哈希表的理解和实现
目录
1. 哈希的概念 (是什么)
2. 实现哈希的两种方式 (哈希函数)
2.1. 直接定址法
2.2. 除留余数法
2.2.1. 哈希冲突
3. 补充知识
3.1. 负载因子
3.2. 线性探测和二次探测
4. 闭散列实现哈希表 (开放定址法)
4.1. 开放定址法的实现框架
4.2. Xq::hash_table::insert 的实现
4.3. Xq::hash_table::find 的实现
4.4. Xq::hash_table::erase 的实现
4.5. 开放定址法实现哈希表的完整代码
5. 开散列实现哈希表 (拉链法)
5.1. 拉链法的实现框架
5.2. 哈希表扩容问题 (表的大小的设计问题)
5.3. Xq::hash_table::insert 的实现
5.4. Xq::hash_table::find 的实现
5.5. Xq::hash_table::erase 的实现
5.6. 拉链法的完整实现 (初始版本)
5.7. 解决取模操作的限制
5.8. 拉链法的完整实现 (更新版本)
1. 哈希的概念 (是什么)
哈希也叫做散列,本质是一种映射关系,key 和存储位置建立映射(关联)关系,哈希or散列是一种思想(映射)。
2. 实现哈希的两种方式 (哈希函数)
哈希函数(Hash Function)是一种将任意长度的输入数据(也称为消息、键或原始数据)转换为固定长度的输出(哈希值或摘要)的算法。
常见的哈希函数有两种:
- 直接定址法;
- 除留余数法。
2.1. 直接定址法
直接定址法(Direct Addressing)也被称为确定性哈希函数(Deterministic Hash Function)。
具体来说,直接定址法会将键直接映射到索引值上,不需要进行任何复杂的计算或处理。
比如下面这个例子:
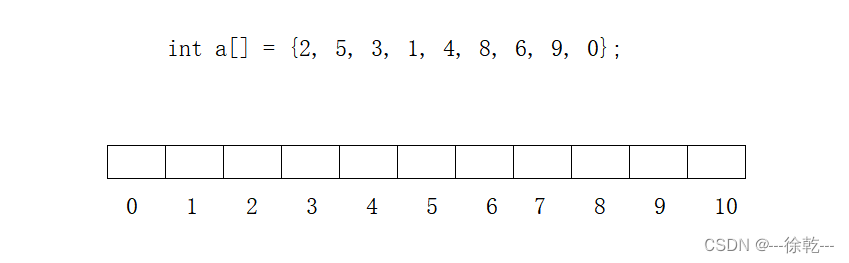
我们要将 a 数组中的元素全部映射到这张表中, 比如,你是2,我就映射到下标为2的空间中;如果你是0,我就映射到下标为0的地址空间中。
可以看到, 直接定址法的基本思想就是,将键的某个属性或组合 (比如这里键自身的值) 作为索引来直接访问哈希表的特定位置。这样一来,每个键都会与唯一的索引位置相对应,即映射关系是唯一的。
直接定址法的优点:
- 插入和查找操作的时间复杂度为 O(1);
- 不存在哈希冲突 (因为映射关系是唯一的)。
但是直接定址法在某些场景下会暴露它的缺点,比如,如下场景:
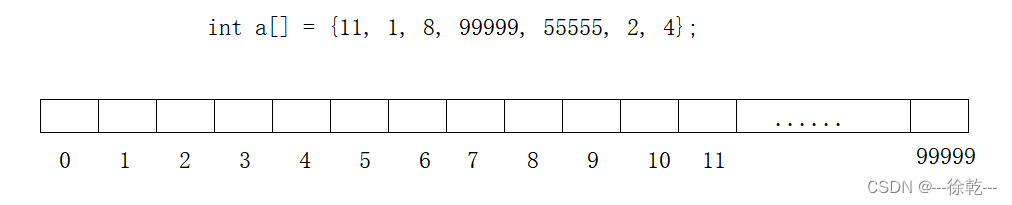
可以看到,我要映射的数据不过寥寥几个,但由于数据波动范围非常大,同时,直接定址法要求映射关系唯一,换言之,此时映射的这张表的空间就需要非常大,但由于数据非常少,导致空间利用率极低。
因此,我们对直接定址法的总结:
- 直接定址法,简单高效,查找和插入的时间复杂度为 O(1);
- 因为直接定址法要求映射关系唯一,故不存在哈希冲突;
- 也正因为直接定址法要求映射关系唯一,对于波动范围比较大的数据,可能会导致空间消耗过大,且空间利用率低;
因此直接定址法的应用场景是非常局限的:只适用于关键字的波动范围比较小的场景,对于波动范围比较大的场景,直接定址法不适用,因此人们提出了除留余数法。
2.2. 除留余数法
除留余数法(Division Method)是一种常见的哈希函数处理方法,用于将输入键映射到哈希表中的索引位置。
除留余数法的基本思想是,将输入键模 (%) 一个特定的数(通常是哈希表的大小),得到余数作为最终的哈希值或索引位置。
具体来说,除留余数法的步骤如下:
- 1. 选择一个用于取模的常数,通常为一个较大的素数,例如哈希表的大小;
- 2. 对于给定的键,使用取模 (%) 运算将其除以选择的常数;
- 3. 得到的余数作为最终的哈希值或索引位置。
例如,下面这种情况,现在有一个数组 {23, 45, 11, 57, 36},同时,哈希表的大小为10。
按照除留余数法的步骤:
- 选择一个用于取模的常数,在这里就是 10;
- Hash(key) = key % 10;
- Hash(Key) 作为最终的哈希值。
具体如下:
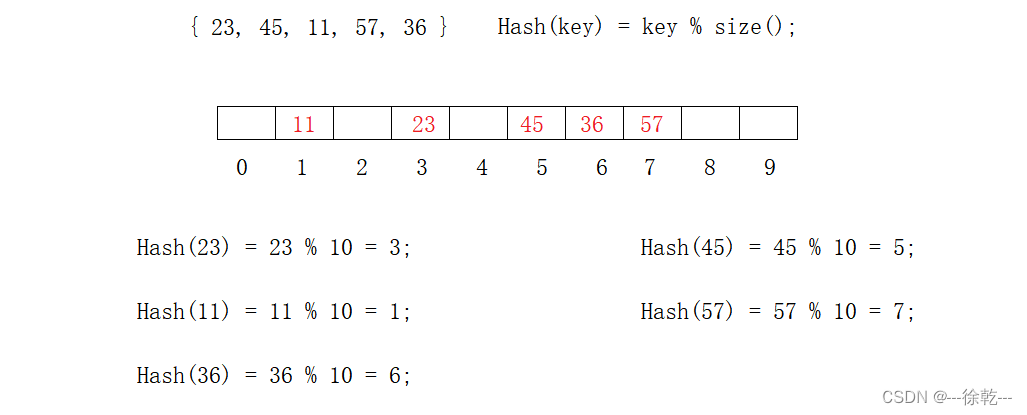
我们发现,上面的数据都可以对应到一个独特的位置,因此查找的时候,我们可以根据同样的方式查找这个数是不是存在。
但是,如果我现在还要继续插入25这个元素,会发生什么问题呢?
我们发现,Hash(25) % 10 = 5,可是 5 这个位置已经被占用了啊,那该怎么办呢?
首先,我们将这种情况称之为哈希冲突/哈希碰撞,即不同的关键字映射到了哈希表的同一个位置。
2.2.1. 哈希冲突
哈希冲突(Hash Collision)或者称之为哈希碰撞,它是指不同的键(Key)被哈希函数映射到相同的哈希值(Hash Value)或哈希表(Hash Table)的同一个位置的情况。
在哈希结构中,哈希函数将键映射到固定长度的哈希值或索引位置。由于哈希函数的输出空间通常要比键的输入空间小得多,因此不同的键可能会产生相同的哈希值。
解决哈希冲突的常见方法包括:
- 1. 开放寻址法(Open Addressing):开放寻址法也称之为闭散列 ,在哈希表的冲突位置寻找下一个可用的空槽来存储键值对。常见的开放寻址方法包括线性探测、二次探索等;
- 2. 拉链法(哈希桶):拉链法也称之为开散列,在哈希表的每个索引位置上维护一个单链表,将具有相同哈希值的键值对存储在链表中。在插入、查找或删除时,根据哈希值找到对应的链表,然后在链表中进行操作;
- 3. 增加哈希函数的复杂度:通过改变哈希函数的设计,可以尽量减少哈希冲突的发生。例如,使用更复杂的哈希函数算法、增加哈希表的大小等。
接下来,我们就要以除留余数法为基本思想实现哈希表 (直接定址法实现哈希表价值不大),由于除留余数法的映射关系并不唯一,因此会有哈希冲突,而我们为了解决哈希冲突,选择两个方案解决,分别是:
- 闭散列,即开放定址法;
- 开散列,即拉链法。
3. 补充知识
3.1. 负载因子
负载因子(load factor)是指哈希表中已经存储的有效元素数量与哈希表总大小之间的比率。它可以用来衡量哈希表的装填程度或密度。
一般情况下,负载因子的计算公式:
- 负载因子 = 已存储的有效元素个数 / 哈希表大小;
在哈希表中,负载因子的数值范围通常为 0 到 1 之间:
- 负载因子越接近 1,表示哈希表中存储的有效元素越多,装填程度越高,哈希冲突的概率也就越高,空间利用率高;
- 负载因子越接近 0,表示哈希表中存储的有效元素较少,装填程度较低,哈希冲突的概率也就越低,空间利用率低。
从这里应该可以看出,负载因子不可太大,也不可太小,而应该适中。
一般来说,负载因子会有一个阈值(例如 0.7 或 0.8)时,我们通常会考虑对哈希表进行扩容操作,以保持合理的负载因子。
总而言之,较低的负载因子可以提供较好的性能,但会占用更多的内存空间;较高的负载因子则可以节省内存空间,但可能会带来更多的哈希冲突和性能下降。
3.2. 线性探测和二次探测
线性探测(Linear Probing)是一种常见的解决哈希冲突的方法,用于处理哈希表中的元素冲突问题。
当发生哈希冲突时,线性探测会尝试在哈希表中找到下一个可用的位置来存储冲突的元素。具体的操作是,如果哈希表中的某个槽位已经被占用,则线性探测会依次检查下一个槽位,直到找到一个空闲的槽位,然后将元素存储在该位置。
当需要查找或删除特定元素时,也需要使用线性探测来定位目标元素所在的位置。如果目标元素不在哈希表的初始位置上,线性探测会按照相同的方式,依次检查下一个槽位,直到找到目标元素或遇到空槽位。
线性探测的优点是实现简单,不需要维护额外的数据结构。然而,线性探测也有一些限制。当装填因子较高时,线性探测容易引发聚集现象,即一些相邻聚集位置连续冲突,可能形成 "踩踏" ,导致哈希表的性能下降。此外,线性探测也可能导致元素的聚集在表的一侧,造成不均匀的分布。
为了克服线性探测的缺点,还有其他的解决冲突方法,如二次探测等,二次探测,缓解线性探测的 "踩踏" ,在实际运用中,可以根据具体的场景和需求选择适合的解决方案。
- 线性探测:pos++;
- 二次探测:pos + i ^ 2;
4. 闭散列实现哈希表 (开放定址法)
4.1. 开放定址法的实现框架
在实现闭散列之前,我们需要讨论一个问题:
如何判定一个位置是否有值呢? 当某个位置存在值的同时,如何判定这个值是否有效呢?
因为,除留余数法的映射关系并不唯一,存在哈希冲突,而闭散列解决哈希冲突,是通过线性探测或者二次探测,而探测是需要找一个空位置,此时就需要判定,某个位置是否有值, 且这个值是否有效。
事实上,对于一个位置无非就三种情况:
- 存在有效值;
- 存在无效值 (该位置的值已被删除);
- 不存在值 (该位置没有被赋值过);
我们的解决方案是,通过枚举解决,如下:
enum state
{EXIST, // (存在有效值)EMPTY, // 存在无效值 (该位置的值已被删除)DELETE // 不存在值 (该位置没有被赋值过);
};正因为要区分位置的状态,而哈希表有存储相应的值,故哈希表的数据应该是一个自定义类型,将状态和值封装起来,如下:
template<class K, class V>
struct hash_data
{std::pair<K, V> _kv;state _st;hash_data(const std::pair<K, V>& kv = std::pair<K, V>()):_kv(kv), _st(EMPTY){}
};同时,为了获得负载因子,我们需要保存有效元素的个数。
有了上面,我们的哈希表的框架如下:
namespace Xq
{template<class K, class V>class hash_table{private:typedef hash_data<K, V> Node;public:bool insert(const std::pair<K, V>& kv) {}bool find(const K& key) {}bool erase(const K& key) {}private:std::vector<Node> _table;size_t _size; // 有效元素个数};
}4.2. Xq::hash_table::insert 的实现
首先,暂不考虑扩容和去重问题,如何实现 insert 呢?
bool insert(const std::pair<K, V>& kv)
{// 除留余数法, 计算位置// 注意:这里不能模capacity, 因为 vector 的 operator[] 会强制见检查 pos < size()// 因此实际中, 最好让 size == capacity, 即开空间 or 扩容用 resize 即可.size_t pos = kv.first % _table.size();// 如果这个位置已经有值了, 说明出现了哈希冲突, 在这里采用线性探测// 线性探测: 当发生哈希冲突的位置开始,依次向后探测,直到寻找到下一个空位置(没有被占用的位置)while (_table[pos]._st == EXIST){++pos;// 如果 pos 走到了表的结尾, 让 pos 回到表的开始 if (pos == _table.size())pos = 0;}_table[pos]._kv = kv;_table[pos]._st = EXIST;++_size;return true;
}当处理完上面的逻辑后,我们需要考虑扩容问题:
void broaden_capacity(size_t new_size)
{// 在这里重新构造一个哈希表,复用inserthash_table<K, V> new_table;new_table._table.resize(new_size);for (size_t i = 0; i < _table.size(); ++i){if (_table[i]._st == EXIST){new_table.insert(_table[i]._kv);}}//更新完数据后,交换新表和旧表std::swap(new_table._table, _table);// 新表出了函数作用域, 自动调用析构, 释放资源.
}bool insert(const std::pair<K, V>& kv)
{// 去重if (find(kv.first)) return false;// 处理扩容// 空表或者负载因子大于等于0.7进行扩容// 扩容不可以将数据直接拷贝下来, 因为扩容后, 原来的映射关系会受到影响 (表的大小改变)// 此时需要重新映射, 将旧表的数据重新映射到新表, 因此, // 哈希表的扩容代价是很大的,比 vector 的扩容代价还大if (_table.size() == 0 || _size * 10 / _table.size() >= 7){size_t new_size = _table.size() == 0 ? 10 : 2 * _table.size();broaden_capacity(new_size);}// 插入数据逻辑, 在这里省略.
}当处理完这个问题,此时我们还需要考虑去重问题,解决方案很简单,写一个 find, 如果这个 Key 已经存在,不插入即可,如下:
bool insert(const std::pair<K, V>& kv)
{// 去重if (find(kv.first)) return false;// 处理扩容逻辑, 省略// 插入数据逻辑, 省略.return true;
}4.3. Xq::hash_table::find 的实现
find 的处理逻辑很简单:
- 如果表为空,直接返回fasle;
- 如果表不为空:
- 计算这个 key 的初始位置;
- 如果当前位置没有,线性探测下一个位置;
- 如果在线性探测过程中,某个位置的状态为 EMPTY,说明没有这个值,返回 false;
- 如果走到表的结尾,回到表的开始;
- 如果走到了初始位置,代表没有这个值,返回 false。
实现如下:
bool find(const K& key)
{// 如果没有数据,直接返回falseif (_size == 0) return false;size_t pos = key % _table.size();size_t start = pos;// 如果走到空,说明没有这个值while (_table[pos]._st != EMPTY){if (_table[pos]._kv.first == key){return true;}++pos;if (pos == _table.size())pos = 0;// 遍历了一圈也没找到,说明不存在,避免死循环if (pos == start)return false;}return false;
}4.4. Xq::hash_table::erase 的实现
由于我们对哈希表的每个位置都设置了状态,因此,删除就很简单了,只需要将某个位置的状态设置为 DELETE 即可,实现如下:
bool erase(const K& key)
{// 如果目标 key 不存在, 返回false即可if (_size == 0 || !find(key)) return false;// 如果目标 key 存在, 只需要将目标位置的状态置为DELETE即可size_t pos = key % _table.size();// 由于存储元素是线性探测的方式存储的, 因此删除也需要按照线性探测的方式查找while (_table[pos]._kv.first != key){++pos;if (pos == _table.size())pos = 0;}// 将目标 key 所在的位置的状态置为 DELETE_table[pos]._st = DELETE;// 并--有效元素的个数--_size;return true;
}4.5. 开放定址法实现哈希表的完整代码
namespace Xq
{// 用三种状态标记哈希表的每个空间的情况enum state{EXIST, // (存在有效值)EMPTY, // 存在无效值 (该位置的值已被删除)DELETE // 不存在值 (该位置没有被赋值过);};template<class K, class V>struct hash_data{std::pair<K, V> _kv;state _st;hash_data(const std::pair<K, V>& kv = std::pair<K, V>()):_kv(kv), _st(EMPTY){}};template<class K, class V>class hash_table{private:typedef hash_data<K, V> Node;public:hash_table() :_size(0){}void broaden_capacity(size_t new_size){// 在这里重新构造一个哈希表,复用inserthash_table<K, V> new_table;new_table._table.resize(new_size);for (size_t i = 0; i < _table.size(); ++i){if (_table[i]._st == EXIST){new_table.insert(_table[i]._kv);}}//更新完数据后,交换新表和旧表std::swap(new_table._table, _table);// 新表出了函数作用域, 自动调用析构, 释放资源. }bool insert(const std::pair<K, V>& kv){// 去重if (find(kv.first)) return false;// 处理扩容// 空表或者负载因子大于等于0.7进行扩容// 扩容不可以将数据直接拷贝下来, 因为扩容后, 原来的映射关系会受到影响 (表的大小改变)// 此时需要重新映射, 将旧表的数据重新映射到新表, 因此, // 哈希表的扩容代价是很大的,比 vector 的扩容代价还大if (_table.size() == 0 || _size * 10 / _table.size() >= 7){size_t new_size = _table.size() == 0 ? 10 : 2 * _table.size();broaden_capacity(new_size);}// 除留余数法, 计算位置// 注意:这里不能模capacity, 因为 vector 的 operator[] 会强制见检查 pos < size()// 因此实际中, 最好让 size == capacity, 即开空间 or 扩容用 resize 即可.size_t pos = kv.first % _table.size();// 如果这个位置已经有值了, 说明出现了哈希冲突, 在这里采用线性探测// 线性探测: 当发生哈希冲突的位置开始,依次向后探测,直到寻找到下一个空位置(没有被占用的位置)while (_table[pos]._st == EXIST){++pos;// 如果 pos 走到了表的结尾, 让 pos 回到表的开始 if (pos == _table.size())pos = 0;}_table[pos]._kv = kv;_table[pos]._st = EXIST;++_size;return true;}bool find(const K& key){// 如果没有数据,直接返回falseif (_size == 0) return false;size_t pos = key % _table.size();size_t start = pos;// 如果走到空,说明没有这个值while (_table[pos]._st != EMPTY){if (_table[pos]._kv.first == key){return true;}++pos;if (pos == _table.size())pos = 0;// 遍历了一圈也没找到,说明不存在,避免死循环if (pos == start)return false;}return false;}bool erase(const K& key){// 如果目标 key 不存在, 返回false即可if (_size == 0 || !find(key)) return false;// 如果目标 key 存在, 只需要将目标位置的状态置为DELETE即可size_t pos = key % _table.size();// 由于存储元素是线性探测的方式存储的, 因此删除也需要按照线性探测的方式查找while (_table[pos]._kv.first != key){++pos;if (pos == _table.size())pos = 0;}// 将目标 key 所在的位置的状态置为 DELETE_table[pos]._st = DELETE;// 并--有效元素的个数--_size;return true;}private:std::vector<Node> _table;size_t _size; // 有效元素个数};
}5. 开散列实现哈希表 (拉链法)
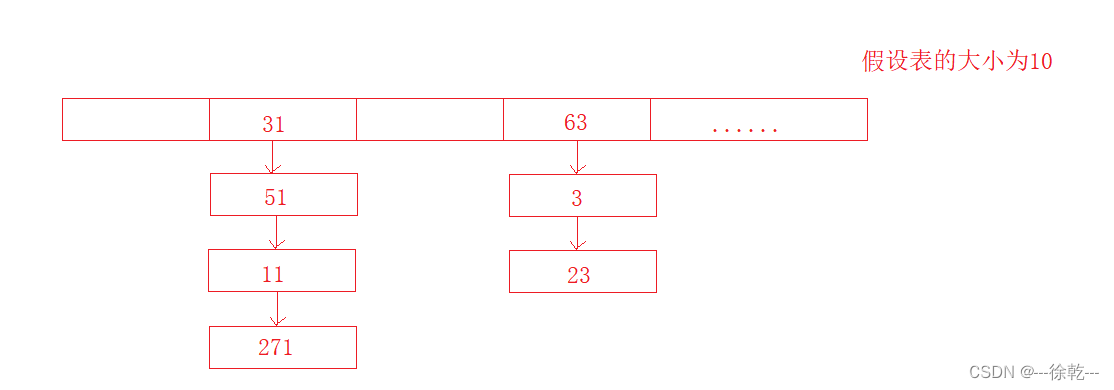
拉链法实现哈希表,是如何解决哈希冲突的呢?
拉链法实现的哈希表也称之为哈希桶,本质上是哈希表中每个位置中存储的并不仅仅是一个节点,而是一个单链表,当产生哈希冲突时,就会将相同位置的节点链入到一个链表中,如下所示:
5.1. 拉链法的实现框架
#pragma once
#include <iostream>
#include <utility>
#include <vector>namespace Xq
{template<class K, class V>struct hash_table_node{struct hash_table_node<K, V>* _next;std::pair<K, V> _kv;hash_table_node(const std::pair<K, V>& kv = std::pair<K, V>()):_kv(kv), _next(nullptr){}};template <class K, class V>class hash_table{private:typedef hash_table_node<K, V> Node;public:hash_table() :_size(0){}bool insert(const std::pair<K, V>& kv) {}Node* find(const K& key) {}bool erase(const K& key) {}private:std::vector<Node*> _table;size_t _size; // 存储有效数据的个数};
}5.2. 哈希表扩容问题 (表的大小的设计问题)
在闭散列中实现哈希表时,我们所用的哈希表的初始大小为10,且后续扩容是以2倍的方式进行的,但我们在直接说过,由于除留余数法存在哈希冲突,故为了减少哈希冲突,人们发现,如果表的大小为一个素数,就会减小哈希冲突的可能。
同时,我们可以看看 SGI-STL 版本的哈希表如何处理表的大小的问题的,如下:
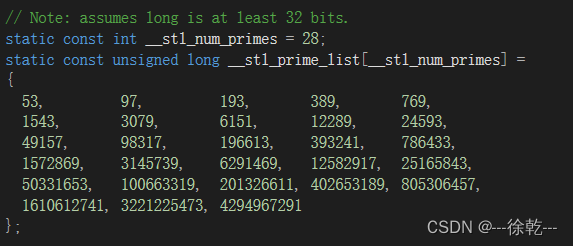
可以发现,STL 中哈希表的大小都是一个素数,我们也照葫芦画瓢,如下:
#pragma once
#include <iostream>
#include <utility>
#include <vector>namespace Xq
{template<class K, class V>struct hash_table_node{// 省略 ...};template <class K, class V>class hash_table{private:typedef hash_table_node<K, V> Node;static const size_t _table_size = 28; // 静态数组的大小static const size_t _table_count_arr[_table_size]; // 哈希表的大小(每个都是素数)public:hash_table() :_size(0){}bool insert(const std::pair<K, V>& kv) {}Node* find(const K& key) {}bool erase(const K& key) {}private:std::vector<Node*> _table;size_t _size; // 存储有效数据的个数};template<class K, class V>const size_t hash_table<K, V>::_table_count_arr[hash_table<K, V>::_table_size] = // 哈希表的大小(每个都是素数){53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};
}因为扩容需要得到新的表的大小,故我们写一个接口,用于获取哈希表新的大小,如下:
// 用来获取下一次扩容后的表的大小
size_t get_prime_size(size_t size)
{for (size_t i = 0; i < _table_size; ++i){if (i == 28) break;if (_table_count_arr[i] > size)return _table_count_arr[i];}return -1;
}5.3. Xq::hash_table::insert 的实现
分三个大致逻辑:
- 插入数据 (头插);
- 扩容;
- 去重。
实现如下:
bool insert(const std::pair<K, V>& kv)
{// 去重逻辑if (find(kv.first)) return false;// 扩容逻辑// 空表或者负载因子>=1 进行扩容if (_table.size() == 0 || _size * 10 / _table.size() >= 10){// 创建新表std::vector<Node*> new_table;// 获得新表的大小new_table.resize(get_prime_size(_table.size()), nullptr);// 将旧表的有效节点摘下来, 头插到新表for (size_t i = 0; i < _table.size(); ++i){// 如果当前位置有节点, 不为空// 那么保存下一个节点, 并获取当前节点在新表的位置, 链入到新表中// 遍历下一个节点while (_table[i]){Node* next = _table[i]->_next;size_t pos = _table[i]->_kv.first % new_table.size();_table[i]->_next = new_table[pos];new_table[pos] = _table[i];_table[i] = next;}}// 交换两个表,扩容结束std::swap(_table, new_table);}// 插入数据逻辑size_t pos = kv.first % _table.size();Node* newnode = new Node(kv);// 这里采用头插, 因为是单链表, 时间复杂度为 O(1)newnode->_next = _table[pos];_table[pos] = newnode;++_size;return true;
}5.4. Xq::hash_table::find 的实现
Node* find(const K& key)
{// 空表, 直接返回空if (_size == 0) return nullptr;// 非空表, 计算目标位置size_t obj_pos = key % _table.size();// 搜索这个单链表Node* cur = _table[obj_pos];while (cur){if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;
}5.5. Xq::hash_table::erase 的实现
事实上,这里就是一个单链表的删除,代码如下:
bool erase(const K& key)
{if (!find(key) || _size == 0) return false;size_t pos = key % _table.size();//头删Node* cur = _table[pos];if (cur->_kv.first == key){Node* next = cur->_next;delete cur;_table[pos] = next;}// !头删else{while (cur->_next->_kv.first != key){cur = cur->_next;}Node* next = cur->_next->_next;delete cur->_next;cur->_next = next;}--_size;return true;
}5.6. 拉链法的完整实现 (初始版本)
#pragma once
#include <iostream>
#include <utility>
#include <vector>namespace Xq
{template<class K, class V>struct hash_table_node{struct hash_table_node<K, V>* _next;std::pair<K, V> _kv;hash_table_node(const std::pair<K, V>& kv = std::pair<K, V>()):_kv(kv), _next(nullptr){}};template <class K, class V>class hash_table{private:typedef hash_table_node<K, V> Node;static const size_t _table_size = 28; // 静态数组的大小static const size_t _table_count_arr[_table_size]; // 哈希表的大小(每个都是素数)public:hash_table() :_size(0){}// 用来获取下一次扩容后的表的大小size_t get_prime_size(size_t size){for (size_t i = 0; i < _table_size; ++i){if (i == 28) break;if (_table_count_arr[i] > size)return _table_count_arr[i];}return -1;}bool insert(const std::pair<K, V>& kv){// 去重逻辑if (find(kv.first)) return false;// 扩容逻辑// 空表或者负载因子>=1 进行扩容if (_table.size() == 0 || _size * 10 / _table.size() >= 10){// 创建新表std::vector<Node*> new_table;// 获得新表的大小new_table.resize(get_prime_size(_table.size()), nullptr);// 将旧表的有效节点摘下来, 头插到新表for (size_t i = 0; i < _table.size(); ++i){// 如果当前位置有节点, 不为空// 那么保存下一个节点, 并获取当前节点在新表的位置, 链入到新表中// 遍历下一个节点while (_table[i]){Node* next = _table[i]->_next;size_t pos = _table[i]->_kv.first % new_table.size();_table[i]->_next = new_table[pos];new_table[pos] = _table[i];_table[i] = next;}}// 交换两个表,扩容结束std::swap(_table, new_table);}// 插入数据逻辑size_t pos = kv.first % _table.size();Node* newnode = new Node(kv);newnode->_next = _table[pos];_table[pos] = newnode;++_size;return true;}Node* find(const K& key){// 空表, 直接返回空if (_size == 0) return nullptr;// 非空表, 计算目标位置size_t obj_pos = key % _table.size();// 搜索这个单链表Node* cur = _table[obj_pos];while (cur){if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;}bool erase(const K& key){if (!find(key) || _size == 0) return false;size_t pos = key % _table.size();//头删Node* cur = _table[pos];if (cur->_kv.first == key){Node* next = cur->_next;delete cur;_table[pos] = next;}// !头删else{while (cur->_next->_kv.first != key){cur = cur->_next;}Node* next = cur->_next->_next;delete cur->_next;cur->_next = next;}--_size;return true;}private:std::vector<Node*> _table;size_t _size; // 存储有效数据的个数};// 哈希表的大小(每个都是素数)template<class K, class V>const size_t hash_table<K, V>::_table_count_arr[hash_table<K, V>::_table_size] = {53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};
}5.7. 解决取模操作的限制
上面的代码,存在问题,假如此时的这个K是一个 string,那么会带来什么样的问题呢?
如下 demo :
void Test1(void)
{std::string str[] = { "老虎", "狮子", "大熊猫", "长颈鹿", "孔雀" };srand((unsigned int)time(nullptr));Xq::hash_table<std::string, int> my_hash;for (size_t i = 0; i < 10; ++i){std::string tmp = str[rand() % 5];Xq::hash_table_node<std::string, int>* ret = my_hash.find(tmp);// 如果该动物没存在,就插入map中,并将Value赋值为1if (!ret)my_hash.insert(std::make_pair(tmp, 1));// 如果该动物存在,将Value值++即可else++ret->_kv.second;}
}现象如下:

因为此时的 key 是一个 string, 而默认情况下, string 是不支持取模操作的,故编译报错,如何解决?
我们需要利用仿函数和特化机制,让哈希表具有一种功能,能够让特定的类型支持取模操作,在这里,具体操作就是,让哈希表这个类模板具有第三个模板参数,这个模板参数是一个仿函数类型,通过这个仿函数,让特定类型支持取模操作,如下:
// hash_func这个仿函数的主要目的: 将 key 转换为 size_t, 以便于支持取模操作
template<class K>
struct hash_func
{size_t operator()(const K& key){return (size_t)key;}
};// 例如在这里,string默认是不可以进行取模运算的
// 因此在这里利用类模板的特化,针对string特殊处理
template<>
struct hash_func<std::string>
{size_t operator()(const std::string& str){size_t ret = 0;for (auto ch : str){ret *= 131;ret += ch;}return ret;}
};template <class K, class V, class Hash = hash_func<K>>
class hash_table {};可以看到,上面的代码中,当我们需要将一个 string 类型的 key 转为整形的时候,我们会让其每个字符乘等于131,这是为什么呢?
首先,我们将 string 类的 key 转化为整形的目的是:为了让其可以进行取模,但是如果是以下场景:
- string str1 = "ate";
- string str2 = "eat";
我们可以发现,如果我们让其的每个字符直接进行相加求和,那么带来的问题就是它们最后结果是一致的,那么就会带来增大哈希冲突的可能性,因此为了减少哈希冲突,将其每个字符都 *= 131,至于这里为什么是 131,原因如下:
- 131是一个较大的质数,质数具有较好的散列性质,可以减少哈希冲突的概率。
有了这个模板参数 (Hash),未来哈希表只要涉及到取模操作,都需要让 key 通过这个仿函数进行取模,在这里只演示 insert 如下:
bool insert(const std::pair<K, V>& kv)
{if (find(kv.first)) return false;// #####################################################// 实例化这个仿函数对象Hash hash_func;// #####################################################if (_table.size() == 0 || _size * 10 / _table.size() >= 10){std::vector<Node*> new_table;new_table.resize(get_prime_size(_table.size()), nullptr);for (size_t i = 0; i < _table.size(); ++i){while (_table[i]){Node* next = _table[i]->_next;// #####################################################// 只要涉及到取模操作, 都需要通过这个模板参数size_t pos = hash_func(_table[i]->_kv.first) % new_table.size();// #####################################################_table[i]->_next = new_table[pos];new_table[pos] = _table[i];_table[i] = next;}}std::swap(_table, new_table);}// #####################################################// 只要涉及到取模操作, 都需要通过这个模板参数size_t pos = hash_func(kv.first) % _table.size();// #####################################################Node* newnode = new Node(kv);newnode->_next = _table[pos];_table[pos] = newnode;++_size;return true;
}5.8. 拉链法的完整实现 (更新版本)
#pragma once
#include <iostream>
#include <utility>
#include <vector>namespace Xq
{template<class K, class V>struct hash_table_node{struct hash_table_node<K, V>* _next;std::pair<K, V> _kv;hash_table_node(const std::pair<K, V>& kv = std::pair<K, V>()):_kv(kv), _next(nullptr){}};// hash_func这个仿函数的主要目的: 将 key 转换为 size_t, 以便于支持取模操作template<class K>struct hash_func{size_t operator()(const K& key){return (size_t)key;}};// 例如在这里,string默认是不可以进行取模运算的// 因此在这里利用类模板的特化,针对string特殊处理template<>struct hash_func<std::string>{size_t operator()(const std::string& str){size_t ret = 0;// 具体这里为什么要乘于131,请看解释(1)for (auto ch : str){ret *= 131;ret += ch;}return ret;}};template <class K, class V, class Hash = hash_func<K>>class hash_table{private:typedef hash_table_node<K, V> Node;static const size_t _table_size = 28; // 静态数组的大小static const size_t _table_count_arr[_table_size]; // 哈希表的大小(每个都是素数)public:hash_table() :_size(0){}// 用来获取下一次扩容后的表的大小size_t get_prime_size(size_t size){for (size_t i = 0; i < _table_size; ++i){if (i == 28) break;if (_table_count_arr[i] > size)return _table_count_arr[i];}return -1;}bool insert(const std::pair<K, V>& kv){// 去重逻辑if (find(kv.first)) return false;// 实例化这个仿函数对象Hash hash_func;// 扩容逻辑// 空表或者负载因子>=1 进行扩容if (_table.size() == 0 || _size * 10 / _table.size() >= 10){// 创建新表std::vector<Node*> new_table;// 获得新表的大小new_table.resize(get_prime_size(_table.size()), nullptr);// 将旧表的有效节点摘下来, 头插到新表for (size_t i = 0; i < _table.size(); ++i){// 如果当前位置有节点, 不为空// 那么保存下一个节点, 并获取当前节点在新表的位置, 链入到新表中// 遍历下一个节点while (_table[i]){Node* next = _table[i]->_next;// 只要涉及到取模操作, 都需要通过这个模板参数size_t pos = hash_func(_table[i]->_kv.first) % new_table.size();_table[i]->_next = new_table[pos];new_table[pos] = _table[i];_table[i] = next;}}// 交换两个表,扩容结束std::swap(_table, new_table);}// 插入数据逻辑// 只要涉及到取模操作, 都需要通过这个模板参数size_t pos = hash_func(kv.first) % _table.size();Node* newnode = new Node(kv);newnode->_next = _table[pos];_table[pos] = newnode;++_size;return true;}Node* find(const K& key){Hash hash_func;// 空表, 直接返回空if (_size == 0) return nullptr;// 非空表, 计算目标位置size_t obj_pos = hash_func(key) % _table.size();// 搜索这个单链表Node* cur = _table[obj_pos];while (cur){if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;}bool erase(const K& key){Hash hash_func;if (!find(key) || _size == 0) return false;size_t pos = hash_func(key) % _table.size();//头删Node* cur = _table[pos];if (cur->_kv.first == key){Node* next = cur->_next;delete cur;_table[pos] = next;}// !头删else{while (cur->_next->_kv.first != key){cur = cur->_next;}Node* next = cur->_next->_next;delete cur->_next;cur->_next = next;}--_size;return true;}private:std::vector<Node*> _table;size_t _size; // 存储有效数据的个数};// 哈希表的大小(每个都是素数)template<class K, class V, class Hash = hash_func<K>>const size_t hash_table<K, V, Hash>::_table_count_arr[hash_table<K, V, Hash>::_table_size] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};
}下篇博客,我们就要讨论哈希表的封装,即 unordered_set 和 unordered_map。
相关文章:
哈希表的理解和实现
目录 1. 哈希的概念 (是什么) 2. 实现哈希的两种方式 (哈希函数) 2.1. 直接定址法 2.2. 除留余数法 2.2.1. 哈希冲突 3. 补充知识 3.1. 负载因子 3.2. 线性探测和二次探测 4. 闭散列实现哈希表 (开放定址法) 4.1. 开放定址法的实现框架 4.2. Xq::hash_table::insert…...
)
分治算法(Divide-and-Conquer Algorithm)
分治算法(Divide-and-Conquer Algorithm)是一种重要的计算机科学和数学领域的通用问题解决策略。其基本思想是将一个复杂的大规模问题分割成若干个规模较小、结构与原问题相似但相对简单的子问题来处理。这些子问题相互独立,分别求解后再通过…...
Java项目:基于ssm框架实现的实验室耗材管理系统(B/S架构+源码+数据库+毕业论文+答辩PPT)
一、项目简介 本项目是一套基于ssm框架实现的实验室耗材管理系统 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 二、技术实现 jdk版本:1.8 …...

如何通过专业的二手机店erp优化手机商家运营!
在数字化浪潮席卷全球的大背景下,手机行业作为科技发展的前沿阵地,正经历着前所未有的变革。对于众多手机商家而言,如何在这场变革中抢占先机,实现数字化转型,成为了摆在他们面前的一大难题。幸运的是,途渡…...

CentOS常见的命令及其高质量应用
CentOS是一个流行的、基于Red Hat Enterprise Linux(RHEL)的开源服务器操作系统。由于其稳定性和强大的性能,CentOS被广泛应用于各种服务器环境中。为了有效地管理和维护CentOS系统,熟悉并掌握其常见命令是非常重要的。本文将介绍…...
nodeJs用ffmpeg直播推流到rtmp服务器上
总结 最近在写直播项目 目前比较重要的点就是推拉流 自己也去了解了一下 ffmpeg FFmpeg 是一个开源项目,它提供了一个跨平台的命令行工具,以及一系列用于处理音频和视频数据的库。FFmpeg 能够执行多种任务,包括解封装、转封装、视频和音频…...

Django信号与扩展:深入理解与实践
title: Django信号与扩展:深入理解与实践 date: 2024/5/15 22:40:52 updated: 2024/5/15 22:40:52 categories: 后端开发 tags: Django信号松耦合观察者扩展安全性能 第一部分:Django信号基础 Django信号概述 一. Django信号的定义与作用 Django信…...

使用Docker创建verdaccio私服
verdaccio官网 1.Docker安装 这边以Ubuntu安装为例Ubuntu 安装Docker,具体安装方式请根据自己电脑自行搜索。 2.下载verdaccio docker pull verdaccio/verdaccio3.运行verdaccio 运行容器: docker run -it -d --name verdaccio -p 4873:4873 ver…...

Spring 使用 Groovy 实现动态server
本人在项目中遇到这么个需求,有一个模块的server方法需要频繁修改 经阅读可以使用 Groovy 使用java脚本来时pom坐标 <dependency><groupId>org.codehaus.groovy</groupId><artifactId>groovy</artifactId><version>3.0.9</version>…...

oracle不得不知道的sql
一、oracle 查询语句 1.translate select translate(abc你好cdefgdc,abcdefg,1234567)from dual; select translate(abc你好cdefgdc,abcdefg,)from dual;--如果替换字符整个为空字符 ,则直接返回null select translate(abc你好cdefgdc,abcdefg,122)from dual; sel…...

算法-卡尔曼滤波之卡尔曼滤波的第二个方程:预测方程(状态外推方程)
在上一节中,使用了静态模型,我们推导出了卡尔曼滤波的状态更新方程,但是在实际情况下,系统都是动态,预测阶段,前后时刻的状态是改变的,此时我们引入预测方程,也叫状态外推方程&#…...

刘邦的创业团队是沛县人,朱元璋的则是凤阳;要创业,一个县人才就够了
当人们回顾刘邦和朱元璋的创业经历时,总是会感慨他们起于微末,都创下了偌大王朝,成就无上荣誉。 尤其是我们查阅史书时,发现这二人的崛起班底都是各自的家乡人,例如刘邦的班底就是沛县人,朱元璋的班底是凤…...

【Unity之FairyGUI】你了解FGUI吗,跨平台多功能高效UI插件
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:就业…...
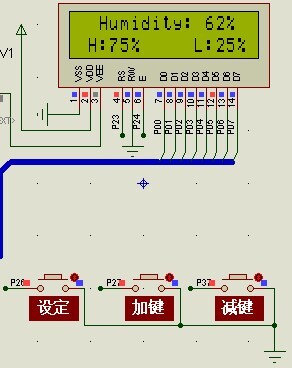
基于51单片机的自动浇花器电路
一、系统概述 自动浇水灌溉系统设计方案,以AT89C51单片机为控制核心,采用模块化的设计方法。 组成部分为:5V供电模块、土壤湿度传感器模块、ADC0832模数转换模块、水泵控制模块、按键输入模块、LCD显示模块和声光报警模块,结构如…...

2024中国(重庆)商旅文化川渝美食暨消费品博览会8月举办
2024中国(重庆)商旅文化川渝美食暨消费品博览会8月举办 邀请函 主办单位: 中国航空学会 重庆市南岸区人民政府 招商执行单位: 重庆港华展览有限公司 展会背景: 2024中国航空科普大会暨第八届全国青少年无人机大赛在重庆举办ÿ…...
MacOS docker 安装与配置
orbstack 安装 官网: https://orbstack.dev 下载链接:Download OrbStack Fast, light, simple Docker Desktop alternative 选择是Apple M系列处理器, 或 Intel系列处理器 到这里就安装好了Orbstack软件,下面开始配置docker 下…...

【嵌入式大赛应用赛道】机械手臂
电机 进步电机:它的转动是以确定的步数进行的,只要计算好脉冲数量和频率,就可以准确预测和控制电机的转动角度、速度以及停止的位置 伺服电机:将输入的电信号(如电压或电流指令)转换成轴上的精确旋转运动…...
MES系统主要包括那些功能?
一开始接触MES系统,对MES细条的功能不清楚,这样很正常,因为MES系统相对于其他系统来讲,功能有多又复杂! 作为曾参与200企业MES系统架构的资深从业人员,我给大家选出了一款优秀模板——简道云MES系统,给大家…...

git 合并commit
操作步骤 合并commit cd xxx/ git checkout a8c0efegfwgtw # 最新commit git reset rhgertheryhg --soft # 最初的commit git status git checkout -b test1 git commit -m "test1" git branch git push origin test1 git tag test1_v0.0.1 git push origin test1_…...
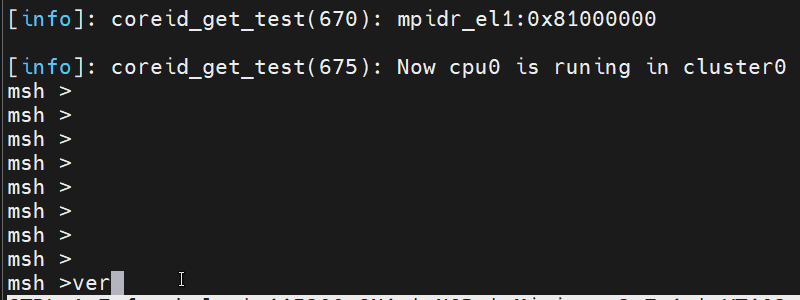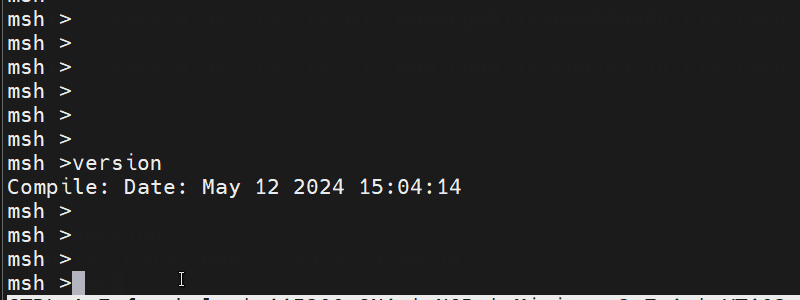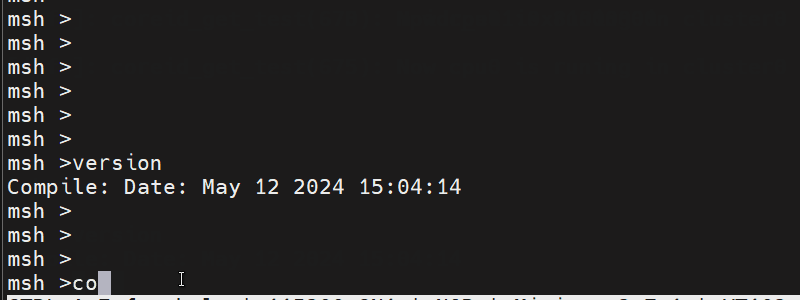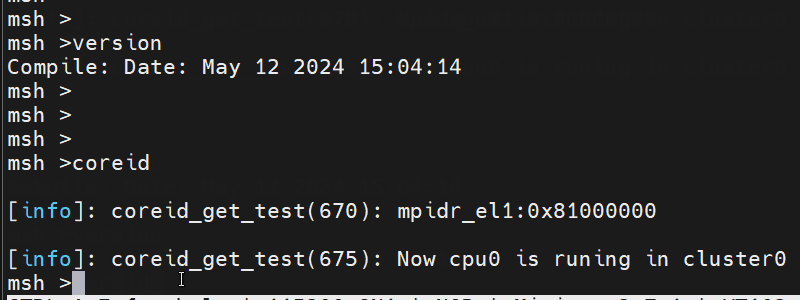
【ARMv8/v9 系统寄存器 5 -- CPU ID 判断寄存器 MPIDR_EL1 使用详细介绍】
文章目录 寄存器名称: MPIDR_EL1寄存器结构:主要功能和用途亲和级别(Affinity Levels)简介CORE ID 获取函数 在ARMv8-A架构中, MPIDR_EL1寄存器是一个非常重要的系统寄存器,它提供了关于处理器在其物理和逻辑配置中的位置的信息。…...
)
超越点灯:深入探索高云FPGA云源软件的高级调试与优化功能(逻辑分析仪+时序约束实战)
超越点灯:深入探索高云FPGA云源软件的高级调试与优化功能(逻辑分析仪时序约束实战) 当LED流水灯项目已经无法满足你的FPGA开发需求时,意味着你正站在从入门到进阶的关键转折点。高云FPGA平台提供的云源软件不仅支持基础开发&#…...

修一个Bug,引入另一个Bug:从Tomcat高危漏洞看中间件安全修复的困境
攻击者无需认证,仅需向集群通信端口发送构造数据,即可绕过加密校验并触发反序列化,实现远程代码执行。这个漏洞的特殊之处在于——它是官方修复上一个漏洞时“顺手”引入的。2026年5月,Apache Tomcat官方披露了一个高危漏洞CVE-20…...

嵌入式开发实战:SPI、UART、I2C三大硬件接口通信协议详解与CircuitPython应用
1. 项目概述:为什么硬件接口是嵌入式开发的基石如果你玩过单片机或者树莓派,肯定遇到过这样的场景:手里有一块炫酷的LED灯带、一个GPS模块或者一个环境传感器,想让它和你的主控板“说上话”,结果发现连线复杂、代码难调…...

柔性电力系统中油浸式变压器的最佳老化极限研究附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &…...

双足机器人步态规划算法与动平衡控制【附仿真】
✨ 长期致力于双足机器人、步态规划、动平衡控制、运动发散分量、模型预测控制、二次优化、可视化仿真研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)…...

番茄小说下载器终极指南:3分钟掌握全平台电子书制作技巧 [特殊字符]
番茄小说下载器终极指南:3分钟掌握全平台电子书制作技巧 🚀 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 番茄小说下载器是一款基于Rust语言开发的专…...

利用Taotoken统一API为多Agent框架提供模型调度服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken统一API为多Agent框架提供模型调度服务 在构建基于Agent的自动化工作流时,一个常见的工程挑战是如何高效、…...

基于CircuitPython与YouTube API的智能直播状态指示器制作指南
1. 项目概述与核心价值 如果你是一个内容创作者,或者你关注的某个频道正在直播,一个醒目、酷炫的“ON AIR”指示灯绝对能瞬间提升氛围感。今天要聊的这个项目,就是基于CircuitPython和YouTube API,自己动手打造一个能自动感知直播…...

基于MCP协议实现AI安全访问MongoDB:架构、部署与安全实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想让大语言模型(LLM)能直接操作数据库,比如MongoDB。这听起来很酷,对吧?想象一下,你直接告诉AI助手“帮我查一下上个月销量最高的产品”&…...

3步彻底清理Windows右键菜单:ContextMenuManager高效管理指南
3步彻底清理Windows右键菜单:ContextMenuManager高效管理指南 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否曾因Windows右键菜单中堆积如山的…...