python数据处理与分析入门-pandas使用(4)
往期文章:
- pandas使用1
- pandas使用2
- pandas使用3
pandas使用技巧
创建一个DF对象
# 首先创建一个时间序列
dates = pd.date_range('20180101', periods=6)
print(dates)# 创建DataFrame对象,指定index和columns标签
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df)
布尔型索引使用
# 用一列的值来选择数据
print(df.A > 0)
print("-----------------------------------------------")
# 使用.isin()函数过滤数据
df2 = df.copy()
df2['E'] = ['one', 'one','two','three','four','three']
# 提取df2中'E'值属于['two', 'four']的行
print(df2[df2['E'].isin(['two','four'])])
# 输出
2018-01-01 True
2018-01-02 True
2018-01-03 False
2018-01-04 False
2018-01-05 False
2018-01-06 True
Freq: D, Name: A, dtype: bool
-----------------------------------------------A B C D E
2018-01-03 -0.737122 -1.018953 1.367684 0.038003 two
2018-01-05 -1.120744 -0.270765 -0.182049 -1.142167 four
# 为DataFrame创建一个新的列,其值为时间顺序(与df相同)的索引值
s1 = pd.Series([1,2,3,4,5,6], index=pd.date_range('20180101', periods=6))
print(s1)df['F'] = s1# 按标签赋值
df.at[dates[0],'A'] = 0# 按索引赋值
df.iat[0,1] = 0# 用Numpy数组赋值
df.loc[:,'D'] = np.array([5] * len(df))
print("-----------------------------------------------")
# 最终结果
print(df)
# 输出
2018-01-01 1
2018-01-02 2
2018-01-03 3
2018-01-04 4
2018-01-05 5
2018-01-06 6
Freq: D, dtype: int64
-----------------------------------------------A B C D F
2018-01-01 0.000000 0.000000 -1.688875 5 1
2018-01-02 0.405921 0.596388 0.742552 5 2
2018-01-03 -0.737122 -1.018953 1.367684 5 3
2018-01-04 -0.356770 1.083033 0.876066 5 4
2018-01-05 -1.120744 -0.270765 -0.182049 5 5
2018-01-06 1.279730 -0.662744 0.443358 5 6
缺失数据
Pandas默认使用np.nan来代表缺失数据。Reindexing允许用户对某一轴上的索引改/增/删,并返回数据的副本
# 创建DataFrame对象df1,以dates[0:4]为索引,
# 在df的基础上再加一个新的列'E'(初始均为NaN)
df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ['E'])
print(df1)
print("-----------------------------------------------")
# 将'E'列的前两个行设为1
df1.loc[dates[0]:dates[1],'E'] = 1
print(df1)
# 输出A B C D F E
2018-01-01 0.000000 0.000000 -1.688875 5 1 NaN
2018-01-02 0.405921 0.596388 0.742552 5 2 NaN
2018-01-03 -0.737122 -1.018953 1.367684 5 3 NaN
2018-01-04 -0.356770 1.083033 0.876066 5 4 NaN
-----------------------------------------------A B C D F E
2018-01-01 0.000000 0.000000 -1.688875 5 1 1.0
2018-01-02 0.405921 0.596388 0.742552 5 2 1.0
2018-01-03 -0.737122 -1.018953 1.367684 5 3 NaN
2018-01-04 -0.356770 1.083033 0.876066 5 4 NaN
# 处理缺失数据
# 剔除df1中含NaN的行(只要任一一列为NaN就算)
df2 = df1.dropna(how='any')
print(df2)
print("--------------------------------------")
# 用5填充df1里的缺失值
df2 = df1.fillna(value=5)
print(df2)
print("--------------------------------------")
# 判断df2中的值是否为缺失数据,返回True/False
print(pd.isnull(df2))
# 输出A B C D F E
2018-01-01 0.000000 0.000000 -1.688875 5 1 1.0
2018-01-02 0.405921 0.596388 0.742552 5 2 1.0
--------------------------------------A B C D F E
2018-01-01 0.000000 0.000000 -1.688875 5 1 1.0
2018-01-02 0.405921 0.596388 0.742552 5 2 1.0
2018-01-03 -0.737122 -1.018953 1.367684 5 3 5.0
2018-01-04 -0.356770 1.083033 0.876066 5 4 5.0
--------------------------------------A B C D F E
2018-01-01 False False False False False False
2018-01-02 False False False False False False
2018-01-03 False False False False False False
2018-01-04 False False False False False False此类操作默认排除缺失数据
# 重新创建一份数据
dates = pd.date_range('20180101', periods=6)
df = pd.DataFrame(np.ones((6,4)), index=dates, columns=list('ABCD'))
s = pd.Series([2,2,2,2,2,2], index=dates)
df['E'] = s
df.head()
# 求平均值
print(df.mean())
print("------")# 一行求平均值
print(df.mean(1))
print("------")# 创建Series对象s,以dates为索引并平移2个位置
s = pd.Series([1,3,5,np.nan,6,8], index=dates).shift(2)
print(s)
print("------")# 从df中逐列减去s(若有NaN则得NaN)
print(df.sub(s, axis='index'))# 逐行累加
print(df.apply(np.cumsum))
print("------")# 每列的最大值减最小值
print(df.apply(lambda x: x.max() - x.min()))# 字符
# Series对象的str属性具有一系列字符处理方法,可以很轻松地操作数组的每个元素。
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'])
print(s.str.lower())更多内容请查看我的gittee仓库 : Python基础练习
相关文章:
)
python数据处理与分析入门-pandas使用(4)
往期文章: pandas使用1pandas使用2pandas使用3 pandas使用技巧 创建一个DF对象 # 首先创建一个时间序列 dates pd.date_range(20180101, periods6) print(dates)# 创建DataFrame对象,指定index和columns标签 df pd.DataFrame(np.random.randn(6,4), …...
)
操作系统-单片机进程状态问题(三态模型问题)
例题:在单处理机计算机系统中有1台打印机、1台扫描仪,系统采用先来先服务调度算法。假设系统中有进程P1、P2、P3、P4,其中P1为运行状态,P2为就绪状态,P3等待打印机,P4等待扫描仪。此时,若P1释放…...
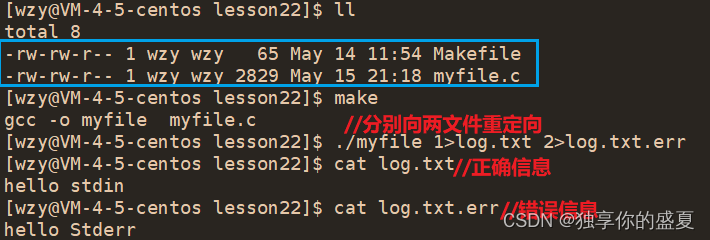
Linux文件:重定向底层实现原理(输入重定向、输出重定向、追加重定向)
Linux文件:重定向底层实现原理(输入重定向、输出重定向、追加重定向) 前言一、文件描述符fd的分配规则二、输出重定向(>)三、输出重定向底层实现原理四、追加重定向(>>)五、输入重定向…...
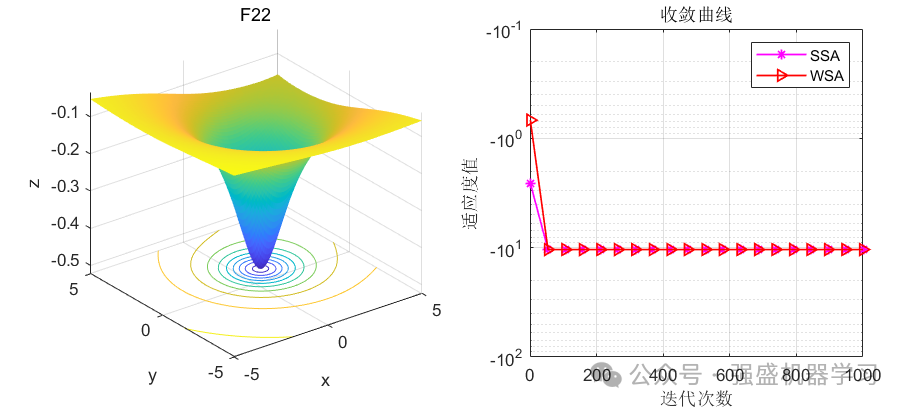
波搜索算法(WSA)-2024年SCI新算法-公式原理详解与性能测评 Matlab代码免费获取
声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~ 目录 原理简介 一、初始化阶段 二、全…...
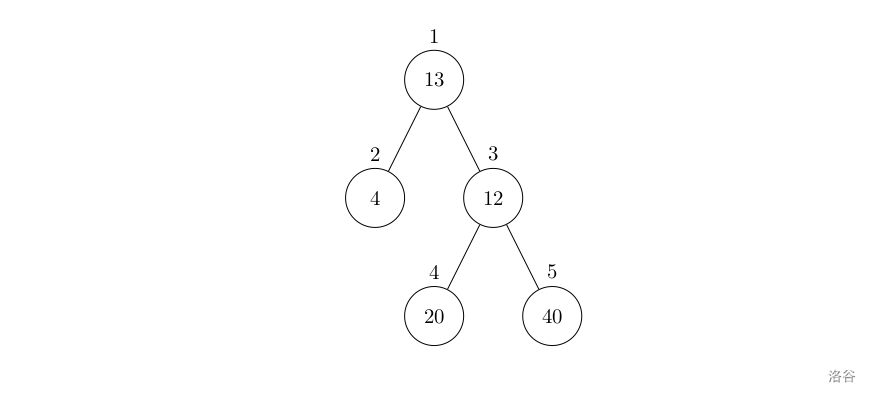
洛谷P1364 医院设置
P1364 医院设置 题目描述 设有一棵二叉树,如图: 其中,圈中的数字表示结点中居民的人口。圈边上数字表示结点编号,现在要求在某个结点上建立一个医院,使所有居民所走的路程之和为最小,同时约定,…...

哈希表的理解和实现
目录 1. 哈希的概念 (是什么) 2. 实现哈希的两种方式 (哈希函数) 2.1. 直接定址法 2.2. 除留余数法 2.2.1. 哈希冲突 3. 补充知识 3.1. 负载因子 3.2. 线性探测和二次探测 4. 闭散列实现哈希表 (开放定址法) 4.1. 开放定址法的实现框架 4.2. Xq::hash_table::insert…...
)
分治算法(Divide-and-Conquer Algorithm)
分治算法(Divide-and-Conquer Algorithm)是一种重要的计算机科学和数学领域的通用问题解决策略。其基本思想是将一个复杂的大规模问题分割成若干个规模较小、结构与原问题相似但相对简单的子问题来处理。这些子问题相互独立,分别求解后再通过…...
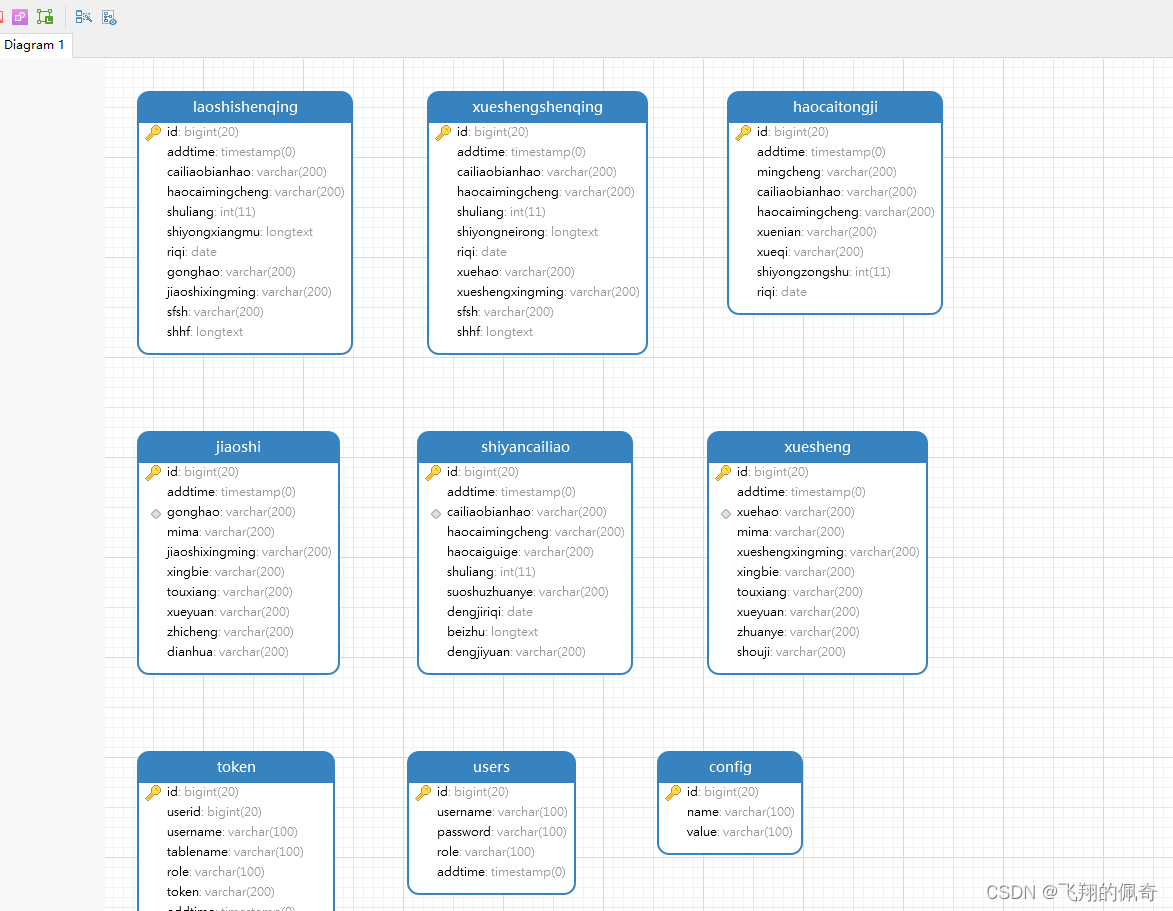
Java项目:基于ssm框架实现的实验室耗材管理系统(B/S架构+源码+数据库+毕业论文+答辩PPT)
一、项目简介 本项目是一套基于ssm框架实现的实验室耗材管理系统 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 二、技术实现 jdk版本:1.8 …...

如何通过专业的二手机店erp优化手机商家运营!
在数字化浪潮席卷全球的大背景下,手机行业作为科技发展的前沿阵地,正经历着前所未有的变革。对于众多手机商家而言,如何在这场变革中抢占先机,实现数字化转型,成为了摆在他们面前的一大难题。幸运的是,途渡…...

CentOS常见的命令及其高质量应用
CentOS是一个流行的、基于Red Hat Enterprise Linux(RHEL)的开源服务器操作系统。由于其稳定性和强大的性能,CentOS被广泛应用于各种服务器环境中。为了有效地管理和维护CentOS系统,熟悉并掌握其常见命令是非常重要的。本文将介绍…...
nodeJs用ffmpeg直播推流到rtmp服务器上
总结 最近在写直播项目 目前比较重要的点就是推拉流 自己也去了解了一下 ffmpeg FFmpeg 是一个开源项目,它提供了一个跨平台的命令行工具,以及一系列用于处理音频和视频数据的库。FFmpeg 能够执行多种任务,包括解封装、转封装、视频和音频…...

Django信号与扩展:深入理解与实践
title: Django信号与扩展:深入理解与实践 date: 2024/5/15 22:40:52 updated: 2024/5/15 22:40:52 categories: 后端开发 tags: Django信号松耦合观察者扩展安全性能 第一部分:Django信号基础 Django信号概述 一. Django信号的定义与作用 Django信…...

使用Docker创建verdaccio私服
verdaccio官网 1.Docker安装 这边以Ubuntu安装为例Ubuntu 安装Docker,具体安装方式请根据自己电脑自行搜索。 2.下载verdaccio docker pull verdaccio/verdaccio3.运行verdaccio 运行容器: docker run -it -d --name verdaccio -p 4873:4873 ver…...

Spring 使用 Groovy 实现动态server
本人在项目中遇到这么个需求,有一个模块的server方法需要频繁修改 经阅读可以使用 Groovy 使用java脚本来时pom坐标 <dependency><groupId>org.codehaus.groovy</groupId><artifactId>groovy</artifactId><version>3.0.9</version>…...

oracle不得不知道的sql
一、oracle 查询语句 1.translate select translate(abc你好cdefgdc,abcdefg,1234567)from dual; select translate(abc你好cdefgdc,abcdefg,)from dual;--如果替换字符整个为空字符 ,则直接返回null select translate(abc你好cdefgdc,abcdefg,122)from dual; sel…...

算法-卡尔曼滤波之卡尔曼滤波的第二个方程:预测方程(状态外推方程)
在上一节中,使用了静态模型,我们推导出了卡尔曼滤波的状态更新方程,但是在实际情况下,系统都是动态,预测阶段,前后时刻的状态是改变的,此时我们引入预测方程,也叫状态外推方程&#…...

刘邦的创业团队是沛县人,朱元璋的则是凤阳;要创业,一个县人才就够了
当人们回顾刘邦和朱元璋的创业经历时,总是会感慨他们起于微末,都创下了偌大王朝,成就无上荣誉。 尤其是我们查阅史书时,发现这二人的崛起班底都是各自的家乡人,例如刘邦的班底就是沛县人,朱元璋的班底是凤…...

【Unity之FairyGUI】你了解FGUI吗,跨平台多功能高效UI插件
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:就业…...
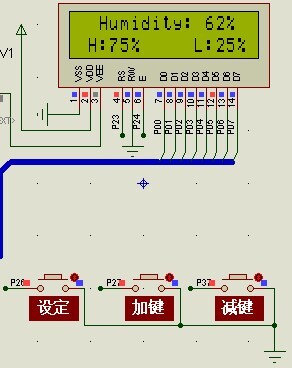
基于51单片机的自动浇花器电路
一、系统概述 自动浇水灌溉系统设计方案,以AT89C51单片机为控制核心,采用模块化的设计方法。 组成部分为:5V供电模块、土壤湿度传感器模块、ADC0832模数转换模块、水泵控制模块、按键输入模块、LCD显示模块和声光报警模块,结构如…...

2024中国(重庆)商旅文化川渝美食暨消费品博览会8月举办
2024中国(重庆)商旅文化川渝美食暨消费品博览会8月举办 邀请函 主办单位: 中国航空学会 重庆市南岸区人民政府 招商执行单位: 重庆港华展览有限公司 展会背景: 2024中国航空科普大会暨第八届全国青少年无人机大赛在重庆举办ÿ…...


HLS技术解析:从原理到FPGA开发实战
1. HLS技术概述与评估背景高等级综合(High-Level Synthesis, HLS)技术正在重塑FPGA开发范式。作为从业十年的硬件加速工程师,我见证了这项技术从实验室走向工业界的全过程。传统RTL开发需要手动编写每一行寄存器传输级代码,而HLS允许开发者用C等高级语言…...

UE5新手必看:给你的自定义Pawn加上碰撞,别再让它“穿墙”了!
UE5碰撞系统实战:从零构建防穿墙Pawn的完整指南 当你在UE5中第一次创建自定义Pawn时,最令人沮丧的莫过于看着自己精心设计的角色像幽灵一样穿过墙壁和障碍物。这种"穿模"现象不仅破坏游戏体验,更会导致后续游戏逻辑的全面崩溃。本文…...

3分钟快速上手:Windows实时语音转文字工具TMSpeech完整使用指南
3分钟快速上手:Windows实时语音转文字工具TMSpeech完整使用指南 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 还在为会议记录手忙脚乱吗?是否曾因错过重要信息而懊恼?今天我要向…...

利用Taotoken实现AI应用的高可用与容灾路由设计思路
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken实现AI应用的高可用与容灾路由设计思路 应用场景类,探讨在构建对稳定性要求高的生产级AI应用时࿰…...

智能识别整理会议内容,让开会后怎么列待办更清晰更省事
作为经常跑客户、开会议的销售,此前我常被整理沟通内容、梳理待办的工作困扰,不仅耗时久,还容易漏记客户需求、搞错时间节点。结合大半年的实测体验,整理出一套AI整理方法,能快速清晰梳理待办,节省大量时间…...

AMD Ryzen处理器终极调试指南:SMU Debug Tool实战技巧与完整解决方案
AMD Ryzen处理器终极调试指南:SMU Debug Tool实战技巧与完整解决方案 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地…...

告别卡顿!手把手教你配置UE5+Cesium子关卡,打造流畅的大型开放世界
告别卡顿!UE5Cesium子关卡实战:打造流畅的大型开放世界 当你在UE5中构建一个横跨多个城市的开放世界时,是否遇到过这样的场景:镜头拉到高空俯瞰时帧率骤降,或者角色在城市间快速移动时出现明显的加载卡顿?这…...

面试题详解:智能客服 Agent 系统全栈拆解——Rasa Pro、对话管理、意图识别、GraphRAG、Qwen 与 RAG 优化实战
1. 先把整个问题想清楚:智能客服系统到底在解决什么?1.1 它不是一个“会聊天的机器人”,而是一套能理解、决策、执行、反馈的系统很多人一提客服系统,就把重点全部放在大模型会不会回答上。但企业里真正的客服系统,从来…...

Loop窗口管理:终极Mac多窗口高效布局指南
Loop窗口管理:终极Mac多窗口高效布局指南 【免费下载链接】Loop Window management made elegant. 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop 你是不是经常在Mac上同时打开十几个窗口,然后迷失在层层叠叠的界面中?写代码…...