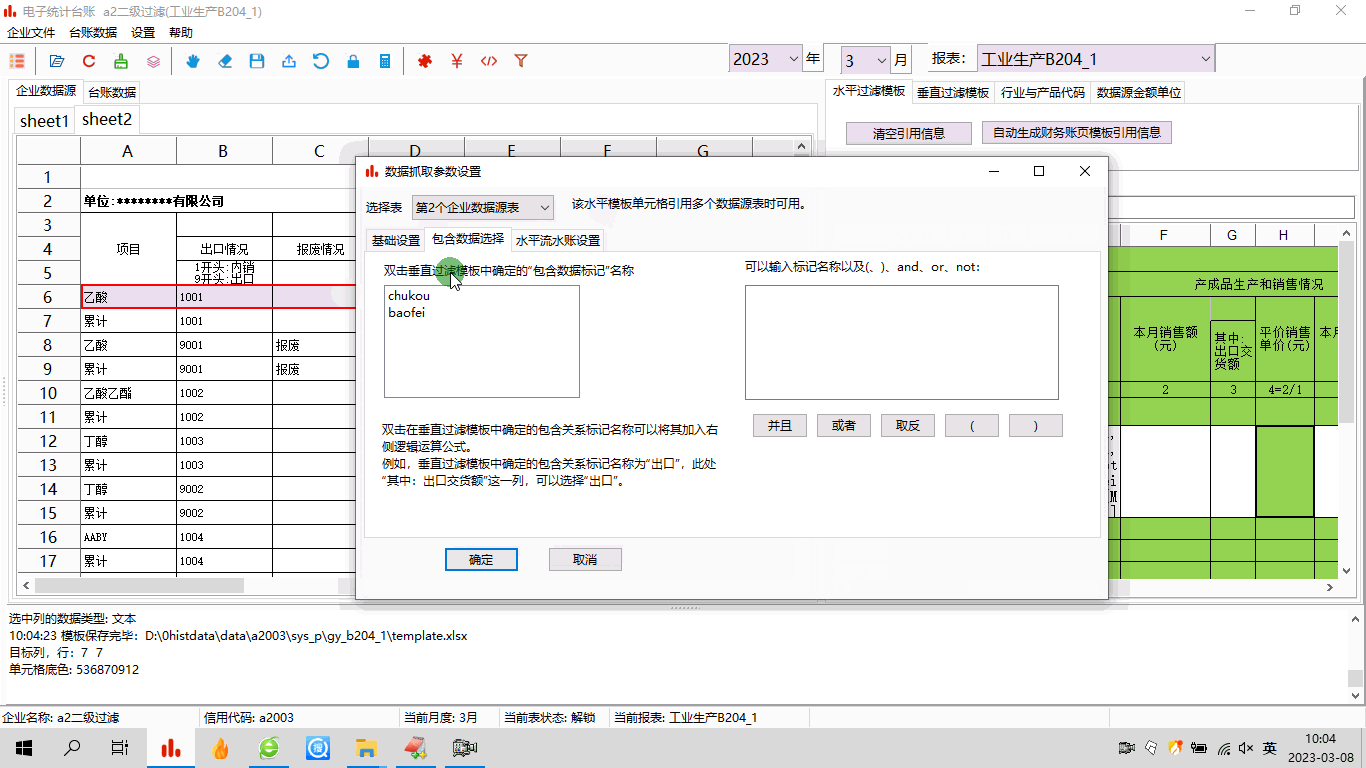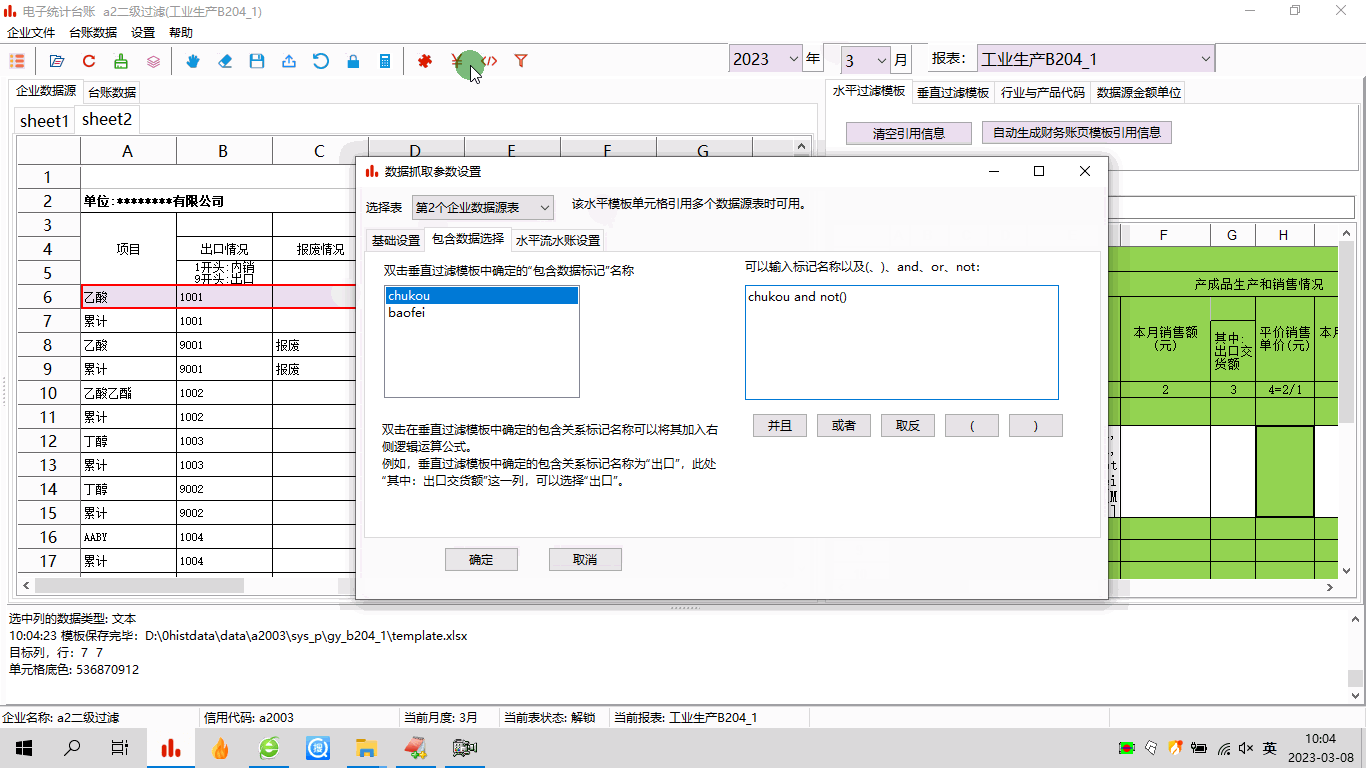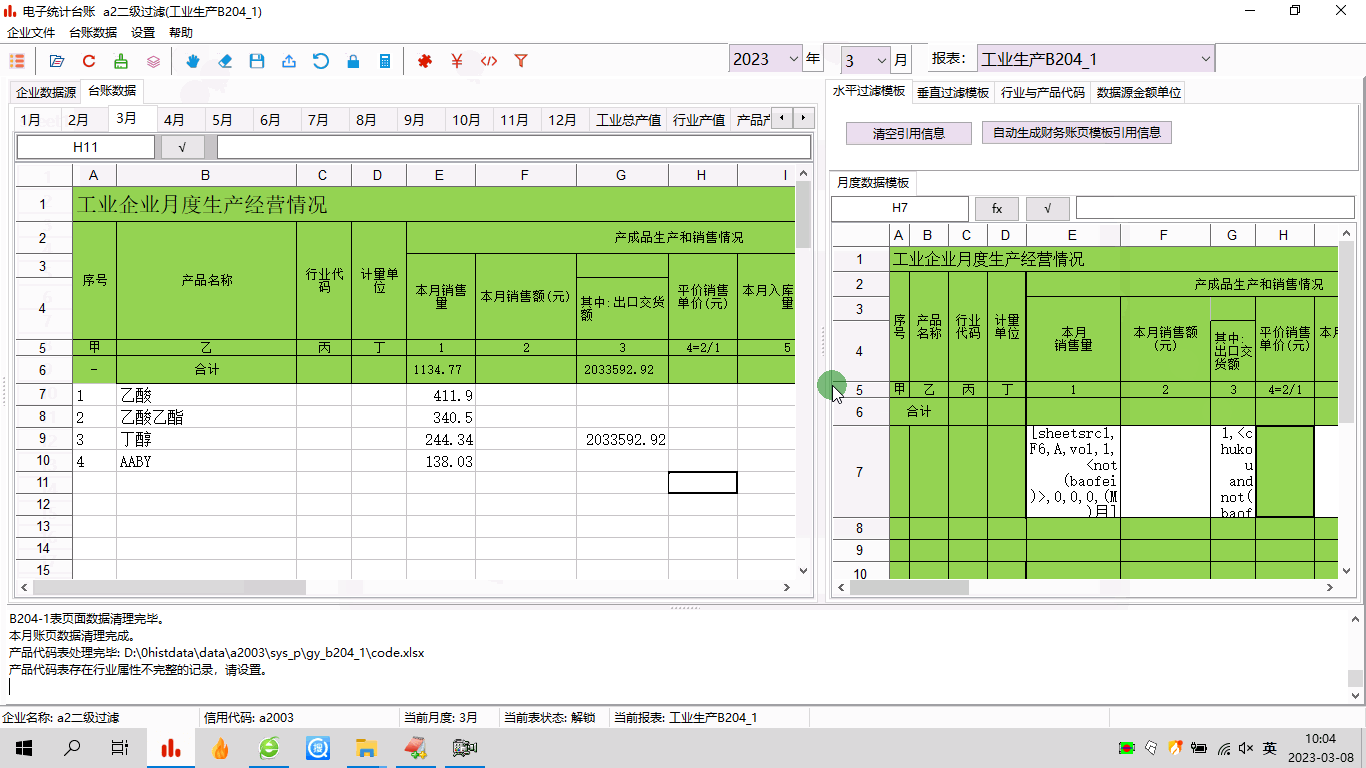
电子台账:模板制作之五——二级过滤与多条件组合
1 前言工作中,经常会遇到很复杂的数据,比如内销产品和出口产品、正常产品和报废产品都混在一块儿。电子台账中,需要把这些数据都区分开,分别汇总。这种情况,可以用台账软件的二级过滤功能来处理,实际上就是…...

Kaldi Data preparation
链接:GitHub - nessessence/Kaldi_ASR_Tutorial: speech recognition using Kaldi framework Lets start with formatting data. We will randomly split wave files into test and train dataset(set the ratio as you want). Create a directory data and,then t…...

libevent 学习笔记
一、参考 libevent Libevent深入浅出 - 《Libevent 深入浅出》 - 书栈网 BookStack libevent 之 event config的相关函数介绍_event_config_new_yldfree的博客-CSDN博客 Libevent之evbuffer详解_有时需要偏执狂的博客-CSDN博客 二、libevent概述 libevent 就是将网络、I…...
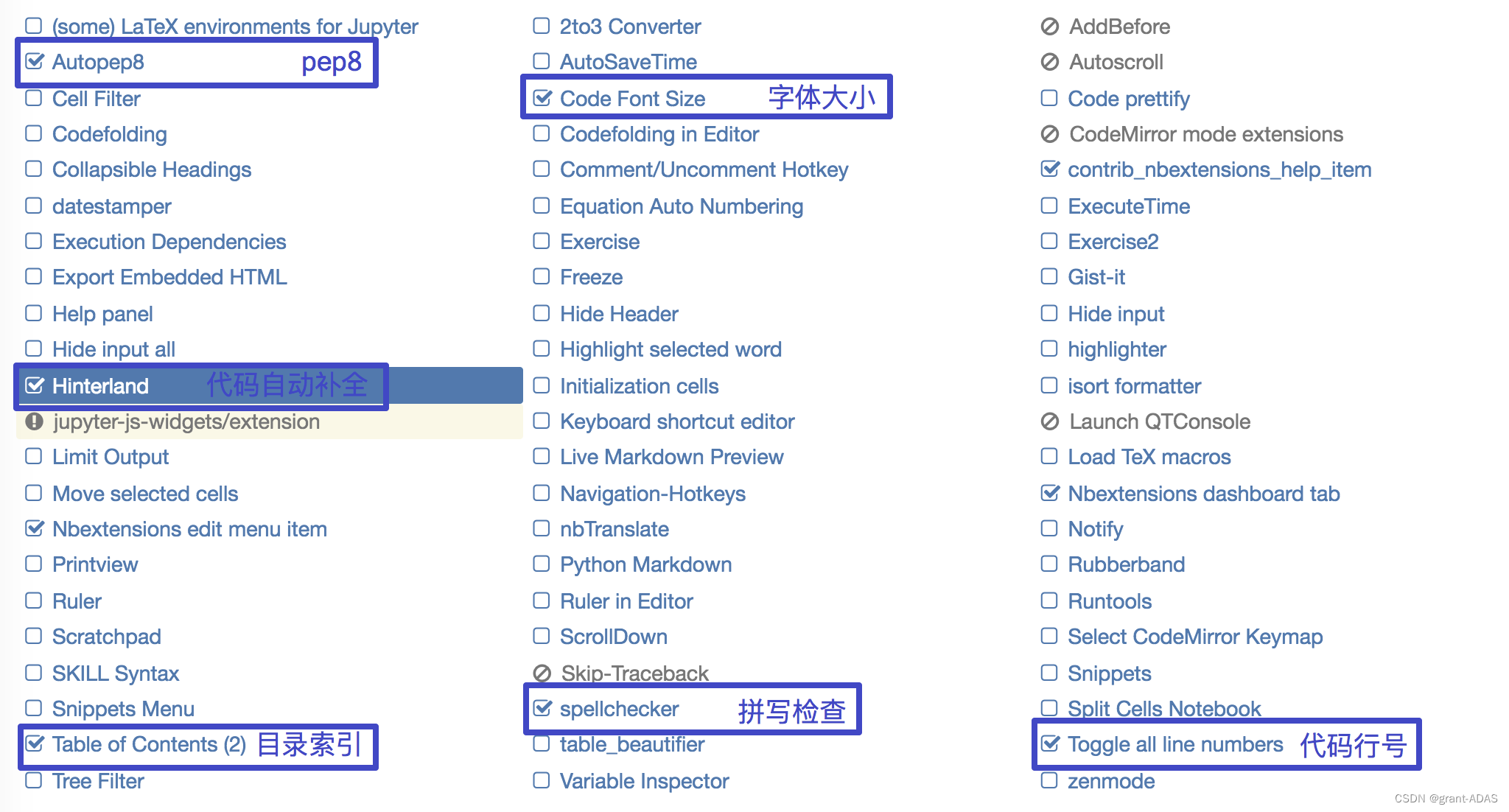
jupyter的使用
1.安装 安装过程看这篇记录。 安装 2.如何启动 环境搭建好后,本机输⼊jupyter notebook命令,会⾃动弹出浏览器窗⼝打开 Jupyter Notebook # 进⼊虚拟环境 workon ai(这个是虚拟环境的名称) # 输⼊命令 jupyter notebook本地notebook的默认URL为&…...

中级数据开发工程师养成计
目标 工作之后就很少时间用来沉淀知识了,难得用空闲时间沉淀一下自己。 成为一名中级数据开发工程师。偏向于数据仓库,数据治理方向。 整体排期 1 hive 2 hadoop 3 flink 4 spark 5 闲杂工具 kafka maxwell cancal 6 数据建模(偏向于kimbo…...
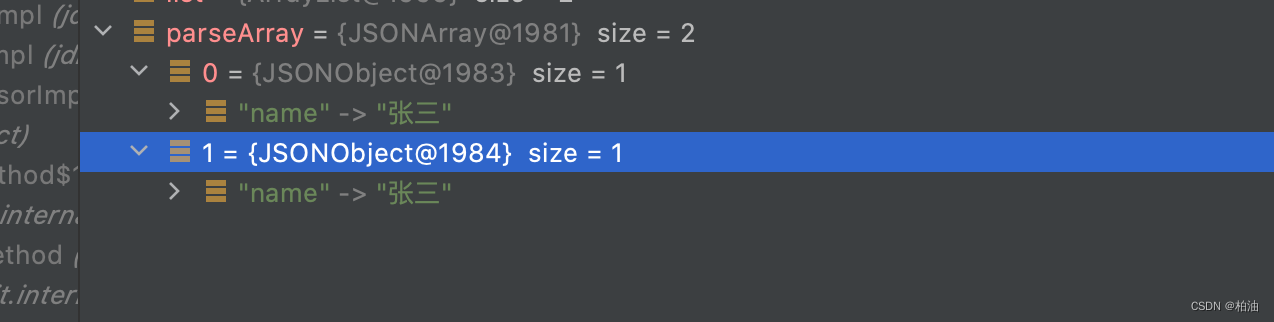
fastjson 返回 $ref 数据
文章目录问题描述:1、重复引用:2、循环引用:原因分析:1、重复引用:2、循环引用:反序列化:1、开启引用检测:2、关闭引用检测:小结:问题描述: 问题…...

Zookeeper特性和节点数据类型详解
什么是ZK? zk,分布式应用协调框架,Apache Hadoop的一个子项目,解决分布式应用中遇到的数据管理问题。 可以理解为存储少量数据基于内存的数据库。两大核心:文件系统存储结构 和 监听通知机制。 文件系统存储结构 文件目录以 / …...

Java代码是如何被CPU狂飙起来的?
无论是刚刚入门Java的新手还是已经工作了的老司机,恐怕都不容易把Java代码如何一步步被CPU执行起来这个问题完全讲清楚。但是对于一个Java程序员来说写了那么久的代码,我们总要搞清楚自己写的Java代码到底是怎么运行起来的。另外在求职面试的时候这个问题…...

保姆级教程:在ROS2 Humble和Gazebo 11中配置FAST_LIO_ROS2进行三维SLAM仿真
从零搭建ROS2与Gazebo环境:FAST_LIO_ROS2三维SLAM实战指南 刚接触机器人仿真的开发者常被环境配置的复杂性劝退——依赖冲突、参数配置错误、话题不匹配等问题层出不穷。本文将手把手带您完成ROS2 Humble、Gazebo 11与FAST_LIO_ROS2的完整集成,实现一个可…...

Qwen3-ForcedAligner在开源项目中的贡献指南
Qwen3-ForcedAligner在开源项目中的贡献指南 1. 引言 如果你对语音识别和音频处理感兴趣,想要为开源项目做贡献,Qwen3-ForcedAligner是个绝佳的选择。这个项目专注于语音文本对齐技术,能够精确标注音频中每个词或字符的时间戳,对…...

QLVideo终极指南:三步让Mac视频预览功能全面升级
QLVideo终极指南:三步让Mac视频预览功能全面升级 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: https://gitcode.com…...

从OV2640升级到OV3660:除了像素提升,ESP32-Cam硬件设计要注意这几点
从OV2640升级到OV3660:硬件设计中的隐形挑战与实战指南 当我们在ESP32-Cam项目中从OV2640升级到OV3660摄像头模组时,很多工程师的第一反应是检查引脚兼容性——这当然没错,但真正的挑战往往藏在那些数据手册不会明确标注的细节里。去年我们团…...

GLM-OCR .NET平台集成指南:C#调用与桌面应用开发
GLM-OCR .NET平台集成指南:C#调用与桌面应用开发 如果你是一名.NET开发者,正在琢磨怎么给你的桌面应用或者Web项目加上一个“眼睛”,让它能看懂图片里的文字,那这篇文章就是为你准备的。OCR(光学字符识别)…...

Boss-Key:重新定义窗口隐私管理的智能办公伴侣
Boss-Key:重新定义窗口隐私管理的智能办公伴侣 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在数字化办公时代,窗…...

基于本机配置的 YOLO26 Conda ss安装教程:Windows 11 + RTX 3050 Ti 实战版
基于本机配置的 YOLO26 Conda 环境安装教程:Windows 11 RTX 3050 Ti 实战版 这篇文章不是泛泛而谈的“通用装环境教程”,而是按你这台电脑当前的实际配置整理出来的一份可直接照做的安装方案。 如果你以前没有配过深度学习环境,只想先把 co…...

效率提升秘籍:用快马平台快速生成魔鬼面具试戴应用代码骨架
效率提升秘籍:用快马平台快速生成魔鬼面具试戴应用代码骨架 最近在做一个有趣的个人项目——魔鬼面具在线试戴应用。作为一个前端开发者,我深知从零开始搭建这种交互式应用需要花费不少时间在基础框架上。幸运的是,我发现了InsCode(快马)平台…...

别再拍脑袋定A/B测试样本量了!用Python/Excel/R三分钟算出靠谱结果
别再拍脑袋定A/B测试样本量了!用Python/Excel/R三分钟算出靠谱结果 每次启动A/B测试前,团队总会陷入同样的争论:"这次实验需要多少流量才够?"产品经理凭经验说"10万用户应该够了",运营同学翻出上次…...

突破性GPU显存释放技术:解决ComfyUI模型占用难题的底层API方案
突破性GPU显存释放技术:解决ComfyUI模型占用难题的底层API方案 【免费下载链接】ComfyUI-Easy-Use In order to make it easier to use the ComfyUI, I have made some optimizations and integrations to some commonly used nodes. 项目地址: https://gitcode.c…...